自2022年11月30日OpenAI发布ChatGPT以来,大模型技术掀起了新一轮人工智能浪潮。ChatGPT在各个领域(如人机对话、文本摘要、内容生成问题解答、识图、数学计算、代码编写等)取得了比之前算法好得多的成绩,很多方面都超越了人类专家的水平,特别是人机对话具备了一定的共情能力,这让AI领域的工作者和普通大众都相信AGI(Artificial General Intelligence,通用人工智能)时代马上就要来临了。
大模型除了对话能力达到了跟真正互动的水准,更厉害的是当模型参数规模达到一定量(100B+,这里B是billion,十亿的意思)时,会涌现出新的能力,即大模型具备举一反三、任务分解、逻辑推理、解决未知任务的能力,这在之前的机器学习范式中是从没见到过的。之前的机器学习都是为某个具体任务构建的,只能解决特定任务,对于新任务,必须训练一个新的机器学习模型。
最近7-8年都没有哪一项科技进步如ChatGPT这般吸引全球的目光(上一次引发全球关注的AI大事件是2016年的AlphaGo)。除了媒体的大肆报道,国内外各类科技公司、科研机构、高等院校都在跟进大模型技术,基于大模型的创业公司如雨后春笋一样冒出。国外有Google发布的Bard、Meta发布的LLaMA、Anthropic的Claude等,不到一年时间,国外就跑出了上百家大模型应用的创业公司,做得优秀的如m、Midjourney、runway、inflection AI、Anthropic等,都获得了上亿、甚至几十亿美元的融资,估值达数十亿、上百亿美金规模。国内也不甘落后,各个大厂、创业公司、科研院校都相继发布了大模型产品(如智谱AI的ChatGLM、百度的文心一言、华为的盘古大模型、阿里的通义大模型、科大讯飞的星火大模型等),也有不少科技大佬亲自下场做大模型,如李开复、王慧文、王小川等。以ChatGPT为核心的大模型相关技术,可以应用于搜索、对话、内容创作等众多领域。推荐系统也不例外,在这方面已经有广泛的学术研究了,学术界已经发表过大量的相关论文。我相信不久的将来(2024~2025年)大模型相关技术会在工业界大量用于推荐系统,大模型相关技术一定会成为推荐系统的核心技术,就像2016年开始深度学习技术对推荐系统的革新一样。ChatGPT、大模型相关技术不能被任何人、任何行业忽视,它在各行各业的应用一定会出现井喷。我在2023年初开始一直在跟进大模型相关技术的进展以及在行业上的应用,特别是在推荐系统领域的应用。在这个每天都有大模型相关重磅突破发布的时间节点,我们必须跟上技术发展的步伐。为此,我花了近一年的时间写了这本《推荐系统:算法、案例与大模型》著作,这本书是国内第一本包含大模型应用于推荐系统的著作。希望本书能抛砖引玉,起到在国内普及推广大模型在推荐系统上的应用的作用。
同时为了读者更好地学习这本书中大模型推荐系统的知识,我还写了一个配套的大模型推荐系统的代码实战课程,包含完整的代码实现案例,手把手教你从零到一实现大模型推荐系统。你可以扫码下面链接了解。
为了让你能够更好理解大模型怎么应用于推荐系统,我先用非常直觉、浅显的方式来简单说明,有了这个基础认识,我相信你可以更好地学习本书和在线课程的知识。
大模型是通过海量的互联网文本信息,通过在底层构建Transformer架构,预测下一个token(token可能是一个单词也可能是一个单词的一部分)出现的概率来训练模型的(BERT等模型是基于左右两边的token预测中间的token,这属于模型架构上的不同)。由于有海量互联网文本数据,模型的训练过程不需要人工标注(但需要对数据进行预处理),一旦模型完成预训练就可以用于解决语言理解和语言生成任务。简单来说,大模型基于海量文本中token序列中下一个token出现的概率进行统计建模,来学习在给定语言片段后出现下一个token的概率来解决下游任务(比如文本摘要、翻译、生成文本等)。对于推荐系统,用户过往的操作行为其实就是一个有序的序列,每个用户的操作序列类似于一篇文本,所有用户的操作行为序列类似于大模型的训练语料库。预测用户下一个操作行为就类似于预测词序列的下一个token(这里推荐系统的物品类似语言模型中的一个token)。通过这个简单的类比,我们就知道推荐系统是可以嵌入到大模型的理论框架中的。因此,直观地看,大模型一定是可以用于解决推荐系统问题的。

图3:大模型预测下一个token跟推荐系统预测下一个用户行为是类似的
上面的思路比较简单,只用到了用户与物品的交互信息。实际上,推荐系统的数据来源更复杂,除了有用户交互序列,还有用户画像信息、物品画像信息等。部分用户画像、物品画像信息(比如用户的年龄、性别、偏好等,物品的标题、标签、描述文本等)可以利用自然语言来呈现,行为交互序列、用户画像、物品画像等信息都可以输入到大模型中给大模型提供更多的背景知识,最终的推荐会更加精准。

图4:以新闻推荐为例,推荐系统依赖4类数据
推荐系统涉及到的数据很多都是多模态的(比如物品有描述文本、有图片、甚至有视频介绍等),这类异构的信息对于推荐系统的效果相当重要。多模态信息可以通过转化为文本信息供大模型使用,目前的多模块大模型可以直接处理多模态数据,这类多模态大模型也可以直接用于推荐系统。即使目前不使用图片、视频等多模态数据,利用好文本数据就已经很强大了。大模型的强大之处是具备ICL(zero-shot、few-shot)的能力(简单解释一下:zero-shot就是预训练后直接可以解决未知下游任务,few-shot就是给出几个示例,大模型可以解决类似的问题,即所谓的In-Context Learning能力,也就是举一反三的能力)。有很多方法就是利用了大模型这个能力进行推荐,只不过需要在使用大模型过程中设计一些prompt(提示词)和模板(template)来激活大模型的推荐能力。说一下我个人对激活的理解。大模型有上百亿、上千亿、甚至上万亿参数,是一个非常庞大的神经网络。当用一些prompt告诉大模型作为一个推荐系统角色进行推荐时,就激活了深度神经网络中的某些连接,这些连接是神经网络的某个子网络,而这个子网络具备进行个性化推荐的能力,这个过程非常类似人类大脑神经元的工作机制,比如你看到美食时,就会激活大脑中负责进食的区域——这个区域是大脑整个复杂神经元网络的子网络,导致看到美食可能流口水、吞咽等行为,这里看到美食就类似大模型的prompt。另外,我们在进行头脑风暴时,突然被别人启发想到某个绝妙的创意也是一种激活过程。对于few-shot更复杂一些,需要在prompt中告诉大模型一些怎么进行推荐的案例(比如用户看了A、B、C三个视频后,会看另外一个视频D),让它临时学习怎么做推荐。prompt学习是没有改变大模型的参数的(即没有进行梯度下降的反向传播训练),但为什么具备few-shot、zero-shot的能力呢?prompt作为一个整体,激活了大模型神经网络的某个功能区域。大模型具备多伦对话能力的道理也是类似的,我们可以将多伦对话作为一个整体,这个整体激活了大模型在某个对话主题下的功能区域,导致大模型能“记住”多伦对话之前的信息(因为是将这个对话作为整体输入大模型的,或者可以理解为整个对话过程就是一次连贯的语言生成过程,只不过部分话语是人类给出的,模型接着人类的话语继续生成)。对话完成后,这个对话中的新信息是没有被大模型学习到,因为目前的大模型不具备增量学习的能力(也就是遇到一个新信息马上学习到模型的参数中,人是具备增量学习能力的,增量学习肯定是大模型未来最重要的一个研究方向)。同时,我们还可以在prompt中提供具体问题的思路,让大模型学习解决问题的方法,然后大模型就具备举一反三的能力,这就是所谓大模型的CoT能力。在新闻推荐中你可以告诉大模型用户之前看了什么后面又看了什么,大模型就会学会你的兴趣偏好,为你进行下一步推荐。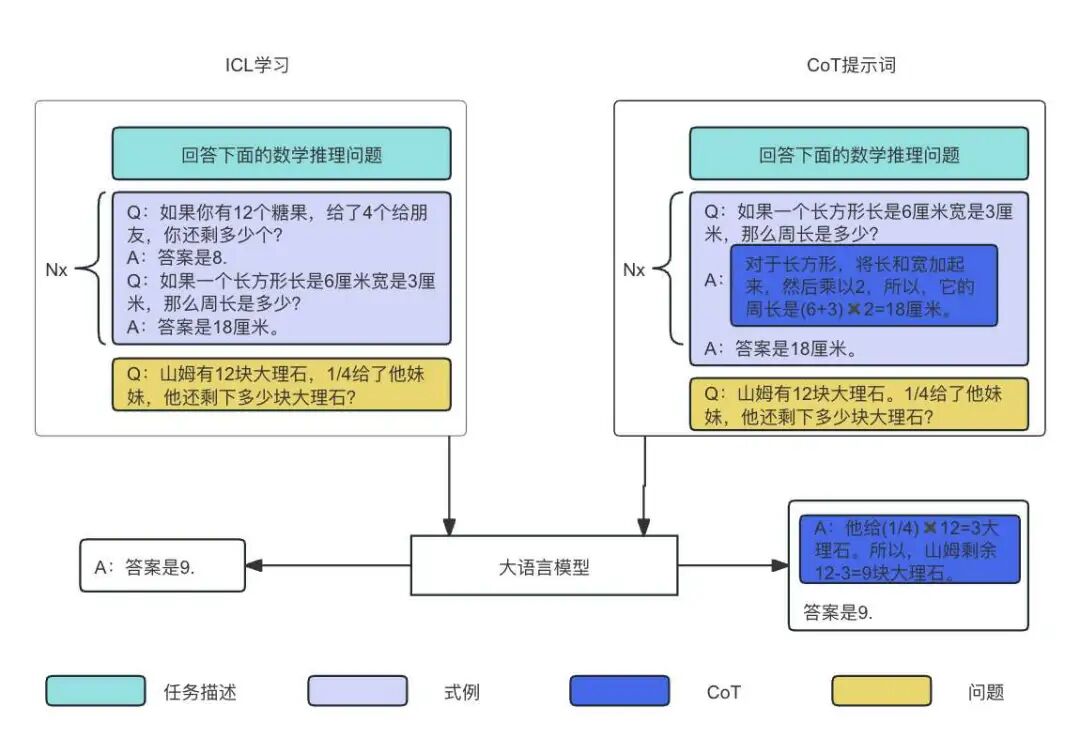
图5:大模型的ICL与CoT能力
除了直接利用大模型的ICL、CoT能力进行推荐,我们可以将推荐系统相关的数据按照大模型的输入、输出范式进行准备,然后通过监督学习微调大模型,这样可以让大模型更好地适配具体的推荐场景,这也是大模型应用于推荐系统的一个非常有价值的方向。另外,大模型压缩的世界知识、大模型的涌现能力、大模型的自然对话能力都可以很好地被用于推荐系统,解决之前推荐系统很难解决的问题,下面举两个例子说明:首先,大模型可以帮助缓解数据稀疏性问题,特别是冷启动问题(因为大模型学习的是海量的互联网的知识,对于新物品、新用户都可以很好进行知识的迁移),这是当前深度学习推荐模型的主要瓶颈。通过从不同模型架构中学习的预训练模型中提取和迁移知识,可以在通用性、稀疏性、效率和有效性等多个角度提高推荐系统的性能。其次,大模型另外一个很大的优势是可以利用对话的方式跟用户互动,就如ChatGPT所呈现的那样,如果能将推荐系统设计成一个跟用户互动的对话式推荐引擎,那么大模型可以利用自然语言响应用户的个性化需求,从而提升用户整体体验和参与度。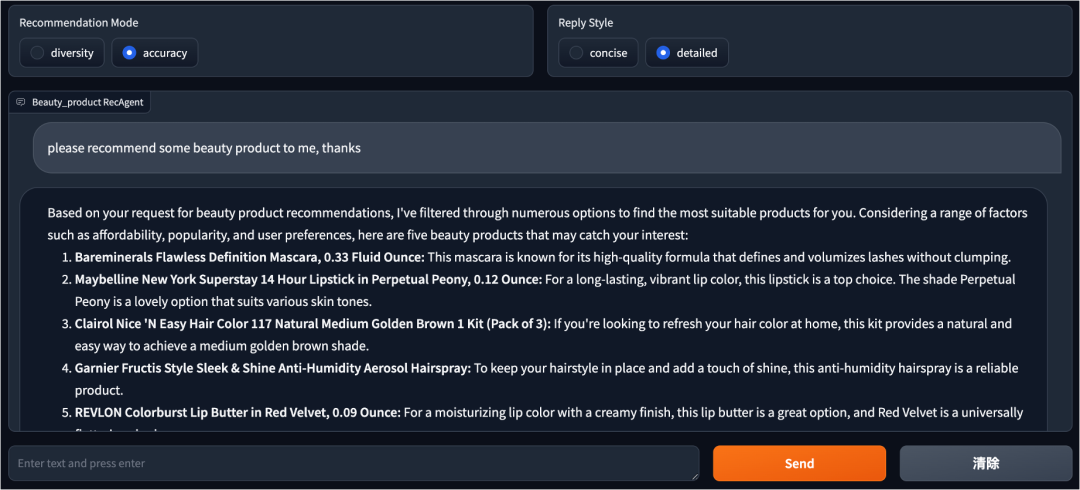
图6:对话式互动案例
通过前面的介绍,相信你能够大致知道为什么大模型可以应用于推荐系统了,也知道了大模型应用于推荐系统的几个独特的优势,那么大模型怎么应用于推荐系统呢?这就是这本书和在线课程的核心主题,你能从这本书和在线课程中找到答案。
大模型带来的技术革新和交互范式革新,引起了全球的关注。这是第四次科技革命,它带来的变革力量一定远超前几次科技革命!是指数级的爆发!自从ChatGPT发布以来,大模型相关的技术呈井喷之势,几乎所有的科技公司都重金投入到了大模型的研究、开发、实践中。苹果都放弃了10年的造车计划,准备投入到大模型的创新和落地中,目前已经宣布了跟百度进行合作的计划,在今年(2024)新发布的硬件产品中增加生成式AI能力!苹果的决策一般是当一个行业比较成熟、有非常大的商业前景的时候做出的,他们一定是相信现在大模型正在带来产业颠覆和巨大的商业价值!大模型越来越有革新所有行业的势头:Sora的发布带来了视频生产的革命,目前OpenAI正在跟好莱坞谈合作,希望通过生成式AI来革新影视制作;OpenAI投资的Figure 01机器人,可以理解人的意图,在测试人员说饿了的时候,将面前唯一能吃的苹果递给了他;初创公司CognitionLabs推出的全球第一个AI程序员Devin,它掌握了全栈的技能,不仅可以写代码、debug,训模型,还可以去美国最大求职网站Upwork上抢单;一家专注研发无代码游戏引擎的初创公司BuildBox AI,发布了新一代AI游戏引擎——Buildbox 4 Alpha,它可以做到输入提示即可为游戏添加资产和动画,或者只需几个字就能生成整个场景;最近(2024年3月底)大火的Suno,可以通过输入一段提示词,直接生成高质量的音乐,让人人都成为作曲家......上述这些革新行业、给世界带来极大变化的新产品和新应用场景层出不穷,每天都发生在我们身边!我们不能无视这些变化的存在,否则最终我们的工作被AI取代了,自己还蒙在鼓里。AI取代的永远是那些不会使用AI的人!最好的应对第四次AI革命的方法就是尽快掌握它,而掌握的第一步是尽早开始学习!作为从事推荐系统的我们也不例外,开始学习大模型在推荐场景的应用是我们必须要经历的过程!推荐系统作为过去10年互联网科技中最重要的技术手段,是互联网公司最核心的商业化工具,创造了抖音、tiktok等以推荐系统为核心引擎的、具备极大变现效率的产品。一般来说,越是具备商业价值的场景,人类越会利用新技术去变革它。既然推荐系统有这么大的商业价值,一定是以大模型为驱动引擎的新技术革新的方向,这正是学术界和产业界当前正在努力推进的!阿里去年上半年已经在淘宝上开启了淘宝问问(一个对话式推荐产品)的内测;百度也将大模型应用到了最核心的广告营销场景;meta已经在尝试利用大模型技术进行万亿级参数的新一代推荐系统的尝试。
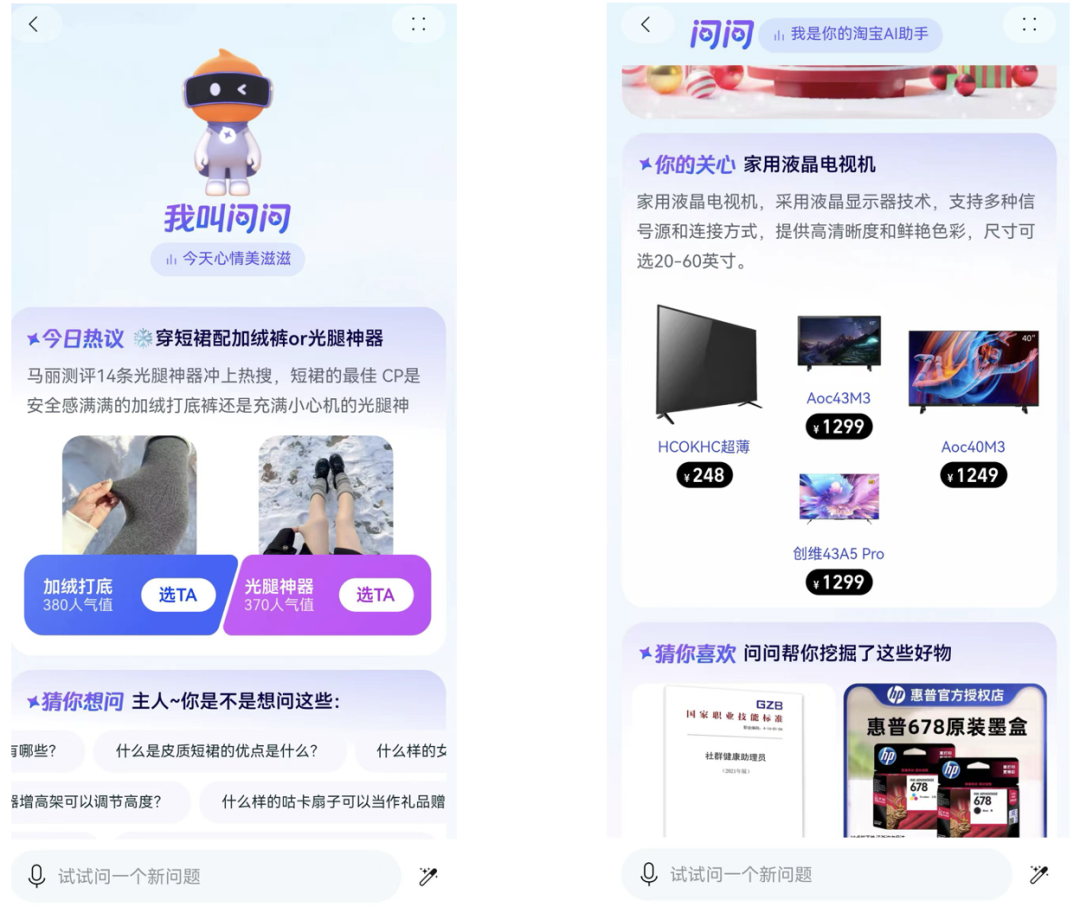
图7:淘宝问问——在淘宝首页搜索淘宝问问会出现上述界面
有了大模型加持的推荐系统就像人有了大脑一样,可以将传统的推荐技术等融合到一个统一的对话式框架下,让大模型来利用已有的工具(传统的召回算法、搜索、比价等)来为你提供更加个性化、更好交互友好的推荐。
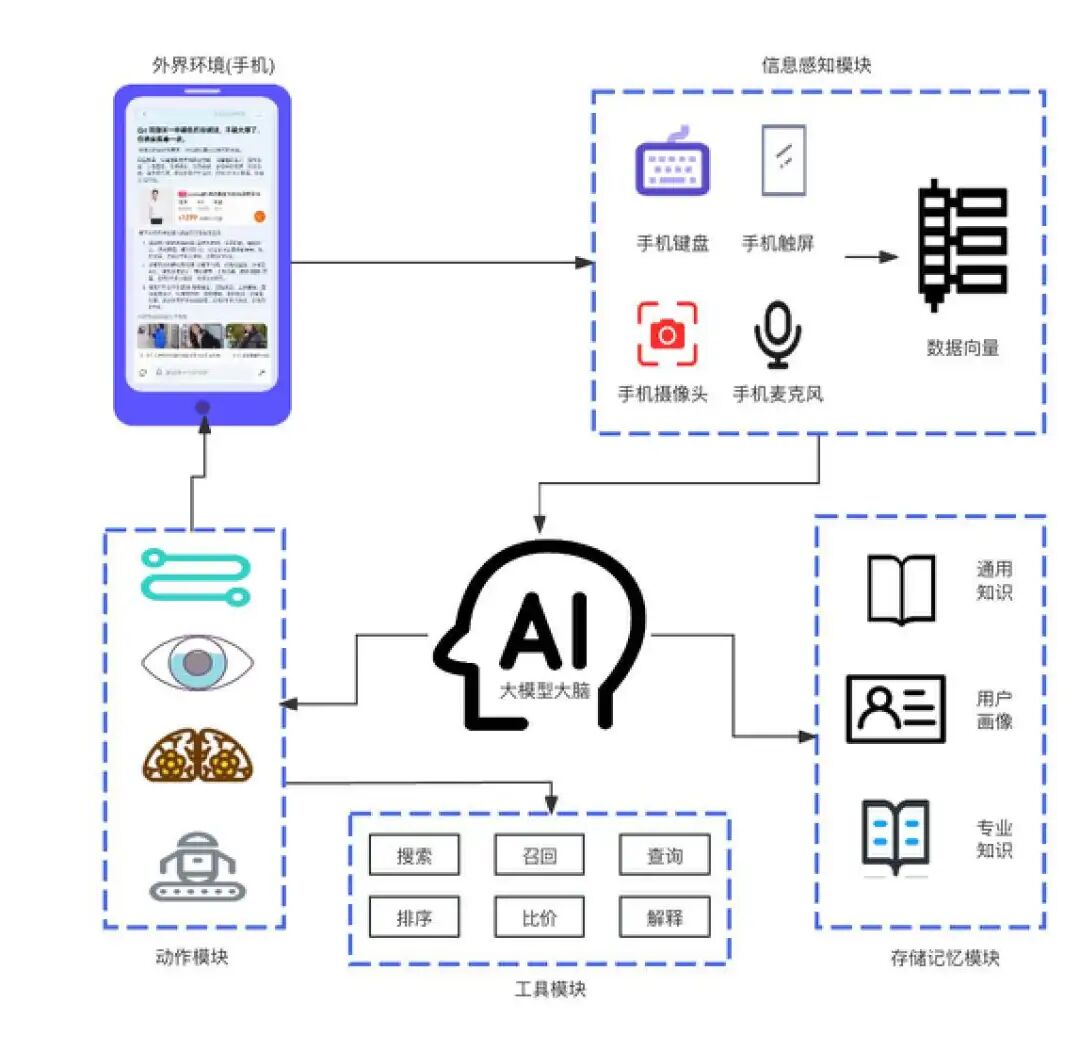
图8:大模型做为大脑的推荐系统
上面只是举了一些大模型应用推荐系统上的思路和场景,大模型在推荐系统上的应用还有很多很多.......就拿推荐系统最有业务价值的电商场景来说,大模型的应用可以覆盖到样本、特征、商品“生产”、排序、推荐解释、冷启动、交互推荐等等。下面用一个脑图总结大模型在电商场景上的应用。
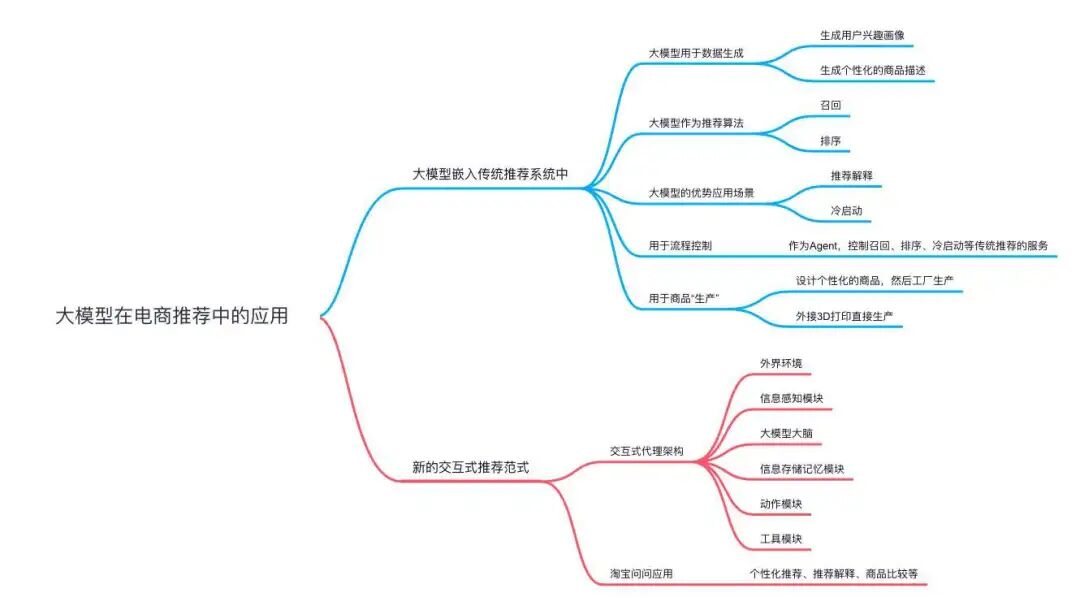
图9:大模型在电商中的应用
阿里、百度、抖音、快手等大公司已经走在了前面,已经在尝试将大模型应用到推荐系统中了。而作为从事推荐系统开发的我们,也不能落后前进的步伐!我们需要马上出发!这本书和在线课程就是我给大家提供的大模型推荐系统学习的导航图。它正是为了应对AI变革大势而进行的尝试和探索。希望这本书和在线课程可以帮到你,通过本书的学习,让你尽早入门和实践大模型推荐系统!






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
