大型语言模型(LLMs)在推进人工通用智能(AGI)方面取得了显著进展,促进了像GPT-4和LLaMA-405B这样越来越大的模型的发展。然而,模型规模的扩大导致计算成本和能源消耗呈指数级增长,使得这些模型对于资源有限的学术研究人员和企业来说不切实际。与此同时,小型模型(SMs)在实际应用中经常被使用,尽管它们的重要性目前被低估了。这引发了关于LLMs时代小型模型角色的重要问题,这是以往研究中很少关注的话题。在本项工作中,我们系统地从两个关键角度检视了LLMs和SMs之间的关系:合作与竞争。我们希望这项调查能为从业者提供有价值的见解,促进对小型模型贡献的更深层次理解,并促进计算资源的更有效利用。
我们翻译解读最新论文:大型语言模型时代小型模型的角色,文末有论文链接。
 作者:张长旺,图源:旺知识
作者:张长旺,图源:旺知识
1 引言
近年来,大型语言模型(LLMs)的快速发展彻底改变了自然语言处理(NLP)。像ELMo(Peters et al., 2018)和BERT(Devlin et al., 2019)这样的预训练语言模型验证了预训练和微调范式,该范式涉及通过预训练学习通用语言表示,然后通过微调将这些知识转移到特定NLP任务上以提高性能(Min et al., 2023a)。这种方法已经发展为基于提示的推理,如GPT家族(Radford et al., 2019; Brown et al., 2020),在模型对新输入执行任务之前,提示中会提供一些示例(Liu et al., 2023a)。
这些范式在包括语言生成(Dong et al., 2023)、语言理解(Wang et al., 2019)和特定领域的应用(如编码(Jiang et al., 2024b)、医学(He et al., 2023)和法律(Sun, 2023))等一系列任务上展示了卓越的性能。此外,关于突现能力的理论表明,某些推理能力通过增加模型大小而得到增强,一些能力仅在更大的模型中才出现(Wei et al., 2022a)。这导致了越来越大的模型的开发热潮,如GPT-4(Achiam et al., 2023)、Mixtral 8x22B(Jiang et al., 2024a)、PaLM-340B(Anil et al., 2023)和LLaMA-405B(Dubey et al., 2024)。结果,LLMs变得非常普遍,2024年3月的数据显示,ChatGPT(OpenAI, 2024)达到了约1.8亿用户。
尽管LLMs在人工通用智能(AGI)方面取得了显著进展,但它们的能力伴随着巨大的开销。模型规模的扩大导致计算成本和能源消耗呈指数级增长(Wan et al., 2023)。此外,训练和部署LLMs对于资源有限的学术研究人员和企业来说通常是不可行的。因此,人们转向了更小的语言模型(SLMs),如Phi-3.8B(Abdin et al., 2024)和Gemma-2B(Team et al., 2024),它们可以在显著减少参数的情况下实现可比的性能。
有人可能会认为像Phi-3.8B和Gemma-2B这样的模型不能算作真正的小型模型,而像BERT这样的真正小型模型已不再突出。然而,我们的发现表明,在实际应用中小型模型的使用被大大低估了。如图1所示,我们分析了HuggingFace上各种大小的开源模型的下载数量。结果显示,尤其是BERT-base这样的小型模型仍然非常受欢迎。这引发了关于LLMs时代小型模型角色的重要问题,这是以往研究中很少关注的话题。
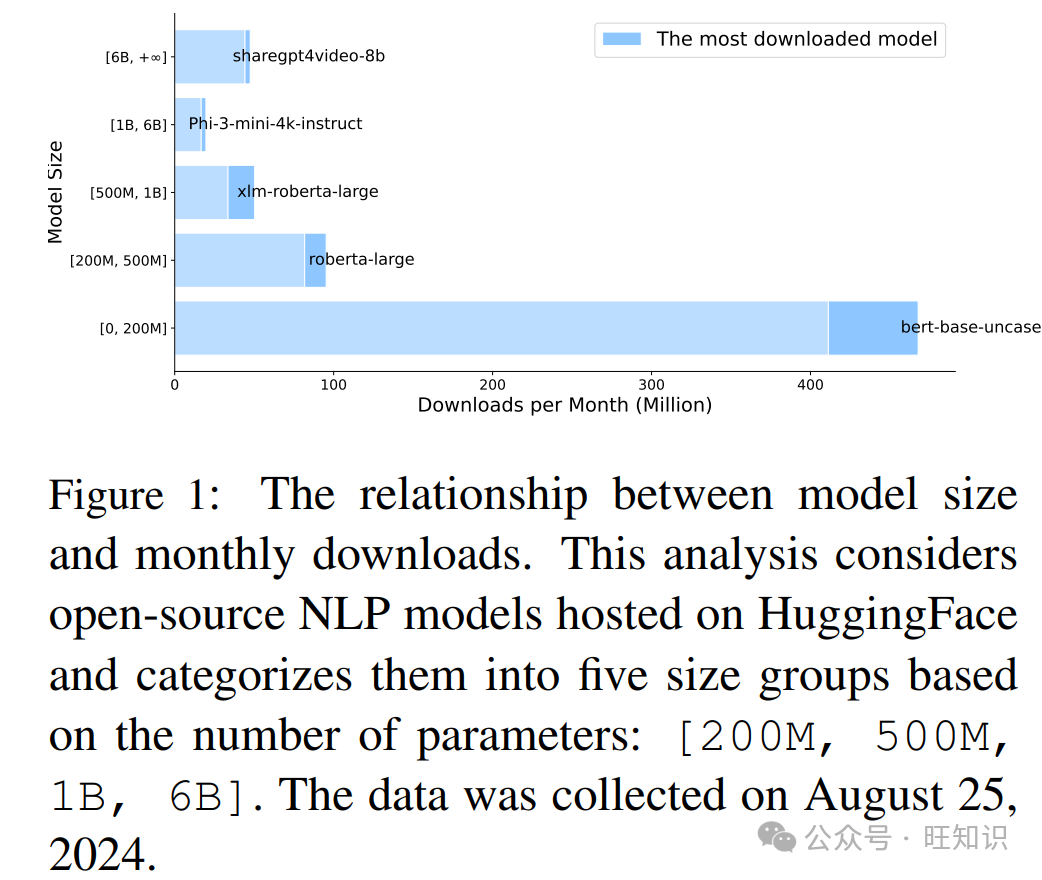
作为LLMs的对应物,小型模型(SMs)通常指的是参数数量相对较少的模型,包括语言模型以及简单的统计模型和浅层神经网络。然而,并没有明确的定义来区分大型模型和小型模型。在本项工作中,我们相对地考虑模型大小。例如,BERT(110M参数)(Devlin et al., 2019)与LLaMA-8B(Dubey et al., 2024)相比被认为是小型的,而LLaMA-8B与GPT4(175B参数)(Achiam et al., 2023)相比则被认为是小型的。这种相对定义允许灵活性,并确保随着未来开发出更大的模型,概念仍然相关。
为了评估SMs的角色,有必要比较它们与LLMs的优势和劣势。表1突出了四个关键维度:

准确性。LLMs由于参数数量大和在多样化数据集上的广泛训练,在广泛的NLP任务上展示了卓越的性能(Raffel et al., 2020; Kaplan et al., 2020)。尽管SMs在整体性能上通常落后,但通过知识蒸馏(Xu et al., 2024a)等技术增强后,它们可以实现可比的结果。
通用性。LLMs具有高度的通用性,能够处理广泛的任务,只需最少的训练示例(Dong et al., 2023; Liu et al., 2023a)。相比之下,SMs通常更加专业化,研究表明,在特定领域的数据集上微调SMs有时可以在特定任务上胜过通用的LLMs(Hernandez et al., 2023; Juan José Bucher and Martini, 2024; Zhang et al., 2023a)。
效率。LLMs需要大量的计算资源进行训练和推理(Wan et al., 2023),导致高成本和延迟,使它们在实时应用(例如信息检索(Reimers and Gurevych, 2019))或资源受限环境(例如边缘设备(Dhar et al., 2024))中不太实用。相比之下,SMs需要较少的训练数据和计算能力,提供了有竞争力的性能,同时显著降低了资源需求。
可解释性。较小、较浅的模型通常比它们更大、更深的对应物更透明、更易于解释(Gilpin et al., 2018; Barceló et al., 2020)。在医疗(Caruana et al., 2015)、金融(Kurshan et al., 2021)和法律(Eliot, 2021)等领域,通常更倾向于使用小型模型,因为它们的决策必须容易被非专家(例如医生、金融分析师)理解。
在本项工作中,我们从两个关键角度系统地检视了LLMs时代小型模型的角色:(1)合作(§ 2)。LLMs提供了卓越的准确性,能够处理广泛的任务,而SMs更加专业化和成本效益高。在实践中,LLMs和SMs之间的合作可以在性能和效率之间取得平衡,实现了资源高效、可扩展、可解释和成本效益高,同时保持高性能和灵活性的系统。(2)竞争(§ 3)。SMs具有独特的优势,如简单性、低成本和更大的可解释性,并且它们拥有利基市场。根据任务或应用的具体要求,仔细评估LLMs和SMs之间的权衡至关重要。
2 大小模型合作
在下文中,我们将展示SMs和LLMs如何合作以优化资源使用:SMs增强LLMs(§ 2.1)和LLMs增强SMs(§ 2.2)。整体合作框架列在图2中。
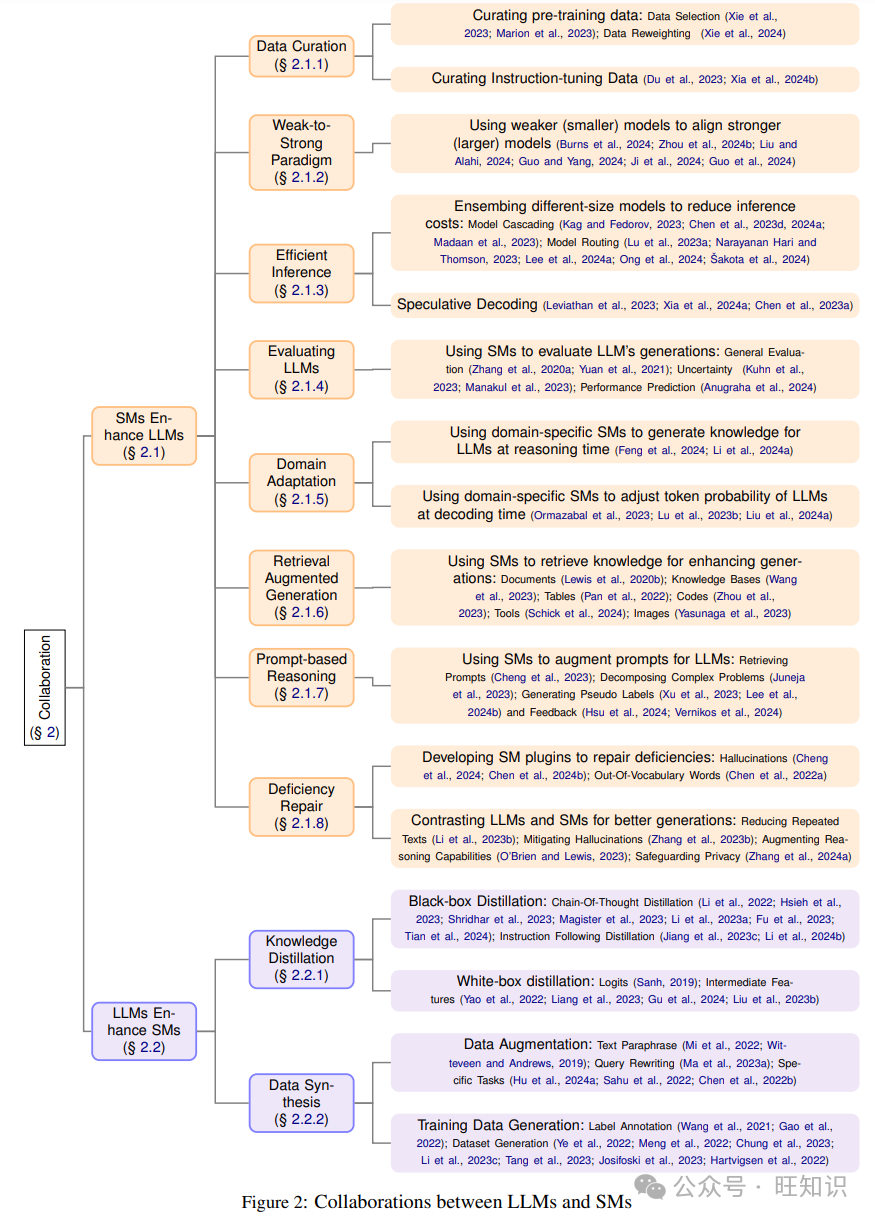
2.1 SMs增强LLMs
2.1.1 数据策展
在下文中,我们将展示如何使用小型模型从两个方面策展数据:预训练数据和指令调整数据。
策展预训练数据 LLMs的推理能力主要归因于它们在广泛和多样化的数据集上的预训练,这些数据集通常来自网络抓取、书籍和科学文献。由于扩大这些训练数据集的数量和多样性增强了LLMs的泛化能力,因此已经做出了重大努力来编制大规模和多样化的预训练语料库,如C4(Raffel et al., 2020)和Pile(Gao et al., 2021)。此外,规模法则(Kaplan et al., 2020)已经证明,模型性能高度依赖于模型参数的规模和训练数据集的大小。这可能表明,为了开发更强大的模型,人们应该尽可能多地使用数据进行预训练。
然而,这种方法面临一个重大挑战:数据的可用性是有限的,公共人类文本数据可能很快就会耗尽(Villalobos et al., 2024)。此外,并非所有数据对模型性能的贡献都是相等的;网络抓取的内容通常包含噪声和低质量文本。这导致了从纯粹关注数据数量的范式转变,转而优先考虑数据的质量。最近的研究表明“少即是多”(Marion et al., 2023),主张使用数据选择或修剪技术从大型数据集中策展出高质量的子集,从而增强模型性能(Albalak et al., 2024)。
现有的数据策展方法通常依赖于基于规则的启发式方法,如黑名单过滤和MinHash去重(Raffel et al., 2020; Tirumala et al., 2024; Penedo et al., 2023; Wenzek et al., 2020)。然而,这些手动的、基于规则的方法对于原始文本数据的规模和复杂性越来越不够用。一个常见的替代方案是使用专门训练来评估文本质量的小型模型,从而选择高质量的子集。例如,可以训练一个简单的分类器来评估内容质量,专注于移除嘈杂的、有毒的和私人的数据(Brown et al., 2020; Du et al., 2022; Chowdhery et al., 2023; Xie et al., 2023)。另一种技术涉及使用代理语言模型计算的困惑度分数来选择更可能高质量的数据(Wenzek et al., 2020; Marion et al., 2023)。
除了数据选择,数据重新加权是一种策略,它分配特定领域的权重,有效地调整不同文本来源的采样概率。这可以通过训练一个小型代理模型来设置这些领域权重来实现,这反过来可以增强预训练模型在各个领域的泛化能力(Xie et al., 2024)。
策展指令调整数据 LLMs通过预训练获得了大量的知识,指令调整旨在将这些模型能力与人类偏好对齐(Ouyang et al., 2022; Bai et al., 2022a)。虽然早期研究集中在使用大规模指令数据集对LLMs进行调整,但最近的发现表明,即使使用更小的数据集也可以实现强大的对齐。具体来说,“少即是多对齐”研究表明,仅在1000个精心策展的指令示例上进行微调就可以产生一个对齐良好的模型(Zhou et al., 2024a)。这强调了为有效的指令调整选择高质量数据的重要性(Longpre et al., 2023; Chen et al., 2023c)。
面向模型的数据选择(MoDS)(Du et al., 2023)是一种方法,它使用小型语言模型DeBERTa(He et al., 2021)来评估指令数据的质量、覆盖范围和必要性。此外,LESS框架(Xia et al., 2024b)表明,小型模型可以用来为不同家族的更大模型选择有影响力的数据。这强调了使用针对性的数据选择技术来优化指令调整过程的潜力。
总结和未来方向
鉴于我们人类能够创造的数据量即将受到限制,专注于策展现有数据并接受“少即是多”的原则至关重要。在本节中,我们探讨了小型模型如何在预训练和微调过程中的数据选择和重新加权中发挥重要作用。
未来方向:
虽然数据策展提供了明显的优势,但LLMs仍然倾向于产生幻觉和有毒内容。此外,移除低质量或有毒文本可能会潜在地降低某些能力,如通用性(Longpre et al., 2024)。因此,定义更细致的数据质量评估标准至关重要,包括事实性、安全性和多样性等维度(Wettig et al., 2024; Liu et al., 2024b)。研究使用小型模型开发有效和高效的数据选择方法是一个有价值的研究领域。
合成数据作为人类生成数据的宝贵补充(Long et al., 2024),但小型模型在策展合成数据方面的潜力在很大程度上还未被探索。
2.1.2 弱强范式
LLMs通常通过人类反馈的强化学习(RLHF)与人类价值观对齐,人类青睐的行为会得到奖励,而评价不佳的行为会受到惩罚(Shen et al., 2023)。然而,随着LLMs的不断发展并在各种任务中超越人类能力,它们正在成为超人模型,能够执行可能超出人类理解的复杂和创造性任务。例如,这些模型可以生成数千行专业代码,进行复杂的数学推理,并创作长篇、创意性的小说。评估这类输出的正确性和安全性对人类评估者来说是一个巨大的挑战。这种情况引入了一种新的对齐超人模型的范式,称为弱强泛化,涉及使用较弱(较小)的模型作为监督者来对齐更强大(更大)的模型(Burns et al., 2024)。在这种方法中,大型、功能强大的模型在由较小、能力较弱的模型生成的标签上进行微调,使强大的模型能够超越它们较弱监督者的局限性进行泛化。
在弱强泛化的概念基础上,最近提出了几种变体。例如,Liu和Alahi(2024)建议使用一组多样化的专业化弱教师,而不是依赖于单一的通用模型,来共同监督强大的学生模型。Guo和Yang(2024)介绍了一种方法,通过在弱模型提供多个答案中结合可靠性估计来增强弱强泛化。这种方法通过过滤掉不确定的数据或调整可靠数据的权重来改进对齐过程。除了数据标签,弱模型还可以在推理阶段与大型模型合作,以进一步增强对齐。Aligner(Ji et al., 2024)使用小型模型来学习优选和非优选响应之间的校正残差,使直接应用于各种上游LLMs以与人类偏好对齐成为可能。Weak-to-Strong Search(Zhou et al., 2024b)将大型模型的对齐视为测试时的贪婪搜索,旨在最大化小型调整和未调整模型之间的对数似然差异,这些模型分别充当密集奖励信号和批评者。这种弱强范式不仅限于语言模型,也已经扩展到视觉基础模型(Guo et al., 2024)。
总结和未来方向
随着大型模型的快速发展,我们正接近一个超人模型将会出现的未来,这使得有效的人类监督变得越来越具有挑战性。弱强范式表明,弱监督者可以用来从强模型中提取知识,从而开发出确保安全和可靠对齐的超人奖励模型。
未来方向:
虽然弱强框架在从更强模型中提取知识方面是有效的,但它仍然远远没有恢复弱模型和强模型之间的全部性能差距。至关重要的是确保强模型对任务有深刻的、直观的理解,能够纠正弱模型的错误,并自然地与任务目标对齐(Burns et al., 2024)。未来的工作应该集中在识别有助于实现这一目标的属性和方法上。
当前对弱强泛化的理解有限。研究人员应该发展对支配对齐方法成功或失败的潜在机制的深刻理解,例如理论分析(Lang et al., 2024)、弱监督中的错误(Guo and Yang, 2024)和使用规模法则外推泛化错误(Kaplan et al., 2020)。
2.1.3 高效推理
模型集成 大型模型通常更强大,但伴随着显著的成本,包括更慢的推理速度和更昂贵的价格(APIs)。除了财务成本外,使用更大的模型还对环境和能源有相当大的影响(Wu et al., 2022)。相比之下,小型模型虽然可能性能较低,但在成本更低和推理更快方面具有优势。鉴于用户查询的复杂性范围广泛——从小型模型可以处理的简单问题到需要更大模型的更复杂问题——通过利用不同大小的模型集合,可以实现成本效益的推理。这种模型集成方法可以分为两类:模型级联和模型路由。
模型级联涉及顺序使用多个具有不同复杂度的模型来进行预测或决策,级联中的每个模型都有不同的复杂度。一个模型的输出可能会触发序列中下一个模型的激活(Varshney and Baral, 2022; Viola and Jones, 2004; Wang et al., 2011)。这种方法允许不同大小的模型协作,使小型模型能够处理更简单的输入查询,同时将更复杂的任务转移给更大的模型。这一过程中的关键步骤是确定给定模型是否能够处理输入问题。这种方法有效地优化了推理速度并减少了财务成本。
一些现有技术训练了一个小型评估器来评估模型输出的正确性(Kag and Fedorov, 2023; Chen et al., 2020, 2023d)、置信度(Chen et al., 2024a)或质量(Ding et al., 2024b),从而决定是否将查询升级到更复杂的模型。鉴于LLMs可以执行自我验证(Dhuliawala et al., 2023)并在其响应中提供置信度水平(Tian et al., 2023),AutoMix(Madaan et al., 2023)使用验证提示多次查询模型,使用这些响应的一致性作为估计的置信度分数。然后,框架决定是否接受当前模型的输出,或者是否将查询转发给其他模型以提高性能。
模型路由通过动态地将输入数据定向到最合适的模型来优化多个不同大小模型的部署,从而在实际应用中提高效率和有效性。这种方法的核心组件是开发一个路由器,它将输入分配到池中的一个或多个合适的模型。
一种直接的方法是考虑所有模型的输入输出对,并选择表现最好的模型(Jiang et al., 2023a)。然而,这种全面的集成策略并没有显著降低推理成本。为了解决这个问题,一些方法训练了基于奖励的高效路由器,无需访问模型的输出即可选择最优模型(Lu et al., 2023a; Narayanan Hari and Thomson, 2023)。OrchestraLLM(Lee et al., 2024a)引入了一个基于检索的动态路由器,假设具有相似语义嵌入的实例共享相同的难度水平。这允许根据测试实例与专家池中实例之间的嵌入距离选择适当的专家。类似地,RouteLLM(Ong et al., 2024)利用人类偏好数据和数据增强来训练一个小型路由器模型,有效地减少了推理成本并增强了域外泛化。FORC(Šakota et al., 2024)提出了一个元模型(一个回归模型),在过程中不需要执行任何大型模型即可将查询分配给最合适的模型。元模型是在现有的查询和模型性能分数对上训练的。此外,最近还建立了模型路由的基准(Hu et al., 2024b; Shnitzer et al., 2023),促进了大型语言模型更易于访问和成本效益的部署。
推测性解码 这种技术旨在加速生成模型的解码过程,通常涉及使用一个小型、更快的辅助模型与主要的大型模型一起使用。辅助模型可以并行快速生成多个令牌候选项,然后由更大、更精确的模型进行验证或提炼。这种方法允许更快的初始预测,随后由更计算密集型的模型进行验证(Leviathan et al., 2023; Xia et al., 2024a; Chen et al., 2023a)。
总结和未来方向
与大型模型或APIs相关的推理成本可能相当高,但异构模型的协作可以有效降低这些费用并加快推理速度。在本节中,我们介绍了模型集成和推测性解码作为优化推理过程的策略。
未来方向:
现有的集成方法通常依赖于有限的、预定义的模型列表,然而现实世界包含开放域和不断演变的LLMs,如HuggingFace上可用的模型。探索如何利用这些广泛的模型库创建智能和高效的系统具有重要的前景(Shen et al., 2024)。
在当前的推测性解码方法中,辅助模型通常被限制为与主模型来自相同的模型家族,例如不同大小的GPT。然而,探索来自不同来源的模型之间的协作是有益的。
2.1.4 评估LLMs
有效评估LLMs生成的开放式文本在各种NLP任务中提出了重大挑战(Chang et al., 2024)。传统的评估方法,如BLEU(Papineni et al., 2002)和ROUGE(Lin, 2004),侧重于表面形式的相似性,通常不足以捕捉生成文本的细微语义意义和组合多样性(Liu et al., 2016)。
为了解决这些限制,基于模型的评估方法使用小型模型自动评估性能。例如,BERTSCORE(Zhang et al., 2020b)使用BERT计算语义相似性,以评估机器翻译和图像字幕。同样,BARTSCORE(Yuan et al., 2021)利用编码器-解码器模型BART(Lewis et al., 2020a)从多个角度评估文本,包括信息量、流畅性和事实性。除了一般文本评估,一些方法使用小型自然语言推理(NLI)模型来估计LLM响应的不确定性(Manakul et al., 2023; Kuhn et al., 2023)。另一个有价值的应用涉及使用代理模型预测LLM性能(Anugraha et al., 2024),这大大减少了微调和推理过程中与模型选择相关的计算成本。
总结和未来方向
LLMs能够生成广泛和复杂的文本,这使得基于简单启发式指标评估内容变得困难。为了克服这一挑战,可以采用小型代理模型从多个角度自动化评估生成的文本,包括事实性和流畅性等方面。
未来方向:
随着大型模型的进步,它们越来越多地生成长篇和复杂的文本,如专业代码和科学论文,这对人类评估者来说是一个挑战。因此,开发高效的评估器来评估生成内容的各个方面,如事实性(Min et al., 2023b)、安全性(Zhang et al., 2024b)和不确定性(Huang et al., 2023),是至关重要的。
2.1.5 领域适应
尽管LLMs的能力不断增长,但它们仍然需要进一步定制,以在特定用例(例如编码)和领域(例如医疗任务)中实现最佳性能。虽然在特定领域数据上微调是一种适应LLMs的方法,但这一过程变得越来越资源密集,有时是不可行的——特别是当无法访问内部模型参数时,如ChatGPT这样的模型。最近的研究发现,使用小型模型适应LLMs,可以根据是否访问模型的内部状态,将这些方法分为两类:白盒适应和黑盒适应。
白盒适应通常涉及微调小型模型,以调整冻结LLMs的特定目标领域的令牌分布。例如,CombLM(Ormazabal et al., 2023)学习一个线性函数,将来自大型黑盒模型的概率分布与来自小型领域特定专家模型的概率分布结合起来。IPA(Lu et al., 2023b)引入了一个轻量级适配器,在解码过程中将大型模型调整为期望目标,而无需微调。IPA通过优化结合分布来实现这一点,使用强化学习。Proxy-tuning(Liu et al., 2024a)微调一个小型语言模型,对比调整过的模型(专家)和未调整版本(反专家)的概率,以指导更大的基础模型。
这些方法仅修改小型领域特定专家的参数,允许LLMs适应特定领域的任务。然而,白盒适应不适用于API-only建模服务,这些服务限制了对内部模型参数的访问。
黑盒适应涉及使用小型领域特定模型通过提供文本相关知识来引导LLMs朝向目标领域。检索增强生成(RAG)可以从外部文档集合或知识库中提取与查询相关的知识,并因此通过利用它们的上下文学习能力增强通用LLMs。它涉及首先使用轻量级检索器从领域语料库中找到相关内容,然后将这些内容纳入LLM的输入中,以提高其对领域特定知识的了解(Siriwardhana et al., 2023; Shi et al., 2023; Gao et al., 2023)。
另一种方法使用小型专家模型以生成方式检索背景知识,供基础LLM使用。例如,BLADE(Li et al., 2024a)和Knowledge Card(Feng et al., 2024)首先在特定领域数据上预训练小型专家模型,然后生成专业知识以响应查询,从而提高基础LLM的性能。
总结和未来方向
调整大型模型以适应特定目标领域是资源密集型的。为了解决这一挑战,一种更有效的方法是基于特定领域数据微调小型模型。这个轻量级专家模型随后可以在解码(白盒适应)或推理(黑盒适应)期间指导LLM,为领域适应提供了一种成本效益高的解决方案。
未来方向:
在白盒适应中,大多数方法要求小型模型和基础模型属于同一家族,如GPT家族。为了增强领域适应,重要的是开发利用更广泛的多样化模型的技术(Kasai et al., 2022; Xu et al., 2024b; Remy et al., 2024)。
当前方法通常需要从头开始预训练领域特定的专家,这对于资源受限的任务是不切实际的。研究如何使用有限数量的样本适应LLMs是一个有价值的研究领域(Sun et al., 2024)。
2.1.6 检索增强生成
LLMs展示了令人印象深刻的推理能力,但它们对特定知识的记忆能力是有限的。因此,LLMs可能在需要领域特定专业知识或最新信息的任务中挣扎。为了解决这些限制,检索增强生成(RAG)通过使用轻量级检索器从外部知识库、文档集合或其他工具中提取相关文档片段来增强LLMs。通过纳入外部知识,RAG有效地缓解了生成事实不准确的内容的问题,通常被称为幻觉(Shuster et al., 2021)。基于检索的增强生成方法可以根据检索源的性质广泛地分为三种类型。
文本文档是RAG方法中最常用的检索源,包括维基百科(Trivedi et al., 2023; Asai et al., 2023)、跨语言文本(Nie et al., 2023)和特定领域语料库(例如医疗(Xiong et al., 2024)和法律(Yue et al., 2023)领域)。这些方法通常使用轻量级检索模型,如稀疏BM25(Robertson et al., 2009)和密集BERT基础(Izacard et al., 2021)检索器,从这些来源中提取相关文本。
结构化知识包括知识库和数据库等来源,这些通常是经过验证的,可以提供更精确的信息。例如,
KnowledgeGPT(Wang et al., 2023)使LLMs能够从知识库中检索信息,而T-RAG(Pan et al., 2022)通过将检索到的表格与查询连接起来增强答案。StructGPT(Jiang et al., 2023b)进一步通过从包括知识库、表格和数据库在内的混合来源中检索来增强生成。这些方法中的检索器可以是一个轻量级实体链接器、查询执行器或API。
其他来源包括代码、工具甚至图像,使LLMs能够利用外部信息进行增强推理。例如,DocPrompting(Zhou et al., 2023)使用BM25检索器在代码生成之前获得相关的代码文档。类似地,Toolformer(Schick et al., 2024)展示了LMs可以通过简单的API自我学习使用外部工具,如翻译器、计算器和日历,从而显著提高性能。
总结和未来方向
检索增强生成显著扩展了LLMs的知识边界,小型模型主要在这个过程中充当检索器。通过使用轻量级检索器,可以高效地访问各种类型的信息——如文档、结构化知识、代码和有用的工具——以增强模型的能力。
未来方向:
检索增强文本生成的性能对检索质量非常敏感(Yoran et al., 2023)。因此,开发稳健的方法来整合嘈杂的检索文本是重要的。
RAG可以扩展到多模态场景,超越仅文本信息,如图像(Yasunaga et al., 2023)、音频(Zhao et al., 2023)等。
2.1.7 基于提示的学习
基于提示的学习是LLMs中的一个普遍范式,其中提示被精心设计以促进少样本甚至零样本学习,使它们能够以最少或无需标记数据的方式适应新场景(Liu et al., 2023a)。这种方法利用了上下文学习(ICL)(Dong et al., 2023)的能力,它不执行参数更新。相反,它依赖于包括几个演示示例在内的提示上下文,这些示例在自然语言模板中结构化。
在这个学习过程中,小型模型可以被用来增强提示,从而提高更大模型的性能。例如,Uprise(Cheng et al., 2023)优化了一个轻量级检索器,自主检索零样本任务的提示,从而最小化手动提示工程所需的工作量。类似地,DaSLaM(Juneja et al., 2023)使用小型模型将复杂问题分解为需要较少推理步骤的子问题,从而在多个推理数据集上提高大型模型的性能。其他方法涉及微调小型模型为输入生成伪标签(Xu et al., 2023; Lee et al., 2024b),这比原始ICL实现了更好的性能。此外,小型模型也可以用来验证(Hsu et al., 2024)或重写(Vernikos et al., 2024)LLMs的输出,从而在不需要微调的情况下实现性能提升。
总结和未来方向
基于提示的学习能够处理各种复杂任务,通过在提示模板中嵌入少量示例。为了进一步增强这一过程,小型模型可以被用来增强提示,通过重新构造问题和生成反馈。这种高效的增强允许在不需要参数更新的情况下改进LLMs。
未来方向:
最近的研究发现集中在利用小型模型来增强大型模型在基于提示的学习范式中的推理能力。同样重要的是探索如何使用小型模型来开发值得信赖、安全和公平的LLMs。
2.1.8 缺陷修复
功能强大的LLMs可能会生成重复的、不真实的和有毒的内容,小型模型可以用来修复这些缺陷。我们介绍两种实现这一目标的方法:对比解码和小模型插件。
对比解码利用较大模型(专家)和较小模型(业余爱好者)之间的对比,通过选择最大化它们对数似然差异的令牌。现有研究探索了利用LLMs和SMs的对数几率的协同使用,以减少重复文本(Li et al., 2023b)、减轻幻觉(Sennrich et al., 2024)、增强推理能力(O’Brien and Lewis, 2023)和保护用户隐私(Zhang et al., 2024a)。由于微调LLMs计算密集,代理调整提出微调小型模型,并对比原始LLMs和小型模型之间的差异以适应目标任务(Liu et al., 2024a)。
小型模型插件微调一个专门的小型模型来解决较大模型的一些缺点。例如,LLMs在遇到未见过的词汇(Out-Of-Vocabulary)时性能可能会下降。为了解决这个问题,我们可以训练一个小型模型来模仿大型模型的行为,并为未见过的词汇插补表示(Pinter et al., 2017; Chen et al., 2022a)。通过这种方式,我们可以以很小的成本使大型模型更加健壮。此外,LLMs可能会生成幻觉文本,我们可以训练一个小型模型来检测幻觉(Cheng et al., 2024)或校准置信度分数(Chen et al., 2024b)。
总结和未来方向
尽管语言模型非常强大,但它们有自己的弱点需要解决,例如幻觉、毒性等。在这里,我们介绍了对比解码和开发小型模型插件来使LLMs更加健壮和安全。
未来方向:
我们可以将使用小型模型修复大型模型缺陷的模式扩展到其他问题。例如,LLMs的数学推理非常脆弱,它们在面对基本数学问题时可能会崩溃,例如ChatGPT认为9.11大于9.9 a。
ahttps://x.com/goodside/status/1812977352085020680
2.2 LLMs增强小型模型
2.2.1 知识蒸馏
通过扩大模型规模来增强性能是一种直接的方法,但这通常对于广泛部署给众多用户来说计算成本过高。为了缓解这一挑战,知识蒸馏(KD)(Hinton, 2015; Gou et al., 2021; Zhu et al., 2023; Xu et al., 2024a)提供了一种有效的解决方案。在KD中,一个较小的学生模型被训练来复制一个较大的教师模型的行为。通常,这一过程涉及较大的模型生成带有伪标签的数据集,然后较小的模型使用这些数据进行训练。
白盒蒸馏涉及使用教师模型的内部状态,这为学生模型的训练过程提供了透明度。这种方法利用教师LLMs的输出分布和中间特征,统称为特征知识(Liang et al., 2023; Gu et al., 2024; Liu et al., 2023b)。它使得开发成本效益高但功能强大的模型成为可能,如DistilBERT(Sanh, 2019)和QuantizedGPT(Yao et al., 2022)。
相比之下,黑盒知识蒸馏通常涉及通过教师LLM生成用于微调学生模型的蒸馏数据集。例如,Chain-of-Thought蒸馏(Wei et al., 2022b)提取LLM的理由来提供额外的监督,从而增强小型模型的推理能力(Li et al., 2022; Hsieh et al., 2023; Shridhar et al., 2023; Magister et al., 2023; Li et al., 2023a; Fu et al., 2023; Tian et al., 2024)。此外,Instruction Following Distillation旨在通过一组指令式提示-响应对微调LLMs,以提高它们的零样本性能(Jiang et al., 2023c; Li et al., 2024b)。此外,其他研究使用蒸馏来训练小型模型,用于知识密集型任务(Li et al., 2024c; Kang et al., 2024; Chen et al., 2024d)、意图发现(Liang et al., 2024)和幽默生成(Ravi et al., 2024),展示了KD在各个领域的多样性和有效性。
总结和未来方向
知识蒸馏促进了从较大模型到较小模型的知识转移,使得开发像DistilBERT这样的成本效益高且高效的模型成为可能。最近的进步集中在技术如Chain-of-Thought蒸馏和Instruction Following蒸馏上,这些技术增强了小型模型的推理能力。
未来方向:
当前的知识蒸馏方法主要侧重于使用闭源LLMs生成的标签和解释通过简单的监督微调来训练学生模型(Xu et al., 2024a)。然而,扩大从教师模型转移的知识范围,包括对学生模型输出的反馈(Lee et al., 2023)和特征知识(Gu et al., 2024),可以提供额外的好处。
LLM知识蒸馏的努力主要集中在转移LLMs的各种技能上,对可信赖性(Xu et al., 2024a),如有帮助性、诚实性和无害性(Bai et al., 2022b; Yang et al., 2023; Cui et al., 2023)的关注相对较少。
2.2.2 数据合成
人类创造的数据是有限的,并且有担忧认为公开可用的人类文本可能很快就会耗尽(Villalobos et al., 2024)。此外,并非所有特定任务都需要大型模型。鉴于这些考虑,使用LLMs为小型模型训练生成训练数据既高效又可行。在以下部分中,我们讨论如何利用LLMs进行数据合成,重点关注两个关键领域:训练数据生成和数据增强。
训练数据生成涉及首先使用LLMs(如ChatGPT)以无监督方式从头开始生成数据集,然后在合成的数据集上训练小型任务特定模型。这种方法使得高度高效的推理成为可能,因为最终任务模型的参数数量比原始大型模型少几个数量级(Ye et al., 2022; Meng et al., 2022; Chung et al., 2023)。后续研究将这种方法扩展到各种任务,包括文本分类(Li et al., 2023c)、临床文本挖掘(Tang et al., 2023)、信息提取(Josifoski et al., 2023)和仇恨言论检测(Hartvigsen et al., 2022)。另一种方法仅利用LLMs生成标签而不是整个训练数据集,类似于知识蒸馏的过程(Wang et al., 2021; Gao et al., 2022)。
数据增强在这里指的是使用LLMs修改现有数据点,从而增加数据多样性,然后可以直接用于训练小型模型(Ding et al., 2024a; Chen et al., 2023b)。例如,LLMs可以被用来改写或重构文本以生成额外的训练样本(Mi et al., 2022; Witteveen and Andrews, 2019)。在信息检索中,LLMs可以重写查询(Ma et al., 2023a),以更好地与目标文档对齐。此外,数据增强可以应用于各种任务,如个性检测(Hu et al., 2024a)、意图分类(Sahu et al., 2022)和对话理解(Chen et al., 2022b)。使用这些增强样本对小型模型进行微调可以显著提高其有效性和鲁棒性。
总结和未来方向
合成数据作为人类生成数据的有效补充,增加了数据多样性并改善了长尾样本的覆盖。这种方法可以显著提高小型模型的性能和鲁棒性。
未来方向:
目前,闭源LLMs仍然比开源对应物更强大。然而,使用闭源模型进行数据合成可能会引发隐私和安全问题,特别是在涉及患者数据等敏感医疗场景中(Ollion et al., 2023)。解决在此过程中如何保护数据隐私是一个关键的关注领域。
使用大规模模型生成训练数据成本高昂,因此探索减少费用同时仍然产生高质量数据的方法至关重要。例如,最近的研究表明,有时较小、功能较弱的模型可以生成更好的训练数据点(Bansal et al., 2024)。
3 大小模型竞争
下面,我们介绍了小型模型更可取的三种情况:计算受限的环境(§ 3.1)、特定任务的环境(§ 3.2)和需要可解释性的环境(§ 3.3)。
3.1 计算受限环境
尽管LLMs代表了人工通用智能(AGI)发展的重要里程碑,但它们令人印象深刻的能力伴随着巨大的计算需求。扩大模型规模导致训练时间呈指数级增长,显著增加了推理延迟(Wan et al., 2023)。训练和部署LLMs需要更多的硬件和更大的能源消耗,这对于资源有限的学术研究人员和企业来说通常是不可行的。此外,这种高计算开销阻止了LLMs直接应用于计算受限的环境,如边缘和移动设备(Dhar et al., 2024)。
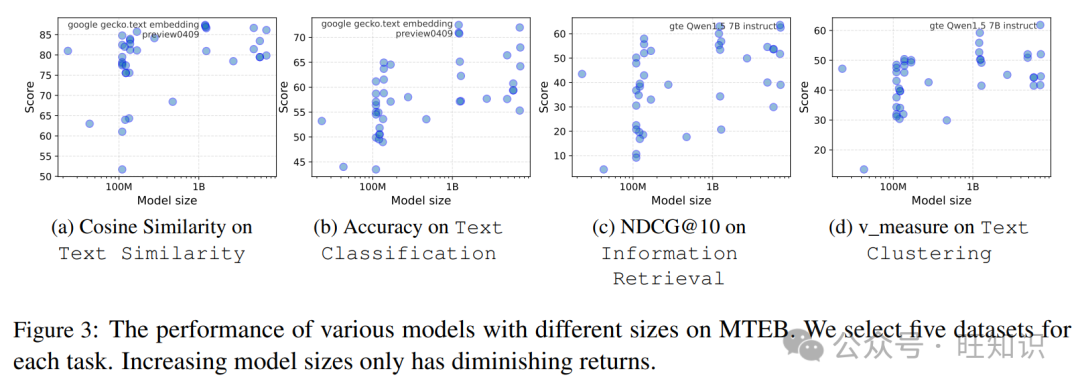
此外,并非所有任务都需要大型模型;一些不涉及知识密集和不要求复杂推理的任务可以由小型模型有效处理。例如,图3c展示了MTEB(Muennighoff et al., 2023)中四项任务的性能与模型规模之间的关系,我们观察到随着模型规模的增加,性能收益递减,特别是在文本相似性和分类等任务中。在信息检索(图3c)的情况下,它涉及计算查询和文档集合之间的相似性,快速推理速度至关重要。在这些条件下,轻量级Sentence-BERT(Reimers and Gurevych, 2019)仍然在IR任务中广泛使用。
因此,由于对可访问性、效率和民主化的需求,人们越来越倾向于更小、更高效的模型。例如,Phi-3.8B(Abdin et al., 2024)、MiniCPM(Hu et al., 2024c)和Gemma2B(Team et al., 2024)。
在计算资源有限的情况下,小型模型越来越有价值。技术如知识蒸馏(Xu et al., 2024a)允许从LLMs转移知识到小型模型,使这些小型模型在显著减少模型规模的同时实现类似的性能。此外,小型模型通常更适合于计算密集型任务,如信息检索,因为它们的资源需求较低。
3.2 特定任务环境
训练LLMs需要数万亿个标记(Raffel et al., 2020; Kaplan et al., 2020; Gao et al., 2021),但对于某些特定领域(例如生物医学文本)或任务(例如表格学习)来说,足够的数据往往不可用。在这种情况下,预训练一个大型基础模型是不可行的,小型模型在这种情况下可以提供有希望的回报。
我们概述了几个特定任务场景,小型模型可以在这些场景中提供可比的结果:
领域特定任务:像生物医学或法律这样的领域通常可用的训练标记较少。最近的研究表明,对特定领域的数据集进行微调可以使小型模型在各种生物医学(Hernandez et al., 2023; Juan José Bucher and Martini, 2024)和法律(Chalkidis, 2023)任务上胜过通用LLMs。
表格学习:表格数据集通常比其他领域的基准数据集小,如文本或图像数据,并且是高度结构化的,由不同类型的数据(例如,数值、分类、序数)组成。由于这些特点,小型基于树的模型在表格数据上可以实现与大型深度学习模型相媲美的性能(Grinsztajn et al., 2022)。
短文本任务:短文本表示和推理通常不需要广泛的背景知识。因此,小型模型特别适合于文本分类(Zhang et al., 2023a)、短语表示(Chen et al., 2024c)和实体检索(Chen et al., 2021)等任务。
其他专业任务:在某些小众领域,小型模型可以超越大型模型。例如,机器生成文本检测(Mireshghallah et al., 2023)、电子表格表示(Joshi et al., 2024)和信息提取(Ma et al., 2023b)。
小型模型在专业领域有明显的优势,为这些领域或任务开发轻量级模型是一个有前景的方法。
3.3 需要可解释性的环境
可解释性的目标是提供模型内部推理过程的人类可理解的解释,即模型是如何工作的(透明度)。通常,较小(例如,浅层)和更简单(例如,基于树)的模型比更大(例如,深度)和更复杂(例如,神经)的模型提供更好的可解释性(Barceló et al., 2020; Gosiewska et al., 2021)。
在实践中,医疗(Caruana et al., 2015)、金融(Kurshan et al., 2021)和法律(Eliot, 2021)等行业通常更青睐小型、更可解释的模型,因为这些模型产生的决策必须对非专家(例如,医生、金融分析师)来说是可理解的。在高风险决策制定环境中,通常更倾向于使用可以轻松审核和解释的模型。
在选择LLMs或SMs时,重要的是权衡模型复杂性与人类理解需求之间的关系。
4 结论
在本项工作中,我们从两个角度系统地分析了LLMs和SMs之间的关系。首先,LLMs和SMs可以合作,在性能和效率之间取得平衡。其次,它们在特定条件下竞争:计算受限的环境、特定任务的应用和需要高可解释性的场景。在选择给定任务或应用的合适模型时,仔细评估LLMs和SMs之间的权衡至关重要。虽然LLMs提供了卓越的性能,但SMs具有显著的优势,包括可访问性、简单性、低成本和互操作性。我们希望这项研究为从业者提供了宝贵的见解,鼓励对资源优化和开发成本效益高的系统的进一步研究。

































 粤ICP备17114055号
粤ICP备17114055号