
将您的LLM API成本削减10倍,速度提升100倍。
ChatGPT和各种大型语言模型(LLM)具有令人难以置信的多功能性,能够开发广泛的应用程序。然而,随着您的应用程序越来越受欢迎并遇到更高的流量级别,与LLM API调用相关的费用可能会变得相当可观。此外,LLM服务可能会显示出响应时间慢的问题,尤其是在处理大量请求时。为了解决这个问题,创建了GPTCache,这是一个专门用于构建语义缓存以存储LLM响应的项目。在线服务通常表现出数据局部性,用户经常访问流行或趋势内容。缓存系统利用这种行为,通过存储常访问的数据来减少数据检索时间,提高响应速度,并减轻后端服务器的负担。传统的缓存系统通常利用新查询与缓存查询之间的精确匹配来确定请求的内容是否在缓存中,然后再获取数据。然而,使用精确匹配的方法对LLM缓存效果较差,因为LLM查询的复杂性和多变性导致缓存命中率低。为了解决这个问题,GPTCache采用了语义缓存等替代策略。语义缓存识别并存储相似或相关的查询,从而增加缓存命中概率并提高整体缓存效率。GPTCache 使用嵌入算法将查询转换为嵌入,并使用向量存储进行这些嵌入的相似性搜索。这个过程使GPTCache能够识别和检索缓存存储中的相似或相关查询,如模块部分所示。GPTCache 具有模块化设计,使用户可以轻松自定义自己的语义缓存。系统为每个模块提供各种实现,用户甚至可以开发自己的实现以满足其特定需求。在语义缓存中,您可能会遇到缓存命中时的假阳性和缓存未命中时的假阴性。GPTCache提供了三种度量标准来衡量其性能,这些对开发者优化其缓存系统非常有帮助:命中率:该指标量化缓存成功满足内容请求的能力,与其接收到的请求总数相比。更高的命中率表明缓存更有效。延迟:该指标衡量处理查询并从缓存中检索相应数据所需的时间。较低的延迟意味着缓存系统更高效和响应更迅速。召回率:该指标表示缓存服务的查询占应由缓存服务的查询总数的比例。更高的召回率表明缓存有效地提供了适当的内容。包括一个示例基准测试供用户开始评估其语义缓存的性能。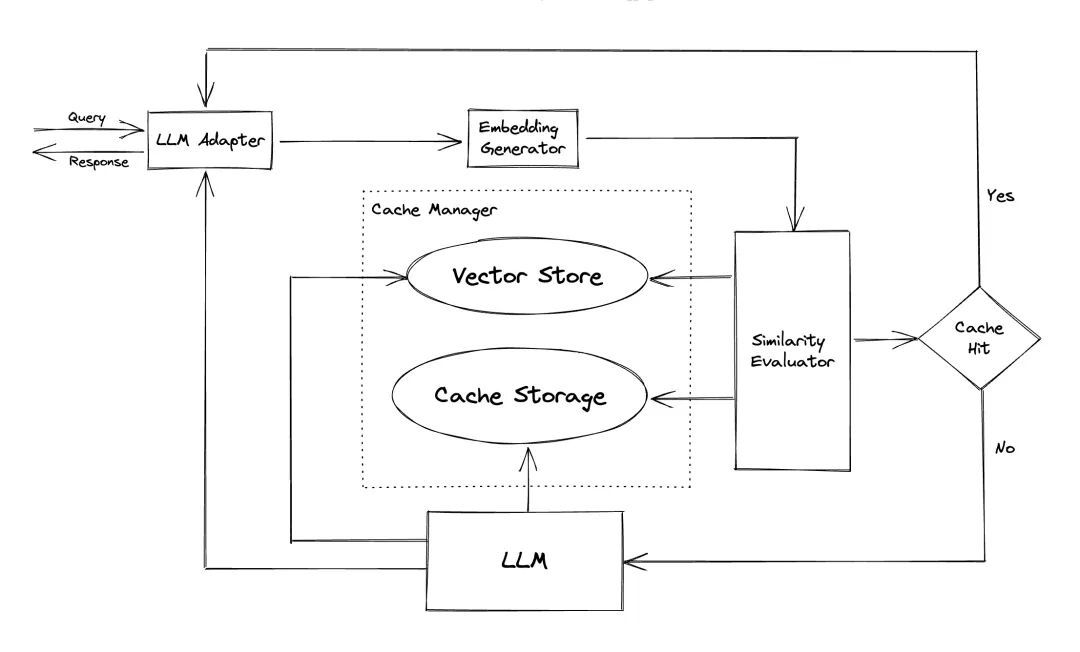
LLM适配器旨在通过统一其API和请求协议来集成不同的LLM模型。GPTCache提供了一个标准化接口,目前支持ChatGPT集成。
- 支持其他LLM,例如Hugging Face Hub、Bard、Anthropic。
多模态适配器旨在通过统一其API和请求协议来集成不同的大型多模态模型。GPTCache提供了一个标准化接口,目前支持图像生成、音频转录的集成。
- 支持Hugging Face稳定扩散管道(本地推理)。
该模块用于从请求中提取嵌入以进行相似性搜索。GPTCache提供了一个通用接口,支持多种嵌入API,并提供多种解决方案供选择。
- 禁用嵌入。这将使GPTCache成为一个关键词匹配缓存。
- 支持使用GPTCache/paraphrase-albert-onnx模型的ONNX。
- 支持使用transformers、ViTModel、Data2VecAudio的Hugging Face嵌入。
- 支持SentenceTransformers嵌入。
缓存存储是存储来自LLM(例如ChatGPT)的响应的地方。缓存的响应被检索以帮助评估相似性,如果有良好的语义匹配,则返回给请求者。目前,GPTCache支持SQLite,并提供了一个通用接口来扩展此模块。
向量存储模块有助于从输入请求的提取嵌入中找到K个最相似的请求。结果可以帮助评估相似性。GPTCache提供了一个用户友好的接口,支持多种向量存储,包括Milvus、Zilliz Cloud和FAISS。未来将提供更多选项。
- 支持Milvus,一个用于生产就绪AI/LLM应用的开源向量数据库。
- 支持Zilliz Cloud,一个基于Milvus的完全托管的云向量数据库。
- 支持Milvus Lite,Milvus的轻量版,可以嵌入到您的Python应用中。
- 支持FAISS,一个用于高效相似性搜索和密集向量聚类的库。
- 支持Hnswlib,一个用于快速近似最近邻的头文件C++/python库。
- 支持PGVector,Postgres的开源向量相似性搜索。
- 支持DocArray,DocArray是一个用于表示、发送和存储多模态数据的库,非常适合机器学习应用。
驱逐策略:目前,GPTCache仅基于行数做出驱逐决策。这种方法可能会导致资源评估不准确,并可能导致内存不足(OOM)错误。我们正在积极研究和开发更复杂的策略。
该模块从缓存存储和向量存储中收集数据,并使用各种策略来确定输入请求与向量存储中的请求之间的相似性。基于这种相似性,它确定请求是否匹配缓存。GPTCache提供了一个标准化接口,用于集成各种策略,并提供了一系列实现供使用。当前支持或将来支持以下相似性定义:
- 使用GPTCache/albert-duplicate-onnx模型从ONNX确定的基于模型的相似性。
- 通过将numpy的linalg.norm应用于嵌入来表示的距离。
注意:不同模块的组合可能不兼容。例如,如果禁用嵌入提取器,则向量存储可能无法按预期工作。我们目前正在为GPTCache实施组合合理性检查。Code: https://github.com/zilliztech/GPTCache
Paper:https://aclanthology.org/2023.nlposs-1.24.pdf
































 粤ICP备17114055号
粤ICP备17114055号
 支持私有云部署
支持私有云部署







