严格说MS 的graphRAG 是vector RAG和graph RAG的合体
也有叫hybird RAG的,之前贝莱德资本还写过一个论文,不过它写的有点水,方法也是比较浮于表面,愿意看到的大家可以读一下,我就不在这里讲了
HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction (arxiv.org)
那我们看看MS的graphRAG是咋做的
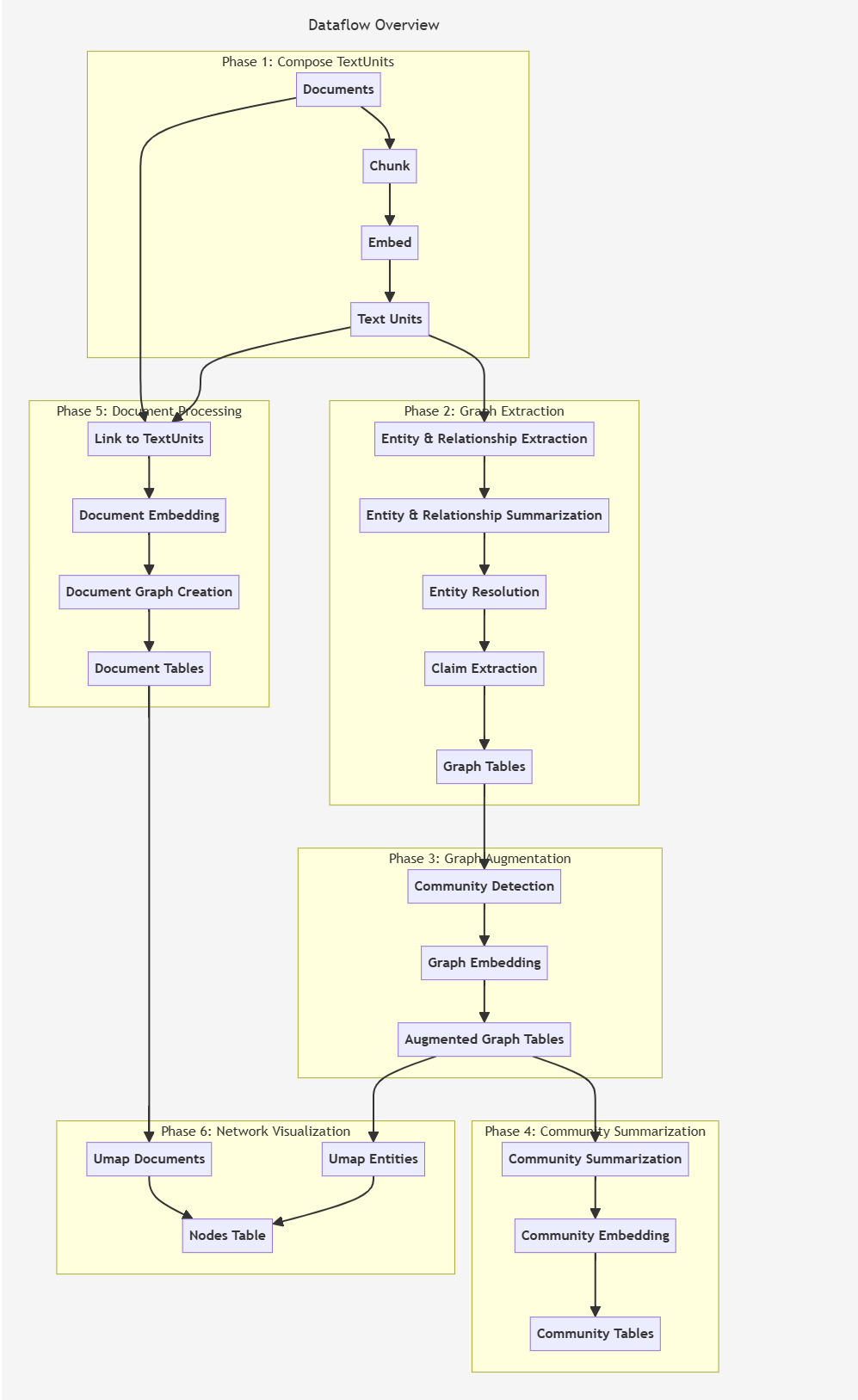
流程图比较长,我们分块看,从1到6一共6个步骤,其实6可以不做
首先
Phase1
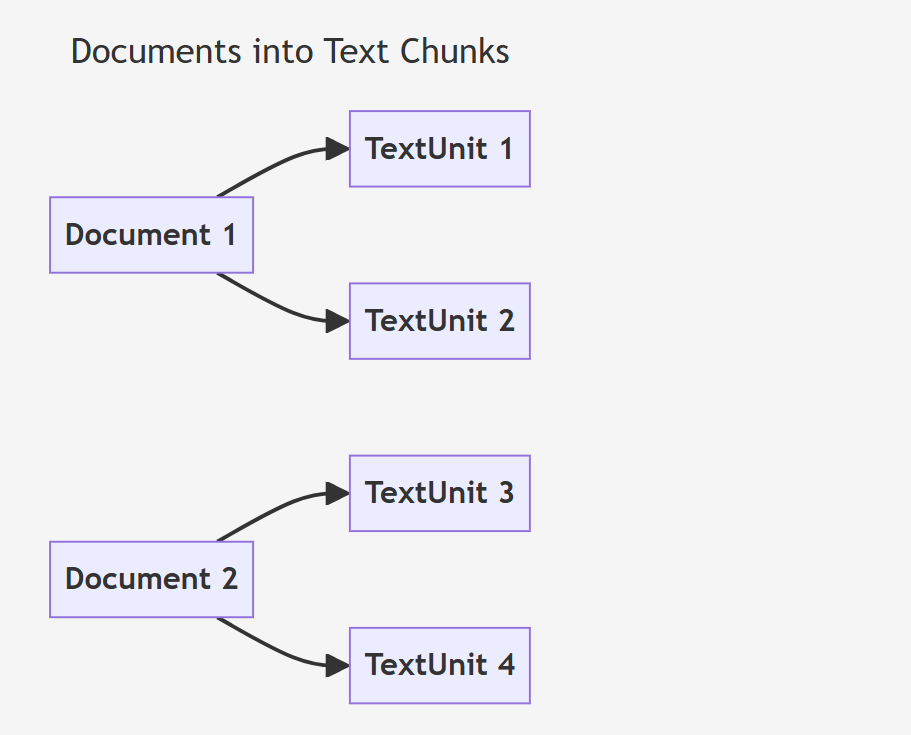
Phase 1 的任务是将输入的文档转换为 TextUnits(文本单元)。这些 TextUnits 是用于图谱抽取技术的基本文本块,并且可以作为知识项的来源引用。
具体步骤:
文档分块(Chunking):
文本嵌入(Embedding):
块与文档的映射(Mapping Chunks to Documents):
核心思想:
这些生成的 TextUnits 随后会被传递到下一个处理阶段,进入更深层次的实体和关系提取流程。这些文本块会通过嵌入模型转化为向量表示(embedding),以捕捉其语义信息。
TextUnit 是整个流程中的基本处理单元,后续的所有实体和关系提取、知识图谱的生成,都依赖于这些 TextUnits 及其对应的嵌入信息。
Phase2:
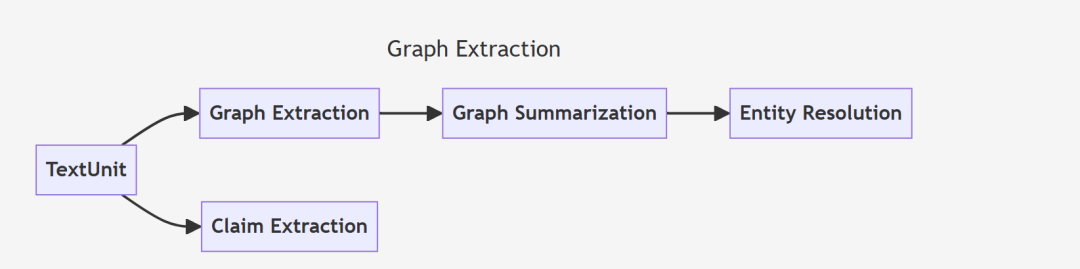
在第二阶段,系统会对每个 TextUnit 进行分析,提取出图谱的基本元素:实体(Entities)、关系(Relationships) 和 声明(Claims)。这一阶段的目标是从文本中生成与知识图谱相关的实体和关系,并将这些元素汇总为结构化的表示。
具体步骤:
实体和关系抽取(Entity & Relationship Extraction):
在图谱抽取的第一个步骤中,系统会处理每个 TextUnit,从原始文本中提取出实体和关系。
输出:每个 TextUnit 的子图包含一个实体列表(带有名称、类型和描述)和关系列表(带有源、目标和描述)。
系统会将具有相同名称和类型的实体合并在一起,并且将源和目标相同的关系也进行合并。
实体和关系总结(Entity & Relationship Summarization):
实体消解(Entity Resolution, 可选):(这个你就别开了,目前不建议)
声明抽取(Claim Extraction):
关键点:
实体和关系提取与总结:这一阶段的核心任务是提取实体和关系,并将它们简洁化为知识图谱的一部分。通过合并相同类型的实体和关系,系统确保了图谱的简洁性和有效性。
实体消解(Entity Resolution):虽然并未默认启用,但实体消解对于确保图谱中的实体一致性非常重要。未来的发展方向是通过非破坏性的方法实现实体的统一。
声明提取:声明的提取独立于实体和关系的处理,提供了关于文本中事实陈述的结构化信息,这些信息在后续的分析中非常有用,
我看好多人不理解声明或者这里面叫协变量Covariates啥意思,我来生动的解释一下,其实正常来说声明和协变量可以拆开两个概念。这里就当一个算了,好比说以下几个例子
经济分析:在经济图谱中,声明“2023年第二季度GDP增长了2%”可能会有协变量“消费者支出增加了5%”、“利率下降了0.5个百分点”等。这些协变量帮助解释了GDP增长的原因。
社会科学研究:在社会学研究中,声明“某地区犯罪率在2022年下降了10%”可能伴随有协变量如“该地区的失业率降低了5%”或“警察巡逻增加了20%”。这些协变量为犯罪率下降提供了背景信息。
临床试验:在医学研究中,声明“药物ABC在70%的试验者中有效”可能会有协变量如“试验者年龄范围为18-65岁”或“试验者的基础病情为糖尿病”。这些协变量帮助理解药物在不同条件下的效果。
协变量的功能
增强事实性:为图谱中的实体和关系提供了额外的上下文。例如,不仅描述某个实体存在的事实,还可以描述该实体在某个时间点或特定条件下的状态。
引入动态性:通过声明,知识图谱可以从静态信息扩展到动态信息。声明可以描述某些事实是如何随着时间变化的。
丰富推理信息:声明可以用来丰富图谱中的推理能力。例如,特定声明可能会影响到系统对某些查询的推理过程。
解释因果关系:例如,特定的市场条件(协变量)可能解释了公司业绩的变化。
提供额外上下文:提供了额外的上下文信息,使得知识图谱中的信息更加完整。例如可能受到某些条件的影响,而这些条件就是协变量。
增强模型推理:可以作为输入,帮助模型更好地推理特定声明的有效性或适用性。例如,在分析不同因素对某个结果的影响时,协变量的存在能够帮助模型做出更加精确的推断。
简单说就是提供了一定得动态图能力和时序处理能力,非常有用。
Phase3:

Graph Augmentation (图谱增强阶段)
在图谱增强阶段,系统已经拥有了一个可用的实体和关系图谱,接下来需要进一步理解图谱的社区结构,并通过额外的信息来增强图谱。这个阶段通过社区检测(Community Detection)和图谱嵌入(Graph Embedding)**两个步骤来完成。
1. 社区检测(Community Detection):
2. 图谱嵌入(Graph Embedding):
3. 图谱表输出(Graph Tables Emission):
总结:
Phase 3 的核心任务是通过社区检测和图谱嵌入,增强和丰富已经构建的实体和关系图谱:
提到Node2Vec大家可能比较乱,word2vec好理解,你把Node2Vec干么呢?
那你想想你word2vec是为了干么呢?
找语义相似性对不?那Node2Vec不也一样吗,近似的node会在隐空间距离更近,聚类不就好弄了么,其实就这么点事,看我的文章是不是一下子就明白了
Phase4:

Community Summarization(社区总结阶段)
在第四阶段,系统已经有了一个包含实体、关系和社区层次结构的功能性图谱,并且完成了通过Node2Vec生成的图嵌入。接下来,系统会基于这些社区数据生成社区报告,从而提供图谱在不同粒度级别上的总结。
1. 生成社区报告(Generate Community Reports):
2. 总结社区报告(Summarize Community Reports):
3. 社区嵌入(Community Embedding):
4. 社区表输出(Community Tables Emission):
总结:
Phase 4 的关键任务是生成和总结社区报告,并通过嵌入技术为这些社区报告生成向量表示。通过这些步骤,系统能够在不同的社区粒度上提供图谱的高层次理解,增强其对复杂查询的响应能力。
社区报告生成:通过LLM生成每个社区的总结报告,提供详细或高层次的图谱理解。
社区嵌入:为社区生成向量表示,使得系统可以在向量空间中更高效地处理与社区相关的查询。
最终输出:社区报告表包含了社区的所有关键信息和嵌入,供后续阶段使用。
第四步没啥歧义,没啥可解释的。
Phase5:

我之所以说MS的GraphRAG不是纯血graphRAG,是hybird主要就在这步
我们刚才讲了其实你看一下前4步,明明生成图的东西都够了,在第五步又折腾一回,但是是对什么操作呢?不是对entity级别的,而是对文档级别的
Document Processing(文档处理阶段)
在这个阶段,系统开始处理文档数据,并生成知识模型中的Documents表。这一阶段的任务是将文档与之前创建的 TextUnits 相关联,并生成文档的向量表示。文档处理完成后,系统会输出Documents表,供知识模型进一步使用。
1. 字段增强(Augment with Columns, CSV Only):
2. 链接到文本单元(Link to TextUnits):
3. 文档嵌入(Document Embedding):
4. 文档表输出(Documents Table Emission):
目标:在完成文档处理之后,系统会输出 Documents 表。这张表格包含了所有处理过的文档及其嵌入表示,并将这些文档与之前的 TextUnits 关联起来。
作用:Documents 表是知识模型中的一个重要部分,它包含了文档的语义表示和结构化信息,供后续的查询、推理或分析使用。
与前几个阶段的关联:在前几个阶段中,系统已经创建了 TextUnits(文本单元)并生成了图谱中的实体和关系。而在Phase 5中,文档处理阶段则将这些文档与 TextUnits 关联起来,并生成文档的嵌入表示。这一阶段为文档提供了更丰富的语义层次,并为后续阶段的查询和分析奠定了基础。
文档的嵌入生成:通过文档嵌入,系统可以将整个文档映射到向量空间中,这使得文档能够在语义层面被理解和处理。这一过程与之前生成的 TextUnits 嵌入相辅相成,确保文档在语义搜索时具有一致性。
总结:
Phase 5 的文档处理阶段将文档与 TextUnits 相关联,并生成文档的嵌入表示,为知识模型提供了文档的语义信息。这一阶段输出的 Documents 表格将作为后续查询和分析的重要基础。
第五部分疑惑可能是最多的,尤其是懂点rag的人
大部分都集中在,为啥要做文档级别的向量化?
全局语义 vs 局部语义:TextUnits 的嵌入能够捕捉文档的局部信息,但文档作为一个整体,其全局语义可能不同于各个局部语义的简单叠加。生成文档的嵌入表示可以帮助系统理解文档整体的语义内容,而不仅仅是单独的块。
文档级别的操作:在实际应用中,有些任务可能需要处理整个文档的语义,而不是局部信息。例如,文档分类、主题分析或文档间相似性计算等任务往往依赖于文档的全局表示。文档嵌入使得这些文档级别的操作更加方便。
下一个问题,文档级别向量化,好多LLM根本装不下,太大了。
这是个好问题,所以我们化整为零,再串起来。啥意思呢?
重新分块:虽然文档在Phase 1已经被分块为 TextUnits,但在文档嵌入阶段,系统可能会重新对文档进行分块(chunking),这些新的块可能和之前的 TextUnits 不同。新的分块不重叠,目的是生成一组新的块。
生成块的嵌入:对于这些新的块,系统会为每个块生成嵌入表示。这与之前针对 TextUnits 的嵌入生成类似,但这些块的嵌入将被用作生成整个文档嵌入的基础。
加权平均:生成块的嵌入之后,系统会对这些块的嵌入进行加权平均(通常根据每个块的token数量),从而得到整个文档的向量表示。这个加权平均过程确保了每个块对文档整体嵌入的贡献是按其大小比例来决定的。
针对整个文档进行向量化,但这个过程是通过对文档重新分块、生成每个块的嵌入,然后对这些块的嵌入进行加权平均来完成的。最终得到的是文档的全局向量表示,而不是仅仅依赖 TextUnits 生成的局部嵌入
这样弄的话每次进行embedding的东西其实不大,然后和一起加权就能生成完整的文档的向量化,虽然说,有可能丢失一定得上下文,但是最起码能用,还省资源。
最后一个值得说的就是MS GraphRAG处理csv是挺好用的,咋说呢?
比如你有这么个表
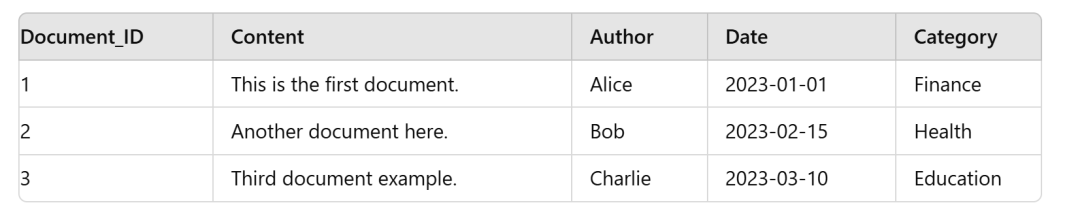
正常向量化,要不就是只把content部分给向量化了,要不就是把后面字段一起放进来。那笨寻思,后面什么作者,date,分类啥玩意的,这些东西就这么点,在语义上肯定啥也不是啊,根本也分不出来
但是你说它们几个有没有有用呢?那在特定认为比如分类啥的,这都太有用的东西。
MS的graphRAG就提供了high light他们的能力
增强的方式:
元数据的使用方式:
直接作为特征使用:在某些情况下,CSV文件中的额外字段可以被直接用作特征。例如,如果你有文档的类别标签(Category),那么这个标签可以直接作为文档分类的一个输入特征。
嵌入元数据:如果额外字段的信息不是简单的类别标签,而是像文本数据一样可以表示语义(如作者名、标题等),系统可能会对这些字段进行嵌入(embedding),然后将这些嵌入与文档内容的嵌入结合起来,形成文档的整体表示。例如,如果Author字段代表的是文本信息,可以将这个字段嵌入为向量,然后与文档的内容嵌入进行拼接或合并。
增强的具体过程:
嵌入方法:
增强后的应用:
假设我们有一个文档的Category字段,该字段表示文档的类别为“Finance”。这个字段可以作为一个简单的分类标签直接使用,也可以通过嵌入表示与文档内容结合。例如:
Phase6:
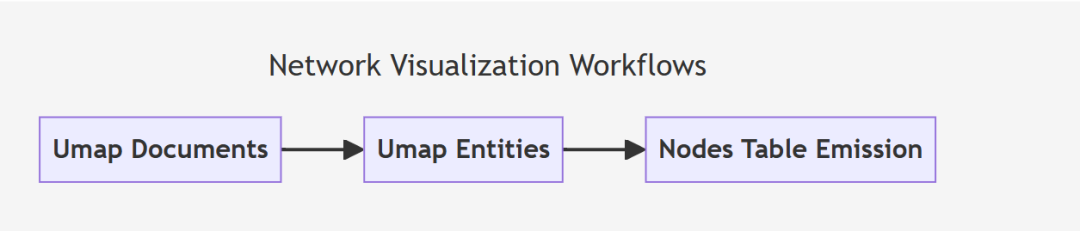
就是一个可视化而已,这步没啥可说的,就是拿UMP做降维用,降成2维坐标,其实也可以3维展示node和relationship啥的关系
































 粤ICP备14082021号
粤ICP备14082021号