mkdir -p ./ragtest/input这里的 input 是什么呢?就是我们存放输入的文本 —— 像刚刚提到的 200 页的书或者文章 —— 的地方。
我在 Visual Studio Code 下给你演示吧,比较直观。
执行这条命令后,侧边栏会出现一个新的文件夹。
接下来,我们要把书籍资料下载下来。这里 GraphRAG 官网样例使用的是古腾堡计划,上面有很多免费的图书。古腾堡计划是一个致力于创建和分发免费电子书的志愿者项目,它提供了大量版权已过期的经典文学作品。
GraphRAG 官网给的样例是《圣诞颂歌》,是查尔斯・狄更斯创作的一部著名小说,讲述了一个守财奴在圣诞节前夜经历的奇妙故事,最终改变了自己的人生态度。
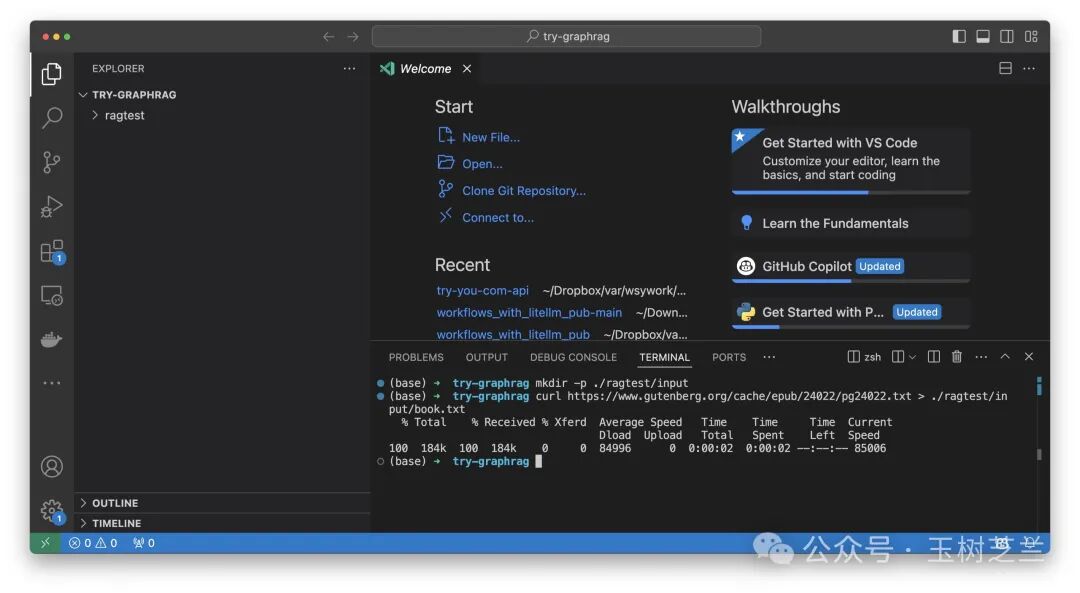
执行下面这条命令下载即可:
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt > ./ragtest/input/book.txt我查看了一下,下载的文件在本地显示为 189KB。大吗?对于文本来说,不算太少。不过相对于今天动辄上 GB 的存储内容来说,那是真不大。
下载完成后,我们需要进行初始化。
python -m graphrag.index --init --root ./ragtest这个步骤是为了设置 GraphRAG 的基本环境和配置,确保后续操作能够顺利进行。

我们来看一下,执行很快,因为这里面不做任何实际索引操作,只是新建几个文件和文件夹。
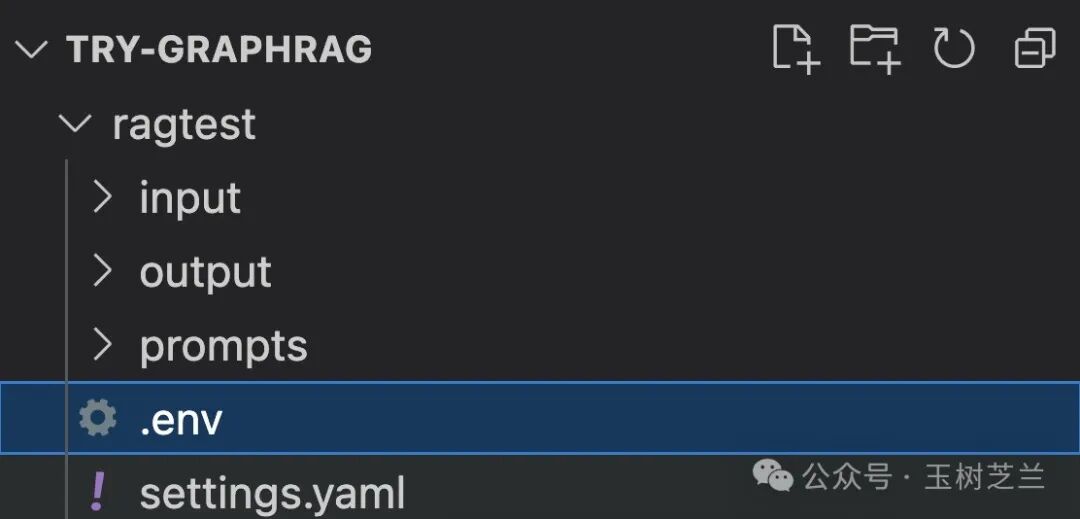
刚才有一个 input 是你自己建的,现在 GraphRAG 创建了 output 文件夹、prompts 文件夹,还有两个设定文件。
我们先设置这个 .env 文件,里面需要填入一些配置。这些配置通常包括 API 密钥、模型选择等重要参数,它们对于 GraphRAG 的正常运行至关重要。
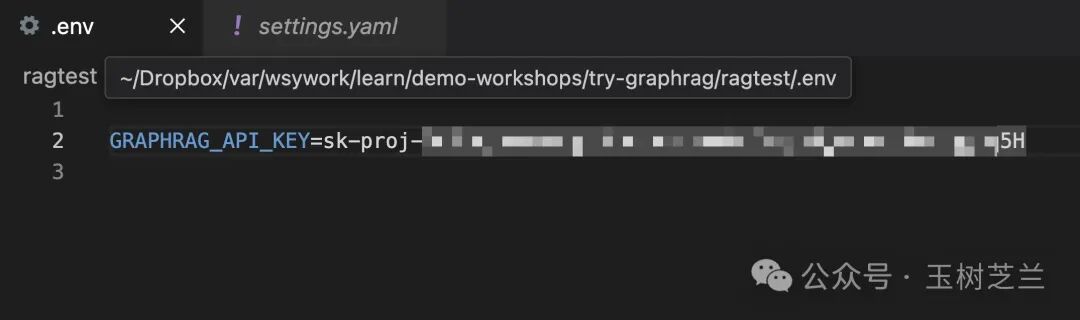
你需要将 OpenAI 提供的 API 密钥填入 GRAPHRAG_API_KEY 即可。
另外,settings.yaml 文件也需要修改。
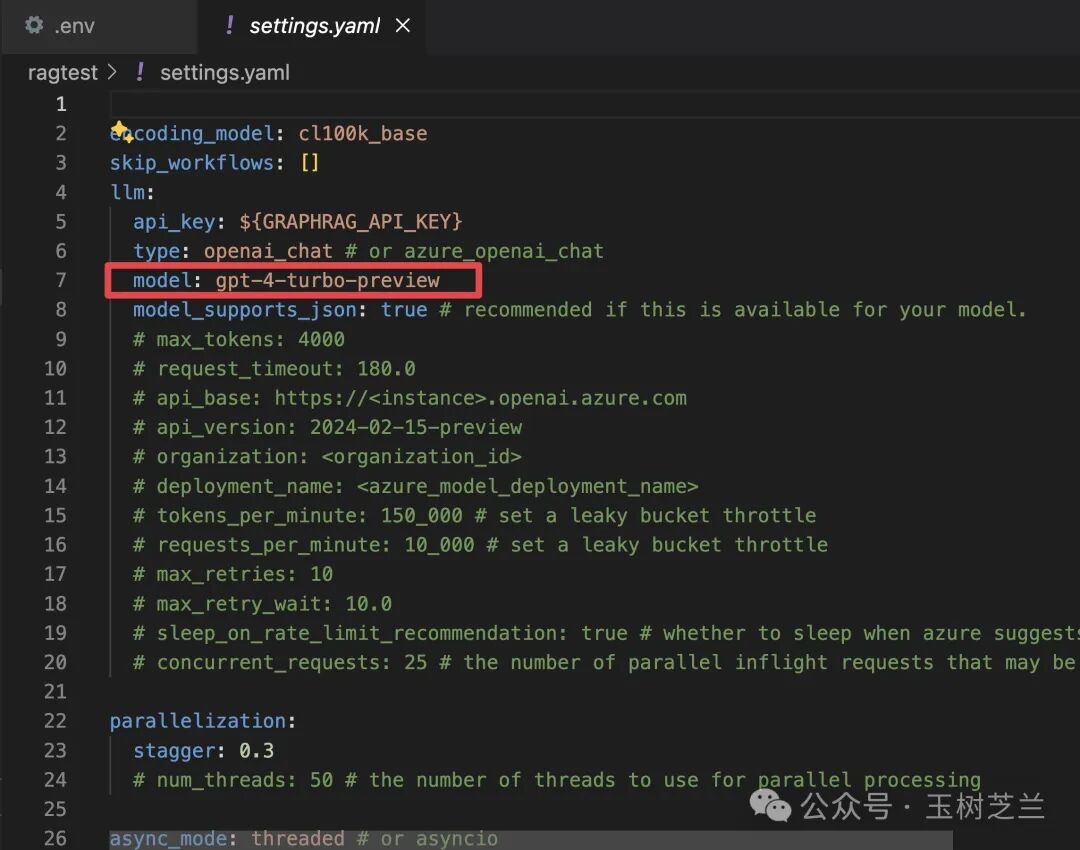
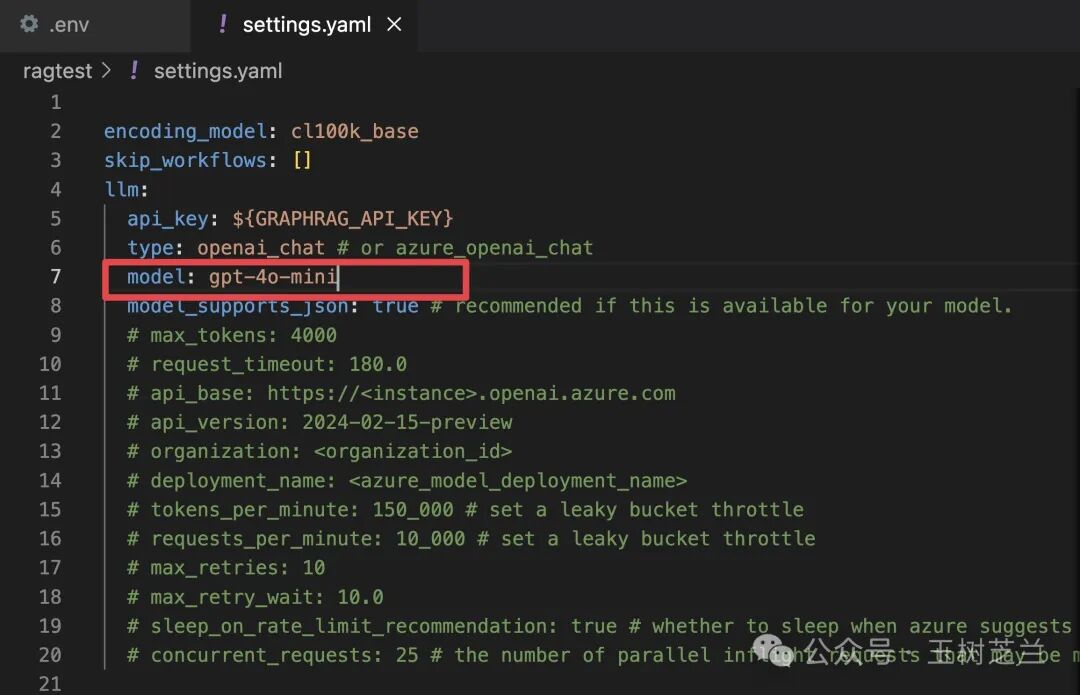
这里面有一项尤其需要注意。原来默认使用的是 GPT-4 Turbo preview,这一定要改为 GPT-4o mini,因为我们要尝试降低成本。其他设置无需更改。
接下来我们来建立索引。回到终端,执行以下命令。
python -m graphrag.index --root ./ragtest这条命令建立一个图谱化的知识库。这个过程花了足足五分钟的时间,咱们就不详细展示了。
查询
终于,图谱构建完毕。下面我们做一个查询。
python -m graphrag.query \ --root ./ragtest \ --method global \ "What are the top themes in this story?"注意这里的命令,Global(全局)代表我对整本书提问。我们问的问题是:这个故事有哪些最主要的主题?
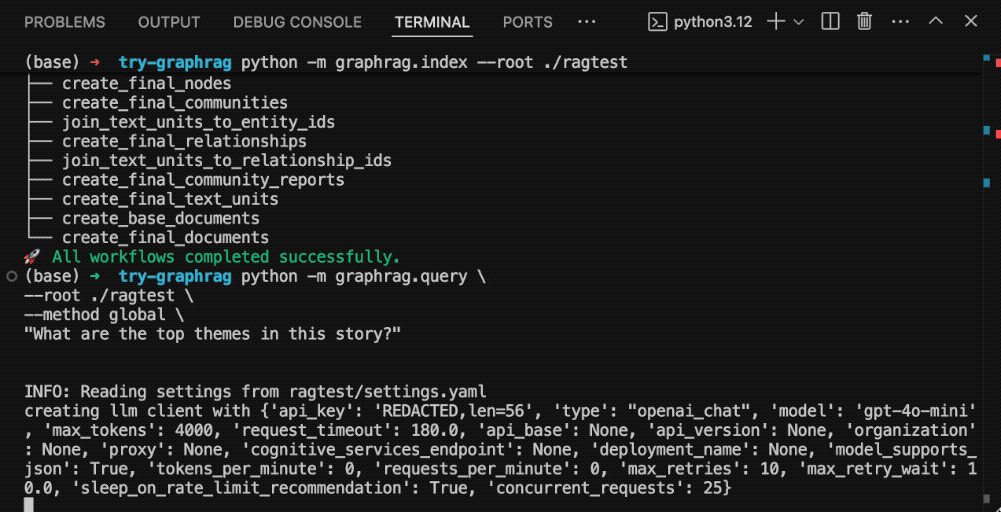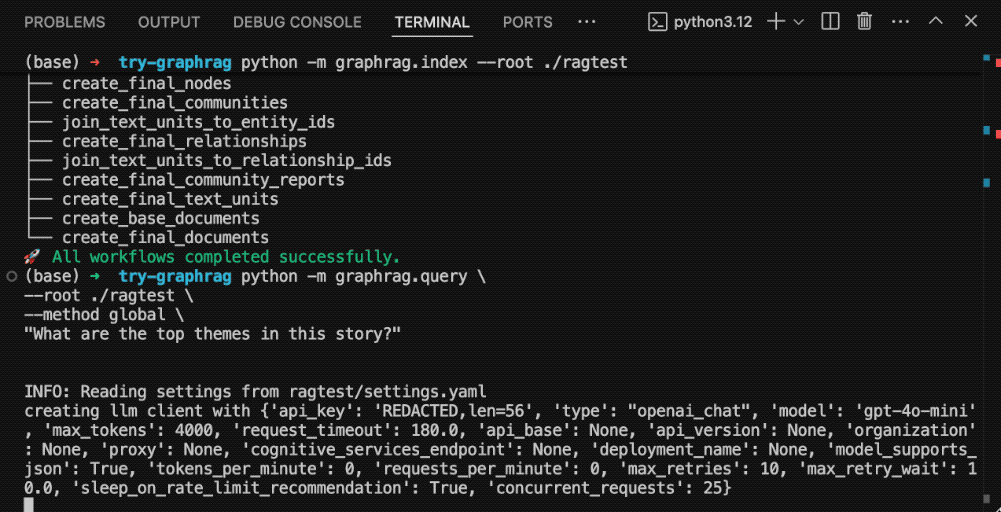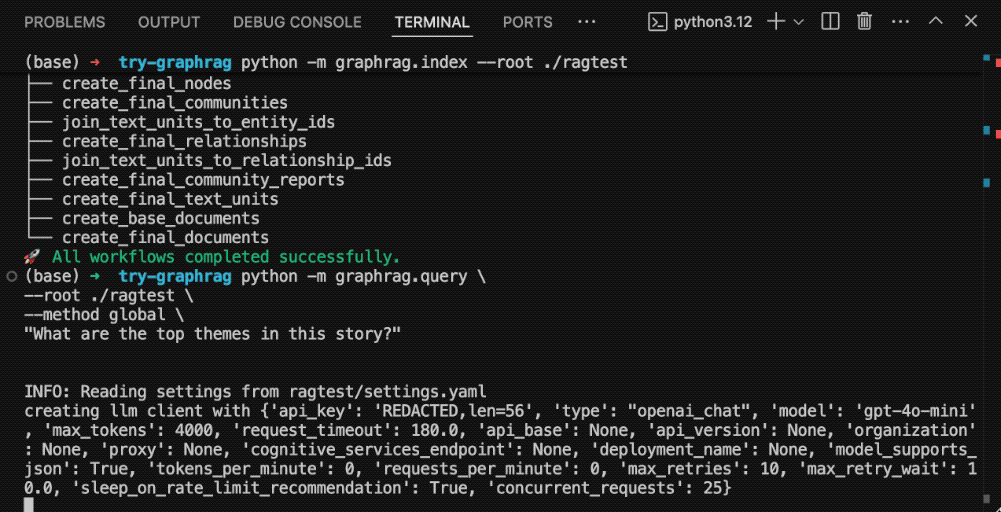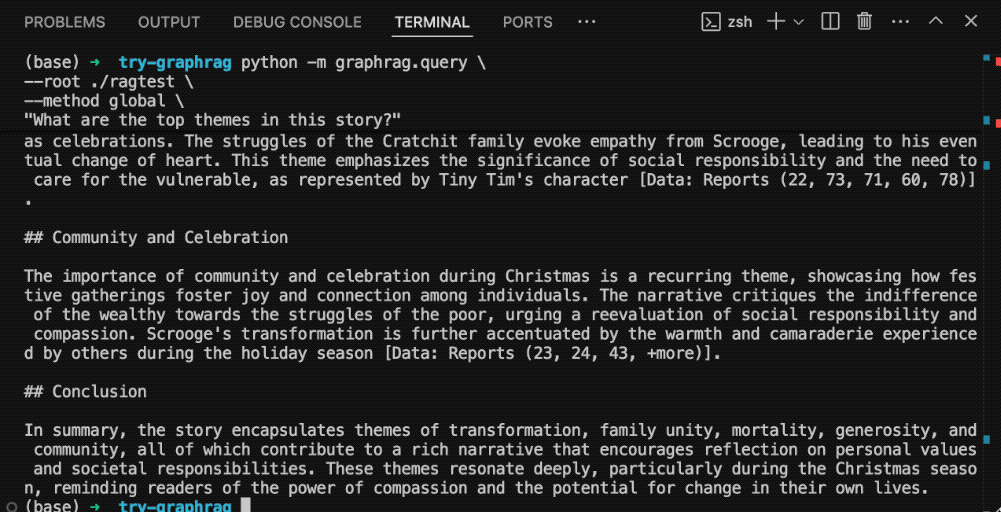
来看一下结果。

结果显示了若干主题,每个答案后面都有一系列的内容来源标号,这一点很重要。它强调了大语言模型没有幻觉,而确实是利用你提供的资料来给出答案。
为了让你看得更加清楚,我给你把上面的答案翻译一下。这里我们使用的是吴恩达老师的三步反思翻译法。
为了让 AI 工作流更加简单,我做了一个工具,并且开放在了 Github 上面,网址在这里。(https://github.com/wshuyi/workflows_with_litellm_pub)如果你觉得好用,别忘了给加颗星啊。
这个项目可以帮助我们快捷地执行工作流程。它包含了一系列预设的脚本和配置文件,使得我们能够轻松地设置环境、运行查询。
这个项目不仅可以提高效率,还能确保工作流程的一致性。你可以将复杂的工作流程简化为一个配置文件。这个文件可以清晰地定义每一个步骤,使得整个流程变得更加透明和可管理。
这就是一个配置文件的例子。
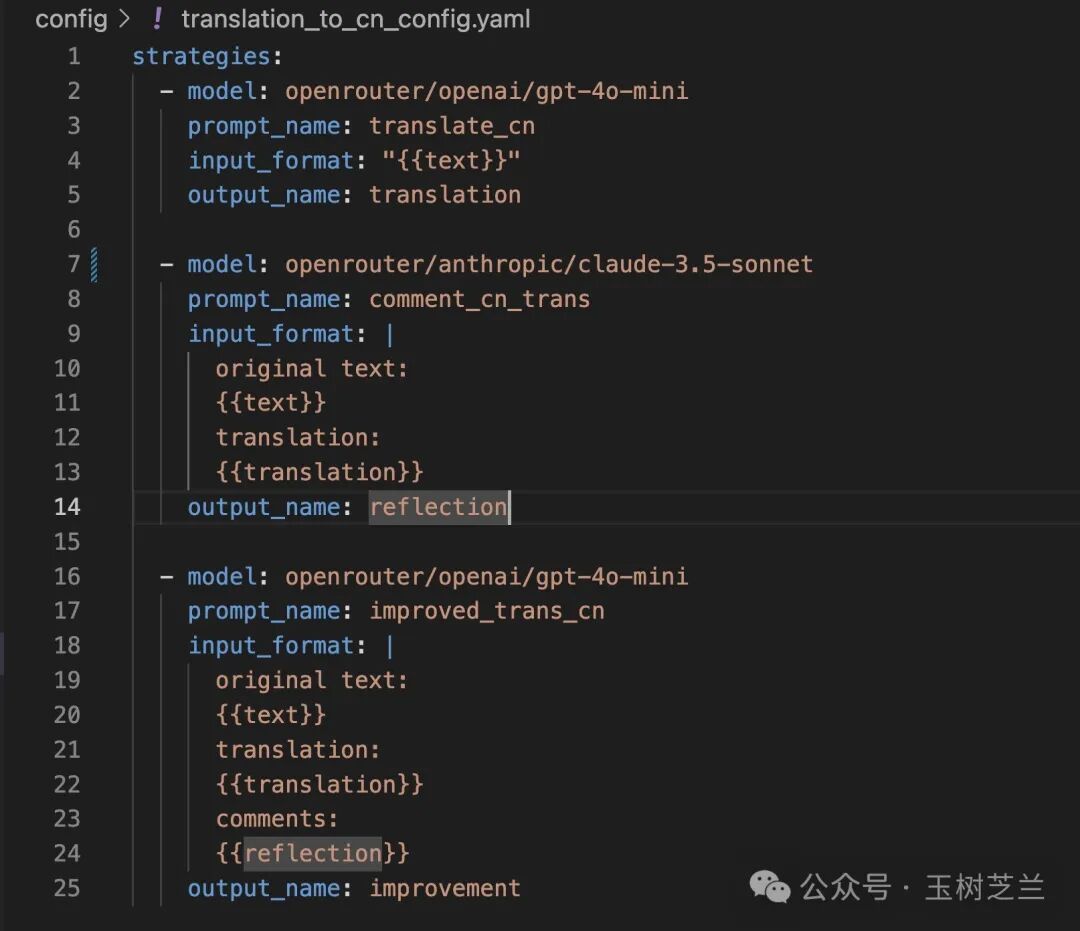
这里我说你要进行三步操作,这三步操作构成了一个完整的工作流程。
第一步是执行一个叫做 “翻译成中文”(translate_cn) 的工作提示词。这个步骤的目的是将输入的英文内容转换为中文。使用的输入来自于用户提供的信息,模型调用的还是 GPT-4o mini。
第二步是对刚才的翻译结果进行评价。这一步的目的是确保翻译的质量,通过客观的评价来识别可能存在的问题或改进空间。它的输入相对多一些,除了原文,还应该包括刚才第一步给出的直译结果。为了保证修改建议的有效性和可靠性,我们使用思辨能力更强的 Claude 3.5 Sonnet 模型。
第三步则是综合原文、直译和反思建议,进行精细翻译。这里我们还是使用 GPT-4o mini 模型,以降低成本,提升输出速度。
这种方法的优势在于它的灵活性和可定制性,你可以根据具体需求来调整每一步的提示词,从而优化整个工作流程。具体安装和使用方式,请参考《如何轻松定制和调用你自己的 AI 工作流》一文。

闲言少叙,我们来看翻译的结果。这个结果是经过我们刚才描述的三步工作流程处理后得到的。通过这个例子,你也可以直观看到工作流的效果。

验证
我们该不该相信这个结果?我觉得尽管在回答中,GraphRAG 给出了来源片段信息,但这还不够。
假设你根本就没有读过狄更斯的这本小说,该如何验证刚才给出的答案呢?
你可以写一个提示词:
然后,把这个提示词,连同刚刚 GraphRAG 给出的结果(英文即可)交给 Claude 3.5 Sonnet 。
然后,这是 Claude 3.5 Sonnet 给出的回答质量分析结果。让我们来看看它的评价。

Claude 3.5 Sonnet 给出总体评价:这是一个非常优秀的分析。这个结果证明了我们利用知识图谱进行检索的方法非常有效。到此为止,我们是否可以完全相信这个答案呢?
当然不行。
刚才看到的是大语言模型基于自己训练时对数据的记忆得出的结果,这依然可能会产生幻觉。因此,我们需要让 AI 连接网络进行查询,以验证信息的准确性。
在这方面,一个比较好的工具就是 Perplexity。它能够网络查询,验证信息的准确性。
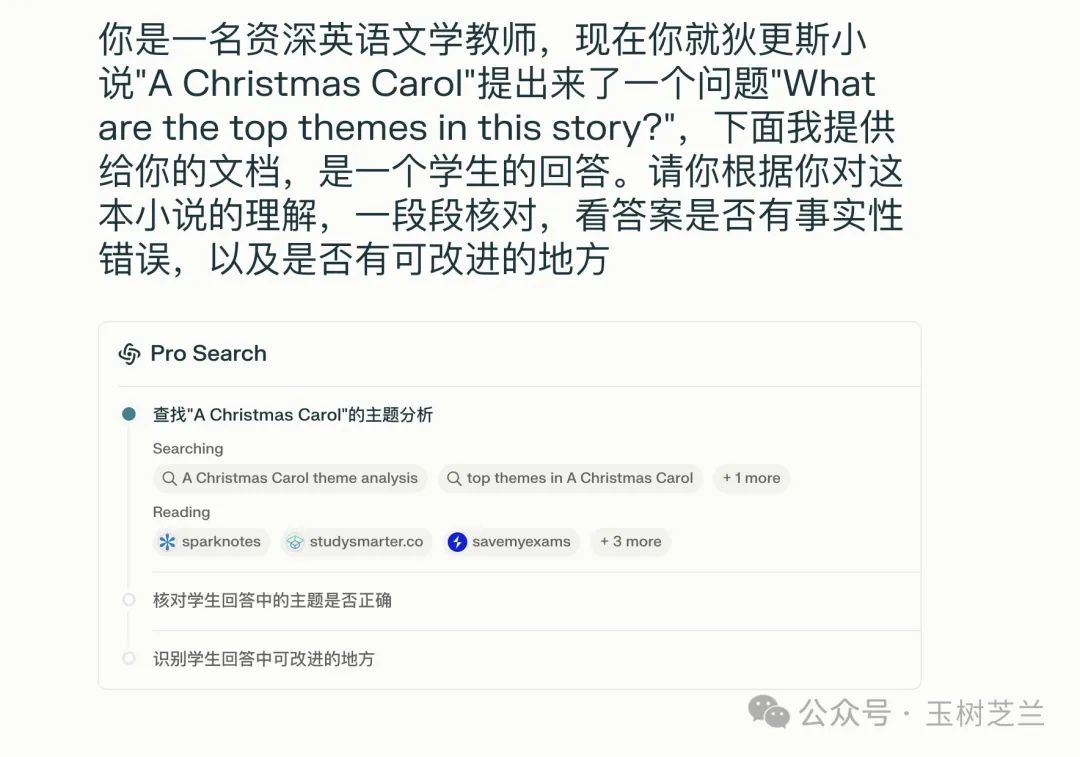
首先,Perplexity 会查找与输入内容相关的信息,列出了多个相关的信息来源。然后,Perplexity 会核对主题识别的准确性。

在 Perplexity 的分析中,你可以看到它使用了这些词语来评价:准确地捕捉、准确地识别、很好的捕捉,准确地指出、很好的总结。它还指出没有明显的事实性错误,主题的选择和分析都很到位。
通过这两种方法的交叉验证,我们对大语言模型根据我们的图谱式知识库给出的答案就更有信心了。
成本
使用这种方法的成本如何呢?
我打开 OpenAI 控制台查看,一开始吓了一跳 —— 今天的账单又起飞了?
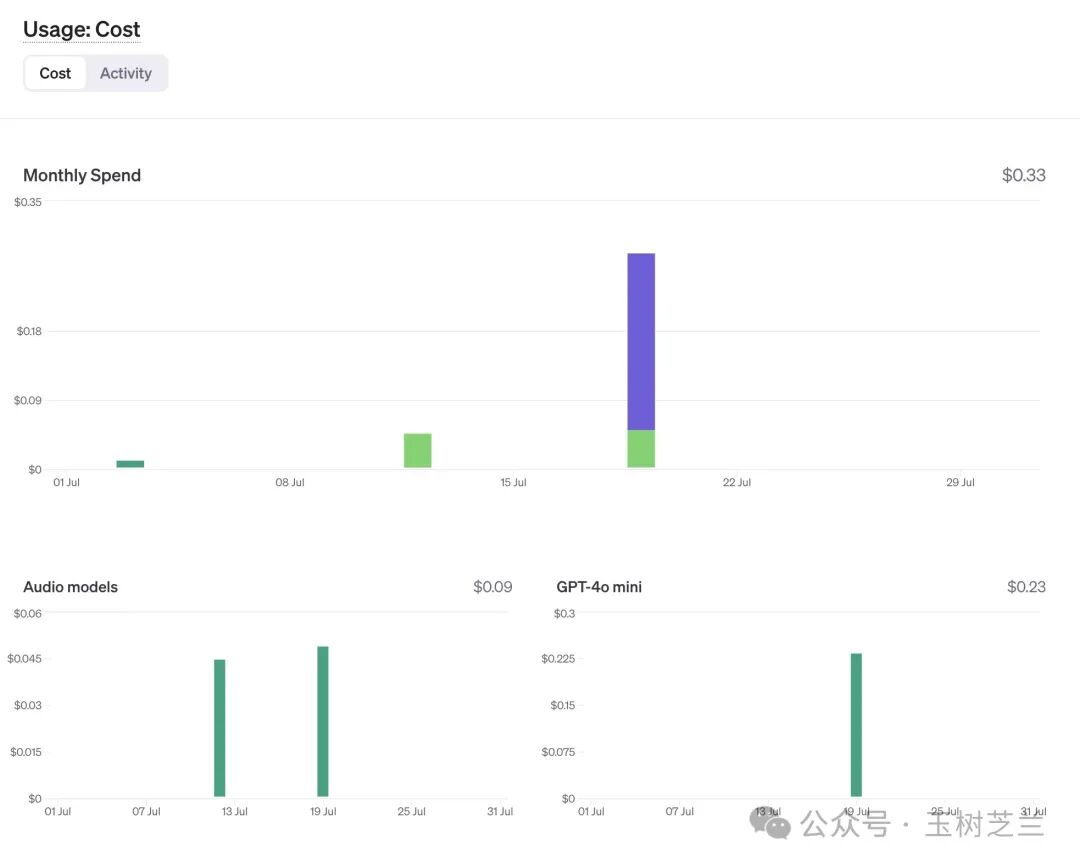
好在仔细一看,实际花费仅仅 0.28 美金。下面是明细。
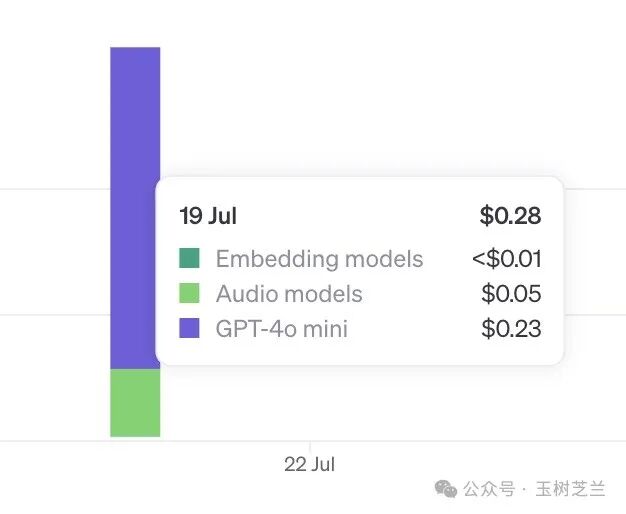
有 0.05 美金(将近五分之一)是用于语音识别的,这与我们当前的任务无关。
换句话说,我们用于总结这本书、构建知识图谱型知识库,以及进行查询的实际花费是多少呢?仅需要 0.23 美金。
考虑到使用官方样例花费 11 美金,你会发现 GPT-4o mini 带来的成本改善令人惊叹。
小结
通过本文的讲解,你可以发现 GraphRAG 技术能帮助我们更准确地回答全局性的复杂问题,这对许多应用场景来说至关重要。
进一步,结合 GPT-4o mini 模型,我们不仅提高了处理效率和速度,还有效降低了成本。对于个人用户、研究人员和企业来说,这都是一个好消息。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
