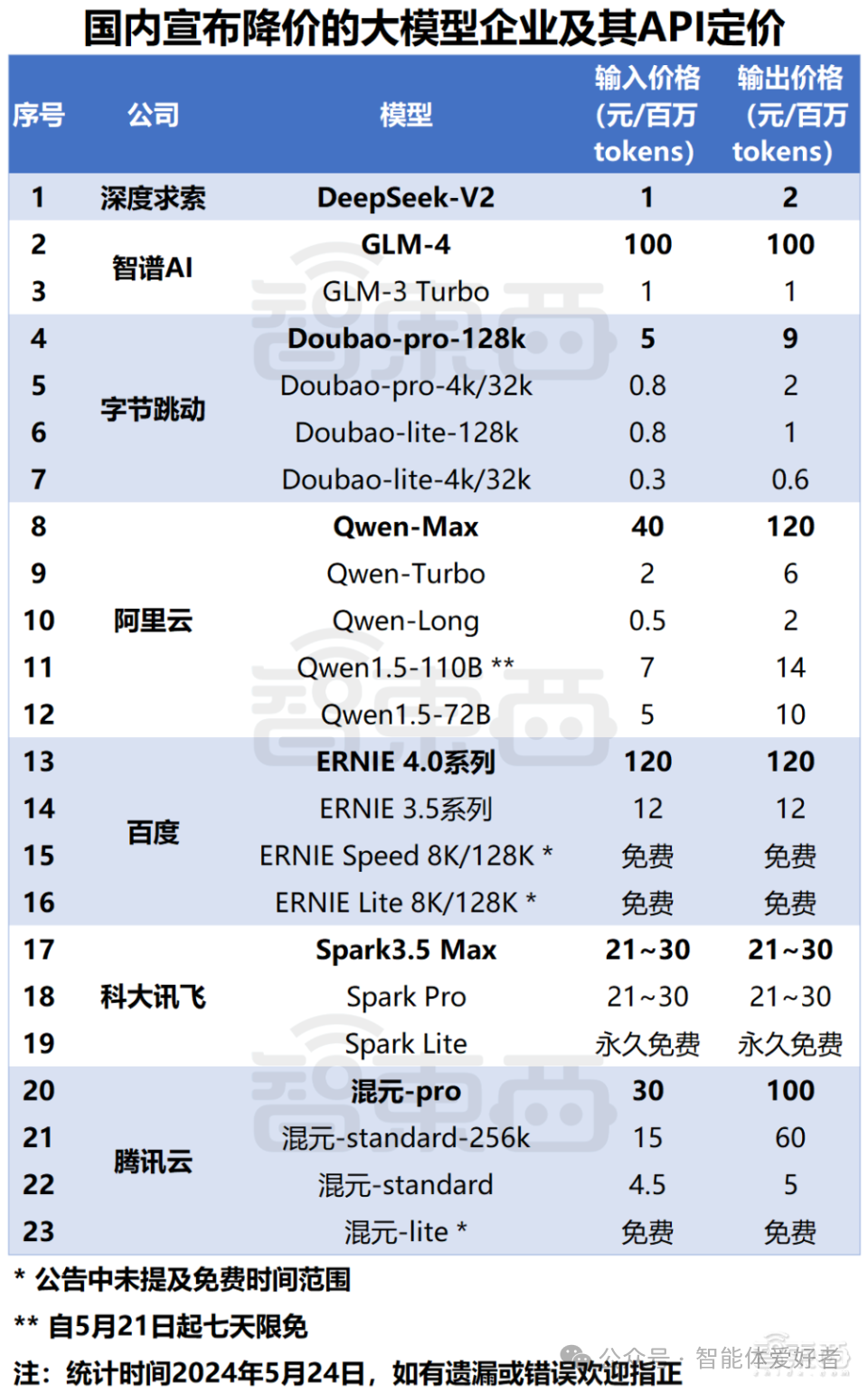
1. 引言
在大模型领域,经常会见到一个词叫作“Token”。比如前段时间国内大模型厂商的价格战,各个大模型都是以Token作为计价单位。
(图片来自网络)
如果你使用过扣子(Coze)之类的智能体平台或调用大模型的API,会发现每次使用大模型处理文本时都会消耗一定数量的Token。比如,下图是扣子一次调试信息中展示的Token消耗量,包括输入Token和输出Token。

那么,Token这个词到底是什么意思呢?
技术背景的人应该知道,Token大致相当于是词语或字符,但为什么大家都不约而同地使用Token这个英文单词,而不使用对应的中文呢?(Token这个词甚至都没有一个对应的中文名称)
2. Token的几种含义
在计算机领域,Token是一个很常见的词汇,但在不同的方向,Token往往代表不同的含义。比如在安全、编译器、区块链等方向都有Token一词,但他们的意义各不相同。下面是计算机不同领域中Token的几种典型含义。计算机安全
在计算机安全领域,Token通常指的是一种安全令牌,用于身份验证和授权。例如,在多因素认证(MFA)中使用的硬件令牌和软件令牌。在Web身份认证时,当用户登录成功,后台通常会生成一个具有时效的字符串作为Token回传给客户端/浏览器,后续客户端/浏览器每次请求都会带上Token,后台只要验证Token即可判断用户登录状态。网络
在网络通信中,Token可以指一种访问控制机制,用于管理对共享资源的访问。例如,令牌环网络中使用的Token传递机制。编译器
在编译器设计中,Token是源代码中最小的有意义元素,称为“符号”,如关键字、运算符、标识符等。词法分析器会将源代码分解成Token,供语法分析器使用。区块链
在区块链行业或币圈,Token通常指的是一种数字资产(代币),可以代表某种权利或价值。例如,比特币和以太坊中的加密货币就是典型的Token。自然语言处理
在自然语言处理(NLP)领域,Token是指文本中的最小单位,可以是单词、子词或字符。Token化(即分词)是将文本分割成Token的过程,这是NLP任务的基础。3. 大模型中的Token
大语言模型和自然语言处理是一脉相承的,所以大模型中的Token与自然语言处理中的Token是一个意思。 在大模型(如GPT-4)中,Token是模型处理和理解文本的基本单位。模型通过将用户输入文本分割成Token,然后在这些Token的基础上进行计算和推理,并产生输出Token,最后将输出Token转换为用户可理解的文本。如下图所示: 在大模型内部,每个Token都对应一个向量表示,大模型通过这些向量进行语言理解和生成,通过使用Token(向量),大模型能够更高效地进行计算和推理。从上图可以看出,Token与文本(自然语言)之间是可以通过Tokenizer(分词器)进行相互转换的。 以上对大模型中Token的描述,仍然比较抽象。接下来,我们通过具体的例子看看Token到底长什么样。 对于英文来讲,通过GPT自带的Tokenizer可以直观地看到英文句子转换成的Token序列。如下图所示,这句话包含224个字符,被转换成49个Token。同时,还可以发现,Token并不是严格按照英文单词粒度进行划分的,如:tokenization被分成了token和ization两个Token,Newer被分成了New和er两个Token。此外,单词前面的空格与单词一起被划分为一个Token。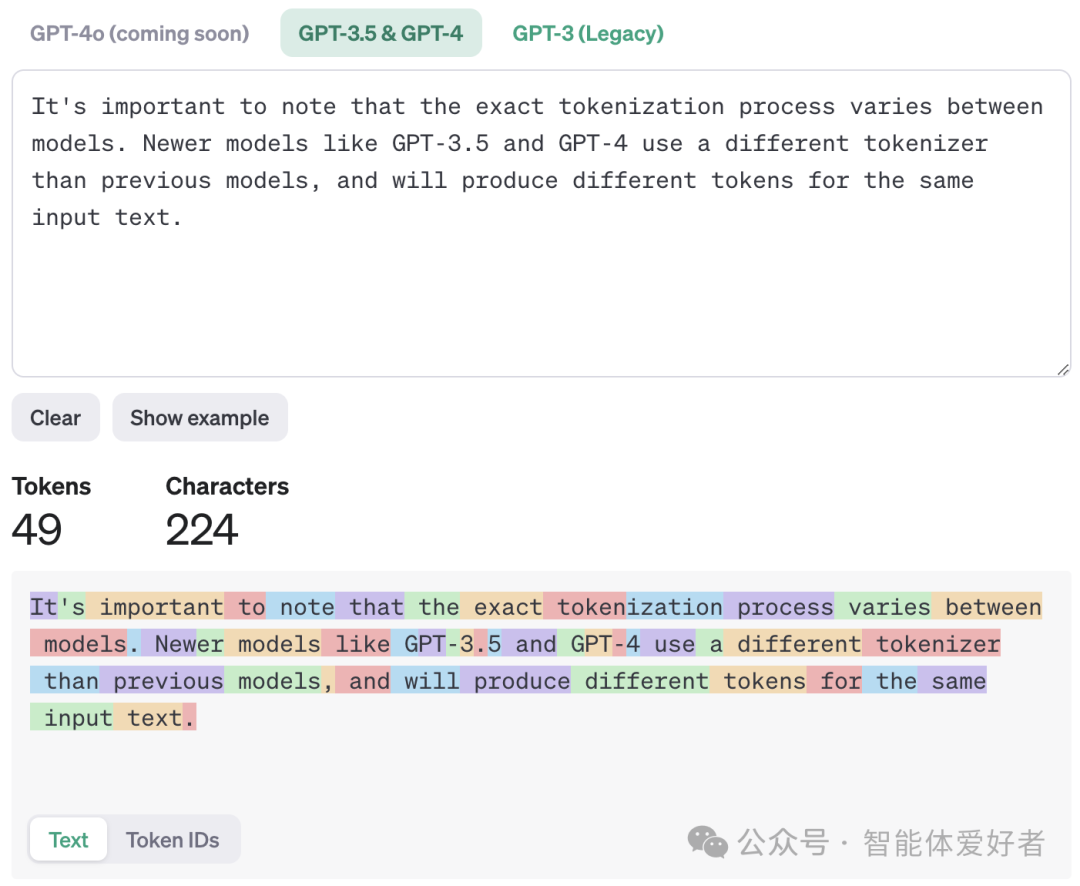
上图显示结果是文本表示的Token,大模型并不是直接处理文本形式的Token的,每个Token都有一个唯一ID,大模型在推理计算时,会基于Token的唯一ID进行一系列转换。通过切换Text/Token IDs标签,可以看到Token文本和ID的映射关系,如:示例中第一个Token:It的ID是2181。 中文Token和英文是类似的,下图通过通义千问的Token计算器展示了中文句子Token化的结果以及Token文本和ID的对应关系。从结果也可以看出,中文Token和我们常用的汉语词语并不完全一致,比如“大模型”这个词被分成了“大”和“模型”两个Token,而“的基础”并非一个汉语词语,却被分为一个Token。
还有一点需要说明的是,由于各个大模型使用的分词器(Tokenizer)不同,所以同样一句话,在不同的大模型中Token化的结果可能是不一样的。如上图中这句话,在通义千问中被分出60个Token,而在文心一言中被分成了50个Token。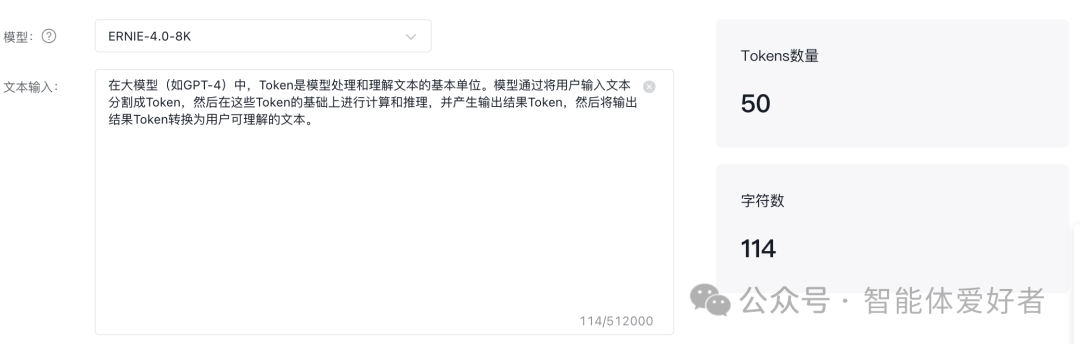
由此可见,大模型中的Token与我们所熟知的字符或词语是不同的。它是分词器(Tokenizer)根据一定算法将文本切割为一个个的小片段,可能是一个字符/符号、一个词语、或是半个词,甚至是一个由经常同时出现的字符/词语构成的序列。根据OpenAI的文档,一个Token大致相当于4个英文字符。根据腾讯混元文档说明,一个Token大概相当于1.8个汉字或3个英文字母。4. Token化过程
Token化是将文本分割成Token的过程,中文称为“分词”,这个过程对于大模型理解和处理自然语言至关重要。不同的Token化方法会根据具体应用和需求选择不同的策略。常见的Token化方法包括:- 按单词分割:将文本按空格分割成单词。优点是易于理解,但在处理未登录词(out-of-vocabulary)时会有问题。
- 按字符分割:将文本按字符分割。优点是处理灵活,但会生成大量Token,增加计算负担。
- 按子词分割:将文本分割成更小的子词单元,平衡了词级和字符级的优缺点。常用的子词分割算法有:Byte Pair Encoding(BPE) 、WordPiece、SentencePiece、Unigram。
Token化过程是由Tokenizer(分词器)来完成的。从前面介绍可知,Tokenizer一般包括两个操作:一是将自然语言文本转换为Token(ID)序列作为大模型的输入,而是将模型输出的Token(ID)序列转换为自然语言。 有很多开源的Tokenizer项目,如GPT使用的Tokenizer,OpenAI将其开源为tiktoken项目,地址是:https://github.com/openai/tiktoken,它使用的是BPE算法。5. Token消耗计算方式
输入Token
当模型接收输入文本时,会将文本分割成Token。输入Token的数量取决于文本的长度和所用的Tokenizier。例如,输入句子“Hello, how are you?”可能会被分割成6个Token(“Hello”, “,”, “how”, “are”, “you”, “?”)。输出Token
模型在生成响应时也会消耗Token。生成的每个单词或符号都会作为一个Token被计数。例如,模型生成“I'm fine, thank you.”,可能会被分割成7个Token(“I”, “‘m”, “fine”, “,”, “thank”, “you”, “.”)。总Token消耗
总Token消耗量等于输入Token和输出Token的总和。假设输入文本分割成6个Token,模型生成的响应也分割成7个Token,那么这次调用的总Token消耗量为13个Token。 大模型在计算Token消耗时,通常是计算输入Token+输出Token的总和。在具体计算Token开销时,需要参考各家大模型厂商的计费文档。 为什么要计算输入跟输出Token的总和呢?
这是因为生成式大模型的工作方式是根据上下文预测下一个Token,首先根据用户输入序列预测出第一个输出Token,然后将第一个Token追加到输入序列预测出第二个输出Token,依此类推。因此,除了输入Token,每个输出Token也都会参与推理计算(可能最后一个除外)。 了解Token消耗计算方式有助于用户优化输入文本和模型响应,减少不必要的Token消耗,从而降低使用成本。6. Token与上下文窗口
上下文窗口指的是模型在处理文本时能够看到的最大Token数量。这个窗口决定了大模型在一次推理中能处理多长的文本。例如:Doubao-pro-128K表示模型在推理时最大能够支持128000个Token的上下文。 较大的上下文窗口能够捕捉更多的信息,但也会增加计算复杂度。在处理长文本时,Token长度与上下文窗口的选择至关重要。过长的Token序列可能会超出上下文窗口的限制,需要采用滑动窗口(Sliding Window)或截断(Truncation)策略来处理。 在聊天应用中,上下文窗口不仅包括当前对话的输入和输出,还包括之前的对话历史。如果聊天的对话比较长,可能会超出大模型上下文窗口限制,这样会导致较早的对话内容被丢弃,模型可能会出现答非所问的情况。遇到这种情况,我们需要重复最初的问题,或者新开一个对话。7. 结论
Token是大模型中不可或缺的基础单位。通过Token化,文本能够被大模型理解和处理,从而执行各种推理任务。了解Token的不同含义及其在大模型中的作用,有助于更好地使用大模型,节约成本,提高效率。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
