导读 人工智能平台 PAI 是面向开发者和企业的 AI 工程化平台,提供了覆盖数据准备、模型开发、模型训练、模型部署的全流程服务。本文将分享阿里云 PAI 大语言模型微调实践。
1. 大语言模型微调简介
2. 使用 PAI-QuickStart 微调大语言模型
3. 模型微调实践
分享嘉宾|梁权 阿里云 人工智能平台 PAI 技术专家
编辑整理|阿东同学
内容校对|李瑶
出品社区|DataFun
大语言模型微调简介
在机器学习的发展过程中,模型的开发与应用模式一直在不断迭代。传统的机器学习年代,机器学习工程师在采集数据之后,需要通过特征工程处理数据,使用模型训练。在深度学习的年代,计算资源更加丰富,模型层数增加,模型能够支持直接从原始的数据中端到端地进行训练,而不大量依赖于特征工程。到了预训练模型的阶段,在模型开发流程中,工程师更多得采用在基础的预训练模型上,使用少量数据微调的方式构建下游应用的模型。
而到了大语言模型阶段之后,以 ChatGPT,Llama 为代表的语言模型,他们能力更加强大,拥有海量的知识,能够理解复杂的语义,有了一定的逻辑推理能力,支持通过 Prompt 工程的方式,直接应用于下游各类不同的任务。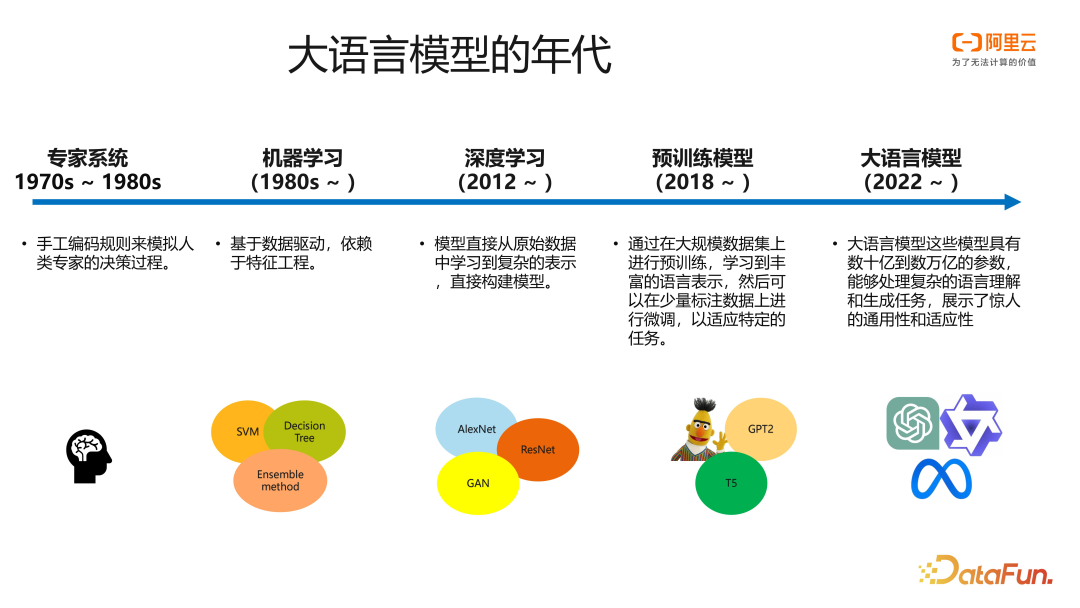
1. LLM 的应用限制
在过去的一年中,大语言模型领域呈现出了极为火热的发展势态。然而,在实践运用过程中,我们发现大语言模型仍然存在一系列亟待解决的应用难题。
由于语言模型的知识实际上是在预训练阶段被压缩进模型的,因此模型本身是静态,并不能动态更新知识。其使用的大规模数据大多是源自于互联网上可以公开获取的数据,缺少企业独有的,或者是长尾的数据。其次,大语言模型本身是一种概率模型,由于长尾知识的缺失,或者在训练过程中存在的不一致或冲突,大语言模型会有幻觉问题。基于 Transformer 架构的语言模型,其上下文长度是固定受限的。模型参数量较大,随之带来推理的成本和延迟也是实际产品化中不容忽视的问题。
2. LLM 性能优化:检索增强生成(RAG)
针对大语言模型性能的优化方案,检索增强生成(RAG)如今已被广泛采纳为一项关键技术。其核心原理在于,对用户输入的问题,不再直接提供给模型,而是首先到知识库中进行检索,继而将检索得到的信息拼接到用户问题作为 prompt 一起作为语言模型输入信息。
ChatGPT 和 Kimi 等工具都是 RAG 的典型应用,都支持从互联网获取数据,来提升交互过程中的性能表现。尽管 RAG 通过对输入上下文的优化,以提供更多信息的方式来提升模型性能,但它并不能使一个 LLM 成为法律专家,或者让其掌握一门全新的语言。
3. LLM 性能优化:RAG vs Fine-Tuning
OpenAI 的一篇关于如何改进与优化大语言模型性能的文章中提出,推荐的路径是从提示式工程到检索增强生成(RAG),再到微调,其关键在于性能与成本之间的权衡。通常情况下,检索增强生成的实施更为简便,其效果亦相当显著。而模型的微调训练则需要用户收集高质量的数据,并具备足够的计算资源进行训练。此外,通常还需进行多次实验。然而,这两者并非完全对立的关系,RAG 是通过上下文优化输入,更类似于我们在考试时携带试卷和参考答案答题,而微调则更像是在考试前或复习后,将知识内化到模型中。实际应用中,这两者是可以相互配合的,在 RAG 应用构建过程中也通常需要这两者的配合,才能达到最佳的效果。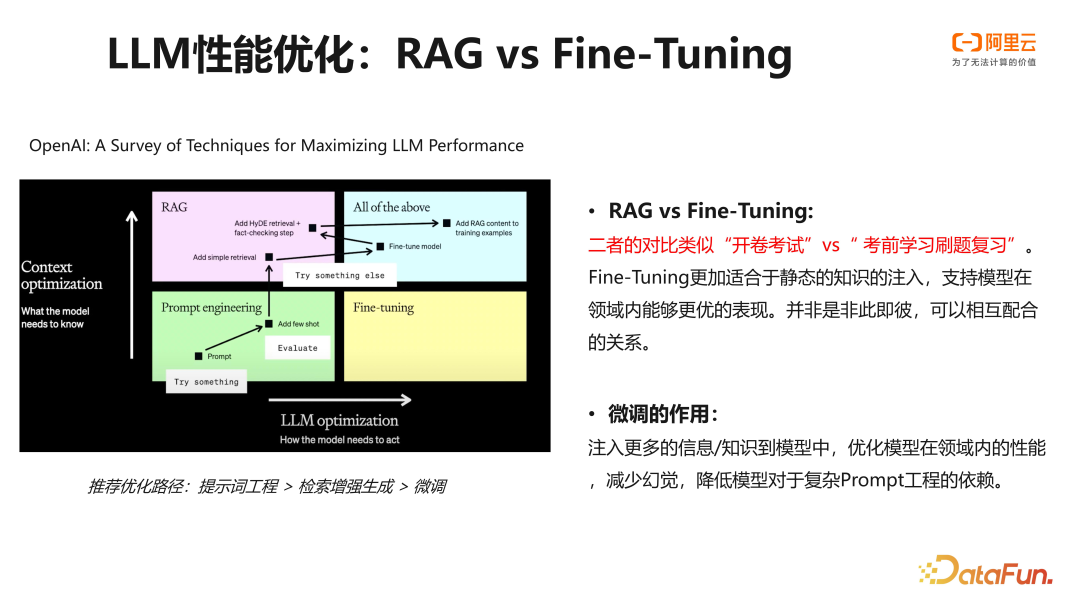
4. 推理成本和性能
在推理成本与性能优化上,毫无疑问,采用较小的模型比大模型更具优势。以 Qwen(千问) 7B 为例,大概需要 16G 左右的显存,通过 A10 提供推理服务,在实际应用中,其成本远低于 GPT-3 和 GPT-4 等大型模型。
另一个制约大语言模型实际应用的因素是其推理性能延迟,由于大语言模型自身的推理机制,需要经过两个阶段的推理,先是 prefill,然后是 decoding,其 prompt 复杂度以及输出长度都决定了推理请求的延迟。
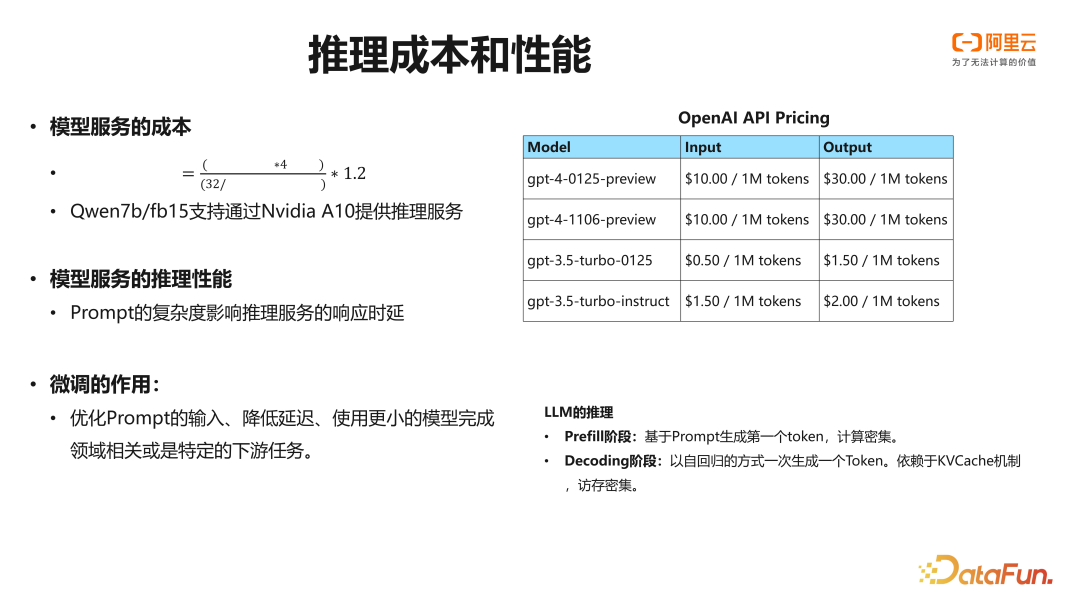
在使用 RAG 等复杂提示工程扩展其上下文作为提示输入时,往往会导致模型推理的延迟,直接影响到实际用户体验。在构建更为复杂的 RAG 应用可能并非仅调用一次语言模型。例如,RAG 可能会依赖于用户的输入,使用模型识别用户意图,确定下游应调用哪些函数或功能;或是通过知识库检索回的信息,可能会依赖于模型进行一次重新排序,然后选择使用排名靠前的数据作为下游的语言模型输入。如果全部使用大模型,服务的成本较高,带来的延迟会对用户体验产生较大的影响。
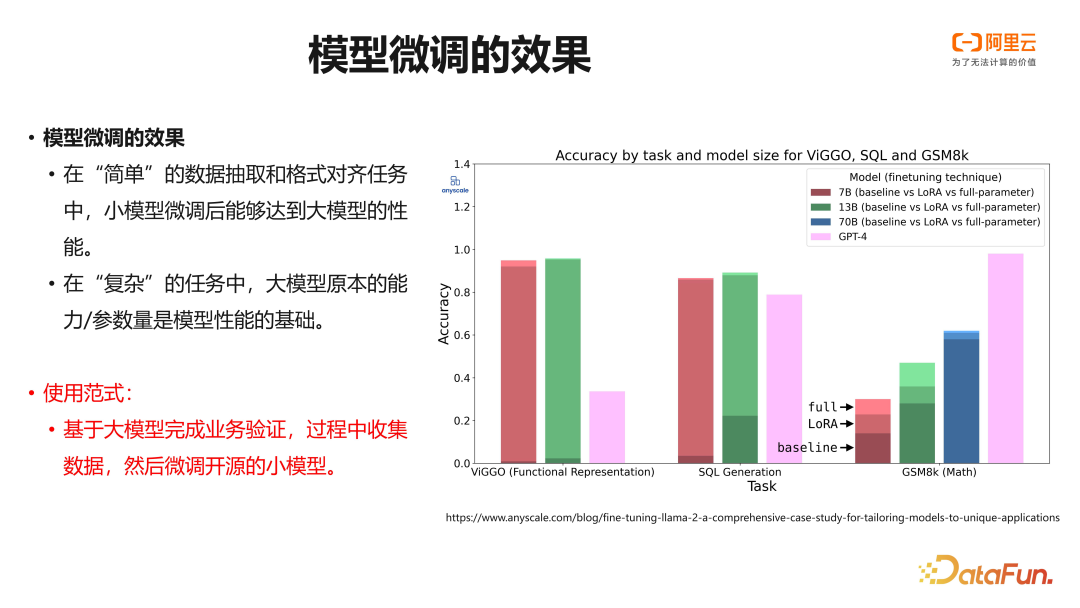
使用小模型能够降低成本和推理延迟,在一定的场景中替代大模型。图示是 Anyscale 的一项实验,其中自左向右依次展示了将文本抽象为函数表示、基于用户意图构建 SQL 和数学推理等三个任务。需要注意的是,实验中的任务难度是从低到高逐步提升的。从与 GPT 4 的比较来看,小模型在简单任务上经过微调后,其性能甚至可能超过大模型。同时模型本身的参数量是大模型能够解决复杂任务的基础。
那么,何时应该对小模型进行微调替代大模型呢?业界应用的一种范式,在业务启动初期,使用如 GPT-4 这样的大模型进行业务验证,并在此过程中收集数据。当业务验证成功且可行后,使用采集到的数据对开源模型微调进行替换,后续通过数据飞轮持续优化自持的模型的表现。
5. 微调能做什么?
总结一下微调究竟能为我们实现哪些目标。首先便是对模型进行优化,通过将知识与信息添加到大语言模型中,提升模型在特定领域的表现,减少模型幻觉。此外,通过微调在一些领域场景中使用小模型替换,优化推理成本和推理延迟。
使用 PAl-QuickStart 微调大语言模型
1. PAI 产品架构
PAI 是一款云端的机器学习平台,属 PaaS 产品范畴。在计算资源层面,PAI支持使用云上通用计算资源,例如 ECS(弹性计算)与 ACK(容器服务)等,同时亦支持 PAI 灵骏计算资源。PAI 灵骏是高性能计算集群,提供高性能 GPU,支持 RDMA 网络及高性能文件存储,尤其适用于大语言模型的训练。
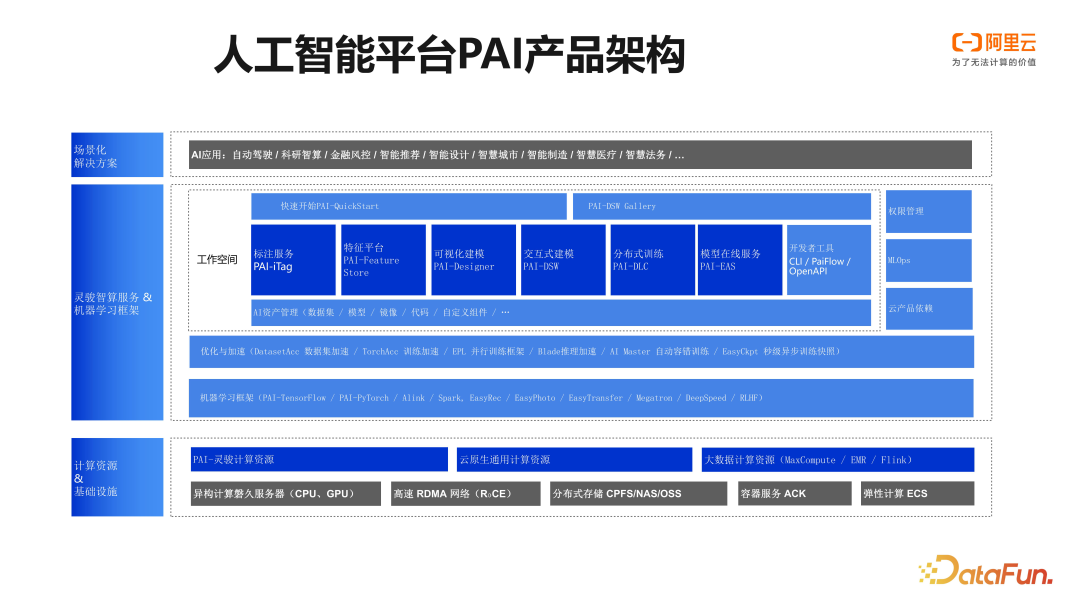
在平台产品方面,PAI 提供了标注服务 PAI-iTag、Notebook 交互式建模 PAI-DSW、大规模分布式训练服务 PAI-DLC,以及极致弹性的模型推理服务 PAI-EAS。计算加速和引擎框架方面,PAI 提供了 DatasetAcc,TorchAcc,Blade 等一系列框架和产品,帮助用户能够在 PAI 上获得极致的性能。在算法方面,PAI 提供 Alink,EasyRec,EasyNLP 等一系列库和算法,支持用户在 PAI 开箱即用。
这些工具和产品帮助 PAI 的用户可以在云上能够更加轻松、高效地完成机器学习模型的开发和应用。
2. PAI 快速开始 ModelGallery
如前所述,机器学习的模型开发应用的范式逐步迁移到以模型为中心。越来越多的开发者倾向于基于预训练模型开发自己的模型或直接将模型进行部署应用。为此 PAI 也提供了新的产品支持——PAI 快速开始 ModelGallery。ModelGallery 提供了大量的预训练模型,包括大语言模型、文生图模型、图片 caption、语音识别等,并支持模型一键微调训练,以及一键部署创建推理服务。
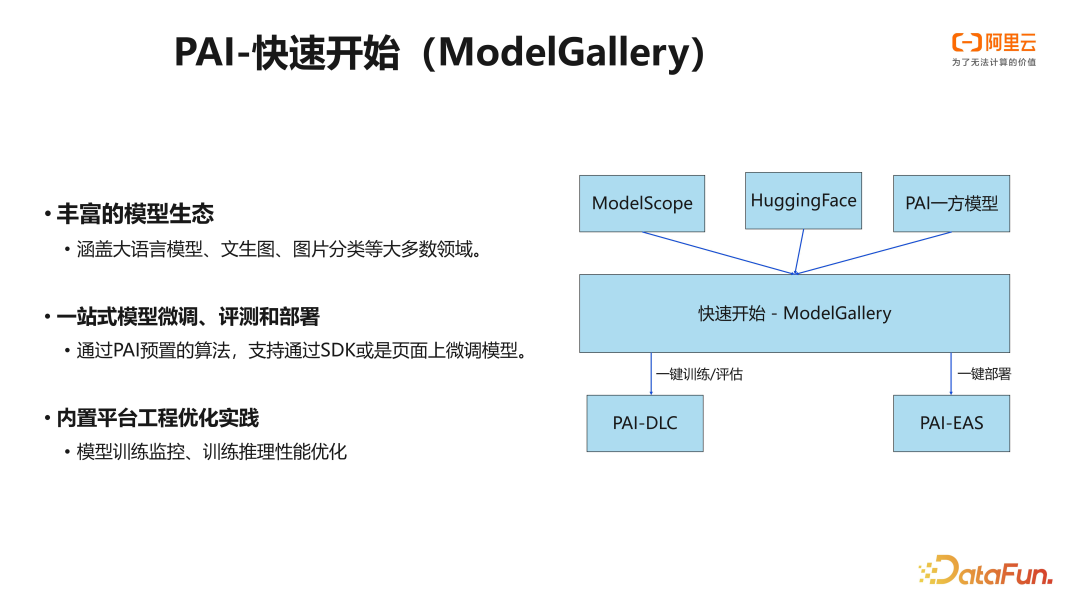
在大语言模型方面,ModelGallery 支持当前主流的开源大语言模型,包括 Qwen,ChatGLM,Baichuan,Gemma,Mixtral 等,并且在这些模型上都预置了相应的微调算法,以及推理服务配置。用户可以通过控制台页面,或是 PAI SDK 的方式调用这些模型。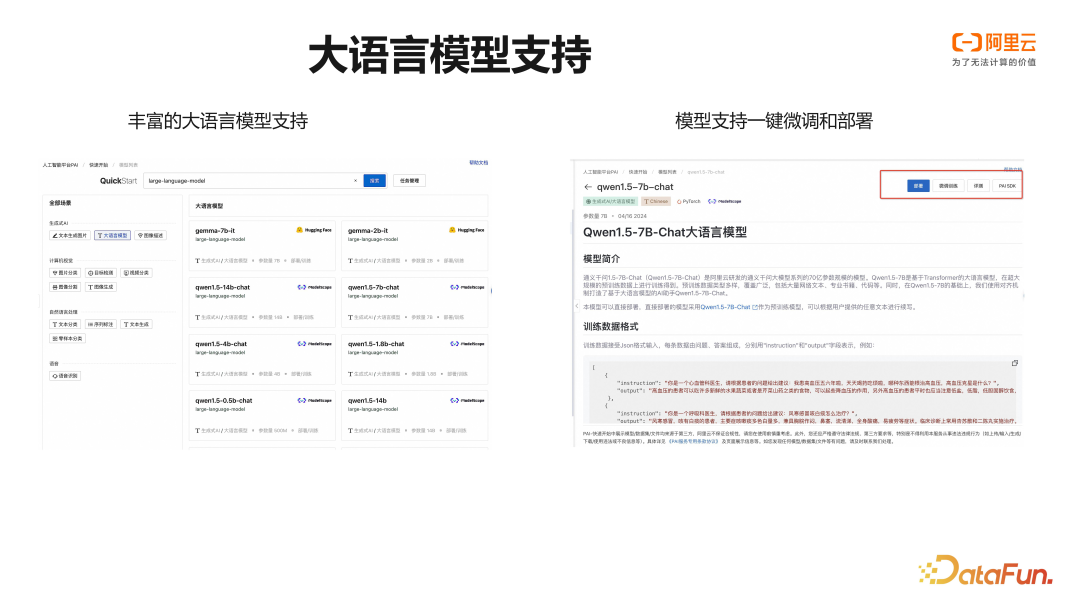
3. 模型训练和部署
以下是 Qwen1.5-7B-Chat 模型的 SDK 调用示例,我们通过数行代码即可调用PAI 预置的镜像和脚本完成对模型的微调训练和部署。通过 RegisteredModel 对象配置 model_provider=“pai“,即可获得 PAI ModelGallery 提供的模型。模型可以通过 deploy 方法直接部署,也支持通过 get_estimator 方法获取模型关联的微调算法,指定 OSS,NAS,或是 MaxCompute 表数据后提交模型微调训练任务,产出的模型将被保存到用户的 OSS Bucket 中。
4. LLM 微调算法
PAI 预置的模型微调训练算法针对云上训练做了一系列的算法工程工作。微调算法支持全参,LoRA,QLoRA 的微调训练方式,支持 OSS,MaxCompute,NAS 等云上数据源上作为训练数据。同时模型也根据不同的训练方法提供了相应的默认机型配置,以及优化的训练作业超参。提交的训练作业支持通过 TensorBoard 进行训练作业监控和任务比对。针对支持的 GPU 卡,默认会开启使用 FlashAttention 优化训练性能。对于更小型的机型,在训练大模型时,会采用 DeepSpeed 技术来优化模型整体的资源占用,以及模型的显存利用率。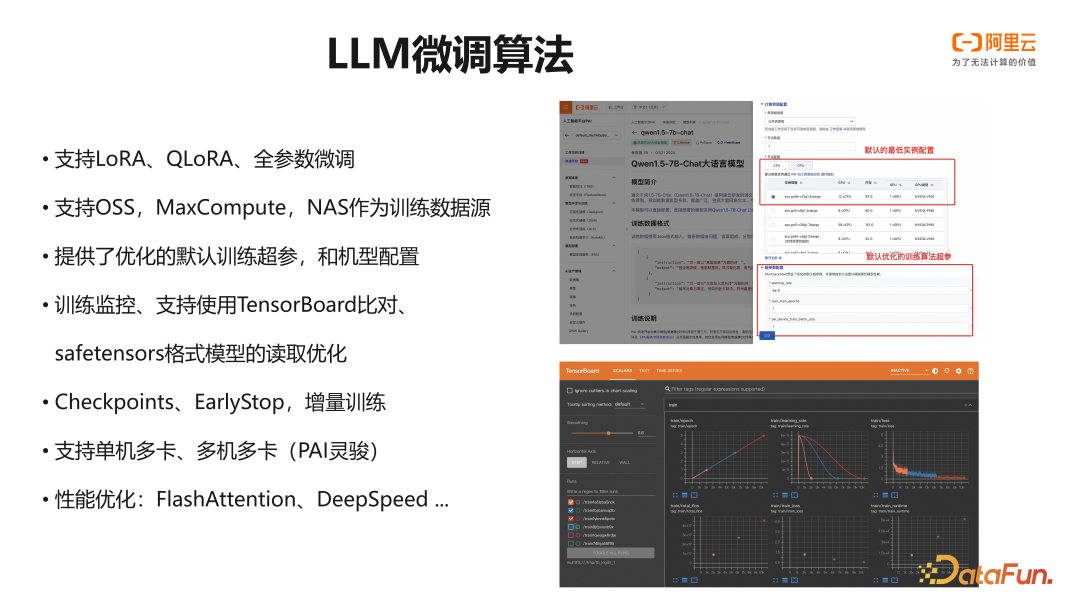
5. 模型评测
在完成模型微调训练后,至关重要的一步是对模型进行评测,以了解模型性能。PAI 目前也提供了针对大型语言模型的一键微调评测功能,借助预置算法组件,我们可以方便地对现有的预训练模型或微调后的模型进行评测。
目前,我们提供的模型评测支持使用公开的数据集对模型进行评测,以评估其通用知识能力是否存在退化;同时也支持通过自定义数据集的评测,以评估其在特定领域的相关性,以及在实际业务场景下的表现,包括其精度如何。此外,我们还可以在页面上将多个评估任务进行汇总,以便对比多个模型的评估结果。
6. 模型推理部署
微调后模型的典型应用场景是将其进行部署为在线推理服务。借助于预置的推理服务镜像,我们可以便捷地将模型部署至 PAI-EAS,从而构建一个推理服务。通过预置镜像部署的服务支持通过 Web 应用方式直接进行交互,也支持以 OpenAI API 方式进行调用。
在推理优化领域,PAI 的推理服务支持 BladeLLM 以及开源的 vLLM 等多种方式进行优化。BladeLLM 是 PAI 自主研发的推理优化引擎,它支持更为丰富的量化策略,在模型的首个 token 返回上表现显著优于 vLLM,而在推理吞吐性能方面则略胜于 vLLM。
模型微调实践
我们一直致力于对模型进行精细调整,并在为用户提供服务的过程中积累了丰富的实践经验,主要包括以下四个方面,即模型微调、模型选择、数据准备以及模型评估。目前PAI 系统支持全参数微调、LoRA 和 QLoRA 三种方法,它们在资源占用和实际性能方面存在差异。
1. 微调方法
首先,最为基本且常见的一种微调方法是全参数微调。在训练过程中,全参数微调不会冻结参数,也不会为参数添加新的层,因为每个参数都会直接参与模型的训练。当使用 Adam 优化器时,使用混合精度进训练,每个参数对应的模型权重、梯度、优化器状态需要占用 16Bytes 的显存空间。以 Qwen(千问) 7B 为例,每个模型的副本实际占用的显存空间高达 112G,这至少需要两张 80GB 显存的 A100 才能完成对 7B 模型的全参数微调。

可训练参数带来的梯度,优化器状态会大大增加显存的需求,LoRA 的思路是通过减少可训练参数来降低显存占用。其基本假设是在模型训练过程中引入的权重变化是低秩的,可以用两个较小的矩阵来近似表示。通过在模型的线性层添加 Adaptor,仅对 Trainable Adaptor 进行训练,可以显著减少可训练参数,从而降低显存占用。
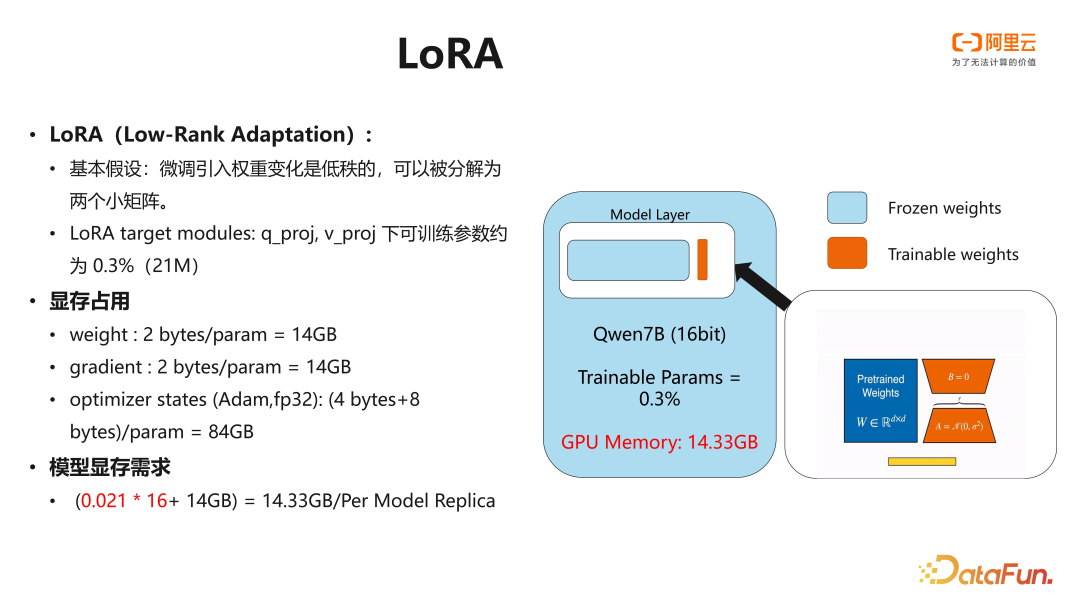
以 Qwen(千问) 7B 为例,如果我们在 q_proj 和 v_proj 这两层上添加 LoRA 的 Adapter,那么整个模型的可训练参数将占模型总参数的约 0.3%,即约为 21 million。由于只有这 21 million 是可训练参数,才会产生梯度和优化器的显存占用,因此,这些可训练参数的显存占用会大大降低,降至约 0.3GB。结合模型本身的权重 14GB,使用 LoRA 后,可以将显存占用降低到约 14.3GB。
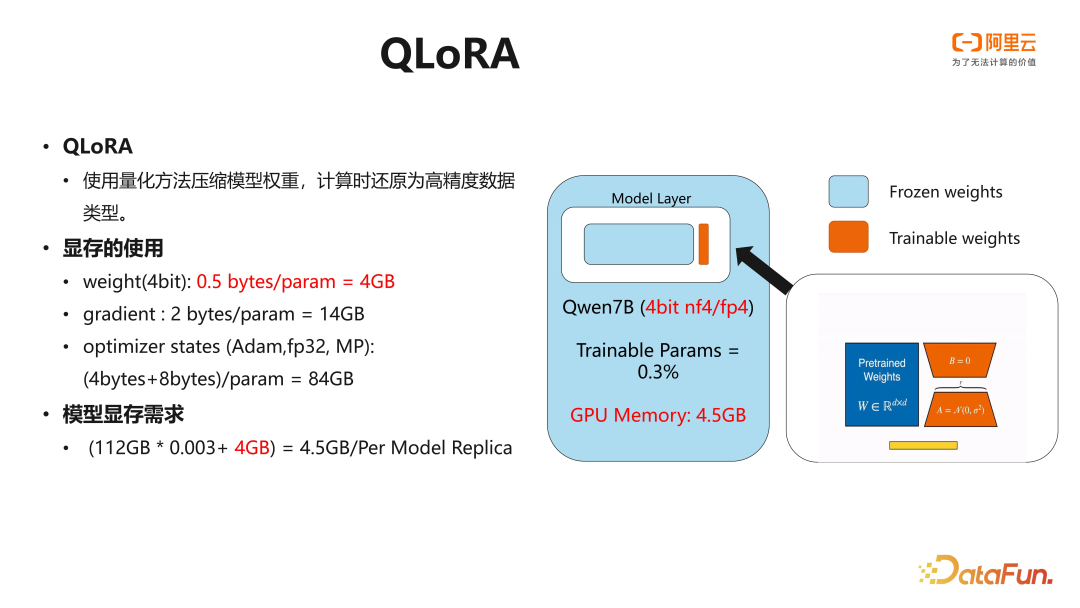
QLoRA 的思路则是在 LoRA 的基础上优化模型权重占用。LoRA 微调训练中,显存占用主要由模型的权重为主。模型的权重是以 16bit 的形式存储的,QLoRA 的思路是在显存中采用量化的方式将模型压缩到 4bit,在计算时再反量化为高精度参与计算。
以 Qwen 7B 为例,通过使用 QLoRA 对模型进行训练,其实际模型的权重仅需 4GB,结合可训练参数的显存占用,每个模型的副本仅需 4.5GB 的显存占用。
下图中的表格列出了 Qwen(千问)模型在实际运行过程中使用不同训练方式的显存占用分值和训练速度之间的比较。与前文所述是一致的,当然也存在一些偏差,主要源于的超参数、序列长度、显存分配等影响。

从原理来看,SFT 全参数微调的可调参数规模更大,能够取得比 LoRA 和 QLoRA 更高的性能。然而,在实际操作中,我们发现通过 SFT 容易导致模型过拟合。因此,我们更倾向于建议用户从 LoRA、QLoRA 基于 Chat 模型开始,通过适当增加 Lora Rank 的方式扩大模型可调空间。若仍无法满足需求,再考虑采用 SFT 全参数微调。
此外,值得注意的是,LoRA 和 QLoRA 的可训练参数规模较小,并不适用于基础模型的训练过程。通常我们期望微调后的模型具备指令遵循、对话的能力,而 LoRA 和 QLoRA 由于可调参数空间较小,较难实现这一目标。
2. 模型选择
在微调基座模型选择上,模型的基础性能是关键因素,目前的开源模型更新迭代迅速,HuggingFace,OpenCompass 等社区提供的 Leaderboard 可以作为模型基础性能的参考。右图是 LMSys 提供的 Chatbot Leaderboard,是一个基于人类反馈打分作为评价标准的榜单,涵盖了主流闭源模型和开源模型。在开源模型中,阿里云的 Qwen 系列模型在 Leaderboard 整体表现不错,在社区中受到广泛认可,欢迎大家进行试用。
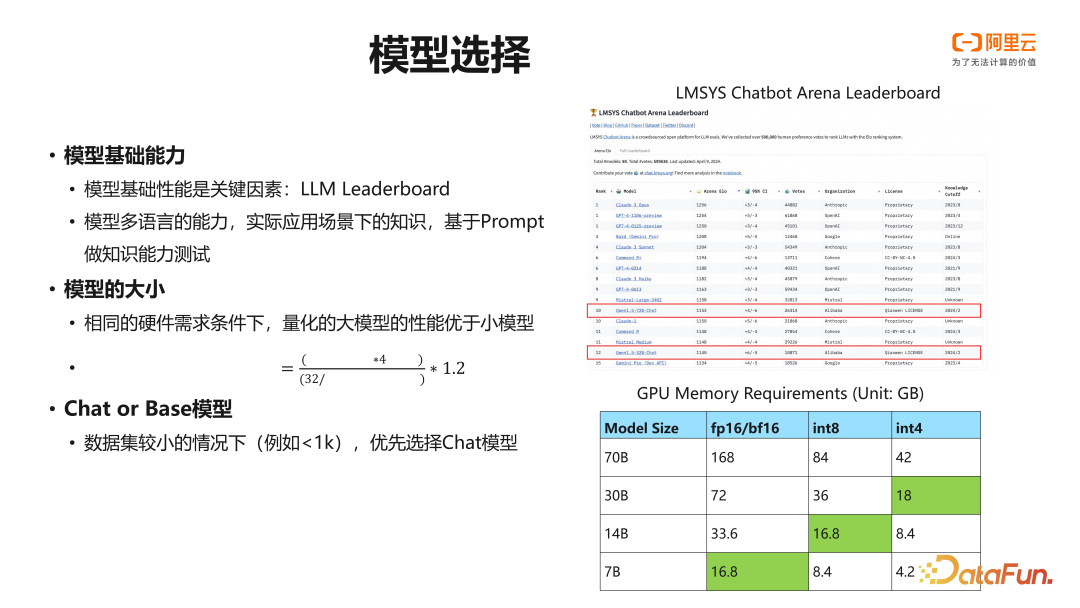
语言模型在训练过程中因为使用的语料,不同领域数据配比,最终获得模型也不是六边形战士,在各个领域都能够完胜其他模型。微调模型的目标通常是针对业务场景进行定制,选择模型时对下游场景进行测试是非常有必要的。如果语言模型本身在下游的领域,例如某一种语言、编码能力,或是某一个领域知识内表现出色,这些能力最终也会体现在微调后的模型上。
选择模型大小的权衡是模型的性能和成本。通常模型微调训练的频率较低,是一次性或是周期性的任务,微调后的模型会被用于部署为在线推理服务,对一定规模的产品,模型会大量部署,长期在线上服务,推理成本是高于训练成本地。另外一点,量化对语言模型的性能影响并不显著,int8 的量化通常被认为是免费午餐,能够很好得提升推理性能,降低推理资源需求。因而通常推荐选择更大的模型进行微调训练,在推理服务部署时使用量化的策略降低资源需求,提高推理性能。
在推理资源需求上,另外一个值得考虑的点是模型架构上是否支持分组注意力(GQA,Grouped Query Attention)。目前的语言模型主要基于 Transformer Decoder 架构,支持通过 KV cache 的加速模型推理。GQA 能够显著降低 KV cache 占用,降低推理资源需求。同时推理的 Decode 阶段是访存密集型的任务,KV cache 的减小能够提升单个请求的推理速度,提升推理服务的整体吞吐。
语言模型经过预训练阶段获得的 Base 模型的能力是预测下一次 token,经过后训练,包括指令微调,基于人类反馈的强化学习,获得的 Chat/Instruct 模型则能够遵循指令,支持对话。在 Chat 模型和 Base 模型选择上,与用户数据量关系紧密。通常下游的场景需要模型具有指令遵循的能力,而数据集较小则较难让 Base 模型学会指令遵循的能力,因而通常推荐基于 Chat 模型进行微调。
3. 数据准备
采用预训练模型能够加速模型的开发迭代,但是要达到理想的效果,往往需要围绕数据展开工作。在实际的微调过程中,至少需要 200 条高质量的数据才能对 Chat 模型进行有效的微调,同时数据量较少的情况下需要适当增加 epoch,才能让模型学习到相应的信息。如果是对 Base 模型进行训练,则至少需要数千条高质量数据。

模型微调数据需要准备问答对形式的数据,数据标注的成本不低。一种解决的方法是通过大型语言模型来生成数据。例如,用户可以将知识库按照知识点进行拆分,然后让语言模型基于这些内容生成问答对,再使用这些问答对进行微调。另一种方法是使用开源的数据集。目前,ModelScope 和 HuggingFace 上提供了一系列开源的对话数据集,用户可以直接使用。
语言模型的输入是一个序列,当将问答对给到语言模型时,需要按一定的规则模版生成序列,这个模版通常被称为 ChatTemplate。不同的模型使用的 ChatTemplate 并不相同,Qwen、ChatGLM 等使用 ChatML格式,而 Llama2、Mixtral 等则是另外一种格式。经过指令微调训练后,Chat 模型能够学会按指定模版格式进行对话和指令。因此,在对 Chat 模型进行微调时,需要注意使用它们已有的 ChatTemplate 生成语言模型输入,否则会与已有知识产生冲突,导致模型无法收敛或指令遵循能力的丢失。
4. 模型评测
目前对大语言模型的评测方式主要包括使用标准数据集、裁判员模型(LLM as Judge),或是基于人类反馈的竞技场模式等方式。标准数据集接入简单,不过存在评测数据泄漏,无法很好的评估复杂生成,或是领域相关任务。基于大语言模型的评估方式对裁判员模型能力要求较高,采用 GPT4 也能够获得接近人类水平的结果,不过裁判员模型也存在倾向于开头部分的、较长的,或是自己生成的答案。基于人类的评估主要局限还是成本高,效率低。
PAI 提供的语言模型评测支持对公开数据集的评测,以及自定义数据集的评测,对自定义数据集的评测采用基于规则的 BLEU 和 ROUGE 系列指标计算模型和标注数据之间的差距。实践中,对公开数据集的评测主要用于评估微调后语言模型是否存在能力退化或是知识遗忘,如果模型的目标任务比较简单确定,例如意图识别,或是 SQL 生成,前者也并非是必须的。目前我们也在规划支持裁判员模型模式,从而提高能够对一些非确定性、生成类任务的评测效果。实际上,在较为复杂的领域任务、内容生成相关的任务中,领域专家的评估结果往往最为准确。由领域专家对模型进行评估,不仅可以评估结果,还可以标记相应的数据。利用标注的数据迭代训练模型,可以取得更好的效果。
5. 实际案例
在此,以一家电视制造商的案例作为参考。他们希望通过引入语言模型来优化整体用户体验。例如,当用户询问“霸王别姬的导演是谁?”等问题时,他们可以调用下游的功能模块来进行查询,因为其功能模块众多,达到上千个,且对推理延迟有一定要求,因此选择通过微调的方式对模型进行定制。

从最终结果来看,由于该任务相对简单,在 Qwen1.5 7B 上的函数识别即能达到较高的效果。不过这里仍有优化空间,因为识别过程分为两步,一部分是函数识别,另一部分是针对函数的参数,如“霸王别姬”中的槽位(slot)识别,目前后者的精度略低,需要进一步优化。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
