由语言模型(LMs)驱动的自主智能体在执行诸如网络自动化的决策任务方面展现出了潜力。然而,一个关键的限制仍然存在:LMs主要针对自然语言理解和生成进行优化,在尝试解决现实计算机任务时,在多步推理、规划和使用环境反馈方面存在困难。为了解决这个问题,我们为LM智能体提出了一种推理时搜索算法,以在交互式网络环境中明确执行探索和多步规划。我们的方法是一种在实际环境空间内运行的最佳优先树搜索形式,并且与大多数现有的最先进智能体兼容。这是首个在现实网络任务上显示出有效性的语言模型智能体的树搜索算法。在具有挑战性的VisualWebArena基准测试中,将我们的搜索算法应用于GPT-4o智能体,与没有搜索的同一基线相比,成功率相对提高了39.7%,达到了26.4%的最新成功率。在WebArena上,搜索同样带来了28.0%的相对改进,达到了19.2%的竞争成功率。我们的实验突显了搜索对网络智能体的有效性,并展示了性能随着测试时间计算的增加而提高。我们对结果进行了深入分析,以突出搜索带来的改进、局限性和未来工作的有希望的方向。
1 引言
构建能够感知、规划和自主行动的智能体一直是人工智能研究的长期目标(Russell & Norvig, 1995; Franklin & Graesser, 1996)。近年来,具有强大通用能力的大型语言模型(LMs)的出现为构建能够自动化计算机任务的语言引导智能体铺平了道路。然而,即使是今天最好的LM智能体也远远不如人类。在现实网络基准测试WebArena(Zhou et al., 2024b)和VisualWebArena(Koh et al., 2024)上,人类分别在78%和89%的任务上取得成功,但智能体——即使是由最新前沿模型驱动的——表现要差得多,通常成功率低于20%。现有智能体的一个重大瓶颈是它们无法利用测试时间计算进行探索和多步规划。搜索和规划在开放式网络环境中尤为重要,因为潜在的动作空间(即在网页上可以采取的所有可能动作)比大多数视频游戏或基于文本的模拟器要大得多。通常需要对多个合理动作进行序列化以达到目标,能够高效地探索和修剪轨迹至关重要。
在人工智能系统中,利用测试计算来提高结果的有效策略之一是搜索:迭代地构建、探索和修剪中间状态和可能解决方案的图(Newell et al., 1959; Laird, 2019; Silver et al., 2016)。搜索算法的有效性已经一次又一次地得到证明,使模型能够在各种游戏上实现或超越人类的性能,包括围棋(Silver et al., 2016, 2017)、扑克(Brown & Sandholm, 2018, 2019)和外交(Gray et al., 2020)。
我们如何在自动化计算机任务的背景下应用搜索,其中搜索空间很大,并且——与游戏不同——没有明确的奖励和获胜条件?为了实现这一目标,我们提出了一种方法,使自主网络智能体能够在通过探索交互式网络环境而迭代构建的图上进行搜索。这种搜索过程在实际环境空间内,并通过环境反馈指导。我们的方法允许智能体在测试时枚举更多潜在的有希望的轨迹,通过明确的探索和多步规划降低不确定性。据我们所知,这是第一次在实际网络环境中显示推理时搜索提高了自主智能体的成功率。为了处理这些多样化环境中缺乏明确的奖励,我们提出了一个基于模型的价值函数来指导最佳优先搜索。该价值函数是通过在智能体的观察条件下,对多模态LM的条件推理链进行边缘化来计算的,从而产生细粒度分数,有效地指导搜索。
我们的实验表明,这种搜索过程与现有的LM智能体互补,并使这些模型能够在更难和更长远视野的任务上表现更好。在VisualWebArena(Koh等人,2024年)上,搜索将基线GPT-4o(OpenAI,2024年)的性能提高了39.7%,相对于没有搜索的基线,达到了26.4%的最新成功率。在WebArena(Zhou等人,2024b)上,搜索也非常有效,相对于基线智能体提高了28.0%(达到19.2%的竞争成功率)。我们还证明,搜索从规模中受益:允许智能体利用增加的测试时间计算来提高性能。
2 背景
2.1 现实的模拟网络环境
为了开发由大型语言模型驱动的自主网络智能体,以前的工作集中在构建评估基准上,以衡量模型在网络任务上的进展。Mind2Web(Deng等人,2023年)是一个评估基准,用于衡量前沿模型在预测静态互联网页面上采取的行动方面的能力。VisualWebBench(Liu等人,2024年)引入了一个多模态基准,用于评估模型理解网络内容的能力。
其他人则着眼于模拟器(与静态HTML内容相对):MiniWoB(Shi等人,2017;Liu等人,2018)是最早的交互式模拟器之一,用于网络任务,但包含的简化环境不直接转化为现实世界的性能。WebShop(Yao等人,2022a)模拟了一个简化的电子商务网站,具有真实世界数据。WebLINX(L`u等人,2024年)提出了一个基准,用于解决会话网络导航,涉及智能体和人类指导者之间的通信。MMIA(Zhang等人,2024b)和OSWorld(Xie等人,2024a)提出了基准,用于衡量智能体通过导航多个计算机应用程序和网页来完成任务的能力。WorkArena(Drouin等人,2024年)是ServiceNow平台上的任务的基准和模拟环境。WebArena(WA)(Zhou等人,2024b)是一个基准,涵盖了5个现实自我托管的流行网站的重新实现(购物,Reddit,CMS,GitLab,地图),每个网站都填充了真实世界的数据,共有812个任务。VisualWebArena(VWA)(Koh等人,2024年)是WebArena的多模态扩展,包括3个流行真实世界网站的910个新任务的现实重新实现(分类广告,Reddit,购物)。要解决VWA中的任务,智能体必须利用视觉基础和理解图像输入,为多模态智能体提供现实和具有挑战性的测试。

表1:(Visual)WebArena环境中可能的操作A。经Koh等人(2024年)许可转载。
由于(V)WA环境是网络任务中最现实和最全面的评估套件之一,我们主要在(V)WA上基准测试我们的方法。我们在这里简要描述设置,但请读者参考Zhou等人(2024b)以获取更多上下文。环境E = (S, A, Ω, T)由一组状态S、动作A(表1)、以及一个确定性转移函数T : S × A → S组成,该函数根据动作定义了状态之间的转移。基准中的每个任务都包含一个用自然语言指令I指定的目标(例如,“找到2000美元以下最便宜的红色丰田汽车。”)。每个任务都有一个预定义的奖励函数R : S × A → {0, 1},用于衡量智能体的执行是否成功。我们在(V)WA网络模拟器上实现我们的搜索算法,但我们的方法是完全通用的,可以应用于任何智能体可以自由探索的交互式环境设置。
2.2 语言引导的自主智能体
由前沿(多模态)语言模型(Google,2023年;OpenAI,2024年;Anthropic,2024年)驱动的自主网络智能体,是许多上述基准的SOTA方法。Kim等人(2024年)表明,大型语言模型可以在MiniWoB++(Liu等人,2018年)上执行计算机任务,所需的演示比强化学习方法少得多。AutoWebGLM(Lai等人,2024年)收集了网络浏览数据进行课程训练,并基于6B参数语言模型开发了一个网络导航智能体,其性能超过了WebArena上的GPT-4。Patel等人(2024年)表明,语言模型智能体可以通过对其自身合成生成的数据进行微调来提高性能。Pan等人(2024年)表明,引入一个自动评估器以提供有关任务失败或成功的指导可以提高基线Reflexion(Shinn等人,2024年)智能体的性能。Fu等人(2024年)从离线数据中提取领域知识,并在推理期间将其提供给语言智能体,使其能够利用有帮助的领域知识。Sodhi等人(2024年)提出了一种方法,使智能体能够动态组合策略以解决各种网络任务。我们的程序是一种推理时方法,与开发更好的基线智能体的许多过去方法兼容。
在多模态设置中,WebGUM(Furuta等人,2024年)对一个3B参数的多模态语言模型进行了微调,使用了大量演示语料库,在MiniWoB和WebShop上取得了强大的性能。Koh等人(2024年)表明,使用SetofMarks(Yang等人,2023a)表示提示多模态语言模型可以使模型更有效地导航复杂的网页,而不是仅使用文本的智能体。SeeAct(Zheng等人,2024年)证明了像GPT-4V(Yang等人,2023b)和Gemini(Google,2023年)这样的前沿多模态模型可以被基础化并提示以遵循自然语言指令,以自动化网络任务。
2.3 搜索和规划
我们的方法还借鉴了计算机科学中搜索和规划算法的丰富历史。搜索算法,如广度优先搜索、深度优先搜索和A*搜索(Hart等人,1968年)早已在人工智能系统中使用。Newell等人(1959年)和Laird(2019年)将目标导向行为视为通过可能状态空间的搜索。Dean等人(1993年)和Tash & Russell(1994年)提出了有限搜索范围的规划算法,并采用了基于信息价值的启发式扩展策略来改进计划。Tash & Russell(1994年)表明,这允许智能体适当地响应时间压力和世界中的随机性。深蓝(Campbell等人,2002年),这个在1997年击败了世界象棋冠军卡斯帕罗夫的国际象棋引擎,就是基于大规模并行树搜索。Pluribus(Brown & Sandholm,2019年)利用搜索找到了更好的多人扑克策略,以应对动态情况。最近,几篇论文(Yao等人,2024年;Besta等人,2024年)展示了将搜索应用于大型语言模型的潜力,通过引入在多个推理路径上的探索,增强了需要非平凡规划的基于文本任务的性能。其他人已经将MCTS应用于提高LMs在数学基准(Cobbe等人,2021年)或简化环境(Yao等人,2022a;Valmeekam等人,2023年)上的性能。
与以往的工作不同,我们的环境是根植于现实的网络环境,我们在实际的环境空间(即网络)上进行搜索。这意味着搜索机制需要不仅包括智能体的文本输出,还要包括来自高度复杂(和现实)环境的外部环境反馈。我们的实验表明,我们基于环境的树搜索大大提高了语言模型智能体的性能。
3 方法
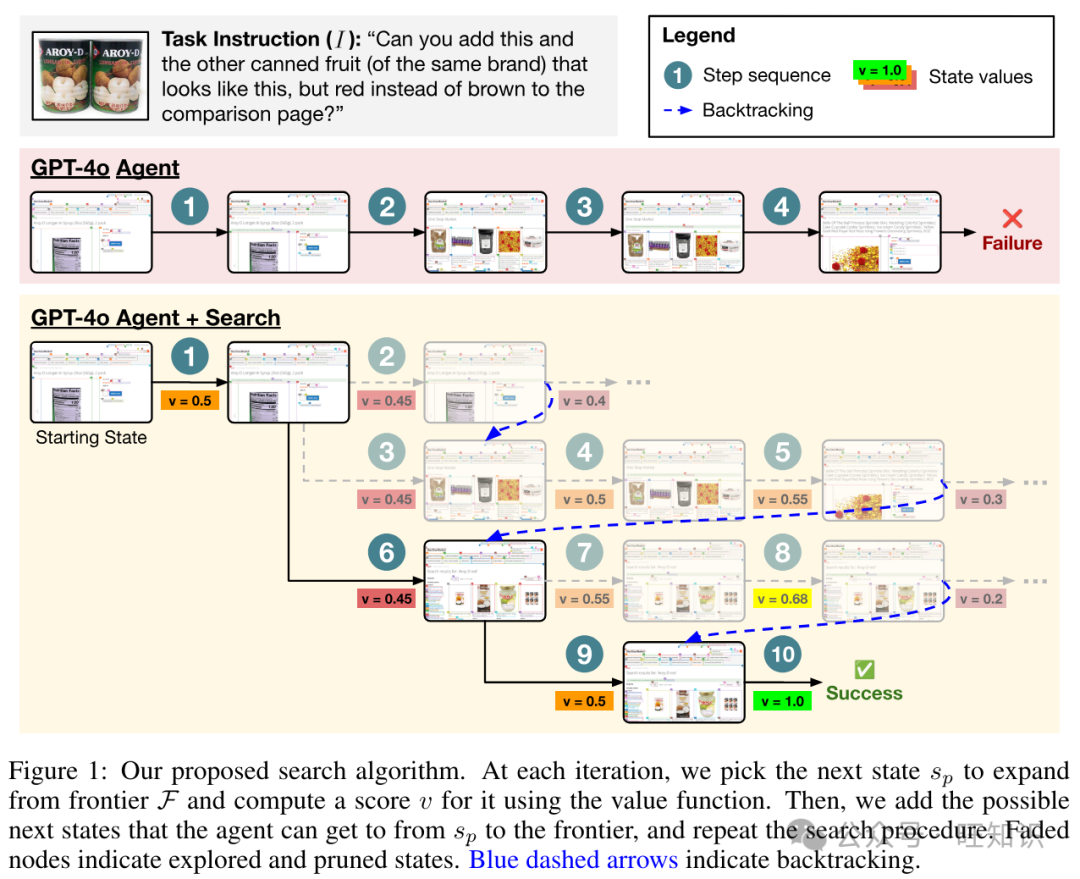
在这一部分,我们详细描述了搜索过程(图1)。成功解决(V)WA等网络环境中的任务可以解释为导航到某个目标状态s*,该状态提供正奖励R(s*) = 1。智能体从状态s0开始(例如,主页)。给定自然语言任务指令I,智能体的目标是通过执行一系列动作(a0, ..., at) ∈ A导航到目标状态。每个动作产生一个新的状态st+1 ∈ S和来自环境的观察ot+1 ∈ Ω。状态st到st+1的转移由确定性转移函数T : S × A → S控制。
大多数方法将其视为部分可观测马尔可夫决策过程,并仅在预测要采取的下一个动作at时考虑当前观察ot。这有显著的局限性:智能体的错误随着每个步骤的进行而累积,如果在时间t采取了错误的行动,如果这导致将来处于一个糟糕的状态,那么这不容易纠正。我们的方法旨在通过明确进行搜索和回溯来识别更好的轨迹来缓解这个问题。下面几节中描述了涉及的几个组成部分:基线智能体模型(第3.1节)、价值函数(第3.2节)和搜索算法(第3.3节)。
3.1 智能体骨干
大多数SOTA网络智能体是通过提示大型(多模态)语言模型(Zhou等人,2024b;Pan等人,2024年;Fu等人,2024年;Zheng等人,2024年;Koh等人,2024年)构建的。预训练的语言模型或多模态模型fϕ会根据当前网页观察ot提示,并指示执行要执行的下一个动作at。通常利用提示技术,如ReAct(Yao等人,2022b)、RCI(Kim等人,2024年)或Chain-of-Thought(CoT)提示(Wei等人,2022年),来提高智能体的性能。语言模型智能体还允许我们采样一组多样化的动作(例如,使用nucleus sampling(Holtzman等人,2020)),这在搜索期间创建合理的分支进行探索(见第3.3节)是必不可少的。我们提出的搜索算法原则上可以应用于任何基线语言智能体模型。我们在第4节中展示了搜索如何在不重新训练或微调fϕ的情况下提高一系列模型的推理时性能。
3.2 价值函数
我们实现了一个最佳优先搜索启发式方法,使用一个价值函数fv来估计当前状态st的预期奖励E[R(st)],其中真实的目标状态将提供完美的奖励1。由于模拟器的状态st并不总是对智能体可见(st可能包括站点的数据库条目等私有信息),价值函数使用智能体的当前和先前观察以及自然语言任务指令I来计算值vt:
vt = fv(I, {o1, ..., ot}) ∈ [0, 1]
在我们的实验中,价值函数是通过提示多模态语言模型使用自然语言指令和观察作为屏幕截图(第4.1节)来实现的。
3.3 搜索算法
我们提出的搜索算法是一种最佳优先搜索方法,受到A搜索(Hart等人,1968年)的启发,A搜索是计算机科学中广泛使用的经典图遍历算法。我们使用语言模型智能体来提出搜索树的候选分支。搜索具有超参数深度d、分支因子b和搜索预算c,这些参数决定了搜索树的最大大小,以及终止阈值θ。我们在以下段落中详细描述过程,并在附录A.3中提供正式算法。
在执行轨迹的时间t,智能体已经执行了一系列动作到达当前状态st。我们从st开始搜索算法,通过初始化前沿F ← {}(实现为最大优先级队列),它保存我们计划评估的状态集,到目前为止找到的最佳状态ˆst ← st,最佳序列的分数ˆvt ← 0,以及搜索计数器s ← 0。
在搜索过程的每次迭代中,我们从前沿提取下一个项目,sp ← pop(F)。我们使用价值函数计算状态sp的分数(具有观察op和先前观察o1, ..., op−1):
vp = fv(I, {o1, ..., op})
然后,我们增加搜索计数器s,如果vp高于当前最佳分数ˆvt,我们相应地更新它和我们的最佳状态:
s ← s + 1
ˆst ← sp如果vp > ˆvt 否则 ˆst
ˆvt ← max(ˆvt, vp)
如果vp ≥ θ(智能体可能已经找到了目标状态)或s ≥ c(搜索预算已用完),我们将终止搜索并导航到迄今为止找到的最佳状态ˆst。
否则,如果当前分支不超过最大深度(即,|(s0, ..., sp)| < d),我们将通过从语言模型智能体fϕ获取b个候选动作{a1p, ..., abp}来生成分支。对于每个i,我们执行aip并添加结果状态sip到前沿,其分数为当前状态的分数:
F ← F ∪ (vp, sip)对于i = 1, ..., b
这结束了搜索的一次迭代。如果两个终止条件都未达到,我们将回溯并为更新的前沿F中的下一个最佳状态重复此过程。
这结束了搜索的一次迭代。如果两个终止条件都未达到,我们将回溯并为更新的前沿F中的下一个最佳状态重复此过程。
1 在执行轨迹的t时刻,智能体通过执行一系列动作到达了当前状态st。我们从st开始搜索算法,通过初始化前沿F ← {}(实现为最大优先级队列),它保存我们计划评估的状态集合,目前找到的最佳状态 ˆst ← st,最佳序列的分数 ˆvt ← 0,以及搜索计数器 s ← 0。
在搜索过程的每次迭代中,我们从前沿提取下一个项目 sp ← pop(F)。我们使用价值函数计算状态 sp(具有观察 op 和之前的观察 o1, ..., op−1)的分数:
vp = fv(I, {o1, ..., op})
然后,我们增加搜索计数器 s,并如果 vp 高于当前最佳分数 ˆvt,我们更新它和我们的最佳状态:
s ← s + 1
ˆst ← sp 如果 vp > ˆvt 否则 ˆst
ˆvt ← max(ˆvt, vp)
如果 vp ≥ θ(智能体可能已经找到了目标状态)或 s ≥ c(搜索预算已用完),我们将终止搜索并导航到迄今为止找到的最佳状态 ˆst。
否则,如果当前分支不超过最大深度(即,|(s0, ..., sp)| < d),我们将通过从语言模型智能体 fϕ 获取 b 个候选动作 {a1p, ..., abp} 来生成分支。对于每个 i,我们执行 aip 并添加结果状态 sip 到前沿,其分数为当前状态:
F ← F ∪ (vp, sip) 对于 i = 1, ..., b
这结束了搜索的一次迭代。如果两个终止条件都未达到,我们回溯并重复此过程,针对更新的前沿 F 中的下一个最佳状态。
1 在第 t 步,我们根据深度 d、分支因子 b 和搜索预算 c 初始化前沿 F 为空的最大优先队列,最佳状态 ˆst 为 st,最佳分数 ˆvt 为负无穷大,搜索计数器 s 为 0。只要 s < c,我们就从 F 中弹出 sp,并回溯并执行新动作到达状态 sp。我们计算当前和之前观察的分数 vp = fv(I, {o1, ..., op})。每次迭代计数器 s 增加 1,如果 vp 至少与 ˆvt 相等,则更新最佳分数和状态。如果 vp 达到阈值 θ 或搜索预算 c 已用完,则搜索终止。否则,如果搜索深度未超过限制,我们从语言模型采样 b 个候选下一步动作,并为每个动作执行并添加新状态到前沿 F。重复此过程直到满足终止条件。
4 实验
我们在全套910个 VisualWebArena (VWA) 和 812个 WebArena (WA) 任务上运行实验。这些任务分布在一系列多样和现实的网络环境上:VWA 的分类广告、Reddit 和购物环境,WA 的购物、CMS、Reddit、GitLab 和地图环境。
4.1 实现细节
基线智能体模型 我们的搜索算法与大多数现成的语言模型智能体兼容。在这项工作中,我们测试了更简单、更通用的基于提示的智能体,并将在未来的工作中将我们的方法与包含特定领域技术的更高性能方法结合起来。我们运行了几个智能体基线(完整的提示见附录):
GPT-4o + SoM: 我们运行了基于多模态 GPT-4o (OpenAI, 2024) (gpt-4o-2024-05-13) 的智能体,使用与 Koh 等人 (2024) 相同的提示。我们同样应用了一个预处理步骤,为网页分配了 Set-of-Marks (SoM) 表示。这突出显示了网页上每个可交互元素的边框和唯一 ID。智能体的输入是带有 SoM 注解的网页屏幕截图,以及页面上元素的文本描述及其相应的 SoM ID。
Llama-3-70B-Instruct: 我们运行了带有字幕增强的 Llama-3-70B-Instruct 智能体,使用与 Koh 等人 (2024) 相同的提示。我们使用现成的字幕模型(在我们的情况下是 BLIP-2;Li 等人,2023)为网页上的每个图像生成字幕。网页观察的可访问性树表示被提取并作为智能体的输入观察在每个步骤中提供。
GPT-4o: 在 WebArena(不需要视觉基础)上,我们运行了一个仅文本的 GPT-4o 智能体,使用与 Zhou 等人 (2024b) 相同的提示。与 Llama-3 基线类似,此模型使用当前网页的可访问性树作为其输入观察(但此基线不包括图像字幕)。
搜索参数 我们在有无搜索的情况下运行这些智能体。我们的搜索参数设置为 d = 5, b = 5, c = 20,并且在最多执行 5 个动作后停止执行。由于计算和预算限制,我们执行这些限制,尽管我们期望增加这些参数可能会进一步提高结果(见第 5.1 节,关于扩展搜索参数的结果)。
获取动作 在每个执行步骤,我们使用 CoT 推理(Wei 等人,2022)提示智能体,并生成 20 个输出,并聚合动作候选的计数。我们使用最高计数的前 b 个动作进行分支。
价值函数 如第 3.2 节所述,我们需要一个价值函数来评估当前状态 st 是目标状态的可能性。我们通过提示多模态语言模型(具体来说,GPT-4o (OpenAI, 2024) (gpt-4o-2024-05-13))使用任务指令 I、智能体轨迹的屏幕截图、智能体采取的先前动作和当前页面 URL 来实现价值函数。完整的提示在附录 A.2.2 中提供。多模态 LM 被指示输出当前状态是成功、失败,如果是失败,是否在通往成功的轨迹上。这些输出分别被赋予 1、0 和 0.5 的值(无效输出为 0)。为了获得更细粒度和可靠的分数,我们利用了自我一致性提示(Wang 等人,2023)的思想,并通过 CoT (Wei 等人,2022) 提示多模态 LM 来采样多个推理路径。我们使用祖先采样(温度为 1.0 和 top-p 为 1.0)从 GPT-4o 模型中采样 20 条不同的路径。在最佳优先搜索启发式中使用的状态 st 的最终值是通过平均每个 20 条推理路径的值来计算的。在我们的实现中,从价值函数中采样的成本明显低于预测下一个动作的成本,因为动作预测需要更多的输入标记用于少数示例和页面的文本表示。我们估计 GPT-4o 智能体预测下一个动作的总 API 成本大约是计算状态值的 2 倍。
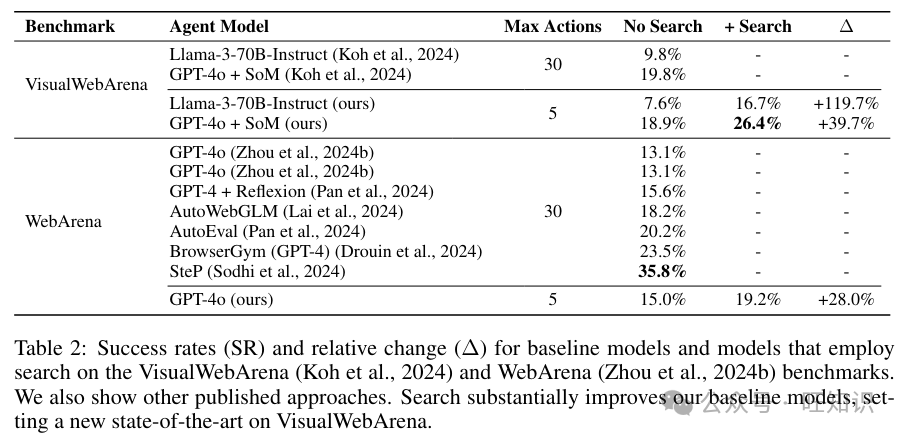
4.2 结果
我们的结果总结在表 2 中。引入搜索显著提高了整体的成功率。搜索将 VWA 上的基线 GPT-4o + SoM 智能体的成功率提高了 39.7%(从 18.6% 增加到 26.4%),在基准测试上设定了新的 SOTA。在 WA 上,向 GPT-4o 智能体引入搜索也显著提高了成功率,相对提高了 28.0%(从 15.0% 增加到 19.2%)。这与 WA 上其他基于提示的智能体竞争,但在未来的研究中,将搜索引入更强大的基线智能体,如 SteP (Sodhi 等人,2024) 或 AutoGuide (Fu 等人,2024),将是一个有趣的探索。
使用 VWA 上的 Llama-3 字幕增强智能体,我们看到搜索带来了更显著的改进,将成功率提高了一倍多。使用搜索,成功率相对于基线提高了 119.7%(从 7.6% 到 16.7%)。我们认为这是由于用于价值函数的 GPT-4o 模型通常比 Llama-3 更强大(多模态)。使用搜索,Llama-3-70BInstruct 达到了接近最好的前沿多模态模型的成功率。由于 Llama-3 公开提供了模型权重,因此在需要访问模型内部结构的未来工作中,Llama-3-70B-Instruct 智能体与搜索的强大性能可能证明是一个具有成本效益的智能体模型。
5 分析
5.1 消融实验
我们对 VWA 的 200 个任务(100 个购物任务,50 个 Reddit 任务和 50 个分类广告任务)进行了几项消融实验。
搜索预算 我们在图 2 中绘制了将搜索限制为不同预算 c ∈ {0, 5, 10, 15, 20} 的 GPT-4o 智能体的成功率。所有实验都使用搜索参数 d = 5 和分支因子 b = 5。搜索预算指定了每个步骤执行的最大节点扩展次数。例如,搜索预算为10 表示最多扩展 10 个节点,之后智能体将提交并执行具有最高价值的轨迹。我们观察到,随着搜索预算的增加,成功率通常会增加。值得注意的是,即使进行非常小量的搜索(c = 5),相对于不进行搜索(24.5% 到 32.0%),成功率也提高了 30.6%。当预算增加到 c = 20 时,相对于不进行搜索提高了 51.0%(从 24.5% 到 37.0%),这凸显了扩展搜索预算的好处。进行实验以评估更大的搜索预算以探索扩展趋势将是未来研究的一个有希望的方向。
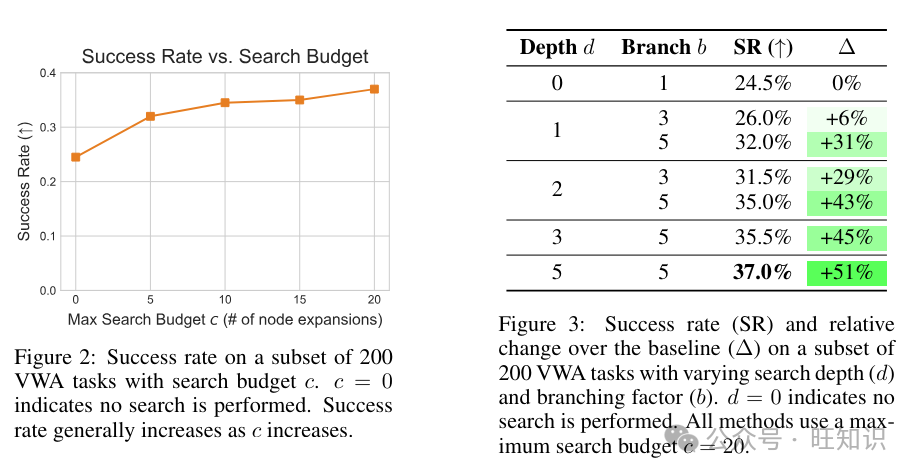
搜索深度和广度 我们运行了一个消融实验,变化了搜索分支因子 b 和最大深度 d。结果总结在表 3 中。我们观察到,通常,随着搜索树的大小增加(沿着 b 和 d 两个维度),成功率会增加。特别是,扩展 b 和 d 都是实现强性能所必需的。
轨迹级重新排序 树搜索的一个替代方案是生成多个轨迹,重新排序,并提交最佳轨迹,由价值函数评分,类似于 Chen 等人 (2024b) 和 Pan 等人 (2024) 提出的方法,没有他们的 Reflexion (Shinn 等人,2024) 组件。这是一种不太实用的方法,因为更难防止破坏性动作被执行(见第 5.4 节的更多讨论),因为智能体需要采取轨迹才能完成才能评估。这也是一种更有限形式的搜索,因为它只考虑整个轨迹,不能回溯修剪坏分支。尽管如此,我们进行了消融,从 GPT-4o 智能体中采样 3 个轨迹(在每个步骤使用核心采样 (Holtzman 等人,2020),温度为 1.0 和 top-p 为 0.95),并使用相同的价值函数重新排序轨迹,选择最佳的 3 个。我们选择 3 是因为这是 Pan 等人 (2024) 使用的轨迹数量(他们的方法在 3 个轨迹时性能达到峰值)。这个重新排序基线达到了 28.5% 的成功率,这比我们的方法用搜索预算 c ≥ 5(见图 2)要差。它也大大低于我们的方法用 c = 20,后者在消融子集上实现了 37.0% 的成功率,相对于重新排序增加了 29.8%。
5.2 成功率分解
难度 无搜索 搜索 ∆
简单 34.2% 42.3% +24%
中等 12.7% 22.2% +75%
困难 10.2% 14.9% +47%
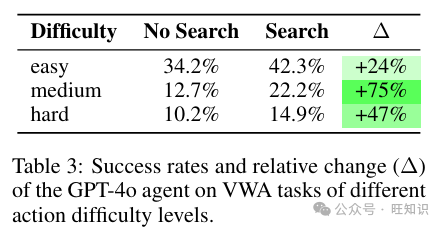
表 3:GPT-4o 智能体在 VWA 任务上不同动作难度级别的成功率和相对变化(∆)。
按任务难度的成功率 VWA 基准包括每个任务的动作难度标签。这些标签是人类注释的,大致表示人类需要采取多少行动来解决任务:简单任务需要 3 个或更少的动作,中等任务需要 4-9 个动作,困难任务需要 10 个或更多的动作。这些指南是近似的,由 VWA 的人类注释者设计,因此实际上可能存在更优的解决方案。引入搜索的成功率增加总结在表 3 中。引入搜索提高了所有难度级别的性能,但在中等动作难度的任务上,成功率的相对增加更大,相对增加了 75%(从 12.7% 到 22.2%)。我们假设这是因为我们的搜索参数(最大深度 d = 5)对大多数中等难度的任务都是有益的。相反,要在困难的任务上实现更好的性能,可能需要搜索更深的树。简单任务可能不会从搜索中受益太多,因为它们通常涉及较少的多步规划(有些可以通过 1 或 2 个动作解决),而且基线已经有更高的成功率。
按网站成功率 表 4 和表 5 总结了 VWA 和 WA 基准上各个网站的成功率。我们观察到整体成功率的提高,证明了我们的方法跨网站的泛化能力。具体来说,在 VWA 的分类广告和购物网站上,相对提高了 44% 和 45%,增幅最大。类似地,WA 基准中的 CMS 网站显示出 50% 的显著相对改进。
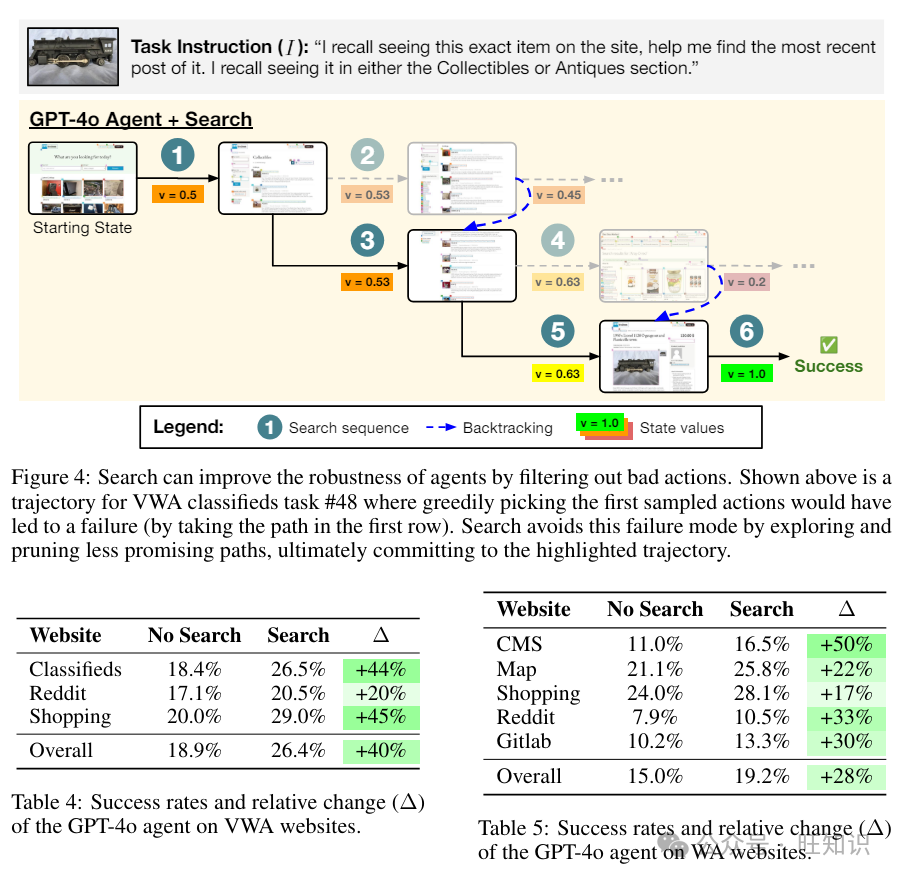
5.3 定性结果
在这一部分,我们展示了几个智能体轨迹的定性示例,并确定了通过引入搜索可以解决的各种失败模式。
更强的多步规划 VWA 和 WA 中的许多任务要求智能体保持对多个先前动作和观察的记忆。没有搜索的智能体的一个常见失败模式是它们倾向于撤销先前的动作,或者陷入循环(见 Koh 等人,2024 年的附录 C.4)。图 1 展示了 VWA 购物任务 #256 的一个示例,智能体的任务是将两种不同类型、同一品牌的罐装水果添加到比较列表中。基线智能体成功添加了第一个项目,但未能导航到第二个项目,因为它在第 3 步返回到主页并变得困惑。这是一个复合错误导致整体任务失败的例子,这在现有的基线智能体中相当普遍。
当引入搜索时,智能体现在能够探索其他合理的轨迹,并在最终导致失败时回溯。使用搜索的相同 GPT-4o 智能体现在能够为这个任务找到一个成功的多步轨迹,包括添加第一个项目(图 1 中的动作 #1),输入搜索查询(动作 #6),并导航并添加正确的第二个项目到比较列表中(动作 #8)。
解决不确定性 从语言模型中采样动作的一个固有问题是我们是从文本的分布中进行采样,我们生成的第一个样本可能不是在环境中采取的最佳动作。搜索允许我们通过在模拟器中执行每个生成的动作,并使用收到的环境反馈来做出更好的决策。一个例子是 VWA 分类广告任务 #48(图 4),它要求找到一个包含特定图像的帖子。如果智能体在每一步都执行第一个采样的动作,它将导致失败。搜索允许智能体在执行动作并接收环境反馈后枚举所有可能性,这使它能够选择最佳(在这种情况下,成功的)轨迹。
5.4 局限性
虽然我们已经展示了在网络任务中引入搜索到 LM 智能体可以获得有希望的结果,但它确实有一些实际的局限性。在这一部分中,我们讨论了一些常见的失败模式以及可能的解决方法。
搜索可能会很慢 引入搜索允许我们在推理时使用更多的计算来从预训练的 LM 智能体中提取更强的结果。然而,这导致轨迹需要更长的时间来执行,因为智能体必须进行更多的探索,因此需要更多的 LM 调用。例如,搜索预算 c = 20 意味着具有搜索的智能体在每次搜索迭代中可能潜在地扩展多达 20 个状态,这将比没有搜索的智能体多用 20 倍的 LM 调用。Leviathan 等人(2023年)、Dao 等人(2022年)、Dao(2023年)关于提高机器学习系统效率和吞吐量的研究可能有助于优化这一点,但对于实际部署,可能需要仔细设置搜索参数 b、d 和 c,以在实现更好结果和完成任务所需的总时间之间取得平衡。
在我们的方法中,我们通过跟踪到达状态所需的动作序列来实现搜索。在回溯时,我们重置环境并重新应用相同的序列。这是必要的,因为简单地执行返回操作(表 1)可能会丢弃页面上的重要信息,如滚动偏移和已经输入的文本。然而,这些环境调用对于回溯引入了额外的开销,如果环境调用成本高昂,这可能会限制部署。
破坏性动作 对于现实世界的部署,我们需要将搜索空间限制在非破坏性的动作上。破坏性动作被定义为会不可逆转地改变网站状态并难以回溯的动作。例如,在电子商务网站上下订单通常很难自动撤销。
解决这个问题的一种方法是引入一个分类器,预测某些动作是否具有破坏性,并防止这些状态的节点扩展。如果我们拥有关于下游应用的特定领域知识(例如,我们知道某些页面应该禁止访问),这些规则可以手动执行,并且具有很高的准确性。我们的方法比轨迹级重新排序(第 5.1 节)的一个优势是,更容易地将此类约束整合进来:它可以直接集成到价值函数中,以防止执行危险动作。处理这个的另一种方向是训练一个世界模型(Ha & Schmidhuber,2018),我们可以使用它进行模拟,并在此之上搜索,而不是探索真实世界。搜索也可能更容易在离线设置中实现,在这些设置中,动作是非破坏性的,因为它们总是可以撤销或重置,例如编程(Jimenez 等人,2023;Yang 等人,2024)或 Microsoft Excel(Li 等人,2024)。
6 结论
在本文中,我们介绍了一种推理时搜索算法,旨在增强语言模型智能体在现实网络任务上的能力。我们的方法将最佳优先树搜索与 LM 智能体集成,使它们能够探索和评估多个动作轨迹,以在网络任务上实现卓越的性能。这是第一次搜索在现实网络环境中显著提高了 LM 智能体的成功率,如在 (Visual)WebArena 基准测试中所示。我们的搜索程序是通用的,将其应用于其他领域将对未来的工作具有重要价值。我们相信,推理时搜索将是构建能够规划、推理和自主行动以执行计算机任务的有能力的智能体的关键组成部分。


























 粤ICP备17114055号
粤ICP备17114055号
