参考文献ChartBench 面向复杂图表的认知与推理评测数据集
引言
作者介绍
Jay,清华大学深圳国际研究生院计算机博士研究生,IDEA 实习生
近年来,通用生成式人工智能大模型在语言处理领域展现出了惊人的语义理解和逻辑推理能力,吸引了越来越多企业和研究者的关注。多模态大模型更是通过将图像转换为与文本形式相似的Token,成功实现了对自然图像内容的理解,在多个多模态数据集(如MME、SEED等)上展现了令人信服的性能提升。尽管如此,多模态大模型在实际应用中仍面临诸多挑战,其中可信的图表理解就是一个亟待解决的问题。现有文档中常常包含大量嵌入式图表,以提供更直观和详尽的数据和信息描述。对于自然图像的描述,通常基于可识别的语义对象及其相对位置或作用关系。然而,与自然图像不同,图表通过可视化格式呈现详细而复杂的数据叙述,主要依靠视觉逻辑(如趋势线、图例颜色等元素)来表达数值和实体的映射关系。在我们的测试中,多模态大模型常常无法准确读取图表中的数值,尤其是在没有数据点标注的图表中,其生成的幻觉回答非常严重。当前的多模态大模型严重依赖其OCR能力,但缺乏类似人类的图表逻辑推理能力。因此,合理评估多模态大模型在数据可靠性和内容理解方面的表现至关重要。目前,主流的工作主要使用 ChartQA 等数据集评测多模态大模型的图表理解能力,但是其有着一些固有的缺陷,如图像来源单一、图表类型较少和评估方法不够合理等。特别的,图表上丰富的数据点标记容易导致评测题目退化为简单的 OCR 问题,从而导致无法正确评测模型的视觉逻辑推理能力。基于以上考虑,我们提出了一个新的用于评估多模态大模型图表认知与推理的数据集ChartBench。概述:
ChartBench 通过图表问答的方式评估模型的图表理解能力,它全面评估了多模态大模型在更广泛的图表类型上的性能,包括带注释的图表和未注释的图表。ChartBench 包含超过 68k 个图表和超过 600k 个高质量指令数据,涵盖 9 个主要类别和 42 个子类别图表。此外,ChartBench设计了 5 个不同层次的图表问答任务来评估模型的认知和感知能力。为了评估 模型在未注释图表上的能力,ChartBench 在 42 个类别中都包含了一定数量的未注释图表。实验结果表明,模型在有和没有数据点注释的图表之间存在显着性能差距。为了增强未注释图表的模型能力,ChartBench的训练集中超过 80% 都是没有数据点标注的图表,方便研究者进行对齐预训练或者思维链等其他有效的技术改进。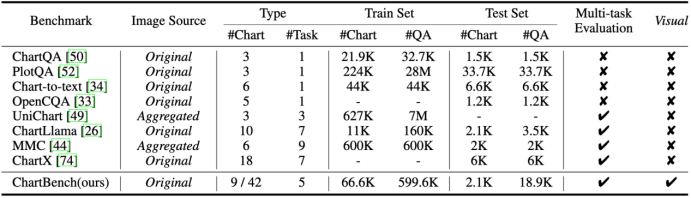
数据收集流程:
下图展示了Chartbench的数据处理流程。其核心思想是生成多种类型的、未标注图表及其对应的指令数据。1)数据收集。为了设计反映现实场景的图表,我们从Kaggle收集适合科学研究的主题和数据,并匿名化所有真实姓名和可识别实体以确保隐私。此外,为了确保图表类型的多样性,我们还利用大型语言模型生成真实的虚拟主题和数据,以补充较为少见的图表类型。2) 数据过滤。我们为42种图表类型建立了标准的JSON格式,并过滤掉所有不符合这些标准的表格数据,以确保图表生成的正确性。3)图表生成。通过有效的数据过滤,我们使用各种绘图库(如Matplotlib,Echart等)绘制各种图表。我们随机应用不同的绘图风格和配色方案,以确保图表的多样性,提供9大类和42个子类的图表。4) 数据集划分。我们随机从每种图表类型选择50个样本来形成评测集。我们在保持基本设置一致的情况下,选择了部分数据通过在线绘图网站进行绘制,以保证图表的风格多样性。5)人工审查。为了保证数据集质量,我们对所有的测试集图表进行了人工审查,以去除有缺陷的或者不显著的图表。指令数据的自动化生成:
ChartBench由5个任务组成,包括感知和推理任务。感知任务主要需要感知和处理原始数据来提取有价值的特征和信息。推理任务涉及处理和理解抽象概念和更高级别的信息。1)类型识别任务旨在评估模型准确识别图表类型的能力。2)数值提取任务旨在评估模型在面对复杂的视觉逻辑时是否可以正确提取相关值。在没有注释数据的情况下,模型需要依赖于图例、坐标轴和其他图表元素来提供答案。概念任务包括两种类型的问答:3) 数值比较任务通过要求模型仅依赖于图形元素而不是元数据(表格数据)来确定答案。4) 全局推理任务评估了感知全局指标(例如最大值)的能力。5) 数值问答任务。对数值提取任务采用了容差评估,以避免数值提取任务中负样本数量过多的问题。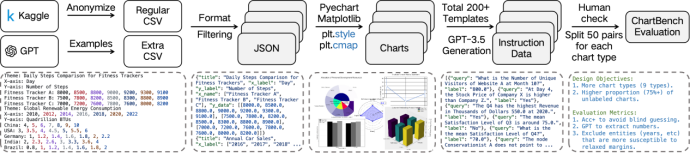
评测指标
Acc+: 我们改进了MME的评测方法,以避免昂贵的大模型评估。对同一个问题采用正反两种提问方式,只有模型能同时正确回答这两种提问,才被认为正确回答了问题。3)不正确的值不是随机生成的,而是从真值的邻域采样的。Confusion Rate: 我们发现,许多模型对两个提问产生相同的输出,可能是因为它们没有利用图表的视觉信息。为了评估这种情况,我们引入了混淆率(CoR)作为度量标准。如果模型没有使用图表中的信息,它往往会生成相同的答案,从而导致CoR接近100%。GPT-acc: 虽然Acc+是一种评估模型响应的有效方法,但它在特定的数值问题上有所不足,因为正确回答负样本并不能完全证明模型的泛化能力。为了解决这个问题,我们改进了ChartQA中的误差范围评估。我们的改进包括:1) 使用大模型来过滤回答并提取数字答案,避免由于额外文本而导致的模式匹配错误; 2) 数值问答任务排除了年月等元素,这类问答可能因为误差范围变得过于宽松,使评估缺乏意义。基线模型
ChartBench主要评估模型理解无数据点标注图表的能力。我们提出了两个简单而有效的基线,可以显着提高模型的性能。ChartCoT:如下图所示,我们提出了基于思维链的有效基线,在不调整模型的情况下增强视觉推理能力。我们设计了一系列的问题以分解用户查询,并使用提示来模拟人类的视觉推理来进行图表识别。此外,我们使模型能够生成自己的思维链,或者寻求更大模型的帮助来生成思维链。这种方法有效地帮助模型理解图表,特别是在视觉逻辑更复杂的情况下。
模型微调:我们基于几个较为优秀的模型进行了两阶段监督微调。在第一阶段,我们使用图表CSV样本对进行对齐训练,以更新连接器参数。在第二阶段,我们利用指令数据对对语言分支进行微调。考虑到图表与中性图像相比并不复杂,我们在微调过程中冻结视觉编码器的参数。实验结果表明,对齐训练有效的提升了模型对无标注图表的理解能力。实验结果
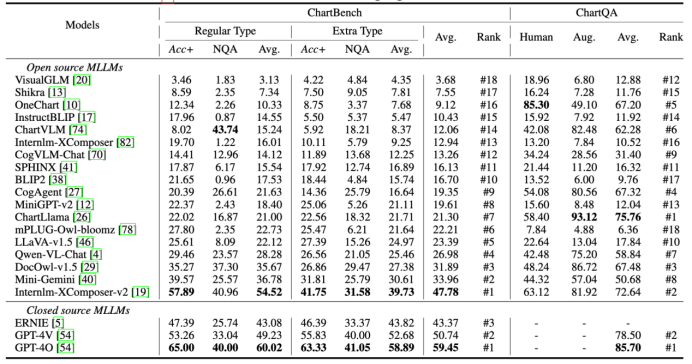
对 18 个开源大模型和 3 个闭源大模型的评测结果
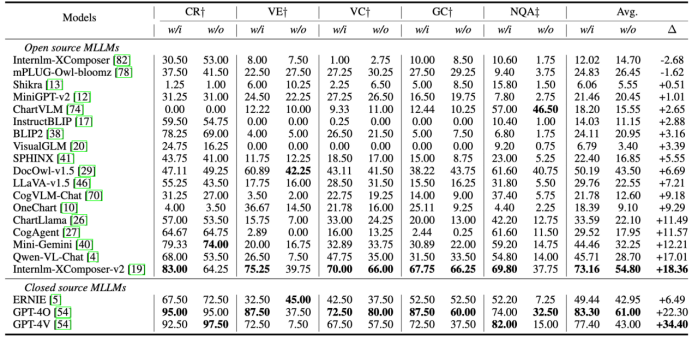
模型在有无数据点标注的图表上的性能差异
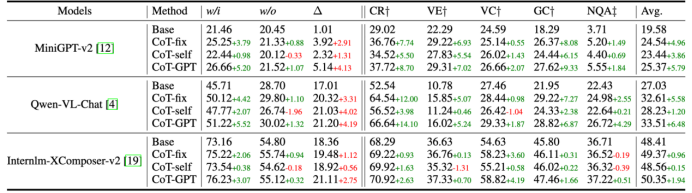
模型应用不同的思维链方法的提升对比

模型使用ChartBench对齐微调后的性能提升
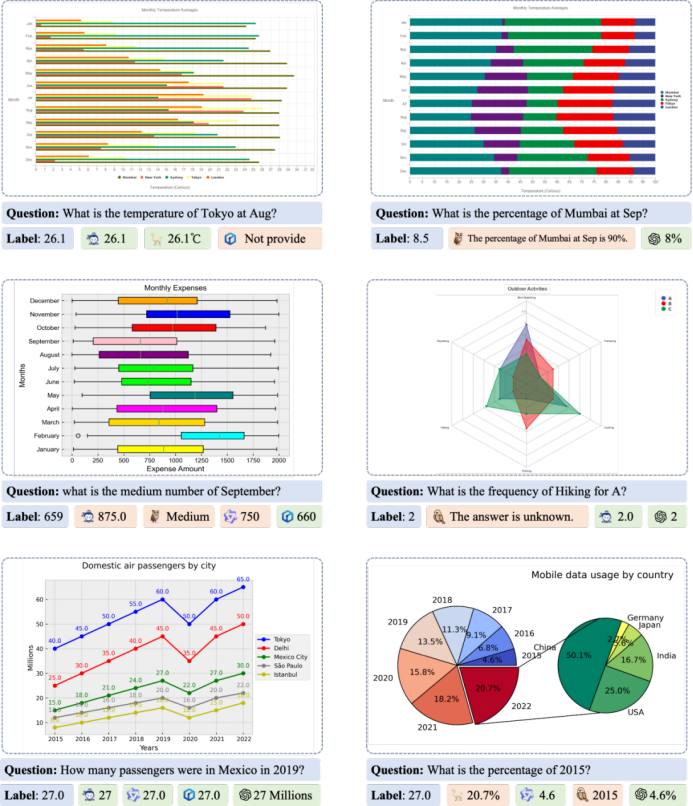
ChartBench评测流程案例的部分可视化结果






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
