近年来,随着预训练语言模型(PLM)在自然语言处理(NLP)领域的广泛应用,如何在不改变大型语言模型结构和参数的情况下,适配各种下游任务成为了研究的热点。本文将介绍三种主流的参数高效微调(PEFT)技术方案:Prompt Tuning、Prefix Tuning 和 P-Tuning,这些方案都围绕 Token 做文章,并且在保持预训练语言模型(PLM)不变的情况下,实现了模型在不同任务上的适配,并结合快递运输等例子进行比喻说明。一、Prompt Tuning 小模型适配下游任务
1、基本概念
Prompt Tuning 是通过在输入序列前添加额外的 Token 来适配下游任务的方法。这些额外的 Token 是可训练的,而预训练语言模型的参数保持不变。
2、 例子讲解
例1:想象你是一家通用快递公司的快递员,你能够处理各种包裹。然而,现在你有一些特殊的包裹需要额外处理,比如易碎品。在 Prompt Tuning 中,相当于你在每个易碎品包裹前面加上一个特别的标签,比如“易碎”,以提醒你在处理这些包裹时要更加小心。例如,原始包裹信息是:“Package contains glassware”(包裹内含玻璃制品)。在 Prompt Tuning 中,你会在包裹信息前加上“易碎”标签,让信息变成:“Fragile: Package contains glassware”。这些“Fragile”标签是可训练的,通过训练这些标签,你可以更好地处理易碎品。例2:假设你有一个已经训练好的模型,能够回答通用问题。现在你希望它能够更好地回答旅游相关的问题。原始输入句子是:“What is the best place to visit in summer?”(夏天最好的旅游地点是哪里?)。在 Prompt Tuning 中,你会在输入句子前添加一些额外的 Token,比如 [TRAVEL],让输入变成:[TRAVEL] What is the best place to visit in summer? 这些 [TRAVEL] Token 是可训练的,通过训练这些 Token,你可以让模型更好地理解这是一个关于旅游的问题。3、 数学表示
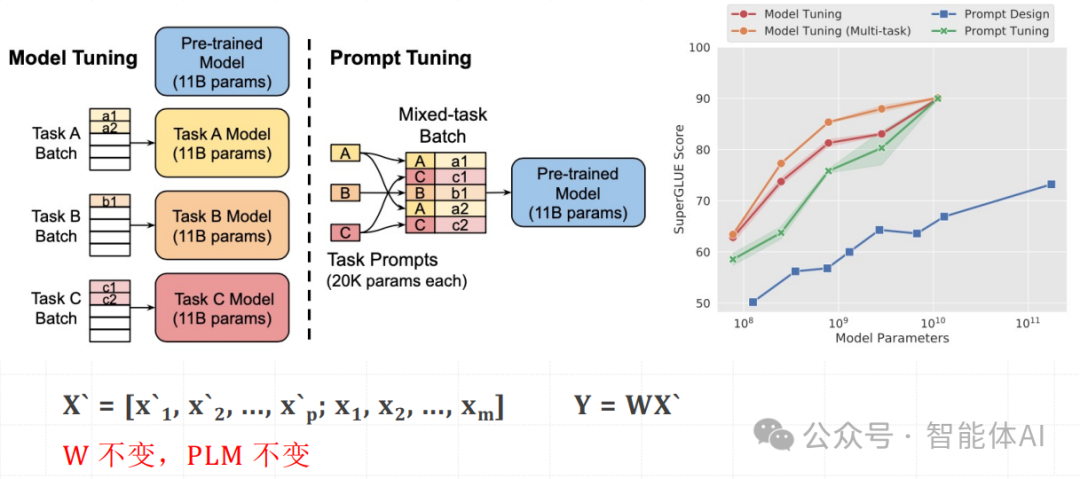
假设原始输入序列为 X=[x1,x2,...,xm],在其前面添加 p 个 Prompt Token,形成新的输入序列 X`。
X′=[x1′,x2′,...,xp′;x1,x2,...,xm]
Y=WX′
在这个过程中,W 不变,仅通过训练前面的 Prompt Token 来适配下游任务。
4、应用场景
Prompt Tuning 特别适用于任务复杂度较低或数据量较少的下游任务例如:
二、Prefix Tuning 在 Transformer 中适配下游任务
1、基本概念
Prefix Tuning 是在每层 Transformer 结构的输入前添加一组可训练的 Token。这样,模型在处理输入序列时,每一层的输入都会包含这些额外的 Token,从而适配下游任务。2、例子讲解
例1:想象你是一家快递公司的管理员,你的任务是优化每个配送员的路线。现在,你需要处理一些重要包裹,确保它们能够优先配送。在 Prefix Tuning 中,相当于你在每个重要包裹的配送路线上添加一些额外的标记,比如“优先配送”,以确保配送员知道这些包裹需要优先处理。例如,原始配送路线信息是:“Deliver package to address A, then address B”(先送包裹到地址A,然后送到地址B)。在 Prefix Tuning 中,你会在每层配送路线上加上“优先配送”标签,让信息变成:“Priority: Deliver package to address A, then address B”。这些“Priority”标签是可训练的,通过训练这些标签,你可以更好地优化重要包裹的配送路线。例2:假设你有一个模型,可以翻译通用的句子。现在你希望它能够更好地翻译医学领域的句子。原始输入句子是:“The patient needs immediate attention.”(病人需要立即关注。)在 Prefix Tuning 中,你会在每层 Transformer 的输入前添加一些 Token,比如 [MEDICAL],让输入变成:[MEDICAL] The patient needs immediate attention. 这些 [MEDICAL] Token 是可训练的,通过训练这些 Token,你可以让模型更好地理解这是一个关于医学的句子。3、数学表示
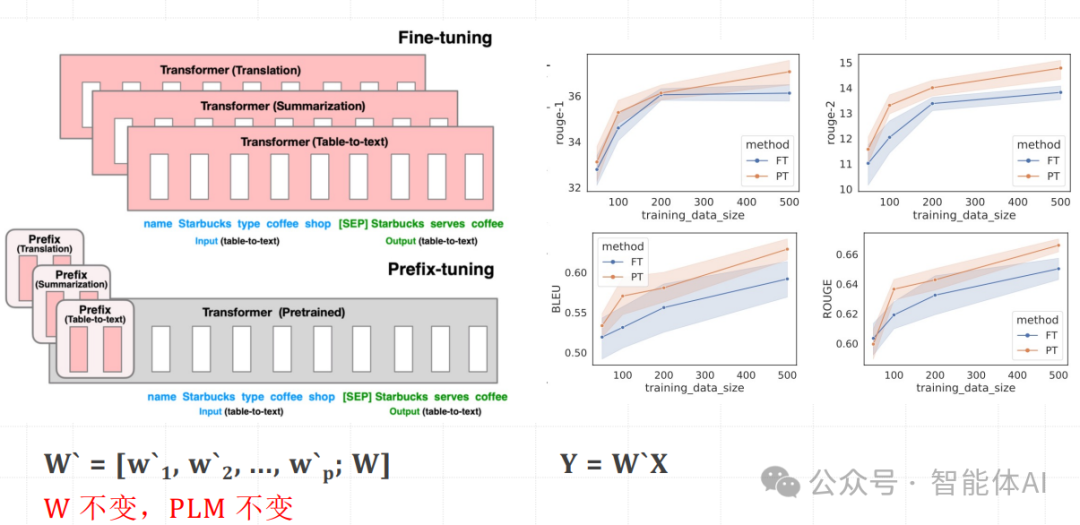
假设 Transformer 的原始权重矩阵为 W,我们在其前面添加 p 个可训练的 Token,形成新的权重矩阵 W`。在输入序列 X 上应用新的权重矩阵 W。
W′=[w1′,w2′,...,wp′;W]
Y=W′X
这样,每一层 Transformer 的输入都会包含这些可训练的 Token。
4、 应用场景
Prefix Tuning 特别适用于需要捕捉复杂上下文信息的任务,例如:
三、P-Tuning
1、基本概念
P-Tuning 是 Prompt Tuning 的一种变体,其核心思想是在特定位置插入可训练的 Token,使模型能够更好地理解下游任务的需求。P-Tuning 方法通过在输入序列中间插入额外的 Prompt Token,使模型在处理输入时能更好地捕捉上下文信息。2、例子讲解
例1:想象你是一名快递员,你的任务是将包裹准确无误地送达目的地。现在,你需要处理一些特殊包裹,这些包裹需要在中途添加一些额外的处理步骤。在 P-Tuning 中,相当于你在配送过程中间的某个环节插入一些额外的处理步骤,比如“重新包装”或“安全检查”,以确保这些包裹能够安全送达。例如,原始包裹信息是:“Deliver package to address A”(将包裹送到地址A)。在 P-Tuning 中,你会在中途插入一些额外的处理步骤,让信息变成:“Deliver package to address A, stop for security check, then continue to address A”。这些额外的处理步骤是可训练的,通过训练这些步骤,你可以更好地处理特殊包裹。例2:假设你有一个已经训练好的模型,可以生成文章。现在你希望它能够生成关于科技的文章。原始输入句子是:“Artificial intelligence is transforming the world.”(人工智能正在改变世界。)在 P-Tuning 中,你会在输入序列中间插入一些 Token,比如 [TECH],让输入变成:“Artificial intelligence [TECH] is transforming the world.” 这些 [TECH] Token 是可训练的,通过训练这些 Token,你可以让模型更好地理解这是一个关于科技的文章。3、数学表示
假设输入序列为 X=[x1,x2,...,xm],在特定位置插入 p 个 Prompt Token,形成新的输入序列 X`。
X′=[x1,...,xi,x1′,x2′,...,xp′,xi+1,...,xm]
Y=WX′
通过在输入序列的关键位置插入可训练的 Token,使得模型能够更有效地捕捉任务相关信息。
4、 应用场景
P-Tuning 适用于各种下游任务,特别是那些需要在输入序列中捕捉特定位置信息的任务,例如:
四、总结
通过上述三种参数高效微调(PEFT)技术方案——Prompt Tuning、Prefix Tuning 和 P-Tuning,研究者们能够在不改变预训练语言模型(PLM)参数的前提下,实现模型在不同下游任务上的高效适配。这些方法不仅降低了计算成本和存储需求,还提高了模型在各种任务上的表现。希望这些快递运输的比喻和其他例子能帮助你更好地理解这些技术原理。随着技术的不断发展,相信会有更多创新的方案涌现,为自然语言处理领域带来新的突破。

































 粤ICP备17114055号
粤ICP备17114055号