构建能够处理多样化任务并在不同环境中自我演化的通才智能体是人工智能界的长期目标。大型语言模型(LLMs)因其通用能力而被视为构建此类智能体的有希望的基础。当前的方法要么让基于LLM的智能体逐步模仿专家提供的轨迹,这需要人类监督,难以扩展并限制了环境探索;要么让智能体在隔离的环境中探索和学习,导致专家智能体的出现,这些智能体在泛化方面有限。在本文中,我们迈出了构建具有自我演化能力的通用LLM基础智能体的第一步。我们确定了三个要素:1)多样化的环境,供智能体探索和学习;2)一套轨迹,为智能体提供基本能力和先验知识;3)一种有效且可扩展的演化方法。我们提出了智能体健身房,这是一个新框架,具有多种环境和任务,支持广泛的、实时的、统一格式的、并发的智能体探索。智能体健身房还包括一个数据库,包含扩展指令、基准套件和跨环境的高质量轨迹。接下来,我们提出了一种新方法,AGENTEVOL,以研究智能体在跨任务和环境的自我演化潜力。实验结果表明,演化出的智能体可以达到与最先进模型相当的结果。我们发布了智能体健身房套件,包括平台、数据集、基准、检查点和算法实现。
我们翻译解读最新论文:在多样化环境中演化智能体,文末有论文链接。
 作者:张长旺,图源:旺知识
作者:张长旺,图源:旺知识
1 引言
开发能够在多样化环境中执行广泛任务的智能体一直是人工智能界的长期目标,并且已经进行了重大的努力[1; 2; 3; 4; 5]。与人类学习类似,智能体首先通过模仿[4; 6]获得基础知识和技能。随着其发展,智能体预计将通过与不同环境的交互不断学习和适应以前未见的任务[7; 8; 6; 9]。此外,它可能利用来自自身和他人的丰富洞察力和智慧,发展出一定程度的泛化能力[10; 11]。图1描绘了这一演化过程。

在本文中,我们采取了构建具有自我演化能力的通用LLM基础智能体的第一步。我们确定了三个关键要素:首先,多样化的环境和任务,允许智能体动态和全面地演化,而不是被限制在孤立的世界中,这可能会限制泛化[7; 23; 8; 6]。其次,适当大小的轨迹集,用于训练具有初步指令遵循能力和知识的基线智能体。这有助于进一步探索,因为在多样化、复杂的环境中,让智能体通过试错从头开始学习一切将极其低效[6; 22]。第三,一种有效且灵活的演化方法,能够适应不同难度的环境并激发基于LLM的智能体的泛化能力。这涉及到智能体如何与环境互动以及如何利用反馈[19; 20]。
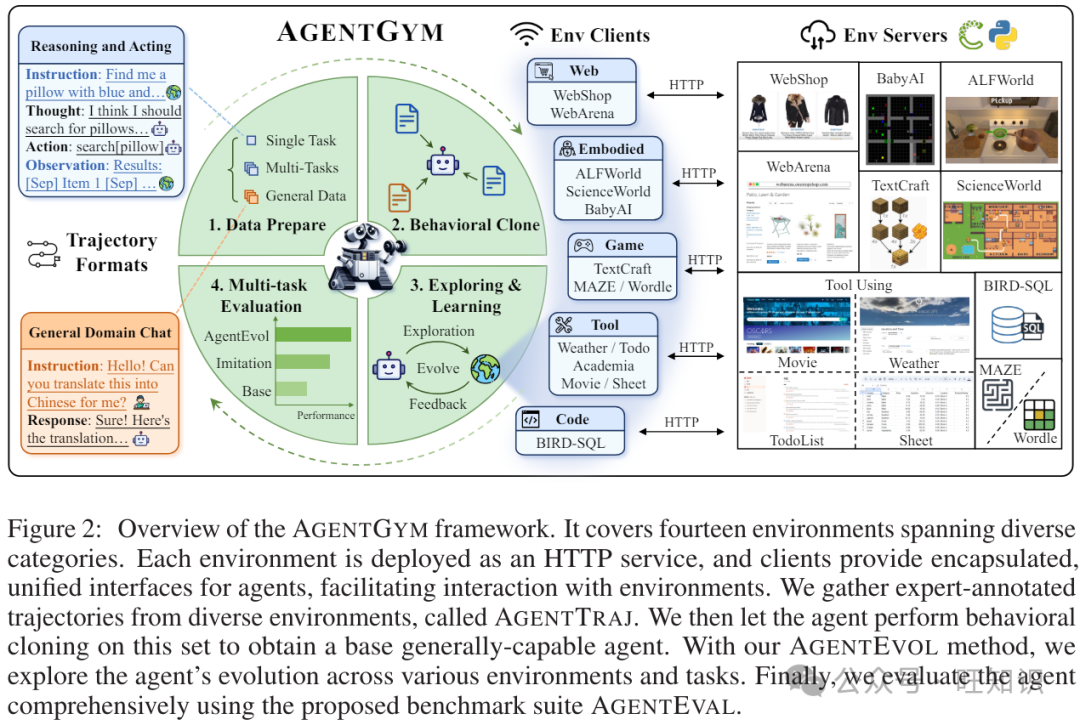
考虑到这三个要素,我们提出了AGENTGYM(见图2),这是一个新框架,旨在帮助社区开发具有通用能力的LLM基础智能体并探索自我演化。我们的主要贡献是:
一个交互式平台,包括多样化的环境、任务和目标,适用于LLM基础智能体。AGENTGYM通过HTTP服务提供便捷的API,标准化任务规范、环境设置以及智能体的观察/动作空间。在此平台上,我们实现了多轮交互和不同环境的实时反馈的统一接口,以支持在线评估、轨迹采样和交互式训练。具体来说,它包括14种智能体环境、89种任务,涵盖网络任务[24; 25]、具身任务[26; 27]等[28; 29; 30; 31; 32],具有高度的灵活性以扩展到其他环境。
扩展指令、基准套件和跨环境的高质量交互轨迹。我们从各种环境和任务中收集指令,并通过众包和基于AI的方法如自指导[33]和指令演化[34]进行扩展。随后,我们选择一个多样化且具有挑战性的子集形成测试集,构建名为AGENTEVAL的基准套件。接下来,使用众包程序和最先进的(SOTA)模型,我们注释并筛选了一个统一格式的轨迹集,名为AGENTTRAJ。
基于环境反馈对通用LLM基础智能体的自我演化进行初步调查。从基础通用智能体开始,我们提出了AGENTEVOL,一种新方法,用于探索智能体在多个环境和任务中的演化。我们的重点是调查智能体在面对以前未见的任务和指令时是否能够自我演化,这要求它们进行探索并从新经验中学习。实验结果表明,智能体的演化非常显著,甚至达到了与SOTA模型相当或更好的性能。此外,我们进行了充分的消融分析,以展示我们的方法如何工作。
总之,我们展示了AGENTGYM,这是一个包括多个智能体环境的交互平台、AGENTEVAL基准套件和两个轨迹集AGENTTRAJ和AGENTTRAJ-L的新框架。我们还提出了一种新算法AGENTEVOL,探索了通用LLM基础智能体的自我演化。我们将发布整个套件、算法实现和智能体检查点。我们希望AGENTGYM能够帮助社区开发新的算法和进步,以实现更好的通用LLM基础智能体。
2 预备知识
我们定义环境集合为 。对于特定的 ,我们将环境中的智能体任务形式化为部分可观察的马尔可夫决策过程(POMDP)
,其中指令空间为 U,状态空间为 ,动作空间为 ,观察空间为 ,确定性状态转移函数 ,以及奖励函数 。
给定环境中的任务指令 u,由 θ 参数化的基于LLM的智能体根据其策略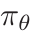 生成一个动作
生成一个动作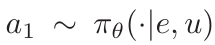 。然后,状态空间转移到 S1 ,智能体接收反馈 O1。随后,智能体与环境交互,直到任务结束或超过最大步数。我们采用 ReAct [35] 来建模智能体输出,即基于LLM的智能体在输出动作之前生成一个推理思考。因此,在时间步,给定历史和当前反馈,智能体首先生成思考
。然后,状态空间转移到 S1 ,智能体接收反馈 O1。随后,智能体与环境交互,直到任务结束或超过最大步数。我们采用 ReAct [35] 来建模智能体输出,即基于LLM的智能体在输出动作之前生成一个推理思考。因此,在时间步,给定历史和当前反馈,智能体首先生成思考 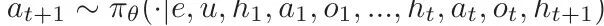 。其轨迹表示为:
。其轨迹表示为:
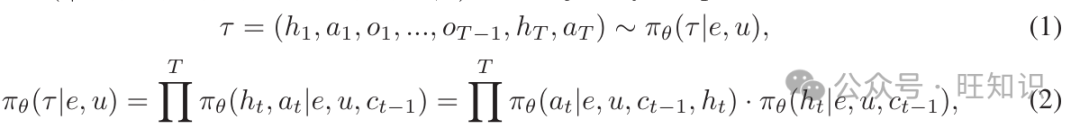
其中 是交互轮数, 表示直到t-1的交互历史。最终奖励计算为
表示直到t-1的交互历史。最终奖励计算为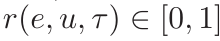 范围内的值。
范围内的值。
3 AGENTGYM: 平台、基准套件和轨迹集
AGENTGYM是一个旨在帮助社区轻松评估和开发通用LLM基础智能体的框架。它具有多样化的交互环境和任务,采用统一格式,即ReAct格式[35]。它支持实时反馈和并发,易于扩展。我们包括了14个环境和89个任务,涵盖网页导航、文本游戏、家务任务、数字游戏、体现任务、工具使用和编程。它们对当前的LLM基础智能体来说具有挑战性。对于网页导航任务,我们引入了WebArena (WA) [24]和WebShop (WS) [25]。我们在文本游戏中包括了MAZE (MZ)和Wordle (WD) [28]。我们选择ALFWorld (ALF) [29]用于家务任务。我们将SciWorld (Sci) [26]和BabyAI (Baby) [27]包括在体现任务中。我们选择TextCraft (TC) [30]用于数字游戏。我们得到Tool-Weather (WT)、Tool-Movie (MV)、Tool-Academia (AM)、ToolSheet (ST)和Tool-TODOList (TL) [31]用于工具使用任务。我们为编程任务建立了BIRD (BD) [32]。见附录C了解环境详情。表1展示了AGENTGYM与其他框架的比较。
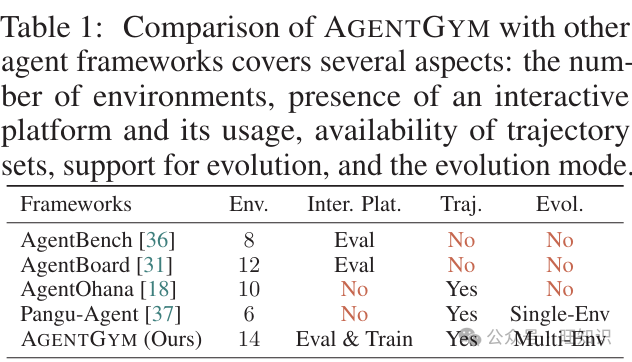
表1:AGENTGYM与其他智能体框架的比较涵盖了几个方面:环境数量、交互平台的存在及其使用、轨迹集的可用性、对演化的支持以及演化模式。
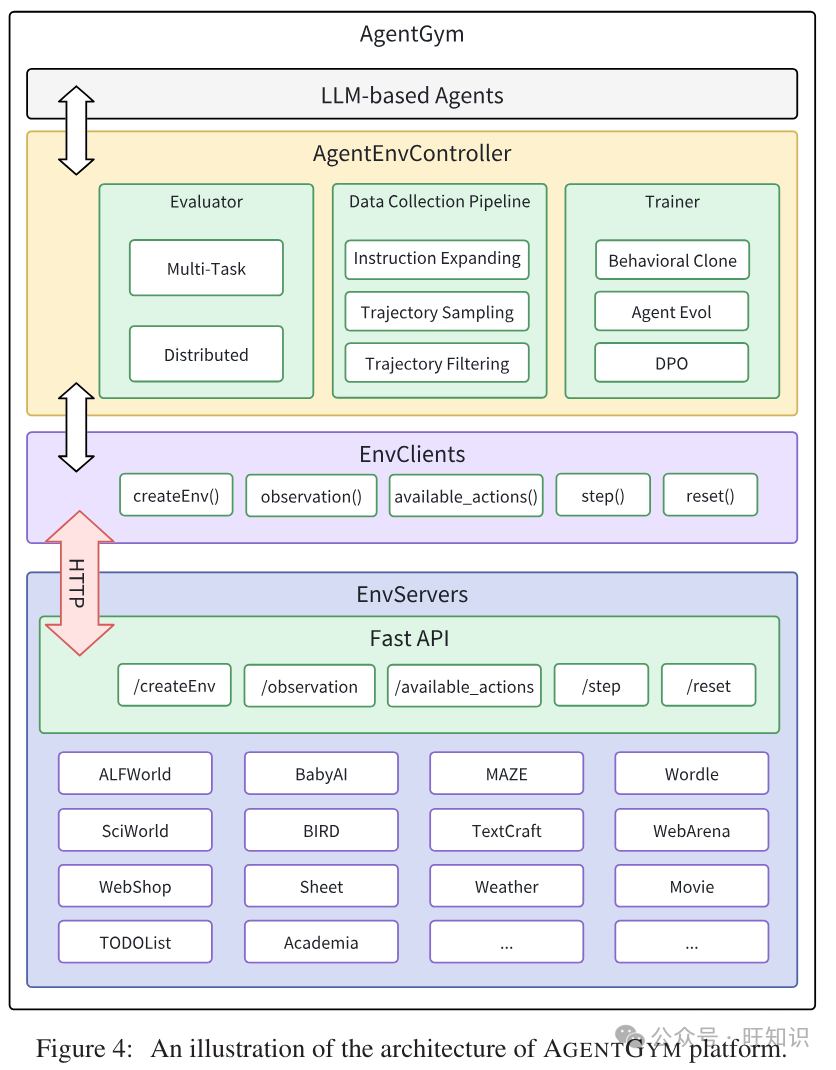
平台架构和组件 认识到不同智能体环境固有的多样化依赖性,AGENTGYM以用户友好的方式为每个环境部署单独的服务以防止冲突。客户端可以使用HTTP协议与环境通信。该架构的核心是控制器,它作为智能体与环境服务之间交互的通道,为智能体提供了封装的、统一的环境功能或操作接口。此外,我们还实现了用户友好的组件,如评估器、训练器和数据收集管道,以支持社区开发。附录D中的图4展示了平台的架构设计。
指令收集和基准构建 我们收集了20509条跨环境和任务的指令和查询。对于那些已经有大量指令的任务,如WebShop和ALFWorld,我们主要依赖它们的原始来源。与此同时,对于那些指令较少的任务,如工具使用任务,我们使用自指导和指令演化方法进行扩展,具体是通过提示GPT-4生成新指令[33; 34]。详细信息在附录C中。然后,我们从每个环境中提取一个多样化和具有挑战性的子集Qeval,包含1160条指令,构建名为AGENTEVAL的基准套件,它可以全面评估基于LLM的智能体。剩余的指令集记为 ,其中Qe表示环境e剩余的指令。
,其中Qe表示环境e剩余的指令。
轨迹收集和过滤 在AGENTGYM中,服务器提供包括任务描述、环境设置和问题的指令给智能体。接下来,如第2节所述,智能体以ReAct风格与环境交互,直到任务完成。我们使用最先进的模型(例如,GPT-4-Turbo)和众包注释收集轨迹。详细信息在附录C中。我们严格过滤轨迹,以基于奖励或正确性确保数据质量,并得到一组6130条轨迹。这组名为AGENTTRAJ的轨迹用于第4.1节中训练基础通用智能体。为了公平比较,我们还使用相同的流程对所有指令进行注释和过滤,得到AGENTTRAJ-L,以展示通过BC实现的最大性能。表2显示了AGENTGYM框架的详细统计数据。
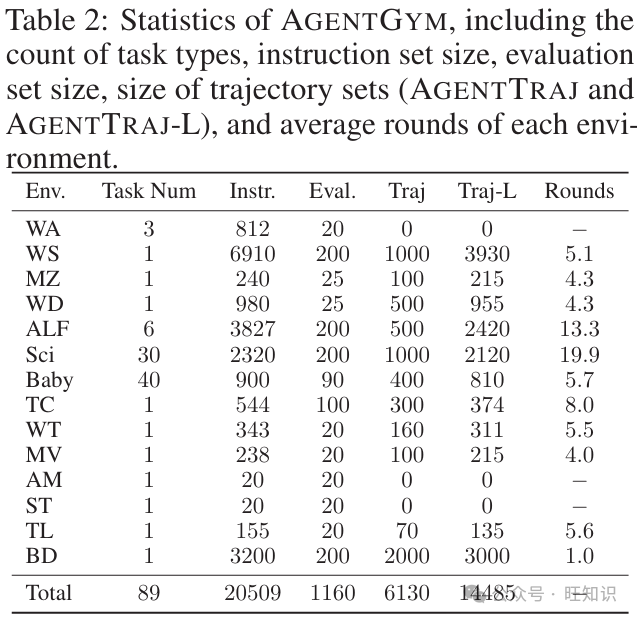
表2:AGENTGYM的统计数据,包括任务类型数量、指令集大小、评估集大小、轨迹集大小(AGENTTRAJ和AGENTTRAJ-L)以及每个环境的平均轮数。
4 AGENTEVOL:通用LLM基础智能体的演化
在本节中,我们首先通过行为克隆训练一个基础通用智能体,使其具备基本的交互能力。在这个智能体的基础上,我们开始探索LLM基础智能体在多个环境和任务中的全面演化。我们在算法1中总结了算法。
4.1 使用收集的轨迹进行行为克隆
行为克隆通过让智能体逐步模仿收集到的专家轨迹来微调基于LLM的智能体。在实践中,我们希望智能体能够完成适当的内部思考h和动作a。我们使用AGENTTRAJ(记为Ds)训练一个具有基本指令跟随能力和先验知识的基础通用智能体。我们最大化以下目标:
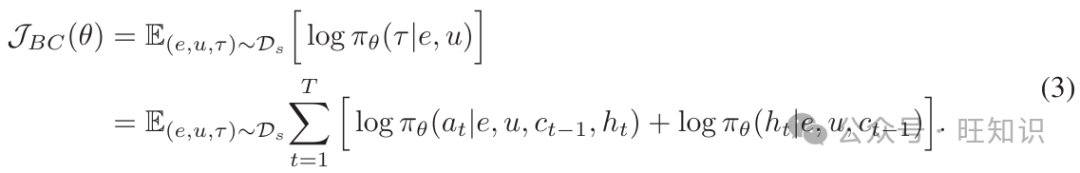
注意,我们包括了一个通用领域数据集Dgeneral,如Zeng等人[38]中所述,以保持智能体在语言理解和生成方面的能力。结果智能体πθbase作为后续在不同环境和任务中演化的起点。
4.2 通过探索和学习进行演化
这项工作试图探索通用LLM基础智能体在多个环境和任务中的自我演化潜力。更重要的是,在演化过程中,智能体将面临以前未见的任务和指令。因此,智能体需要探索环境,接收反馈,并根据反馈优化自己。为了实现我们的目标,强化学习(RL)[39]值得考虑,相应的目标是:
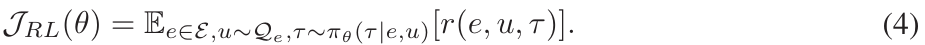
然而,在我们的设置中,标准RL面临重大挑战,因为智能体任务的采样空间大且长期性导致计算复杂度高和训练不稳定,这妨碍了可扩展性[40; 41; 42]。因此,我们从RL和概率推断之间建立的联系中获得灵感[43; 44; 45; 46],并提出了一种名为AGENTEVOL的方法,涉及智能体在探索和学习之间交替进行。
从估计的最优策略中学习。在这项工作中,我们将RL视为特定概率模型内的推断问题[43; 46; 47]。与传统的RL公式不同,后者侧重于识别最大化期望奖励的轨迹,基于推断的方法从轨迹的最优分布开始。我们最初定义P(O = 1)表示“通过最大化期望奖励获得最优策略”或“在RL任务中取得成功”的事件,这可以通过在每个采样点上集成最优策略概率来计算。给定策略智能体πθ,可以通过最大化以下公式获得最优策略:
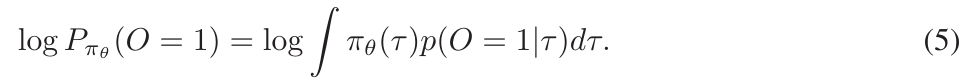

然而,上述优化过程由于LLM基础智能体需要逐个标记的反馈来进行梯度更新,直接进行是困难的。在本文中,我们通过引入一个估计函数 q 来构建等式5的变分下界。利用詹森不等式(Jensen’s inequality),我们很快得到:
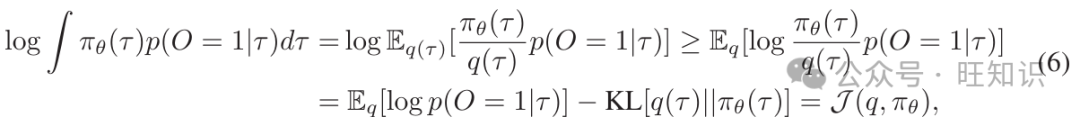
其中πθ 是由智能体引起的轨迹分布,q(τ) 是变分分布。
由于对数函数的单调性,通过最大化下界 ,我们可以比之前获得一个期望回报更高的策略。通常,我们的框架可以分为两个循环迭代步骤。 的前一步可以解释为通过最大化状态空间上的期望奖励来估计采样轨迹上的最优策略分布。后一步涉及将当前智能体的参数θ更新为最优策略q,从而完成单个迭代的优化。类比于SGD[48],估计过程由于未见决策轨迹的存在而引入了噪声到策略优化中。这种误差随着算法的进行逐渐减小,并在当前智能体变得最优时收敛到零[43]。
5 实验和讨论
5.1 实验设置
环境和任务。我们使用AGENTGYM框架探索通用LLM基础智能体的自我演化。主要实验涵盖了11个环境:WebShop [25]、ALFWorld [29]、SciWorld [26]、BabyAI [27]、TextCraft [30]、BIRD [32]、MAZE、Wordle [28]、ToolTODOList、Tool-Weather 和 Tool-Movie [31]。注意,在行为克隆(BC)中使用的指令少于演化阶段,以研究智能体在执行探索时的泛化能力。
基线。我们包括了闭源模型,如GPT-3.5-Turbo [50]、GPT-4-Turbo [12]、Claude 3 [13] 和 DeepSeek-Chat [51]。我们还包括了开源模型,如Llama-2-Chat [52],以及在专家轨迹上训练的智能体,即AgentLM [38]。为了公平比较,我们包括了一个基线,它在AGENTTRAJ-L上执行BC,作为本文BC可达到的最大性能。
实现细节。所有实验都是在八个A100-80GB GPU上进行的。我们的主要骨干模型是Llama-2-Chat-7B。不同的环境服务部署在同一个服务器的不同端口上。我们将迭代次数M设置为4。为了节省计算资源,每个指令在演化过程中只采样一次。注意,一些环境提供密集的奖励r ∈ [0, 1],而其他环境只提供二元反馈r ∈ {0, 1}。为了简单和一致性,我们遵循以前的工作[47]使用二元奖励。我们将r < 1的轨迹设置为r = 0,而r = 1的轨迹保持不变。更多细节见附录E。
5.2 主要结果
表3中的实验结果表明:(1) 尽管闭源模型表现良好,即使是像GPT-4-Turbo这样的最先进闭源模型也无法在所有任务上取得令人满意的性能,这突显了开发更有能力的智能体的必要性。(2) 以Llama2-Chat为代表的开源模型在所有任务上表现不佳,这突显了BC初始化步骤的重要性。(3) 在许多任务上,像AgentLM [38]这样在智能体轨迹上训练的模型可以与GPT-4-Turbo媲美,特别是70B版本。然而,它们在TextCraft [30]或SciWorld [26]等任务上的性能并不匹配,这可以归因于训练数据的缺乏。(4) 在AGENTTRAJ-L上训练的模型,即BClarge,在许多任务上表现出色,与最先进模型相匹配甚至超越,显示出它是一个强大的基线。(5) AGENTEVOL尽管用于模仿的轨迹有限,但在许多任务上如WebShop [25]、ALFWorld [29]和BabyAI [27]超越了BClarge和最先进模型,验证了智能体演化的优越性和前景。
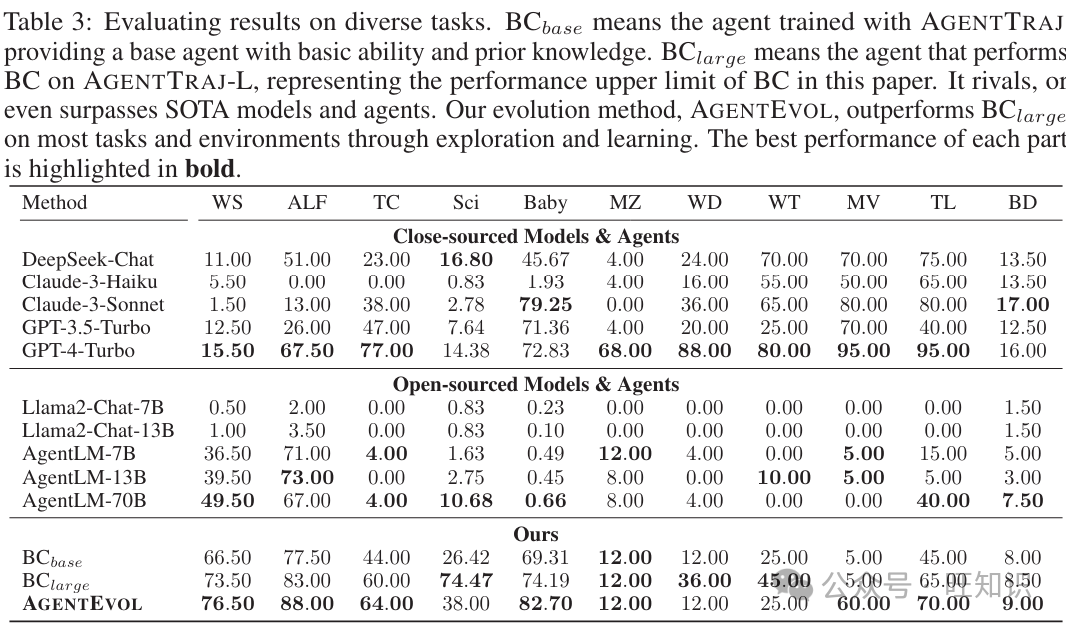
此外,我们报告了不同模型解决任务所需的交互轮数,以展示我们方法的效率(见附录F.1)。
5.3 讨论 & 分析
图3显示了数据合并策略和迭代次数M的消融研究。策略1意味着将当前智能体生成的轨迹与初始轨迹集合合并;策略2意味着将当前轨迹与上一次迭代生成的轨迹合并。
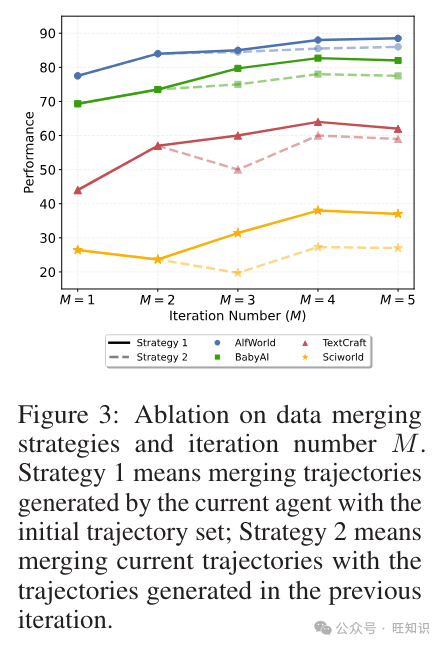
消融研究:数据合并策略和迭代次数M。在我们的实验中,我们将每次迭代中采样的轨迹与初始轨迹合并来训练智能体,而不是与上一次迭代生成的轨迹合并。在这里,我们进行了消融研究,以展示这种合并策略和迭代次数M的影响。实验结果如图3所示,与初始数据合并提供了更稳定的改进,而与上一次迭代的轨迹合并则导致性能波动,可能是由于过拟合[53; 47]。此外,随着M的增加,性能趋于提高,但在后期迭代中逐渐趋于稳定。因此,我们选择M = 4来平衡性能和效率。
消融研究:样本数量K。在探索步骤中,我们每次迭代对每个指令进行一次采样。这里,我们在四个任务上对样本数量K进行了消融研究。表4显示,随着K的增加,性能有所提高,但改进并不显著。因此,我们选择K = 1以获得计算效率。
消融研究:探索范围。在我们的实验中,我们首先使用Ds训练基础智能体,然后让它探索更广泛的指令和任务。我们对四个任务进行了消融研究,以了解智能体在BC阶段的有限指令下如何演化。表4显示,即使在有限范围内,基础智能体的性能也有所提高,这可能归因于从智能体采样的更多样化的轨迹。然而,改进并不显著,表明有效的演化需要更广泛的环境。
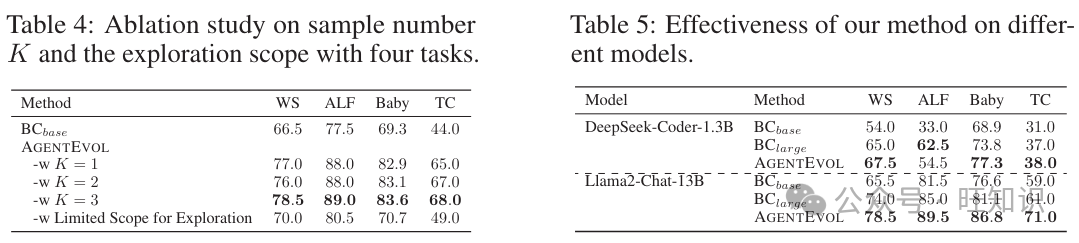
不同模型上的有效性。为了证明我们的方法在不同骨干模型上的泛化能力,我们在Llama-2-13B [52]和DeepSeek-Coder-1.3B [54]上进行了实验。整个演化过程仍然基于AGENTGYM。实验结果见表5,显示我们的AGENTEVOL在不同骨干模型上保持了其演化能力,实现了与BClarge相媲美或超越的性能。
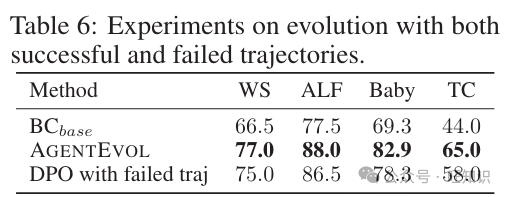
表6:使用成功和失败轨迹的演化实验。
使用成功和失败轨迹的演化。在学习步骤中,我们只使用高奖励(成功)的采样轨迹,不使用失败的轨迹。受之前工作[55; 56; 22; 19; 57]的启发,我们探索是否包括失败的轨迹可以更好地演化。具体来说,我们构建了成功和失败轨迹的配对,并使用DPO方法[58]优化智能体,该方法适合于成对数据集[57; 55; 59]。表6的结果显示,使用两种类型的轨迹仍然可以带来演化效果,但性能不如我们的方法,表明在多任务设置中偏好优化比单任务更具挑战性[55; 22]。将来,我们希望探索更多算法,充分利用所有轨迹进行全面演化。
6 相关工作
随着大型语言模型(LLMs)[12; 13; 14]的发展,基于它们的智能体开发已成为一个重要的研究方向[5; 15]。这些智能体通常被赋予推理和行动能力,并能执行许多类型的任务[35; 20; 60]。为了评估这些智能体,研究人员提出了包含各种任务的基准[25; 36; 31; 61]。我们的基准套件AGENTEVAL提供了更多样化的环境和任务,提供了更全面的评估。
闭源的大型语言模型,配备了如ReAct[35]和PlanAct[62]的提示方法,在智能体任务中可以取得很好的性能,而基于开源方法的智能体在这些任务上表现不佳[36; 37]。为了解决这一挑战,一系列工作从不同环境和任务中收集专家轨迹,并通过行为克隆训练基于LLM的智能体[38; 60; 17; 18]。然而,获取这些专家轨迹通常成本很高,并且它们缺乏对环境的充分探索[19; 20]。
另一系列工作基于环境反馈训练LLM基础智能体,称为交互学习方法[21; 37; 22; 63]。具体来说,它们涉及通过探索和学习来训练LLM或智能体。作为一个代表性方法,强化学习已经在LLM对齐[64; 65; 50; 41; 66]中取得成功,并已被引入到推理和智能体任务中,取得了优异的成果[42; 67; 21; 37]。然而,在我们的多环境场景中,奖励一致性和训练稳定性可能成为问题[21; 22; 68]。另一系列工作使用自我演化/自我改进,其中模型探索环境以获得高奖励轨迹,并根据这些轨迹微调自己,在推理、编码和网络任务中取得了有希望的性能[69; 47; 49; 70; 20; 19; 22; 10; 71; 59]。然而,像基于RL的方法一样,这些工作只在一个单一的环境或任务中探索。有了AGENTGYM,这项工作使用新的AGENTEVOL方法探索了在多个环境中进行智能体演化。
7 结论
在这项工作中,我们提出了一个新的框架,名为AGENTGYM,它包括一个具有多样化智能体环境和任务的交互平台,一个名为AGENTEVAL的基准,以及两个名为AGENTTRAJ和AGENTTRAJ-L的专家轨迹集合。此外,我们提出了一种新算法AGENTEVOL,并在探索多个环境中通用LLM基础智能体的自我演化方面迈出了第一步。实证结果证明了我们的框架和方法的有效性。我们还进行了充分的消融分析,以研究我们的方法的工作原理。我们希望我们的工作可以帮助AI社区开发更先进的通用LLM基础智能体。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
