导读 随着大模型技术的发展,图文多模态数据在互联网领域的应用越来越多。本文将分享 360 对图文多模态大模型技术的探索和实践。
1. 背景介绍
2. 图文多模态大模型
3. 360 多模态大模型探索
4. 业务落地实践
分享嘉宾|谢春宇 360 多模态团队负责人
编辑整理|Edith
内容校对|李瑶
出品社区|DataFun
背景介绍
1. 什么是大模型
很多人可能认为是因为出现了大模型,才需要很大的算力和大数据。但其实正是有了大数据,才催生了大模型,也对应衍生出了大算力。
2. 在人工智能时代,我们需要什么
2022 年发布的 ChatGPT 将 AI 拉到了一个新的高度,影响力及其广泛,无论是在技术圈还是在大众日常,AI 都成为了一个热门话题。AI 大模型所展现出的能力,也让大家对 AGI 的实现提升了预期。下面图中这段话是由 ChatGPT 生成的,介绍了 ChatGPT 的意义和影响。受益于大参数和大规模数据,生成式模型除了解决特定域问题之外,在对跨域问题的理解上也取得了不错的效果,使模型具有了创造性的开放理解能力。开放理解能力指的是模型不再局限在闭集问题上,而是对开集问题也具有了更好的理解能力。
增加了视觉多模态能力的 GPT-4 为应用层面带来了更多的可能,之后出现的 GPT-4V 视觉能力进一步增强,除了分析和理解图像内容外,还可以对场景进行解释,根据图像生成创意,以及赋予了模型更强大的 OCR 能力。今年推出的 GPT-4O 支持了文本、音频和图像的组合,进一步扩展了多模态能力。
3. 视觉能力是通用人工智能 AGI 需必备的基础能力
视觉-语言跨模态学习是多模态大模型的基础。20 年 OpenAI 推出的 CLIP 是视觉-语言跨模态学习的代表,其原理是分别将视觉编码器 VIT 和文本编码器 Bert 输出的特征做对比学习,进行图片和文本的匹配,缩小对应图片-文本对之间的距离。早在 2016 年,就有相关工作采用了类似的方法,但是 CLIP 通过大数据量的训练让模型有了突破性飞跃。
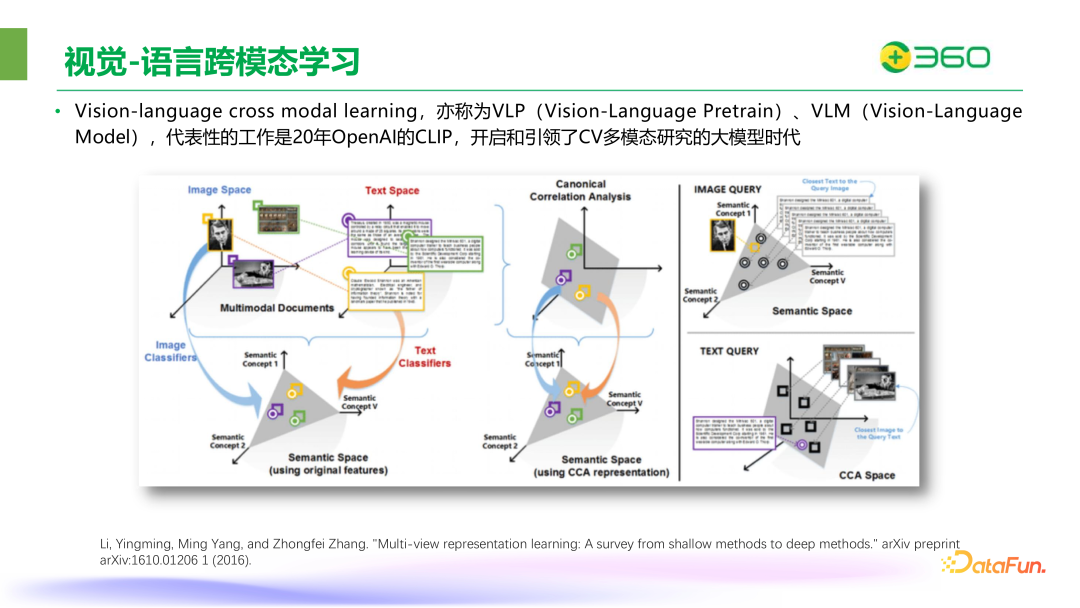
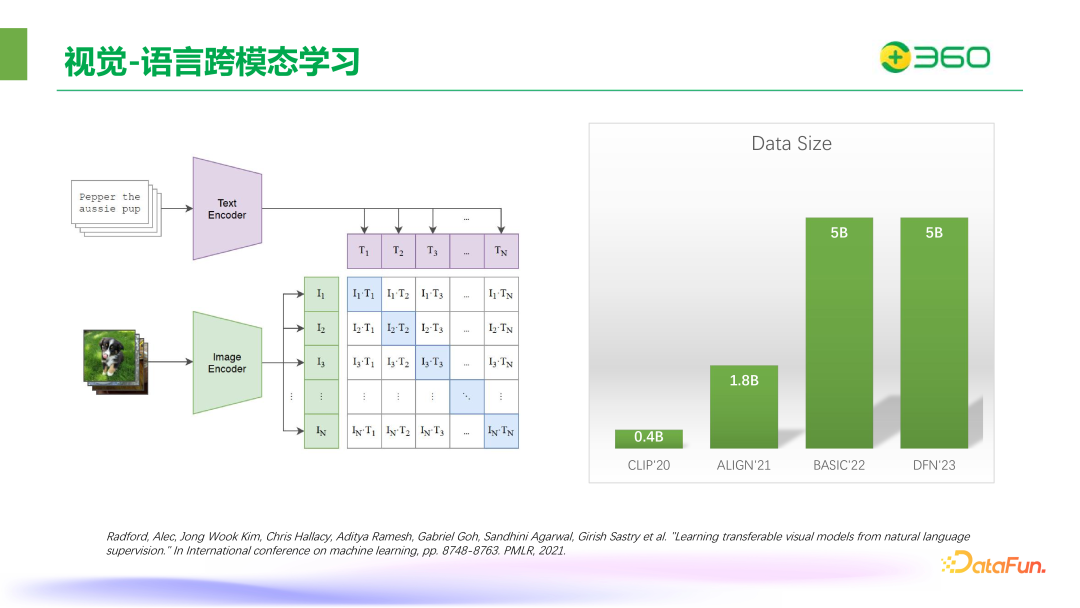
在图文对齐之上也衍生出一些开放理解的能力,例如,CLIP 可以实现 zero-shot 分类。在那之后,各家机构的逐渐扩大了模型训练的数据量,从 0.4B 到 1.8B,去年 Apple 的 DFN 系列的数据量甚至扩展到了 50 亿。
图文的跨模态学习带来的基于内容的图文互检能力,对于 360 搜索的实际业务来说是具有非常重要的落地价值的。下面两个图展示了 360 将多模态技术应用于搜索中的一个能力。左侧是使用多模态技术之前的结果,当用户搜索“这就是爱简谱张杰”时,关键词搜索会让模型搜索出不少张杰的照片,但这并不是用户想要的。当应用了多模态技术之后,搜索结果只显示对应的简谱,优化了搜索的效果。

360 在图文跨模态方面开展了一系列研究工作,2022 年提出了中文的图文跨模态模型 R2D2。该模型采用了双塔加单塔的模型结构,并且基于 EMA 机制的双蒸馏策略,除了对跨模态数据进行 soft label 处理外,还通过特征蒸馏让模型更鲁棒。使用自身采集的 2300 万高质量中文多模态数据进行训练,在当年的中文图文检索任务上达到一个 SOTA 的效果。消融实验结果显示,在相同的模型条件下,使用 2300 万的数据训练的模型能够超过 wukong1 亿数据的效果。

伴随着算法和模型,360 团队开源了对应的图文多模态数据集 Zero:Zero V1 拥有 2300 万的数据,Zero V2 达到了 2.5 亿的数据规模。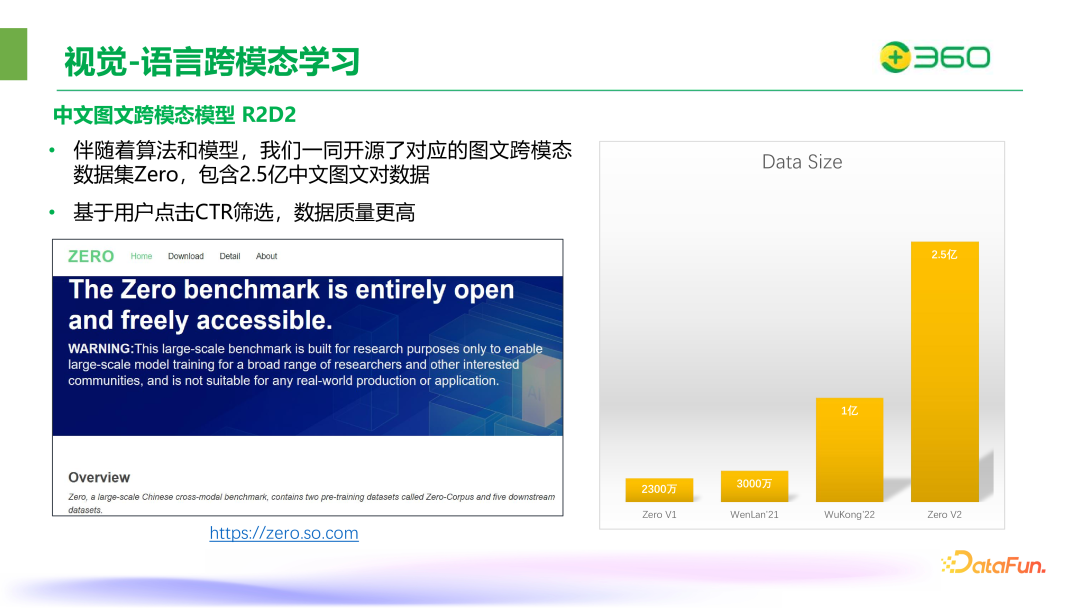
图文多模态大模型
1. 多模态大模型的研究路线
多模态大模型简称为 LMM(Large Multimodal Model),也称为 MLLM(Multimodal Large Language Model),目前有小部分工作为了强调视觉能力,将其称为 LVM(Large Vision Model)。LMM 是在单文本模态的语言模型基础上发展起来的研究方向,赋予了大模型对动态信息混合输入的理解和处理。
相关的研究路线主要分为两条:一条是原生多模态路线,模型设计从一开始就专门针对多模态数据进行适配设计,代表性的工作有 MSRA 的 KOSMOS、Google 的 Gemeni、OpenAI 的 GPT-4O;另一条是单模态专家模型缝合路线,通过桥接层将预训练的视觉专家模型与预训练的语言模型链接起来,代表性的工作有 23 年 1 月 Saleforce 的 BLIP-2,以及近期的 Idefics2 和 InternVL2 等。
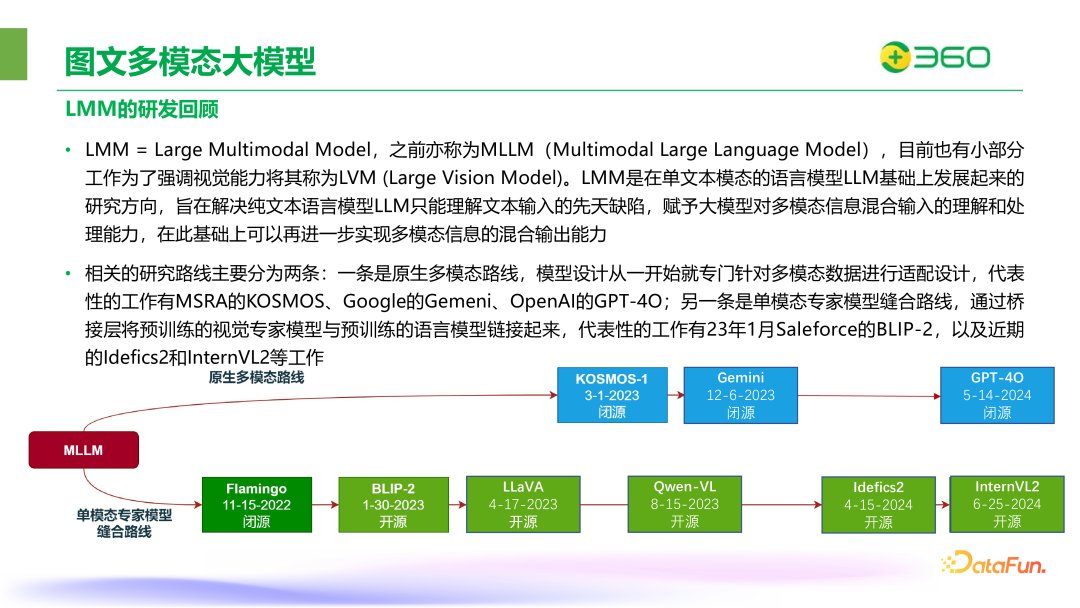
原生多模态路线的理论上限更高,但对应的是训练成本远高于缝合路线。缝合路线可以复用各个单模态领域的已有成果,因此具有很经济的训练成本优势。少数的巨头机构采用的是原生多模态路线,其它绝大多数企业和学界研究机构采用的是缝合路线。下图中右侧是关于训练成本的统计,对应的是一个月使用 A100 卡的数量,可以从图中观察到像 PALM-E 这种原生多模态模型的成本是非常高的。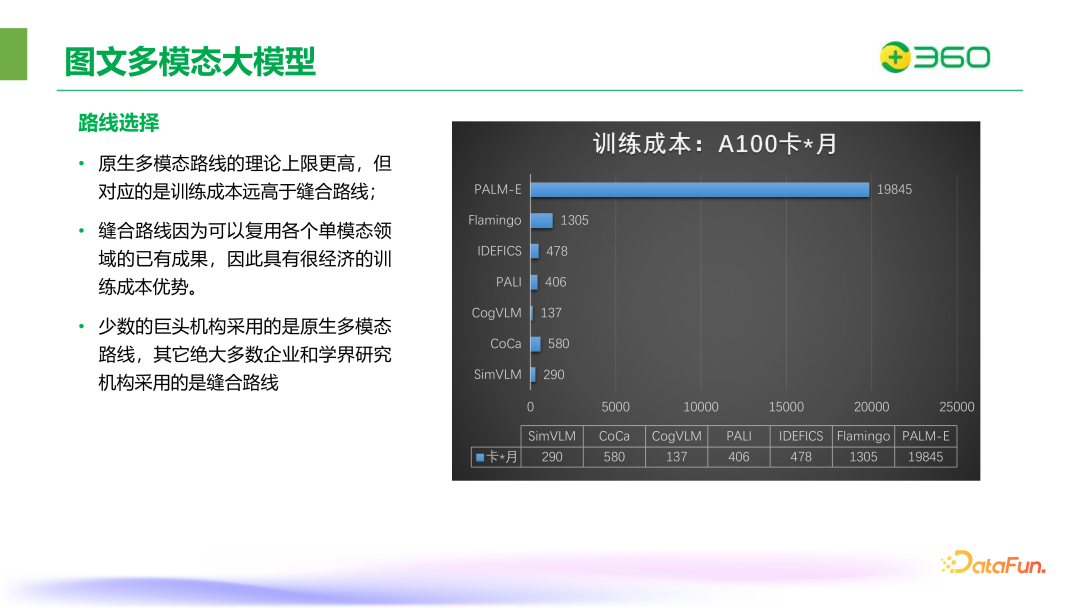
2. 多模态大模型的三代发展
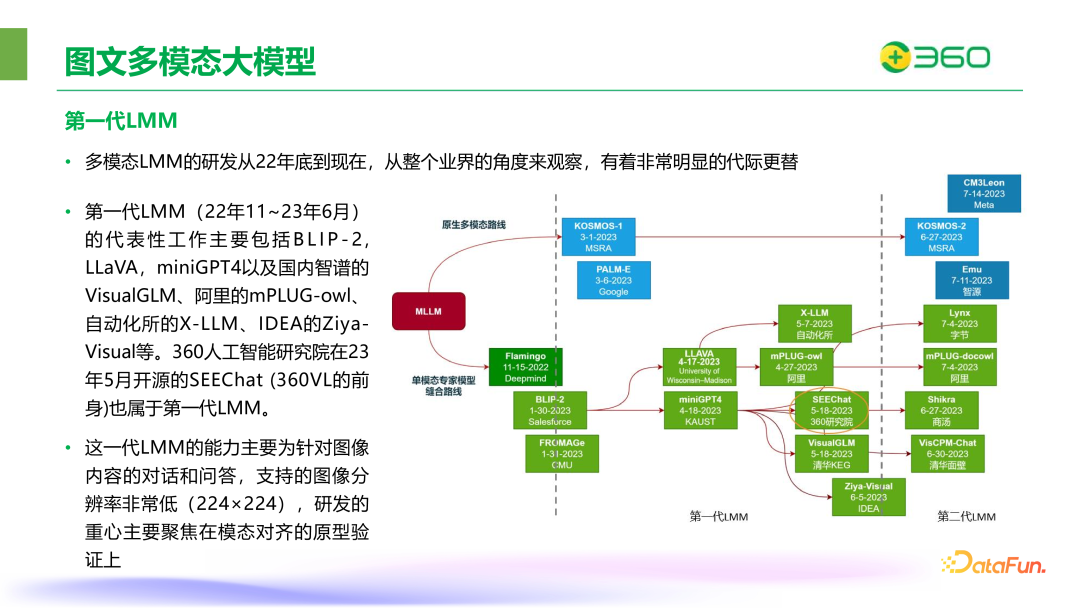
2022 年底到现在,统观整个业界,多模态大模型的研发有着比较明显的代际更迭,这里按照时间线将多模态大模型划分成三代。
第一代 LMM,从 22 年 11 月至 23 年 6 月,其间的代表性工作主要包括 BLIP-2,LLaVA,miniGPT4 以及国内智谱的 VisualGLM、阿里的 mPLUG-owl、自动化所的 X-LLM、IDEA 的 Ziya-Visual 等。360 人工智能研究院在 23 年 5 月开源的 SEEChat (360VL 的前身)也属于第一代 LMM。这一代 LMM 的能力主要为针对图像内容的对话和问答,支持的图像分辨率非常低(224×224),研发的重心主要聚焦在模态对齐的原型验证上。
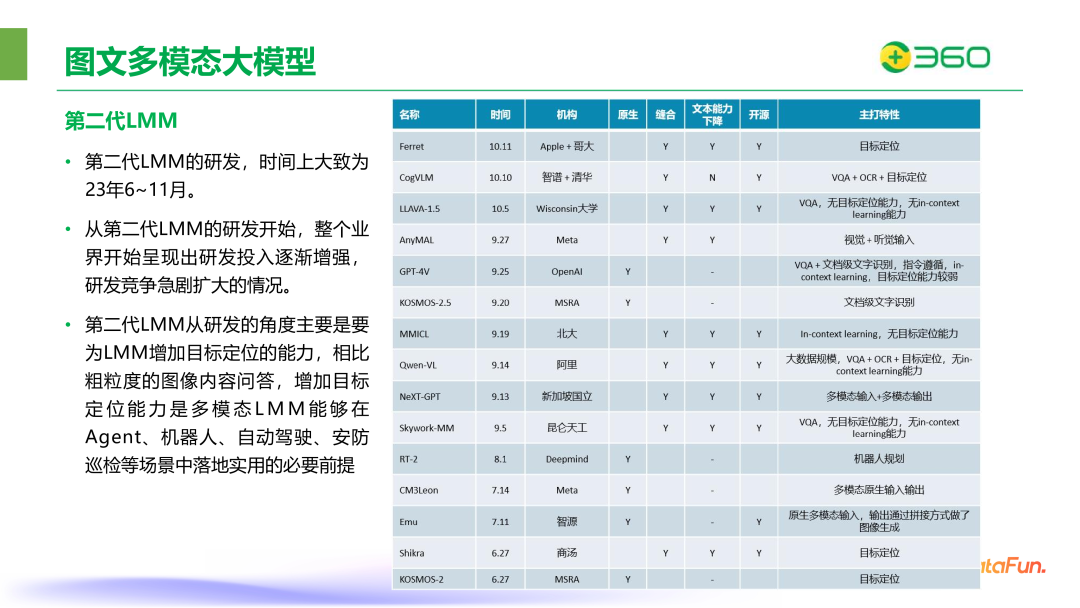
第二代 LMM 的研发,时间上大致为 23 年 6~11 月。从第二代 LMM 的研发开始,整个业界开始呈现出研发投入逐渐增强,研发竞争急剧扩大的情况。第二代 LMM 从研发的角度主要是要为 LMM 增加目标定位的能力,相比粗粒度的图像内容问答,增加目标定位能力是多模态 LMM 能够在 Agent、机器人、自动驾驶、安防巡检等场景中落地实用的必要前提。
从去年年底到现在,进入了第三代多模态大模型的研发。在第二代多模态大模型中暴露出的几个关键问题,需要在第三代的研发中进一步解决。

较低的分辨率限制了模型性能的进一步提升。第一代 LMM 所能处理的图像分辨率固定为 224(对应图像 token 32~256),第二代 LMM 的典型分辨率是 336~448。主要制约因素是训练的成本和语言模型的窗口大小:一方面图像分辨率越高,图像编码后的 image token 数越多,对应的训练成本越高;另一方面 23 年语言模型的输入窗口大小普遍在1K 左右,过长的图像编码 token 长度会压缩文本输入的空间,导致问答能力下降。图像分辨率支持不够高带来的问题,一方面是 LMM 在图像对话/问答中对细节的理解能力受限,另一方面更为重要的是作为通用模型的 LMM 很难在下游任务上实现对传统专业模型的超越,这也是目前 LMM 在实际落地应用中最显著的障碍。目前第三代 LMM 模型通过将输入图像切块的方式已基本解决了高分辨率图像支持的技术障碍,同期语言模型的输入窗口也普遍从 1K 提升到 4K、8K 甚至几十万字,24 年 2 月后开始陆续有第三代 LMM 的工作实现了高分辨率以及混合分辨率的支持,代表性的工作有 LLaVA 1.6,阿里的 QwenVL-plus/max,金山的 Monkey,旷视的 Vary 等工作。

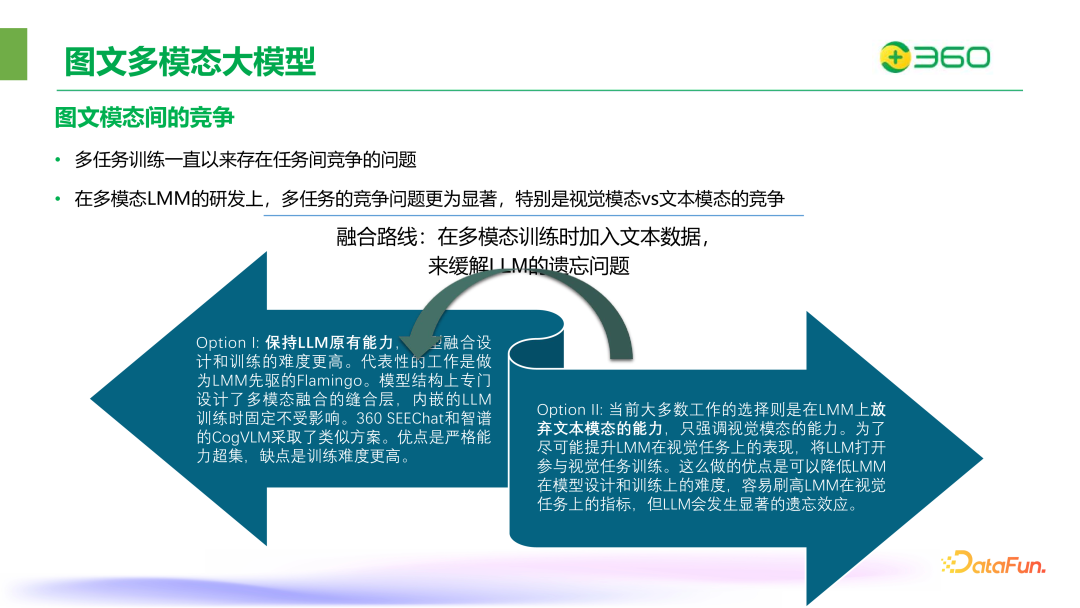
多任务训练一直以来存在任务间竞争的问题。在多模态 LMM 的研发上,多任务的竞争问题更为显著,特别是视觉模态和文本模态之间的竞争,这一时期的工作普遍都会有语言模型能力下降的问题。有三种解决方法:
保持 LLM 原有能力,模型融合设计和训练的难度更高。代表性的工作是做为 LMM 先驱的 Flamingo。模型结构上专门设计了多模态融合的缝合层,内嵌的 LLM 训练时固定不受影响。360 SEEChat 和智谱的 CogVLM 采取了类似方案。优点是严格能力超集,缺点是训练难度更高。
当前大多数工作的选择则是在 LMM 上放弃文本模态的能力,只强调视觉模态的能力。为了尽可能提升 LMM 在视觉任务上的表现,将 LLM 打开参与视觉任务训练。这么做的优点是可以降低 LMM 在模型设计和训练上的难度,容易刷高 LMM 在视觉任务上的指标,但 LLM 会发生显著的遗忘效应。
融合路线,在多模态训练时加入文本数据,来缓解 LLM 的遗忘问题。
(3)更多的数据引入可能不能带来模型能力上的提升。
当前缝合路线的模型结构基本已经收敛为 image encoder + projector + LLM 的结构,其中 image
encoder 负责图像编码,LLM 负责对话逻辑,projector 作为缝合层将视觉编码器和语言模型进行桥接缝合。但是当前以 LLaVA 为代表的浅层缝合模型,通常在百万训练量级后就已经饱和,将训练量提高到千万甚至几亿的量级并不能带来 LMM 模型能力的明显提升。背后的根本原因,要追溯到缝合路线下 LMM 中内嵌的语言模型能力是否需要保持。对于这个问题,有两种解决方案:
方案一:在 image encoder + projector 上做文章,将海量数据的信息在预训练阶段训练到视觉编码器和缝合层中,语言模型参数仅在最后的指令微调阶段参与训练。代表性的工作包括国内零一万物的 Yi-VL,书生浦语 InternLM-XComposer-VL,韩国 KaKaoBrain 的 Honeybee 等。
方案二:在多模态训练过程中也同步加入相当比例的纯文本训练数据同时进行训练,代表性的工作包括 Apple 的 MM1 和国内幻方的 Deepseek-VL 等工作。

下面列举了一部分三代的多模态大模型,单模态专家模型缝合路线的大模型要比原生多模态大模型多很多。360 团队在 23 年 5 月开源了 SEEChat,在今年 5 月份开源了 360VL。LLaVA 和 GPT-4 是行业内比较早期且经典的多模态大模型的形式,被如今许多多模态大模型借鉴。之后推出了中文版多模态大模型,可以实现图像描述对话等任务。Deepseek-VL 做了详细的消融实验,同时探索了纯文本数据加动态数据混合训练来让模型的语言能力不退化。InternVL 系列其实也是在不断提升中,在 benchmark 上拿到了很高的分数。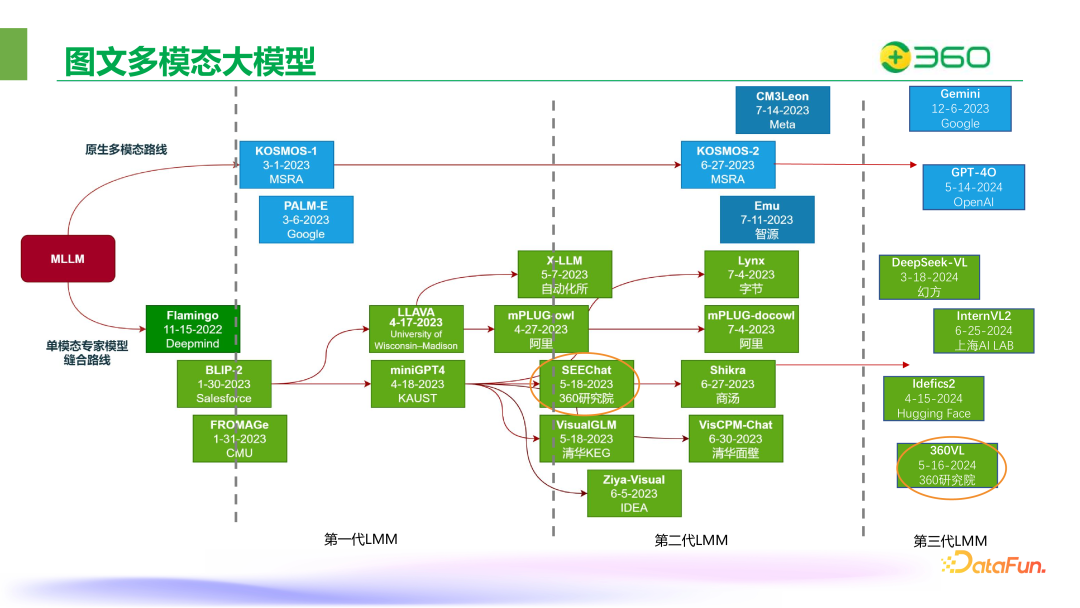
360 多模态大模型探索
1. SEEChat
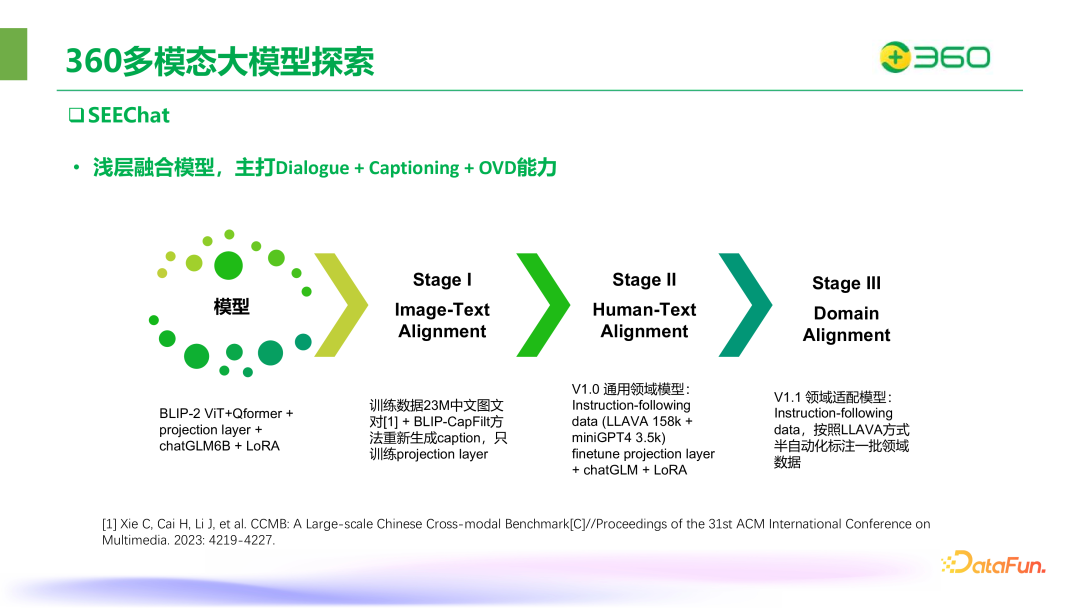
在 2023 年的 5 月份,360 提出了基于单模态专家缝合方案的多模态模型 SEEChat,核心原理是将视觉能力和现有的 LLM 模型相融合。该模型具有以下两个特点,一是严格超集,强调不影响原模型原有的能力;另外一个是 OVD 能力,即开放世界目标检测,在对图像内容的整体理解之外,能够同步给出涉及目标在图像中出现的位置。

模型结构采用了 BLIP-2 ViT+Qformer+MLP+chatGLM6B+LoRA,chatGLM6B 主打中文能力,训练数据使用了开源的 zero 数据。前文中已介绍,zero 是大规模中文多模态数据集,包括了图像的长文本和 query,有着较高的质量,能在中文任务上取得不错的效果。在指令微调上,360 团队构建了中文的微调数据,并对特定领域构造了适配数据。
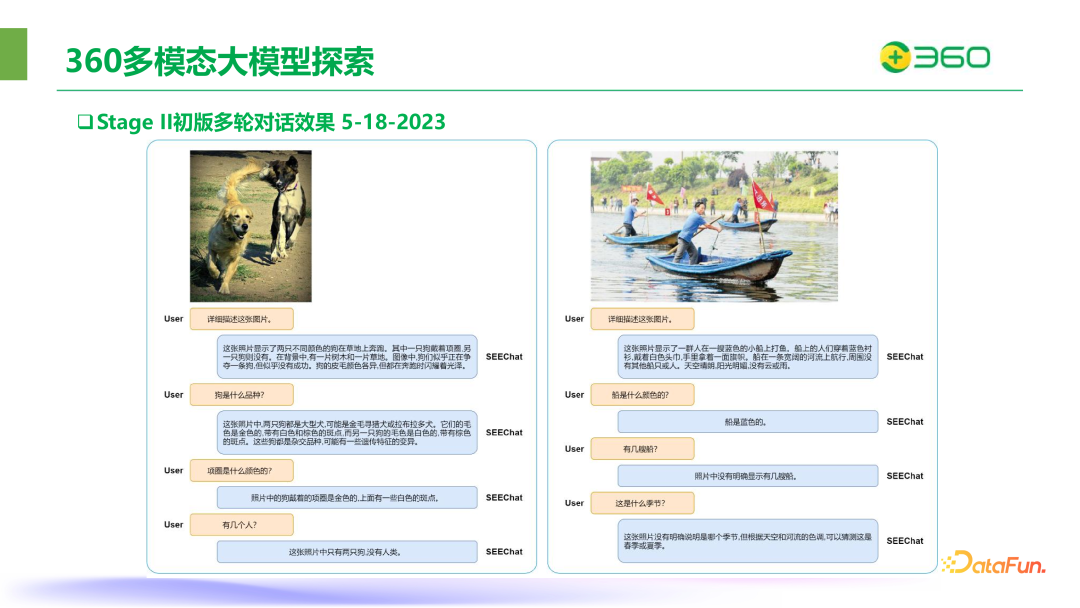
下面这张图是 SEEChat 在 23 年 5 月 18 号开源的模型版本的效果,可以看到除了中文描述能力比较好以外,能认出图中的狗有一只是带着项圈,而另外一只没有带,还能认出狗的品种。模型还可以判断船的颜色,并根据整个场景去推测出当时的季节。模型在识别物体的品种、颜色、数量上都展现出了一定的能力。
下面是对一个街景的描述,模型首先是对图片的详细描述,然后再对整个场景里的人物和物体进行补充的描述,同时能辨别是白天还是晚上,出租车的颜色,以及人物性别。

下图还能够看出当前是一个阳光明媚的天气,并根据人们穿着的衣服如短袖短裤,推测是夏季或者炎热的季节,此外,能够对人数,房子的颜色进行判断。

这几个案例,展现了 SEEChat 在图像理解上的能力以及在中文对话上的性能。除了模型自身的能力以外,高质量的中文训练数据和微调数据给模型带来了很大的收益。在 SEEChat 之后,360 团队又进行了详尽的探索:
- 在大语言模型上,先后对 QWen2、Llama3、Vicuna1.5 和 Chatglm 进行了实验。
- 在视觉工作上,对 Siglip、CLIP-Vit 和 DFN 等结构进行了探索。
- 进行了高分辨率实验,包括训练了一个高分辨率 ViT,以及滑窗策略。
- 在 connector 上,进行了几种不同结构的实验。因为 MLP 和 resampler 的缺陷,360 团队采用了 CNN 形式的 connector。在保证空间信息丢失不严重的同时,使用 adaptive pooling 对图像 token 数进行灵活操作。
- 数据方面,除了使用 caption 对齐数据,也重点加入了 detection 数据,从而使模型能获得很好的检测性能,内部还进行了数据清洗和积累帮助模型取得更好的表现。
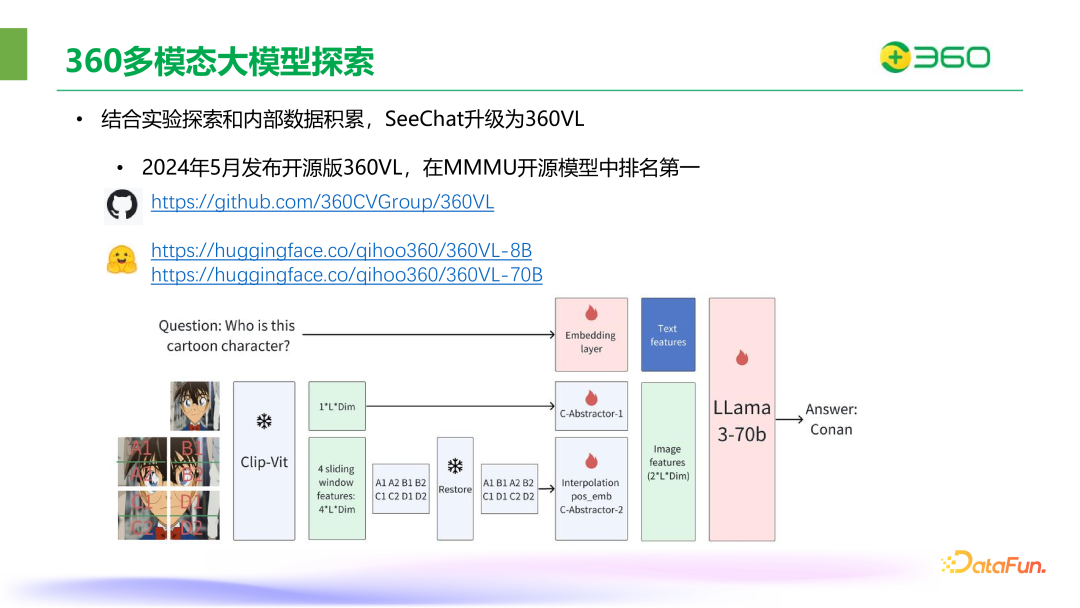
2. SEEChat 升级为 360VL
结合实验的探索和内部数据的积累,360 团队将 SEEChat 升级成了 360 VL,也是在今年五月份发布了 Llama3 版本的 360 VL 多模态大模型,这个版本的模型是基于小批次开源数据训练的。模型发布的时候,360VL 在 MMMU 的开源模型中排名第一,且在 GitHub 和 Huggingface 都已开源。
这是一张 360 团队去年团建的照片,360 VL 除了具有理解任务和物体的能力,还能通过人物表情和站位推测出照片的整体氛围是轻松愉快的。
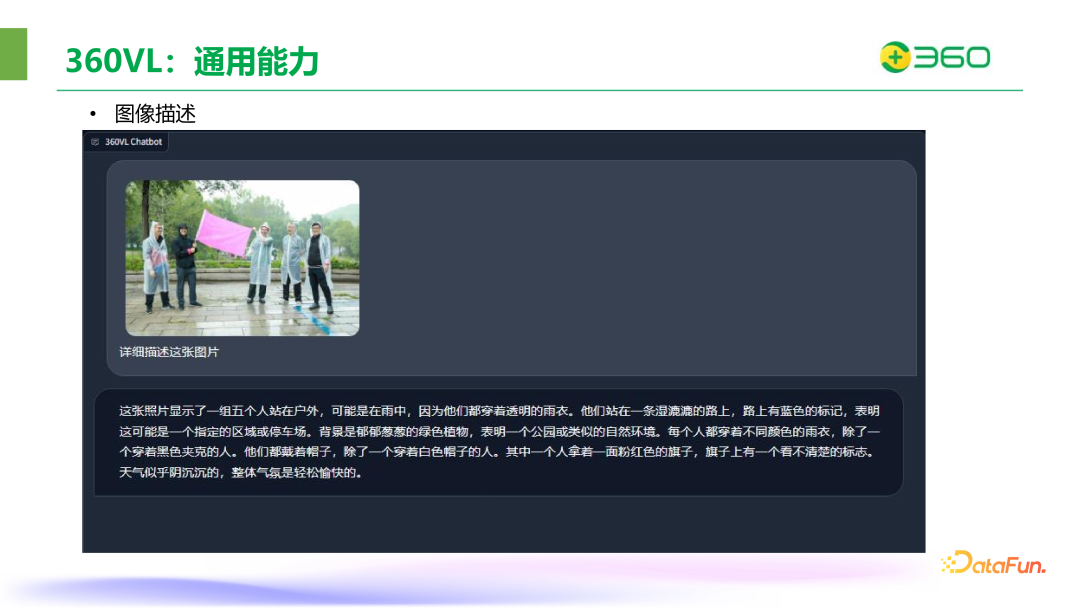
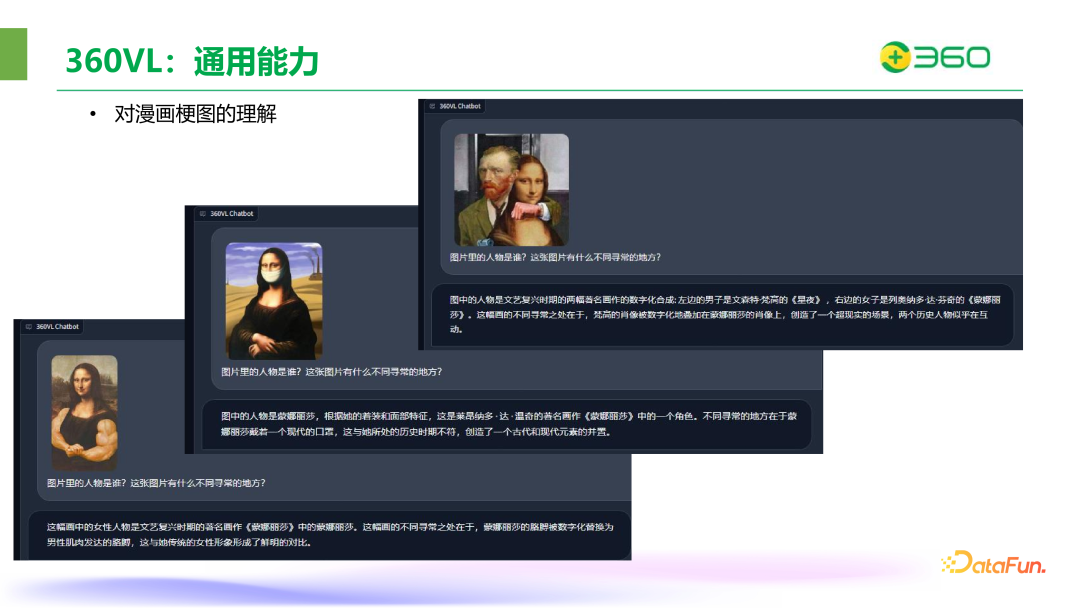
360 VL 能理解漫画梗图,对蒙娜丽莎的不同魔改,360VL 都能给出自己的见解。
下面这张图是重点强调的开放世界目标检测能力。360VL 可以对图中的多种物体进行检测,即使在某些开源数据标注框缺失的情况下,360VL 也能对物体做一个更完整全面的检测。
3. Inner-Adaptor
Architecture
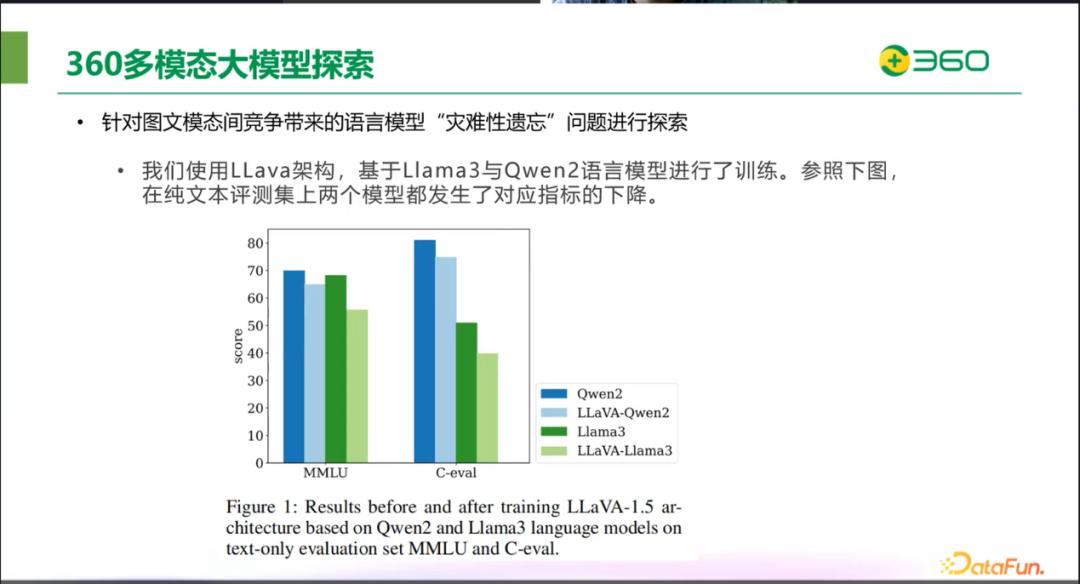
针对前面提出的当前多模态大模型的挑战,360 团队也进行了一定探索。在多模态大模型中,图文模态的竞争给语言模型带来了比较明显的遗忘效应。360 团队使用 LLaVA 架构,基于 Llama3 和 QWen2 的语言模型进行训练。下图是在 MMLU 等纯文本评测集上的结果。在 LLaVA 的架构下,使用多模态数据进行训练后,指标有一定下降。以 MMLU 举例,QWen2(深蓝色柱子)代表原始语言模型的能力。而用 LLaVA 架构去训练后,可以看到能力出现了下降(浅蓝色柱子)。
防止大语言模型能力下降的一种直接方法是在训练过程中冻结大语言模型。然而目前采用这种方法的方法(Blip2,Flamingo,SEEChat)无法取得足够强的多模态能力。为了克服这些挑战,360 团队提出一种新的结构:Inner-Adaptor Architecture(简写为 IAA)。它具备以下优势:
IAA 在多模态评测集 MME、MMB、MMMU 与 Grounding 评测集上取得了很好的效果。
第一个工作流是多模态的工作流,包括图像编码器和桥接层以及语言模型。图像编码器使用的是 CLIP ViT-L/14,桥接层为两层 MLP,使用 Llama3-8B 作为基础语言模。
在多模态的工作流中加入了 insertion layer 是由对应的 language model layer 去初始化来的。同时,针对多模态任务引入了新的 embedding layer 和 language head,同样由原始 Llama3 初始化。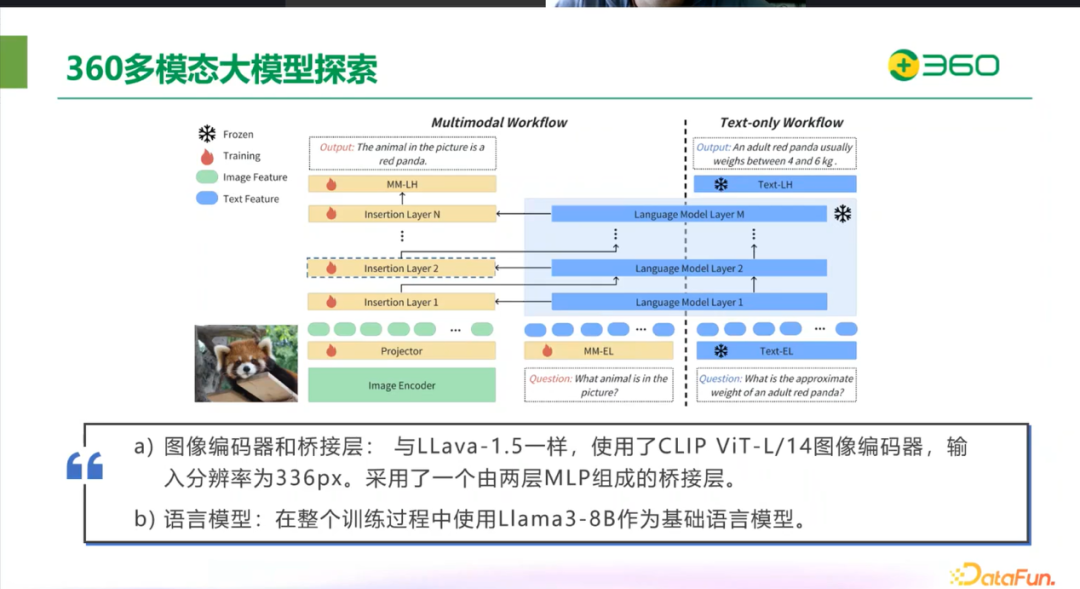
IAA 结构的探索的过程受到了 ControlNet 架构的启发:
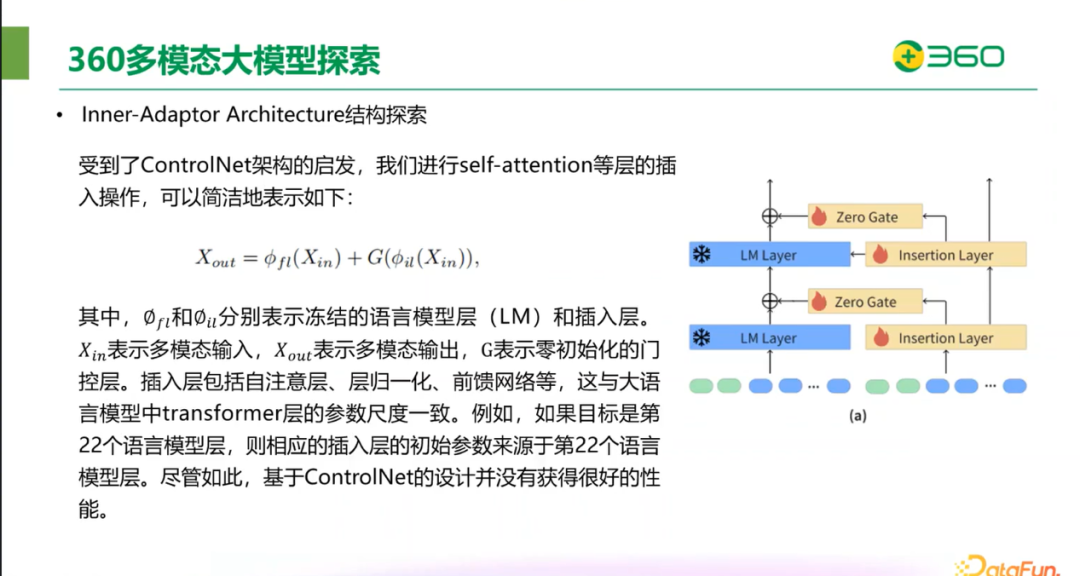
360 团队对基于 ControlNet 的结构进行了进一步改进,消除了插入层之间的特征传播,将语言模型层的输出作为插入层的输入。每个冻结的 LM 层将通过一个插入层和门控层来容纳多模态数据,而插入层不再直接受到后续影响。门控层可能无法通过 LMM 常用的单轮数据训练策略达到最佳状态。因此有一个更精简的解决方案,如果将插入层放置在第 22 个冻结的 LM 层之后,则使用第 22 个冻结的 LM 层参数进行初始化。训练的模型中,插入层的参数可以任意指定。
在实验中,对于 IAA 来说,如果使用过高的学习率,会导致训练损失不稳定且溢出。为了解决这个问题,设计了一个两阶段的预训练策略:在第一阶段,模型由图像编码器,MLP 投影层和大语言模型组成,除了 MLP 外其他参数均冻结,在第一阶段使用 0.001 的高学习率来学习高质量的投影层。第二阶段,模型加入了专门用于处理多模态任务的 IAA。在这个阶段,360 团队使用更低的学习率 2e-5 学习 MLP 和 IAA 的参数。完成预训练后,模型还会接受进一步的指令微调和视觉定位微调,优化性能。
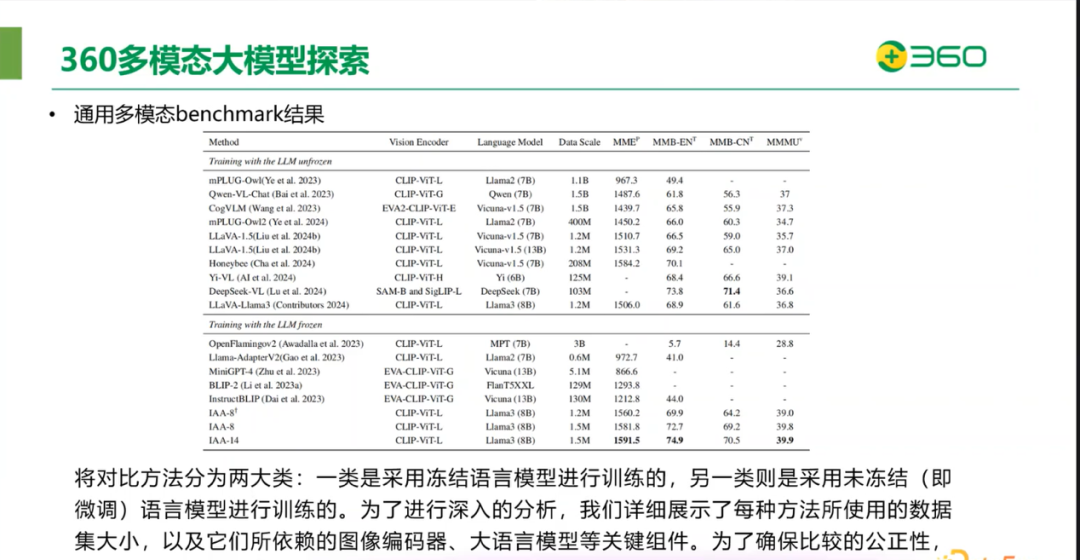
将对比方法分为两大类,一类是采用冻结语言模型进行训练的,另一类则是采用未冻结(微调)语言模型进行训练的。为了进行深入的分析,360 团队详细展示了每种方法所使用的数据集大小,以及所依赖的图像编码器,大语言模型等关键组件。为了确保比较的公正性,选择了参数规模相似的 LMM,并且这些方法的性能指标都是基于官方公布的数据。
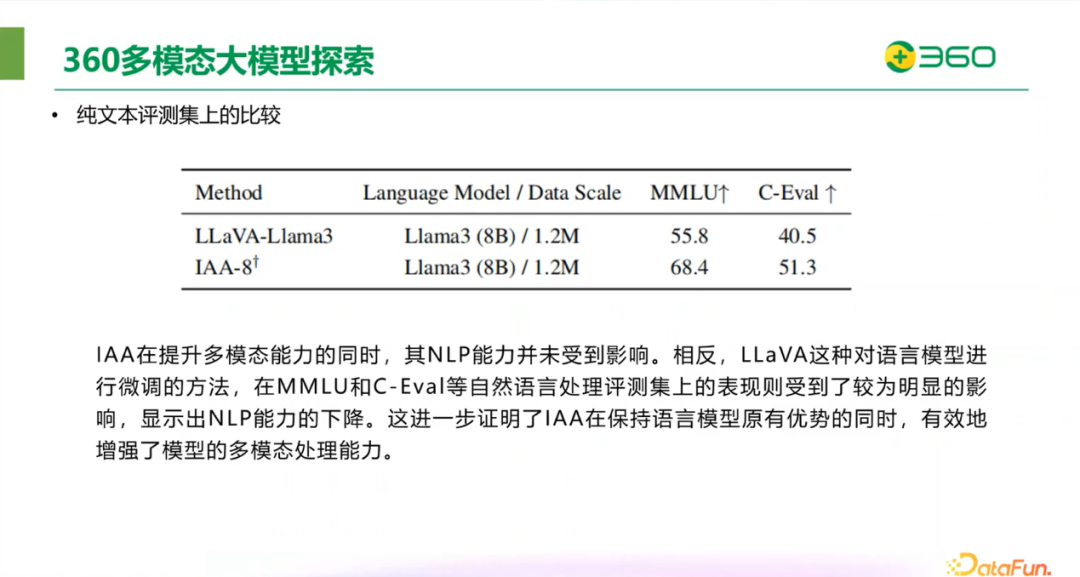
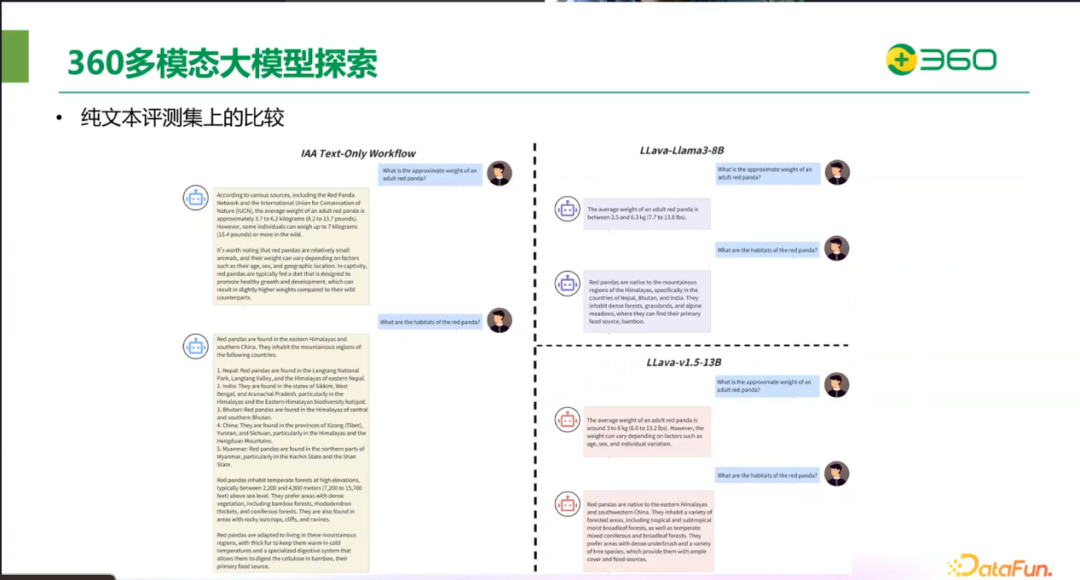
下图是在纯文本评测集上的比较,可以看到,IAA在提升多模态能力的同时,其 NLP 能力并未受到影响。相反,LLava 这种对语言模型进行微调的方法,在 MMLU 和 C-Eval 等自然语言处理评测集上的表现则受到了较为明显的影响,显示出 NLP 能力的下降。这进一步证明了 IAA 在保持语言模型原有优势同时,有效地增强了多模态处理能力。
从下面的图片可以看到经过训练后的 LLava-Llama3-8B 的回复是偏短的,可能会遗失一些关键信息。
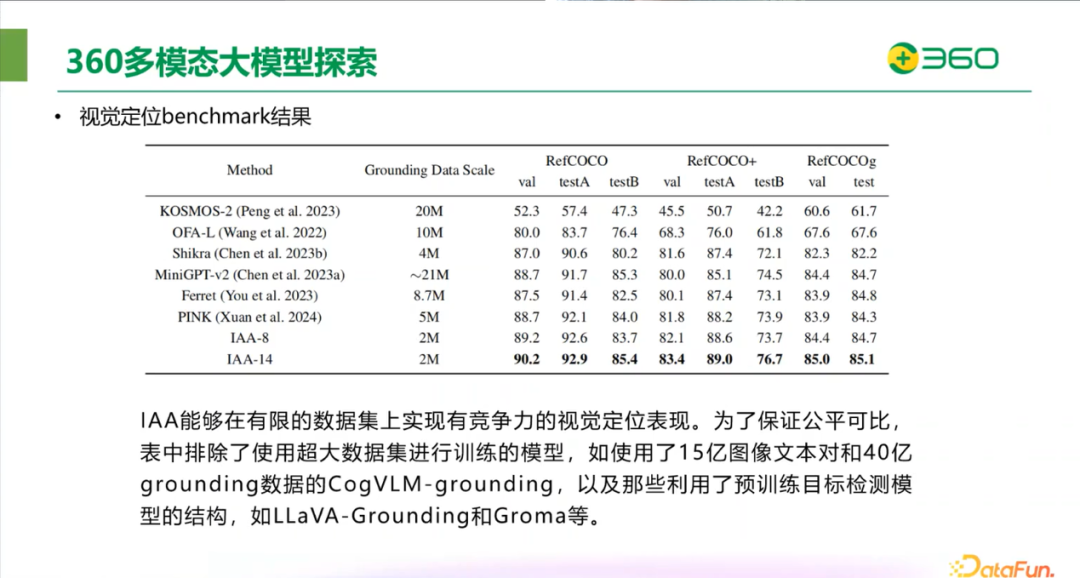
IAA 能够在有限的数据集上实现有竞争力的视觉定位表现。为了保证公平对比,表中排除了使用超大数据集进行训练的模型。如使用了 15 亿图像文本对和 40 亿 grounding 数据的 CogVLM-grounding,以及那些利用了预训练目标检测模型的结构,如 LLava-Grounding 和 Groma 等。
 目前,高性能的多模态模型通常需要解冻大语言模型来训练。CogVLM 强调了开发一个同时擅长多模态理解和视觉定位任务的模型的困难。为了解决这个问题,它采用了双模型策略,一种模型训练通用多模态能力,另一种模型训练视觉定位能力。在这种情况下,在 GPU 上采用 FP16 同时部署一个语言模型,一个通用多模态模型和一个视觉定位模型,大概需要 50GB 的显存。
目前,高性能的多模态模型通常需要解冻大语言模型来训练。CogVLM 强调了开发一个同时擅长多模态理解和视觉定位任务的模型的困难。为了解决这个问题,它采用了双模型策略,一种模型训练通用多模态能力,另一种模型训练视觉定位能力。在这种情况下,在 GPU 上采用 FP16 同时部署一个语言模型,一个通用多模态模型和一个视觉定位模型,大概需要 50GB 的显存。
360 团队提出的方法,通过内部适配器结构巧妙地结合了通用多模态能力和视觉定位能力,同时保护了原始大语言模型的 NLP 能力。举例来说,通过使用 8 层内部适配器配置,模型能够显著减少显存占用,同时部署这三种能力的模型显存占用仅需 30GB 左右。
下图中展示了消融实验的结果,针对模型结构的实验结果可以看到 toC 的结构是最优的。同时,对训练策略进行了实验,证明两阶段预训练策略可以取得很好的效果。在插入层数的选择上,随着插入层数的增加,结果会提升,但考虑到效率,8 层已经足够。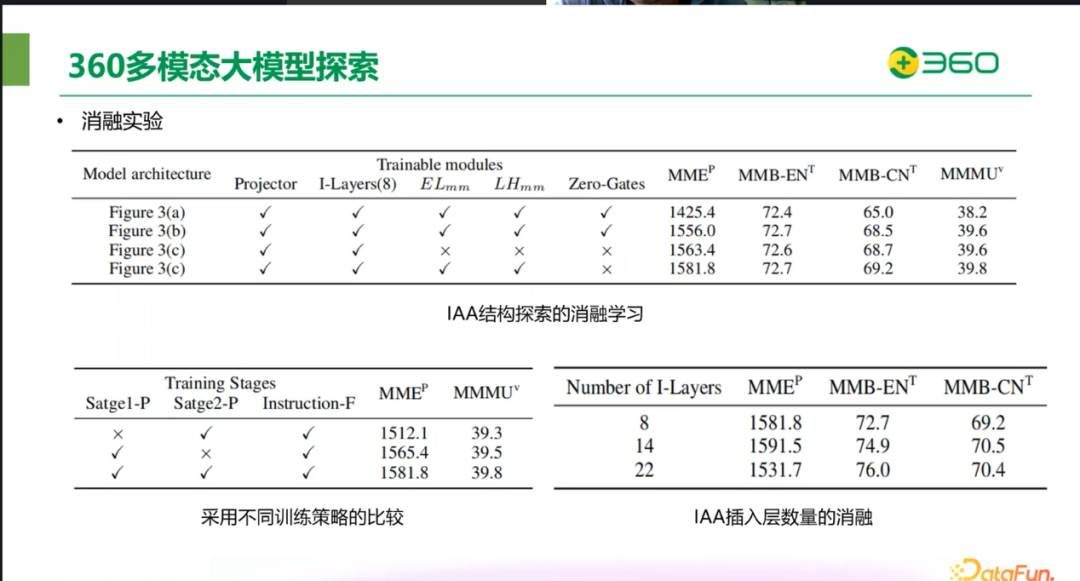
360 多模态大模型业务落地实践
首先是 360 的智能产品,儿童手表搭载了多个 AI 功能。通过拍照学英语的功能,儿童可以随时随地拍照,照片传入大模型的算法,算法分析照片中主体的位置和形象,最后给出中英文描述。

另外一个功能是图像标签化,大模型对图像内容进行识别,然后给出实体标签。

在视频监控场景下,360 智能产品也能够准确的抽象出实体,包括异常物体和人的进入。

还可以用作开放世界目标检测。在城市交通场景下,人们可以任意输入一个要检测的模板,模型就会在视频中定位目标的位置。
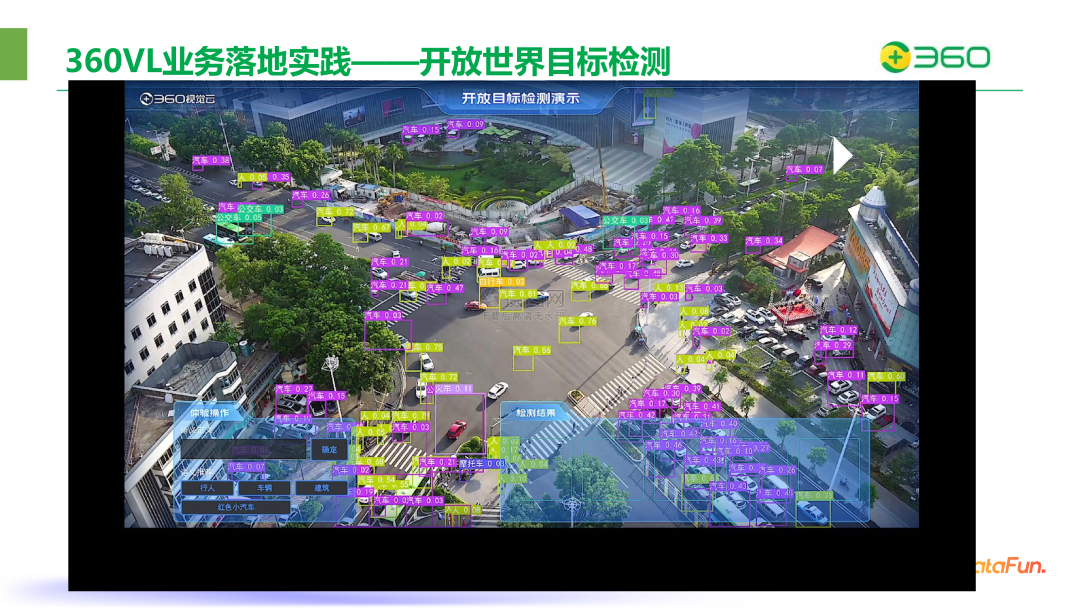
此外,可以基于多模态大模型的实现安防视频自动化巡检,帮助商家店面进行各种开放场景下的反馈。

目前,360 多模态大模型已在公共场所安全巡检、4S 店库存车管理、物业管理等多个场景落地。AI 智能摄像机和视觉云的 SaaS 平台已经为超过五万家企业提供了数字化解决方案。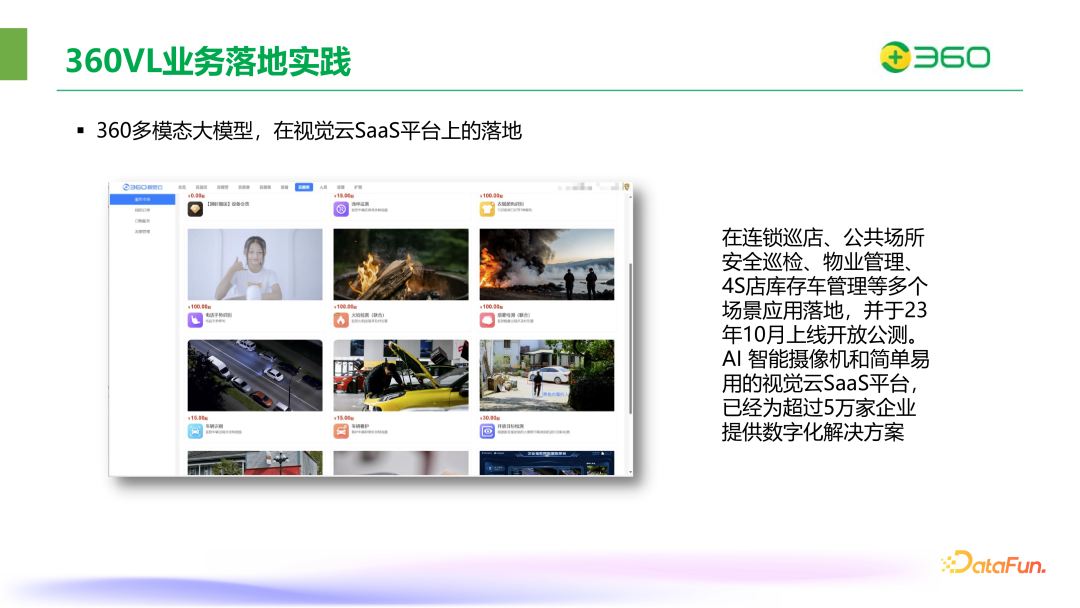






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
