导读 本次分享的主题是大语言模型训练中的数据管理。1. 大语言模型训练中的数据管理概述
2. 预训练阶段的数据管理
3. SFT 阶段的数据管理
4. 挑战及未来方向
分享嘉宾|王紫格 北京大学/华为 博士研究生/实习生
编辑整理|郝浩
内容校对|李瑶
出品社区|DataFun
大语言模型训练中的数据管理概述

数据对于大语言模型训练至关重要,无论是在预训练阶段,还是在有监督微调(SFT)阶段,数据都是关键因素之一。
不同的大语言模型在构建训练数据集时会采取不同的策略,其背后的原因和影响是什么?实践中应该如何去选择?越来越多的研究者关注到这些困惑,并进行了相关研究。我们的工作就是总结和梳理目前已有的这些研究成果,在大语言模型训练中提供一些实践上的参考和指导。
我们这里定义的数据管理是指使用收集到的数据组织一个合适训练数据集的过程,包括数据的选择、组合、使用策略,以及各种策略的评测方式。具体涉及两个阶段:一个是预训练阶段,一个是 SFT 阶段,每个阶段根据数据集构建的特点会包括不同的方面。下面将分别展开介绍。
预训练阶段的数据管理
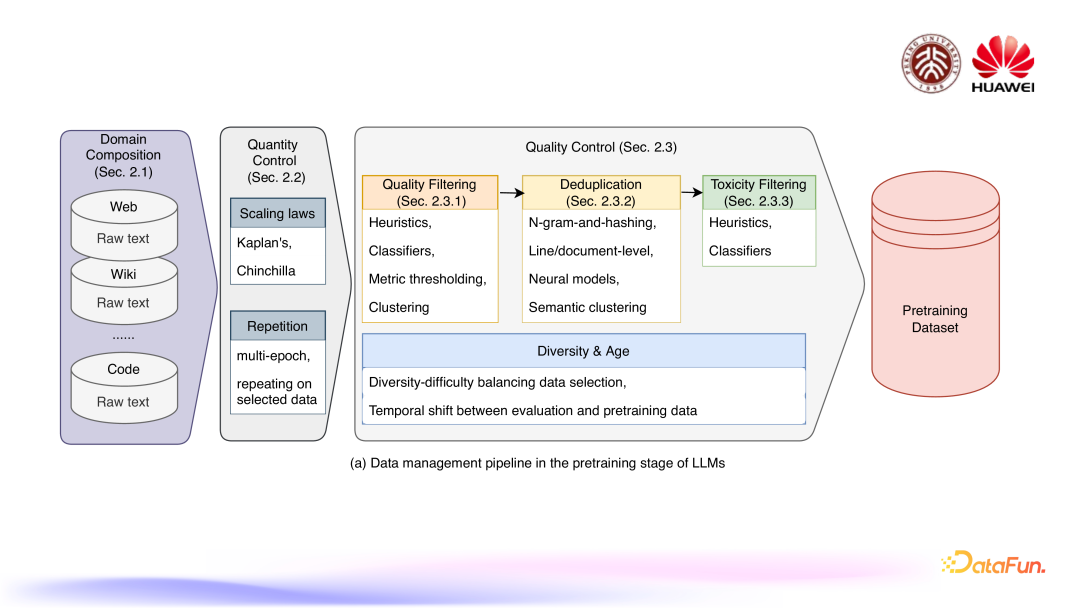
预训练阶段的整体流程如上图所示,主要包括三个部分:首先是领域组成,预训练数据集具体包含网页、wiki 知识库和代码等不同领域;第二个部分是数据数量方面的控制,包括尺度定律(Scaling laws)和数据重复;第三个部分是数据质量方面的控制,数据质量通常的处理是形成一个流程链,包括质量过滤、数据去重、有害信息过滤,同时也涉及一些数据多样性和数据年龄这样的问题。最终可以组成一个预训练数据集。
1. 领域组成
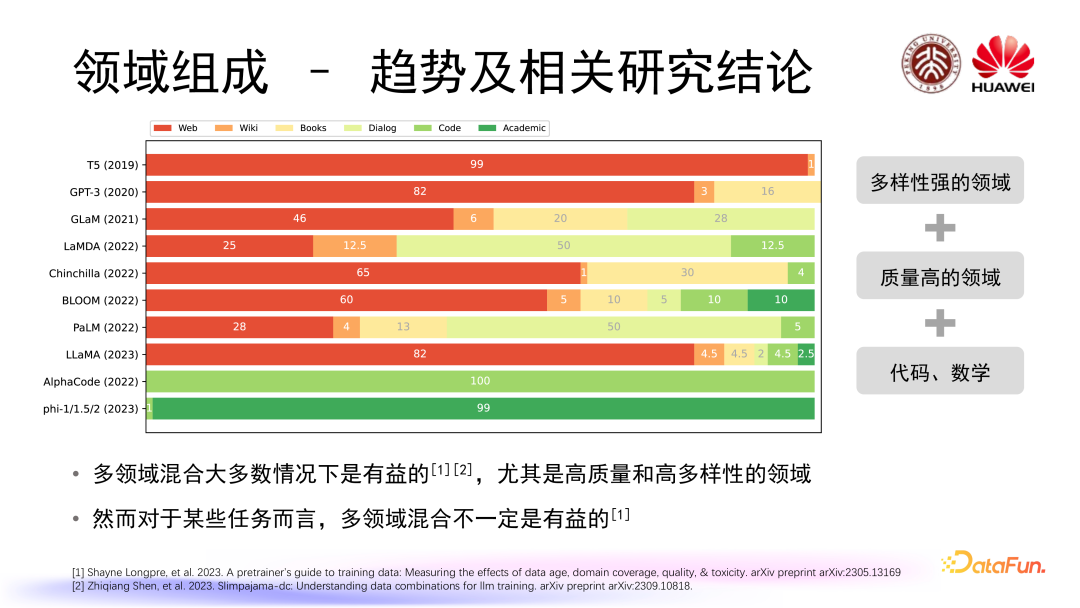
首先我们来看领域组成的趋势及相关研究结论。上图中总结了从 2019 年到 2023 年间比较知名的大语言模型在预训练阶段所采用数据的领域组成,当然有一些非常先进的大语言模型并没有开源和公布出他们的预训练数据集领域组成,我们只列了我们能够找到的已知的一些模型。
可以看到在早期的时候大家普遍采用的是多样性比较强的领域数据,比如 Web 网页数据。后面逐渐开始引入一些质量比较高的领域数据,比如 Wiki 百科、Books 数据。随着我们对大语言模型综合能力发展变化要求的提升,逐步加入了类似 Dialog 对话、Code 代码、Academic、数学等特殊领域的数据。我们知道多领域混合在大多数情况下是有益的,尤其是包含高质量和高多样性的领域数据,但是也有研究表明对于某一些任务而言多领域混合也不一定是有益的。
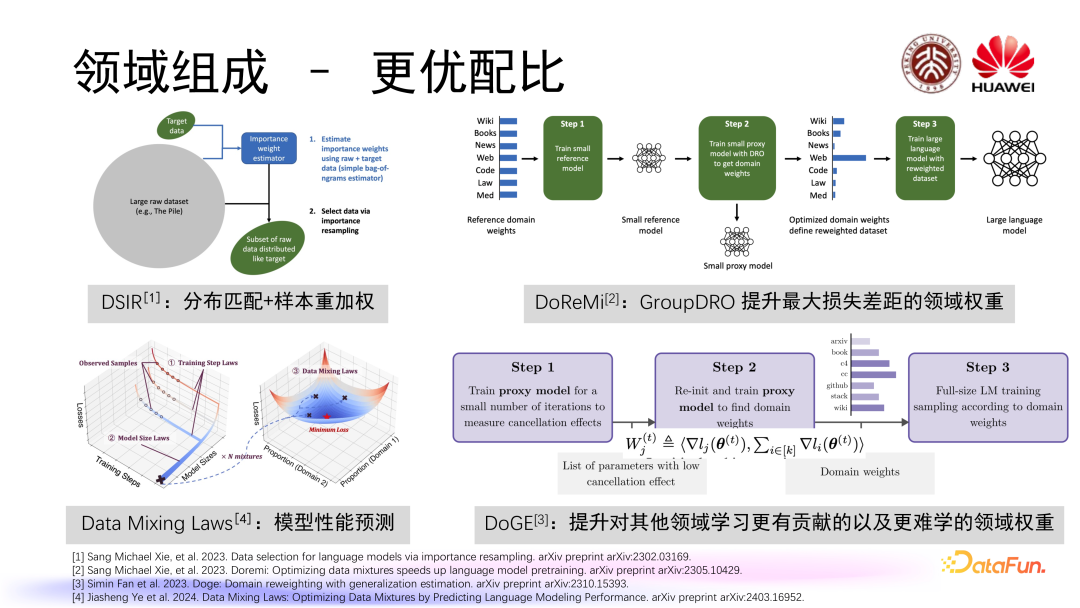
我们自然而然会关心到的一个问题是如何找到一个更优的领域配比。目前有一些工作在这一方面进行了探索,比如 DSIR 采用了一种样本重加权方式使构建出的预训练数据集和我们想要的目标数据集的分布更加一致;DoReMi 借鉴了 GroupDRO 的优化策略来提升有着最大损失差距的领域权重;相对而言 DoGE 更看重的是提升对其他领域学习更有贡献的以及更难学的领域权重,通过梯度方式计算出一个贡献量,进而增加相应领域权重;近期提出的 Data Mixing Laws 则通过拟合领域配比和模型性能的关系,对模型的性能做出一定程度上的预测。
2. 数据数量
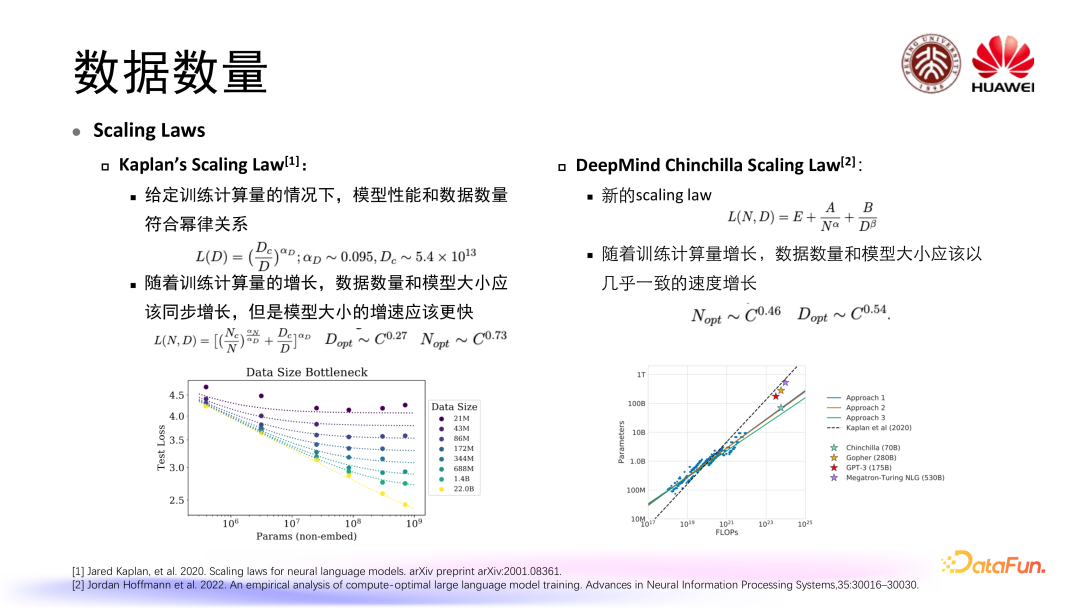
对大语言模型预训练来讲,大规模的数据是非常重要的。早期有研究者关注到数据数量和模型性能之间的关系,比较有名的就是上图中的两条 scaling laws。
第一条是 Kaplan 等人最先提出来的 Scaling Law,在给定一定量训练计算量的情况下,他们发现模型的性能和数据数量符合一定程度上的幂率关系,通过去拟合这个幂率的参数发现,随着训练计算量的增长,数据的数量和模型的大小也应该是一个同步增长的关系,但是模型大小的增速应该要更快一些。
第二条在 Kaplan’s Scaling Law 的基础上,DeepMind 通过对 Chinchilla 模型的研究也提出了一条新的 scaling
law,并且得出了一些和 Kaplan’s Scaling Law 不一样的结论,他们认为随着训练计算量增长,数据数量和模型大小应该以几乎一致的速度去增长,同时更加重了数据数量对于模型性能提升的影响。
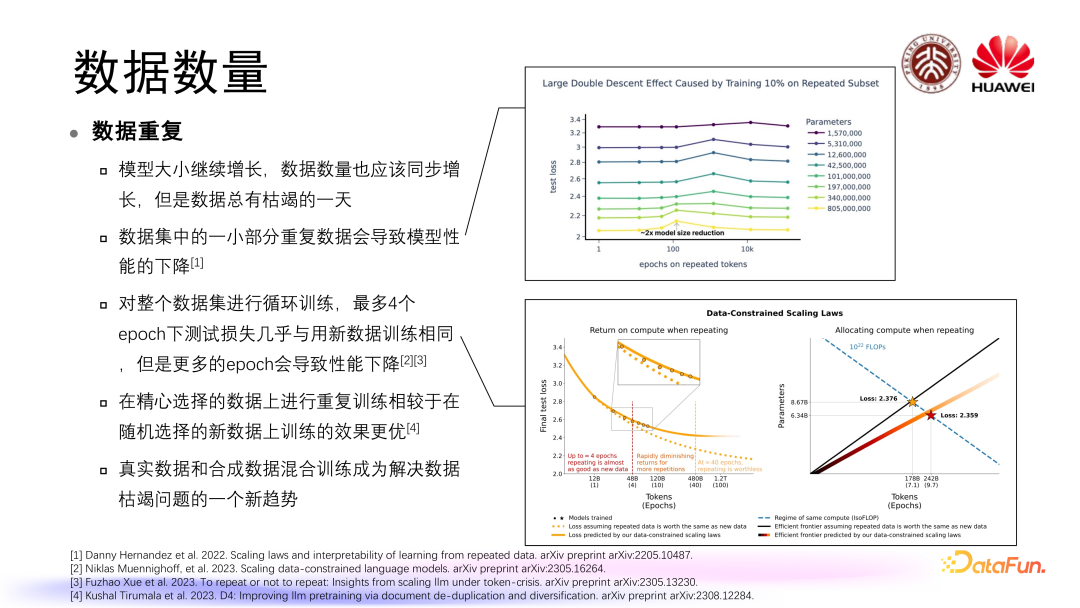
我们都知道随着大语言模型对数据的需求规模越来越大,会碰到一个数据枯竭的问题,尤其在一些领域中数据是有限的,为了解决数据枯竭和数据有限的问题,大家很自然就想到是不是可以对数据进行一些重复性训练。
在数据重复问题的相关研究中,较早的时候,研究者首先关注到的是如果数据集当中存在一小部分重复数据,那么模型性能会出现怎样的变化,通过这样的工作发现数据集当中一小部分重复数据可能会导致模型性能出现一定程度下降,这样的结论其实是偏向于数据重复对于大语言模型的预训练来讲是有负面效应的。
但是之后也有相关工作针对整个数据集的循环训练进行研究,发现如果最多循环 4 个 epoch 的话,训练损失几乎是和用新数据训练相同的,也就是说当训练循环 epoch≤4 的时候,数据重复是可以接受的,但是出现更多的 epoch 会使原有的 scaling law 出现一定程度变形,导致模型性能出现一定程度的下降。
与此同时也有一个工作发现,对数据进行一定程度上精心地选择,然后对这部分精心选择的数据进行重复训练,也可以对模型的性能达到一定程度的维持或者说更优的提升。为了解决数据枯竭的问题,除了数据重复,还出现了合成数据,真实数据和合成数据的混合训练也成了另一新趋势。
3. 数据质量
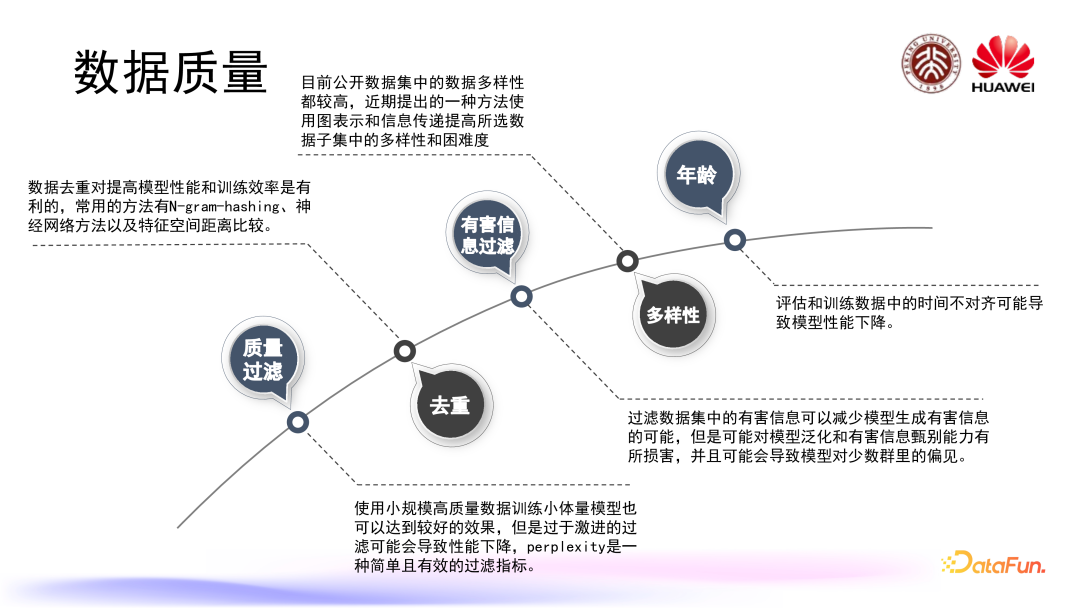
数据质量又可细分为质量过滤、去重、有害信息过滤、数据的多样性以及年龄等方面。
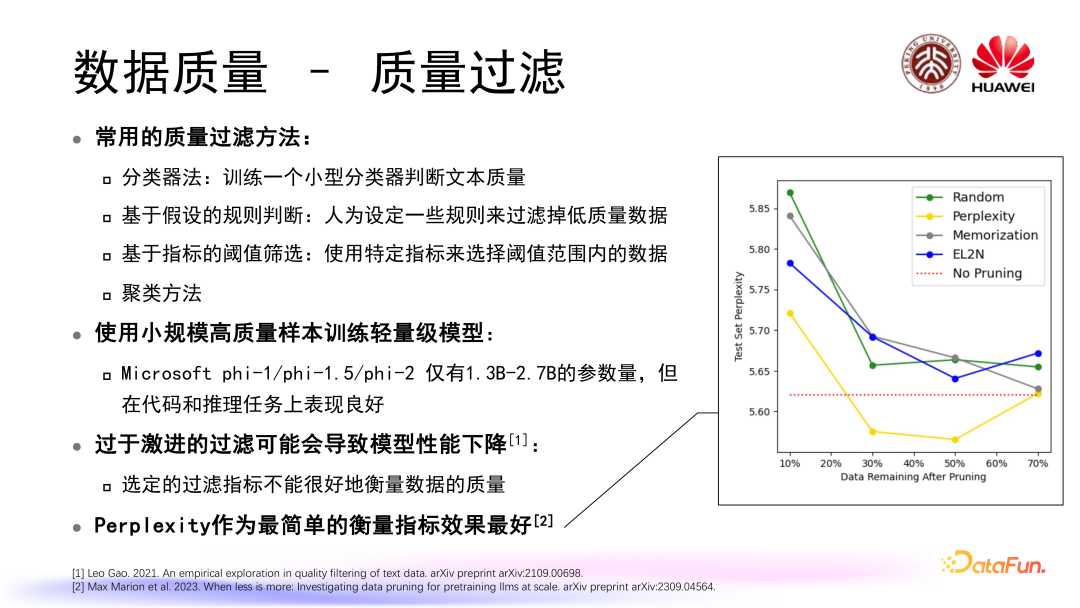
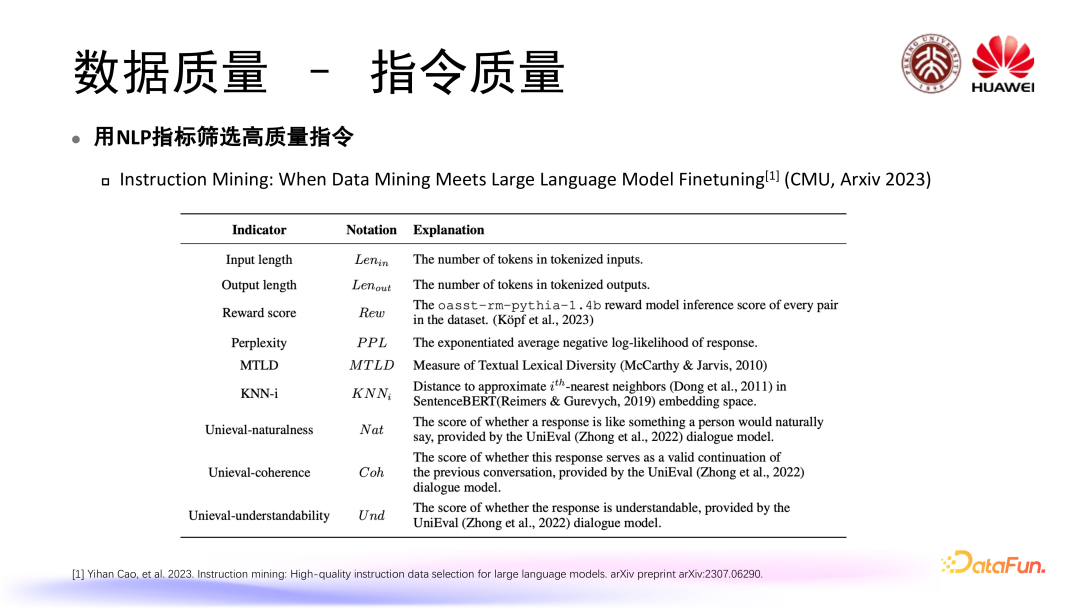
数据质量过滤是数据质量控制过程中的第一步,常用方法如下:
使用小规模高质量样本训练轻量级模型,在一些任务当中取得了比较优的表现例如:Microsoft phi-1/phi-1.5/phi-2 仅有 1.3B-2.7B 的参数量,但在代码和推理任务上表现良好。
过滤程度问题也是大家所关注的一个点,有工作发现过于激进的过滤可能会导致模型性能下降,并且将原因归结于选定的过滤指标不能很好地衡量数据的质量。
有工作去研究到底怎样衡量数据质量指标是更好的,在这个工作当中选用了三个我们比较常用的衡量指标,比如 Memorization(记忆)、EL2N、Perplexity,实验结论发现 Perplexity 作为最简单的衡量指标效果最好。
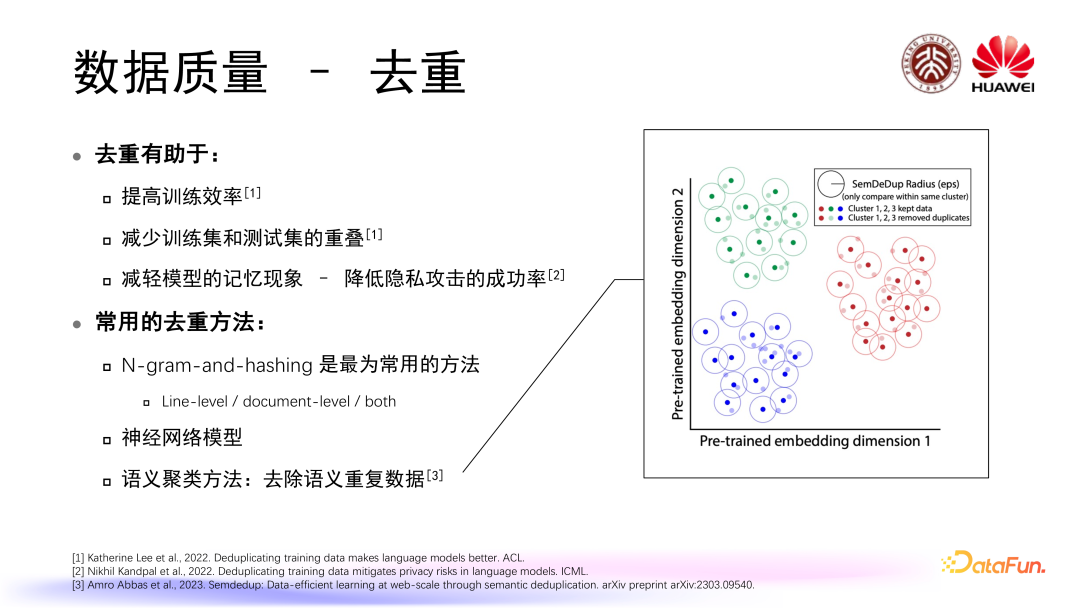
提高训练效率
减少训练集和测试集的重叠
减轻模型的记忆现象 – 降低隐私攻击的成功率
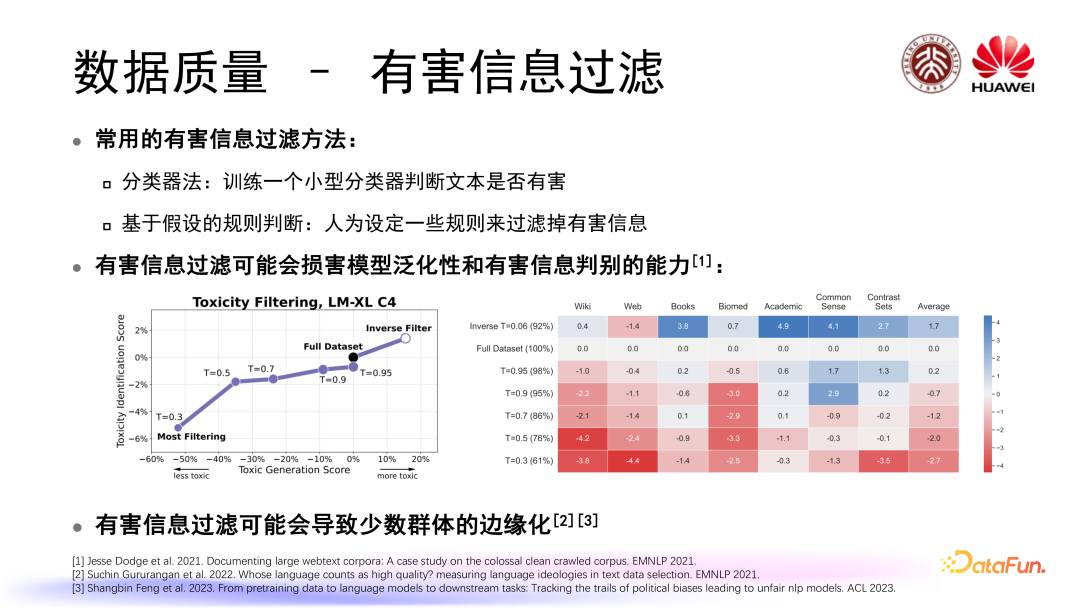
我们都知道模型数据集当中可能存在一些涉及隐私或者涉及偏见的有害信息,所以我们在组织训练数据的时候,应该对有害信息进行一定程度上的过滤。常用的有害信息过滤的方法和质量过滤存在一定的相似性,包括:
有害信息过滤可能会损害模型泛化性和有害信息判别的能力,还可能会导致少数群体的边缘化,进而引发社会偏见。

还有研究工作关心到了数据质量的多样性,衡量多样性指标如下:
用这一指标进行衡量可以得知目前公开的预训练数据集的数据多样性都相对较高。近期也有一些工作针对数据多样性进行预训练数据选择,比如 D2 pruning 用无向图表示数据集,采用 message passing 策略兼顾多样性和困难度。
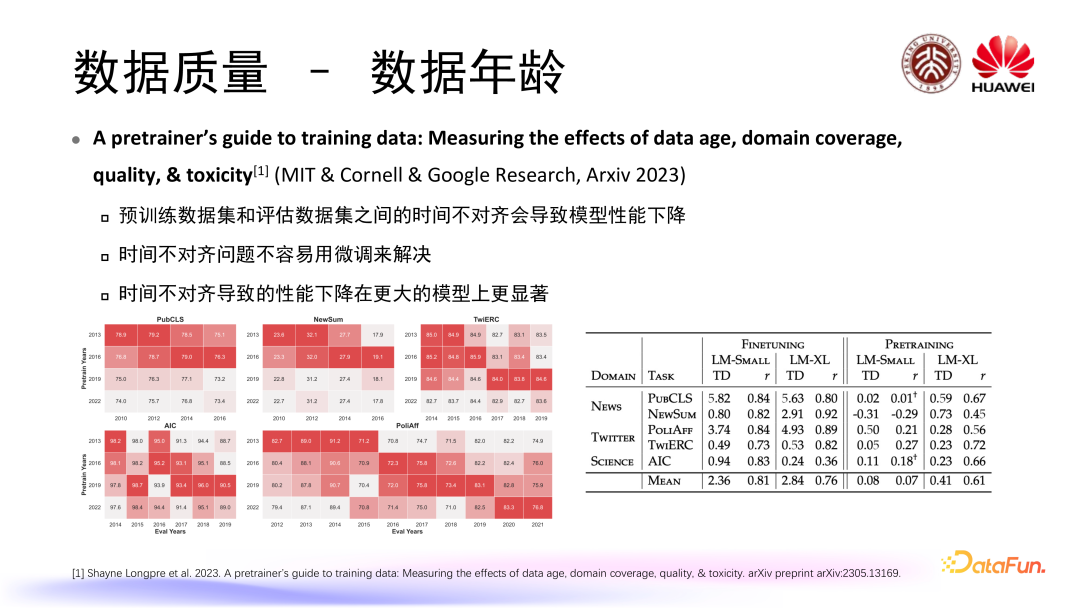
Longpre 等人的一篇工作通过研究数据年龄问题,发现以下结论:
4. 预训练阶段小结
多领域混合和合适的领域配比是十分重要的,但如何寻找合适的领域配比仍有发展空间。
大批量数据仍然是 LLM 预训练的关键,恰当的数据重复可能对于模型训练是有益的。
数据质量控制通常包括质量筛选、去重和有害信息筛选三个步骤,但是过度筛选可能导致性能下降和一定的社会偏差。
数据多样性、数据年龄对模型性能也有一定的影响,数据的其他性质有待进一步探索。
SFT 阶段的数据管理
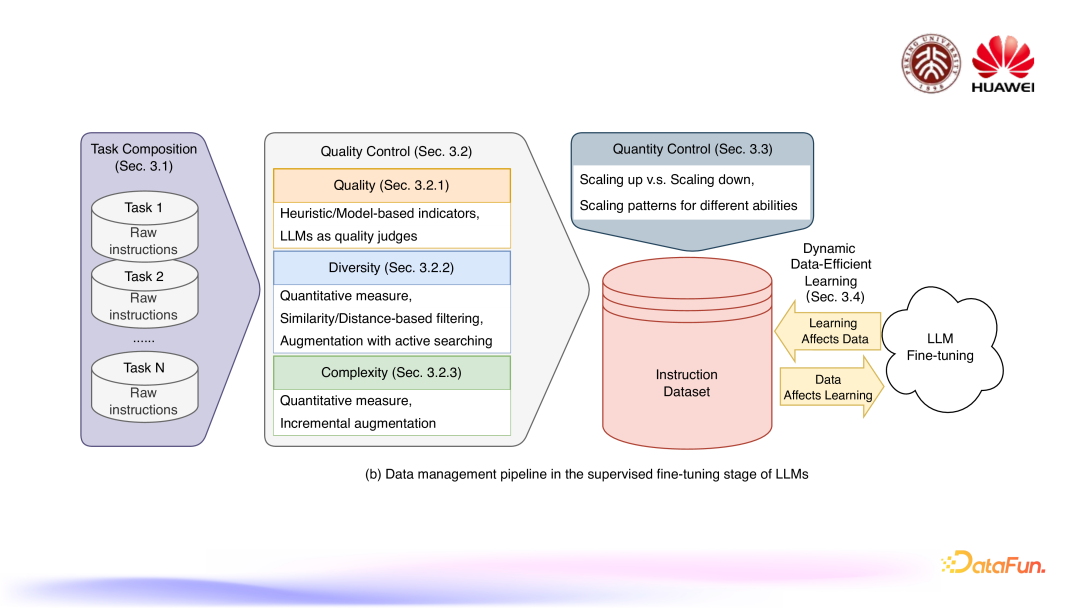
SFT 阶段的流程如上图,首先是任务组成,在对大语言模型进行 SFT 的时候,我们通常希望模型能够拥有处理多种任务的能力,所以我们会对它进行多任务的微调。质量控制是 SFT 数据管理的重中之重,这个质量包括指令指令质量,指令多样性以及指令复杂度。另外,对于数据集的数量也存在着一定的控制,也就是需要多少 SFT 数据能够让模型的微调效果达到比较好的程度。最后我们构建这个指令数据集的时候也会和大语言模型的微调训练的过程进行一定程度的结合,催生出一些动态数据高效学习的研究。
1. 任务组成
首先来看任务组成,对于大语言模型 SFT 微调的影响,刚才提到我们在大多数情况下采取的都是多任务微调这样的设定。
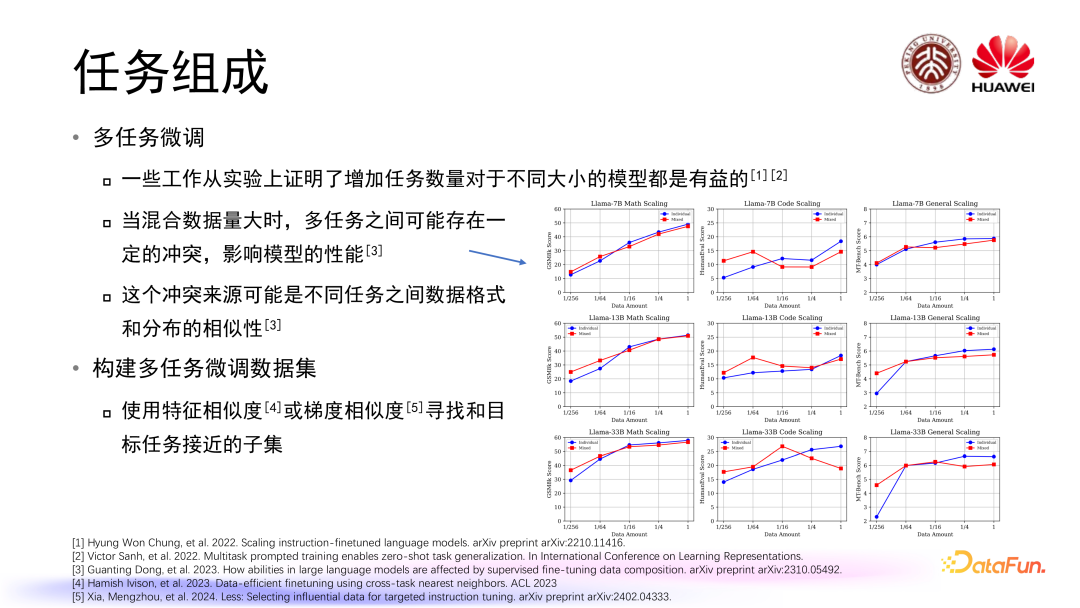
一些工作从实验上证明增加任务数量对于不同大小的模型都是有益的。当混合数据量大时,多任务之间可能存在一定的冲突影响模型的性能,比如模型在学习通用能力,代码能力,数学能力相关数据的时候会存在一定程度上的冲突现象。这个冲突来源可能是不同任务之间数据格式和分布的相似性,不同任务之间的数据格式和分布越接近越相似,他们之间产生冲突的可能性越大。构建多任务微调数据集也存在任务的配比和任务选择的一个问题。目前有相关研究使用了特征相似度或梯度相似度寻找和目标任务接近的子集。
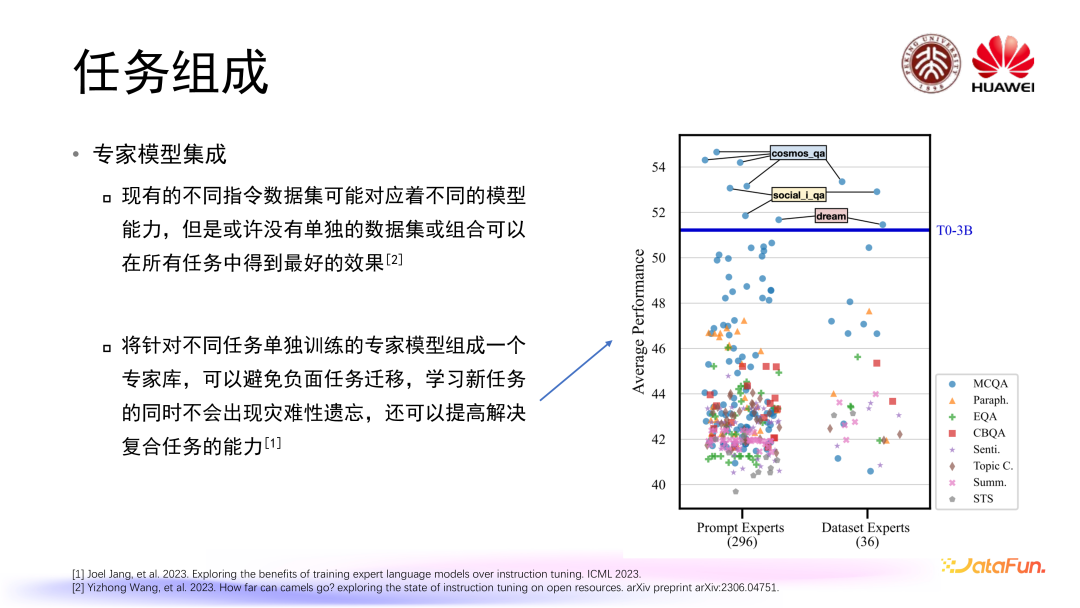
除了多任务微调这样的设定,有研究表明现有不同的指令数据集可能对应着不同的模型能力,并且可能没有单独的数据集或组合可以在所有任务中得到最好的效果。因此,有工作提出将针对不同任务单独训练的专家模型组成一个专家库,并认为这样可以避免负面任务迁移,在学习新任务的同时不会出现灾难性遗忘,也可以提高解决复合任务的能力,这也为我们使用大语言模型去解决多任务提供了一个新思路。
2. 数据质量

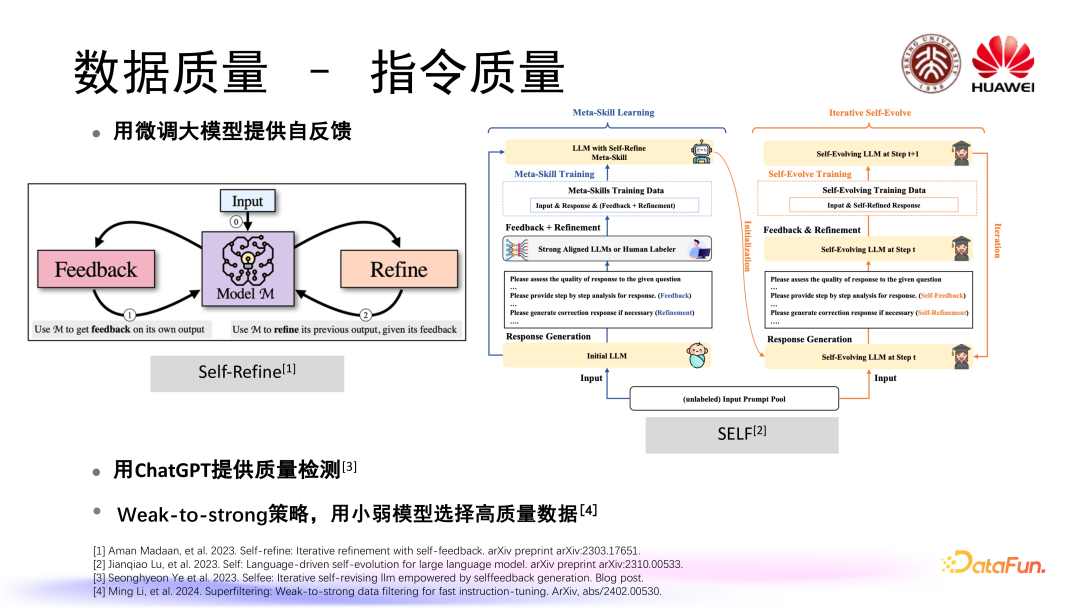
随着对大模型研究的深入,大模型本身可以为我们筛选高质量的数据提供一定参考。比如说有些工作会使用微调后的大模型提供自反馈,也就是让大模型自己对自己生成的指令和回答去进行一个反馈 feedback,通过迭代的方式不停的去优化自己所生成的指令以及指令的回答,同时我们也可以用现在已有的一些比如 ChatGPT 或者 GPT4 这样的强大语言模型来提供质量检测。近期有些工作提出了 Weak-to-strong 的策略,也就是用比较小比较弱的模型来选择高质量的数据以供这些大模型进行训练。

首先对于怎样去评估指令的多样性,#InsTag 提出了通过打标签的方式来评估指令多样性的方法,首先使用了 ChatGPT 对现有开源指令数据集去打标签,然后通过一系列的筛选、聚合等操作对标签进行整合,最后提出一个完整的标签集,基于这个标签集,他们提出多样性的定义是某一个数据集当中所包含的非重复标签占所有标签的比例。

在多样性筛选方面,如果想要筛选出一个多样性比较高的SFT微调数据集,我们可以从字义的层面去筛选,可以使用 Rouge-L 相似度,也可以从语义层面筛选,比如看数据的 embedding 在特征空间上的距离,筛选出特征空间上距离相对较远的一些数据。数据有限或者多样性有限的情况下,我们也可以采取一定的操作去丰富数据的多样性,比如可以从一个基础指令出发,通过指令空间上的 lookahead 去看这个指令能否进一步深化,或者可以从当前的指令出发去看它有没有其他更多的变种来去探索指令上的空间,丰富指令数据的多样性。
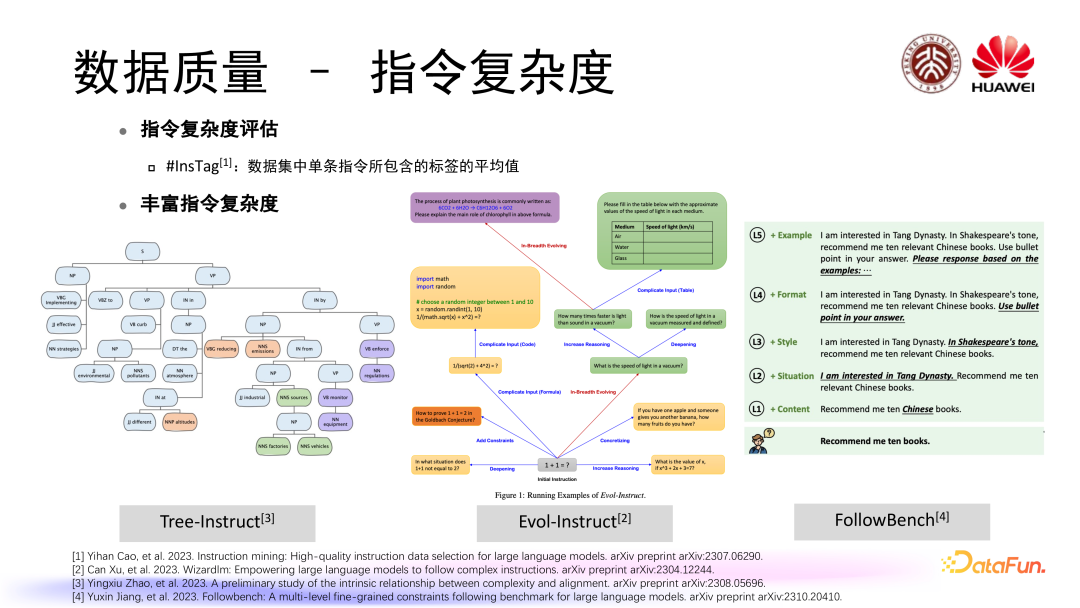
在指令复杂度上也涉及复杂度评估的问题,#InsTag 同样通过打标签这种方式给出了指令复杂度的定义,即指令数据集当中单条指令所包含的标签平均值,同样也有一些方法提出了我们怎样去基于现有的指令来丰富指令复杂度,比如 Tree-instruct 把指令转化成了一棵语义树,通过在语义树上增添节点的方式来达到可控指令复杂度丰富;Evol-instruct 采取了一些不同的操作,比如给这个指令增添图表等实现指令进化;FollowBench 通过对指令增加不同级别的限制条件来提升指令的复杂度。
3. 数据数量
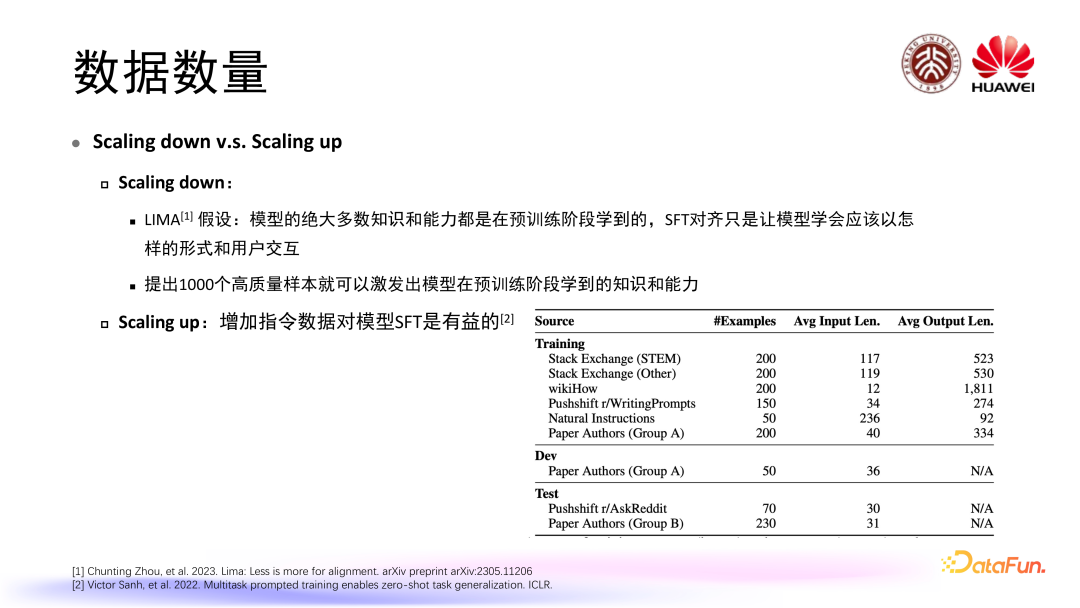
微调数据集数据量和预训练阶段存在一定不同,预训练阶段我们通常认为数据越多越好,比如说我们之前讨论 scaling law 是在更大规模模型上提升性能,我们需要更好更多的数据,但是 SFT 阶段通常所需的数据量并没有那么多。在这一问题上,相关研究出现两个分支:一个分支认为我们需要的数据量不在于多而在于精,比如 Lima 提出了一个假设认为模型绝大多数知识和能力都是在预训练阶段提到,而 SFT 对齐只是让模型学会应该以怎样的形式和用户进行交互,他们精心筛选出了 1000 个高质量、高多样性样本,通过实验,他们认为只要使用这 1000 个样本就可以激发出模型在预训练阶段学到这样的知识和能力。当然另外一个分支认为我们还是应该对指令数据集进行 scaling up,也就是增加指令数据对于模型的 SFT 是有益的。在这样两个分支的情况下,也有一些工作对于模型 SFT 所需要的数据数量进行了一些更加细化的分析。
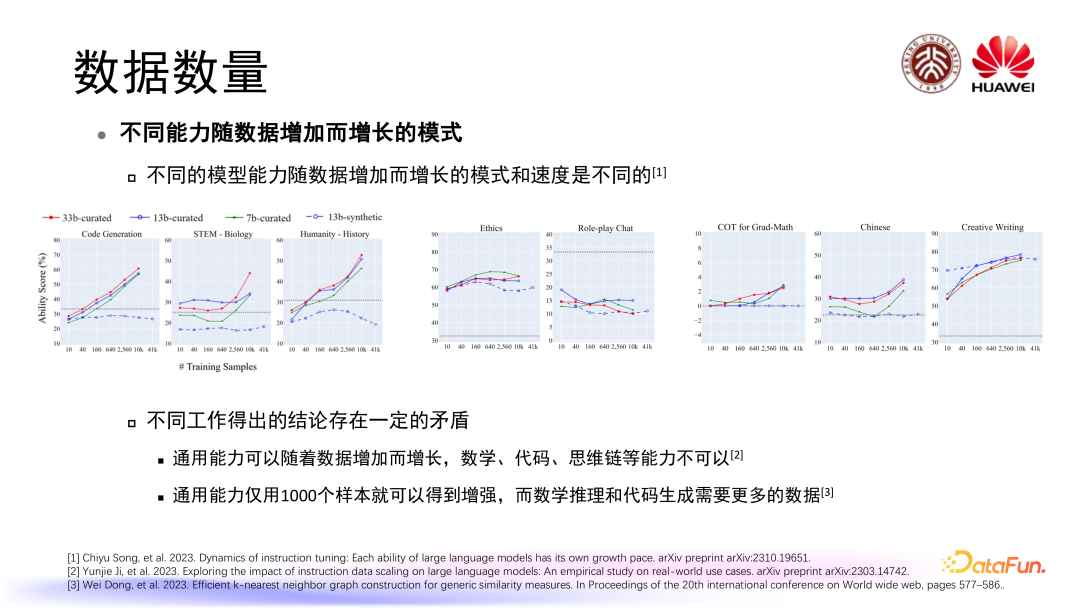
有工作研究了模型在学习不同任务或者不同能力时模型性能随数据增加而增长的模式,发现不同模型能力随着数据增加而增长的模式和速度是不同的,甚至可能出现一些非常不一样的情况。在这一问题上,目前的相关研究得出的结论存在一定程度的矛盾,比如有工作认为通用能力可以随着数据增加而增长,但数学代码、思维链这些复杂能力不可以。与此同时,一些工作认为在通用能力上模型仅仅使用 1000 个样本就可以得到增强,但在数学推理和代码生成这些复杂任务上面,模型需要更多数据进行学习。
4. 动态数据高效学习
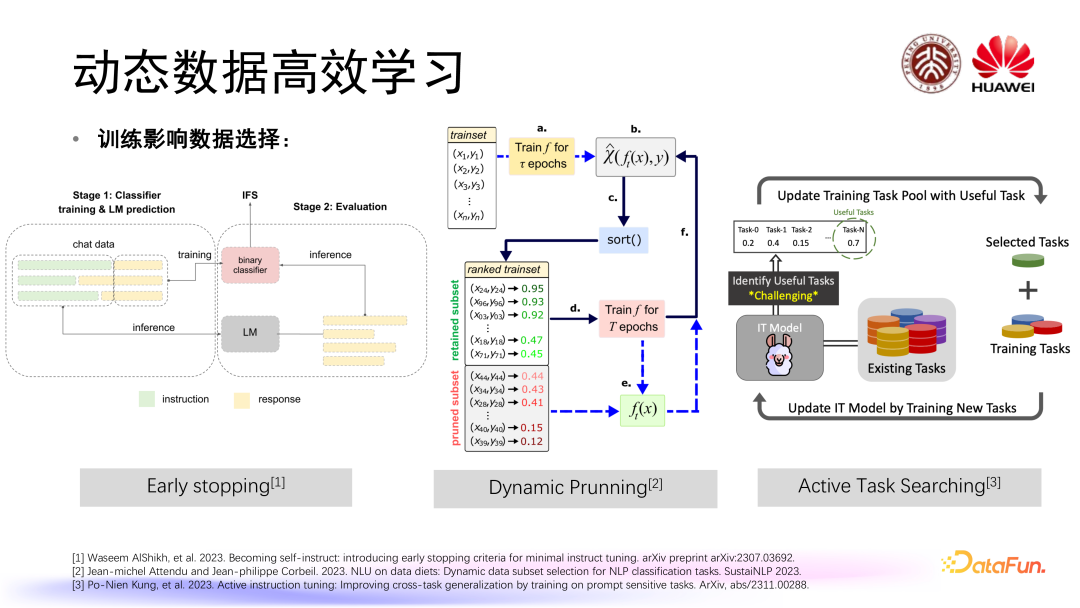
SFT 阶段还包括动态数据的高效学习。在SFT训练过程当中,模型对于数据的需求在不同阶段可能是不一样的,因此我们可以考虑动态地去调整和组织SFT微调数据。首先,训练可能会影响到数据选择,比如可以采取早停(Early stopping)这样的方式,也就是在模型训练过程当中在不同阶段去看模型的能力学习到了什么程度,如果达到预期,就可以进行早停,不需要过度学习。
除此之外可以进行动态剪枝,当模型的微调训练进行到一定的阶段,我们可以计算出判断数据重要性的分数,然后对这个分数进行排序,我们可以选择在当前阶段下模型最想要的一些数据,或者说我们可以去除掉当前阶段模型已经学习到我们认为它最不需要再继续学习的数据,从而提高训练效率,降低训练计算的成本。在任务上面我们也可以去进行一个主动的任务搜索,在模型训练的过程当中我们以任务为单位去判断模型究竟对于哪一些任务需要继续学习,哪一些任务可能已经不需要再继续学习,进而改变我们数据集当中的任务组成。
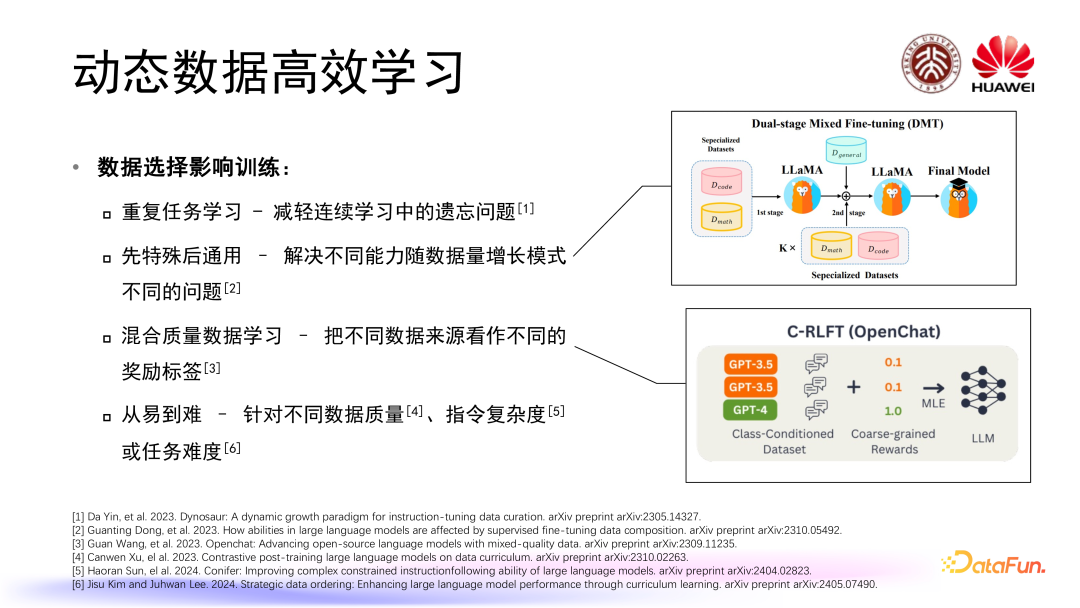
数据选择也会影响到大语言模型微调训练的策略,我们可以针对数据集的不同性质设计特殊的模型微调训练策略。为了减轻在连续学习当中出现遗忘问题可以进行重复任务学习,也就是在连续学习当中一定量地重复之前已经学过的任务。为了解决不同能力随着数据量增长模式不同的问题,我们可以采取一个先通用后特殊的学习流程设计。针对一些微调数据集,我们获取到的数据质量是混合的,在这个数据集当中可能有来自 GPT 4 生成的一些高质量数据,也有来自像 ChatGPT 或者一些其他的大语言模型生成的一些质量相对较低的数据,我们可以把这些不同数据来源看作不同的奖励标签通过有条件的 RLFT 方式对大语言模型进行训练。目前也有一些方法关注到从易到难的数据排布问题,比如说我们可以针对不同数据质量、不同数据指令复杂度或者不同任务难度去进行从易到难的学习。
5. SFT 阶段小结
多任务学习是普遍采用的一种训练方式,但不同任务之间可能存在冲突;与此同时,专家模型集成也是另一个发展方向。
质量控制通常使用基于规则的方法、人工评估或 LLM 评估完成,丰富指令多样性和复杂度的方法仍需进一步探索。
SFT 数据更看重质量而非数量,有研究表明不同模型能力所需数据量可能是不同的。
微调过程中指令数据集的动态调整也是提升模型性能的途径之一,特殊的微调策略也可能实现更高效的数据学习。
挑战及未来方向
能用于大多数通用任务的数据管理框架来减轻数据管理的开销。
训练数据集的去偏和去害、利用微调减轻大语言模型的社会偏见和有害输出等问题。
多模态指令数据集中的 scaling law、质量控制、任务均衡等问题。
大规模交互数据的学习需要有效的数据管理系统来构建合适的数据集。
5. 合成数据的高效筛选
6. 细粒度的数据流程设计
7. 冲突数据隔离

































 粤ICP备17114055号
粤ICP备17114055号