
摘要
在运行大规模机器学习(ML)基础设施时,可靠性是一个关键挑战,尤其随着ML模型和训练集群规模的不断扩大,这一问题愈发突出。尽管已有数十年的基础设施故障研究,但不同规模下作业失败的影响仍不明确。本文分享了管理两个大型多租户ML集群的经验,提供了量化分析、运营经验以及我们在理解和解决大规模可靠性问题方面的视角。我们的分析显示,尽管大型作业最容易受到故障影响,但小型作业在集群中占多数,因此应被纳入优化目标中。我们还识别了关键的工作负载特性,并在不同集群中进行比较,展示了大规模ML训练所需的核心可靠性要求。我们提出了一套故障分类体系及关键可靠性指标,分析了两个最先进ML环境中11个月的运行数据,这些环境总共涵盖了超过1.5亿小时的A100 GPU使用时间和400万个作业。基于这些数据,我们构建了故障模型,预测了不同GPU规模下的平均故障间隔时间(MTTF)。
此外,我们还提出了一种方法来估算相关指标——有效训练时间比率,并用该模型来评估在大规模环境下潜在的软件缓解措施的效果。我们的研究为提升AI超级计算集群的可靠性提供了宝贵的洞见,并指明了未来的研究方向,强调了灵活、与工作负载无关且具备可靠性意识的基础设施、系统软件和算法的必要性。我们的分析依据两个研究集群的数据,时间跨度达11个月,且建立在先前探讨的Slurm调度器术语及节点级健康检查基础之上。需注意的是,本节涉及的集群存在过度配置现象,因此项目级的服务质量(QoS)和分配策略成为决定作业运行的关键要素。调度器作业状态分类:取消(CANCELLED)、完成(COMPLETED)、内存不足终止(OUT_OF_MEMORY)、失败(FAILED,即应用程序返回非零退出代码)、节点故障失败(NODE_FAIL)、被高优先级作业抢占(PREEMPTED)、重新排队(REQUEUED)或超时(TIMEOUT)。图3详细展示了RSC-1集群的作业状态分布:60%的作业顺利完成,24%和0.1%的作业分别因FAILED和NODE_FAIL状态而失败,10%的作业被抢占,2%的作业重新排队,0.1%的作业因内存不足而终止,另有0.6%的作业超时。观察基础设施相关的故障(图3中标记为HW),我们发现这类故障仅影响了0.2%的作业,但令人瞩目的是,它们却占据了18.7%的运行时间。考虑到大型作业易受基础设施故障影响,尽管这类作业数量不多,却占用了大量运行资源,因此这一结果并不意外(详见图6后续讨论)。观察4:得益于健康检查机制,硬件故障成为罕见事件。硬件故障影响了19%的GPU运行时间和不到1%的作业。然而,当考虑检查点机制(checkpointing)时,这种影响会显著降低,因为检查点机制有效限制了工作量的丢失。作业故障特征分析:作业故障可按归因原因进行细分,这些原因可进一步根据服务器级组件(如GPU、网络)和各种系统组件(如文件系统)来划分。我们在图4中展示了RSC-1和RSC-2的GPU小时标准化故障率。如果故障原因在作业失败(FAILED或NODE_FAIL)后的最后10分钟或5分钟内被检测到,我们即将其归因于该原因。
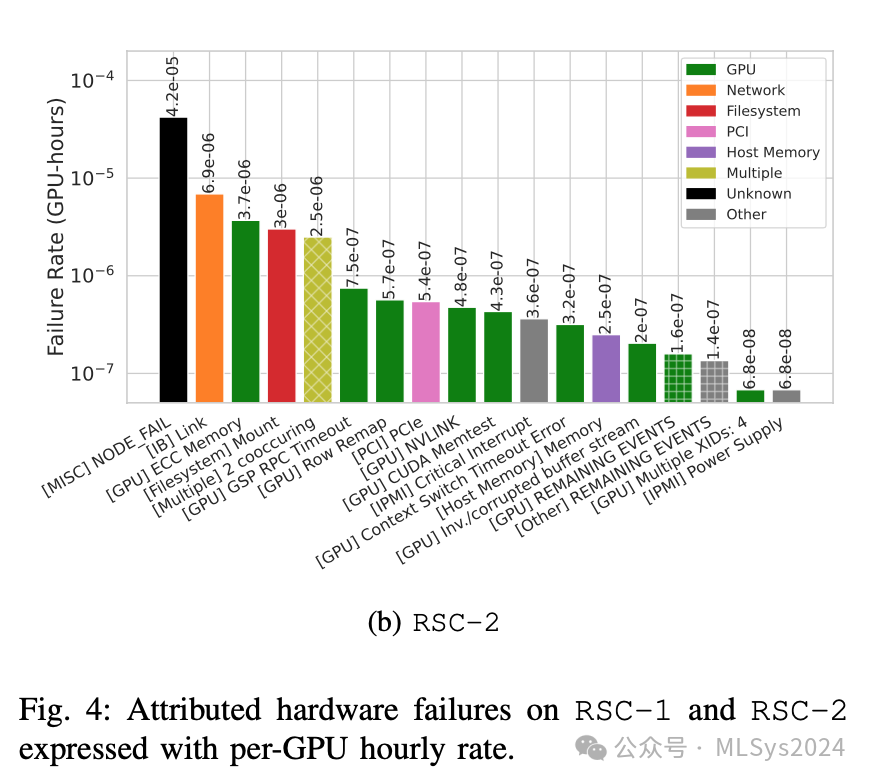
请注意,我们根据开发的启发式方法报告了最可能的故障原因,该方法可指示是否应将节点隔离以进行修复。部分故障存在多重归因(见图4)。一些NODE_FAIL事件与任何健康检查均无关(参见[30]),这可能是因为节点本身无响应。IB链路、文件系统挂载、GPU内存错误和PCIe错误对故障率贡献较大,但特别是IB链路,如图5所示,其故障似乎主要集中在2024年夏季,由少数节点引发的许多IB链路相关作业故障在短时间内爆发。GSP超时是由代码回归引起的,已通过驱动程序补丁修复(见图5)。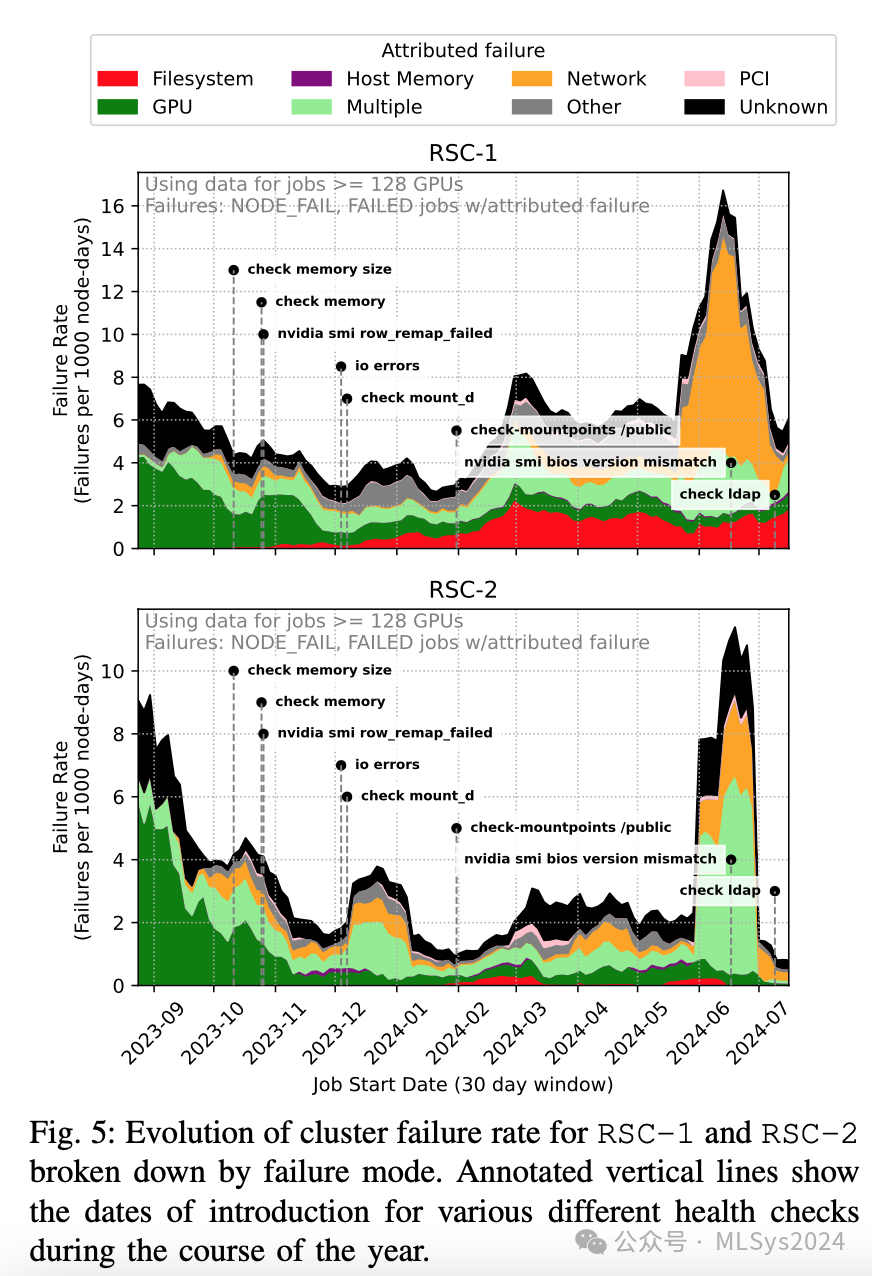
故障可能同时发生——在RSC-1/RSC-2上,分别有3%和5%的硬件故障伴有相同优先级的并发事件。例如,我们观察到PCIe错误常与XID 79(GPU从总线上脱落)和IPMI“关键中断”事件同时发生。在RSC-1(和RSC-2)上,我们观察到43%(63%)的PCI错误与XID 79同时发生,21%(49%)同时包含这三种事件类型。这是预料之中的,因为这些检查都与PCIe和总线健康有关。我们的数据似乎也与十年前关于行重映射、ECC错误和从总线上脱落的研究[40]相吻合,尤其是考虑到PCIe错误与XID 79高度相关。我们还观察到,2%(和6%)的IB链路故障与GPU故障(如从总线上脱落)同时发生,这可能表明与PCIe存在相关性。观察5:许多硬件故障未归因于具体原因,而最常见的归因故障涉及后端网络、文件系统和GPU。GPU由于具有细粒度的XID,显示出丰富的错误类别,尽管顶级错误代码与内存相关。PCIe总线错误和GPU从总线上脱落也很常见,且存在相关性。CPU内存和主机服务对应用程序的影响较小。故障率随时间演变:我们现在将分析转向更大规模的作业,因此转向节点级(而非GPU级)分析。在图5中,我们展示了RSC-1在过去一年(显示30天滚动平均值)的故障率情况,说明:- 故障率不断变化:我们观察到,RSC-1的故障率有时约为每节点天2.5次,有时则高达每节点天约17.5次(高出一个数量级)。
- 故障模式此起彼伏。2023年底,RSC-1上作业失败的主要原因是驱动程序错误导致的XID错误;该问题已解决。2023年春季,在添加了一项针对导致节点宕机的挂载的新健康检查后,这成为RSC-1上的主要故障模式。2024年初夏,少数违规节点上的IB链路故障激增,暂时推高了两个集群的故障率。
- 新的健康检查揭示了新的故障模式。我们标记了在集群中添加新健康检查的时间。通常,在收到关于先前未检查的故障模式的传闻报告后,会添加新的健康检查,这往往会导致故障率出现明显的上升,因为我们突然能够观察到之前可能已存在的故障模式。
观察6:集群故障是动态的,降低集群故障率是一场持续的战斗。新工作负载和软件更新意味着集群在不断变化。训练任务多样性:我们拥有各种规模和总GPU小时数不同的训练任务。调度器必须考虑任务规模的多样性及其对应的训练时间,以在训练时间性能、单个训练任务的公平性和整体集群利用率之间取得平衡。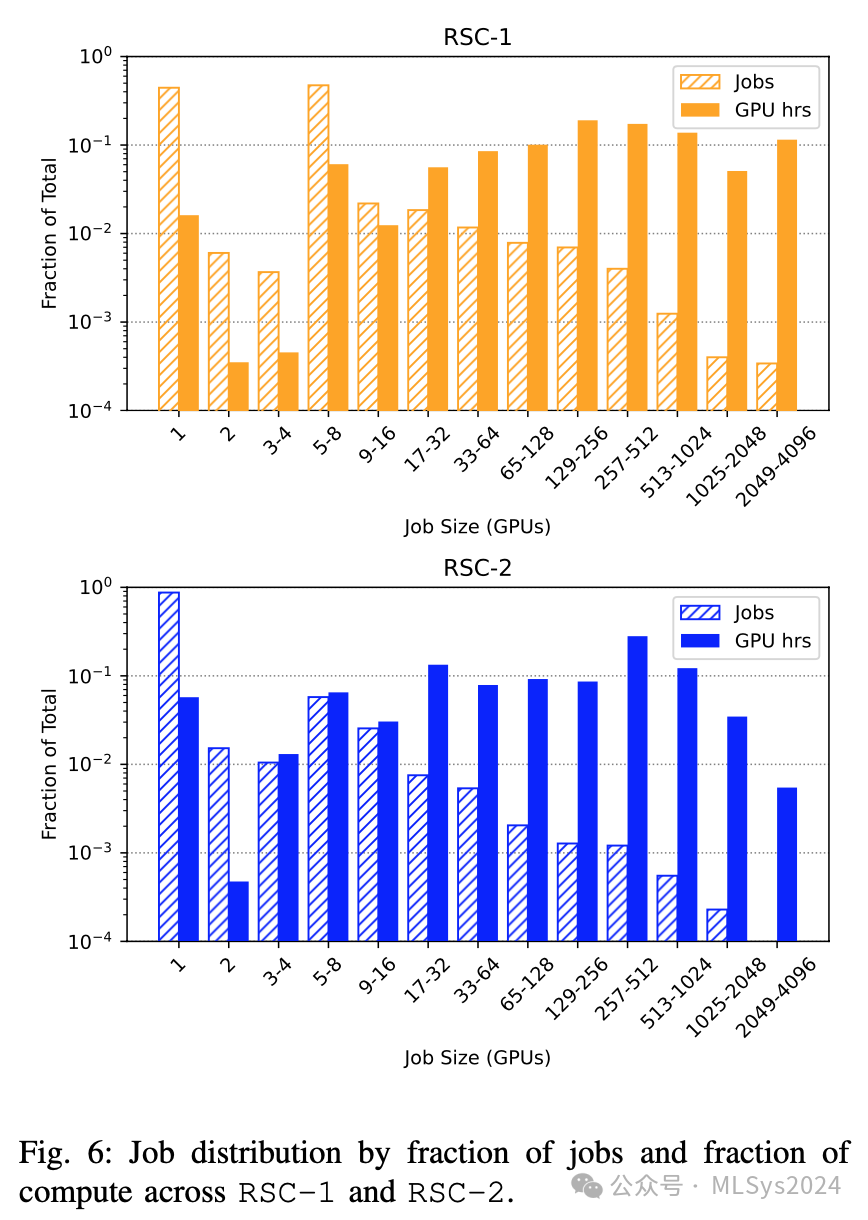
图6展示了RSC-1集群的任务规模分布。超过40%的训练任务使用单个GPU进行开发或模型评估。在研究集群中,只有少数大规模训练任务会利用到上千个GPU。在同一图中,我们还展示了将GPU时间归一化为单个GPU训练任务后的对应情况。尽管存在许多单个GPU的训练任务,但在RSC-1和RSC-2集群中,分别有超过66%和52%的总GPU时间来自256个及以上GPU的任务。与LLaMa 3.0的生产模型训练相比,研究集群中训练任务规模的多样性和相应的训练时间给有效ML调度器的设计带来了独特挑战。
观察7:超过90%的任务规模小于1台服务器,但这些任务所占用的GPU时间却不到10%。与RSC-2相比,RSC-1倾向于有更多8个GPU的任务,而RSC-2则倾向于有更多单个GPU的任务。RSC-1往往拥有规模最大的任务。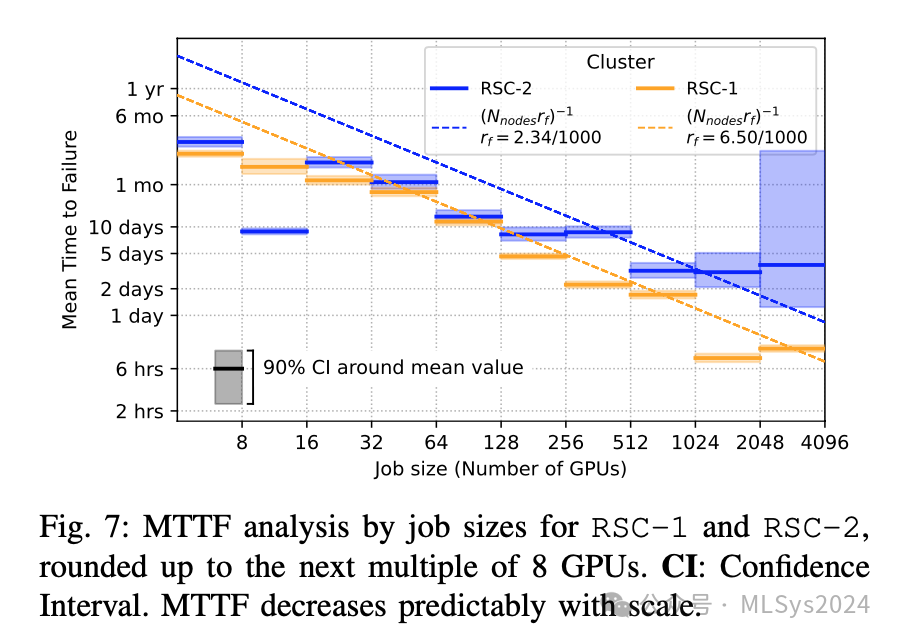
MTTF随规模增加而降低:图7显示,1024个GPU的任务的平均无故障时间(MTTF)为7.9小时,比8个GPU的任务(47.7天)低了大约两个数量级。如第II-E节所示,训练失败源于多种因素,包括用户程序、系统软件以及硬件故障。从经验上看,硬件可靠性与GPU数量成反比下降,从32个GPU开始呈现出更一致的趋势。图中所示90%置信区间是通过拟合Gamma分布得出的。图7还显示,根据集群节点故障率推导出的理论预期MTTF(MTTF ∝ 1/Ngpus):MTTF = (Nnodesrf)−1(其中rf是通过所有大于128个GPU的任务的失败总数和节点运行天数计算得出的)与较大任务(>32个GPU)的观测MTTF值非常吻合。基于我们在大规模真实研究集群中运行的训练任务中观察到的失败概率,我们预测16384个GPU的任务的MTTF为1.8小时,而131072个GPU的任务的MTTF为0.23小时。为了在发生故障时最大化故障恢复时间(ETTR)(第II-D节),我们必须加快故障检测和恢复的过程。更进一步地说,使大型模型训练具备容错能力对于提高训练效率至关重要。请注意,对于较小的任务,我们观察到的MTTF值较难预测,这主要是由于实验使用模式导致的NODE_FAIL相关性。观察8:虽然故障不会直接影响大多数任务,但大型任务会受到显著影响,其故障率与理论趋势相符。在4000个GPU的规模下,MTTF约为10小时,预计随着RSC-1集群规模的扩大,MTTF会进一步降低。RSC-1的MTTF预测值与4到512台服务器的经验MTTF值非常接近。对于RSC-2,预测趋势相似,但16个GPU的经验MTTF数据波动较大,部分原因是相关任务组导致多次NODE_FAIL,总体而言,其可靠性略高于RSC-1的预测趋势。这种差异的部分原因可能是不同的工作负载触发了不同的故障原因,如图4中的文件系统挂载所示。
抢占与故障连锁反应:作业失败的二阶效应是对其他优先级较低且规模可能较小的作业产生影响,从而引发连锁反应。在实际操作中,大型作业往往优先级更高,而小型作业优先级最低。由于高优先级,大型作业会通过抢占低优先级作业的方式迅速被调度。当因硬件不稳定导致高优先级的大型作业失败时,Slurm会配置重新调度该作业,过程中可能会抢占数百个作业。这种情况最坏的结果是崩溃循环,即单个作业在失败时被配置为重新排队(例如,通过在提交脚本中使用异常处理)。在我们观察的期间,我们看到一个1024 GPU的作业遭遇NODE_FAIL并随后重新排队35次,导致总共548次抢占(涉及超过7000个GPU)。此类情况应予以避免,因为它们会导致集群中的过度变动,从而损失有效吞吐量。
在考虑作业失败时,抢占是二阶效应。在我们的集群中,为确保即使优先级最低的作业也能取得进展,抢占只能在作业运行两小时后发生。然而,如果没有精确的检查点机制,作业抢占时会丢失部分工作。关键的是,大型作业1) 预期会丢失大量工作,2) 失败频率更高(见图7),导致有效吞吐量成本随作业规模呈二次方增长。为估算包括因重新调度失败作业而发生的抢占在内的各种有效吞吐量损失源对集群整体有效吞吐量的影响,我们假设所有作业每小时进行一次检查点,平均丢失半小时的工作。
利用Slurm日志,我们确定了哪些作业1) 遭遇了NODE_FAIL(集群相关问题)或我们归因于硬件问题的FAILED状态,2) 因触发NODE_FAIL或FAILED作业而被抢占(PREEMPTED状态),并估算了损失的有效吞吐量(作业运行时间与30分钟的较小值乘以分配给该作业的GPU数量)。
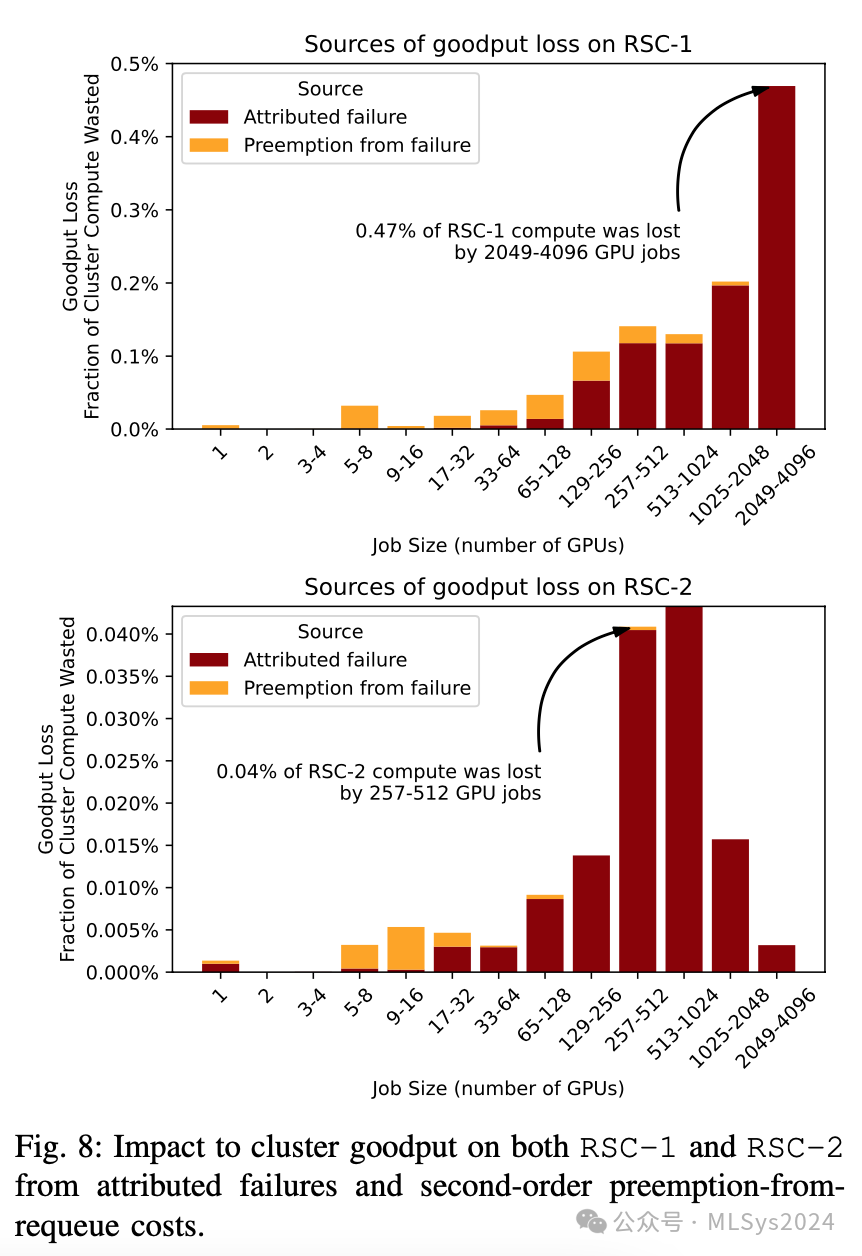
图8显示,正如预期,在RSC-1上,因故障和二阶抢占(就浪费的运行时间而言,忽略对资源碎片化的可能重大影响)而损失的大部分有效吞吐量(y轴)是由2000至4000个GPU规模的大型作业(x轴)导致的。在RSC-2上,由于作业构成不同(见图6),中等规模作业在有效吞吐量损失中占比较高。RSC-2的绝对有效吞吐量损失也比RSC-1小一个数量级,这是作业构成和故障率差异的结果。虽然优化大型作业显然很重要,但由硬件故障导致的总有效吞吐量损失中有16%源于二阶抢占,这些抢占来自规模远小的作业。这些结果表明,集群的整体影响超出了故障本身。
观察9:大型高优先级作业在失败时会强制调度器变动。虽然1000+ GPU作业失败的一阶效应很高,但总故障开销中有16%来自对其他作业的抢占。因此,增加作业多样性为优化提供了额外的途径。
大规模量化ETTR:ETTR提供了一个可解释的指标,用以量化中断、排队时间和开销对训练进度的影响程度。了解ETTR如何随作业配置、调度和故障统计相关的各种数量变化而变化,有助于我们了解各项改进所带来的影响规模。在本节中,我们提供了两项内容:1)基于训练作业参数、作业优先级和集群资源可用性作为输入,对ETTR的期望值公式进行制定;2)使用作业级数据对RSC-1和RSC-2集群的ETTR进行估算的设计空间探索研究。对于第一项内容,我们的公式通过假设检查点频率和重启开销,使我们能够对特定作业的可靠性属性进行建模。请注意,预期ETTR(E[ETTR])对于较长的训练运行最为有用——根据大数定律,较长的训练运行所观察到的ETTR值往往更接近这一预期。使用我们针对预期ETTR的分析公式,有助于我们快速估算和理解优化的影响,例如,故障率减半会带来什么影响?对于第二项内容,我们继续使用先前的参数作为工具,探索不同因素对作业开销的相对重要性——即探索下一代超大型GPU训练运行(使用O(10^5)个GPU)实现合理ETTR(约0.90)的必要条件。分析近似E[ETTR]:首先,定义Q为作业符合调度条件但仍在作业队列中等待的时间,R为有效运行时间,U为非有效运行时间。自作业首次符合调度条件起至其完成所需的总时间,即墙钟时间W = Q + R + U。我们将检查点之间的间隔视为∆tcp,执行初始化任务(如加载检查点等)所需的时间为u0,提交后和每次中断后的预期排队时间为q(我们假设排队时间是独立同分布的,且中断后不会系统性缩短)。作业消耗的节点数为Nnodes,集群故障率rf为每节点天运行时间的预期故障数。该作业的平均无故障时间(MTTF)为(Nnodes*rf)^−1。
对于RSC集群,rf ≈ 5 × 10−1 ≳ 0.1天。与用于计算所涉及的各种期望值的蒙特卡洛方法相比,即使对于大型、长期运行的假设作业(例如,8000个GPU),我们发现上述近似值的准确度也在±5%以内。与实际作业运行的比较:我们将上述ETTR的期望值公式与在两个集群上观察到的实际作业运行情况进行比较。作业运行是指属于同一训练任务的一系列作业(其中一些可能具有不同的作业ID)。我们假设∆tcp为60分钟,u0为5分钟。我们重点关注总训练时间至少为24小时且以最高优先级运行的作业,以了解我们最高优先级作业的ETTR。请注意,在计算作业运行的ETTR时,我们此处不考虑健康检查;我们假设作业运行中的每个作业都会因基础设施故障而中断,无论是否检测到,这意味着我们对ETTR的数据估算应该是偏低的。为了获得计算E[ETTR]所需的集群级故障率rf,我们计算了所有使用超过128个GPU且被赋予NODE_FAIL状态的作业(不仅仅是作业运行),以及我们可以归因于作业最后10分钟(或完成后5分钟)内触发关键健康检查的状态为FAILED的作业的数量。然后,我们将故障数除以节点天运行时间数(运行天数之和乘以分配的节点数)。我们发现,RSC-1的rf为每千节点天6.50次故障,而RSC-2的rf显著较低,为每千节点天2.34次故障。这一发现也通过查看集群中GPU的更换速率得到了证实——我们发现RSC-1的GPU更换速率约为RSC-2的3倍;GPU更换速率和故障率差异可能是由于RSC-1上的GPU工作负载更重所致。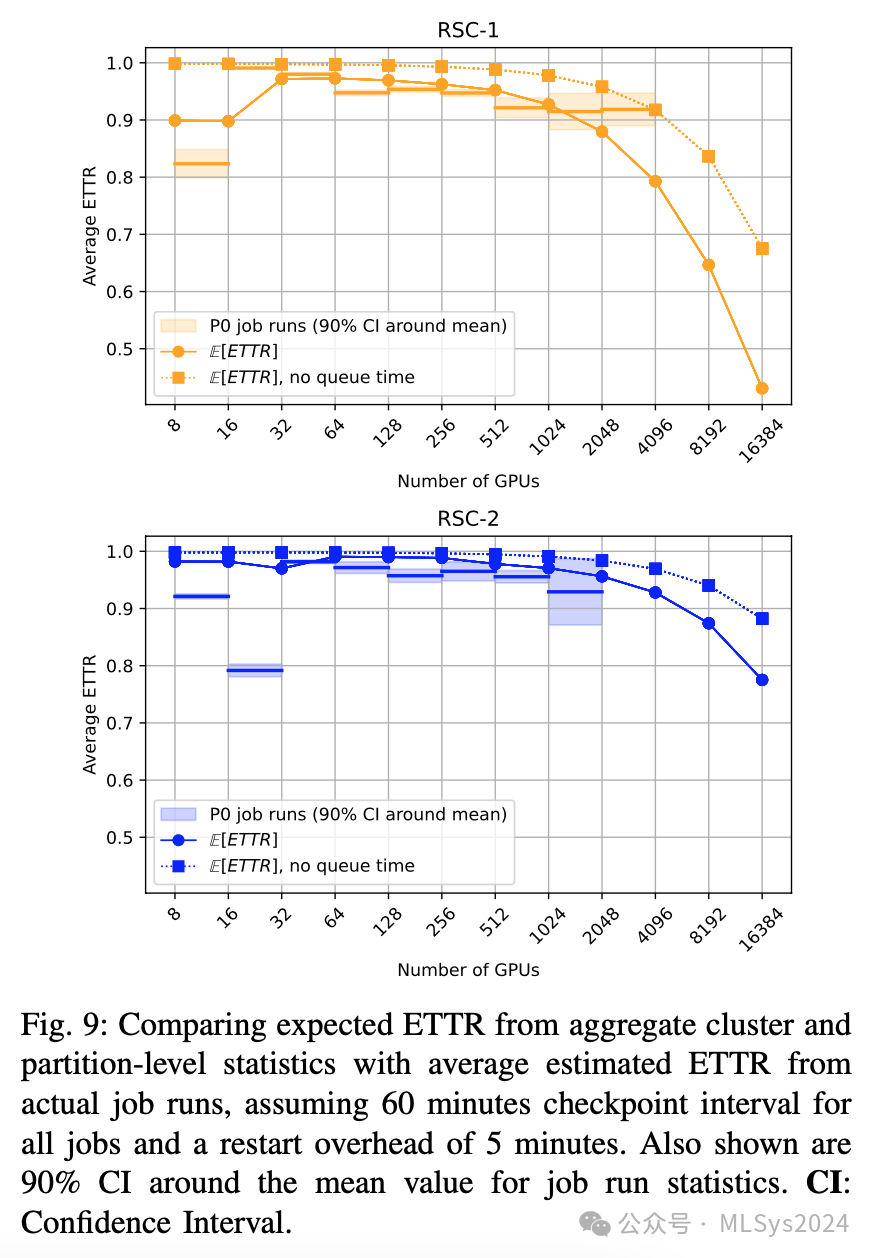
ETTR结果分析:图9展示了我们的发现。除了小型作业运行(<64个GPU)外,E[ETTR](预期平均无故障时间恢复率)与实测作业运行平均ETTR相当吻合。在RSC-1上,大型作业运行(>1024个GPU)的实际ETTR(>0.9)系统地高于E[ETTR]的预测值,这是因为这些大型作业运行的实际等待时间比平均时间更短。
假设RSC-1集群专门用于一个占用整个集群的16,000个GPU的训练任务,如果检查点间隔为60分钟,则预期ETTR为0.7。将检查点间隔缩短至5分钟,预期ETTR将提升至0.93,这说明了频繁设置检查点以抵御中断的价值(假设检查点写入是非阻塞的)。展望未来:对于未来在其他集群上运行的需要O(10^5)个GPU的作业,如果失败率与RSC-1类似(每千节点天6.50次失败),则平均无故障时间(MTTF)约为15分钟。这意味着一小时的检查点间隔是不可行的。图10展示了失败率与检查点间隔之间的权衡,例如,对于RSC-1类似的失败率,要实现E[ETTR]=0.5,检查点间隔需要约为7分钟;如果失败率接近RSC-2,则检查点间隔需要增加到约21分钟。要在RSC-2的失败率下达到0.9的ETTR,需要检查点间隔和重启开销均约为2分钟。观察10:RSC集群在处理其最大且优先级最高的作业时效率极高(ETTR>0.9)。在RSC-1上,为期一天以上的2048-4096个GPU的作业运行,在假设检查点间隔为一小时的情况下,平均ETTR超过0.9,尽管这两个集群都拥挤不堪,且即使是最低优先级的作业也有至少两小时的抢占等待时间要求。为了在RSC-1上实现最大可行的训练运行(8000个GPU,占RSC-1的一半)的0.9 ETTR,如果每次故障后的排队时间为1分钟,则检查点间隔需要为30分钟。要在假设的具有RSC-2类似失败率的集群上实现100,000个GPU训练运行的0.9 ETTR,检查点间隔和重启开销需要约为2分钟。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
