现有的文生图技术已经较为成熟,Flux、SD 3.5 和 Midjounery 等最先进文生图模型已经可以生成足够“以假乱真”的图像。在淘系内部,现有文生图模型已经被应用于各种需要创意图像的业务,例如 AI 会场等。但是,文生图技术的缺陷在于文本作为控制条件的指导性仍然较弱--例如我们无法仅利用文本生成一个带有“GitHub”样式的包包的营销图(见图1)。
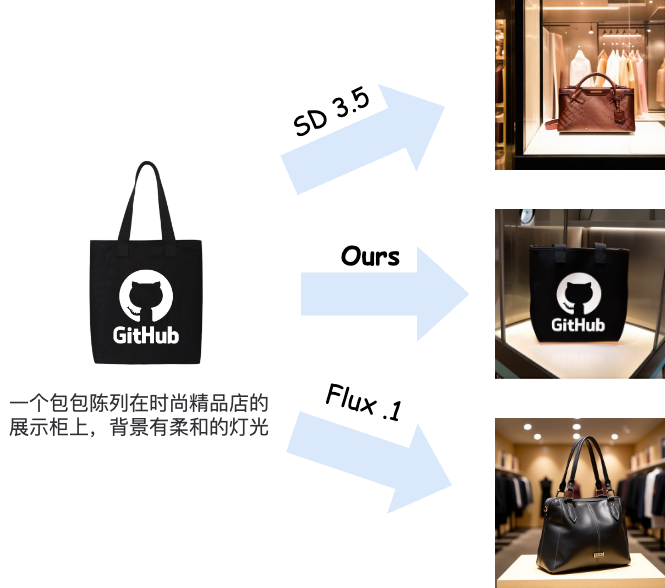
图1. 现有文生图模型与本文方案效果展示
然而,这一能力在淘系有着极为广泛和重要的应用场景和需求--想象对于任意一件商品,如果可以生成该商品在不同场景下的高质量图像,那么这对于to B 和 to C 侧的内容生产和投放,都具有非常大的应用前景,值得我们投入资源进行探索落地。
基于参考图像生成目前主要有两种范式,一种是利用 inpainting 技术实现特定商品的重绘,一种是参考图生成技术。inpainting 技术对除商品以外的区域进行重绘,保证商品本身的内容不发生改变,但是该方案的缺点也较为明显:生成的物体和原图一模一样,且无法较好的将物体融入到新生成的场景中,例如前后景不融洽。
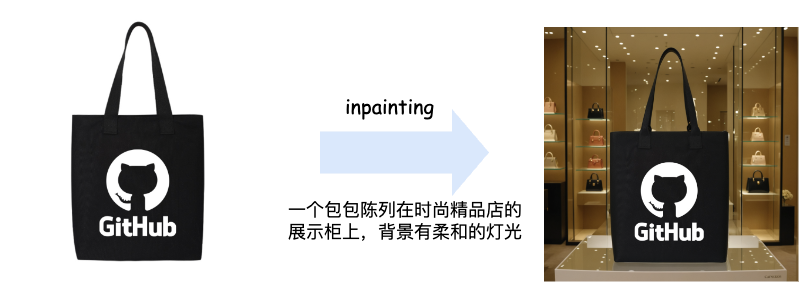
图2. inpainting 效果展示
本文主要介绍参考图生成技术,其在学界的名称为 subject-driven image generation 或者是 personalized image generation。在参考图生成领域,其又分为测试时微调和免测试时微调。以下主要对两种方式进行介绍。▐ 测试时微调
测试时微调,顾名思义,是指当模型训练完成后,对于给定的需要进行“个性化”的物体,需要一次额外的模型微调。测试时微调的代表作有 DreamBooth[1]、Text Inversion[2] 和 Custom Diffusion[3] 等。笔者主要对目前使用较为广泛的 Dreambooth 进行介绍。
Dreambooth 引入了“个性化生成”的概念:通过输入 3-5 张特定人/物的图像,模型即可具备生成特定人/物不同状态、不同场景图像的能力。Dreambooth 通过将特定图像与特定文本捆绑,使得模型学习到人/物到文本的映射关系。例如,通过 "A [V] dog" 将特定的松狮犬图像与文本关联。在实践中,[V] 通常使用较少出现的单词,如 "sks",以替代其原有的语义。此外,为了防止过拟合和语义漂移,Dreambooth 引入了类别保留损失,即在训练中特定的狗图像输入同时,保留对其他品种狗的生成能力。
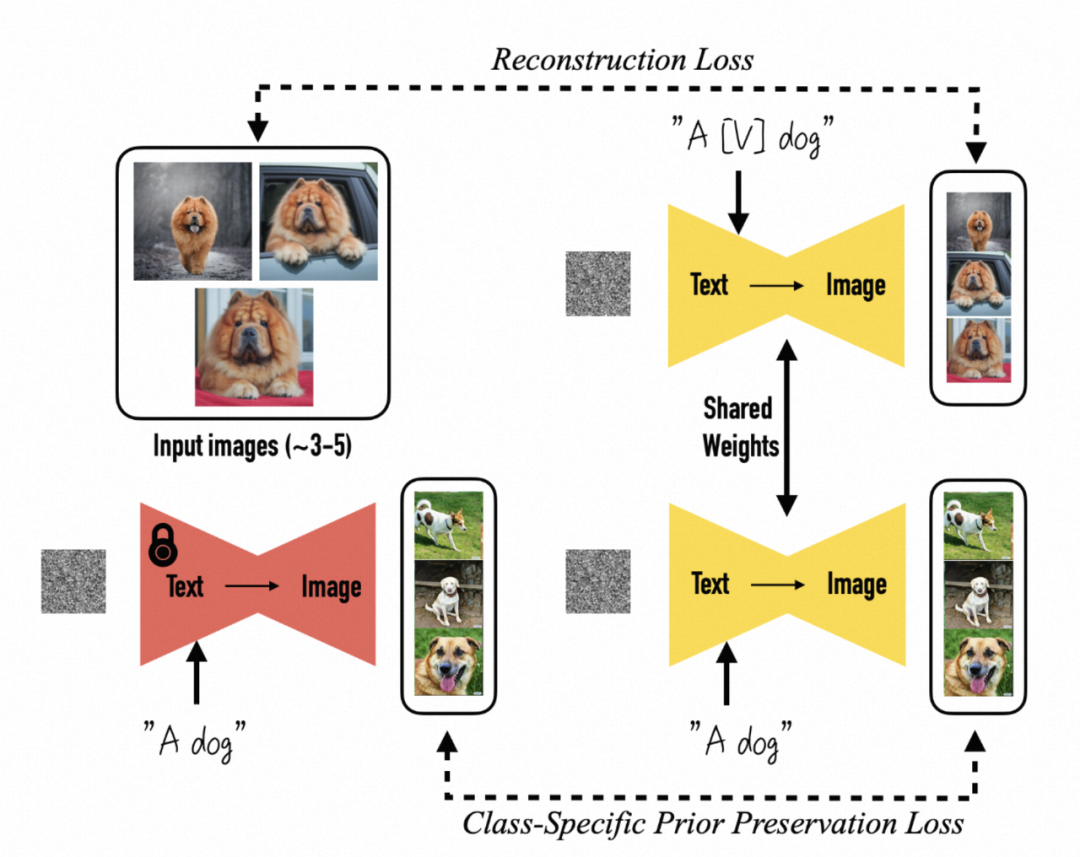
图3. Dreambooth框架图
测试时微调的方案虽然可以生成一致性较高的物体,但是因为其在推理时对于每一个物体都需要进行微调,流程上较为繁琐,所以具有其局限性。
▐ 免测试时微调
免测试时微调,即在模型训练完成后,无需针对特定 case 进行微调,具备了 zero-shot 的生成能力,具有较大的应用前景。免测试时微调的经典的代表作为 IP-Adatper[4] 和 Animate-anyone[5]。二者分别代表了两种不同的将参考图像特征注入到去噪过程中的范式。
对于条件图像,通过 Image Encoder(CLIP Image Encoder) 将条件图像进行编码得到 ,然后通过解耦交叉注意力(见如下公式)将条件图像注入到 latent 特征中,从而实现条件图像的信息注入。
,然后通过解耦交叉注意力(见如下公式)将条件图像注入到 latent 特征中,从而实现条件图像的信息注入。
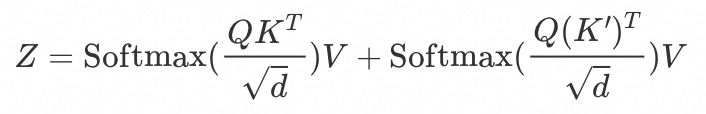
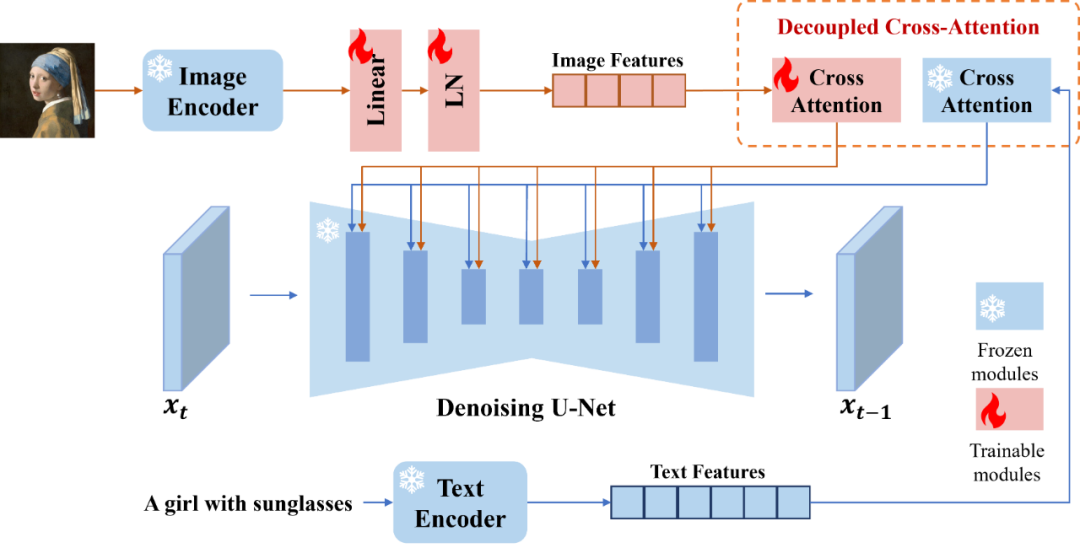
图4. IP-Adapter架构
IP-Adapter 的缺点在于对于图像的细粒度信息注入不足,这是因为条件图像送入 CLIP Image Encoder, 输出的特征形状为: [1, 768],这对于图像的信息压缩十分严重,从而使其难以捕捉条件图像中的细节信息。
Anymate-anyone 提出了一种名为 ReferenceNet 的新颖图像特征注入方法,以解决 IP-Adapter 细节信息不足的问题。ReferenceNet 包含三个主要架构:去噪网络、CLIP 图像编码器和参考网络。除了使用 CLIP 图像编码器注入粗粒度特征外,还引入了预训练 Stable Diffusion 初始化的条件图像特征提取分支。通过 reference net 注入多尺度特征到去噪阶段,此方法在生成图像一致性方面有显著提升,广泛应用于视频生成和虚拟试衣等领域。
技术方案
▐ 数据收集
目前关于参考图生成方向的数据集主要有两类:
1. 重建数据集 (从图像中分割出特定物体,做一定数据增强后让模型恢复出原始物体)
2. 配对数据集:物体的两张不同场景、不同视角的图片对。我们首先在重建数据上进行实验,发现模型最终的生成 copy-paste 的效果较为明显,因而采用配对数据集,在生成的多样性上有较大改善。
▐ 模型选择
在基模选择上,我们首先尝试了 SD1.5 作为基模, 但因为其基础生成能力较弱,无法较好的对物体的细节纹理、文字等进行较好还原,因此转而尝试 SDXL和 Flux 作为基模。SDXL 和 Flux 对文字等具有较好的还原能力。
在方案选择上,我们尝试了基于 ControlNet [6]、ReferenceNet 和一些虚拟试衣的范式,并且最终基于虚拟试衣的范式并进行相应修改调整来进行参考图生成。
实验效果
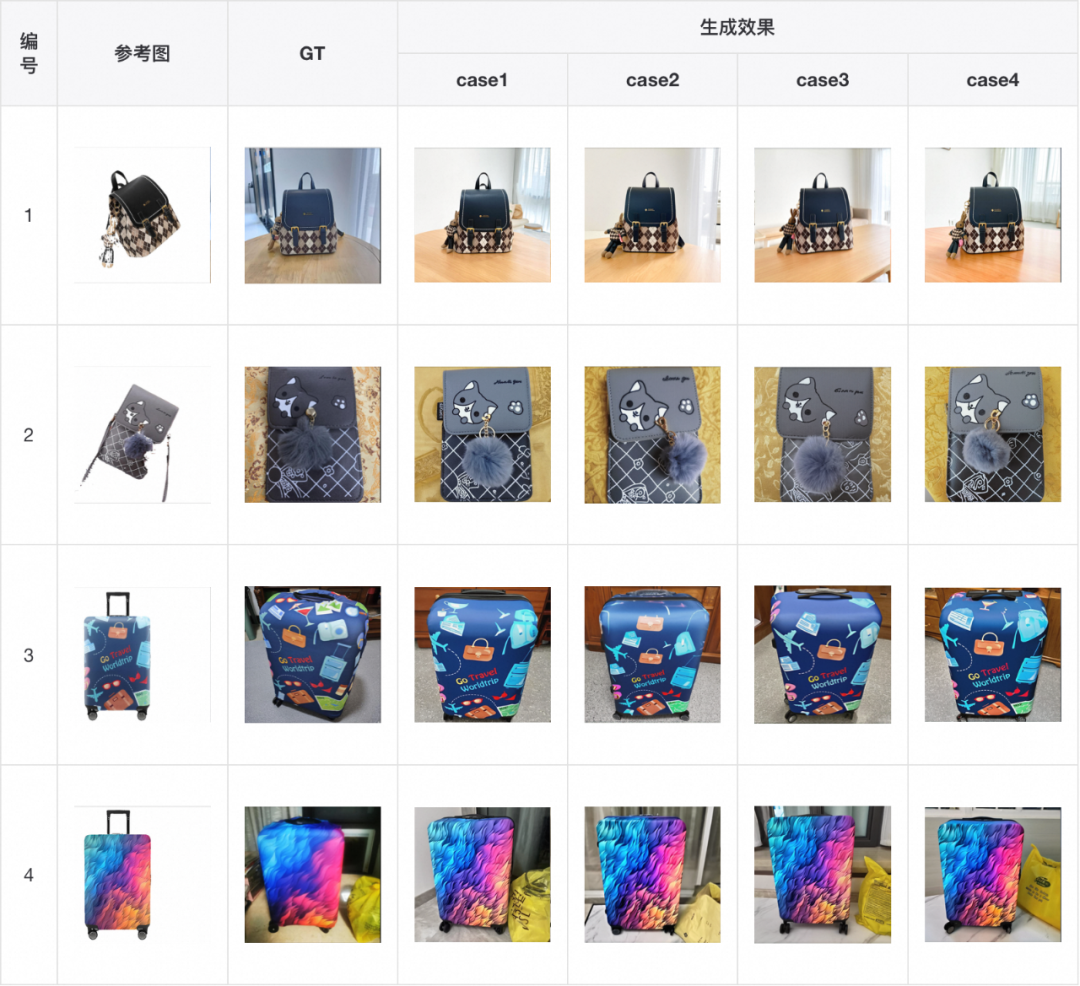
我们首先展示模型在测试集上的效果,可以看出模型可以较好的保持背包的形状、图案和文字等的一致性,甚至比 GT 更像 GT(例如表格第4行)。
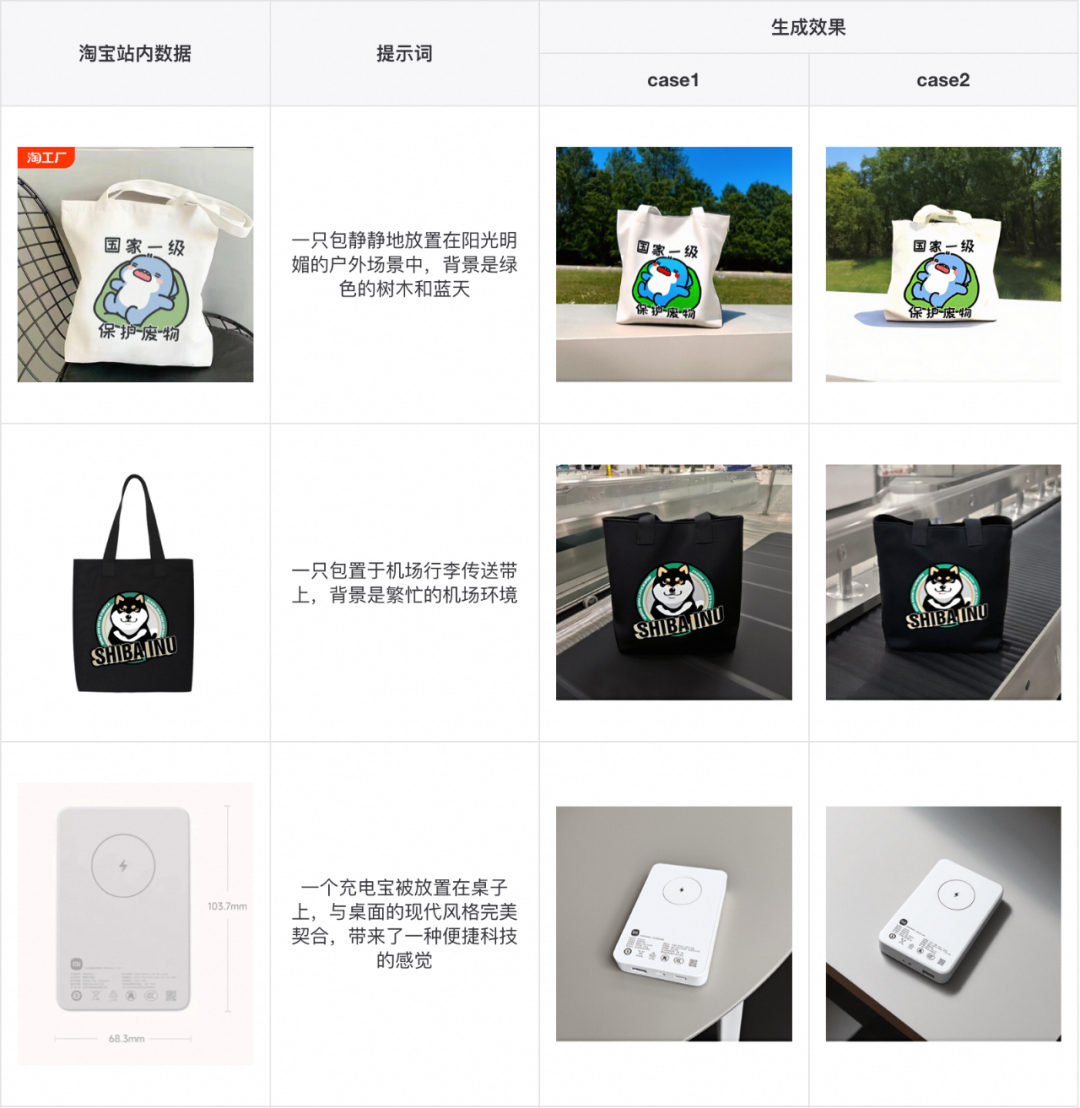
接着,我们在淘宝上随机挑选一些比较具有代表性的 case 进行验证,也能取得不错的效果。
最后,把我们的方案与当前的 SOTA 参考图生成方案进行对比,可以较为明显的发现该方案在一致性上的优势。

我们提出了一种新颖的参考图生成方案,能够实现细粒度的商品一致性生成,在较好地还原物品的形状、纹理、花纹文字的同时,融洽的将商品融入到文本提示的环境中。
我们的模型在参考图生成的一致性上取得了较好的效果,但是目前仍具有以下不足:
因此,后续我们会进一步扩大品类信息,提升数据的数量与图像质量,进一步提升模型的生图效果。
































 粤ICP备14082021号
粤ICP备14082021号