【行客按】Med-Gemini模型是基于Gemini模型系列的高级AI工具,专门针对医学领域进行了优化。该模型整合了网络搜索功能,并可通过自定义编码器针对新型医疗内容进行调整。在14个医疗基准测试中,Med-Gemini在10个中达到或超越了行业最高标准,特别是在MedQA基准测试中,通过引入不确定性引导的搜索策略,实现了91.1%的高精度,较之前的Med-PaLM 2模型提升了4.6%。在实际应用中,Med-Gemini不仅在生成医学文本总结和转介信方面超越了人类专家,还在多模态医学对话和医学研究领域显示出巨大潜力。
Med-Gemini的核心技术及模拟验证
多模态模型
Med-Gemini能够综合处理和解析医疗数据中的文本、图像和视频,这一能力在医学领域尤为关键。例如,在处理X射线影像或MRI扫描时,Med-Gemini不仅分析图像本身,还能结合病历记录中的文本信息,为医生提供更全面的诊断支持。这种多模态理解能力,特别是在紧急情况下快速提供决策支持的能力,极大地增强了其在实际医疗环境中的应用价值。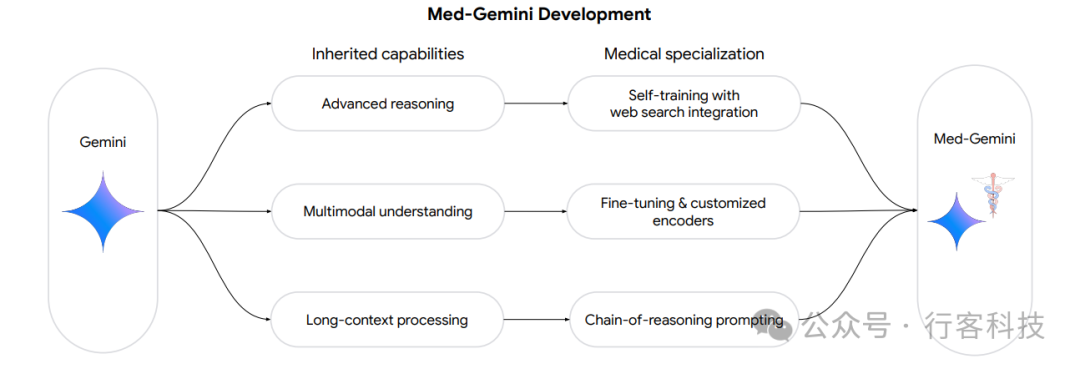 放射学对话:其中示例图像来自MIMIC-CXR数据集的测试集。Med-Gemini-M 1.5展示了与初级保健提供者互动分析胸部X光片(CXR)、识别退行性盘病、讨论因果关系和与患者背痛历史相关的相关性差异、建议后续调查以确定背痛原因,并使用非技术语言提供报告以促进患者理解和沟通的能力。我们观察到Med-Gemini-M 1.5的回应根据提示有一定的变化(例如,对于某些提示,报告将不会列出轻度退行性变化,尤其是如果提示关注其他解剖特征)。全面量化Med-Gemini-M 1.5的多模态对话能力和变化性超出了本项工作的范围,但这些定性示例展示了Med-Gemini-M 1.5支持基于多模态来源的医学知识对话的能力,这是一个潜在有用的特性,适用于考虑用户-人工智能和临床医生-人工智能交互的应用。对这些用例的现实世界探索将需要进行大量的进一步开发和验证,以便在这些初步承诺的迹象上进行建设。图7 | 一个假设性的多模态辅助诊断对话示例,使用Med-Gemini-M 1.5在放射学设置中。(a) 在这次互动中,Med-Gemini-M 1.5展示了它分析胸部X光片(CXR)和与初级保健医生进行假想现实对话的能力。如上所述,Med-Gemini-M 1.5没有进行进一步研究,不适合这种现实世界的使用。然而,这个示例展示了初步的承诺,其中Med-Gemini-M 1.5识别出脊柱的轻度退行性变化,并可以回答关于导致此发现的推理的问题,展示关于退行性盘病的一般医学知识,并区分与患者背痛历史相关的相关性和因果关系。最后,在这个示例中,Med-Gemini-M 1.5能够用外行的术语解释其发现,展示了其在临床设置中促进患者理解和沟通的潜力。
放射学对话:其中示例图像来自MIMIC-CXR数据集的测试集。Med-Gemini-M 1.5展示了与初级保健提供者互动分析胸部X光片(CXR)、识别退行性盘病、讨论因果关系和与患者背痛历史相关的相关性差异、建议后续调查以确定背痛原因,并使用非技术语言提供报告以促进患者理解和沟通的能力。我们观察到Med-Gemini-M 1.5的回应根据提示有一定的变化(例如,对于某些提示,报告将不会列出轻度退行性变化,尤其是如果提示关注其他解剖特征)。全面量化Med-Gemini-M 1.5的多模态对话能力和变化性超出了本项工作的范围,但这些定性示例展示了Med-Gemini-M 1.5支持基于多模态来源的医学知识对话的能力,这是一个潜在有用的特性,适用于考虑用户-人工智能和临床医生-人工智能交互的应用。对这些用例的现实世界探索将需要进行大量的进一步开发和验证,以便在这些初步承诺的迹象上进行建设。图7 | 一个假设性的多模态辅助诊断对话示例,使用Med-Gemini-M 1.5在放射学设置中。(a) 在这次互动中,Med-Gemini-M 1.5展示了它分析胸部X光片(CXR)和与初级保健医生进行假想现实对话的能力。如上所述,Med-Gemini-M 1.5没有进行进一步研究,不适合这种现实世界的使用。然而,这个示例展示了初步的承诺,其中Med-Gemini-M 1.5识别出脊柱的轻度退行性变化,并可以回答关于导致此发现的推理的问题,展示关于退行性盘病的一般医学知识,并区分与患者背痛历史相关的相关性和因果关系。最后,在这个示例中,Med-Gemini-M 1.5能够用外行的术语解释其发现,展示了其在临床设置中促进患者理解和沟通的潜力。长文本处理能力
在处理分散的医疗记录时,Med-Gemini展现出卓越的长文本处理能力。它能够从成千上万的文档中提取和总结关键信息,这对于患者历史的深入了解及其在临床路径中的应用尤为重要。例如,在处理慢性病患者的长期医疗记录时,Med-Gemini能够识别并追踪病情变化,助力医生制定更精确的治疗计划。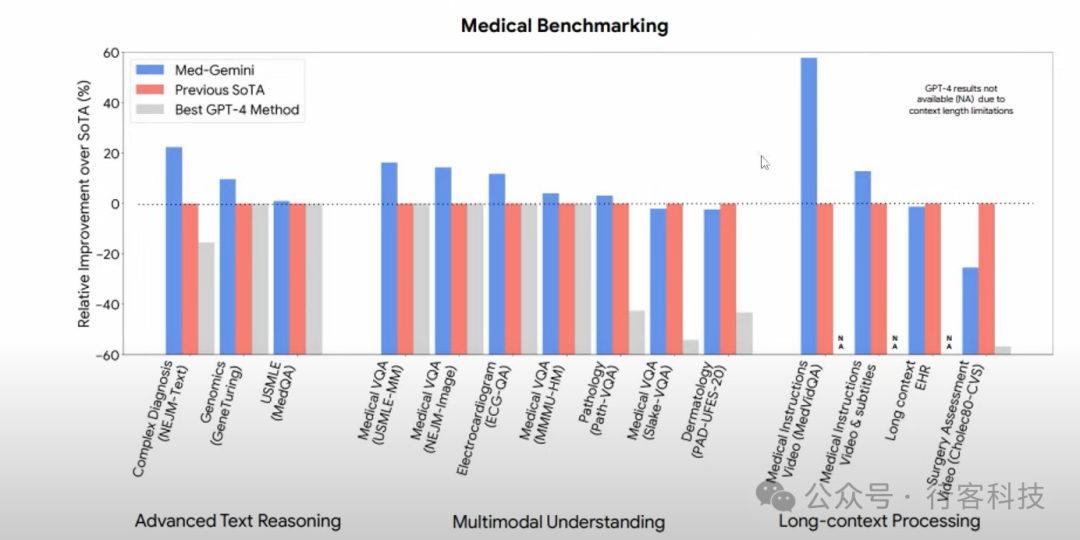
从长篇电子健康记录 (EHR) 中提取医疗状况: 评估 Med-Gemini-M 1.5 从冗长电子健康记录中识别特定但罕见的医疗问题(疾病、症状或手术)的能力。该任务类似于“大海捞针”。。基准方法依赖于使用启发式方法汇总来自多个来源的注释。令人鼓舞的是,Med-Gemini-M 1.5 与基准方法的表现相当,即使基准方法针对此任务进行了高度专门化,并且需要大量人工工作来设置。这表明 Med-Gemini-M 1.5 能够处理长文档并泛化到新的情况,而无需广泛的定制。理解医学视频: 评估 Med-Gemini-M 1.5 在三个医学视频任务中的表现。其中两个任务仅提供视频本身,另一个任务同时提供视频和字幕。任务内容为回答有关视频的问题。在两个任务中,Med-Gemini-M 1.5 取得了最高性能,甚至超越了之前不依赖大型语言模型 (LLM) 的最佳方法。这些先前的方法需要大量人工调整才能正常工作。当视频和字幕同时提供时(视频+字幕任务),Med-Gemini-M 1.5 再次取得了最高性能。额外的字幕显着提高了模型对视频的理解。这表明未来的研究应该探索如何最好地利用视频的各个方面(图像、文本和音频)来进一步提高视频理解。对于评估腹腔镜胆囊切除术视频中的关键手术视图的任务,Med-Gemini-M 1.5 的表现优于 GPT-4V。然而,使用 ResNet3D 架构的监督基准方法表现更好。这表明可能需要进一步研究提示技术或微调指令以提高 Med-Gemini-M 1.5 在此特定任务上的性能。
图 6: 皮肤科场景下与 Med-Gemini-M 1.5 进行假设性多模态诊断对话的示例
(a) 用户与我们的多模态模型 Med-Gemini-M 1.5 进行交互,模拟一位基于 SCIN (Ward et al., 2024) 病例的患者。SCIN 是一个外部数据集,未包含在微调混合物中。如果不进行大量额外的研究和开发,此系统并不适用于实际诊断任务。然而,本例通过继承自原始 Gemini 模型的对话能力与微调获得的新型多模态医学知识相结合,展示了未来丰富的多轮诊断对话的潜在可能性。在此交互中,Med-Gemini-M 1.5 在用户未提供图片时会要求上传图片(多模态信息获取),并能高效地得出正确诊断(开放式诊断),通过整合相关的视觉特征和其他收集到的患者症状来解释其推理过程(可解释性),回答有关治疗方案的问题,同时适当地将最终决定权留给专家。(b) 展示了从皮肤科医生那里收集的反馈,以定性评估诊断对话的内容,特别要求他们对模型的积极和消极方面进行评论。

与GPT-4模型家族的比较
在多个医学基准测试中,Med-Gemini相比GPT-4显示出更加优越的性能。这不仅因为其深度学习能力,还包括其在特定医疗任务中的专业调整,如增强的推理能力和改进的模态集成方式。这使得Med-Gemini在模拟医学考试(如USMLE)等场景中,能够提供更为准确和实用的答案。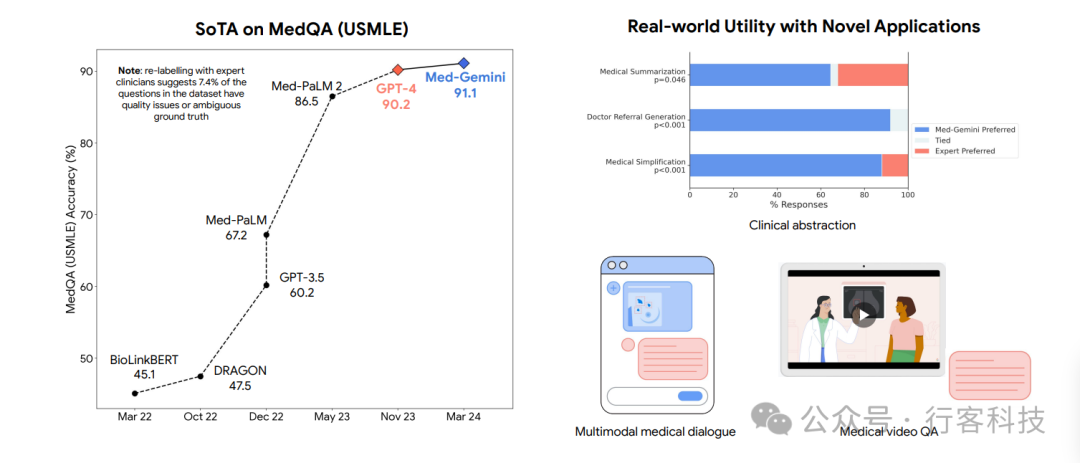 根据下图表1数据,Med-Gemini-L 1.0在MedQA(USMLE)的测试中实现了91.1%的准确率,设定了新的行业最高标准,超过了之前的Med-PaLM 2模型4.5个百分点,也比使用复杂提示的GPT-4增强版——MedPrompt高出0.9%。与MedPrompt的策略相比,Med-Gemini-L 1.0采用了基于不确定性引导的搜索框架,该策略不仅适用于MedQA测试,还可以扩展到更复杂的场景。
根据下图表1数据,Med-Gemini-L 1.0在MedQA(USMLE)的测试中实现了91.1%的准确率,设定了新的行业最高标准,超过了之前的Med-PaLM 2模型4.5个百分点,也比使用复杂提示的GPT-4增强版——MedPrompt高出0.9%。与MedPrompt的策略相比,Med-Gemini-L 1.0采用了基于不确定性引导的搜索框架,该策略不仅适用于MedQA测试,还可以扩展到更复杂的场景。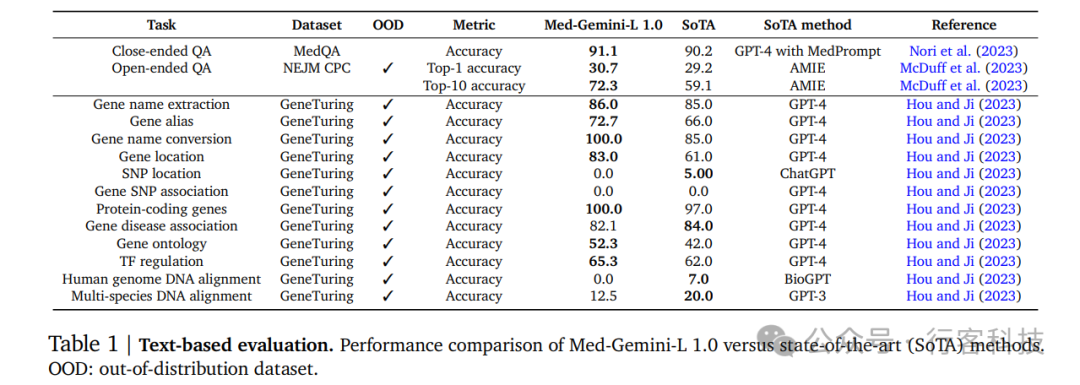 此外,在新英格兰医学杂志(NEJM)发布的CPC复杂诊断挑战中,Med-Gemini-L 1.0以13.2%的优势超越了先前的行业标准AMIE模型,该模型本身已优于GPT-4。这一成就在图3a中有所展示。该搜索策略同样适用于基因组学知识任务,如表1所示。在七个GeneTuring模块中,Med-Gemini-L 1.0的表现优于Hou和Ji在2023年报告的其他顶尖模型。
此外,在新英格兰医学杂志(NEJM)发布的CPC复杂诊断挑战中,Med-Gemini-L 1.0以13.2%的优势超越了先前的行业标准AMIE模型,该模型本身已优于GPT-4。这一成就在图3a中有所展示。该搜索策略同样适用于基因组学知识任务,如表1所示。在七个GeneTuring模块中,Med-Gemini-L 1.0的表现优于Hou和Ji在2023年报告的其他顶尖模型。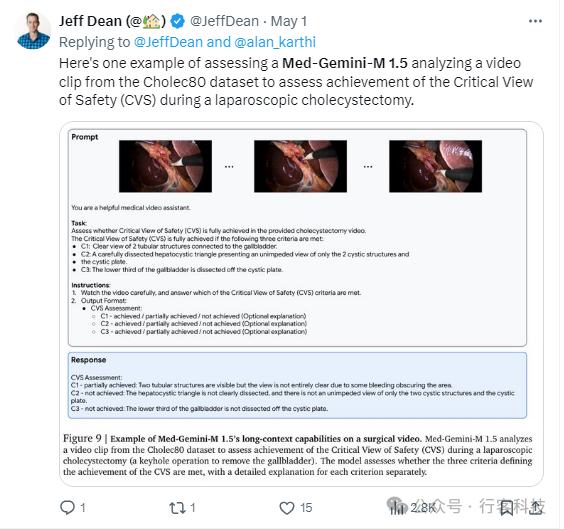
为了更深入地了解自我训练和不确定性引导搜索对模型性能的影响,对Med-Gemini-L 1.0在有无自我训练的情况下的表现进行了比较,同时还考察了在不同次数的不确定性引导搜索下的表现。结果显示,自我训练使模型的准确率提高了3.2%,并且每一轮搜索都有效提高了性能,从最初的87.2%提升至91.1%。同样,在NEJM CPC基准测试中,加入搜索后前十名的准确率提升了4.0%,如图3a所示。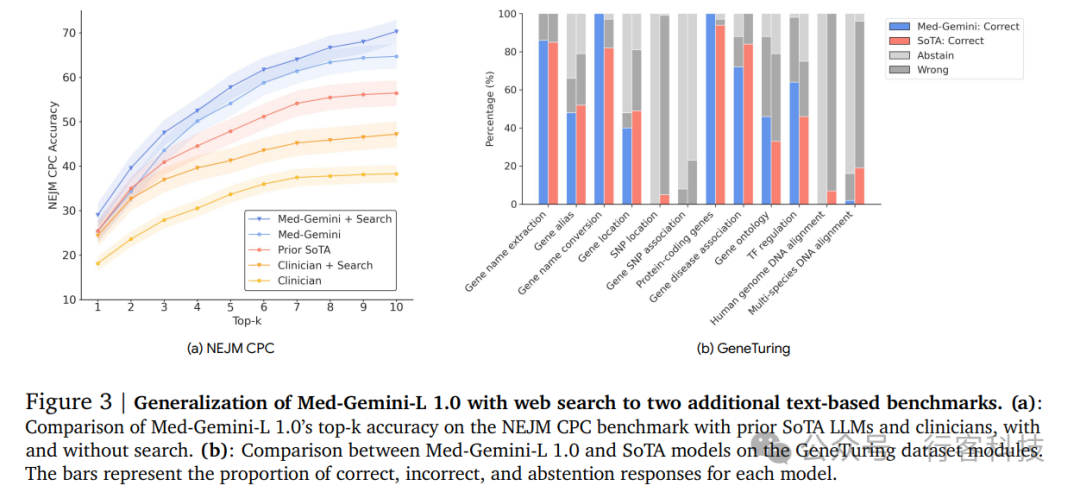 图 3: 利用网络搜索扩展 Med-Gemini-L 1.0 到两个额外文本基准的泛化能力(a): Med-Gemini-L 1.0 在 NEJM CPC 基准测试上的 top-k 准确率与之前最先进 (SoTA) 大型语言模型和临床医生的比较,包含使用和不使用网络搜索的情况。(b): Med-Gemini-L 1.0 与 GeneTuring 数据集模块上最先进模型的比较。柱状图表示每个模型的正确响应、错误响应和弃权响应的比例
图 3: 利用网络搜索扩展 Med-Gemini-L 1.0 到两个额外文本基准的泛化能力(a): Med-Gemini-L 1.0 在 NEJM CPC 基准测试上的 top-k 准确率与之前最先进 (SoTA) 大型语言模型和临床医生的比较,包含使用和不使用网络搜索的情况。(b): Med-Gemini-L 1.0 与 GeneTuring 数据集模块上最先进模型的比较。柱状图表示每个模型的正确响应、错误响应和弃权响应的比例

































 粤ICP备17114055号
粤ICP备17114055号