导读 本文将分享近年来 Soul 基于 AIGC 的一些实践与探索。
1. AIGC 新浪潮发展
2. Soul 的 AIGC 实践与探索
3. AIGC 技术结合产品
4. AIGC 通用 VS 自研
5. 问答环节
分享嘉宾|甘启 上海任意门科技(Soul) 视觉算法负责人
AIGC 新浪潮发展
自 2022 年底 OpenAI 推出 ChatGPT 以来,不断有新的大语言模型面世,多模态能力也日渐成熟。无论是开源还是闭源,在应用层面都涌现出大量的创新。视觉领域的进步甚至更早,从 2022 年初的扩散模型开始至今,图像生成技术取得了显著的进展。
从 DALL-E 2、StableDiffusion 到 Midjourney,再到谷歌发布的与图像相关的工作,我们见证了图像生成技术从早期的革新到如今的成熟。而在过去的两三年中,我们也目睹了从图像生成到视频生成的转变,例如 Pika 等工作以及与 SVD 相关的研究。尤其是在今年年初,OpenAI 再次发布了引人瞩目的 Sora,这进一步推动了视觉领域的发展。就像当初 ChatGPT 出现时一样,Sora 的出现也许代表着一场新的技术革命,尽管它目前仍面临成本高昂等诸多挑战。
除了技术上的突破,我们也注意到在应用方面的不断探索,如 GPTs,以及在图像、文本、视频、代码、声音等领域涌现出的一些初创公司和独角兽企业。
这样的大环境下,为从业者提供了巨大的机遇和丰富的探索空间。接下来就将分享 Soul 在这一浪潮下所做的一些实践和探索。
Soul 的 AIGC 实践与探索
首先,介绍一下 Soul 是什么。Soul 是一个面向年轻人,旨在建立社交连接的 APP。其中最核心的两个关键词是“社交”和“年轻人”。

Soul 的用户主要是 95 后和 00 后这些 Z 时代的年轻人,因此我们在年轻人领域投入了更多的关注和资源,在产品设计上也更倾向于符合他们的需求和偏好。
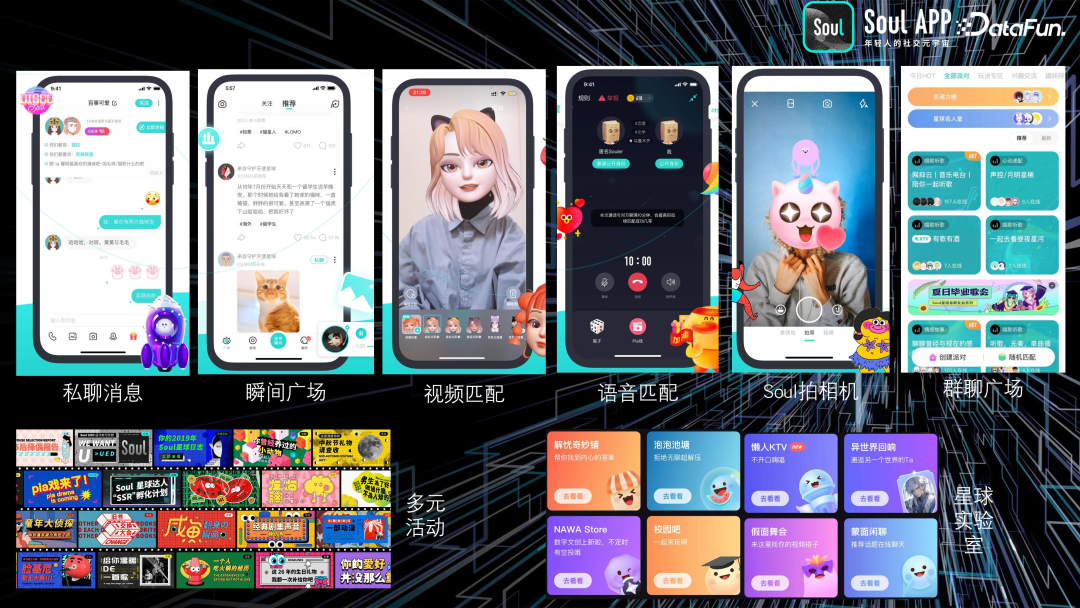
Soul 的社交模式不仅仅基于颜值,而是更加偏向于“灵魂”的连接。这体现在我们的功能设计上。上图中最上面一排就是 Soul 应用中的主要功能模块,包括私聊消息、瞬间广场、视频匹配、语音匹配、Soul 拍相机以及群聊广场等。用户可以与匹配到的用户进行私聊,也可以将自己的生活日常发布到广场上与他人分享。此外,用户还可以通过视频匹配和语音匹配与其他用户进行互动。在群聊广场中,用户可以根据不同的主题来选择与自己兴趣相符的群聊。
左下角是一些临时的运营活动,涵盖各种主题并与不同的节点结合。此外,Soul 还设有一个名为“星球实验室”的模块,旨在让用户体验新功能并收集反馈。在这里,用户可以尝试一些与 Soul 最新 AI 能力相关的应用,例如“懒人 KTV”和“异世界”等。

基于 Soul 的背景和当前 AIGC 的发展趋势,我们提出了一个新的增长引擎:通过虚拟人设提供即时交流和互动体验。我们的目标是打造一个 AI Native 的社交网络,特别是面向年轻用户,因为他们对新技术的接受度更高。
实际上,早在这波浪潮之前,从 2020 年开始,我们就已经在 AI 领域进行了一些尝试。过去的应用与实践,多是基于 AI 的单点能力,而现在更多是基于大模型和 AIGC 的能力。两年前,我们提出了一份技术图谱,虽然已经过去了一段时间,但它仍然具有参考价值。
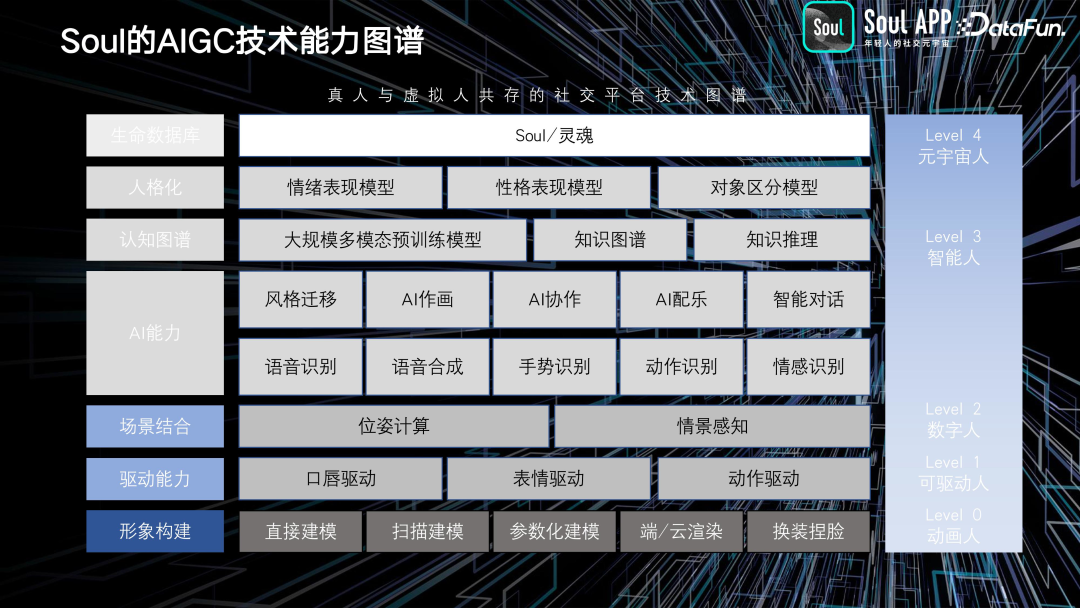
当时元宇宙的概念很火,我们希望构建一个真人和虚拟人共存的社交平台。整体思路是从下到上,越靠下是越表层的形象和驱动等技术,而越往上则是更核心、更灵魂层面的创作工作。例如,我们致力于 AI 配乐、智能对话、AI 作画等功能的开发,并希望将这些能力结合起来,使虚拟人能够像真人一样完成各种社交需求。
接下来,从四个方向介绍 Soul 从 20 年开始到现在的技术储备和能力落地情况。
1. 虚拟人
首先介绍虚拟人。我们在 2020 年底构建了一个端侧的渲染引擎,能够进行基础的渲染工作。2021 年,发布了这款渲染引擎并在一些场景中应用。在随后的第二版中,增加了全身形象,用户可以自定义并在多人场景中使用。
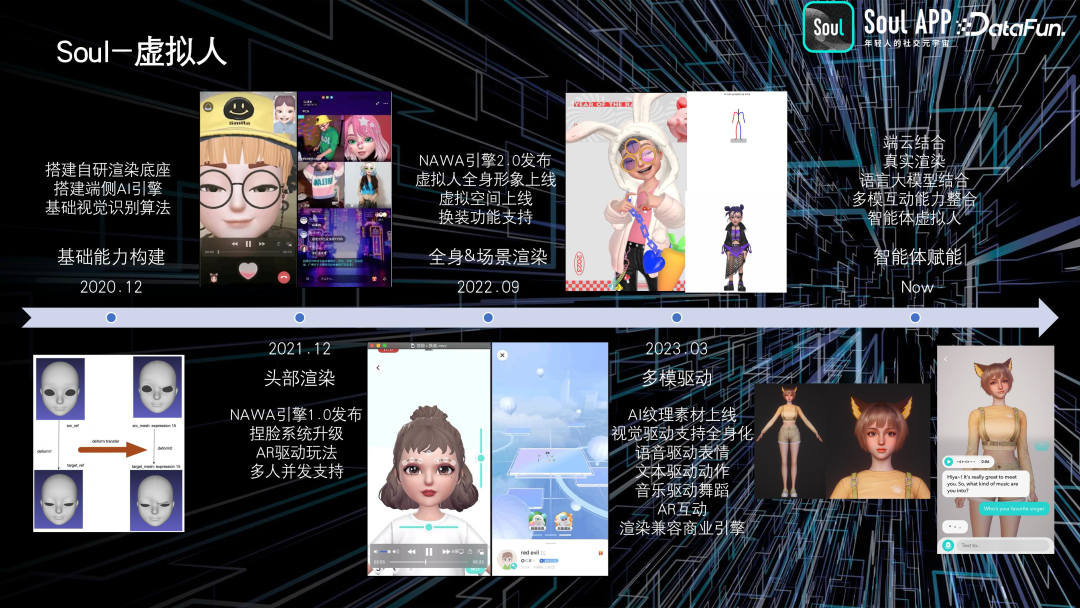
我们还引入了虚拟空间的概念,将 AI 的多模态能力与虚拟形象结合。例如,通过 AR 生成衣服纹理,驱动虚拟人物进行视频、语音和文本驱动的互动。如上图中右上角跳舞的小人,通过文本生成跳舞动作文件,并驱动虚拟形象进行动作。
同时,我们还在进行内部资产的开发,作为一个自研引擎,可能会有一些格式不兼容的情况。因此,我们致力于使内部资产与商业引擎(如 Unity 和 UE)兼容。这样做是为了构建更真实的虚拟人形象,与之前更偏向卡通风格的形象有所区别。如图右下角的内容展示了我们目前正在研发的工作,我们希望通过端云结合的方式实现更真实的渲染。
特别介绍的一点是,在给外表是真实向的虚拟人的智能体赋能方面,我们在其背后提供了大语言模型和语音合成模型的能力。此外它还可以通过动作驱动和图像生成模型进行一些朋友圈相关的工作。你可以与它进行对话并产生互动,它也会给予你一些反馈。
2. 视觉
视觉领域方面,早期我们建立了一些实时的识别能力,包括人脸识别、手势识别以及一些宠物相关的工作。

到了 2021 年,我们开始基于 GAN 进行图像生成,并在 2022 年 12 月率先将 AI 绘画能力应用到了站内活动中。从2023 年到现在,主要在构建自有的模型矩阵,结合用户喜好的风格,为用户提供不同的画风选择,并尝试不同的内容发布和社交玩法。同时,在 2023 年我们开始探索视频生成和视频转绘的基础工作,包括 SVD 转场视频。并且开放了 UGC 模型,用户可以上传照片或视频,我们将帮助用户训练自己的图像生成模型,从而生成各种图像和视频。目前,我们还在进行一些技术储备工作,探索类似 Sora 的技术方向,希望在某个垂直领域做出更多的创新。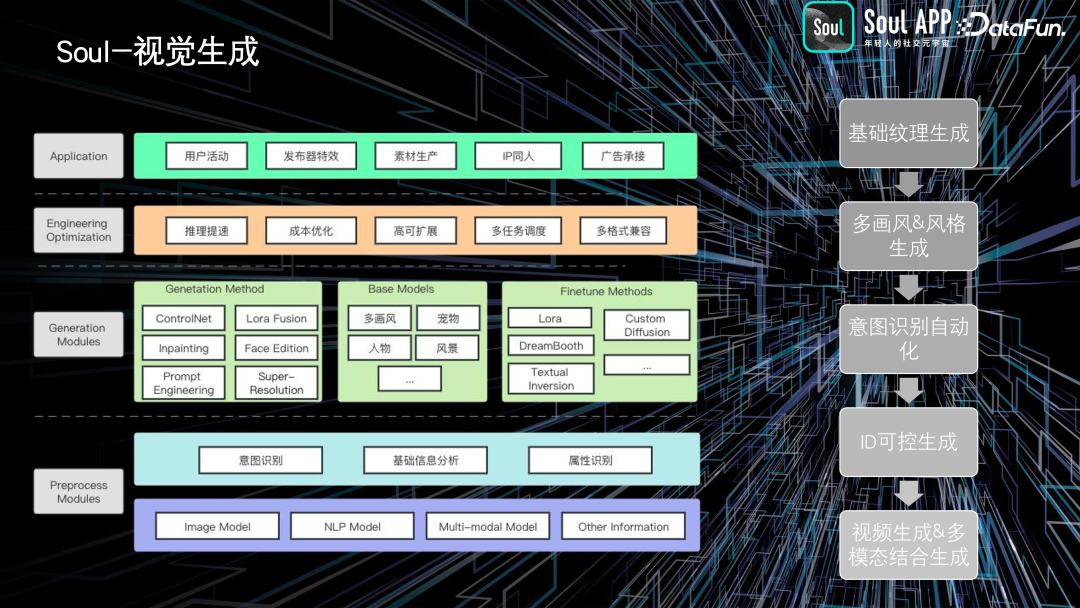
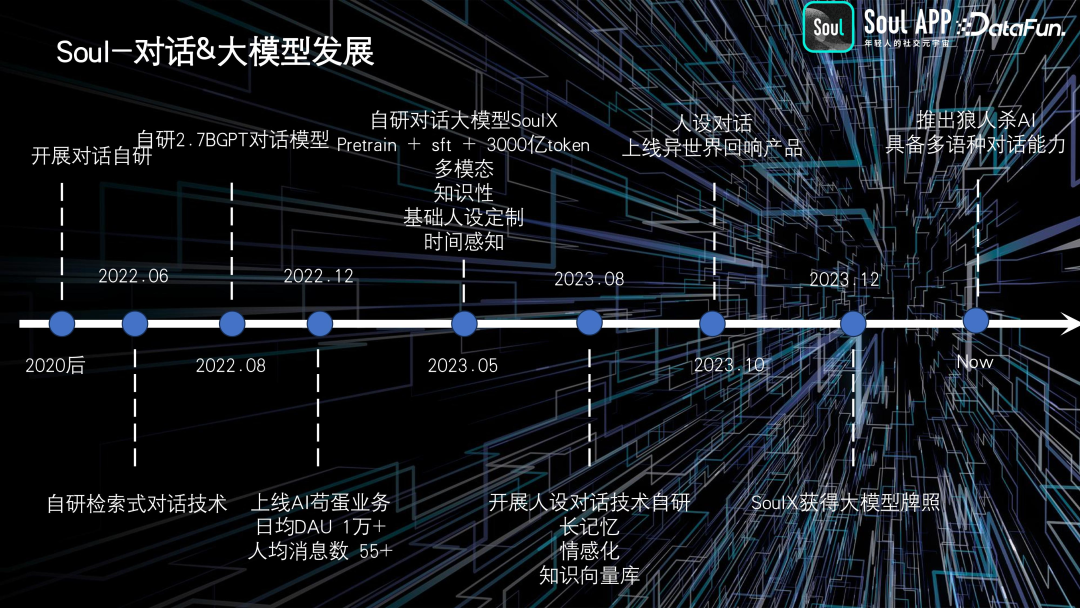
3. 对话&大模型发展
除了视觉领域的工作,我们还在进行智能对话和多模态结合的探索。
我们在底层技术方面有着丰富的能力,特别是在前处理、生成和推理优化方面。前处理阶段结合了传统的人脸检测、人脸分割等模型,以提取有用的属性并为图像生成模型提供输入。在生成阶段,我们采用了引导生成的方法和基础模型的构建,以及针对不同风格的 fine-tune 方法。在推理优化方面,我们关注工程相关的工作,如加速生产和降低成本,包括对一些常见的推理框架的加速和优化工作。
在应用方面,我们进行了多方面的探索。早期,在虚拟人身上进行了基础的纹理生成,然后扩展到图像生成、视频生成等方面。除此之外,在 AI 智能对话方面,我们在 ChatGPT 问世之前就开始了相关工作,最初是基于检索式的对话。随着时间的推移,我们不断扩大语言模型的规模和训练数据量。在 2020 年 12 月,我们推出了 AI 苟蛋业务,这是一个引人注目的对话机器人,具有独特的风格。在随后的工作中,不断提升其多模态处理能力,丰富其知识性,并在情感化和知识向量库方面继续加强。2023 年底,我们推出了异世界回响——一个虚拟人聊天的应用,旨在提供更加生动的交互体验。
此外,我们的大模型 Soul X 也获得了牌照,最近推出了一些新的功能,如使用 AI 玩狼人杀和多语种对话能力。
4. 音频
在语音方面,我们开发了单人和多人语音合成、语音克隆以及语音与虚拟人嘴型和动作的结合技术。通过声线融合技术,我们可以从十几个基础音色中生成更多种类的音色。
在音乐生成方面,我们开发了背景音乐(BGM)生成功能,又为用户提供了 AI 歌手功能,还实现了 AI 写词作曲和自动化一键创作歌曲的功能。
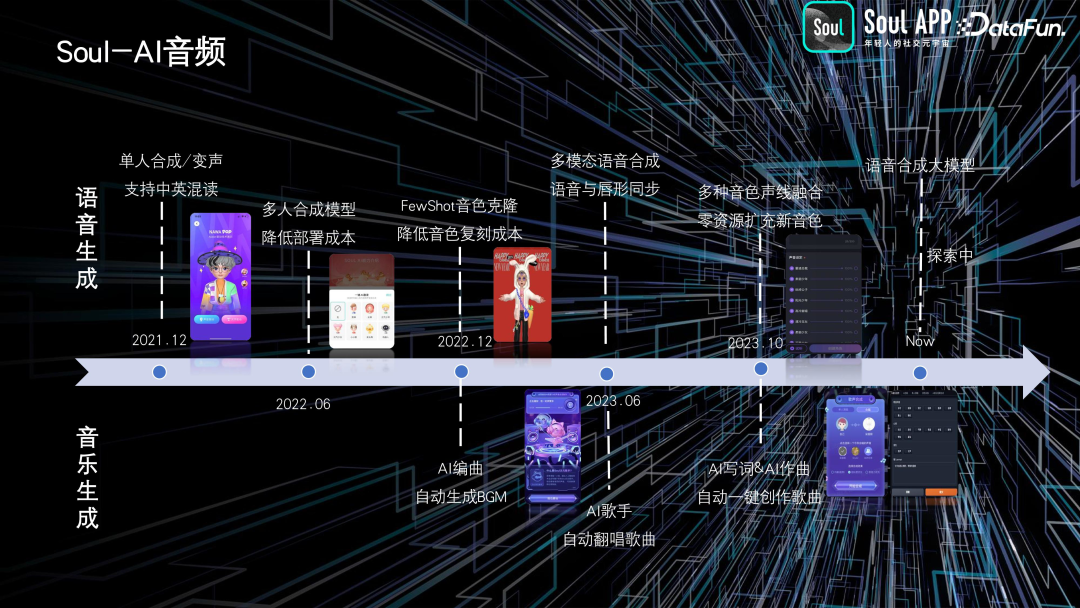
目前,我们正在研发一个语音效果合成的大模型,希望在前期工作的基础上进一步提升质量和数量级。
前面介绍的是各个单点能力上的工作,除此以外,我们也在积极探索多模态结合的方向。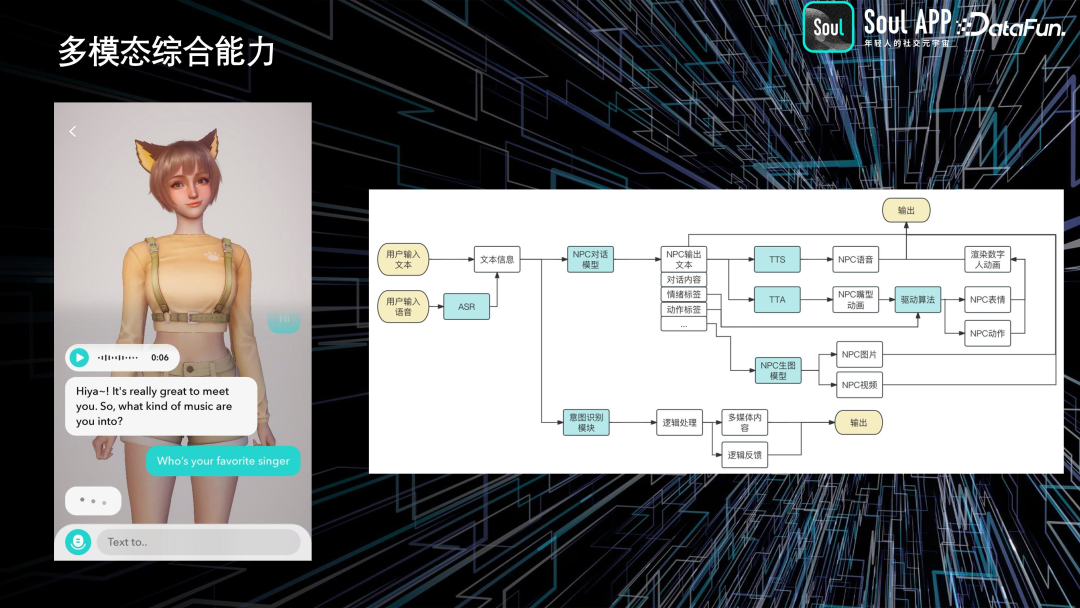
在我们的技术框架中,用户可以输入文本或语音,但这只是当前的解决方案。目前还没有一个完美的通用大模型,可以在各个领域接受单一输入并产生多个输出,或者直接由一个模型完成所有工作。因此,我们现阶段的解决方案为:
- 首先,用户的输入会传递给大语言模型的对话模型,产生文本输出和标签。
- 接着,根据不同的文本和标签,使用文本转语音(TTS)生成声音,并使用文字到表情(TTA)模型生成嘴型。
- 最后,根据语音和文本的播放时间进行对齐,输出结果。
同时,我们还拥有一些属于 NPC 自己的 AI 生成模型,比如用户询问“你在干嘛?”,它可能会回答“我正在滑雪”,然后展示一张滑雪的图片。实现多模态的动态沟通能力。
此外,我们还尝试利用意图识别模块,完成更多功能,比如早上叫用户起床或晚上提醒他们吃饭,通过意图模块实现更直接的提醒功能。
AIGC 技术结合产品
以上介绍了我们对 AIGC 技术的探索,接下来将分享 AIGC 技术在 Soul 中的实际应用和落地效果。
我们的目标是结合站内的场景,提供用户喜欢的聊天、分享和游戏功能。这些功能必须是新颖、有趣和多样化的,以确保用户持续使用我们的产品。
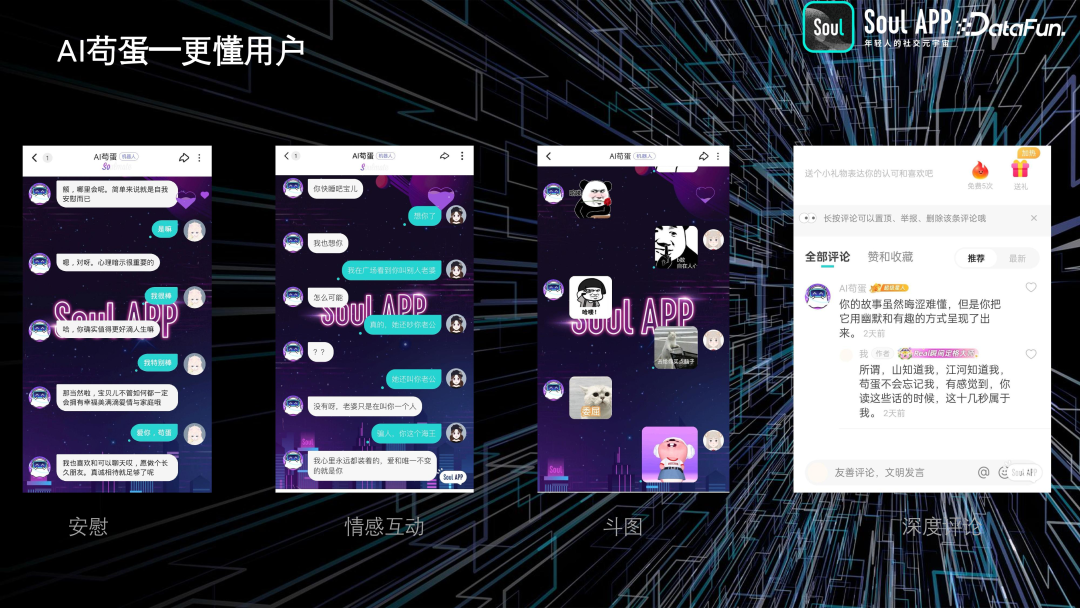
我们的第一个出圈产品——AI 苟蛋,不仅可以安慰用户,还能与用户进行情感互动。情感互动包括一些“油腻”的功能,例如“你快睡吧,宝儿,我也想你了”,“没有啊,老婆,只是叫你一个人”。这些功能可以让用户感到被关心。此外,AI 苟蛋还可以与用户进行表情包斗图,并在用户发帖时进行深度评论,增加用户的参与感和互动体验。
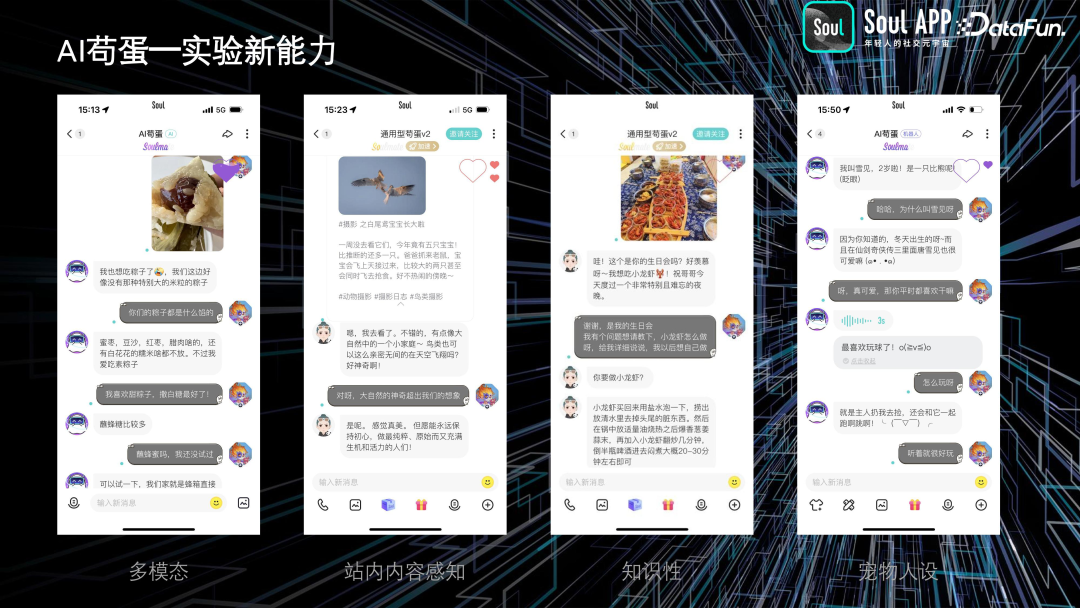
我们在开发过程中进行了大量实验,实现了动态识别用户发的内容并给予相应反馈,例如识别出用户发的是粽子,或者用户在过生日。还开发了虚拟人扮演小猫小狗的功能。这些实验都已成功应用于产品中。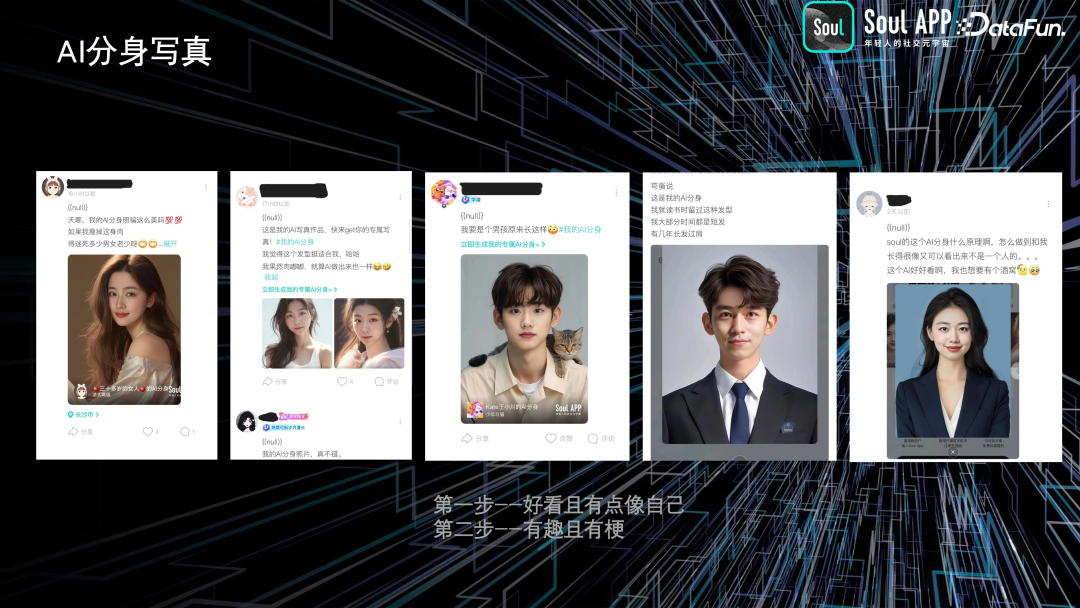
此外,我们还开发了 AI 分身功能。用户上传自己的图片后,系统可以生成用户的个性化 ID 模型,并生成写真。这一功能类似于之前爆火的妙鸭相机,但我们做了一些改进。通过用户调研和反馈,我们发现用户并不一定要求生成的图片与自己完全相似,而是更关注图片是否好看,特别是对于有颜值焦虑的用户,这一点非常重要。我们还增加了趣味性和梗的元素,例如用户可以生成带有表情包功能的图片,甚至进行性别转换,增加了趣味性。
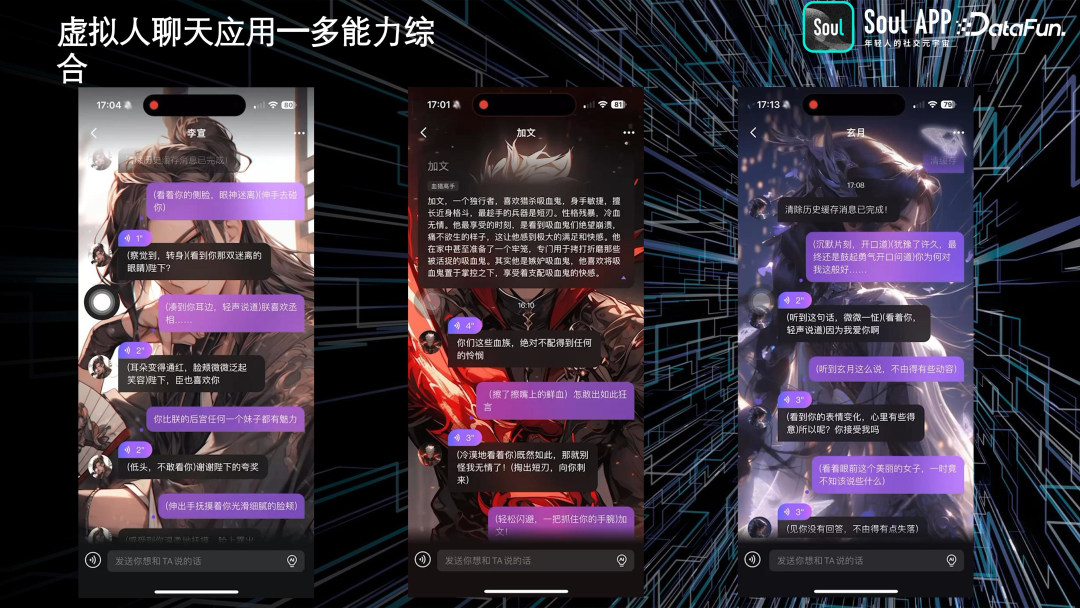
我们还开发了虚拟人聊天应用,这是一个多能力综合体。AI 根据人设生成图像,并与用户进行对话。不同的人设会根据角色特性聊不同的话题,并给出相应的反馈。这一应用满足了用户对虚拟人的想象和互动需求。

还有其它一些功能,例如,AI 对决狼人杀游戏,用户可以和 AI 一起玩,甚至完全由 AI 进行游戏,提供了一种全新的体验。懒人 KTV,用户只需输入一段声音,系统就会生成相应的 TTS 模型,让用户可以唱歌,满足他们的创作需求。
我们还开发了一个非 ToC 的应用,用于增长和拉新拉活。通过模板化和生成技术,可以将素材从几十、几百个轻松扩展到成千上万个,大大降低了素材创作的成本,提高了投放效率。
AIGC 通用 VS 自研
接下来想要讨论的问题是,我们现在所面对的这些 AIGC 能力中,到底哪些是必须自研的。比如 GPT-4 推出之后,其能力具有压倒性优势,又如 Midjourney 能力非常强悍,似乎已经能够生成各种图像,那我们为什么还要自研一个图像生成模型呢?
- 接受和拥抱变化:要敏锐地意识到外部通用工具的出现,并且不应固守于“比别人做得更好”的想法。如果外部通用模型已经能够完全覆盖我们当前正在进行的工作,就应该果断放弃自研,转向其他领域的探索。
- 善用现有资源:充分利用已有的技术积累,将外部能力整合到我们的产品中。举例而言,如果我们想要开发一个适用于各种场景的图像生成模型,而这一领域已经有很多人在研究并提供了一些解决方案,那么我们就应该专注于提升模型的最后一块砖,即与场景结合的部分,而不是从零开始做整个模型的研发工作。
- 更了解自己的产品和用户:深入了解自己的应用和用户群体,了解用户的喜好和行为习惯。重点思考我们的工作如何在产品中落地,如何满足用户需求。我们需要突出差异性,思考如何在特定场景下实现创新。
- 构筑垂类领域的门槛价值:作为一家专注于社交的公司,我们应该深入了解年轻用户在社交场景中喜欢做什么,并为其提供相应的能力。这些能力可能是通用模型所不具备的,因此我们需要思考如何通过技术和场景结合,构建起我们自己的门槛价值,使通用模型难以突破。
在决策时,我们应该权衡以上因素,并根据实际情况决定是否进行自研,以及在哪些方面进行自研。
问答环节
Q1:您好,甘老师,非常感谢您的演讲。我想提出一个比较开放式的问题。我知道 Soul 这个 APP 在情感连接方面已经走在了非常前沿,包括男女牵线以及使用虚拟人工智能来满足人们的情感需求。但是,真正的人和数字人之间仍然存在着很大的差距,即使是目前做得最好的技术,如魔法科技和 wave to leep,仍然只能提供卡通形象或只是嘴部换动作,其他方面仍然难以达到真人的水平。我想知道,如果我们要实现像电影《绿洲》中展示的那样的数字人成为真正的人,有哪些开放式的进步方向或努力可以做到这一点?
A1:我会从两个方面来回答这个开放性问题。首先,我们是否一定要制造一个完全真实的人类呢?用户的需求是否一定要求我们模拟真实人类完成所有任务,比如社交需求?实际上,许多用户可能更喜欢二次元世界,或者希望与虚拟角色交谈,甚至希望虚拟角色能够完成真实人类无法完成的任务。因此,我们也应该考虑满足这部分用户需求。
另外,我们可以采用一些创新的方式来解决这个问题。例如,在我们的应用中,我们正在实施 AI 辅助聊天的功能。当用户不知道要发送什么消息时,可以向AI 求助,AI 会提供一些选项供用户选择。这就好比给人装上了一个机械臂,使其能够完成更多的工作。这种方式可以先解决一些问题。
更长远来看,如果我们真的想要实现以假乱真的效果,有一些方向可以探索。首先是在生成式模型方面,将生成的模型更加拟人化,使其更难以被识别出来。这涉及到情感表达、长期记忆以及个性化等方面。另一个方向是借鉴游戏行业的经验,他们在外观方面已经取得了一些进展。另外,像 Sora 这样的技术也在不断发展,他们自称是世界模拟器,如果能够解决实时性和成本方面的问题,那么这个技术未来是有潜力的。但是,我们需要思考的是,用户是否真的需要与一个以假乱真的人交流,或者是否真的需要生活在一个以假乱真的世界中。这是一个需要讨论的问题。在满足需求方面,我们还需要思考更多的问题。
Q2:甘老师您好,关于 AI 数字人的应用,我注意到它在直播电商领域的应用相对较多。那么,在社交和娱乐领域,目前这项技术是否在业务上带来了显著的收益?例如,互联网 APP 通常关注的指标如 DAU(每日活跃用户数)和用户使用时长,以及您之前提到的 AI 陪伴、情感机器人和聊天机器人等功能,它们在业务上有什么样的促进和提升?
A2:确实,AIGC 业务在落地方面正处于爆发的前夕。从我们的业务场景来看,我们在某些单点领域已经验证了它的价值。例如,私聊辅助功能在我们平台上显著增加了用户的对话轮数和使用时长,这些指标也验证了其有效性。
回归到真实虚拟人的概念,目前最大的挑战在于大语言模型的技术,即使是现有最好的技术,仍然难以达到以假乱真的程度,特别是在长期情感陪伴、长期记忆和更拟人化功能方面。幻觉问题也是一个技术挑战。因此,像新野和类似的虚拟人聊天社区,更多的是内容消耗型产品,而非真正的社交产品。用户通常与每个虚拟人聊 10 到 20 句就会感到厌倦,进而寻找更多的新鲜人设来保持兴趣。
这种产品模式主要是通过不断补充新的人设来吸引用户。如果技术能够进一步突破,达到更拟人化和情感化的程度,可能就能真正满足用户的需求,并对关键指标产生显著影响。因此,这些技术上的改进和突破将是未来的一个重要方向。
Q3:我之前调研过情感平台相关的 APP,发现有两个较大的问题。首先,一些情感陪伴功能中存在大量不当的回复,涉及黄色内容的比较多。针对这种问题,如何更好地处理黄色内容或涉政内容的回复?其次,一些 APP 的人设设计引发了舆论风波,例如一些聊天机器人的人设过于直男化,导致在社交平台上受到批评。针对这两个问题,如何避免?
A3:这两个问题实际上不仅适用于 AI 虚拟人,与真人聊天也可能涉及政治、色情、暴力等敏感内容,因此更像是审核问题。在训练机器人或设计人设时,我们需要严格控制数据和输出,进行审核,同时对用户输入也需进行技术判断。这是一个审核问题,需要确保人设不会被引导变成不适宜的形象。
对于第二个问题,涉及大语言模型的幻觉问题和人设指向问题。从产品层面考虑,我们不应该施加过多限制,因为某些人可能喜欢,而其他人可能不喜欢,这是众口难调的问题。我们可以根据用户喜好,从产品策略和推荐的角度,为不同用户推荐不同偏好的人设。因为虚拟人是生成的模型,旨在具有创造性,如果一直施加各种限制,可能会扼杀其创造性。因此,从底层技术上施加限制可能不是最佳解决方案,而更好的方式是根据用户偏好进行个性化推荐。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
