众所周知,LoRA 是一种常见的参数高效的微调方法,我们在《梯度视角下的LoRA:简介、分析、猜测及推广》做过简单介绍。LoRA 利用低秩分解来降低微调参数量,节省微调显存,同时训练好的权重可以合并到原始权重上,推理架构不需要作出改变,是一种训练和推理都比较友好的微调方案。此外,我们在《配置不同的学习率,LoRA还能再涨一点?》还讨论过 LoRA 的不对称性,指出给 A,B 设置不同的学习率能取得更好的效果,该结论被称为“LoRA+”。
为了进一步提升效果,研究人员还提出了不少其他 LoRA 变体,如 AdaLoRA [1]、rsLoRA [2]、DoRA [3]、PiSSA [4] 等,这些改动都有一定道理,但没有特别让人深刻的地方觉。然而,前两天的《LoRA-GA: Low-Rank Adaptation with Gradient Approximation》[5],却让笔者眼前一亮,仅扫了摘要就有种必然有效的感觉,仔细阅读后更觉得它是至今最精彩的 LoRA 改进。
究竟怎么个精彩法?LoRA-GA 的实际含金量如何?我们一起来学习一下。
基础回顾
首先我们再来温习一下 LoRA。假设预训练参数为 ,那么全量微调时的更新量自然也是一个 矩阵,LoRA将更新量约束为低秩矩阵来降低训练时的参数量,即设 ,其中 以及 ,用新的 W 替换模型原参数,并固定 不变,只训练 A,B,如下图所示:为了使得 LoRA 的初始状态跟预训练模型一致,我们通常会将 A,B 之一全零初始化,这样可以得到 ,那么初始的 W 就是 。但这并不是必须的,如果 A,B 都是非全零初始化,那么我们只需要将 W 设置为: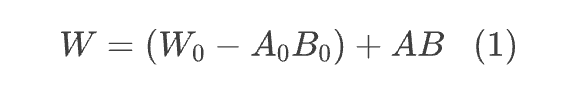
也就是说将固定不变的权重从 换为 ,同样可以满足初始 W 等于 这一条件。需要指出的是,LoRA 往往只是显存不足的无奈之选,因为一般情况下全量微调的效果都会优于 LoRA,所以如果算力足够并且要追求效果最佳时,请优先选择全量微调。这也是 LoRA-GA 的假设之一,因为它的改进方向就是向全量微调对齐。使用 LoRA 的另一个场景是有大量的微型定制化需求,我们要存下非常多的微调结果,此时使用 LoRA 能减少储存成本。对齐全量
LoRA-GA 提出了一个非常深刻的优化点:通过 我们可以保证 W 的初始值等于 ,即初始状态的 LoRA 与全量微调是等价的,那么我们是否还可以调整 和 ,使得 LoRA 和全量微调在后续训练中也尽可能近似?比如最简单地,让经过第一步优化后的 尽可能相等?越仔细回味,我们会越发现这个优化点是如此“直击本质”——LoRA 的目标不就是“以小搏大”,希望能接近全量微调的效果吗?既然如此,尽可能对齐全量微调的后续更新结果,不就是最正确的改进方向?从逼近的角度来看,“W的初始值等于 ”相当于全量微调的零阶近似,保持后面的 接近,则相当于是更高阶的近似,是合情合理的选择,所以笔者看完摘要后就有种“就是它了”的强烈感觉。具体来说,假设我们的优化器是 SGD,那么对于全量微调,我们有: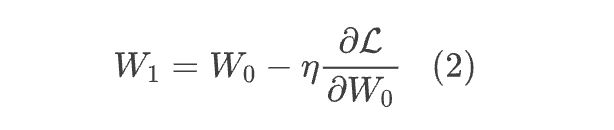
其中 是损失函数, 是学习率。如果是 LoRA 的话,那么有:最后的近似省略了 的二阶项。现在两个 具有相似的形式,为了让它们尽可能近似,我们可以考虑最小化:其中 是矩阵的 Frobenius 范数平方,即矩阵每个元素的平方和。
求解过程
注意 的秩顶多为 r,它们相加后的秩顶多为 2r,我们假设 ,所以上述目标相当于寻找 的一个秩不超过 2r 的最优近似。我们先考虑 是非负对角阵的情形,并且对角线元素已经按照从大到小的顺序排列。这个例子很简单,它的秩不超过 2r 的最优近似就是只保留对角线前2r个元素的新对角矩阵,这个结论叫做“Eckart-Young 定理”[6],而能让 只保留 的前 2r 个对角线元素的 可以是(分块矩阵):其中 分别是 n,m 阶单位阵, 和 就是像 Python 切片那样,取前r列和第 行。注意我们说的是“可以是”,也就是说解并不唯一,说白了就是要把 的前 2r 个对角线元素挑出来, 和 各挑一半,至于怎么分配就无所谓了。上面给出的解,对应的是 挑出前r个, 挑出第 个。当 不是对角阵时,我们将它 SVD 为 ,其中 为正交矩阵, 为对角矩阵,对角线元素非负且从大到小排列。代入式(5)后得到:前两个等号都是简单的代换,第三个等号是因为正交变换不改变Frobenius范数(请读者自行证明一下)。经过这样的转换,我们发现逼近的对象重新转变为对角阵 ,自变量则变成了 ,那么按照 是对角矩阵时所给出的解,我们得到LoRA-GA 选取一批样本,计算初始梯度 ,对梯度SVD为 ,取U的前r列初始化A,取V的第 行初始化B。这样 LoRA + SGD 得到的 就跟全量微调的 尽可能相近了。此外,梯度最重要的是方向,其模长不大重要,所以初始化结果我们还可以乘以个 scale,LoRA 本身也可以乘以个 scale,即 ,这些都是LoRA 常见的超参数,这里就不展开讨论了。顺便提一下,形式上跟LoRA-GA比较相似的是 PiSSA [4],它是对 做 SVD 来初始化 A,B,这在理论支持上就不如 LoRA-GA 了,是一个纯粹的经验选择。当然,可能有读者会发现目前的推导都是基于 SGD 优化器的假设,那么对于我们更常用的 Adam 优化器,结论是否要做出改变呢?理论上是要的。我们在《配置不同的学习率,LoRA还能再涨一点?》讨论过,对于 Adam 来说,第一步优化结果是 而不是 ,这样重复前面的推导,我们可以得到优化目标为:由于符号函数 的存在,我们没法求出它的解析解,所以针对 Adam 的理论分析就只能止步于此了。在这个背景下,对于 Adam 优化器,我们有三个选择:1. 信仰:直接引用 SGD 的结果,相信它也可以在 Adam 中发挥同样的效果;2. 硬刚:用优化器直接去最小化目标(9),由于目标比较简单,计算量尚能接受;3. 投机:直觉上将 换成 ,然后代入 SGD 的结论,可能更贴合 Adam。看起来原论文选择的是第 1 个方案,论文的实验结果确实也支持这一选择。
论文的实验结果还是比较惊艳的,尤其是在 GLUE 上取得了最接近全量微调的效果:
▲ LoRA-GA + T5-Base在GLUE上的表现平均来说,训练数据量越少,相对提升的幅度越大,这表明 LoRA-GA 对齐全量微调的策略,不仅有助于提高最终效果,还能提高训练效率,即可以用更少的训练步数就能达到更优的效果。在 LLAMA2-7b 上的表现也可圈可点:
▲ LoRA-GA + LLAMA2-7b在几个Benchmark的表现
注意使用 LoRA 的主要场景是显存不足,但 LoRA 的初始化需要求出所有训练参数的完整梯度,这可能会由于显存不足而无法实现。为此,原论文提出的技巧是我们可以一个个参数串行地求梯度,而不是同时求所有训练参数的梯度,这样就可以把单步计算的显存降下来。串行求梯度虽然会降低效率,但初始化本身是一次性工作,因此稍慢点也无妨。至于怎么实现这个操作,不同框架有不同方法,这里也不展开讨论了。
文章小结
本文介绍了 LoRA 的一个新改进 LoRA-GA。虽然 LoRA 的各种变体并不鲜见,但 LoRA-GA 以非常直观的理论指导折服了笔者,其改进思路给人一种“确认过眼神,它就是对的论文”的感觉,再配上可圈可点的实验结果,整个过程如行云流水,让人赏心悦目。

































 粤ICP备17114055号
粤ICP备17114055号