导读 本文介绍了腾讯金融科技 AI 开发平台的建设背景和目标,以及在建设过程中遇到的挑战和解决方案。平台经历了多个阶段的发展,但仍存在开发效率低和使用门槛高的问题。为解决这些问题,进行了一站式开发平台的建设,实现了特征工程优化、模型开发效率优化、模型训练能力优化和推理服务稳定性保障。
1. 业务背景&目标介绍
2. 技术挑战与解决方案
3. 未来规划
4. Q&A
分享嘉宾|罗潍红 腾讯金融 腾讯FiT AI平台负责人
编辑整理|朱佳佳
内容校对|李瑶
出品社区|DataFun
01

- 民生服务,如手机充值、信用卡还款、还有一些企业金融相关的业务;
2. AI 开发平台发展历程
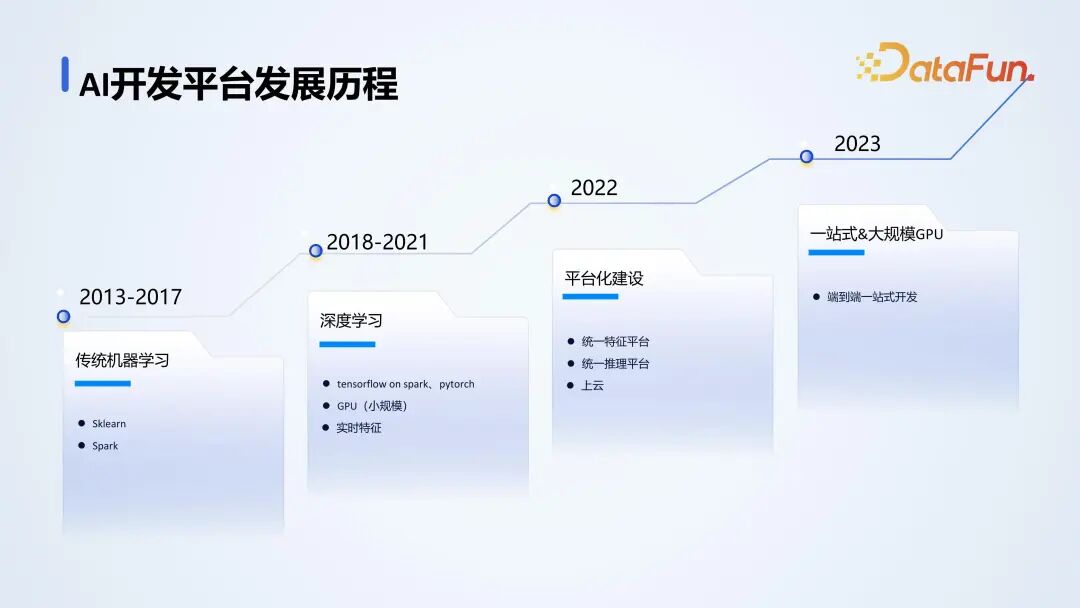
腾讯金融 AI 开发平台的发展经历了四个阶段,第一个阶段是传统的机器学习阶段,第二个阶段是深度学习的阶段。在发展过程中存在一些问题,如重复开发、特征不能共享、能力没有沉淀等,所以在 2022 年进行了统一特征平台的建设和统一推理平台的建设。到 2023 年,仍存在开发效率低和使用门槛高的问题,为解决这些问题,进行了一站式开发平台的建设。
3. AI 开发平台 2022 年遇到的挑战

2022 年,我们对各个算法团队进行了调研,希望解决如下四个问题:- 特征工程性能和特征质量:团队希望业务场景样本的周期拉长,这样可以更好地学习到金融场景的波动性,但这样会使得样本加工耗时久,资源占用大;同时特征质量和特征重要性评估,都缺乏体系化的工具。
- 模型开发效率优化:因不同团队负责的业务目标不同,各团队独立开发,导致算法重复开发,无法共享和复用优秀的算法资产。
- 模型训练能力优化:当样本周期拉长、模型参数变大后,训练效率就会降低,无法满足业务要求。
- 模型服务稳定性优化:所有算法团队的推理服务都统一后,请求量比较大,希望有一个很好的稳定性保障。
4. AI 开发平台目标与整体架构
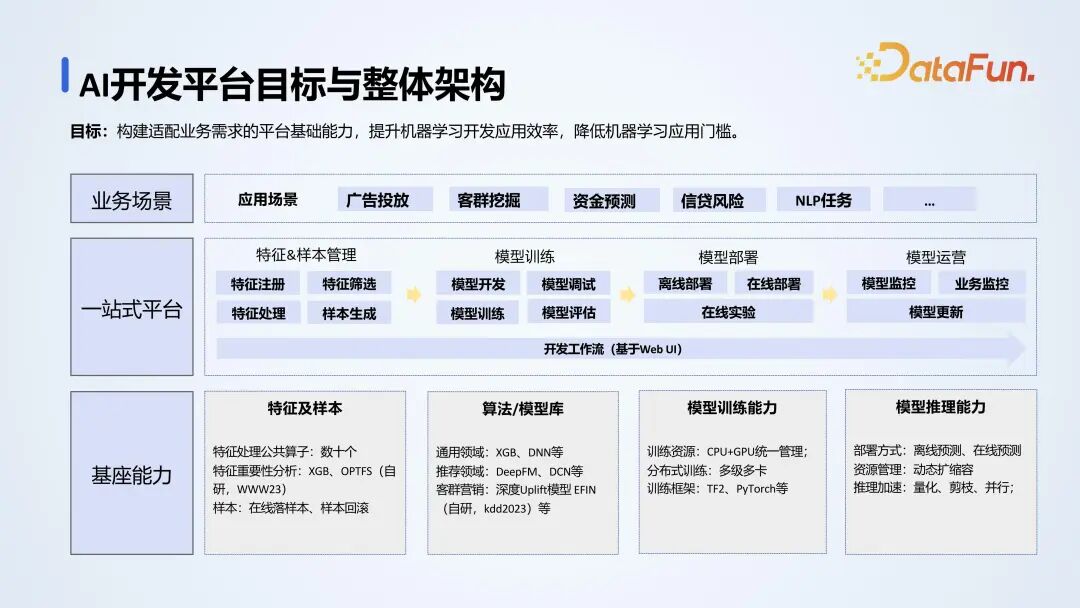
基于上述问题,我们希望构建适配业务需求的平台,提升算法开发的效率,降低算法开发的门槛。
首先搭建平台的基础能力,沉淀样本处理的算子和特征重要性分析的组件,包括样本生成和加工的一些任务。在算法模型库的建设方面,我们把各个团队的一些开源的算法,自研的算法等都统一管理。在模型训练方面,基于 CPU 和 GPU 搭建了一个分布式的训练框架。在模型推理方面,统一实现离线批量预测和在线预测的功能,包含推理加速、资源管理等。
基于这些基础组件的能力,搭建一站式 AI 开发工作流,从特征筛选到特征处理、样本构建、模型训练调试评估、模型的部署和实验,再到后期模型的运维监控,贯穿算法开发的整个流程。
技术挑战与解决方案
1. 特征及样本技术挑战和解决方案
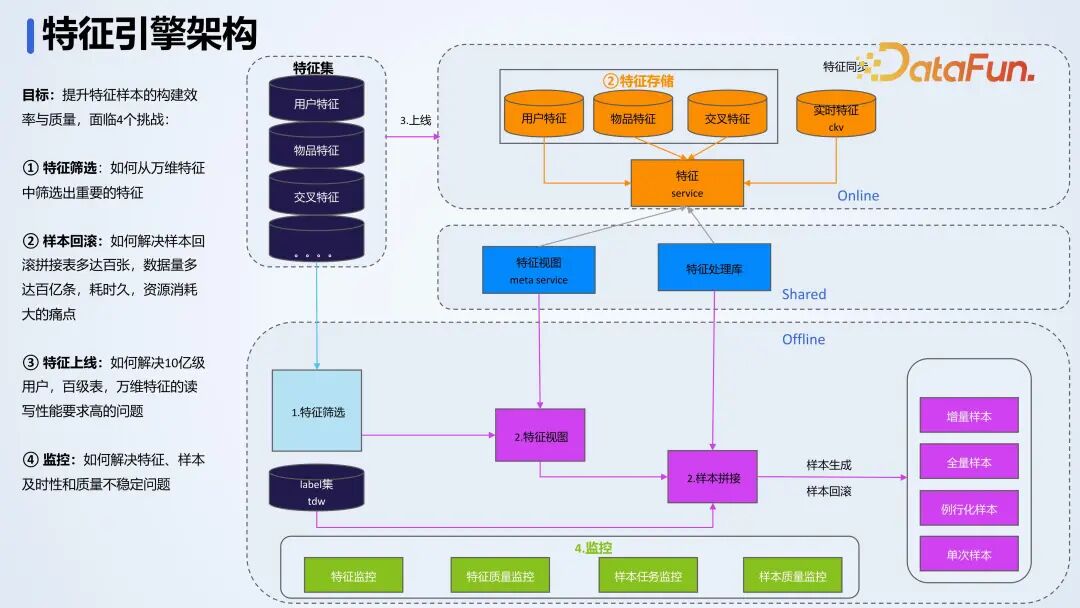
上图是特征引擎的架构,主要分为两部分,在线服务和离线服务。在线特征服务主要提供特征推理、特征读取及特征处理服务。离线特征服务主要提供特征筛选和特征拼接。特征上线后,需要对特征和样本进行监控。整个过程中,会遇到四个问题:特征筛选、样本回滚、特征上线和监控。
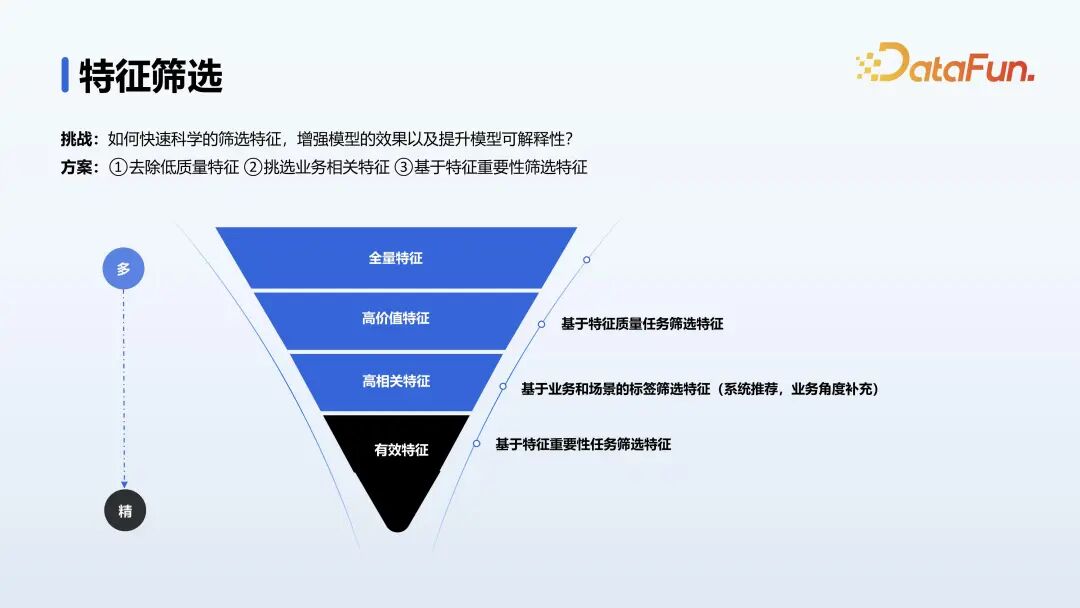
特征筛选是建模的第一个步骤,特征决定了机器学习效果的上限,模型只是逼进这个上限,所以特征筛选是一个非常重要的步骤。首先基于特征质量从全量特征中筛选出一些高价值特征,然后基于业务场景,推荐历史表现较好的特征。特征初筛后,基于特征重要性的算法来进行特征重要性的筛选,比如过滤法、包裹法、嵌入法等。
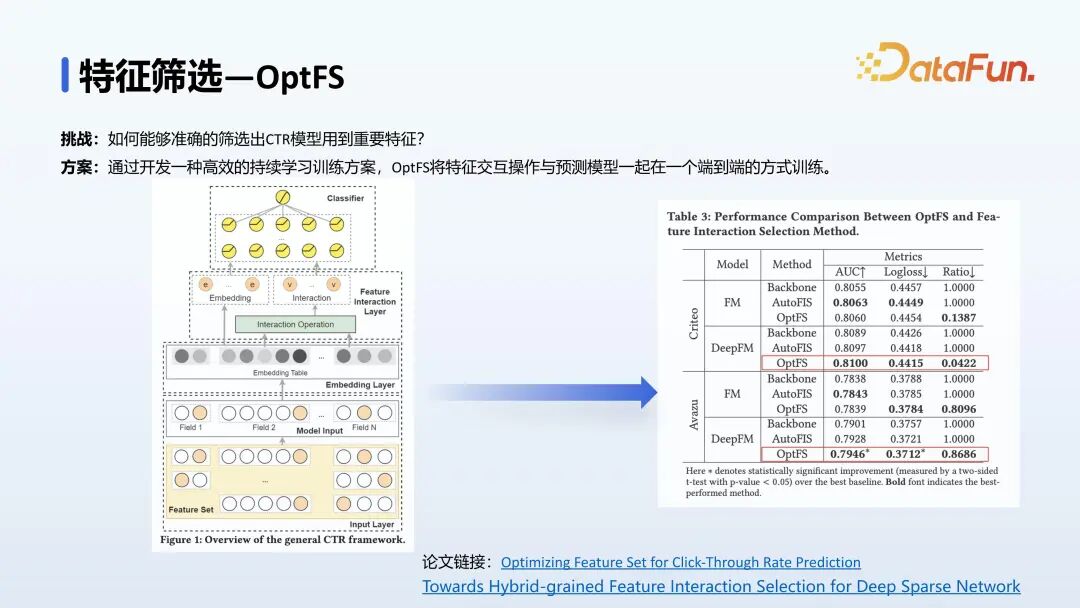
在特征筛选方面,我们开发了一种高效的持续学习的训练方案,能够准确地筛选出 CTR(用户点击率预估)模型的重要特征,该模型将特征交互操作与预测模型一起在一个端到端的方式训练,该方法已经发表论文,论文链接见图片。
论文的主要工作是在特征输入之后,对特征进行 Embedding,之后在Embedding 上进行特征交互和特征选择,捕捉输入特征之间的相互作用。经过在公开数据集的测试发现,我们的方法相比于一些公开方法有显著的提升。
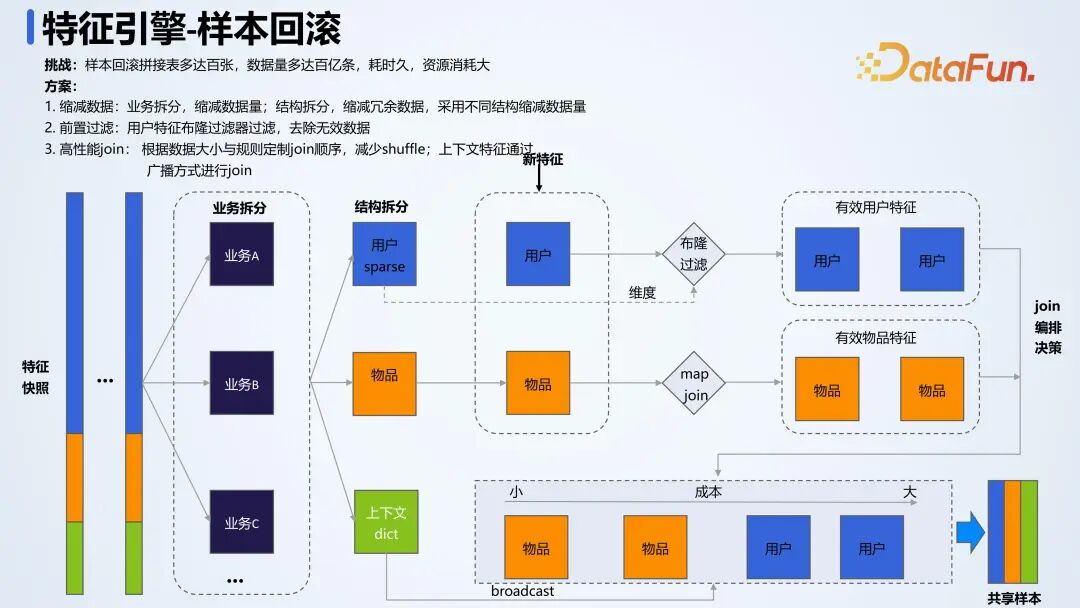
在样本拼接过程中,由于样本回滚需要拼接的主题表数量众多,且数据量较大,对性能带来了挑战。为解决这个问题,在生成特征快照时,按业务拆分特征,缩减数据量,同时采用 Sparse 存储格式进行数据存储。另外,在处理用户与 Label 拼接时,使用布隆过滤器解决 join 性能问题。对于公共特征,可将其转化为字典类型,然后使用广播进行 join。同时,针对多表 join 的情况,可在内存中 join 小表,然后将大表的数据放在硬盘中 join,以提升 join 效率。
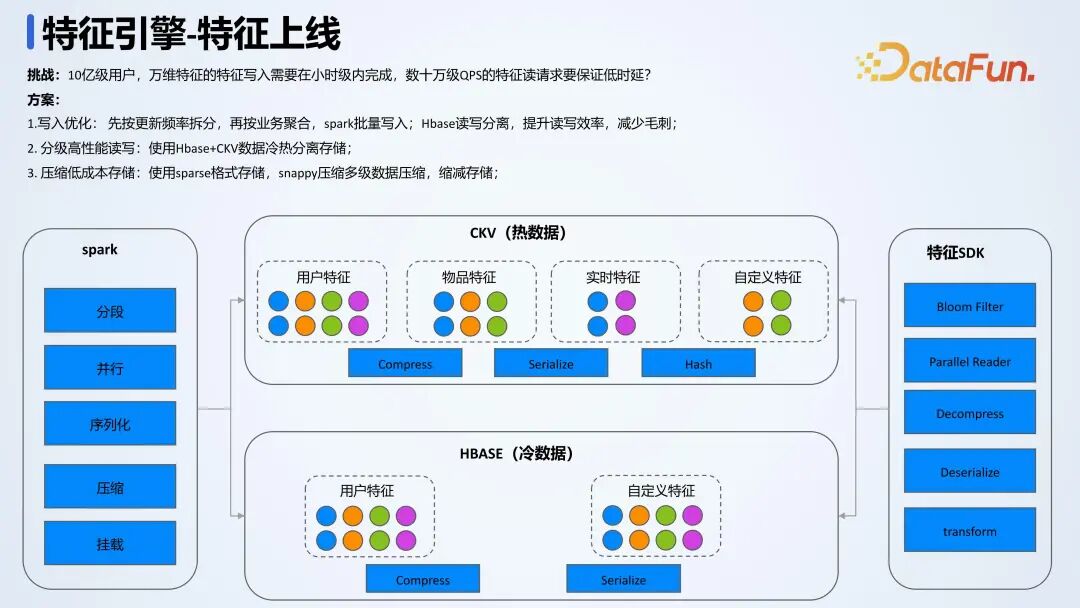
特征上线后,首先根据特征的更新频率进行拆分,然后按照业务进行聚合,以解决读写性能问题。其次,通过数据分离降低成本,将冷数据存在 HBase 中,热数据存储在 CKV 中;为了解决读写的相互影响,对 HBase 进行了读、写分离。
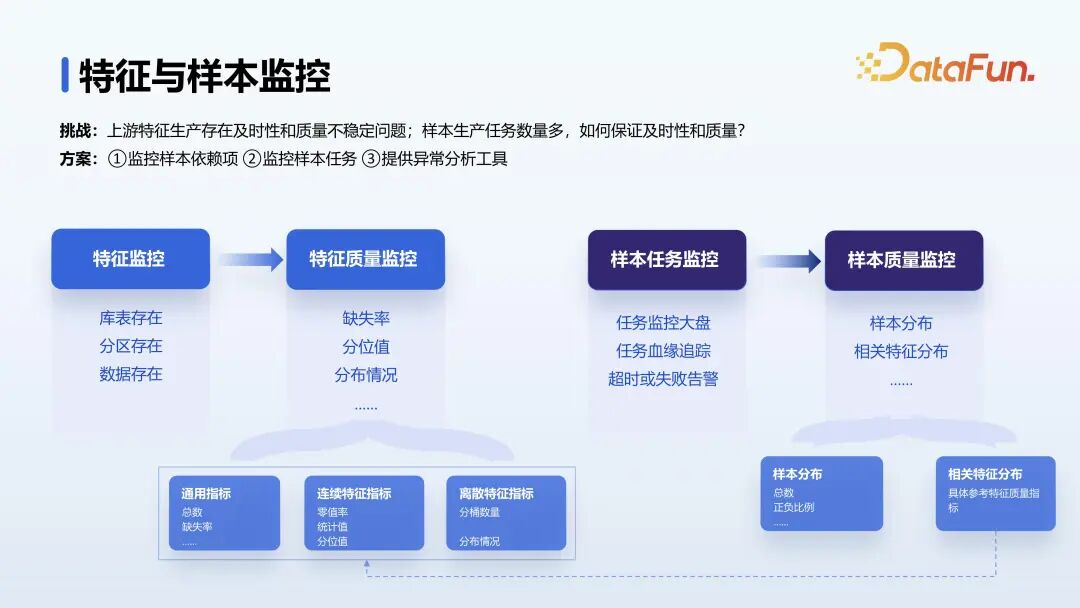
特征上线后,上游特征可能会存在及时性和质量不稳定的问题,我们对特征和样本进行监控,比如特征缺失率、分布;样本条数的变化、分布的变化等。以快速发现和解决问题。
2. 训练优化
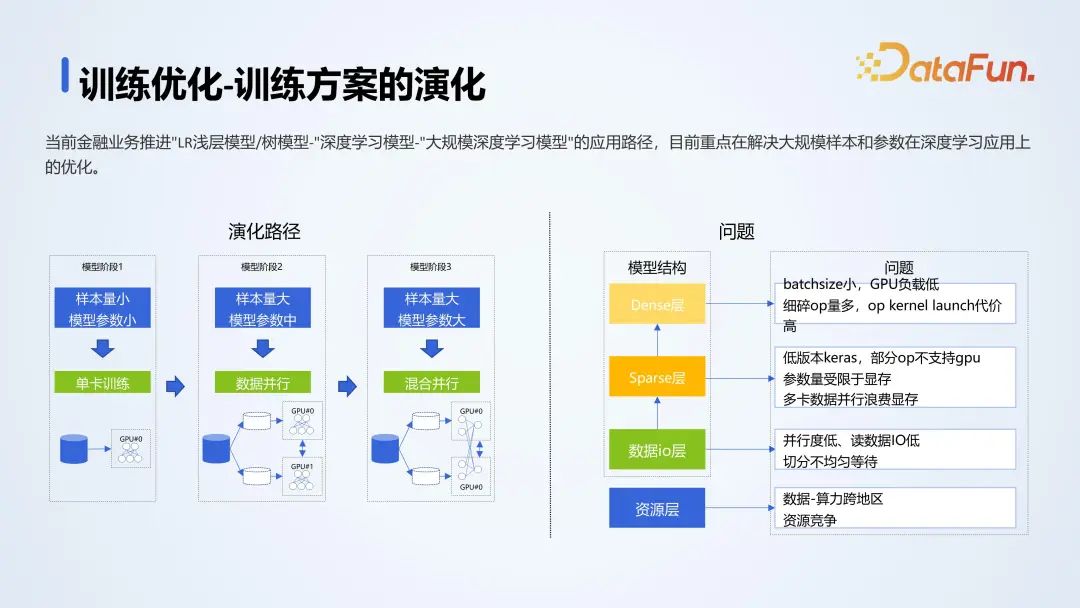
模型训练经历了不同阶段,从浅层模型到深度学习模型,再到目前的大规模深度学习模型。目前重点解决的问题是处理大规模样本和参数在深度学习应用上的优化。在小样本和小模型的情况下,单卡 GPU 可以有效解决问题,但随着样本和模型参数的增加,需要考虑多卡并行训练、混合并行训练的方式。
模型结构方面,数据读取 IO、Sparse Embedding 层和隐藏层,会在计算的过程中遇到不同的程度挑战。
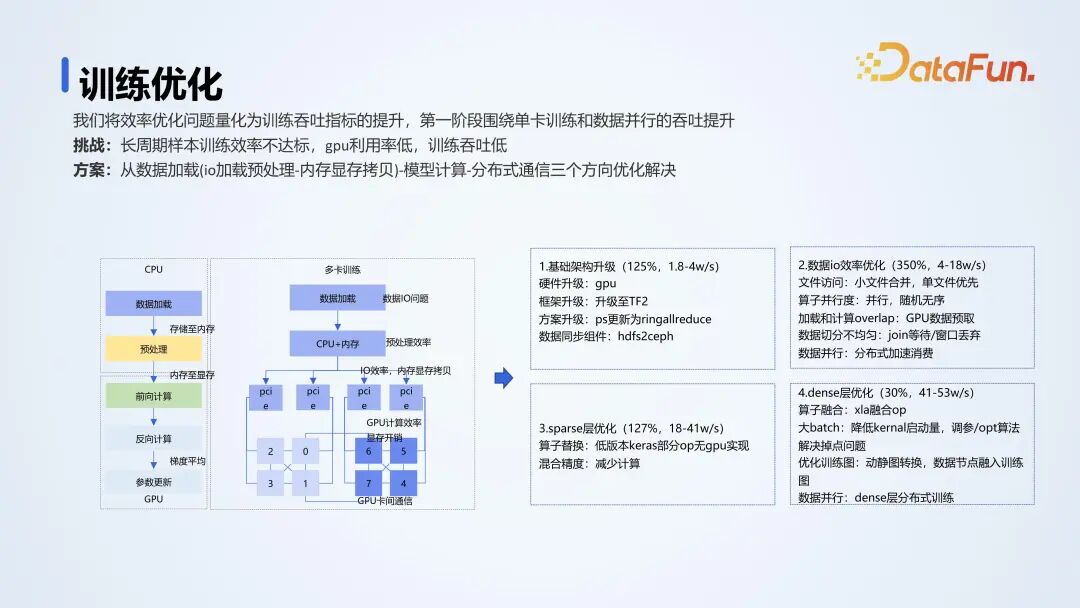
在大规模深度学习模型训练中,会遇到样本和参数量大,以及数据 IO 效率低的问题。数据加载过程中,从存储到内存再到 GPU 显存,CPU 加载数据的效率可能无法跟上 GPU 处理的速度,导致 GPU 的利用率较低。我们采用的解决方案如下:- 升级基础架构:将框架升级到 TensorFlow 2,同时进行通信和其它组件的升级。使用对象存储以加快训练数据的加载速度。
- 数据 IO 效率优化:生成样本时采用 TFRecord(Tensorflow 支持的一种数据格式),合理设置文件数以减少性能影响。对于小文件过多的情况,采用合理的文件数以提高读取效率。
- GPU 数据加载优化:采用预加载方式,提前将接下来几个批次需要使用的数据加载到GPU,解决 GPU 数据 IO 问题。
- Sparse Embedding 层优化:对算子进行优化,替换成 GPU 的时间并进行混合精度相关的操作。进行 dense 层的一些优化,包括算子和动静图转换的相关优化。
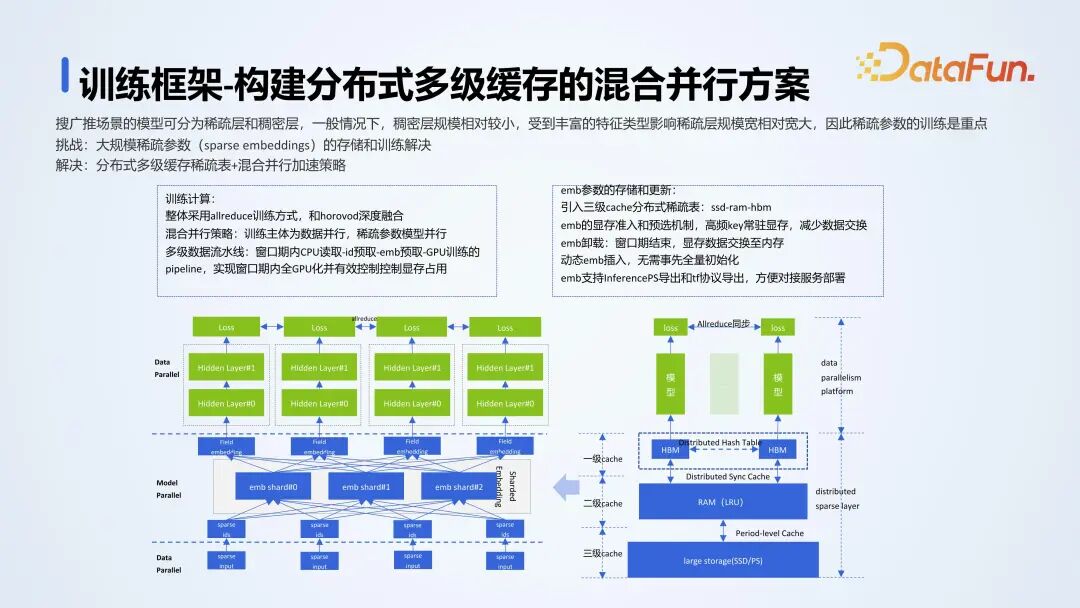
当模型参数规模增大后,单卡 GPU 无法存储大规模模型参数,例如 100B 的参数 FP16 类型需要 200G 显存。我们采用以下方案解决:- 多卡训练:首先采用多卡训练,和 Horovod 深度结合来解决模型参数规模过大的问题。
- 混合并行:在 Sparse Embedding 层使用模型并行,Dense 则采用数据并行,实现混合并行训练。
- 多级流水线:使用 CPU 读取、预取 ID 和 Embedding 预取,以解决混合训练的问题。
- 缓存优化:采用三级缓存的方式进行优化,利用 SSD 类存储、内存、显存构建三级缓存来解决 Embedding 的读取性能问题。
3. 模型部署
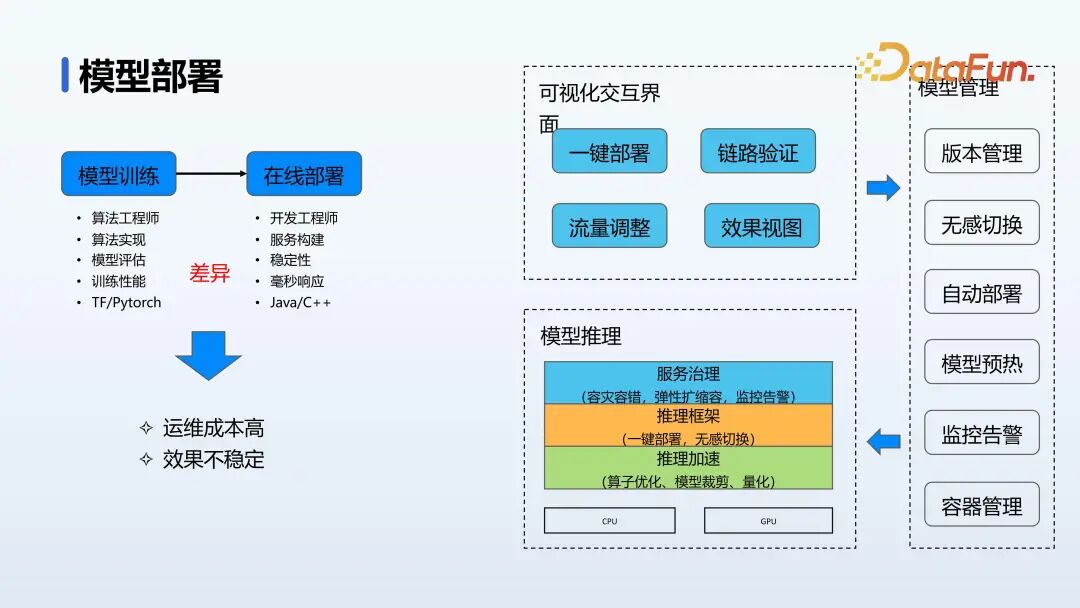
在模型部署阶段,需要开发工程师介入,因为算法和开发在工作流程和专业性上存在差异,但是生产环境对性能和稳定性要求都比较高,不是所有算法工程师都能很好的解决。
- 统一推理服务:建立统一推理服务,提供可视化界面,让算法工程师自主进行模型部署。可视化界面支持模型部署链路验证、流量切换和效果验证。
- 模型切换验证:在模型切换之前进行验证,确保新模型能够顺利运行且符合预期。若新模型不符合预期,保留老模型继续运行,并进行监控告警通知。
- 推理加速:通过算子优化、模型裁剪和量化等手段实现推理加速。
- 服务治理:用云原生的架构进行服务治理,包括容灾、容错、弹性扩容等措施,提高服务可用性和稳定性。
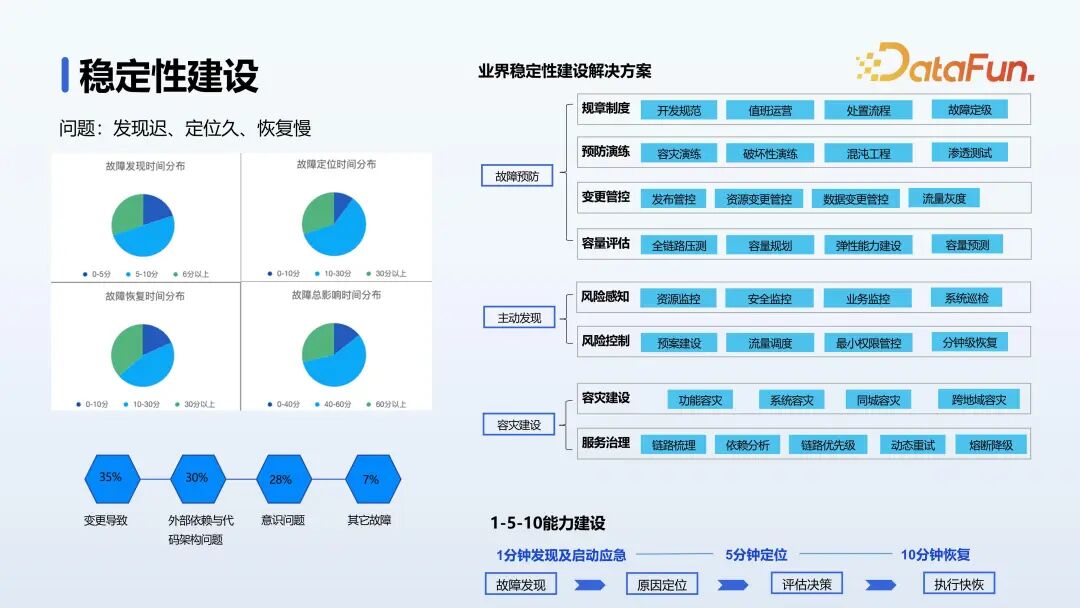
在系统稳定性方面,超过 35% 的故障是由于系统变更导致的,代码本身也可能存在需要优化的地方,关键依赖和代码性能问题会导致线上故障。意识性问题如未遵守开发规范,也是导致故障的原因之一。我们采用以下方案解决:- 系统稳定性维护阶段:按照变更规范进行变更,以降低故障概率。
- 代码和关键依赖优化:优化代码本身,解决关键链路和依赖的性能问题,进行全链路梳理。
- 意识问题解决方案:复盘检查开发规范和变更规范的遵守情况,提高系统稳定性。
- 容灾演练:进行容灾演练,注入故障,模拟实际场景,提高团队应对故障的速度和能力。
最终的目的是能够一分钟发现问题,五分钟定位到问题,十分钟恢复问题。快速恢复的关键在于能够快速发现问题、快速回滚和有良好的降级措施。
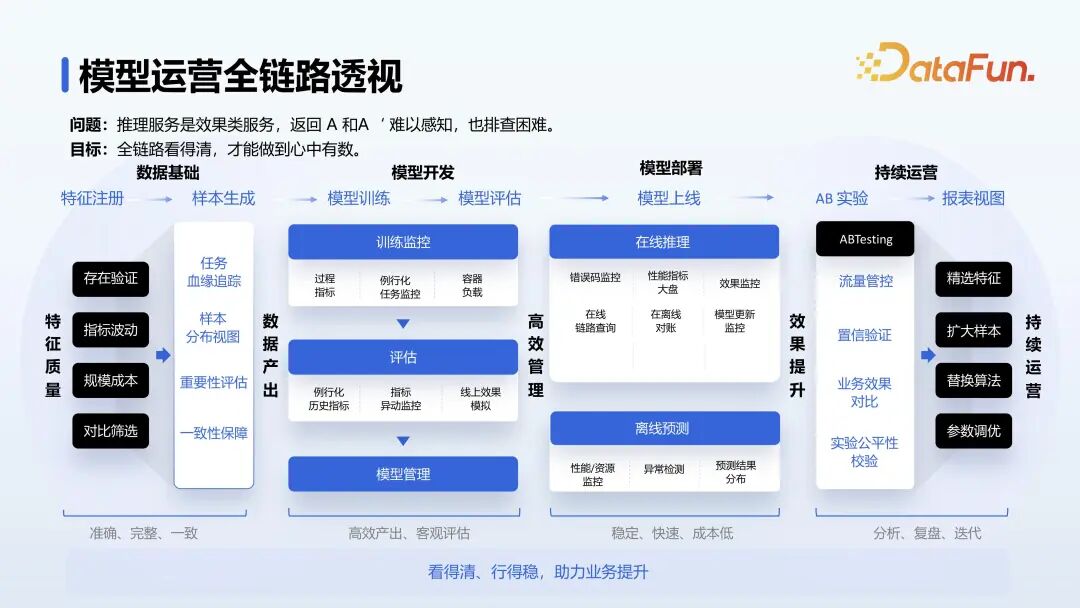
模型的全链路运营,包括特征样本监控、模型训练与开发过程监控以及在线推理的监控。在模型训练中,关注 AUC 等指标,完成后对 AUC 和测试数据进行线上预测结果的评估。在线推理阶段进行错误码、性能、效果等方面的监控,包括问题定位工具、在线模型分数、离线预测监控以及与 AB 实验系统的对接。
最后是整个平台结构的展示,分为数据处理、特征样本生成、模型开发与训练、模型部署以及全链路运营监控四大模块,结构清晰明了。
未来规划

平台未来的规划,包括两大部分,首先,继续完善大规模图训练;另外,在AutoML(自动机器学习)方面,对超参调优和模型选择继续优化。
Q&A
A1:平台目前不考虑开源,因为与公司内部组件的依赖性较强,开源存在一定的复杂性,但整个 AI 平台构建的思路是值得借鉴的。
A2:有两个地方用到了布隆过滤器。首先,在用户样本拼接中,由于用户特征量级较大,而标签(Label)在采样后量级较小,为了快速处理拼接操作,通过布隆过滤器在用户特征数据处理节点上缓存目标的用户 ID,解决了 join 性能问题。其次,在特征 SDK 中,需要判断用户是冷特征还是热特征,通过对冷热特征进行布隆过滤器,实现了快速的冷热特征查询路由。总体而言,布隆过滤器在这两个场景中提供了有效的解决方案。
A3:首先,事前阶段强调开发人员进行设计方案的评审,开发规范的执行、以及代码质量的评审。其次,在发布过程中要做好灰度和可回滚的准备。最后,事后阶段需要快速发现问题和恢复问题。
Q4:大模型对整个平台的功能架构分布上有没有什么影响?
A4:具体来说,大模型与传统的搜广推模型有着不同的模型结构,需要与其不同的训练框架来支持。另一方面,在推理阶段,大模型的推理成本也高,需要对其进行性能优化,涉及到开源方案有 vLLM,TensorRT-LLM 等。整体而言,集团的大模型团队在这些方面都做得比较成熟,我们计划进一步加强这些功能的集成和优化。

































 粤ICP备17114055号
粤ICP备17114055号