前言
最近对之前精读的论文进行梳理,发现一些笔记还是非常有价值的,稍微改改发布出来给大家看看。
LLama3是几个月前的论文了,但是每次精读还是有所收获,本文将一些重点的内容加一些自己的思考和实践进去,对每个技术点进行讨论。
总体概述
如上图所示,Llama3 纯文本模态的整个训练过程分为以下几个主要阶段:
- Pre-Training:主要包括:预训练,长文本预训练,退火预训练三个阶段。
- Post-Training:主要包括:SFT,DPO两个阶段。
对于多模态部分,主要包括以下几个阶段,这部分不是很成熟,所以暂且略过:
- Multi-modal encoder pre-training:训练 image encoder 与 speech encoder。
- Vision adapter training:采用一个 adapter 将 image encoder 与pretrained language model 结合起来。
- Speech adapter training:
模型架构

与llama1 和 llama2没有大差异,效果的提升主要还是来自于:数据质量(data quality),数据多样性(diversity)和 training scale。
- GQA:8 key-value heads来提升推理速度和减少kv-cache缓存
- 采用 attention mask 来防止不同文档之间的 self-attention。实验发现在正常 pt (4k,8k)中没有明显影响,但是对于长文本的CPT非常重要。
- 词表:128k。其中100k来自 tiktoken,额外的28k来支持non-english。28k的新增token不影响英文的分词,并且能提高压缩率和下游表现。实测对中文压缩率相对于llama2 有较大提升,但是跟qwen还是差较远。
- 位置编码:ROPE ,基本频率超参设置到500000,这使得模型能够更好的支持上下文。
Pretrain
Pre-Training Data
PT数据量级为15.6T,涵盖的知识截止到2023年。
Web Data
- PII and safety filtering:设计了多个过滤器来过滤掉涉及 unsafe 内容和 PII 内容的数据。
- Text Extraction and cleaning:从HTML中提取文本。 论文发现,markdown 数据对模型的性能有害,因此去掉了所有的markdown格式。
- De-Duplication:
- url-leval de-duplication:在整个数据集上进行URL去重。
- document-leval de-duplication:采用 global minHash 去除掉重复的文档。
- Line-leval de-duplication:采用ccNet 进行去重。在美3000w的桶中,去除掉出现次数超过 6次 的行。
- Heuristic filtering:设计了一堆规则来过滤低质量文本,重复性文本:
- 采用n-gram coverage radio 来去掉重复内容,如:logging,error。这些行可能非常长且无法通过line-level 去重去掉。
- 采用 dirty word counting 来过滤掉一些成人网站
- 采用token-distrubution kullback-Leibler 分布来过滤掉包含过多outlier tokens 的数据。
- Model-based quality filtering:训练一个质量分类器,采用Distill Robeta 来对每个文档进行质量评分来判断文档是否属于高质量数据。
- Code and resoning data:
- 构建提取代码和数学网页的 domain-specific pipeline。
- 采用DistilledRobeta 训练了一个代码分类器和一个math 分类器。
- Multilingual data:
- 采用fasttext 分类器来区分 176种语言
- 在每个语言类别内进行document-leval 和 line-level 去重
- 采用规则和模型来去掉低质量documents
- 训练了一个质量排序模型来保证多语言数据的高质量。
Determining the data mix
预训练数据中的数据配比是一个非常核心的话题。
- Knowledge classification:对数据进行分类来确定各个类别的配比。比如实际配比中减少对艺术和娱乐的采样配比。
- scaling laws for data mix:从小模型上来验证 data mix,并将其迁移到大模型来获得更好的性能。
- Data mix summary:50% general knowledge,25% mathematical and reasoning tokens,17% code tokens, 18% multilingual tokens。
退火数据:Annealing Data
论文发现,退火阶段加入高质量的代码和数学数据能够提高在 key benchmarks 上的效果。
退火训练在 llama3 8B 上训练后,在 GSM8K和MATH上分别提升了24%和6.4%,但是在 405B 模型上的提升微乎其微,这表明 405B 模型本身具备强大的上下文能力和推理能力,不需要再特定领域的退火来提升效果。
论文后面通过退火训练来评估数据质量。
Scale Laws
值得单独拉专题出来讨论。后面单独写文章讨论下。
Pre-Training Recipe
3.1 Initial Pre-Training:405B
- 学习率:cosine learning reate schedule,学习率=8 * 10-5,linear warm up=8000 steps,1200000 training steps 后衰减到 8*10-7。
- batch size:通过阶梯式的batch size 来增强训练稳定性,减轻 loss spikes。
- 前期采用低batch size来增强训练稳定性,4M tokens,文本长度 4096。
- 在预训练超过 252M 后,batch size 提高到 8M,文本长度8192。
- 2.87T后,batch size 提高到16M。
- data mix:
- 增加 non-english 的比重来增强 multilingual 的表现
- 上采样数学来提高模型的数学表现
- 增加更多近期的数据
- 下采样低质量数据
3.2 Long Context Pre-Training
支持长度:128K,训练 token 数:800B。
用6个阶段从 8K 循序渐进的来扩大文本长度到 128K。在每个阶段训练中,通过评估模型的表现来判断在该长度上是否成功适应。评估的方向包括两个方面:
- short-context evaluations:在短文本上的评估是否正常
- needle in a haystack:大海捞针上的评估是否合理
3.3 退火:Annealing
在最后的 40M tokens中,慢慢将学习率衰减到0,训练长度128k。在退火阶段增大高质量数据的配比。
对 Pretrain 的看法
当前的 Pretrain 在各大厂之间已经不存在明显差距了,并且基座的竞争已经基本结束了,国内Qwen的开源已经吊打很多大厂的闭源团队了,阿里的开源质量还是非常有保障的啊。可预见的是未来的竞争重心已经不在基座上了,现在是谁有卡,谁有数据,谁就是爸爸,看好阿里和字节。
Post-Training

整个 Post-Training 阶段如上图所示,主要是SFT 阶段与DPO 阶段进行迭代优化的过程。
Perference Data:偏好数据
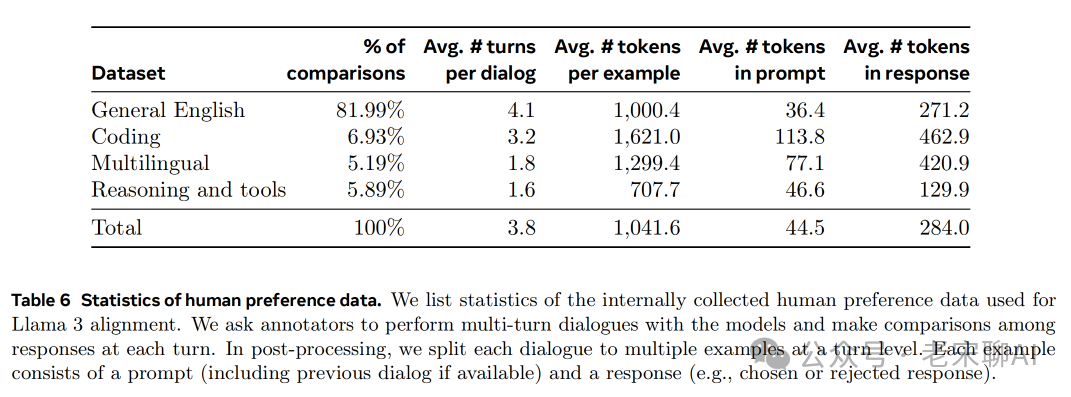
- 对于每一个 prompt,用不同的模型来生成两个答案。不同的模型可以采用不同的数据组合和对齐方式训练得到,从而增加数据的多样性。
- 标注人员对 chosen response 和 rejected response 来分成四级:significatly better,better,slightly better, marginally better。
- 标注人员对 chosen response 进行编辑获得更好的答案。edited > chosen > rejected。
- 对Perference data 进行大致分类,如上表所示。
- 对于每轮训练的改进过程中,相应的增加prompt 复杂性来针对模型的弱点。 在每轮的后训练中,使用所有偏好数据进行 Reward Model 训练,但是仅用最新批次的数据进行DPO。
- 注意:在Reward Model 训练中,使用标记为:significatly better,better的样本来进行训练,其他两个类别的数据丢掉。
SFT 数据
数据来源于三个方面:
- 来自用户的 prompt 和 rejection-sampled 生成的答案
- 特定领域的合成数据
- 少量人工整理标注的的数据
最终使用的SFT 的数据统计如下:

2.1 Rejection sampling
- 对于一个 prompt,用最好的模型采样k(10-30)个response
- 采用 reward model 对这些 prompt-response 进行排序,选择最好的答案
2.2 SFT数据质量处理与过滤
由于数据大多数都是模型生成的,因此需要过滤与质量控制。
数据清洗:
- 数据中存在一些过渡使用标点符号和表情符号的数据
- 答案中存在过度道歉的答案,比如:I’m sorry,I apologize
Data Pruning:采用一些模型来过滤掉低质量的数据
- Topic Classification:通过 LLama3 来进行分类,包括一级分类:mathematical reasoning,二级分类:geometry and trigonometry
- Quality Scoring:
- RM Model:通过 RM model 进行打分,认为前四分之一的数据是高质量数据
- Llama-based score:参考 Deita, 从不同维度数据进行质量打分。针对代码,从Bug Identification 和 User Intention 打分。针对英文数据,从 Accuracy ,Instruction Following,Tone/Presentation 进行打分。
- Difficulty scoring:
- InsTag:采用 Llama3 70B 来进行打 tag,tag 越多则认为越复杂。
- Llama3:参考 Deita,直接采用 Llama3 来进行复杂度打分。
- Semantic deduplication:采用RoBERTa 进行聚类,然后在每个类别中采用quality socre * difficulty score进行排序。
Capabilities
针对特定领域的数据进行优化,主要包括:Code,math 和 reasoning,Long context,tool use,factuality,steerability。
3.1 Code
生成了2.7M的合成数据。
- Synthetic data generation:exection feedback。直接采用 llama3 405B 生成的合成数据加入训练对训练结果没有帮助,甚至会有负面影响。因此采用 exection feedback 的方式来合成数据:
- Problem description generation:收集/生成大量的变成问题描述,并按照主题进行分类保证多样性。
- Solution generation:通过编写prompt用llama3 来生成答案。注意:要求模型来解释其思考过程能够提升答案质量;
- Correctness analysis:模型生成的答案不一定正确,因此需要用额外的方法来保证生成质量:
- Static analysis:直接通过编译器来运行代码,来检查答案中语法错误。比如:代码风格,打字错误,变量遗漏等。
- Unit test generation and execution:通过编写一些单元测试来检查运行错误等。
- Error feedback and iterative self-correction:如果答案运行失败,我们设计prompt来通过错误信息修改答案。比如stderr 错误和单元测试失败等。最终,通过所有测试的数据才能作为sft 数据。
- Fine-tuning and iterative improvement:通过上述过程进行迭代微调,持续多轮微调逐步提升模型效果。
- Synthetic data generation:programming language translation。实验发现模型在主流语言上表现较好如python/c++,但是在小众语言上表现不佳如Typescript/php。主要是因为训练数据中包含很少的小众语言数据。采用Llama3 来将主流语言的答案转为小众语言,如下图所示:

- Synthetic data generation:反向翻译。
3.2 Multilinguality
- 2.4% human annotations
- Data from other NLP tasks:将开源的NLP任务转为dialog数据。
- Rejection sampled data:先用模型生成一些答案,然后用reward model 来选择答案。
- Translated data:
3.3 Math and Reasoning
当前的挑战:
- Lack of prompts:复杂度高的数学prompt 或问题相对较少
- Lack of ground truth chain of thought:缺乏真实的COT 标注数据。
- Incorrect intermediate steps:采用模型生成的COT数据时,中间过程可能会出现问题。
- Teaching models to use external tools:
- Discrepancy betwteen training and inference:
3.4 Long Context
从8k 扩展到128k。
如果使用短sft 数据来微调模型会使得模型的长文本能力出现显著衰退。
采用LLama3 在以下领域合成数据:
- Question Answering:从预训练数据中精选一些长document将其分为8k的chunk,然后通过 Llama3 随机选择document来生成问题-答案pair对。训练时将document 放入上下文中。
- Summarization:采用Llama3 来对 8k 的document 进行总结生成数据。
- Long Context code reasoning:
然后将上述方法用于 16k,32k,64k,128k的数据生成。
配比:0.1% 的长上下文数据与短文本数据结合能够均衡整个结果。
DPO 中仅仅使用短文本不会对sft后的长文本性能产生负面影响。
对 Post-Pretrain 的一些看法
当前基座的竞争结束后接下来就是应用的竞争,而应用层面的竞争会更加关注:增量预训练,SFT,合成数据,RLHF 几个方面。
最后
我认为自 ChatGPT 掀起的这波浪潮已经到了中期,接下来的竞争会更加惨烈,最终大多数的应用落地还得是大厂和一些垂域独角兽说了算。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
