Normalization
【1】为什么模型需要Normalization?
在深度神经网络训练中,模型需要Normalization的原因:
1.归一化可以调整输入数据特征的分布,使其分布更稳定,在训练时可以缓解梯度消失或梯度爆炸问题。
2. 归一化可以将不同特征的值范围映射到相似的区间,有助于优化算法(如梯度下降)更快速地找到全局最优解或局部最优解。有助于加速模型的收敛过程。若各个特征的分布范围差异过大,会影响梯度下降的迭代步数以及梯度更新的难度,从而影响模型的收敛。
3. 归一化有助于使模型更好地泛化到未见过的数据。当输入数据归一化后,模型在训练过程中能够更好地学习到数据的统计特性,从而提高其对新数据的适应能力。
来自论文:https://arxiv.org/pdf/2303.18223
【2】Normalization Position:Pre-Norm&Post-Norm的区别
Post-Norm:Post-Norm在残差之后进行归一化,对参数正则化的效果更强,进而模型的鲁棒性会更好;但由于Post Norm对所有的参数都进行归一化,在训练过深的模型时,梯度在计算回传的时候容易发生梯度消失或梯度爆炸。(不易训练)Pre-Norm:Pre-Norm将部分参数进行归一化,部分参数直接加在后面(没有正则化),这样可以防止模型发生梯度消失或者梯度爆炸,模型训练的稳定性更强。但是Pre-Norm模型的等效“深度”受到影响,L+1层网络近似于一个L层的宽网络,无形之中的降低深度导致最终效果变差。(易训练)Pre Norm和Post Norm的计算公式:
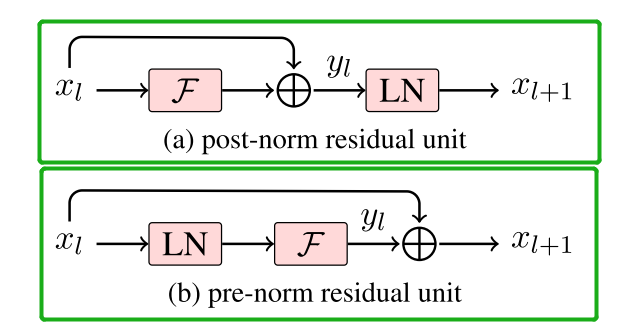
在Add后进行Norm叫Post-Norm。而Norm之后再Add叫Pre-Norm。
结论是:在层数较少,Post Norm和Pre Norm都能正常收敛的情况下,Post Norm的效果更好一些;但是在层数较多情况下,为保证模型训练,可以选择Pre Norm。
在Bert时代由于层数较浅,往往采用的是Post-Norm,而到了大模型时代,由于transformer的层数开始加深,为了训练稳定性开始使用Pre-Norm。
【拓展】在Bert时代中往往使用Post Norm而不使用Pre Norm?
在Bert时代网络结构中基本上都用Post Norm,而几乎不用Pre Norm。明确的结论是:同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm。
Pre Norm更容易训练好理解,因为它的恒等路径更突出,但为什么它效果反而没那么好呢?知乎上 @唐翔昊 给出的答案是:Pre Norm的深度有“水分”!L层的Pre Norm模型实际等效层数不如L层的Post Norm模型;而因为Pre Norm实际层数少了导致效果变差了。【推导】Pre Norm结构无形地增加了模型的宽度而降低了模型的深度,而我们知道深度通常比宽度更重要,所以是无形之中的降低深度导致最终效果变差了。
而Post Norm刚刚相反,在《浅谈Transformer的初始化、参数化与标准化》中就分析过,它每Norm一次就削弱一次恒等分支的权重,所以Post Norm反而是更突出残差分支的,因此Post Norm中的层数更加“足秤”,一旦训练好之后效果更优。
【推荐阅读】
1.为什么Pre Norm的效果不如Post Norm?https://kexue.fm/archives/9009
2.为什么大模型结构设计中往往使用postNorm而不用preNorm?
【3】Post Norm结构模型中warm up如何起作用的?
warmup是Transformer训练的关键步骤,没有它可能不收敛,或者收敛到比较糟糕的位置。为什么会这样呢?
warmup是在训练开始阶段,将学习率从0缓增到指定大小,而不是一开始从指定大小训练。如果不进行warmup,那么模型一开始就快速地学习,由于梯度消失,模型对越靠后的层越敏感,也就是越靠后的层学习得越快,然后后面的层是以前面的层的输出为输入的,前面的层根本就没学好,所以后面的层虽然学得快,但却是建立在糟糕的输入基础上的。很快地,后面的层以糟糕的输入为基础到达了一个糟糕的局部最优点,此时它的学习开始放缓(因为已经到达了它认为的最优点附近),同时反向传播给前面层的梯度信号进一步变弱,这就导致了前面的层的梯度变得不准。
所以,如果Post Norm结构的模型不进行warmup,能观察到的现象往往是:loss快速收敛到一个常数附近,然后再训练一段时间,loss开始发散,直至NAN。
如果进行warmup,那么留给模型足够多的时间进行“预热”,在这个过程中,主要是抑制了后面的层的学习速度,并且给了前面的层更多的优化时间,以促进每个层的同步优化。
这里的讨论前提是梯度消失,如果是Pre Norm之类的结果,没有明显的梯度消失现象,那么不加Warmup往往也可以成功训练。
【推荐阅读】
1.模型优化漫谈:BERT的初始标准差为什么是0.02?https://kexue.fm/archives/8747
【4】简要介绍各种Normalization method
LayerNorm:LayerNorm会计算当前Layer的所有激活值的均值μ和方差σ,然后对激活值X减去均值μ,除以方差σ,再通过可训练的缩放参数 γ 进行缩放,最后添加可训练的平移参数β 得到 Y。LN最重要的两个部分是平移不变性和缩放不变性。
LayerNorm规范化activations的第一动量均值(mean)和第二动量方差(variance)。
RMSNorm:RMSNorm是改进归一化方法的LayerNorm。相比LayerNorm中利用均值和方差进行归一化,RMSNorm 利用均方根进行归一化。RMSNorm会计算当前Layer的所有激活值的均方根rms,然后对激活值X除以均方根rms,再通过可训练的缩放参数 γ 进行缩放,最后得到 Y。
RMSNorm规范化activations的第二动量均方根(RMS)。RMSNorm的收敛速度比LN要快很多。
DeepNorm:与Post-LN相比,DeepNorm在LayerNorm之前对残差链接进行up-scale,在初始化阶段down-scale模型参数。DeepNorm兼具Pre-LN的训练稳定和Post-LN的效果性能。需要注意的是,该方法只会扩大前馈网络的权值的规模,以及attention层的投影值。
DeepNorm试图结合LN和RMSNorm长处,同时规范化activations的第一动量和第二动量。
LayerNorm.RMSNorm.DeepNorm
【1】简要介绍LayerNorm
LayerNorm提出论文:Layer Normalization
论文地址:https://arxiv.org/pdf/1607.06450

LayerNorm的提出背景:LayerNorm是针对序列数据提出的归一化方法,主要在Layer维度进行归一化,即对整个序列进行归一化。LN提出用于提高模型的训练效果和泛化能力。
LayerNorm的简要介绍:LayerNorm会计算当前Layer的所有激活值的均值μ和方差σ,然后对激活值X减去均值μ,除以方差σ,再通过可训练的缩放参数 γ 进行缩放,最后添加可训练的平移参数β 得到 Y。LN最重要的两个部分是平移不变性和缩放不变性。
LayerNorm的计算公式:

LayerNorm的优点:LN对每个样本的每层进行归一化,减少了每层输入分布的变化,有助于提高模型的训练效果。LN通过减少内部层的耦合程度,有助于网络更好地泛化到新数据,提升模型的泛化能力。
LayerNorm在LLM中的不同位置应用可以解决不同的问题。输入层归一化可以提高模型的泛化能力,输出层归一化可以提高模型的稳定性和预测准确性,而中间隐藏层归一化可以改善梯度传播,加速模型的收敛速度。具体应用 Layer Norm 的位置需要根据具体任务和模型的需求进行选择。
【推荐阅读】https://zhuanlan.zhihu.com/p/635710004
【2】简要介绍Pre-LayerNorm和Post-LayerNorm区别
Post-LN和Pre-LN两种架构的具体形式:
来自论文:https://arxiv.org/pdf/2002.04745Post-LN:在transformer的原始结构中,采用了Post-LN结构。Post-LN在残差链接之后LayerNorm。在LLM中训练过程中发现,Post-LN的深层梯度范数过大,会造成训练的不稳定性,需要结合warm up做一些学习率上的调整优化。在应用中,LLM还是会结合一些Pre-Norm,如在GLM-130B中采用Post-LN与Pre-LN结合的方式。( 残差链接是图中addition模块)
Pre-LN:在Xiong et al. 的论文中,提出更优的Pre-LN结构。Pre-LN将LayerNorm放置在残差链接之前。Pre-LN在每层的梯度范数近似相等,有利于提升训练稳定性。相比Post-LN,使用Pre-LN的深层transformer的训练更稳定,但是模型效果略差。出于训练稳定性的考虑,多数LLM都采用Pre-LN。

Pre-LN相比的Post-LN的优势主要表现在:
a.在learning rate schedular上,Pre-LN不需要采用warm-up策略,而Post-LN必须要使用warm-up策略才可以在数据集上取得较好的Loss和BLEU结果。
b.在收敛速度上,由于Pre-LN不采用warm-up,其一开始的learning rate较Post-LN更高,因此它的收敛速度更快。
c.在超参调整上,warm-up策略带来两个需要调整的参数:lr(最大学习率)和 T (warmup过程的总步数)。这两个参数的调整将会影响到模型最终的效果。由于多引入超参,也给模型训练带来了一定难度。
总结看来,Pre-LN带来的好处,基本都是因为不需要做warm-up引起的。而引起这一差异的根本原因是:
a.Post-LN在输出层的gradient norm较大,且越往下层走,gradient norm呈现下降趋势。这种情况下,在训练初期若采用一个较大的学习率,容易引起模型的震荡。
b.Pre-LN在输出层的gradient norm较小,且其不随层数递增或递减而变动,保持稳定。
c.无论使用何种Optimzer,Post-LN(no warm-up)的效果不如Pre-LN和采用warm-up的情况。
【推荐阅读】
1.Transformer学习笔记三:Batch Normalization & Layer Normalization
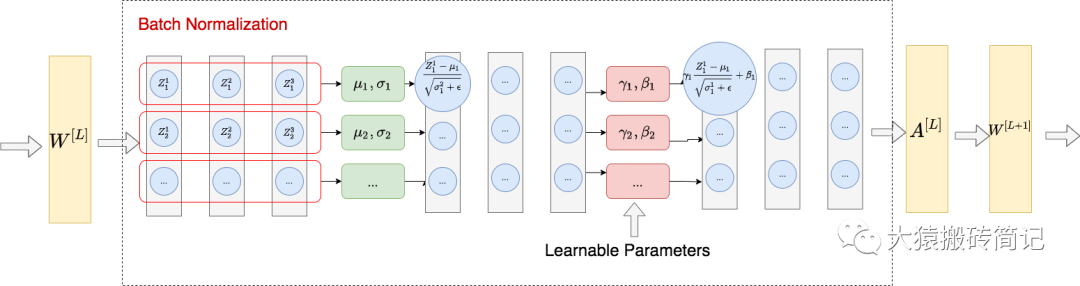
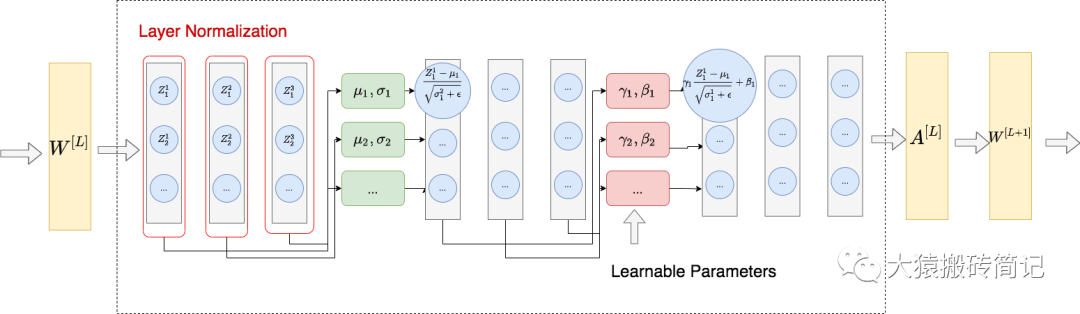
【3】BatchNorm和LayerNorm的区别
BatchNorm的思路:
LayerNorm的思路:
BatchNorm:对每一个batch进行操作,使得对于这一个batch中所有的输入数据,它们的每个特征都是均值为0,方差为1的分布。在BN后,需要再加一个线性变换操作,让数据恢复其表达能力(让模型学习参数γ 和 β)。
LayerNorm:整体做法类似于BN,不同的是LN不是在特征间进行标准化操作(横向操作),而是在整条数据间进行标准化操作(纵向操作)。
BN和LN的区别:BN和LN的作用对象不同,BatchNorm认为相同维的特征具有相同分布,在特征维度上开展归一化操作,归一化的结果保持样本之间的可比较性。而LayerNorm认为每个样本内的特征具有相同分布,因此针对每一个样本进行归一化处理,保持相同样本内部不同对象的可比较性。
【推荐阅读】
1.Transformer学习笔记三:Batch Normalization & Layer Normalization
2.https://www.zhihu.com/question/487766088/answer/3094052709
【4】为什么TF使用LayerNorm而不是BatchNorm?
首先,NLP数据中由于每条样本可能不一样长,会使用padding,如果对padding部分进行normalization,对效果有负面影响。
直观来说,batchnorm会对同一个特征以batch为组进行归一化,而对于文本数据,同一个位置的token很可能是没有关联的两个token,对这样一组数据进行归一化没有什么实际意义。
《PowerNorm: Rethinking Batch Normalization in Transformers》论文的实验也表明,在NLP数据使用batchnorm,均值和方差相对layernorm会更加震荡,因此效果欠佳。
v:BN 是对样本内部某特征的缩放,LN 是样本直接之间所有特征的缩放。为啥BN不适合NLP ?是因为NLP模型训练里的每次输入的句子都是多个句子,并且长度不一,那么 针对每一句的缩放才更加合理,才能表达每个句子之间代表不同的语义表示,这样让模型更加能捕捉句子之间的上下语义关系。如果要用BN,它首先要面临的长度不一的问题。有时候batch size 越小的bn 效果更不好。
【推荐阅读】
1.https://mp.weixin.qq.com/s/IJL5XmwuIaCiuoEhuLaPMw
【1】简要介绍RMSNorm
RMSNorm提出论文:Root Mean Square Layer Normalization
论文地址:https://arxiv.org/pdf/1910.07467
RMSNorm的提出背景:LayerNorm实现中重要的两个部分是平移不变性(re-centering)和缩放不变性(re-scaling) 。有研究认为,LayerNorm取得成功的关键是缩放部分的缩放不变性(re-scaling) ,而不是平移部分的平移不变性。因此,提出的RMSNorm 去除了计算过程中的平移,只保留了缩放。
RMSNorm的简要介绍:RMSNorm是改进归一化方法的LayerNorm。相比LayerNorm中利用均值和方差进行归一化,RMSNorm 利用均方根进行归一化。RMSNorm会计算当前Layer的所有激活值的均方根rms,然后对激活值X除以均方根rms,再通过可训练的缩放参数 γ 进行缩放,最后得到 Y。目前主流大模型都使用RMSNorm(如LLaMA.qwen..)。
RMSNorm的计算公式:
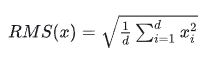
对激活值 x 归一化后得到 y:
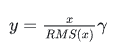
RMSNorm的优点:RMSNorm相比一般的LayerNorm,减少了计算均值和平移系数的部分,在模型训练中的训练速度更快,模型效果表现与LayerNorm基本相当,甚至有所提升(LN取得成功的原因可能是缩放部分的缩放不变性(re-scaling),而不是平移部分的平移不变性)。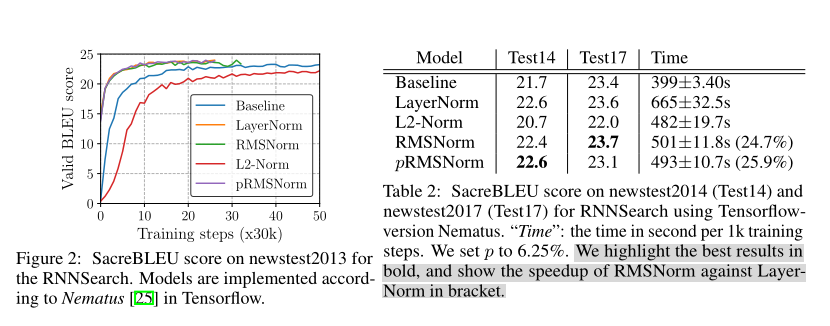
RMSNorm的代码实现:
class RMSNorm(torch.nn.Module):
def init(self, dim: int, eps: float = 1e-6):
super().init()
self.eps = eps
# weight是一个可学习的参数
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
# 对输入x求平方并计算最后一个维度的平均值,
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
# 将输入x转化为浮点数并进行标准化,再将标准化的结果转化回x的类型。
output = self._norm(x.float()).type_as(x)
return output * self.weight
#https://mp.weixin.qq.com/s/tVDaiMWdRkUY0we52O7FGw
【1】简要介绍DeepNorm
DeepNorm提出论文:《DeepNet: Scaling Transformers to 1,000 Layers》
论文地址:https://arxiv.org/pdf/2203.00555
代码地址:https://github.com/microsoft/unilm
DeepNorm的提出背景:Nguyen和Salazar(2019)发现相对于Post-LN,Pre-LN能够提升Transformer的稳定性。然而,Pre-LN在底层的梯度往往大于顶层,导致其性能不及Post-LN。为了缓解这一问题,研究员努力通过更好的初始化方式或更好的模型架构来改进深度Transformer。这些方法可以使多达数百层的Transformer模型实现稳定化,然而以往的方法没有能够成功地扩展至1000层。
Indepth theoretical analysis shows that model updates can be bounded in a stable way. The proposed method combines the best of two worlds, i.e., good performance of Post-LN and stable training of Pre-LN, making DEEPNORM apreferred alternative.
DeepNorm的简要介绍:与Post-LN相比,DeepNorm在LayerNorm之前对残差链接进行up-scale,在初始化阶段down-scale模型参数。DeepNorm兼具Pre-LN的训练稳定和Post-LN的效果性能。需要注意的是,该方法只会扩大前馈网络的权值的规模,以及attention层的投影值。
DeepNorm的具体实现:
DeepNorm在LayerNorm之前对残差链接进行up-scale(,以扩大残差连接。在Xavier参数初始化阶段对模型参数进行down-scale(以减小部分参数的初始化范围。
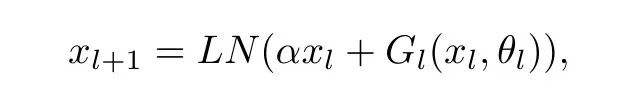
DEEPNET基于transformer架构,不同的就是用了DeepNorm替换每层的Post-LN。Gl 是第 l 层attention和feed-forward网络。DeepNorm的优点:a.DeepNorm可以缓解爆炸式模型更新的问题,把模型更新限制在常数,使得模型训练过程更稳定。具体地,Deep Norm方法在执行Layer Norm之前,up-scale了残差连接( ?>1);另外,在初始化阶段down-scale了模型参数( ?<1 )。b.DeepNorm 通过引入多层归一化操作,可以改善梯度传播、解决DNN模型训练中梯度消失和梯度爆炸问题。归一化操作可以减小数据的分布差异,也可以减少对学习率的敏感性,提高泛化能力。
DeepNorm的模型效果:
发现对比Post-LN,DeepNet更新更加稳定。
DeepNorm的代码实现:Deep Norm 的代码实现可以基于 PyTorch 框架来完成。以下是简单的 Deep Norm 的代码示例:
import torch
import torch.nn as nn
class DeepNorm(nn.Module):
def __init__(self, input_dim, hidden_dims, output_dim):
super(DeepNorm, self).__init__()
self.layers = nn.ModuleList()
self.norm_layers = nn.ModuleList()
# 添加隐藏层和归一化层
for i, hidden_dim in enumerate(hidden_dims):
self.layers.append(nn.Linear(input_dim, hidden_dim))
self.norm_layers.append(nn.LayerNorm(hidden_dim))
input_dim = hidden_dim
# 添加输出层
self.output_layer = nn.Linear(input_dim, output_dim)
def forward(self, x):
for layer, norm_layer in zip(self.layers, self.norm_layers):
x = layer(x)
x = norm_layer(x)
x = torch.relu(x)
x = self.output_layer(x)
return x
# 创建一个 DeepNorm 模型实例
input_dim = 100
hidden_dims = [64, 32]
output_dim = 10
model = DeepNorm(input_dim, hidden_dims, output_dim)
# 使用模型进行训练和预测
input_data = torch.randn(32, input_dim)
output = model(input_data)
在这个示例中,定义了一个 DeepNorm 类,其中包含了多个隐藏层和归一化层。在 forward 方法中,依次对输入数据进行线性变换、归一化和激活函数处理,并通过输出层得到最终的预测结果。
ReLU,GeLU,Swish激活函数
【1】激活函数
图片链接:https://arxiv.org/pdf/2303.18223【2】ReLU激活函数
ReLU(Rectified Linear Unit)
ReLU提出论文:Deep Sparse Rectifier Neural Networks
论文地址:https://www.researchgate.net/publication/
215616967_Deep_Sparse_Rectifier_Neural_Networks
ReLU的提出背景:传统的Sigmoid和Tanh函数在深层网络中存在严重的梯度消失问题。
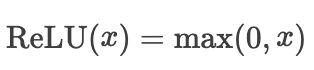
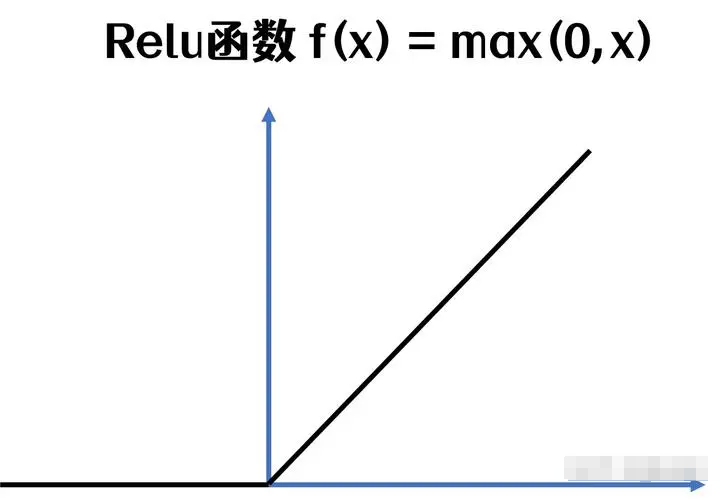
ReLU的优点:1.计算简单:ReLU的计算复杂度远低于Sigmoid和Tanh,有利于加速网络训练。2.缓解梯度消失:对于正输入,ReLU的梯度恒为1,有效缓解了深层网络中的梯度消失问题。3.稀疏激活:ReLU可以使一部分神经元的输出为0,导致网络的稀疏表达,这在某些任务中是有益的。4.生物学解释:ReLU的单侧抑制特性与生物神经元的行为相似。
ReLU的缺点和限制:1."死亡ReLU"问题:当输入为负时,梯度为零,梯度再也无法回传过来,可能导致某些神经元永久失效。2.非零中心输出:ReLU的输出均为非负值,均值不为0,分布发生偏移,可能会影响下一层的学习过程。
ReLU的适用场景:深度卷积神经网络(如ResNet, VGG)中广泛使用。适用于大多数前馈神经网络。
Sigmoid激活函数和Tanh激活函数公式,优缺点和使用场景
【★】推荐阅读:https://mp.weixin.qq.com/s/TCoSeYi1gvEatf2B7eiT-g
Leaky ReLU(Rectified Linear Unit)
Leaky ReLU提出论文:Rectifier Nonlinearities Improve Neural Network Acoustic Models
论文地址:https://ai.stanford.edu/~amaas/papers/
relu_hybrid_icml2013_final.pdf
Leaky ReLU的提出背景:解决ReLU的"死亡"问题。
Leaky ReLU的数学表达式:
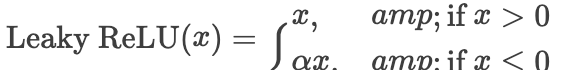
其中, a是一个小的正常数,通常取0.01。
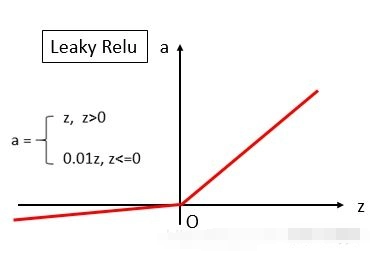
Leaky ReLU的优点:1.缓解"死亡ReLU"问题:在输入为负时仍然保留一个小的梯度,避免神经元完全失活。2.保留ReLU的优点:在正半轴保持线性,计算简单,有助于缓解梯度消失。
Leaky ReLU的缺点和限制:1.引入超参数:值的选择需要调优,增加了模型复杂度。2.非零中心输出:与ReLU类似,输出仍然不是零中心的。
Leaky ReLU的适用场景:1.在ReLU表现不佳的场景中作为替代选择。2.在需要保留一些负值信息的任务中使用。
【推荐阅读】https://mp.weixin.qq.com/s/TCoSeYi1gvEatf2B7eiT-g
ReLU及其变体对比
【推荐阅读】:https://mp.weixin.qq.com/s/TCoSeYi1gvEatf2B7eiT-g
【3】GeLU激活函数
GELU (Gaussian Error Linear Unit)
GeLU提出论文:GAUSSIAN ERROR LINEAR UNITS (GELUS)
论文地址:https://arxiv.org/pdf/1606.08415

GeLU的计算公式:
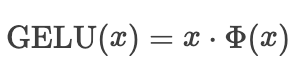
其中 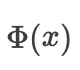 是标准正态分布的累积分布函数。
是标准正态分布的累积分布函数。
GeLU近似形式的计算公式:
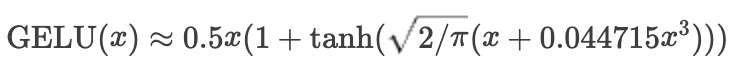
其中,输入是一个标量 x,tanh() 是双曲正切函数,pi 是圆周率。
这个近似形式虽然看起来仍然复杂,但它捕捉了GELU的本质特性,同时更容易计算。
GeLU的函数图像:
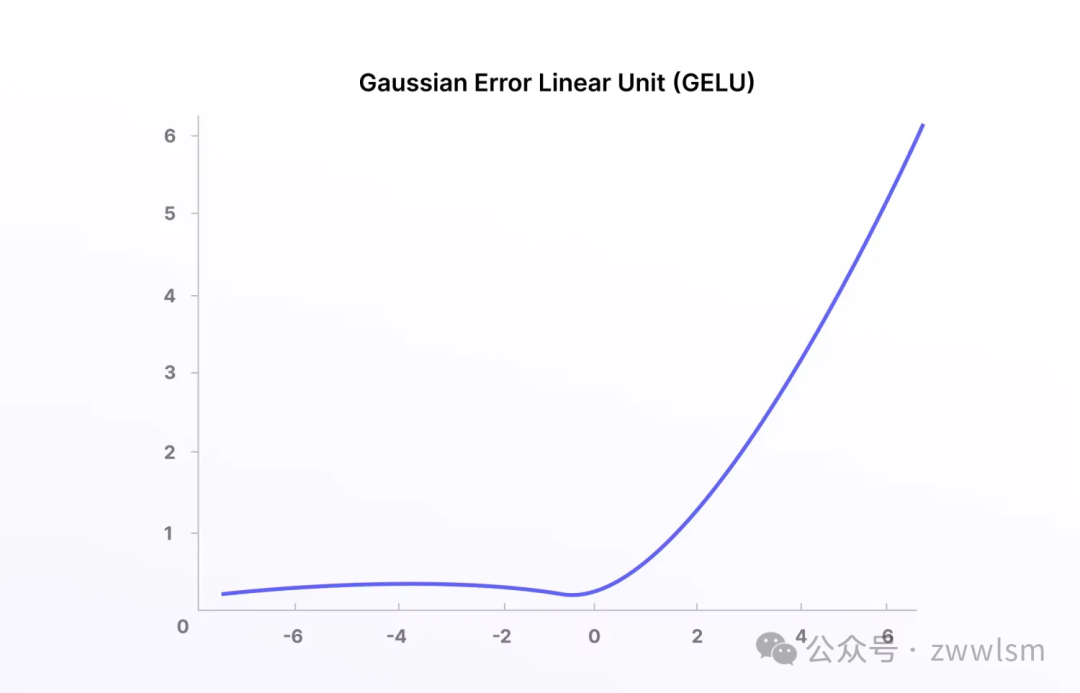
GeLU的优点:a.GeLU具有平滑非线性。在接近零的区域表现得类似于线性函数,而在远离零的区域则表现出非线性的特性,有利于梯度传播。b.相比于ReLU激活函数,GeLU函数在某些情况下能够提供更好的性能和更快的收敛速度。c.GeLU 几乎没有梯度消失的现象,可以更好地支持深层神经网络的训练和优化。
GeLU的缺点与限制:GeLU的计算复杂度高比ReLU复杂得多,可能会显著增加计算时间。解释性较差:相比ReLU,其数学形式更复杂,解释性不强。
GeLU的适用场景:GeLU激活函数在Transformer模型中广泛应用于FFN块。
【推荐阅读】:https://mp.weixin.qq.com/s/TCoSeYi1gvEatf2B7eiT-g
【4】Swish激活函数
Swish提出论文:Swish: a Self-Gated Activation Function
论文地址:https://arxiv.org/pdf/1710.05941v1

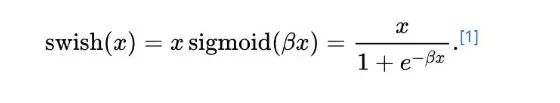
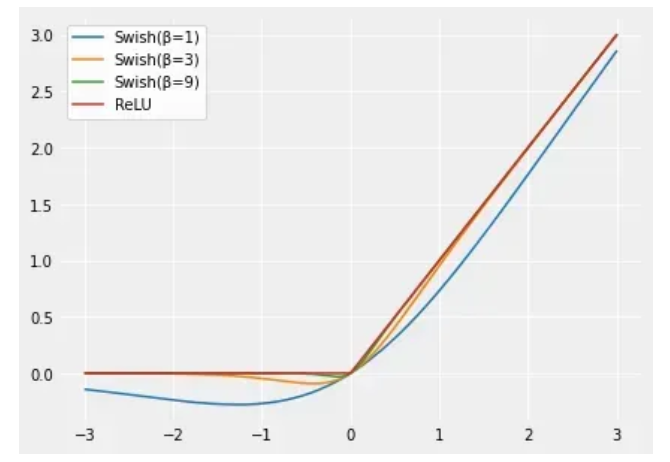
其中,β为可学习参数。swish是对带有非零负值梯度的ReLU平滑版本。Swish的优点:a.平滑非单调:Swish是个平滑且非单调的函数,这使得它能够保留更多的信息。b.无上界有下界:函数在负无穷处趋近于0,但在正方向上没有上界。c.计算效率:虽然比ReLU复杂,但仍可以通过现有的Sigmoid实现高效计算。d.自门控机制:函数的形式可以看作是一种自门控机制,有助于信息流动。Swish的主要优点是它比ReLU更平滑,可以带来更好优化和更快的收敛。Swish的缺点与限制:a.计算复杂度:比ReLU复杂,可能会略微增加训练时间。b.非稀疏激活:不像ReLU那样产生稀疏激活,这在某些任务中可能是不利的。Swish与ReLU的关系:
Swish可以比ReLU激活函数更好,因为它在0附近提供了更平滑的转换,这可以带来更好的优化。【Swish是对带有非零负值梯度的ReLU平滑版本。】随着β值的增加,Swish相似性变得更接近ReLU。Swish可以粗略地看成在线性函数和ReLU函数之间进行非线性插值的平滑函数。β可以设置为可训练参数,则插值程度由模型控制。
【推荐阅读】https://mp.weixin.qq.com/s/TCoSeYi1gvEatf2B7eiT-g
【5】激活函数的选择策略
https://mp.weixin.qq.com/s/TCoSeYi1gvEatf2B7eiT-g
GLU及其变体
【1】简要介绍GLU
GLU提出论文:Language Modeling with Gated Convolutional Networks论文地址:https://arxiv.org/pdf/1612.08083v1GLU的提出背景:GLU是Microsoft在2016年提出的,LSTM序列计算上前后依赖不能很好并行,GLU是在CONV基础上加上了Gate的结构,可以实现stack堆叠,效果上比LSTM更好。它的定义涉及到输入的两个线性变换的向量积,其中一个经过σ函数的处理。GLU 的核心思想是通过门控机制来过滤信息,进而提高网络的表达能力和泛化能力。(门控机制有助于长距离建模)。
GLU定义为两个线性变换的分量积,其中一个线性变换由sigmoid激活。GLU是线性变换后面接门控机制的结构。门控机制默认是使用sigmoid激活函数控制信息能够通过多少。通过修改使用其他激活函数 就能得到GLU的各种变体。添加GLU就是在原来激活函数后面多乘 (xV+c)。其中x表示输入。σ 表示 sigmoid 函数。权重矩阵 W 和 V:用于进行线性变换的两个权重矩阵。偏置项 b 和 c:用于调整线性变换的偏置项。
GLU的各种变体:
GLU是线性变换后面接门控机制的结构。门控机制默认是使用sigmoid激活函数控制信息能够通过多少。通过修改使用其他激活函数 就能得到GLU的各种变体。
比如LLama中采用的SwiGLU就是采用Swish激活函数替代sigmoid的GLU变体: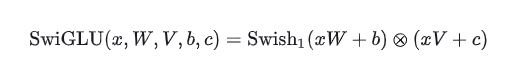
由于GLU机制引入了更多的权重矩阵,通常会对隐藏层进行scaled,从而保证整体的参数量不变。GLU的优点:GLU可以有效地捕获序列中的远程依赖关系,同时避免与lstm和gru等其他门控机制相关的一些梯度消失问题。
【2】GLU针对激活函数的变体
GLU变体是通过在 GLU 的定义中替换激活函数或者引入其他变化来得到的。
例如GLU存在以下的一些变体【带偏置】:
GLU Variants Improve Transformer:https://arxiv.org/pdf/2002.05202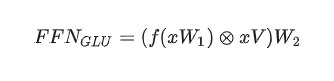
=>使用GeLU激活函数的GLU计算公式为:
=>使用swish激活函数的GLU计算公式为:
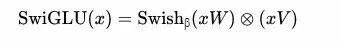
【3】SwishGLU激活函数
SwishGLU提出论文:GLU Variants Improve Transformer
论文地址:https://arxiv.org/pdf/2002.05202.pdf
SwishGLU的实现过程:GLU 的核心思想是通过门控机制来过滤信息,进而提高网络的表达能力和泛化能力。(门控机制有助于长距离建模)。SwishGLU 的核心思想是将 Swish 和 GLU 结合起来,SwishGLU 实际上相对于Swish激活函数只是多乘了个GLU门控单元。 GLU(x)= (xV+c)。SwishGLU = Swish激活函数 · GLU 门控单元。
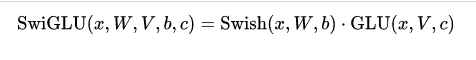
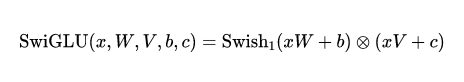
SwishGLU的计算公式:
默认使用sigmoid激活函数的GLU 的定义公式:
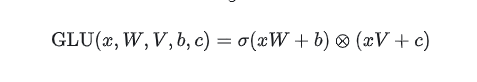
采用Swish激活函数替代sigmoid的GLU变体SwiGLU :
SwishGLU 的优点:
a.SwiGLU能捕获复杂的非线性关系:Swish部分能够捕捉复杂的非线性关系,而GLU部分增强这种能力。
b.SwiGLU具有自适应门控机制:GLU部分实际上是个可学习的门控机制,可以根据输入的不同动态地调整激活强度。这种自适应性使得SwiGLU能够在不同的网络层和不同的训练阶段表现出不同的行为,潜在地增加了网络的表达能力。
c.SwiGLU具有稳定的梯度特性。由于Swish在整个定义域上都有非零梯度,而GLU也具有良好的梯度流动性,SwiGLU在反向传播过程中能够保持稳定的梯度流。这有助于缓解深度网络中的梯度消失问题,使得更深的网络也能够有效训练。
d.表达能力强:结合两种函数的优点,Swish部分提供了一种平滑、非单调的激活,而GLU部分则引入了一种动态的、输入依赖的门控机制,理论上具有更强的函数逼近能力。
SwishGLU 的缺点与限制:a.计算复杂度高:比单一的激活函数(如ReLU或Swish)计算复杂度更高,可能会显著增加训练和推理时间。b.参数增加:GLU部分引入了额外的可学习参数(GLU部分的权重和偏置),增加了模型的复杂度。c.调优难度:可能需要更细致的超参数调整才能发挥最佳性能。d.内存消耗:由于计算过程更复杂,可能会增加内存使用。
SwishGLU 的适用场景:适用于需要强大非线性建模能力的复杂任务。在处理长序列数据的模型中可能会有良好表现,如长文本理解或时间序列预测。
SwishGLU 与其他函数的对比:
vs. ReLU:SwiGLU提供更复杂的非线性变换,理论上具有更强的表达能力。
vs. Swish:SwiGLU通过引入GLU的门控机制,增强了对输入的动态调节能力。
vs. GELU:用在Transformer类模型中,但SwiGLU可能在某些任务上提供更强的非线性建模能力。
vs. Mish:SwiGLU的计算复杂度更高,但在某些大规模模型中可能表现更优异。
SwishGLU的代码实现:
class FeedForward(nn.Module):
def __init__(self, dim: int, hidden_dim: int, multiple_of: int, dropout: float):
super().__init__()
hidden_dim = multiple_of * ((2 * hidden_dim // 3 + multiple_of - 1) // multiple_of)
self.w1 = nn.Linear(dim, hidden_dim)
self.w2 = nn.Linear(hidden_dim, dim)
self.w3 = nn.Linear(dim, hidden_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.dropout(self.w2(F.silu(self.w1(x)) * self.w3(x)))
代码使用的SiLU函数 其实就是 β=1时的swish激活函数,代码可以看到,激活函数中也有3个权重是可以训练的,这就是来自于GLU公式里的参数。
SwiGLU在LLaMA中的实现形式:
SwiGLU本质上是对Transformer的FFN前馈传播层的第一层全连接和ReLU进行了替换。
在原生的FFN中采用两层全连接,第一层升维,第二层降维回归到输入维度,两层之间使用ReLE激活函数,计算流程图如图左(省略LayerNorm模块)
SwiGLU也是全连接配合激活函数的形式,不同的是SwiGLU采用两个权重矩阵和输入分别变换,再配合Swish激活函数做哈达马积的操作,因为FFN本身还有第二层全连接,所以带有SwiGLU激活函数的FFN模块一共有三个权重矩阵,计算流程图如图右。
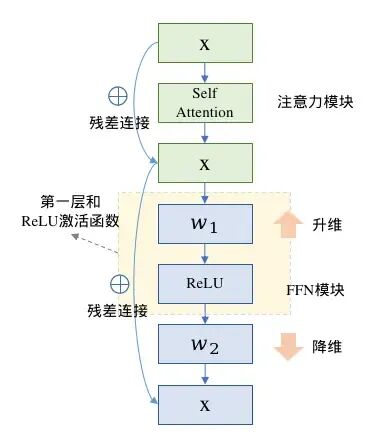
FFN模块计算 | 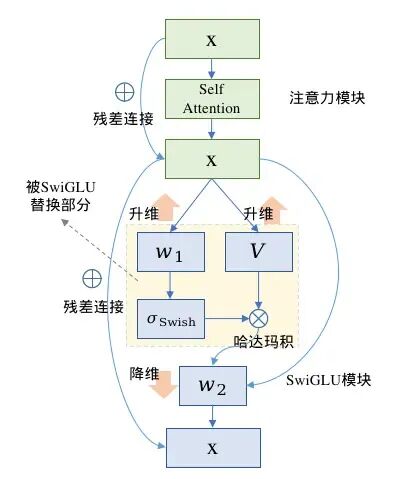
带有SwiGLU的FFN模块计算 |
SwiGLU在LLaMA中的实现代码:
#在HuggingFace LLaMA的源码实现中,在Decoder模块LlamaDecoderLayer中
#的LlamaMLP引入SwiGLU改造了FFN层,实现如下
class LlamaDecoderLayer(nn.Module):
def __init__(self, config: LlamaConfig):
...
# TODO 门控线性单元
self.mlp = LlamaMLP(
hidden_size=self.hidden_size,
intermediate_size=config.intermediate_size, # 11008
hidden_act=config.hidden_act, # silu
)
#LlamaMLP的实现了SwiGLU逻辑,代码和公式完全对应
class LlamaMLP(nn.Module):
def __init__(
self,
hidden_size: int, # 4096
intermediate_size: int, # 11008
hidden_act: str, # silu
):
super().__init__()
self.gate_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
self.down_proj = nn.Linear(intermediate_size, hidden_size, bias=False)
self.up_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
self.act_fn = ACT2FN[hidden_act]
def forward(self, x):
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
#SwiGLU本质上是对Transformer的FFN前馈传播层的第一层全连接和ReLU进行了替换.
#在原生的FFN中采用两层全连接,第一层升维,第二层降维回归到输入维度,两层之间使用ReLE激活函数.
class FeedForward(nn.Module):
def __init__(self, dim: int, hidden_dim: int, multiple_of: int, dropout: float):
super().__init__()
hidden_dim = multiple_of * ((2 * hidden_dim // 3 + multiple_of - 1) // multiple_of)
self.w1 = nn.Linear(dim, hidden_dim)
self.w2 = nn.Linear(hidden_dim, dim)
self.w3 = nn.Linear(dim, hidden_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.dropout(self.w2(F.silu(self.w1(x)) * self.w3(x)))
【推荐阅读】https://www.jianshu.com/p/2354873fe58a
【4】为什么LLM都在使用SwiGKU作为激活函数?
为什么LLM都在使用 SwiGLU 作为激活函数?
论文中只给了测试结果而且并没有说明原因,而是说:We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.其实就是说作者炼丹成功了✅。
2024年可以强行的解释一波:
1、Swish对于负值的响应相对较小克服了 ReLU 某些神经元上输出始终为零的缺点。2、GLU 的门控特性,这意味着它可以根据输入的情况决定哪些信息应该通过、哪些信息应该被过滤。这种机制可以使网络更有效地学习到有用的表示,有助于提高模型的泛化能力。在大语言模型中,这对于处理长序列、长距离依赖的文本特别有用。3、SwiGLU 中的参数 W1,W2,W3,b1,b2,b3W1,W2,W3,b1,b2,b3 可以通过训练学习,使得模型可以根据不同任务和数据集动态调整这些参数,增强了模型的灵活性和适应性。4、计算效率相比某些较复杂的激活函数(如 GELU)更高,同时仍能保持较好的性能。这对于大规模语言模型的训练和推理是很重要的考量因素。选择 SwiGLU 作为大语言模型的激活函数,主要是因为它综合了非线性能力、门控特性、梯度稳定性和可学习参数等方面的优势。在处理语言模型中复杂的语义关系、长依赖问题、以及保持训练稳定性和计算效率方面,SwiGLU 表现出色,因此被广泛采用。论文地址:https://arxiv.org/abs/2002.05202 作者:Aziz Belaweid1.https://mp.weixin.qq.com/s/u372f7UuQ6qOb8HeGO6-Zg
FFN前馈网络层
【1】简要介绍FFN层
Transformer模型通过多头注意力层和FFN层交替工作。FFN层存在于Transformer架构的编码器和解码器部分中。例如,下方的编码器块由多头注意力层和一个FFN层组成。
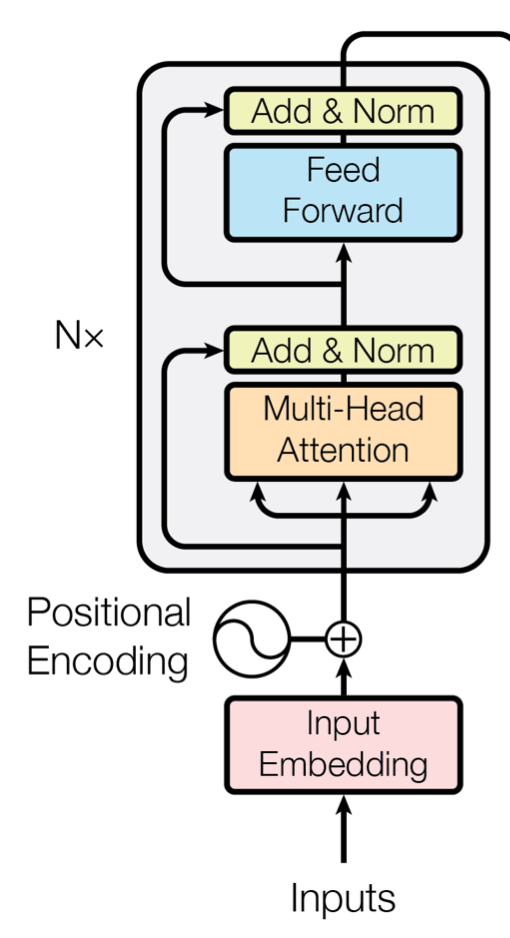 | 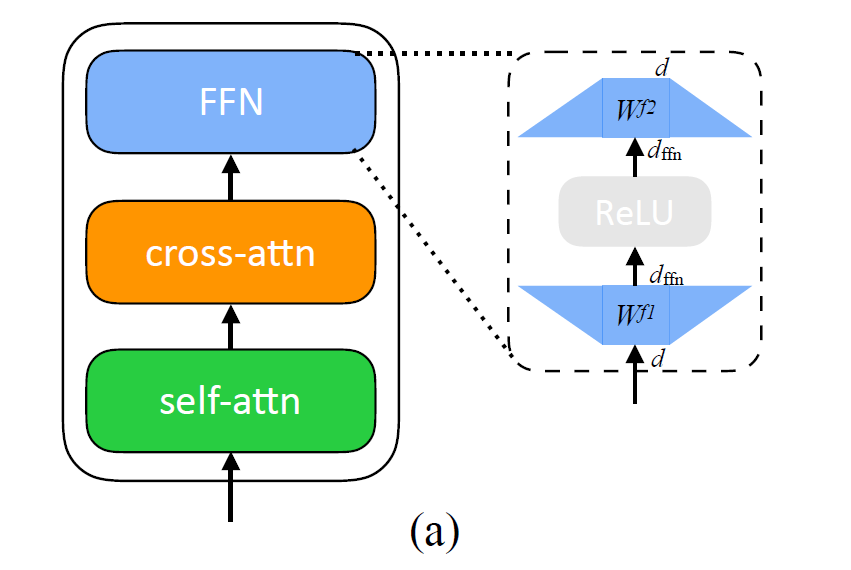
FFN块接受自注意力子层的输出作为输入,并通过一个带有 Relu 激活函数的两层全连接网络对输入进行更加复杂的非线性变换。实验证明,这一非线性变换会对模型最终的性能产生十分 重要的影响。 |
FFN层包括两个线性变换W1和W2,中间插入一个非线性激活函数 f( )。最初的Transformer架构采用了ReLU激活函数。FFN通常先将向量从维度d升维到中间维度4d,再从4d降维到d。
使用ReLU作为激活函数的FFN层(带偏置):
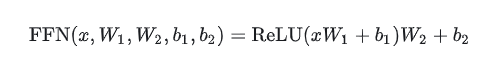
使用ReLU作为激活函数的FFN层(不带偏置)[T5]:
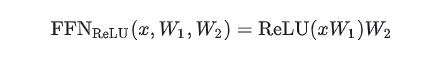
使用GeLU作为激活函数的FFN层(不带偏置):
使用Swish作为激活函数的FFN层(不带偏置):
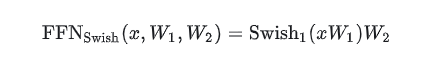
【2】简要介绍FFN的GLU变体
GLU Variants Improve Transformer:https://arxiv.org/pdf/2002.05202
所谓GLU,就是在原来激活函数后面多乘 (xV+c)。所谓FFN,就是在原来的GLU变体 后面乘 权重矩阵W2。
以Swish为激活函数的FNN计算公式:
以SwiGLU为激活函数的FFN计算公式:
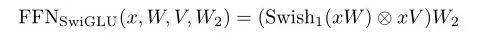
由于这种方式使得FFN中的权重矩阵从2变为了3,为了使得模型的参数大体不变,因此中间层的向量维度需要削减为原始维度的三分之二。
在LLaMA2-7B中,FFN的原始输入维度为4096,一般而言中间层是输入维度的4倍等于16384。
由于SwiGLU的原因FFN从2个矩阵变成3个矩阵,为了使得模型的参数量大体保持不变,中间层维度做了缩减,缩减为原来的2/3即10922,进一步为了使得中间层是256的整数倍,有做了取模再还原的操作,最终中间层维度为11008。
查看hf中的Llama2-7b-hf,与计算是一致的:
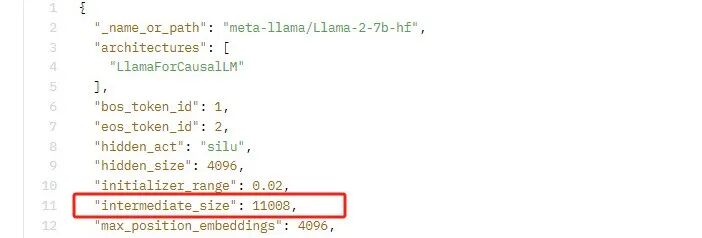
https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/main/config.json



























 粤ICP备17114055号
粤ICP备17114055号