
导读 PingCAP 的 AILab 项目人力投入不超过三人,因此本文将以小团队视角,分享如何利用 RAG 方法高效构建各种 RAG 应用。
1. 较大规模文档的业务挑战
2. RAG 技术落地实践和演化过程
3. 前沿介绍
4. Q&A
分享嘉宾|李粒 PingCAP PM
编辑整理|王吉东
内容校对|李瑶
出品社区|DataFun
PingCAP 作为一家开发关系型数据库的公司,主要产品包括TiDB 和 TiDB Cloud 这两类产品(即 OP 部署和云上服务)。数据库和搜索存储类产品都属于较为复杂的产品,会存在大量的文档。目前 PingCAP 已有英文文档和中文文档超过 2K,再加上社区内有价值的文档,总文档量可达15K。

正因为 TiDB 文档丰富,一个普通用户是不可能阅读完这么多文档的,因此难以得到全盘认知,或快速找到所需的内容。作为一家成长中的小公司,人力有限,随着用户规模的增长,缺乏技术支持人力的问题日益凸显,导致技术回答间隔较长,这一问题在发展相对成熟的海外社区尤为明显。

针对上述问题,我们开发了基于文档的问答机器人(上图为机器人 demo),目前已经上线到 Cloud UI,以及海外社区,比如在 Slack、Discord 上可以直接@机器人进行提问。
RAG 技术落地实践和演化过程
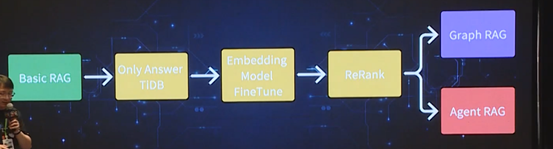
我们的 RAG 实践过程可以分为四个阶段,如上图所示:绿色阶段是 Basic RAG,即最基础的工作;黄色阶段是应用的优化;最后分成 Graph
RAG 和 Agent RAG 两个方向。
1. Basic RAG
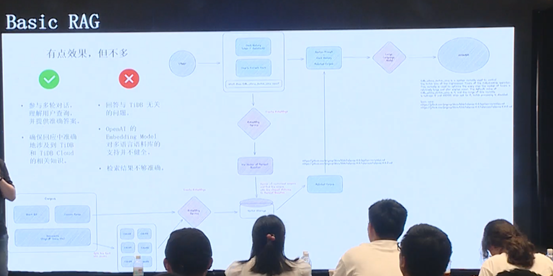
Basic RAG 的逻辑非常简单,利用大语言模型的多轮对话能力,理解用户查询,并提供准确答案。然而基础大预言模型经常会输出与 TiDB 无关的内容。最初尝试的大模型是 OpenAI,其 Embedding model 对多语言数据库的支持并不健全,检索结果不够准确,因此有必要对模型进行调优。
2. Only Answer TiDB

由于我们团队很小,考虑到成本问题,自行训练或 finetune 模型并不是最优解,相比而言 RAG 更加划算,因此最终选用了 RAG 方式。
我们的需求只是限制大模型仅回答 TiDB 和业务相关的问题,使用业界常用的毒性检测技术即可实现,将和 TiDB 无关的业务定性为毒性,进而让大语言模型去判断是否和 TiDB 相关。

上图列举了一些使用 prompt 的例子,包括 TiDB 的描述等没有在图中展示出来的细节;对于 RAG 部分,图中的几个 example 是根据用户问题,通过向量相似度提取,即可简单直接地判断该问题是否和 TiDB 相关。

上述方式的效果是比较理想的,如图,面对用户提出的“how to cook a cake”、“what about China”等与 TiDB 无关或政治敏感的问题,均给出了类似“该问题与 TiDB 无关”这类的回应。
因为在前面的流程图中可以看到,这一环节我们在设定中,只会让 LLM 输出 yes or no,让模型自行判断下一步要走哪一分支。这样的方式,一方面可以做到合理的毒性检测,另一方面,如果有用户尝试使用一些 prompt 的越狱方法时,因为输出不是 yes,该流程也会判定为 no,这样可以避免 prompt 越狱的情况发生,保证 LLM 只输出和业务相关内容。

那么为什么不直接在 System Prompt 中要求输出限制呢?因为 System Prompt 中没有权重,这意味即使增加限制,当用户输入足够长的越狱 prompt 后,模型的回答还是会出现越狱现象,因此还是需要使用 RAG 结合毒性检测的方法来真正避免越狱。
3. Embedding Model
Finetune

TiDB 是面向全世界的,因此会存在英语、日语等多语种语料,而 OpenAI 最先进的 Embedding model(text-embedding-ada-002)不支持非英语语言。假如用户提出一个问题,模型返回的召回文档,top 结果全部是英文文档,然而我们无法将来自全世界的海量文档统一成英文,因此会带来极大的不便。
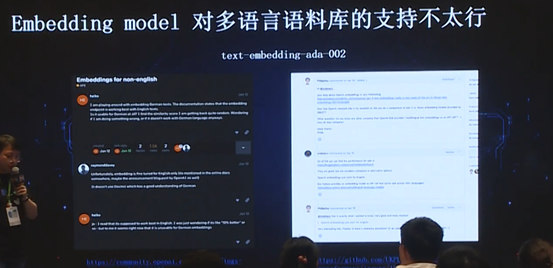
此外,官网以及 UKP Lab 等社区中也证实了 OpenAI 不支持除英语之外的其他语言。
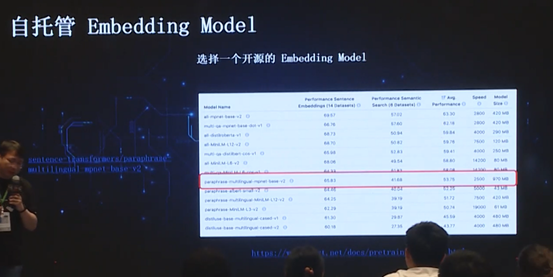
为了解决这一问题,只能自行 finetune
Embedding model,以弥补开源Embedding model 的局限性。
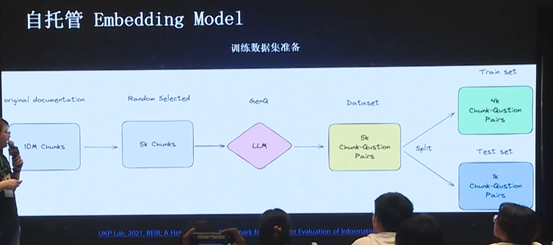
由于团队人数有限,为了尽可能减少人工的工作,因此最终选择了机器学习领域常用的 GenQ 方法,首先对所有文档进行分块(chunk),随后随机挑选部分文档进行进一步切分,最后使用 GenQ 方法生成文档及其对应的 question,从而获得 chunk-question pairs,进而将其拆分成 Train set 和 Test set,对模型进行训练。
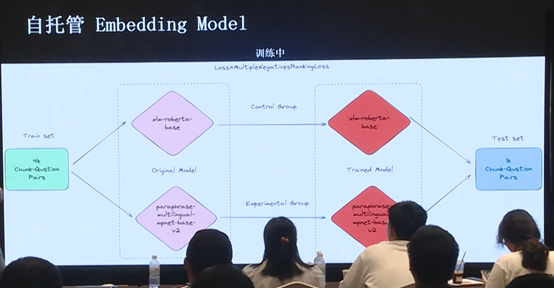
对于模型训练,使用 MultipleNegativesRankingLoss 方法,选取了两个模型(一个是上面的小模型,一个是下面的要用于生产环境的模型),使用 4K 数据去训练,使用 1K 数据做测试。

关于前文提到的 MultipleNegativesRankingLoss 方法,由于训练数据由 GenQ 方法生成,因此只有正例(即正确的 question-answer pair)而没有反例,这样的 Train set 显然是不够的,因此需要去自动生成反例(即错误的 question-answer pair),从而控制正负样本比例,这样的训练才更高效。

上图中,最上面的模型是 OpenAI 的 text-embedding-ada-002,准确率结果为 0.984;最下面的是我们 finetune 得到的模型,结果为 0.983。考虑到该结果是基于 OpenAI 生成语料的训练和测试结果,可能会存在一定程度的过拟合,因此后期又选择 TiDB 官方文档进行多轮测试,结果仍然比较理想。可能在其他领域,该模型的 Accuracy 有可能出现下降,但是对于我们所关心的数据库领域,在正常语料库下,其结果是能够达到我们的要求的。

接下来,使用 finetune 后的多语言模型去完成任务,从而保证公司超过 15K 的全部文档被充分利用,避免了像 OpenAI 那样只能使用英文文档。

使用 Embedding model
finetune,无需过多人力投入,模型训练效率高,且成本很低。此外,自托管 Embedding model 支持多次调整。RAG 向量搜索,其质量主要取决于向量表达,而向量表达则依赖于 Embedding
model,因此会针对性地对用户的提问与文档的关系进行向量表达的匹配,经过多次 finetune 从而获得更高的召回准确率。这也是自托管 Embedding model 的额外好处。
4. ReRank
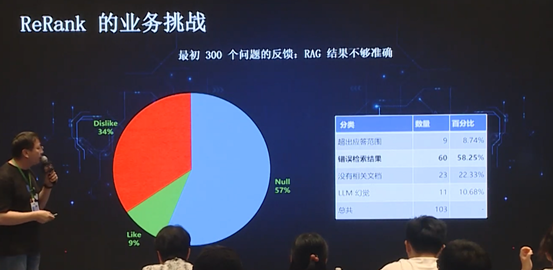
由于我们的产品发布后,会立即应用到公司内部,以及一些灰度客户,在最初的几个月时间内,会让用户对所有的问题结果进行点赞或点踩,从而获得用户的反馈结果。然而并不是所有的问题都能得到用户的反馈,从上图可以看出,有 57% 的问题没有得到反馈。而且用户 like 的占比只有 9%, dislike 占比达到 34%,说明初版模型的效果非常糟糕。通过人工统计发现,其中最大的问题在于检索结果错误。

因为真实世界的问题过于复杂多变,因此在召回时表现得不够理想。从技术角度来说,主要原因在于相似度召回的 ranking 过低,因此被排除在外,这导致没有正确的语料给到大模型,这样大模型只能依靠“幻觉”来回答,这就是前文所述的有文档但是召回了错误的文档。
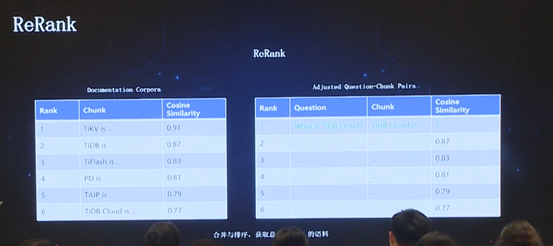
为解决这类问题,我们做了简单的 ReRank,把用户常用的 QA pairs 记录到向量数据库中,并且重新使用向量空间(可能是向量数据库,或者一张表,或者 name space 等)进行存储。在召回阶段,会同时在原始文档向量空间和优化后的向量空间进行召回,选取 top 10 到 LLM 中进行进一步的处理,从而判断最适合的文本语料,这就是 ReRank 的过程。
基于上述过程,目前所有 ad-hoc 的 basic RAG 的问题都能得到较好地解决。
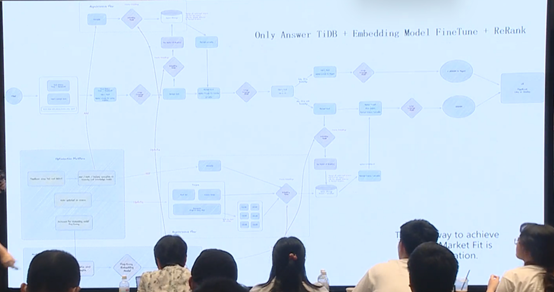
因为要承担相应的业务,因此大量工作都留在上图的左侧,即 OPT 平台(optimization platform),会自动追踪用户产生的各类问题、疑问,并记录用户分享甚至用户的 dislike 等。用户正向的行为数据记录到另一个向量空间中,以备将来使用。而对于用户负向的行为数据,会分成两部分处理,一部分再次让 LLM 进行回答,并定向推送给用户,让用户再次确认回答是否正确;另一部分,由专家介入排查错误原因,进行重新调整。当调整后的 QA pairs 足够多时,便可以将这些数据作为 Embedding
model 的训练材料。
通过上述流程,实现了产品从灰度上线到持续使用并不断优化,目前 dislike 的比例已从最初的 34% 降低到了 2%-3%。
5. Basic RAG 的业务挑战

Basic RAG 面临的挑战也非常明显。前文所述,都是围绕向量相似度展开,然而在有些场景下,向量相似度未必是最优的搜索方法。我们真正的需求并不是 RAG,而是一个全知全能的搜索引擎,只是当下没有任何搜索引擎能做到这个程度(包括 google)。因此我们需要对搜索的方法做调整,而 RAG 是基础的向量搜索方法,如果该方法效果不理想,就要引入其他方法,包括图数据库方法,以及直接加入真正的搜索引擎(如 google、bing 的 API 等),目的是满足业务需求,而并不限定于某一种技术栈。
6. Graph RAG

微软在今年 4 月发表了一篇关于 Graph RAG 的论文,规范、系统化地解释了如何使用 Graph RAG 实现引擎搜索功能。我们与微软团队,以及 LlamaIndex 三方合作,对引擎搜索功能进行了探索,分为 index 和 query 两个阶段。

对于 index 阶段,首先需要实现 KG(Knowledge Graph),因此需要非常丰富的文档及社区问答,接着需要对文档进行切分。
然而这里存在一个问题,在实现 KG 时,到底使用 entity 做 graph,还是用 chunk 做 graph?结合实验,参考 google 方案,最终两者都需要,既包含 entity 也包含 chunk,而且这个 chunk 是基于 entity 进行 summarize 得到的 chunk。
由于构建知识图谱是个异步的过程,因此有充足的时间将每个 entity 相关的摘要信息全部生成,再存到向量数据库中。

我们开发了一个可视化工具,将文档的知识图谱的节点和边展现出来。
我们也制作了一个 Indexing
Handbook,感兴趣的读者可以扫描上图二维码(link to google Colab),了解如何一步步搭建知识图谱,并实现 query。
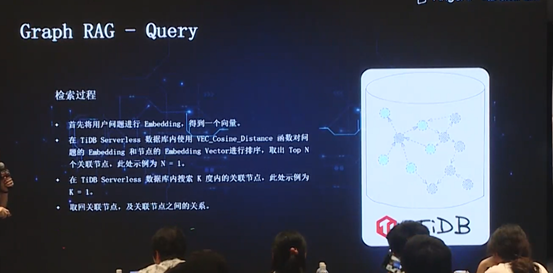
接下来,query 过程就是将用户的问题 embedding,得到一个向量,然后搜索出 K 度内的关联节点及节点间关系,并将其组装起来,输入到 LLM 中。
7. Agent RAG 的业务挑战

前文所述都是基于用户问答进行的,然而用户问答中有一种特殊情况,即诊断问答,诊断问答往往不能仅通过单次交互、单次 RAG 获得,因此另一条线是以 Agent RAG 的方式,供终端客户(如工单,以及云端运维平台的用户等)使用。
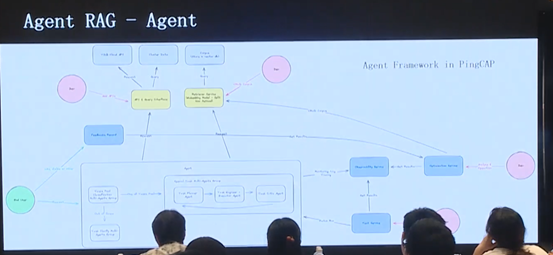
上图展示了 Agent RAG 的简单架构,使用 agent 方法 trigger 语料库,从而获取各类 API 信息以及异构数据信息,并且通过可观测性、优化平台和测试平台,保证模型准确度不断上升。

Planner:将具体问题规划成一系列子任务流程(即图中的 Step);
Engineer &
Executor:形成 pair,负责执行 Planner 构建的 Step,将子任务流程逐步完成;
Critic:对执行结果进行评价,主要关注执行内容和用户问题是否相关,以及用户问题是否得到解决等。
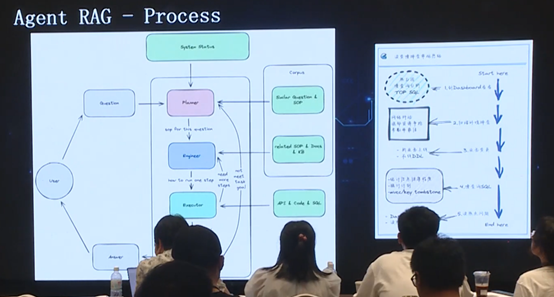
在 Planner 过程中,会输出一系列 system status,并 track 各类 RAG,从而得到相应的背景信息;在 Engineer 和 Executor 过程中,会通过多种 RAG 方法实现,诸如调用相应 API、生成 SQL 或其他代码执行相应计算等功能;Critic 过程判断流程执行情况等。以上就是基本的逻辑。
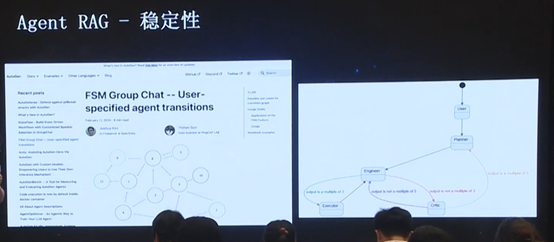
上述 Agent 是基于微软 AutoGen 框架,为了增强其稳定性,增加了FSM 特性,使得整个 agent 之间的流转更加稳定。
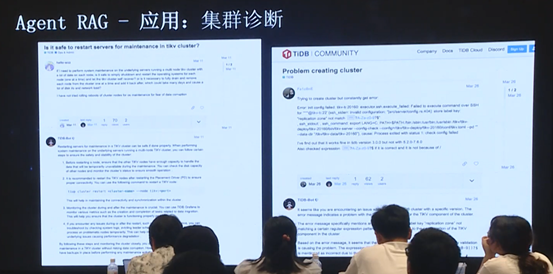
目前 Agent RAG 已应用于内部的一个集群诊断平台。
8. RAG 应用图
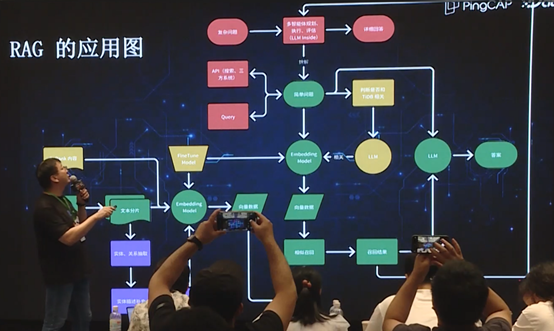
上图中对我们所有的 RAG 应用进行了总结。其中绿色部分是最初的 Basic RAG 的流程,为了优化这一流程,在此基础上增加了黄色部分,包括判断是否 TiDB 相关、finetune Embedding model、ReRank 内容,因为是以业务为目标,所以在语料、模型以及工程等每个环节都进行了优化。
为了让一次更精准,我们构建了知识图谱,特别是对于答案分布于多个文档中的情况,借助知识图谱使之前很多难以回答的问题都得以成功解答。
更进一步,为了解决更复杂的问题,我们又采用了 Agent 的方式,利用多智能体规划评估,使用整个语料结合各类 API,共同联合解决问题。
以上就是 PingCAP 在基于 RAG 进行文档智能问答方面的业务实践。
前沿介绍
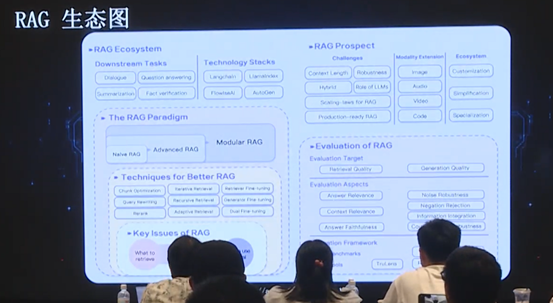
上图展示了当前的 RAG 生态,相信大家已较为熟悉,在此不做展开介绍。值得指出的是,对于 RAG 而言,评估系统至关重要。我们的工作聚焦于 Modular RAG,未来则会向 Evaluation of RAG 方向发展。
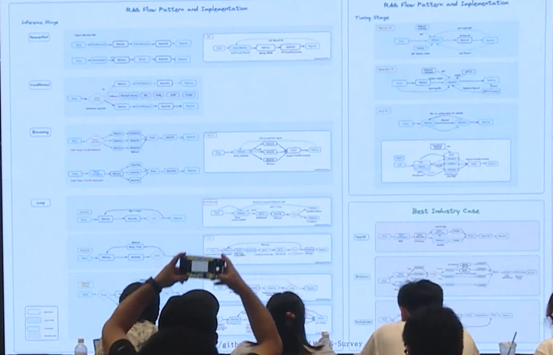
上图是同济大学的 RAG server,涵盖了各类 RAG 实施方法,非常全面。其中右下角是最佳工业案例介绍,为我们的工作提供了很多的参考。我们所使用的 agent 的方法,和图中左下角 loop 方法相似,区别在于我们使用的是 AutoGen Agent。
Q&A
A1:本文没有详细介绍语料这一部分,然而“garbage in garbage out“,语料的重要性不言而喻。在工业实践时,最理想的状态是统一的语料输入(例如我们使用的是 Markdown 输入)。对于图片部分,暂时没有尝试图片识别这类处理,因为初步尝试发现无法达到工业级的质量要求。目前图片识别的最高标准是 GPT-4o,该标准还不足以满足工业级别的图片分析要求,特别是对图片的理解,并与上下文以及用户提问进行关联,进而准确回答用户问题,这一要求目前还无法做到。
A2:有两个建议。首先可以参考 Llama index,充分利用开源的力量,里面包含按标题处理切分这样的逻辑。其次,假如 Llama index 中没有包含该逻辑,那么可以根据具体情况进行灵活处理;例如,对于 Markdown,可以按照井号实现切分,并在井号上下侧各做增加一层 overlap,确保上下文的语意连贯。RAG 领域并没有银弹,需要根据具体业务进行调整。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
