选址作为商业决策和城市基础设施规划的核心环节,对实体店铺、城市基础设施能否发挥预期效用具有重要作用. 现有的选址推荐系统数据服务编排较为固定,无法对不同用户需求系统做出及时调整,应用场景受限,人机交互的系统灵活性和可扩展性差. 最近,以GPT-4为代表的大语言模型(large language model,LLM)展现出了强大的意图理解、任务编排、代码生成和工具使用能力,能够完成传统推荐模型难以兼顾的任务,为重塑推荐流程、实现一体化的推荐服务提供了新的机遇. 然而,一方面选址推荐兼具传统推荐共有的挑战;另一方面,由于其基于空间数据,具有独特的挑战.
在这一背景下,本文提出了大语言模型驱动的选址推荐系统. 首先,拓展了选址推荐的场景,提出了根据位置寻找合适店铺类型的场景推荐任务,结合了协同过滤算法和空间预训练模型. 其次,构建了由大语言模型驱动的选址决策引擎. 语言模型本身在处理空间相关的任务上存在诸多缺陷,例如缺少空间感知能力、无法理解具体位置、会虚构地名地址等. 本文提出了一种在语言模型框架处理空间任务的机制,通过地理编码、逆编码、地名地址解析等工具提升模型的空间感知能力并避免地址虚构问题,结合选址推荐模型、场景推荐模型、外部知识库、地图可视化完成选址推荐中的多样化任务. 实现选址任务的智能规划、执行与归因,提升了空间服务系统的交互体验,为未来人工智能驱动的选址推荐系统提供新的设计和实现思路.
1.从数据驱动的多角度出发,在数据增强、选址结果可解释、任务扩展等方面对当前选址推荐系统进行了完善,使其更能胜任日益复杂的实际选址推荐场景.
2.提出了一种由LLM驱动的选址推荐引擎. 综合利用多种地理编码工具和选址模型实现选址任务的智能规划、执行和归因,提升了LLM在地理空间任务上的表现.
3.在广泛的真实数据上验证我们提出的选址推荐和场景推荐方法,并展示了LLM驱动的选址推荐的相关案例.
亮点图文
1. 相关工作
目前大多的选址推荐任务都是面向连锁企业寻找合适的点位,但是却忽略了从点位出发寻找合适品类的需求. 在实际业务中,主要包括商场的招商引资和广告招租等场景. 在早期,文献[3]基于社交媒体的签到数据分别提取位置特征和商业特征用于店铺类型推荐. 但是由于签到数据的信息密度较低,实际应用范围较窄.
在以LLM驱动的自主代理系统中,LLM作为代理的大脑,辅以多个关键组件. 研究人员提出智能代理等于大语言模型、 记忆、规划技能和工具使用的加和. 文献[5]提出了任务矩阵的概念,将基础模型和现有的应用程序结构通过LLM组合起来完成数字和物理领域的任务. 文献[27]提出了ChemCrow,它整合了17种由专家设计的工具,增强了LLM在化学领域的能力. 文献[28]提出了Autonomous GIS 的概念并开发了LLM-Geo原型系统,其以GPT-4为核心,在没有人工干预的情况下生成Python代码执行地理空间数据分析和可视化的任务. 与本文方法相比,LLM-Geo侧重通过代码生成解决地理数据处理的问题,并没有很好地解决LLM在地理空间文本上的幻觉问题. 依赖代码生成也使得LLM-Geo在应用范围上存在局限性. 而本文则是聚焦综合调用多种工具,提升LLM在空间任务上的感知能力,构建选址决策引擎来实现面向用户的智能选址推荐系统.
2. 本文系统架构
本文系统的框架如图1所示,共包括4个部分:数据层、模型层、应用层和交互层. 其中白色部分为传统选址推荐系统架构,灰色部分本文提出的增强部分.
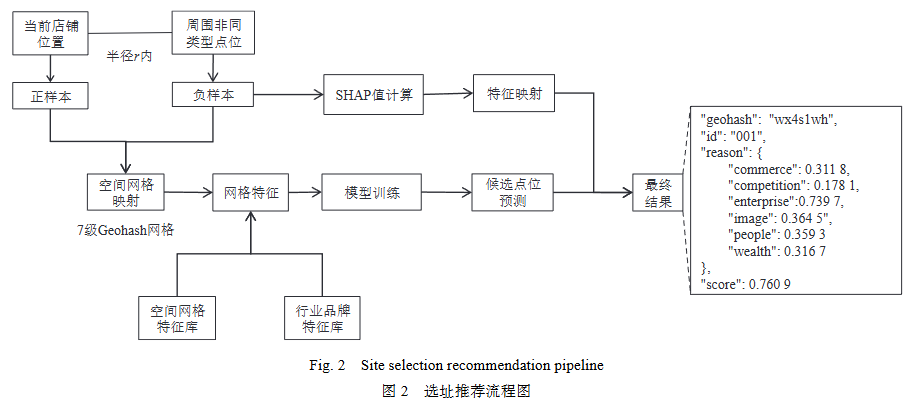
本文提出了一种以历史店铺位置作为正样本来指导选址的方法,方法流程如图2所示. 对于具体的品牌或行业,当前店铺位置所在的网格作为正样本,对于每个正样本,在半径为r的区域内,随机选择一定数量的非当前行业的 POI 所在的网格作为负样本,其中r是一个可以调节的超参数. 将收集到的正负样本点位对应到所处的7级Geohash网格,根据网格编码和行业从空间网格特征库和行业品牌特征库中抽取对应的特征构成训练集. 我们选择梯度提升决策树(gradient boosting decision tree,GBDT)模型作为分类器,模型选型的依据是相比深度学习模型,GBDT模型在拥有强大性能的同时,具有更好的可解释性,且离线推理的速度更快,更适合线上服务使用.
当前的选址推荐系统大多没有覆盖从位置出发寻找适合当前点位的任务. 本文提出了一种基于地理位置-品牌的协同过滤方法来进行场景推荐. 如图3所示的流程,首先输入地理位置,并从品牌地理位置库中检索近邻位置作为候选地点;然后分别提取输入地点和候选地点对应的人口、环境和地理特征,并利用基于场景的模型计算输入地点和候选地点之间的相似度. 将地理空间和其上的商店类比为经典推荐系统中的用户和物品之间的交互.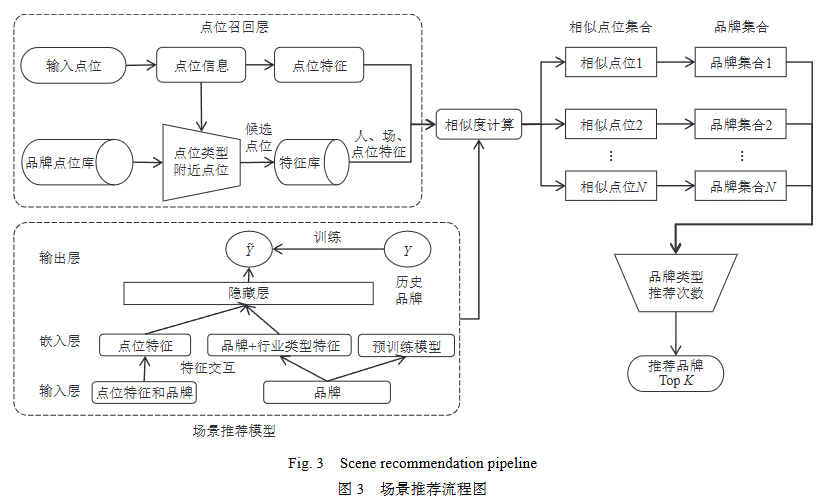
3. 选址决策引擎
LLM展现出强大的语言理解和生成能力,如果将其与其他工具组合使用,则可以实现更复杂的任务. ReAct和MRKL(modular reasoning knowledge and language)系统的成功就证明了这一点,它们将LLM与思维链的使用相结合,利用LLM的推理能力来控制工具链的执行.
在此背景下,我们提出了一个基于LLM的选址决策引擎,系统架构如图4所示. 用户可以用自然语言向系统提出选址要求,系统则利用LLM的语言理解力解析请求,并调用多个模块如空间数据库、地图引擎、选址模型等来完成选址任务. LLM既负责解析请求,又可以协调多个模块,最后用自然语言和可视化的形式向用户呈现结果. 相比传统的选址可视化系统,这样的语言交互系统更符合人的思维方式. 同时使得系统任务不再局限于提前预制的服务中,用户可以自主地完成更多定制化的任务.
语言模型受制于训练语料的限制,无法了解最新内容并且缺少专业领域的知识. 通过知识检索的方式可以有效扩充专业知识,提高生成回复的可靠性,有助于减轻“幻觉”问题,并且无需对整个模型进行重新训练,也被称为检索增强生成(retrieval augmented generation, RAG). 其核心功能在于:1)将用户问题和本地知识进行向量化编码,通过向量相似度实现召回;2)通过 LLM 对用户问题进行意图识别,并对原始答案加工整合.1)知识库构建. 首先,我们对相关文档进行清洗,将其整理为纯文本格式. 其次,将文档进行分片,划分成若干个独立且较短的段落. 每个段落被视为问答系统的最小记录单元,用于与用户提出的问题进行匹配. 然后,调用语言编码模型,对分片后的段落进行编码. 获取到相应的向量(embedding)后,我们将原始的分片和向量一同以键值对的形式存储到向量数据库中. 为了便于管理和防止在不同行业间出现错误的检索,我们为不同行业设置了不同的命名空间(namespace). 2)检索. 检索即从知识库获取相关的上下文信息. 如图5所示,首先对用户的问题进行信息抽取,通过slot填充的方式,确定用户咨询的行业,避免在后续过程中出现行业匹配错误的情况. 其次对用户的问题通过同样的语言模型编码,得到对应的向量表示. 最后获取到与问题相关的K个文档分片. 3)对话. 将检索到的相关文档、任务提示以及历史对话组成的增强提示信息交由语言模型进行处理. 这个处理过程包括去重、过滤、摘要、概述、格式处理以及结合历史对话的分析. 每次交互式对话完成后,都会让语言模型对对话历史进行总结,然后将总结结果存储. 当本地搜索的结果不满足要求,例如,相似度过低时,则会基于对话历史让LLM自行回答.
由于并没有公开具体的MRKL实现流程,因此,在本文中,我们根据MRKL架构的思路,结合ReAct以及其他相关复现方法,设计了一个选址推荐决策引擎,指令模板如图6所示. 整个的决策引擎的核心模板主要包括4部分:
1)任务指令说明. 我们首先定义了LLM的任务,即扮演一个选址推荐的专家,负责根据用户的需求,在特定的区域为品牌推荐适合的开店位置,以及根据特定的点位推荐合适的品牌. 所有点位都是通过7级Geohash进行编码,然后将编码输入模型中进行处理. 此外,我们也特别强调了在推荐点位和品牌时,需要提供推荐的理由.
2)工具说明. 在任务指令说明之后,介绍LLM可以使用的工具,并说明了这些工具的使用场景和输入输出方式. 以选址推荐模型site_selection_model为例子,具体工具描述为:“当你需要做选址推荐,寻找合适的地点开设新店时非常有用. 你需要输入需要进行选址的区域,用上海标准的行政区或街道表示. 你需要确定选址的行业,例如银行业、酒店业、咖啡厅等. 它会以列表的形式返回适合选址的Top K 个网格(grid)的Geohash编码,通常为7位字符串. 当你获取到Geohash编码后,应使用例如geohash_decode等其他工具对其进一步处理. ”
3)执行模板. 我们通过模板规定了LLM的执行流程:Question, Thought, Action, Action Input, Observation, Final Answer. 这包括LLM必须回答的问题、任务规划以及应采取的行动. 执行流程可以重复多次,直到LLM认为已经找到最优答案. 为了避免在调用工具解释过程中出现中英文混杂的情况,给后面的输出解析和工具调用造成影响,我们规定这一部分仍然使用英文. 只需要在任务说明中明确指出GPT最后必须使用中文回答,则不会影响最后的输出.
4)输出解析. 用户需要解析LLM的输出以获取有用的信息. 当检测到“Final Answer”时,用户会接收到最终答案. 在其他情况下,用户会通过正则匹配的方式解析LLM的输出,识别出需要调用的工具和工具参数,然后执行具体的工具调用. 此阶段中也包括参数归一化、空白处理和断点重试.
为了让LLM可以更好地处理地名地址数据,本文设计了一种可以在语言模型Agent中流通的地名地址处理流程,具体如图7所示. 首先,我们让LLM提取出用户指令中所涉及到的地名地址. 其次将该地址通过地名地址匹配工具,从对应的标准地名地址库对该地址进行匹配. 在很多情况下,用户输入的地理位置信息并不是标准的,为避免地址上的歧义,需要将其转换成标准的地名. 在获取标准地址后,通过地址编码(geocoding)的形式将具体的地址先转换再对应到7级Geohash空间网格中. 在系统中其他地理空间工具都以Geohash编码作为地址的索引. 因为Geohash编码的特性更容易地获取到周围相邻网格.4. 实验
在本文中使用了全国主要城市内多个行业的真实城市数据. 在选址推荐任务中分为行业通用选址和品牌选址. 行业通用将该行业内的所有店铺位置纳入训练集中,更具有通用性. 具体的行业和对应的数据量(正例数量,负例数量)分别为:餐饮(595 592,1 325 140)、美妆(37 543, 130 536)、咖啡(12 567, 43 304)、银行(168 762, 479 647)、便利店(70 007, 208 924)、酒店(69 188, 203 357)、电影演出(19 139, 73 600)、运动健身(3 017, 9 859)、亲子(38 398, 119 007)、美容塑形(165 865, 399 474)、购物(196 688, 483 924)、学习培训(62 889, 174 678)、园区(20 323, 66 828)、休闲娱乐(125 912, 307 290)、婚庆(3 106, 9 881)、医疗健康(195 864, 465 079). 品牌行业选址以5个城市的浦发银行为例,并根据文献[18]中的方法,使用规模接近的股份制银行对浦发银行的点位进行扩充,正负样本数据量分别为:上海(1 422, 2 920)、北京(1 084, 2 682)、广州(616, 1 372)、西安(530, 934)、武汉(662, 1 422). 场景推荐数据集使用上海市范围内数据作为实验数据集,在过滤掉有效历史点位类型数据后,共包含398 526条正样本和99 632条负样本. 在实际推荐应用场景中,对推荐服务的稳定性和即时性都提出了更高的要求. 在算法和模型方面,我们从4个角度出发: 1)任务相似性. 场景推荐任务是一个较为新颖的任务,但是其仍与传统的商品推荐具有一定的相似性. 因此,我们对任务进行抽象,希望可以借助成熟的传统推荐方法的建模思路. 在我们的任务中,我们试图找到与特定地点的地理位置特征相匹配的品牌,这可以看作是用户-商品交互的一个类比,其中的“点位-品牌”交互类比为“用户-商品”. 在这之前没有特定的技术被应用于场景推荐,因此我们首先采用较为经典的推荐方法作为对比. 2)数据的适配性. 随着研究的深入和专业化,推荐方法逐渐引入了如图神经网络、Transformer等复杂结构,它们也对具体的推荐数据提出了更高的需求,例如具有图结构或序列结构的数据. 然而,在场景推荐任务中,点位和品牌之间并没有天然的图结构或序列结构,因此,对于这些复杂算法的适配性较弱. 3)算法的稳定性与性能. 尽管越来越多的推荐方法不断刷新评测数据集的最优结果,但是实际工业应用中经典推荐方法仍表现出了持续的稳定性和可靠的性能. 这是我们选择它们作为基准的一大原因. 4)线上服务的效率. 场景推荐需要在线上提供及时的服务,这迫使我们选择一种既简洁又高效的方法. 这也阻碍了我们使用更复杂的算法结构. 通用行业的选址结果如图8所示,可以看到各个行业的选址分类的准确率都集中在70%~90%之间,说明选址模型达到预期效果. 通用选址模型的意义在于,即使没有指定具体的品牌以及对应的品牌数据,依然可以通过行业模型获取到较为稳定的选址效果. 不同的行业之间的选址效果依然存在差异. 例如便利店的准确率为76.67%,购物为71.86%,表现相对较弱,而银行(89.63%)、园区(87.49%)则表现较好,可以推测出当行业的位置具有较明显的特性时,其选址效果更好. 而像广泛存在的便利店一样,对选址没有特殊要求,行业选址表现则较弱. 表1展示了浦发银行在5个城市中的选址推荐结果,可以发现其效果都能超过行业通用选址,说明了当选址范围限定到具体某一品牌并可以获得对应数据时,则可以获得更好的选址效果. 场景推荐的实验室结果如表2所示,其中经典的NeuralCF和Wide&Deep模型作为基线. 其中冷启动场景下是只使用GeoBERT中预训练后的POI表示,没有依赖额外的地理空间特征. 通过构造地理空间特征,本文方法已经能够取得较好的效果,在拼接上预训练POI向量后,性能得到小幅度提升,准确率接近83%的准确率. 综上,说明了本文将空间网格上的历史开店行为类比成传统推荐中的用户与产品的交互逻辑是可行的,可以通过传统推荐方法实现基于位置的行业类型推荐.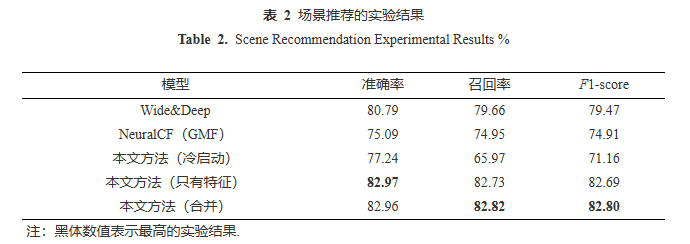
5. 案例研究
图9展示了系统中关于知识检索增强的智能问答的案例. 在实际的拓店选址的任务场景中,无论是连锁企业,还是独立经营店铺,对于是否要在某区域开设一家新的店铺以及开设地点选择的问题,都是一项挑战,不仅受到宏观经济因素的影响,而且与特定行业的发展状况紧密相关. 因此,对于预计开设店铺的商家来说,了解和参考行业发展报告以及行业数据是非常重要的. 基于LLM,结合给定的业内发展报告与行业数据可以实现快速从大量的行业报告和行业数据中找到与用户查询相关的信息,然后结合LLM的生成能力,以智能问答的形式为用户提供详尽而精准的回答. 例如,在案例中,系统根据相关文档阐述了今年美妆、医美和珠宝连锁行业的发展情况,并对各个行业的推荐程度做出了排序. 通过文档快速检索的能力,商家不仅可以快速高效地了解到各个行业的发展情况,还可以了解到行业的风险因素,这对于他们制定开店策略提供了重要的参考. 而原生GPT-4则受限于训练语料,无法提供及时的信息. 图10展示了基于GPT-4的选址问答结果与LLM驱动系统构建的选址推荐的一组对比. 在直接使用GPT-4的问答结果中可以看到多处明显的错误. 场景推荐的展示案例如图11所示. 在原始GPT-4的回答中,由于LLM并不能理解具体的位置信息,同时也无法获取周边的环境信息,只能给出非常笼统的建议. 因此无法满足用户的场景推荐的实际需求.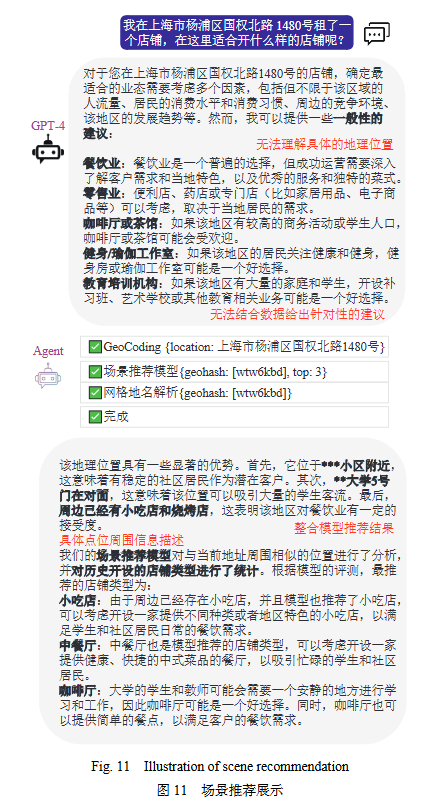
本文提出了一个LLM驱动的选址推荐系统. 对当前推荐系统的应用场景进行了拓展,展示了如何通过外部工具来让LLM在地理空间任务中理解具体位置同时避免虚构地名地址. 将大语言整合到选址推荐系统中,为用户提供更加智能、灵活和全面的选址解决方案. 用户不再被固定的任务场景限制,可以通过交互的形式获取行业信息、模型分析结果和可解释的选址归因. 期待能够推动LLM等新一代人工智能技术在地理空间任务中的应用与落地. 在未来工作中,一方面,我们期待在系统效率方面有所提升,完全依赖LLM的调度与执行时间成本较高,充分结合大模型、小模型和引擎等工具,在保证系统自主性的同时提高整体任务的执行效率. 另一方面,我们希望能够将更多模态的地理数据引入到系统中,进一步扩展任务覆盖范围.






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
