导读 生成式 AI 的应用与大模型的开发是一个复杂的过程,涉及从模型选择、微调到部署和监控的全生命周期管理。通过精细化的角色划分,提供者负责构建基础大模型,调优者进行行业定制化优化,消费者则在此基础上应用模型解决实际问题。技术上,检索增强生成(RAG)和高效微调(如 PEFT)等方法有助于提升模型的准确性和适应性。亚马逊云科技的生成式 AI 服务通过简化的 API 接口,支持用户快速调用和定制大模型,提供持续优化和监控功能,确保模型在实际应用中的稳定性和效果。整个流程需要严格的评估、反馈和优化,才能推动生成式 AI 在各行业中的有效落地和持续改进。
本次分享的主要内容包括:
1. 生成式 AI 用例
分享嘉宾|王宇博 亚马逊云科技 开发者关系负责人,首席布道师
编辑整理|陈思永
内容校对|李瑶
出品社区|DataFun
生成式 AI 用例
生成式 AI 能够不断向前推进,是因为其可以获得实际的落地应用。让我们从一个简单的例子开始探讨生成式 AI 的应用。1. 生成式 AI 用例:电子邮件摘要生成器
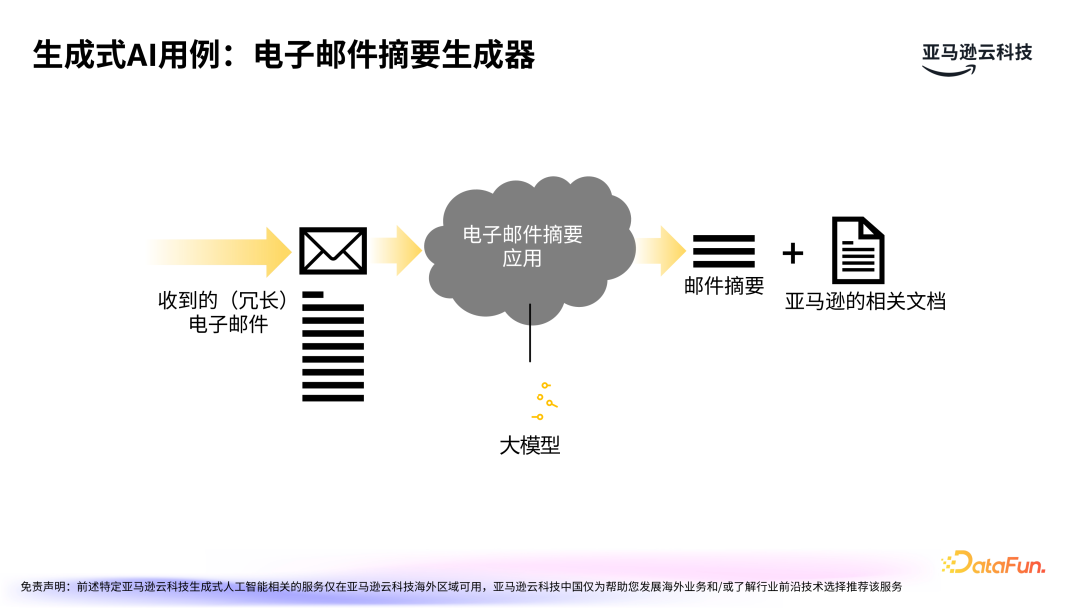
在工作中,我们会收到大量的电子邮件,尤其是涉及长时间跨度的原始邮件及回复,我们希望能够从中快速获取关键信息,以便于进一步判断和采取行动,这时电子邮件摘要生成器就可以发挥作用。通过大模型技术,可以快速生成邮件摘要,帮助用户有效获取信息。同时,针对邮件中的技术细节和最佳实践等信息,可以快速提取相关文档,以利于优化后续工作。除此以外,很多在线应用都增添了类似功能,例如商品评论摘要等等,都是利用大模型自动提炼出关键信息。2. 从小处着手,从大处着想
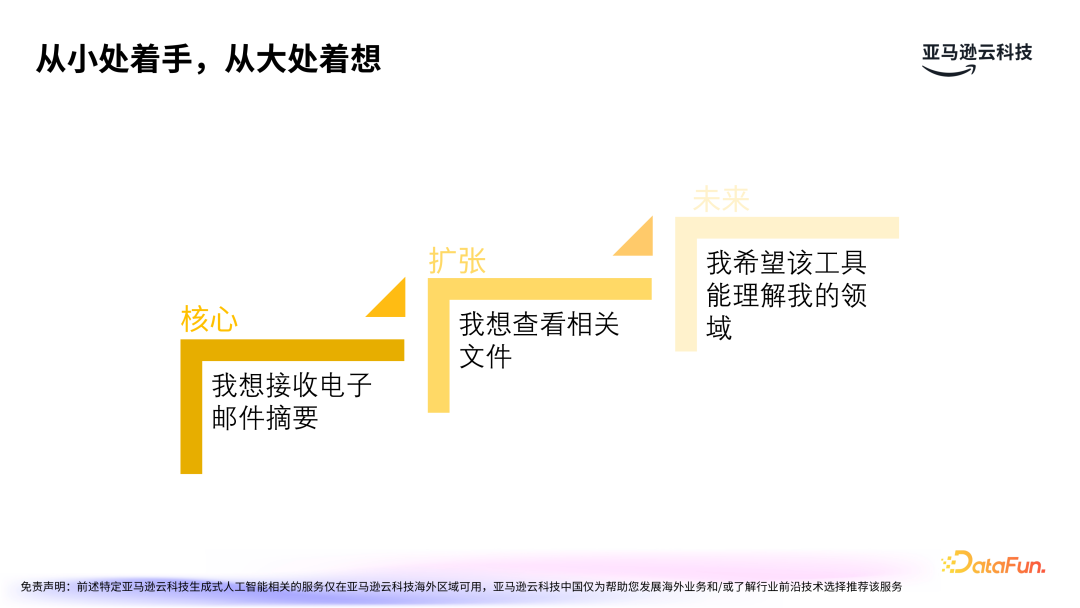
- 核心诉求:用户希望通过大模型快速获得电子邮件的摘要,这需要将大模型应用于信息提炼。
- 扩张思考:摘要生成后,用户可能需要查阅相关文档、产品能力介绍、服务说明等,这需要更复杂的关联功能来实现。
- 未来规划:随着技术的进步,期望大模型能帮助用户解决更多的领域细节问题。
MLOps 与 LLMOps
将大模型应用到实际生产实践中并非一蹴而就,需要经过复杂的技术实现,包括数据处理、模型评估、模型调优等一系列步骤。- 模型的适应性与可扩展性:大模型的一个主要挑战是其适应性和可扩展性。随着企业和项目的需求变化,如何让大模型在不同的场景中都能高效工作,是一个技术难题。例如,一个专为电子邮件摘要设计的大模型,如何在客户服务、技术支持或市场营销等多领域中都能产生有用的信息?这需要模型具有较高的泛化能力,能够根据实际场景灵活调整。
- 成本问题:大模型的训练和部署通常需要庞大的计算资源,这使得它们在生产环境中的运维成本非常高。为了应对这一挑战,云计算和分布式技术的结合显得尤为重要,尤其是采用云端结合的架构来优化成本和计算资源的利用。
- 隐私保护与数据安全:大模型在处理大量敏感数据时,如何确保用户隐私和数据安全是一个亟待解决的问题。尤其是在处理电子邮件或企业内部通讯时,数据泄露或模型训练过程中不当的数据使用可能带来巨大的风险。对此,需要加强数据加密、合规审查、去标识化等技术措施。
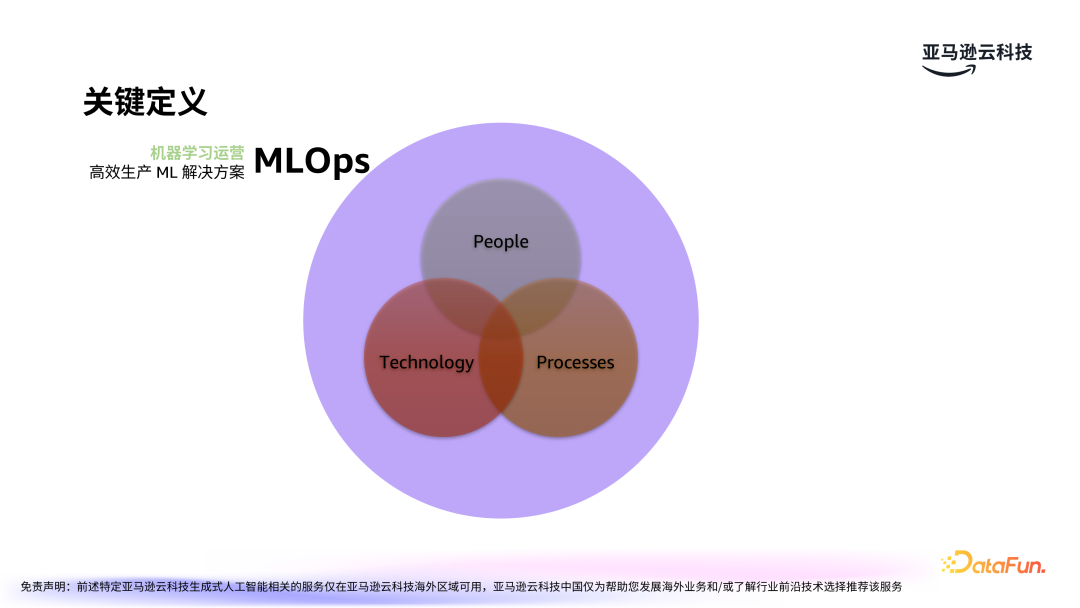
MLOps(Machine Learning
Operations)指的是高效的机器学习生产落地实践方案,是使机器学习运营化的能力。FMOps(Foundation Model Operations)和 LLMOps(Large Language Model Operations)则是针对大模型的生产落地实践方案。
无论是 MLOps 还是 FMOps 或 LLMOps,其核心都是人、技术和流程。人是其中最为重要的一环,包括开发者、工程师、用户等不同角色。技术则是一直以来备受关注的方面,包括模型的选择、性能、准确率、成本等等。最后是流程化,包括流水线的构建,涉及持续集成和交付工具(CICD)等技术。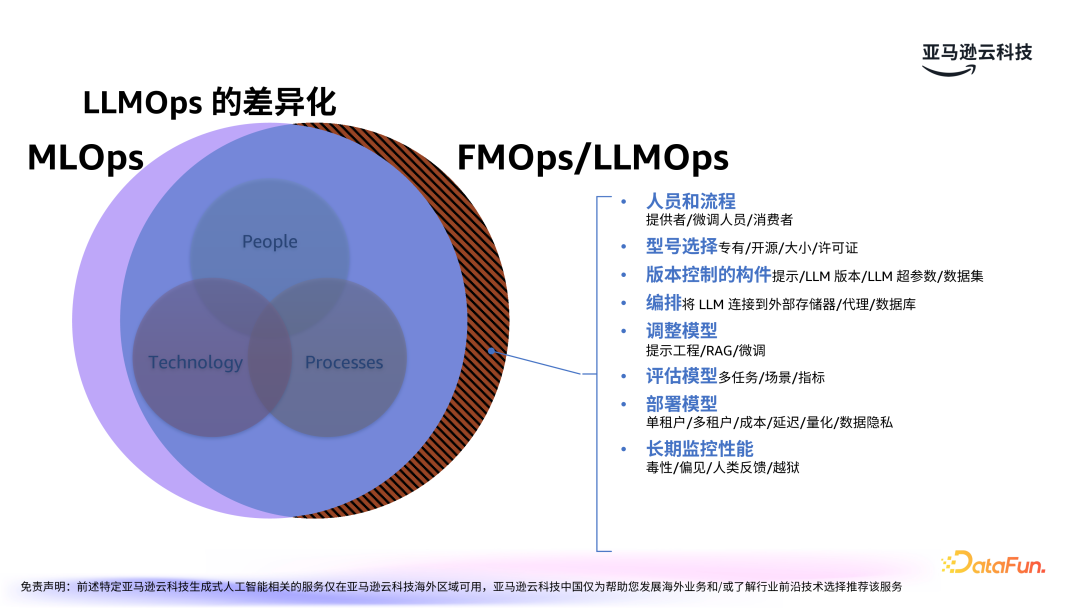
相比于传统的 MLOps,LLMOps 需要考虑更多因素,主要仍是集中在人、技术和流程三大方面。人:按人群画像,分为模型提供者、模型微调者和消费者。
型号选择:包括专有模型还是开源模型的选择,模型大小,并综合考虑性能、准确率、成本,以及许可证。
版本控制的构件:包括提示、LLM 版本、LLM 超参数,以及数据集。
编排:将 LLM 连接到外部存储器、代理、数据库。
调整模型:包括提示工程、RAG、微调。
评估模型:包括多任务、场景,以及各项指标。
部署模型:需要考虑单租户或多租户形式,以及成本、延迟、量化和数据隐私等多个方面。
长期监控性能:大模型可能出现偏见或幻觉问题,需要依据人类反馈长期监控。
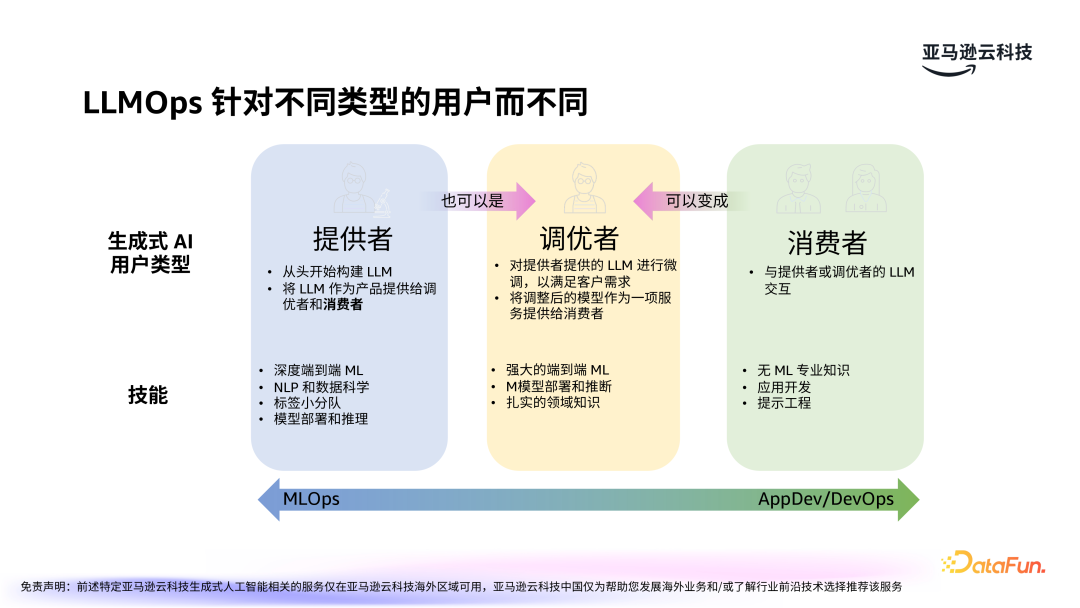
针对不同类型的用户群体,需要构建不同的 LLMOps。从用户的维度来看,三大类人群:提供者、调优者和消费者,涉及不同的技术能力。- 提供者:提供者负责从头开始构建大模型。这包括数据处理以及模型的训练、调优、部署和推理等工作。提供者在技术上需要具备端到端的大模型构建能力,并能够针对不同的业务需求设计或选择合适的模型。
- 调优者:调优者通常是基于提供者提供的基础大模型进行微调,以满足特定领域和应用场景的需求。他们将调整后的模型作为服务(Model as a Service)提供给消费者。调优者需要具备扎实的机器学习技能,尤其是在模型部署、推理、调参方面,同时需要有一定的行业知识,如教育、医疗、金融等,才能更好地进行领域定制化调优。
- 消费者:消费者是最终使用大模型的用户,通常集中在应用开发领域。消费者不一定需要具备深入的机器学习知识,但需要具备对业务领域的深刻理解。通过提示工程,他们能帮助模型更好地适应实际应用场景。消费者在实际应用中是大模型的最终使用者,他们的需求和反馈对于大模型的优化至关重要。
提供者端更加关注 MLOps,而消费者端则更多关注于 AppDev/DevOps。通过对三类人群的需求理解,可以设计出更加适应不同用户的模型架构和应用流程。
构建核心用例
选择合适的应用场景是大模型成功落地的关键。关于用例构建,亚马逊云科技有一套成熟的方法论。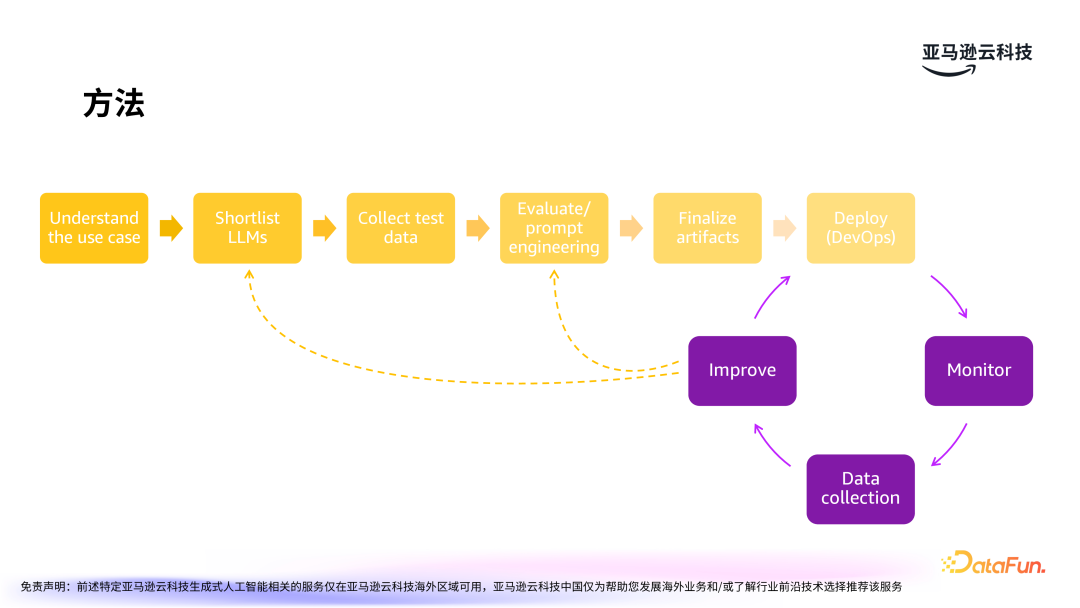
首先是理解应用场景,然后选择合适的大模型,收集测试数据,接着是提示词工程,最终部署。部署后还需要持续地监控,收集反馈数据,不断优化和迭代。
选择应用场景的过程中需要考虑关键性、规模、任务类型、语音和 ROI 等一些重要问题。以邮件摘要的场景为例,这一需求是非常重要的,但并不是必不可少的。规模方面,邮件的目标受众是公司内员工,可能有几十万人,而面向终端用户的应用规模会更大。另外,要深入分析业务流程,挖掘业务价值。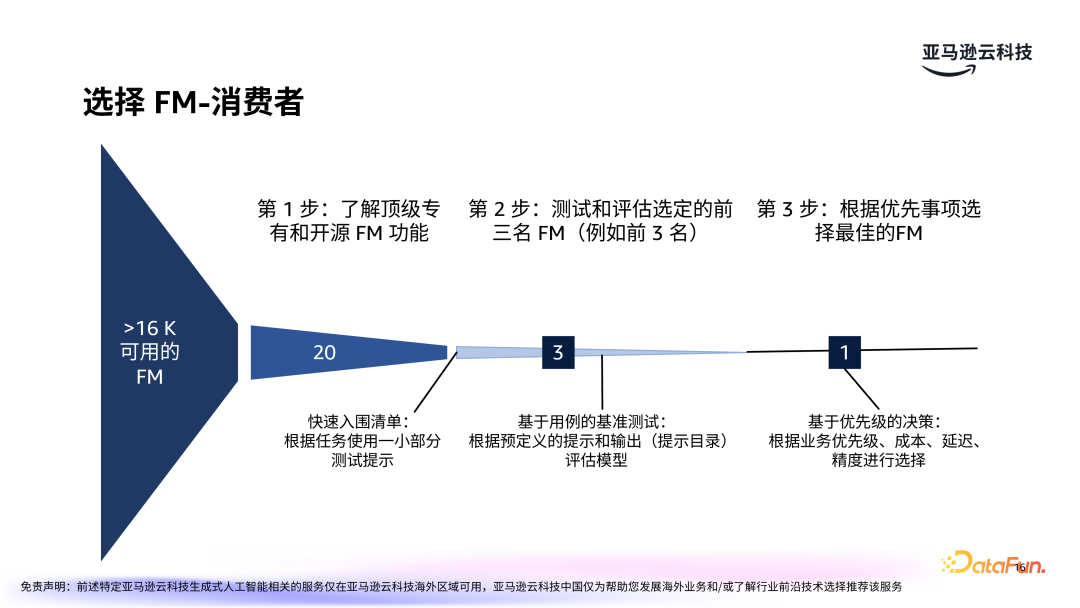
在应用场景明确后,下一步是选择合适的基础模型(FM)并进行调优。选择基础模型的过程包括三个关键步骤:第一步,了解顶级专有和开源大模型的功能;第二步,评估并选定前三名 FM;第三步,根据优先事项选定最佳的 FM。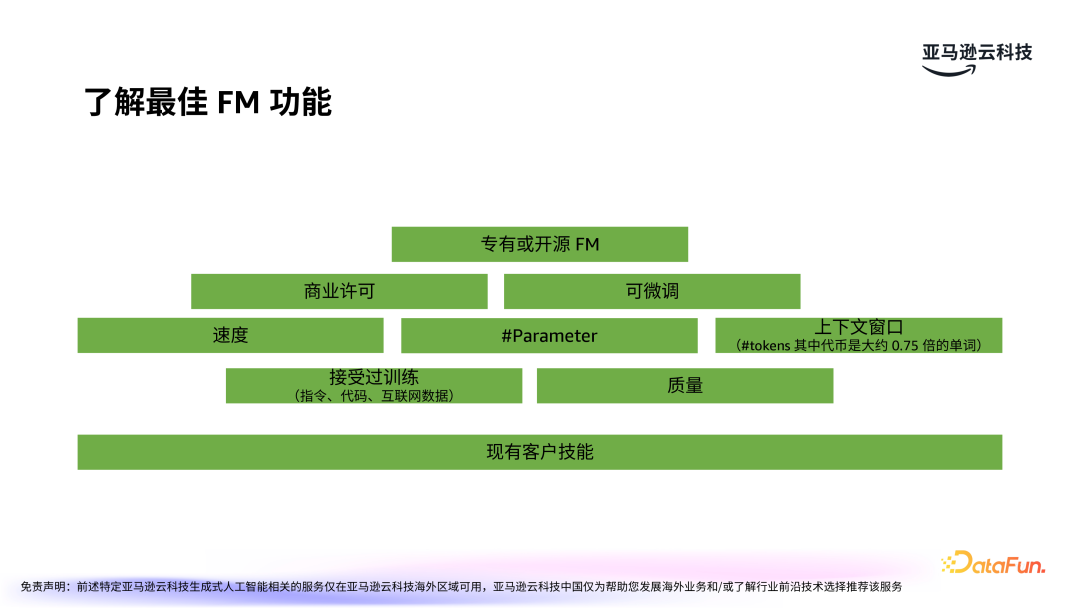
在选择 FM 之前,首先要了解客户现有技能。接着,要了解市场上主流的大模型,包括专有或开源 FM,如 Anthropic 的 Claude 系列、亚马逊的 Nova 系列,Meta 的 Llama 和国内的众多大模型等。每种模型都有其优势与局限,选择时需根据业务需求来进行比较。需要综合考虑模型速度、参数、质量,是否可微调等各方面因素。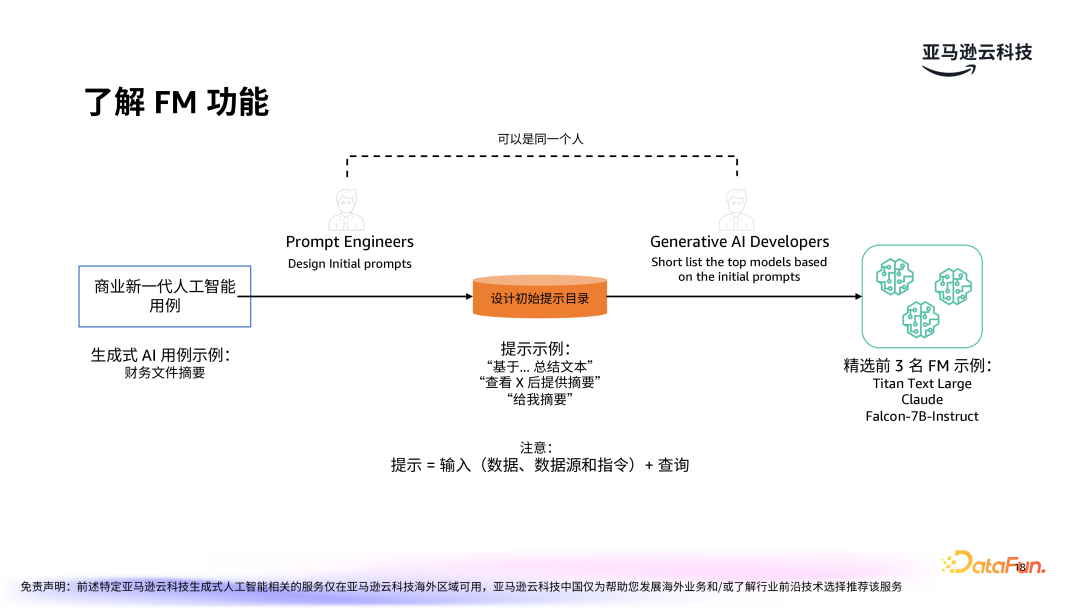
根据业务需求,建立一系列快速入围的模型清单,并通过简单的测试进行初步筛选。对入围模型进行实际案例测试,比如在 BI 能力的场景下,测试模型能否准确生成财务文件摘要等任务。根据测试结果和模型的表现,选择最合适的模型。此时可以考虑的因素包括:模型的精度、响应速度、扩展性以及对特定任务的适应能力。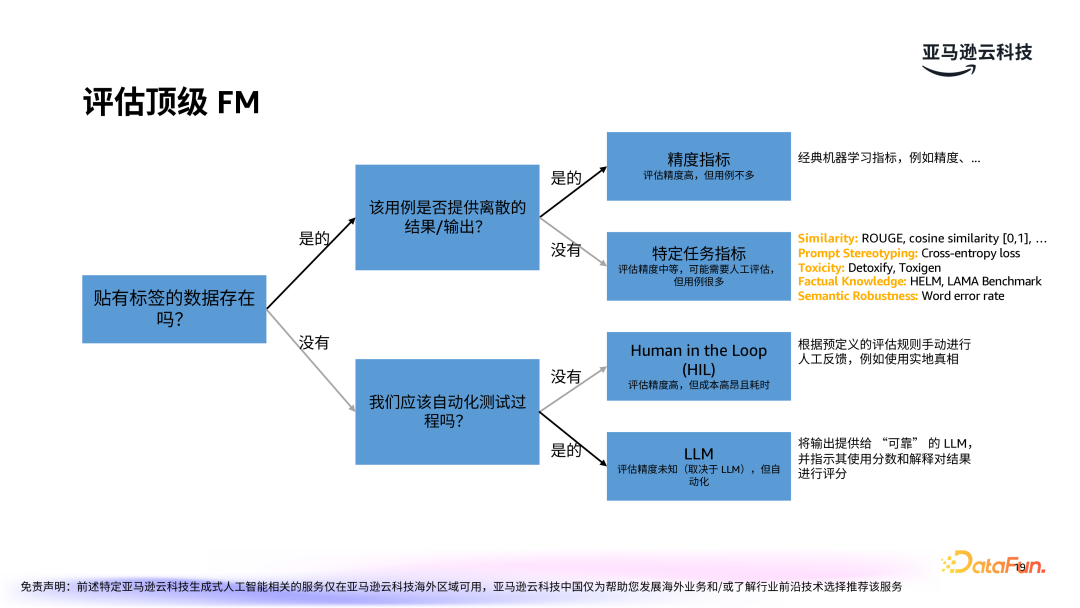
模型评估体系类似于二叉树的结构,包含各种指标,以衡量候选模型是否能够满足需求。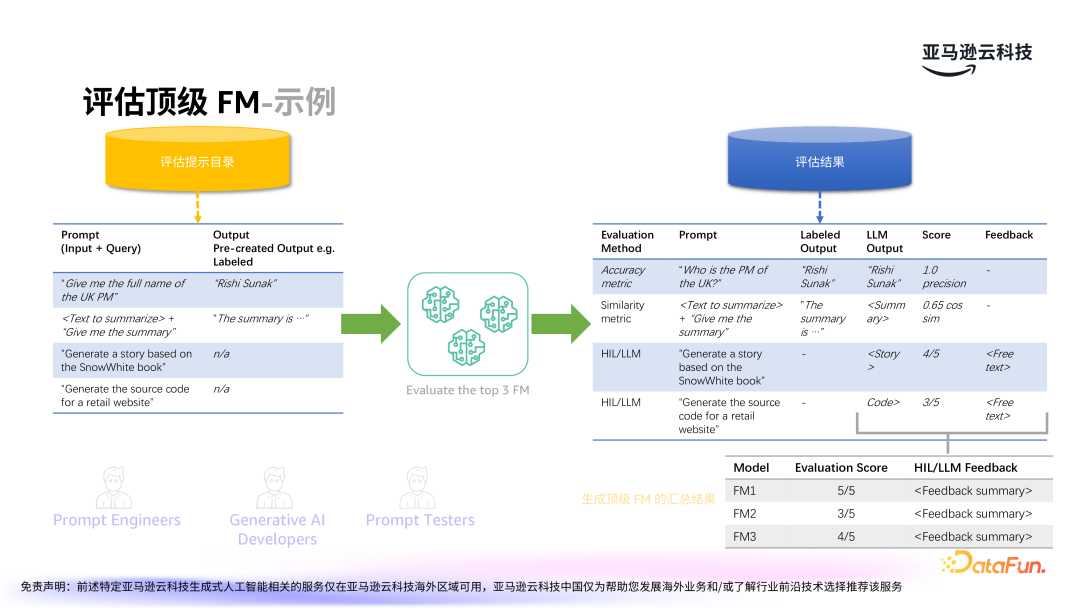
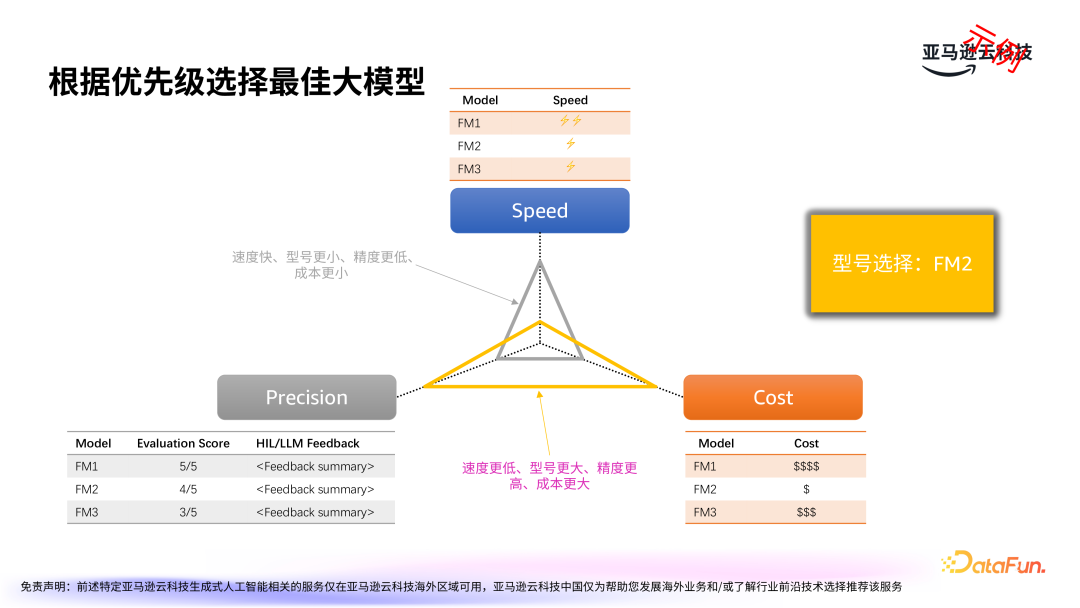
基于初步筛选出的候选大模型,进一步根据优先级选择出最佳大模型。考虑因素包括速度、精度和成本三个维度。实际应用中,有时为了节省成本,可能会选择稍微牺牲精度的模型,而在某些高精度要求的场景中,速度和成本可能会被放到次要位置。因此三者需综合考虑,根据业务需求进行权衡。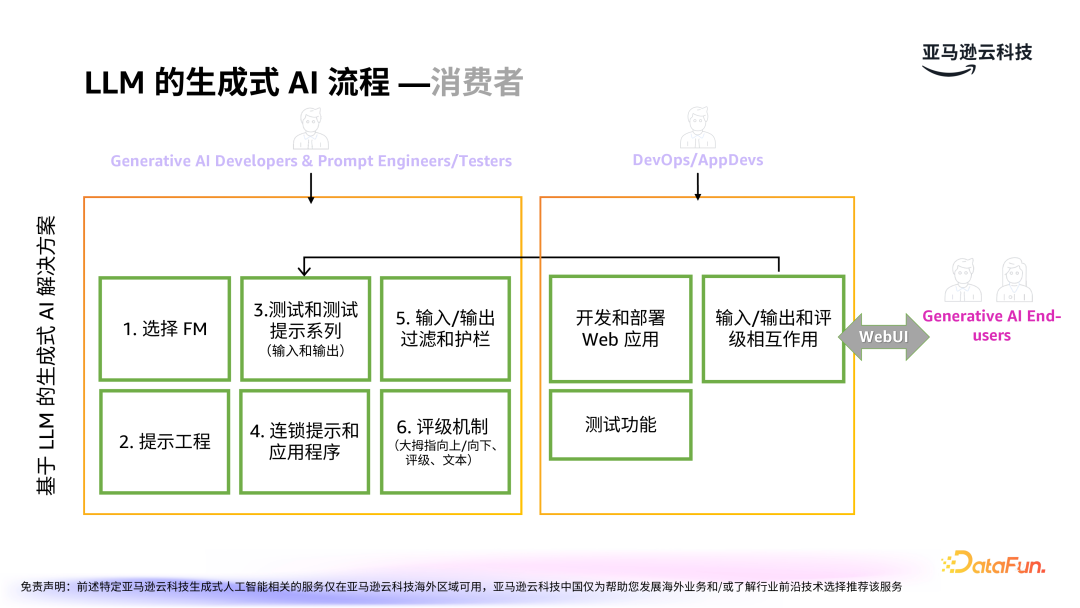
在生成式 AI 的应用开发过程中,开发者、提示词工程师和测试者的工作包括大模型的选择、提示词工程、测试、连锁提示等,还要考虑输入输出的过滤与护栏,对外需要考虑评级机制。
前端 DevOps 和应用开发者,需要在外部应用对大模型进行调用,并进行输入输出的评级和反馈。前端通过 WebUI 与最终用户进行交互。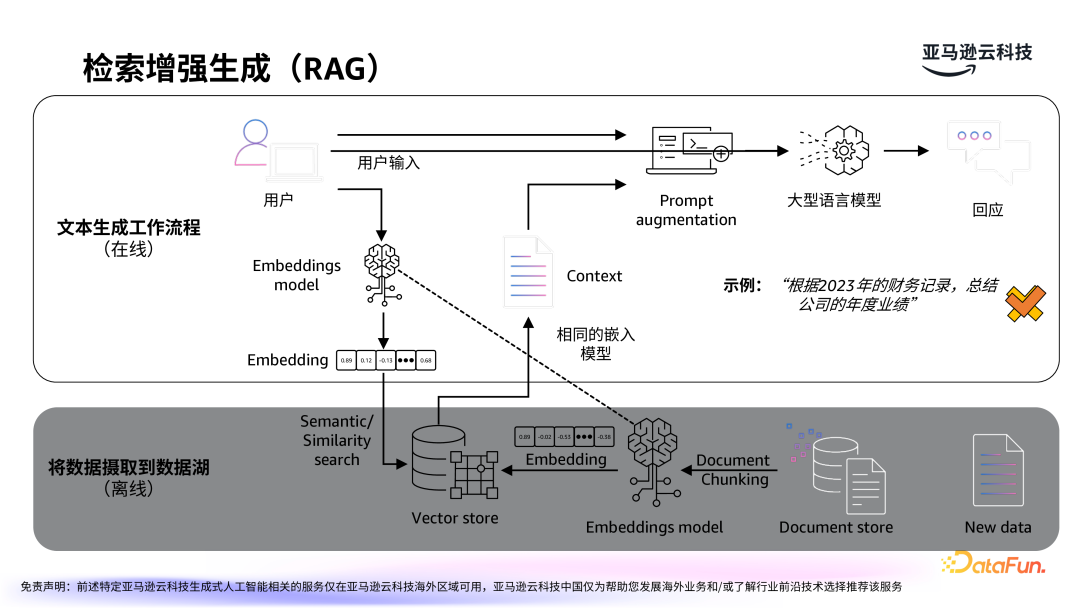
检索增强生成技术(Retrieval-Augmented
Generation,简称 RAG)是近年来生成式 AI 应用中的重要发展方向,旨在通过结合外部数据源(如知识库、数据库、文档存储等)提升大模型的生成效果。- RAG 的工作原理:RAG 结合了生成模型和检索模型,首先通过检索机制从大量的数据源中获取与任务相关的信息,然后利用这些信息作为上下文输入到生成模型中,生成更加准确且有用的结果。这种方法有效弥补了大模型在缺乏外部知识支持时的局限性,尤其在处理动态数据或时效性要求较高的任务时表现尤为突出。
- 提升生成准确性:通过集成检索功能,RAG 能够在生成过程中引入更多的背景知识,提高生成内容的准确性和相关性。例如,在自动化客服系统中,RAG 可以实时检索最新的产品文档和用户反馈,以生成更加符合用户需求的答案。
- 支持多领域知识:RAG 不仅能够增强生成模型的知识广度,还能更好地支持特定行业的需求。
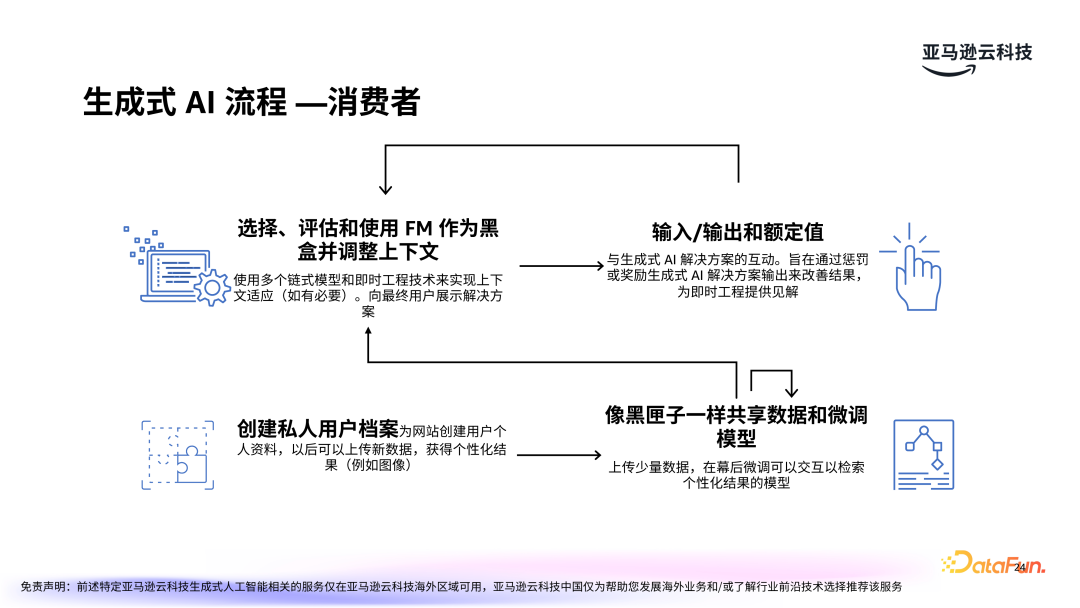
在生成式 AI 的应用过程中,消费者通常会经历几个关键步骤:- 评估和选择模型:由于大模型通常是“黑盒”的,选择合适的模型至关重要。评估时需考虑多个因素,包括模型的准确性、处理速度、资源消耗等。同时,需要通过调整输入的上下文信息,使得模型能够生成符合预期的结果。
- 人机交互与反馈优化:生成 AI 的成功应用不仅依赖于初始的模型能力,还需要通过不断的用户反馈来优化生成结果。用户的互动行为(如对生成内容的评分或评论)能够为模型提供改进的方向,从而不断提升系统的响应能力。
- 个性化微调:微调是优化生成 AI 模型的一种常见方法,尤其是在面向特定行业或领域的应用时。例如,通过上传行业数据、用户历史记录等进行微调,模型可以生成更加个性化和定制化的内容,满足特定用户的需求。

亚马逊云科技推出的 Amazon Bedrock 服务,使用简单的 API 即可调用领先的大模型,无需深入了解大模型的技术细节。该服务支持各种主流大模型(如 Claude、Llama 等),并提供定制化微调能力,帮助用户根据自身需求调整模型。利用 Amazon Bedrock 的智能体和知识库可以快速构建 RAG,利用 Amazon Bedrock Guardrails 可实现可靠的应用。服务提供了多种安全相关能力,全方位保障用户数据和应用的安全与隐私。
调优之旅
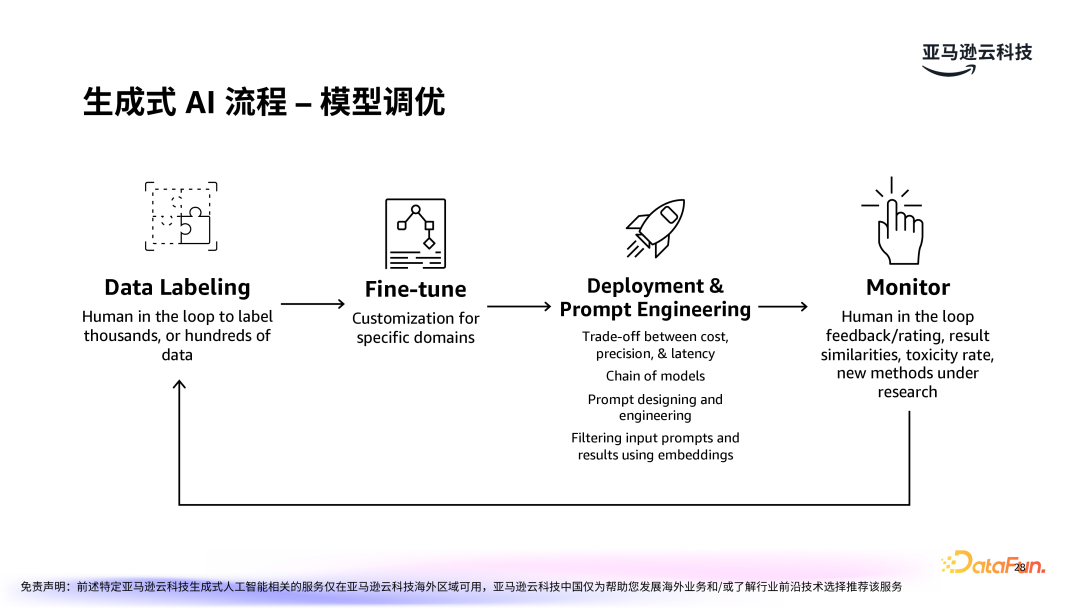
在实际应用中,生成式 AI 的效果不仅仅依赖于基础模型的能力,还需要通过微调和优化来进一步提升,以更好地适应具体的业务场景,提高生成内容的质量和准确性。模型调优过程包括:数据标注:数据标注是微调过程中的一个关键步骤,它为模型提供了学习的基础,帮助模型更好地理解和处理特定任务。在微调时,数据的标注质量直接影响模型的最终效果,因此,确保标注数据的准确性和高质量至关重要。
模型微调:通过修改模型的参数或训练策略,使其在特定领域(如金融、医疗、法律等)表现更好。
部署和提示工程:需权衡准确度、延迟和成本等多方面因素。
监控:模型部署后的监控是确保生成式 AI 能够稳定、有效运行的重要步骤。通过用户反馈、打分等手段持续优化模型。
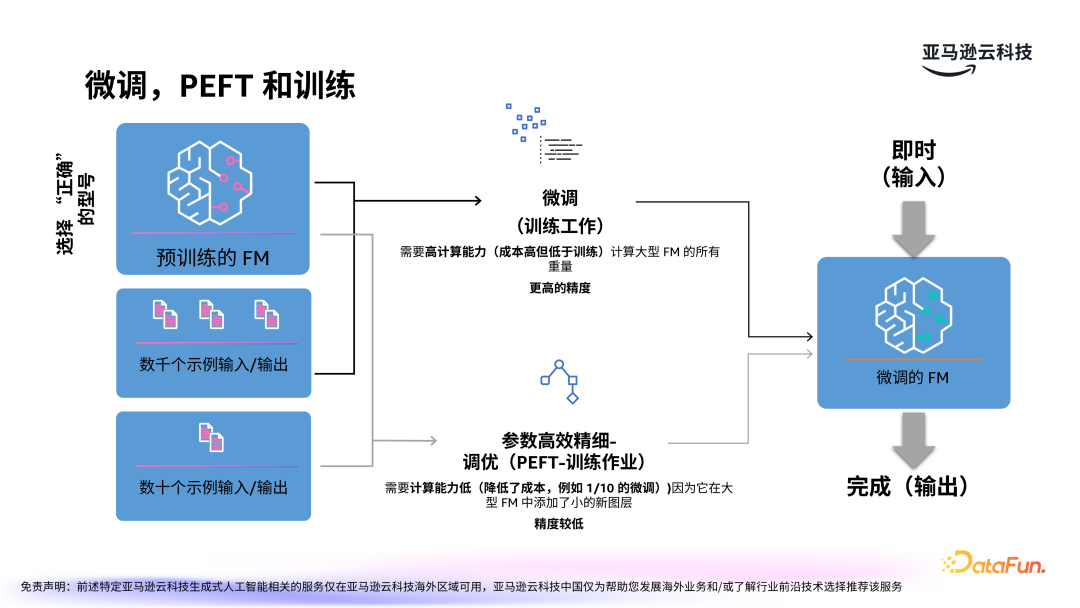
微调有多种不同的方式,第一种是传统的训练式微调,这种方式虽然可以得到更高的精度,但通常需要较高的计算能力,因此成本较高。
另一种是高效微调 PEFT,这是一种更加经济的优化方法。PEFT 只需调整少量参数,大大减少了对 GPU 资源的需求,且能够在垂直领域(如金融、医疗等)获得优异的效果。PEFT 方法已经历多年发展,其中最流行的变体包括 LoRA(Low-Rank Adaptation)等。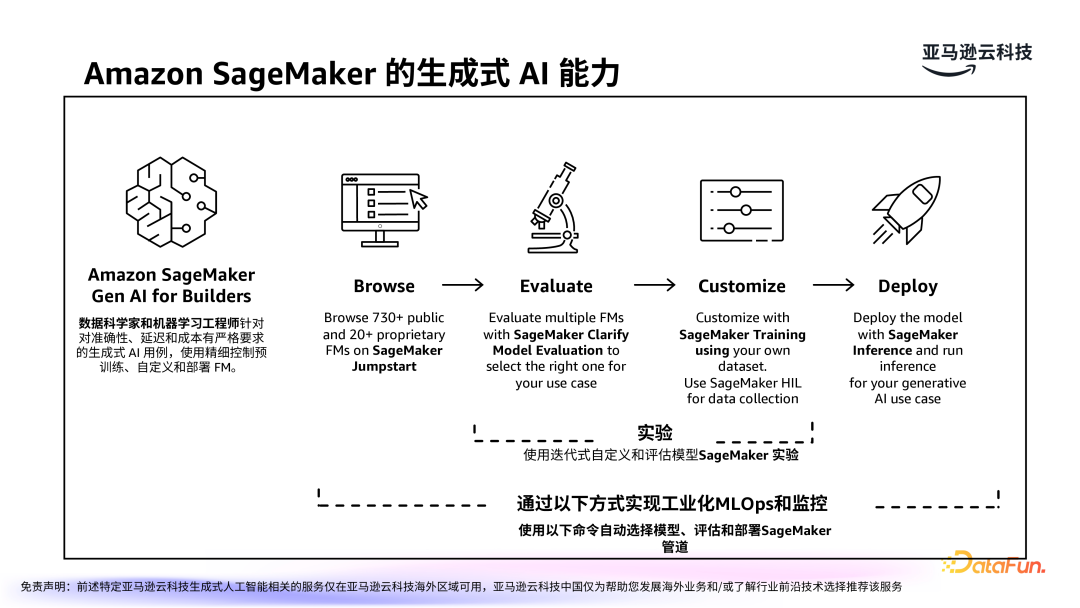
亚马逊云科技提供的云上服务 Amazon SageMaker,依靠其强大的生成式 AI 能力,支持大模型的选择、训练、微调、评估和部署。该平台专门面向数据科学家和机器学习工程师,帮助他们优化生成式 AI 模型,并确保模型能够高效、低成本地应用于生产环境。并提供了工业化的精细管理和监控,使用户可以更高效地实现云端的 LLMOps。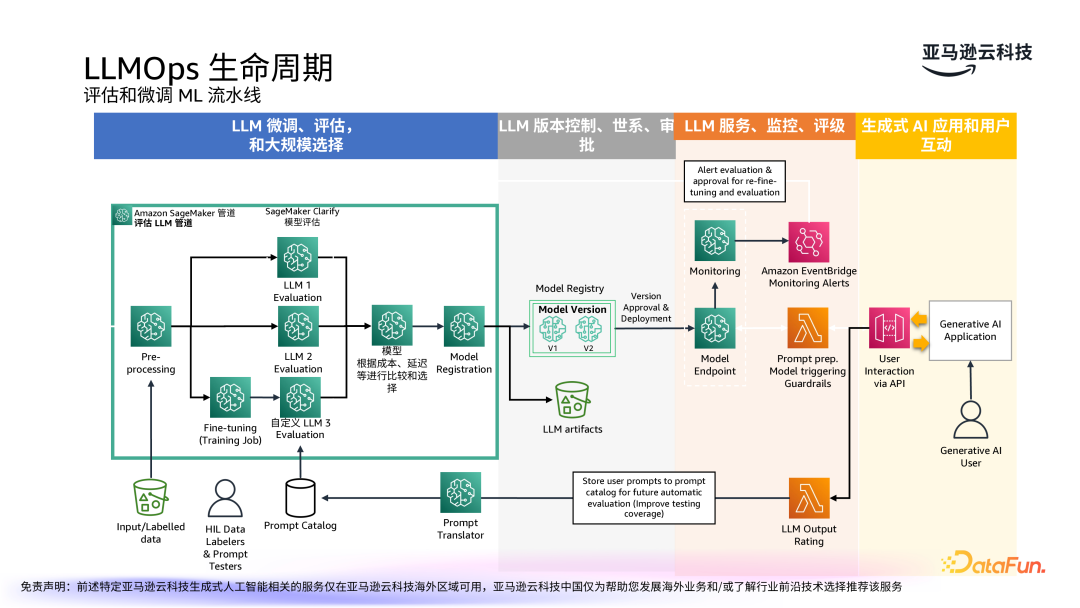
大模型的生命周期管理涵盖了从模型的训练、部署到长期的监控与优化。首先是模型的微调、评估和选择,可以使用 Amazon SageMaker 进行模型评估,根据成本、延迟等进行比较和选择。第二部分是大模型的版本控制、血缘和审批。接下来是模型的部署、监控和评级,保证模型在应用过程中可检测、可反馈。最后是面向终端用户的生成式 AI 应用和互动,互动中也会收集用户反馈,以进一步优化模型。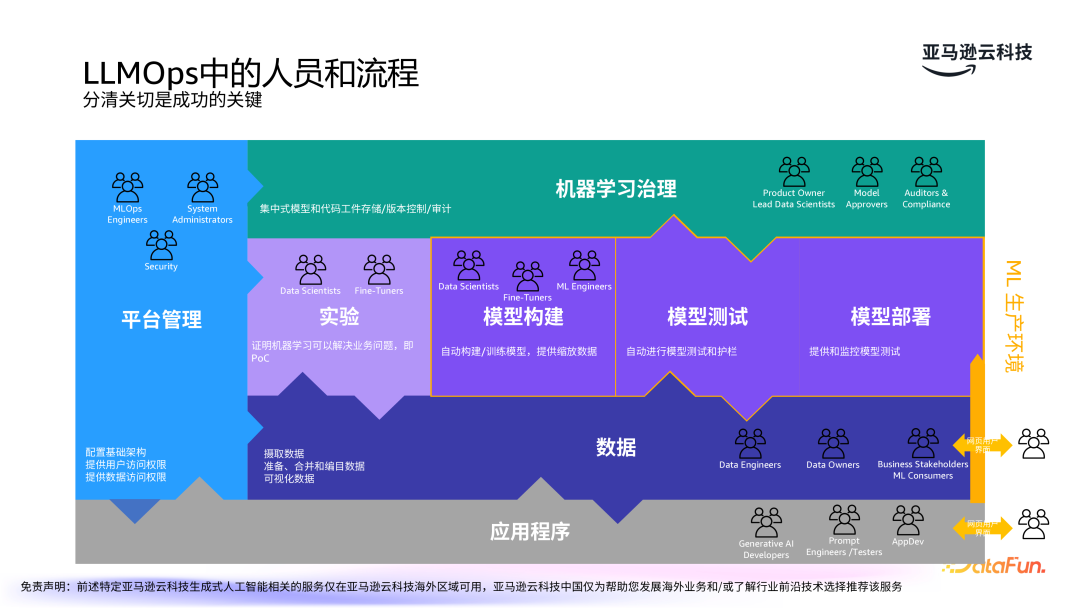
人员和流程也是 LLMOps 中的重要环节,分清关切是成功的关键。我们的实践是通过人群画像作为切入点,在流程中进一步细化分类,构建完善的生产环境的实践。随着技术的不断发展,生成式 AI 的应用场景将更加广泛,亚马逊也将进一步完善所提供的服务,帮助更多的开发者和企业提升 AI 应用的质量与效率。

































 粤ICP备17114055号
粤ICP备17114055号