推荐语
探索AI领域革命性的多模态技术,深入了解其核心组件和应用场景。核心内容:1. 多模态检索的关键组件:检索器、重排序器和精炼器2. 单/双流结构与生成式结构的对比及应用3. 跨模态检索技术:文本-图像、文本-视频和文本-音频检索的实践案例
杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
本公众号主要关注NLP、CV、LLM、RAG、Agent等AI前沿技术,免费分享业界实战案例与课程,助力您全面拥抱AIGC。
四、多模态检索
多模态检索的三个关键组件包括:检索器(retriever)、重排序器(reranker)和精炼器(refiner)。

4.1 检索器(retriever)
可分为单/双流结构和生成式结构,每种结构都涉及单模态(例如,文本、图像)和跨模态信息检索。
4.1.1 单/双流检索
- 单流结构:集成多模态融合模块,在一个统一的语义空间中建模图像-文本关系,捕捉细粒度的交互,但会产生更高的计算成本和更慢的推理速度。
- 双流结构:使用独立的视觉和语言流,利用对比学习在共享语义空间中有效地对齐全局特征。 但是,它缺乏显式多模态交互,并且由于信息不平衡而难以进行特征对齐,数据集标题的简短性加剧了这个问题。
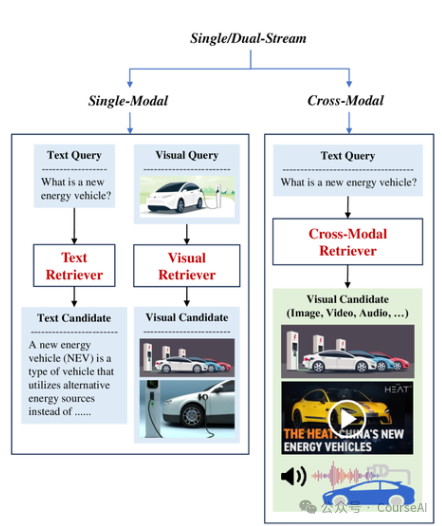
单模态检索,主要以文本检索为主:
- 例如:tf-idf,BM25、DeepCT、HDCT等
- 稀疏检索模型在跨域迁移、检索效率和整体有效性方面达到了最佳平衡

例如:BERT、RoBERTa、Poly-encoder、ColBERT等
- 采用低维欧几里得空间中的密集向量嵌入来建模查询和文档之间的语义关系。
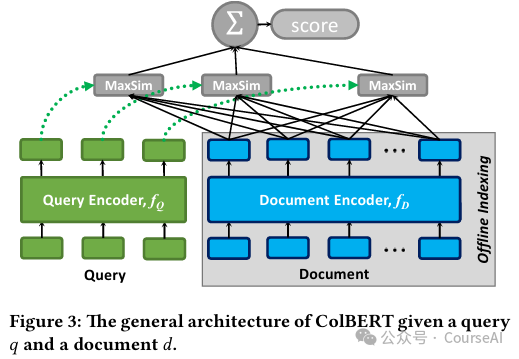
跨模态检索:
- 利用多模态数据共现(例如配对的文本-图像实例或人工标注)来捕获语义相关性,从而将图像与相应的文本查询匹配。
- 例如:基于视觉语言预训练(VLP)模型,利用大规模视觉语言数据集进行联合预训练。
- TEAM单流模型对齐多模态token嵌入以进行token级匹配
- COTS采用双流方法将对比学习与token级和任务级交互相结合。
- CSIC分别通过量化语义意义和将图像块特征与单词关联来改进多模态对齐。
- IRRA采用文本特定掩码机制来捕捉细粒度的模内和模间关系。
- 利用CLIP来整合对比学习和关键词增强,以丰富表示。
- 将文本描述与相应的视频进行匹配,需要时空表示来处理时间动态、场景转换和精确的文本-视频对齐。
- 由于需要有效地对视觉和序列信息进行建模,这项任务比文本-图像检索更复杂。
- 例如:基于VLP模型,利用CLIP等预训练模型来增强文本-视频检索任务中的文本-视频任务,通过捕获跨模态和时间依赖关系。
- CLIP4Clip将CLIP应用于文本-视频检索和字幕生成,分析时间依赖关系。
- VoP引入提示微调并微调CLIP以建模时空视频方面
- Cap4Video利用CLIP和GPT-2进行零样本字幕生成以辅助字幕。
- DGL提出了动态全局-局部提示微调,通过共享潜在空间和注意力机制强调跨模态交互和全局视频信息。
- TeachCLIP通过整合来自高级模型的细粒度跨模态知识,并使用帧特征聚合块细化文本-视频相似度,从而改进CLIP4Clip。

- 将文本查询与相应的音频内容进行匹配,需要将语义文本信息与语音、音乐或环境声音中的动态声学模式进行对齐。
- 例如:基于Transformer的方法利用多头注意力机制和微调来增强跨模态交互。
- TAP-PMR使用缩放点积注意力使文本能够关注相关的音频帧,减少误导性信息,而其先验矩阵修正损失通过解决相似性不一致性来优化双重匹配。
- CMRF通过定向跨模态注意力和强化学习来增强音频-歌词检索,以细化多模态嵌入和交互。
- TTMR++集成了微调的大语言模型和丰富的元数据来生成详细的文本描述,通过解决音乐属性和用户偏好来改进检索。

- 在一个统一的模型架构中,处理各种混合模态数据(例如,文本、图像、视频),并将所有模态编码到共享特征空间中。
- 这使得能够在任何混合模态数据的成对组合之间进行高效的跨模态检索。
- UniIR 引入了一种统一的指令引导多模态检索器,通过在各种多模态信息检索任务上进行指令调优,实现了强大的泛化能力。
- VISTA通过将视觉token嵌入集成到文本编码器中来扩展图像理解能力,这由高质量的组合图像文本数据和多阶段训练算法支持。
- VLM2VEC提出了一种对比训练框架,使用MMEB数据集将视觉语言模型转换为嵌入模型。
- GME为了解决模态不平衡问题,在大型UMRB数据集上训练了一个基于大型多模态语言模型的稠密检索器。
- Ovis 通过集成可学习的视觉嵌入表来对齐视觉和文本嵌入,从而实现索引嵌入的概率组合,以获得丰富的视觉语义。
- ColPali利用视觉语言模型和ViDoRe基准根据其视觉特征索引文档,利用后期交互机制促进高效的查询匹配。
- CREAM采用了一种由粗到精的检索和排序方法,将相似度计算与基于大型语言模型的分组和注意力池化相结合,用于基于大型多模态语言模型的多页文档处理。
- DSE在130万张维基百科网页截图上微调了一个大型视觉语言模型,从而能够将文档截图直接编码成密集表示。

4.1.2 生成式检索(GR)
GR主要由两个基本组成部分组成:模型训练和文档标识符(DocID)。
- 模型训练旨在训练生成模型有效地索引和检索文档,同时增强模型记忆文档语料库中信息的能力,这通常通过序列到序列(seq2seq)训练来实现.
- 模型学习将查询映射到其相应的文档标识符(DocID)
- 训练过程强调优化模型对查询和文档之间语义关系的理解,从而提高检索精度。
- 有效的DocID通常使用密集的、低维的嵌入或结构化表示来生成,这些表示捕获了文档的基本内容和上下文,使模型能够更准确地区分文档并提高检索性能。
文本模态检索
- 可分为基于静态DocID的方法和基于可学习DocID的方法
- 静态DocID的方法依赖于预定义的、固定的文档标识符。 它们通常使用唯一名称、数字格式或结构化标识符来表示文档。
- 例如:DSI引入了数值型DocID格式,包括非结构化、简单结构化和语义结构化标识符,通过索引和检索策略进行训练。
- DynamicRetriever使用非结构化的原子DocID,并通过伪查询增强记忆能力。
- LTRGR重点关注使用生成式检索模型直接学习对段落进行排序,通过秩损失优化自回归模型。
- DGR通过知识蒸馏增强生成式检索,使用交叉编码器作为教师模型提供细粒度的排序监督。
- 基于可学习DocID的方法,使得DocID在训练过程中得到优化,以更好地捕获文档语义并提高检索性能。
- 例如:GLEN采用具有两阶段索引学习策略的动态词法标识符。
- 首先,基于关键词的文档ID是通过使用自监督信号从文档中提取关键词来定义的。
- 其次,通过整合查询-文档相关性来细化动态文档ID,从而实现高效的推理。
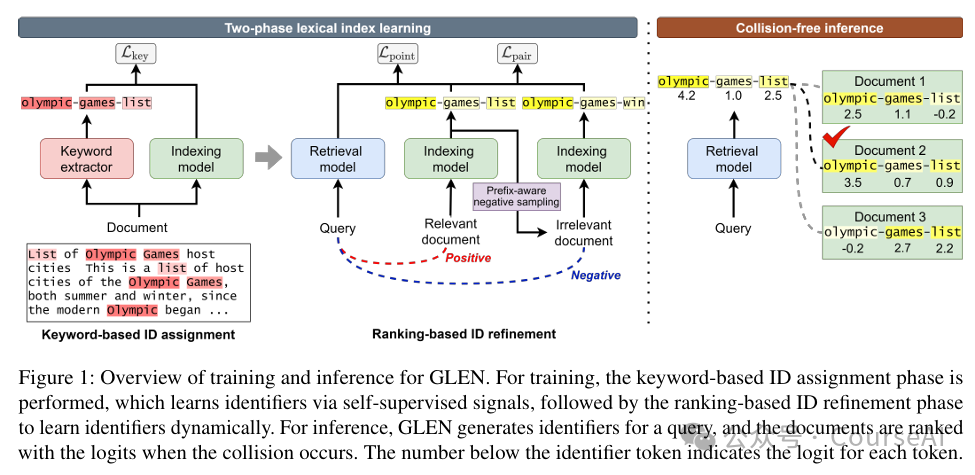
跨模态检索
- 例如:IRGen采用seq2seq模型从查询图像预测离散视觉token(图像标识符)。 其关键创新在于语义图像分词器,它将全局特征编码成离散视觉token,从而实现端到端可微搜索,提高准确性和效率。
- GeMKR通过生成式多模态知识检索框架将大型语言模型 (LLM) 与视觉文本特征相集成。
- GeMKR首先使用基于对象的 prefix tuning 技术指导多粒度视觉学习,以使视觉特征与LLM的文本特征空间对齐
- 然后采用两步检索过程:生成与查询相关的知识线索,并基于这些线索检索文档。
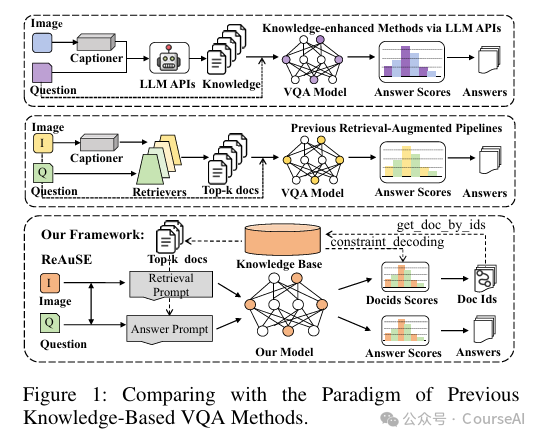
- AVG引入了自回归视觉token (voken) 生成,将图像标记为充当图像标识符的视觉token,同时保持视觉和语义一致性。
- 通过将文本到图像检索框架化为token到视觉token生成任务,AVG 通过判别式训练弥合了生成式训练和检索目标之间的差距,从而在token到视觉token生成的過程中细化学习方向。
4.2 重排序(ReRank)
主要是对第一阶段检索器检索到的多模态文档列表进行重新排序。
采用相关性评分机制,例如:采用交叉注意力模型,对查询和文档之间的上下文关联交互进行评分。
基于大模型(LLM和MLLM)的重排序方法可以分为两个主要范式:微调作为重排序器和提示作为重排序器。
4.2.1 微调作为重排序器
文本模态的重排序,可以分为三类:仅编码器、编码器-解码器和仅解码器。
- 仅编码器的重排序器:通过微调 PLM来实现精确的相关性估计,从而改进了文档排序。
- monoBERT将查询-文档对格式化为查询-文档序列。 相关性分数是从“[CLS]”token的表示中通过线性层导出的,优化通过负采样和交叉熵损失实现。
- 编码器-解码器重排序器:现有研究主要将文档排序表述为生成任务
- 微调像 T5 这样的模型来生成分类token(例如“真”或“假”)用于查询-文档对,相关性分数来自token logits
- RankT5直接为每个查询-文档对生成数值相关性评分,使用排序损失而不是生成损失进行优化。
- ListT5通过同时处理多个文档进一步发展了这一点,使用Fusion-in-Decoder架构直接生成重新排序的列表。
RankLLaMA将查询-文档对格式化为提示,并使用最后一个token表示来进行相关性评分。
TSARankLLM采用两阶段训练方法:在基于网络的相关的文本对上进行连续预训练以使LLM与排序任务对齐,然后使用监督数据和定制的损失函数进行微调。
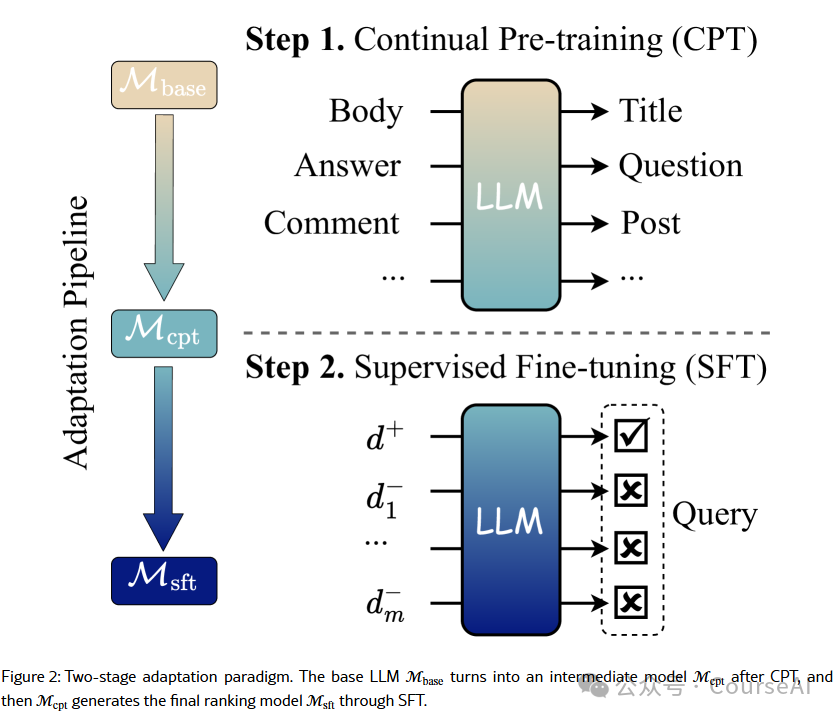
- PE-Rank将文档压缩成单个嵌入,减少输入长度并提高重新排序效率,直接输出重新排序的文档列表

- RagVLRETRIEVAL引入知识增强的重新排序和噪声注入训练,使用简单而有效的模板对MLLM进行指令调优以增强其排序能力,使其能够充当重新排序器以准确过滤topk检索到的图像。
4.2.2 提示作为重排序器
文本模型的重新排序,提示策略通常分为三种类型:逐点法、成对法和列表法。
逐点法:评估查询和单个文档之间的相关性,并根据相关性分数对其进行重新排序。
例如:MCRanker通过基于多视角标准生成相关性分数来解决现有逐点重新排序器中的偏差。
Co-Prompt引入了一种离散提示优化方法,用于改进重新排序任务中的提示生成。
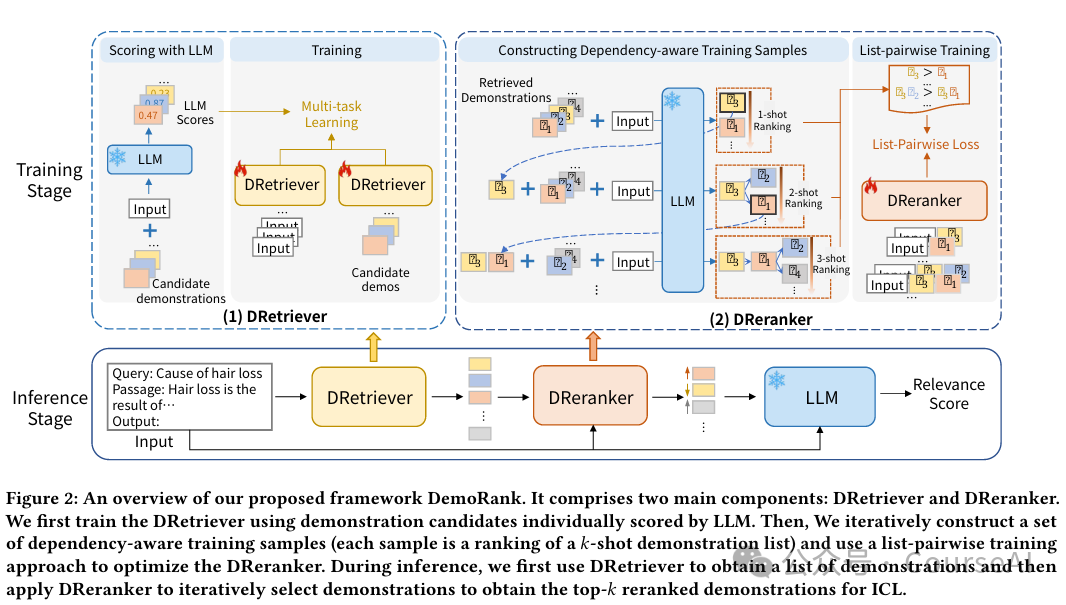
DemoRank通过依赖感知的演示重新排序器来改进演示选择,通过高效的训练样本构建和一种新的列表成对损失来优化排名靠前的示例。
成对方法:包括向大型语言模型呈现查询和文档对,并指示它们识别更相关的文档。
- PRP-AllPair生成所有可能的配对,分配离散的相关性判断,并将这些判断聚合为每个文档的最终相关性分数。
- PRP-Graph通过使用判断生成概率和基于图的聚合来对相关性评分,从而改进了这一点。
列表式方法:通过将查询和文档纳入提示中来直接对文档列表进行排序,指示LLM输出重新排序的文档标识符。
RankGPT引入了指令置换生成和滑动窗口策略来解决上下文长度限制问题

FIRST利用第一个生成的标识符的输出logit直接获得候选对象的排序顺序。
跨模型重新排序:基于提示的多模态重新排序器使用提示来指导MLLM重新排序项目。
TIGeR提出利用多模态LLM通过生成式检索方法进行零样本重新排序的框架。
4.3 精炼器(refiner)
无限的输入长度输入MLLM会带来一些实际的困难:
1、有限的上下文窗口:大型语言模型在预训练期间具有固定的输入长度,任何超过此限制的文本都会被截断,导致上下文语义丢失。
2、灾难性遗忘:缓存空间不足会导致大型语言模型在处理长序列时忘记先前学习的知识。
3、推理速度慢。
精炼器是对检索和重新排序后的信息进行优化。
- 例如:摘要、蒸馏或上下文化,以将内容浓缩并细化为更易于理解和操作的格式。
- 通过提取关键见解,消除冗余,并将信息与查询的上下文对齐
- 精炼器增强了检索数据的效用,使大型语言模型能够生成更连贯、更准确、更符合上下文的响应。
提示改进可以通过两种主要方法实现:硬提示方法和软提示方法。
硬提示精炼器
过滤掉不必要或信息量低的內容,仍然使用自然语言token,从而产生不太流畅但更通用的提示,这些提示可以跨具有不同嵌入配置的LLM使用。
文本精炼器
- CPC通过使用上下文感知编码器去除无关句子来保持语义完整性
- LLMLingua引入了一种由粗到细的方法,使用小型语言模型 (SLM) 通过困惑度 (PPL) 来衡量token信息量,从而压缩提示组件(指令、问题、演示)。
- LongLLMLingua将此扩展到长文档,采用线性调度器、重排序机制和对比困惑度来保留与问题相关的token,同时确保关键信息的完整性。
- CoT-Influx使用样本剪枝器和token剪枝器压缩GPT-4生成的思维链(CoT)提示,两者均作为通过强化学习训练的多层感知器 (MLP) 实现。 这些方法共同提高了性能,同时减少了无用的CoT示例和冗余token。
- Prompt-SAW通过关系感知图提取关键token来保留句法和语义结构,并将它们集成到压缩后的提示中。
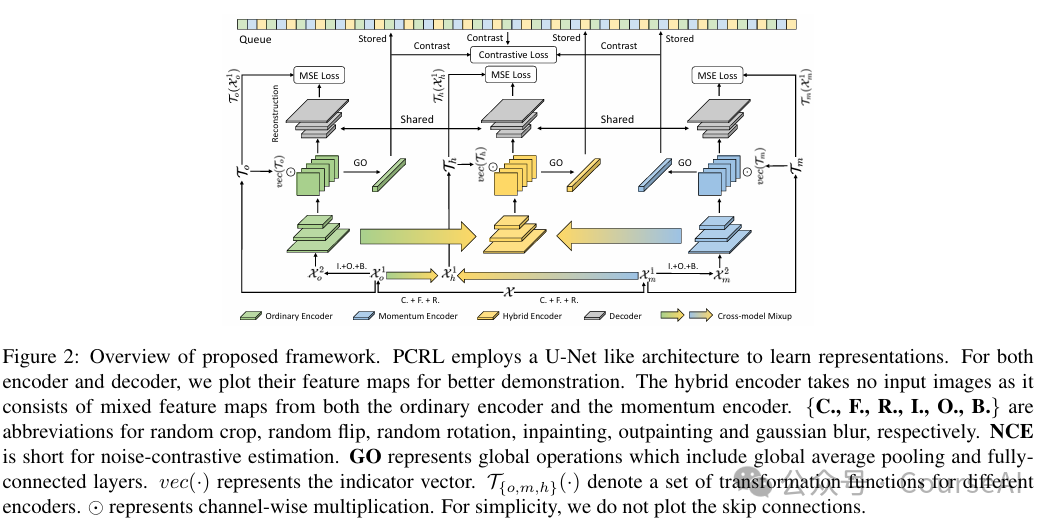
- PCRL将提示压缩视为一个二元分类任务,使用具有可训练MLP层的冻结预训练策略语言模型。 压缩策略将token标记为包含或排除,优化一个平衡保真度和提示长度缩减的奖励函数。
- LLaVolta 引入了一种减少视觉token数量的方法,从而提高了训练和推理效率,而不会影响性能。 为在压缩过程中最大限度地减少信息丢失,同时保持训练效率,它采用了一种轻量级的分阶段训练方案。 此方案在训练过程中逐步压缩视觉token,从重压缩到轻压缩,确保测试过程中不会丢失信息。
- MustDrop测量每个token在其整个生命周期中的重要性,包括视觉编码、预填充和解码阶段。 在视觉编码过程中,它将空间相邻且相似度高的token合并,并建立一个关键token集以保留视觉关键token。 在预填充阶段,它使用双重注意力过滤策略,进一步压缩由文本语义引导的视觉token。 在解码阶段,一种输出感知缓存策略减少了KV缓存的大小。
- G-Search提出了一种贪婪搜索算法,用于确定每一层(从浅层到深层)需要保留的最小视觉token数量。 基于此策略,设计了一个参数化的S型函数(P-Sigmoid)来指导MLLM每一层的token约减,并使用贝叶斯优化来优化参数。
- G-Prune介绍了一种基于图的免训练视觉token剪枝方法。 它将视觉token视为节点,并基于语义相似性构建连接。 信息流通过加权链接传播,迭代后保留MLLM中最重要的token。
软提示精炼器
- 与依赖于预定义词汇表中离散token的硬提示不同,软提示通过训练进行优化,以捕捉离散token无法表达的细微含义。
- UniICL在单个冻结的 LLM 中统一了演示选择、压缩和生成,并将演示和输入投影到虚拟token中以进行基于语义的处理
- AutoCompressor使用循环记忆Transformer迭代地将上下文片段压缩成摘要向量,从而减少了计算负载。
- ICAE对 LoRA 适配的 LLM 进行了微调,用于上下文编码和提示压缩。
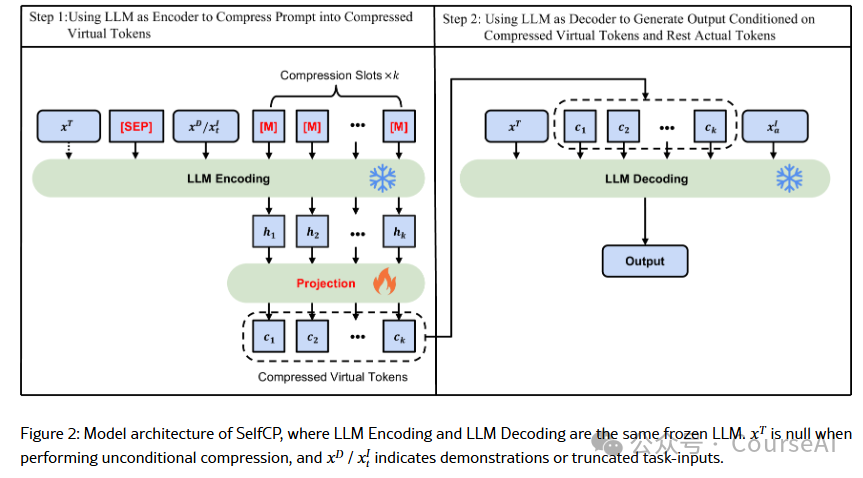
- SelfCP通过使用冻结的大语言模型 (LLM) 作为压缩器和生成器,以及可训练的线性层将隐藏状态投影到LLM可接受的内存token,从而平衡训练成本、推理效率和生成质量,异步压缩超限提示。
[ColBERT](https:[ColBERT](https:[TeachCLIP](https:[TTMR++](https:[GLEN](https:[GeMKR](https:[TSARankLLM](https:[DemoRank](https:[PE-Rank](https:[RankGPT](https:[PCRL](https:[SelfCP](https:

































 粤ICP备17114055号
粤ICP备17114055号