导读 2024 年 12 月 6 日,由 Ray 中文社区、蚂蚁开源联合主办的 Ray Forward 2024 年度盛会在北京蚂蚁 T 空间成功举办。其中,Bilibili 基础架构部技术专家郑志升分享了《Ray 在 Bilibili 的场景探索与落地实践》。Ray 作为新兴分布式计算框架,为 B 站业务发展提供了强大助力。本文将详细解读 B 站如何借助 Ray 实现技术突破与业务升级。文章开篇将介绍 B 站业务概况,包括业务场景、诉求以及面临的痛点,揭示 B 站寻求变革的背景。接着深入架构升级部分,分享问题洞察与方案实施过程,展现如何借助 Ray 优化架构。核心挑战环节聚焦 Ray 的能力增强和优化,揭秘 B 站工程师们如何突破技术瓶颈。最后,未来展望从场景扩展、底层能力提升和平台化等维度,勾勒出基于 Ray 的业务发展蓝图。无论是技术爱好者,还是渴望了解行业前沿的人士,都能从本文收获关于 B 站与 Ray 深度融合的宝贵经验与前瞻性视角。
今天的介绍会围绕下面四点展开:
4. 未来展望
分享嘉宾|郑志升 Bilibili 基础架构部技术专家
编辑整理|苗文亚
内容校对|李瑶
出品社区|DataFun
首先来介绍一下 B 站的业务概况。B 站是一个视频社区,其中很多内容是与 AI 相关的,比如生成式 AI、高光时刻、数字人、音色克隆、视频剪辑等场景。下面分享三个典型场景,介绍其面临的一些痛点。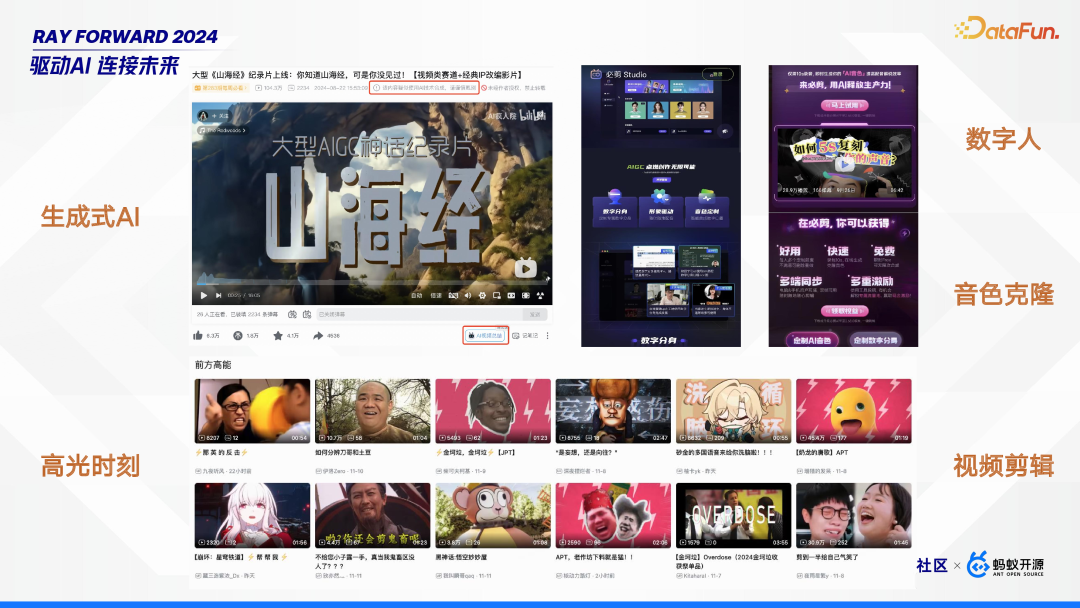
在视频剪辑场景中,需要对视频的内容进行多维度的提取和筛选过滤,当中包括高光片段、画面美学评分、弹幕信息等,具体会包括离线和在线两条链路:- 离线链路:主要工作是对视频数据进行处理,从中提取多维度特征。处理完成后,会将得到的 embedding 向量存储于 ES(Elasticsearch),以便后续在线上实现高效的检索功能。
- 在线链路:首先通过 Query 对用户意图展开分析,并借助标签过滤初步筛选信息。随后,基于多维度特征进行匹配召回,从众多数据中找出相关内容,再经过多路重排进行精细筛选,为用户提供精准的结果。
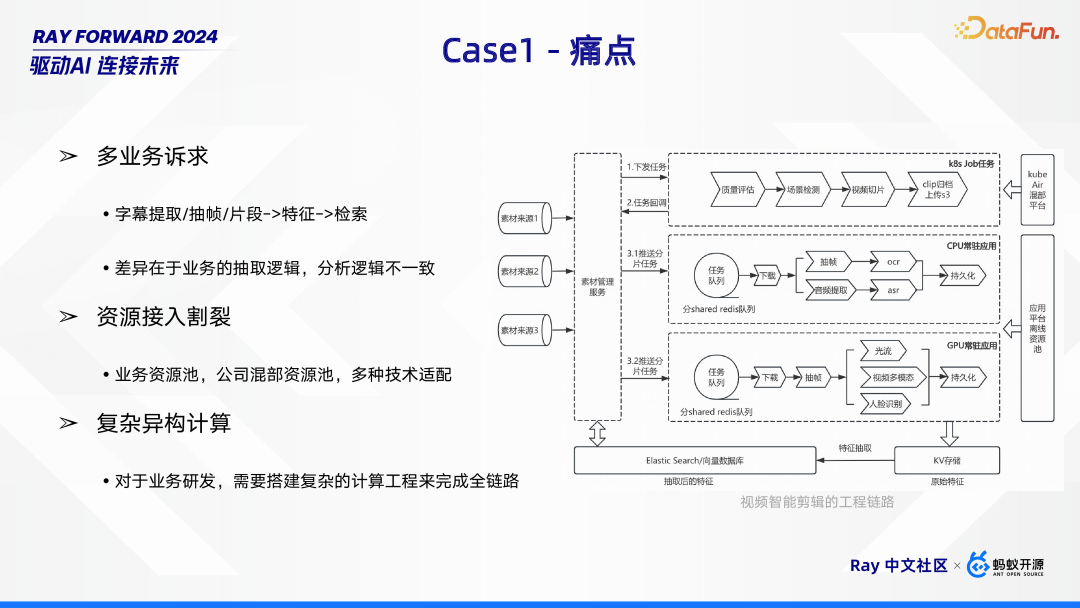
- 在多业务场景下,存在着如字幕提取、抽帧以及片段处理等工作,这些工作的最终目的是通过提取特征实现检索。然而,各业务之间存在差异,主要体现在抽取逻辑和分析逻辑不一致。例如,字幕提取业务可能侧重于文本信息的抽取与分析,抽帧业务则更关注图像画面的特征获取,片段处理或许又有其独特的逻辑思路,这些不同的逻辑共同构成了多业务在实现特征提取与检索过程中的复杂诉求。
- 对于业务研发,需要搭建复杂的计算工程来完成整个链路。
- 预处理阶段主要涵盖视频切片、抽帧等操作,在此基础上还需进行优质数据筛选,而筛选的依据包括光流分析以及美学评分等,通过这些步骤完成对原始数据的预处理,为后续工作奠定基础。
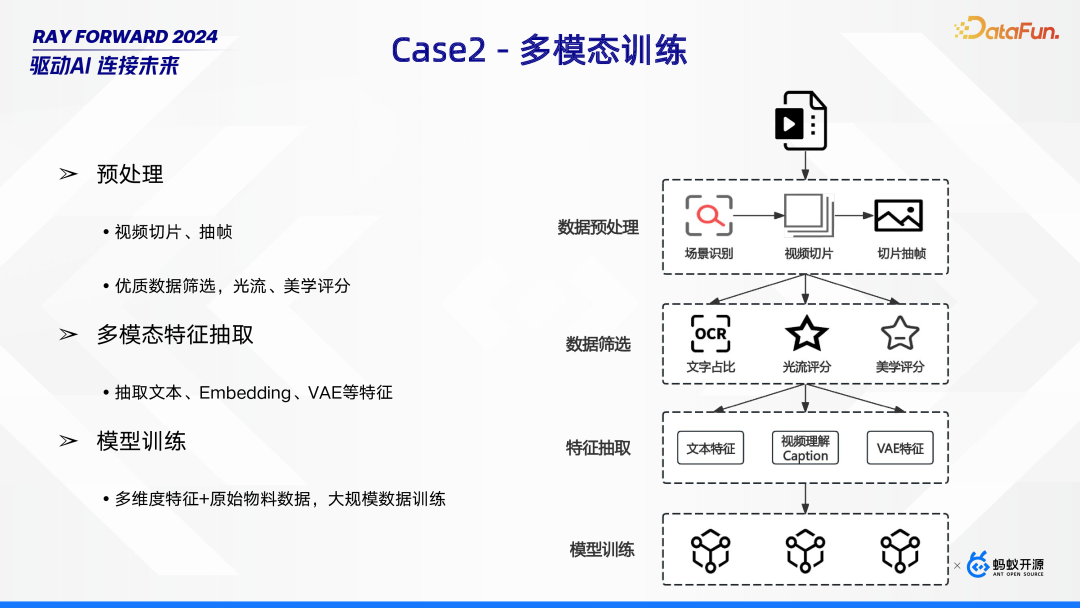
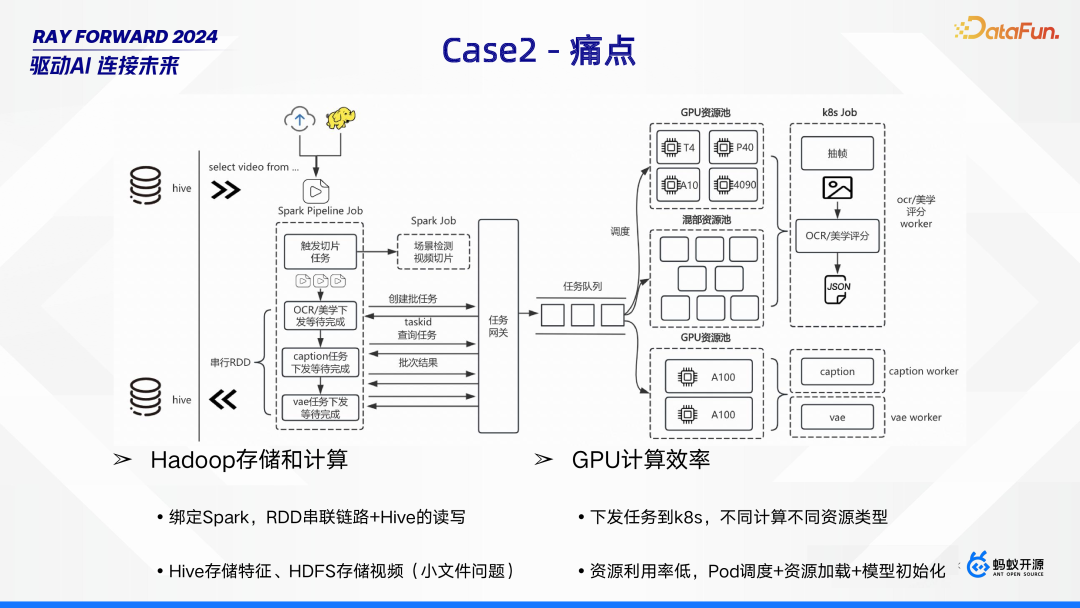
- 当前采用绑定 Spark,通过 RDD 串联链路结合 Hive 读写的方式。其中,特征数据存储于 Hive,视频则存于 HDFS,但 HDFS 存储视频时存在小文件问题,这不仅影响存储效率,还可能增加计算资源消耗,给多模态训练工作带来阻碍。
- 目前采用下发任务到 K8s 的方式,针对不同计算匹配不同资源类型。然而,这一过程中资源利用率较低,主要原因在于 Pod 调度、资源加载以及模型初始化等环节,这些环节消耗了大量时间与资源,影响了整体的 GPU 计算效率。
多媒体业务场景具有一些显著特点。一方面,任务量极为庞大,像直播和点播这类业务均呈现无状态特性。另一方面,存在异构资源诉求,涵盖 GPU、CPU、内存、磁盘以及网络等多种资源。此外,实时性需求具有差异化,其中直播业务要求达到毫秒级的实时响应,普通转码业务需满足秒级的实时性,而优化转码业务则为分钟级的时效性要求。
下图展示了工程链路的设计,分为两部分,第一部分是通过转码调度器驱动切片、转码和合并三个阶段的计算处理;第二部分是提供给业务的一些微服务。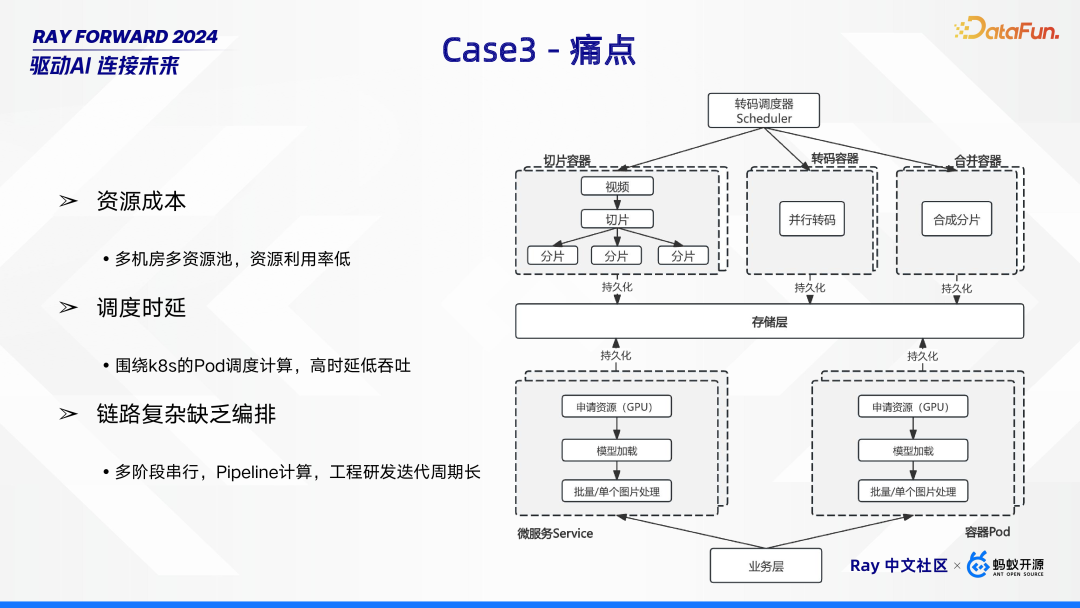
- 资源成本压力,整体的资源利用率偏低,如何提升资源高效利用。
- 调度时延问题突出,当前围绕 K8s 的 Pod 调度计算方式,存在高时延、低吞吐的情况,严重影响业务处理速度。
- 链路复杂且缺乏有效编排,业务流程呈现多阶段串行的 Pipeline 计算模式,使得工程研发迭代周期变长,难以快速响应业务需求变化。
- 分布式数据管道:多态数据的分布式处理;通用算子(OCR 等)和业务定制。
- 内容理解:围绕多模态大模型,抽取特征;各垂域场景微调大模型的推理供给业务。
- 技术底座:资源(C/GPU)、存储(灵活、多时效)、计算(Python/异构/性能效率)。
架构升级
根据上述三个场景的分析和痛点的概括,我们提出了针对性的解决方案。1. 问题洞察和方案实施
在资源管理领域,孤岛资源问题较为突出。其中,GPU 异构现象普遍,存在如 A10、A800 等各种不同类型的 GPU。同时,资源不透明问题严重,一方面无法感知多平台(如 K8s 和 Yarn)之间的资源利用情况,另一方面,不同平台在资源接入时工程差异极大,以 Spark 为例,这种差异给资源整合带来诸多困难。针对这些问题,可采取基于 K8s 资源合池的措施,并引入细粒度(针对异构 GPU)资源弹性的配额调度,以优化资源管理。而这一系列举措,与大数据引擎的高效运行息息相关。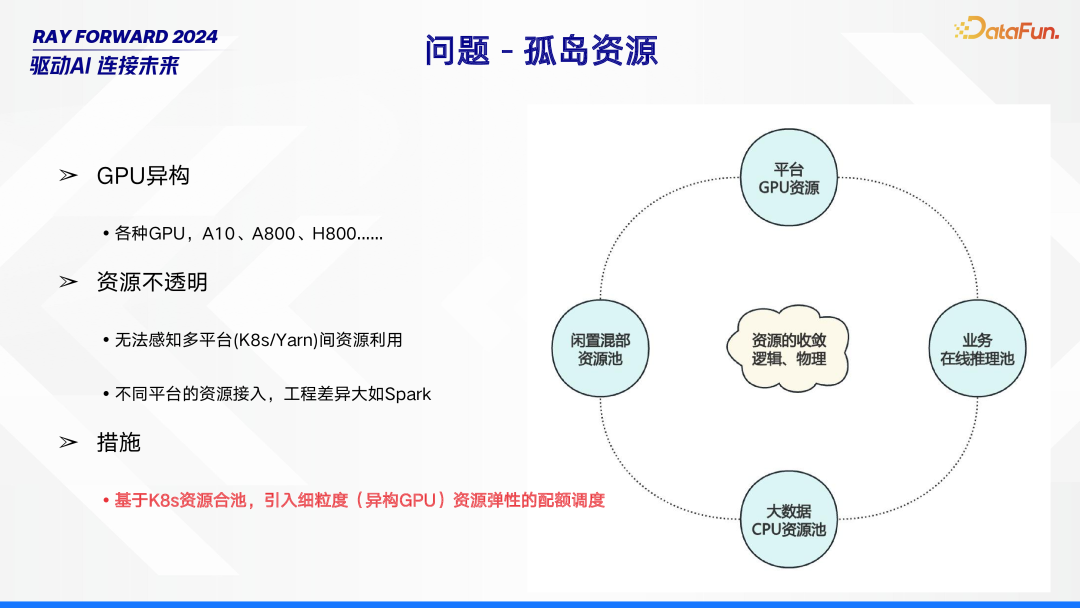
大数据引擎存在两方面显著问题。首先是 Python 生态薄弱,由于大数据计算引擎构建于 JVM 之上,这使得它与 AI 生态难以实现无缝对接,同时,Spark 在 GPU 上运行时问题频发,适配过程困难重重。其次,粗粒度计算原语也带来挑战:异构化计算中,CPU 与 GPU 特性差异明显;计算模型方面,Spark 采用 RDD,Flink 使用 DataStream;而且,尽管 Flink 和 Spark 都采用 DAG 架构,却均无法支持 DAG 图的动态变化。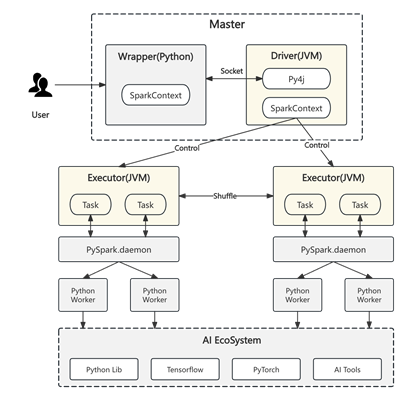
在计算范式中,AI 全链路计算过程涵盖多个关键环节。数据处理环节借助大数据计算引擎,针对多模态数据进行 CPU 与 GPU 协同计算;“炼丹” 环节包括离线和近线训练、超参调优,会用到 TensorFlow、PyTorch、Megatron 等工具;在线服务化环节涉及在线推理以及大规模在线推理,常采用 Triton、Seldon、KFServing、VLLM 等。实施方案方面,每个计算环节都涉及众多组件或工具,且不同环节的基础设施存在差异。尤其是生成式 AI 的兴起,带来更多训练和推理框架,使得资源管理和适配问题愈发突出。在此背景下,引入 Ray 可提供一种 DATA 与 AI 融合的通用计算方式,有望解决上述难题。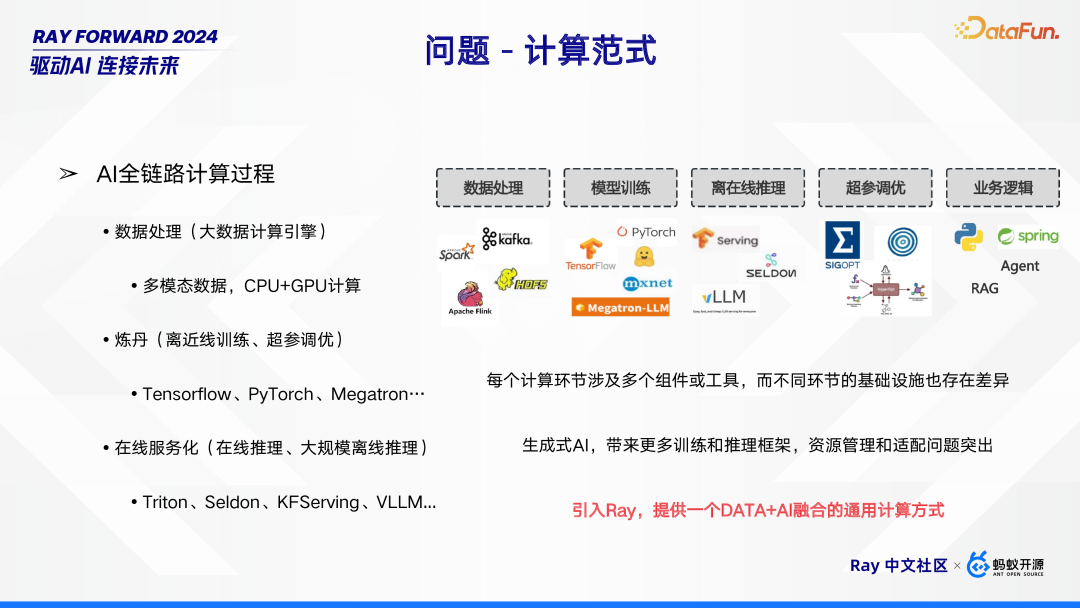
在存储介质方面,AI 对存储有着特定要求。一方面,需要 AI 友好的介质,即遵循 POSIX 协议且具备高吞吐能力(如缓存)的存储介质,以满足 AI 运算对数据读取速度的需求。另一方面,文件组织形式需足够灵活,涵盖非结构化与结构化存储。然而,现有存储常缺乏元信息层,且存在小文件问题。针对这些情况,可采取的措施是,将 DATA 作为 AI 的数据底座,使其能像数据湖一样,匹配不断演进的业务诉求,更好地服务于 AI 应用场景。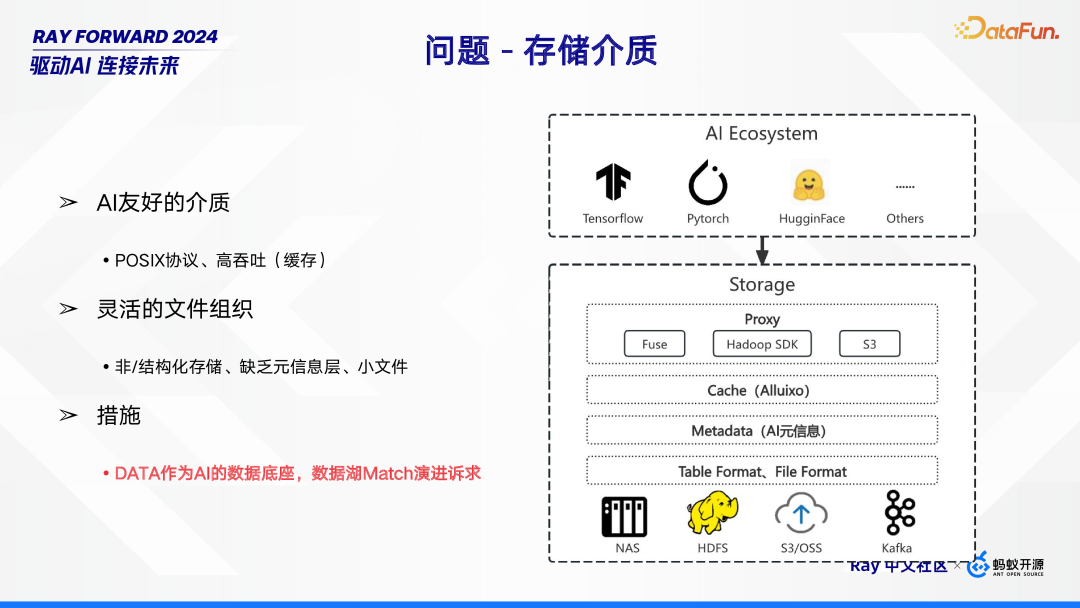
2. Ray 概述
Ray 主要包含 Core 和 AI Runtime 两大部分。在 Core 层面,它具备异构计算能力,能够实现 GPU 与 CPU 的协同工作,同时支持细粒度并行计算,将并行粒度细化到函数级。而 AI Runtime 则是面向 AI 链路,提供从一端到另一端的整套生态解决方案,为 AI 相关任务提供全面支持。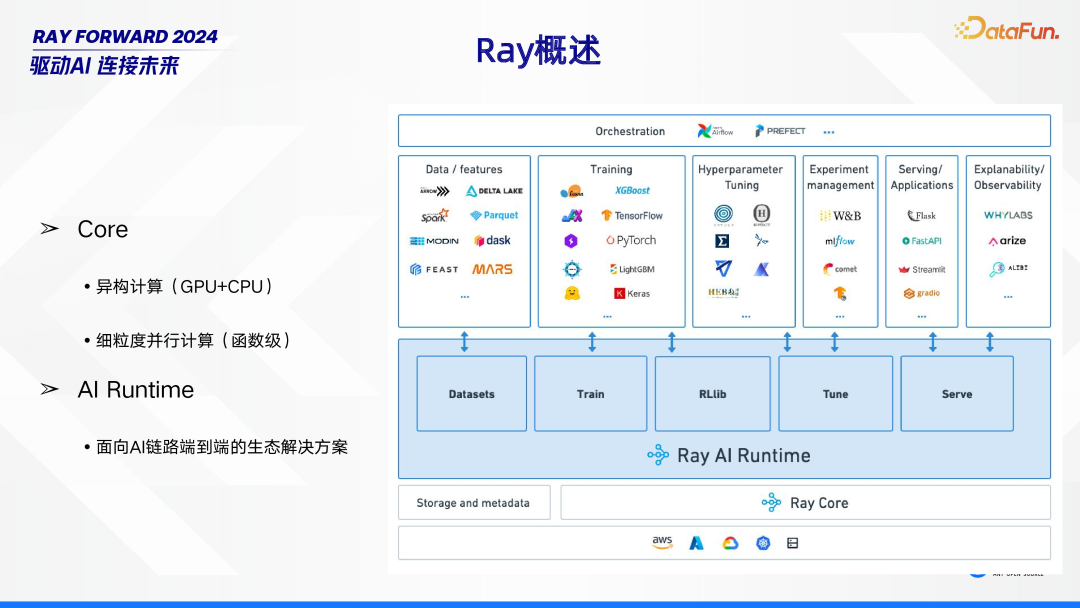
3. Ray 计算原语
在 Ray 的计算体系中,计算原语遵循“一切皆为 Actor、Task” 的理念,并且秉持“Python First” 原则,这使得其在开发过程中能紧密贴近算法开发,极大地方便了算法开发者。与之配套的状态存储,采用 Object Store(Plasma)来实现。此外,Global Control Service 扮演着重要角色,它负责存放 Actor、Task 的元信息,进而实现对整个计算过程的血缘管理,确保计算过程的可追溯性与有序性。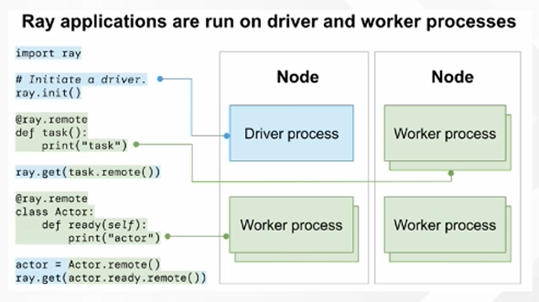
4. Iceberg 概述
Iceberg 是一种融合湖仓优势的解决方案。它具备湖仓一体特性,可实现统一存储,无论是非结构化数据、结构化数据还是元信息,都能整合存储。Iceberg 表格式更是功能强大,不仅支持 ACID 事务及版本控制,确保数据操作的一致性与可追溯性,还着重于元数据管理,有效应对 AI 数据管理难题。同时,它提供 TimeTravel 功能,凭借时间戳或版本号回溯数据,满足不同场景下的数据追溯需求。此外,通过优化数据组织与布局、增强索引等方式,实现高性能查询,为数据处理和分析提供有力支持。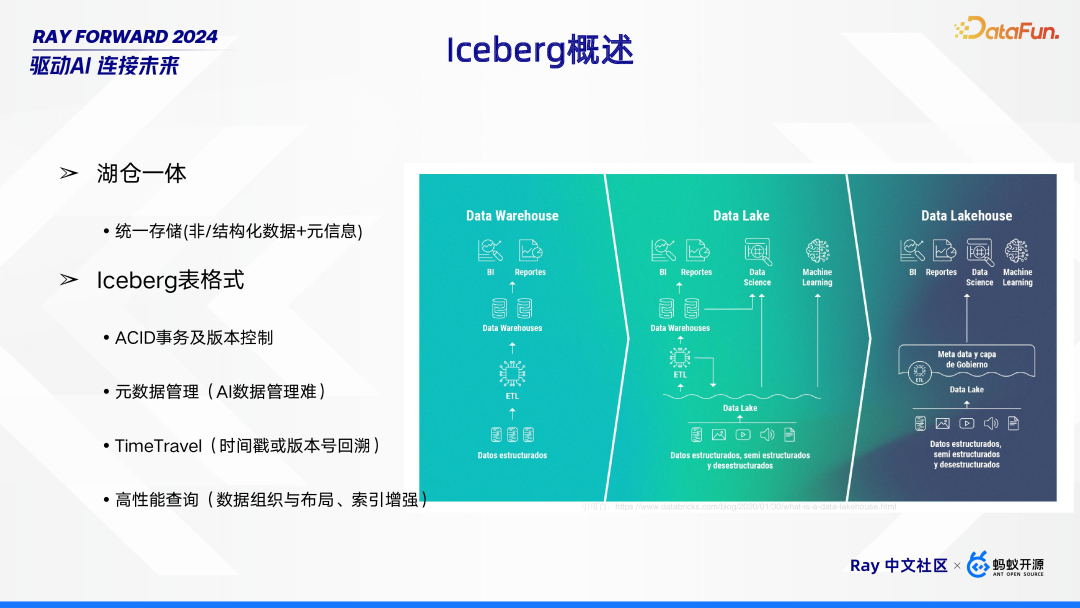
5. PyIceberg
Iceberg 针对 AI,做 PyIceberg 扩展,包含 DuckDB、pandas、daft、Ray 等等。
6. 整体架构
整体架构由接入层、任务编排、异构计算资源、资源管控、底层资源池构成。在接入层,采用标准化接入方式,涵盖 API、WorkFlow、event - driven 以及 Batch,确保各类数据与任务能顺利接入。任务编排环节,依托 Ray Data 完善 Source/Sink,并提供如分片、抽帧、OCR、ASR 等通用领域算子,实现任务的合理编排与处理。资源管控调度基于 K8s 多资源池,通过封装 Ray 的 Session 和 Job 模式,对异构计算资源和底层资源池进行有效管理与调度,保障系统的高效稳定运行。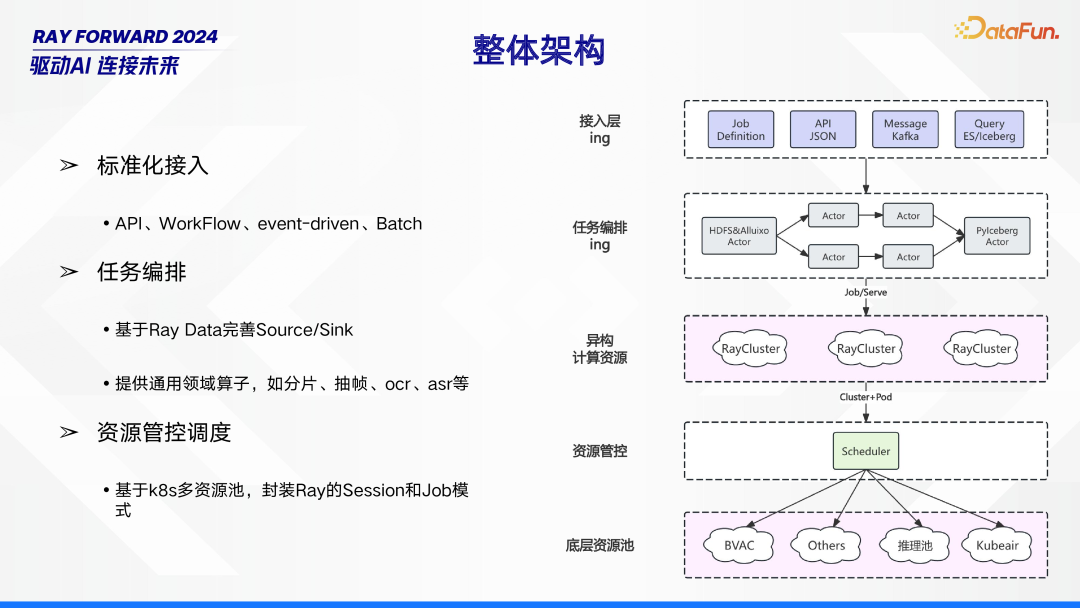
7. 典型计算范式
在典型计算范式中,针对多模态计算范式有着特定的处理流程。首先,借助 Iceberg 读取业务相关视频,这些视频的初步处理运行在配备 CPU 资源的 Ray Actor 中,通过读取 SQL 获取特定条件,进而对视频进行视频切片与抽帧操作。在此过程中,目录下的视频文件会进行装箱处理,并且支持断点处理,利用一个大小为 10G 的持久化队列来记录处理进度并保持实时更新。随后,配备 GPU 资源的 Ray Actor 进一步对相关信息(message)进行处理,具体包括对视频切片开展推理、生成 caption,对图片执行 OCR、进行美学评分等操作。之后,执行结果信息会被推送给配备 CPU 资源的 Ray Actor,由其汇总每个视频的标注数据,这些数据涵盖 OCR、评分、caption 等内容,最后将其持久化写入 Iceberg。
此外,该计算范式还包含不同的服务模式。其中,Serve 用于业务服务化,通过对外暴露 API 实现接入;Per - Job 模式下,一个 Job 对应一个 Cluster,既可以运行流处理任务,也能运行批处理任务;而 Multi - Job 模式则是多个 Job 共用一个 Cluster,以此实现资源的复用与预热(warmup)。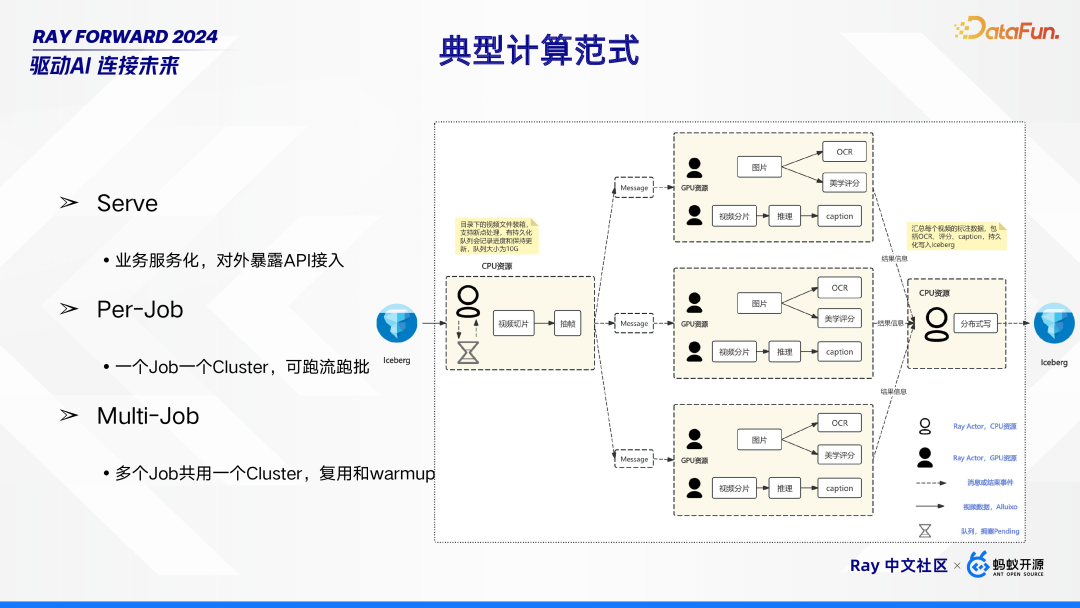
8. 针对 Ray 落地关键点问题处理
下面介绍 Ray 落地过程中,对存储结构、任务并行、Batch 推理关键点的处理。在存储结构方面,包含多个重要部分。首先是查询检索,通过基于索引的方式实现对数据集的高效检索。同时,借助 Iceberg 表与 Alluxio 的联动,达成预热加速效果,进一步提升检索效率。其次是特征列,依据不同场景,会产出不同维度的特征数据,这些数据将按列写入存储系统。再者是小文件处理,诸如 Clip/Frame、向量文件等小文件,会被存储到 Column Chunk 中,以此优化小文件的存储管理。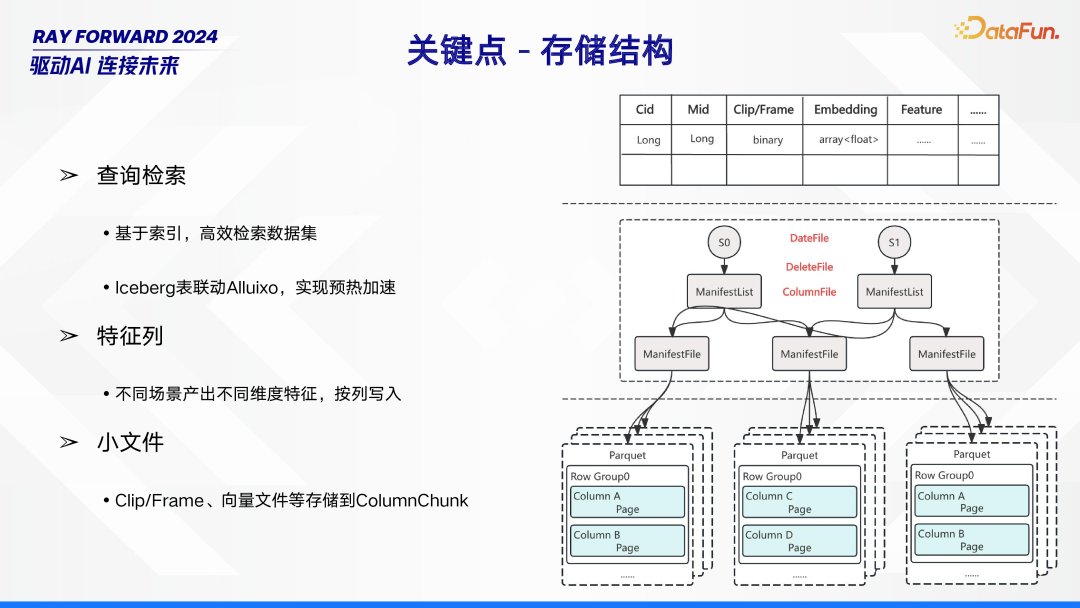
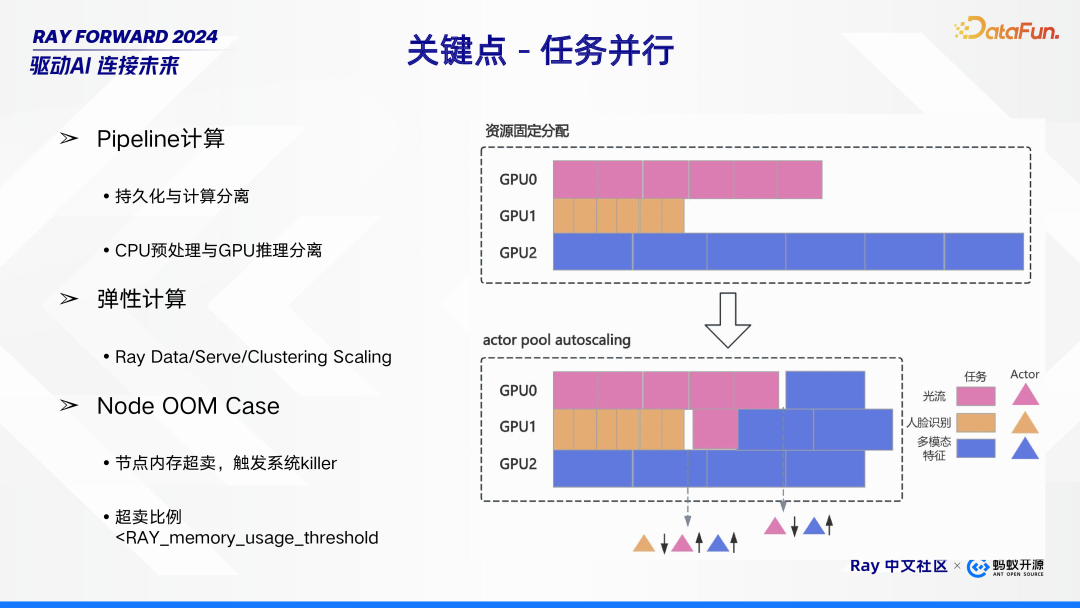
在任务并行处理方面,主要涉及以下几个关键特性。首先是 Pipeline 计算,它将持久化与计算进行分离,同时把 CPU 预处理和 GPU 推理也分离开来,这种方式有助于提高任务处理的效率与灵活性。其次是弹性计算,借助 Ray Data、Serve 以及 Clustering Scaling 等技术,系统能够根据任务需求动态调整资源,实现高效的资源利用。此外,还需关注 Node OOM Case(节点内存超卖情况),当节点出现内存超卖时,会触发系统 killer。这里存在一个超卖比例,该比例需小于 RAY_memory_usage_threshold,以此维持系统的稳定性与可靠性。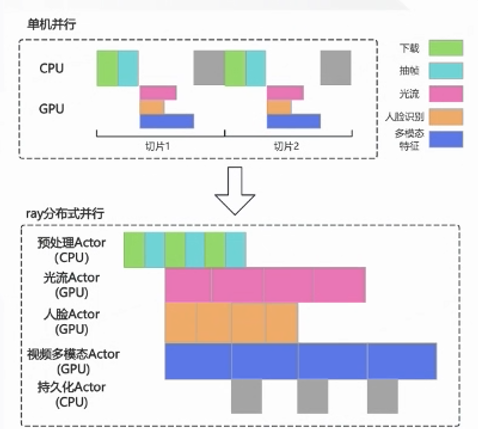
在 Batch 推理方面,推理效率至关重要。实现高效推理主要依赖几个方面:一是 Batch 均衡化,确保数据批次的合理分配;二是减少 Infer 次数,避免不必要的推理操作;通过这两项举措,能够使 GPU 利用率得到均衡且显著的提升,从而整体上提高 Batch 推理的效率。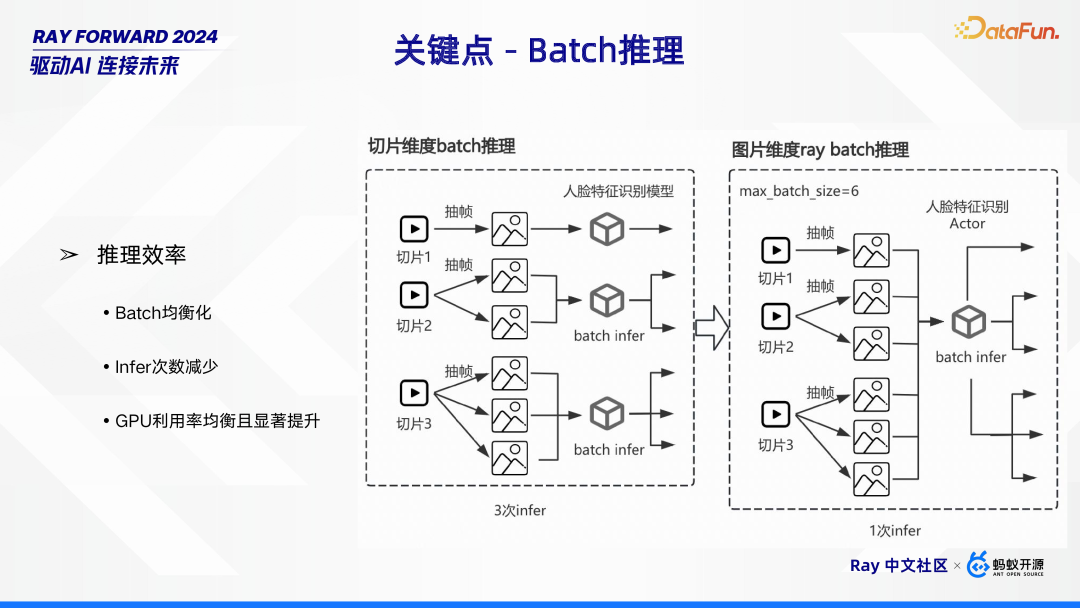
9. 整体收益
整体来看,该方案带来了多方面收益。在开发效率层面,实现了面向算法的 DATA + AI 技术栈闭环,为算法开发提供了更完整、高效的环境,极大地提升了开发效率。在视频标注场景中,成效更为显著:任务吞吐从每小时 4.7 万提升至 18.29 万,提升幅度明显;GPU 利用率也从平均每日 16.9% 跃升至 75.4% ,资源利用效率大幅提高,有力地证明了方案在实际应用中的卓越价值。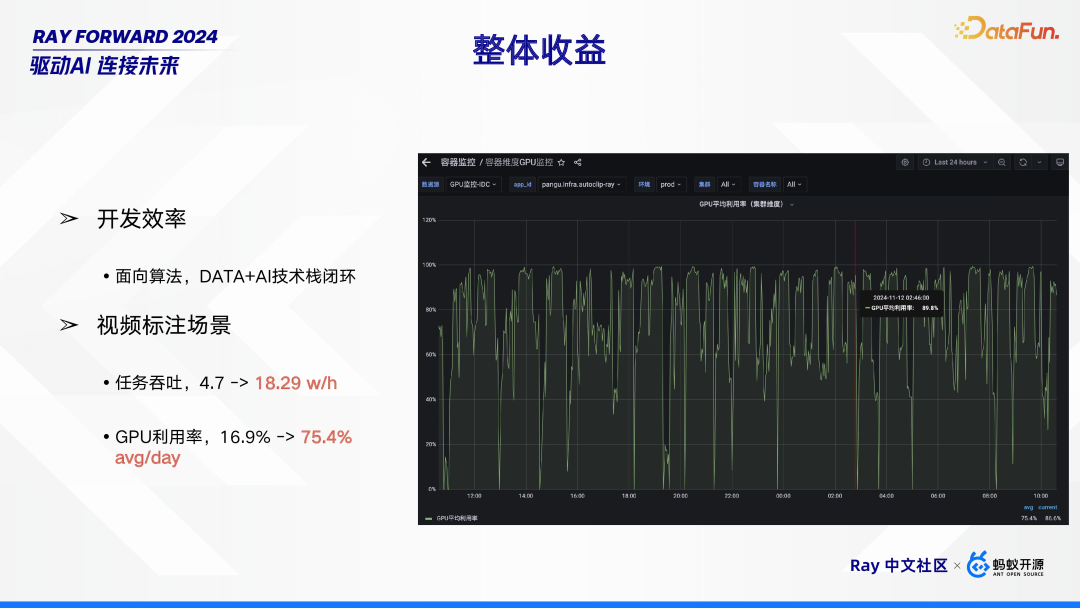
核心挑战
接下来介绍面向 Ray 底层遇到的一些问题以及相关的思考和解决方案。1. 集群级容错
在集群级容错方面,主要围绕核心场景多集群展开工作。针对核心场景中的多个集群,采用共享 Redis 的方式,并在其中注册不同的 Namespace,以此来实现各集群间的有序管理。同时,对 SDK 进行扩展,扩展后的 SDK 能够从 Redis 获取多集群信息,进而连接多个 GCS(Global Control Service,全局控制服务
)。在 Job 提交过程中,实现基于 Pending Job(待处理任务)数量以及剩余资源情况的负载均衡,确保资源的合理分配与高效利用。此外,当单集群出现 Failed(故障)或者下线的情况时,系统能够自动进行摘流,并将任务 Failover(故障转移)到另一套集群,以此保障整个系统的稳定运行,提升容错能力。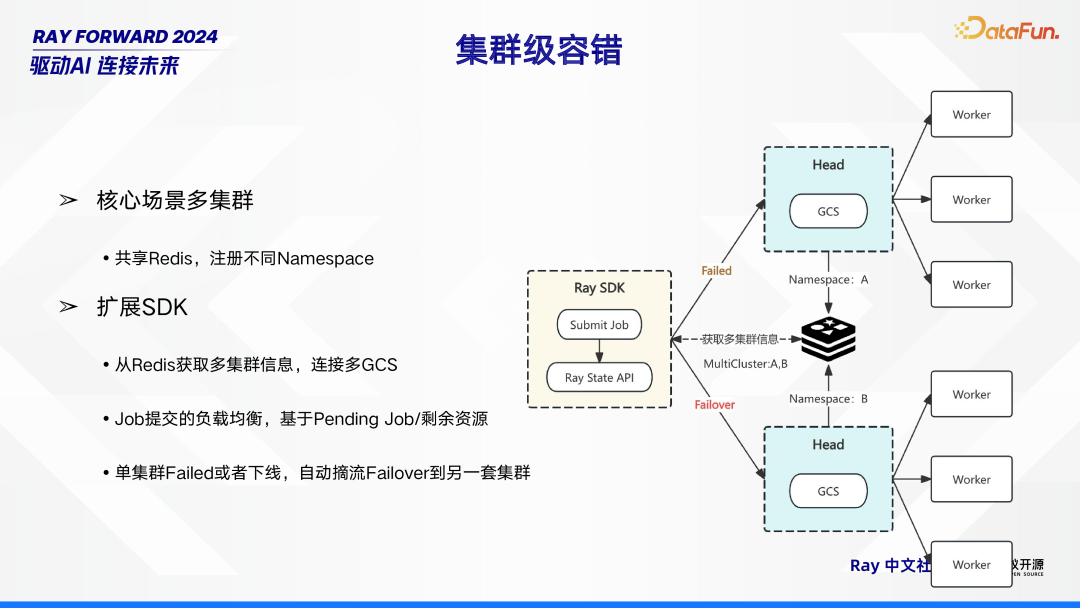
2. 异构资源管理
异构资源管理面临诸多挑战,尤其是在多异构 GPU 场景下。其中一大难点在于,K8s 的 ResourceQuota 采用固定资源分配方式,导致资源利用率较低。为解决此问题,可借鉴 Yarn Capacity Scheduler 的策略。通过构建资源树多层级 Node,将其与多种异构资源 Quota 相关联,不仅支持资源的 Borrow(借用)、Preempt(抢占),还具备多策略的降级和升级功能,从而提升资源的动态管理能力。
在作业提交环节,涉及到 Worker 的相关操作。目前 RayJob 的适配方式尚在探讨中,例如是采用 Kuberay,还是 RayJob Yaml 方式。无论采用何种方式,都需支持多集群、多作业类型,并能将不同的 Job 描述进行封装,提交到 k8s 平台,以实现异构资源管理下作业的高效提交与执行。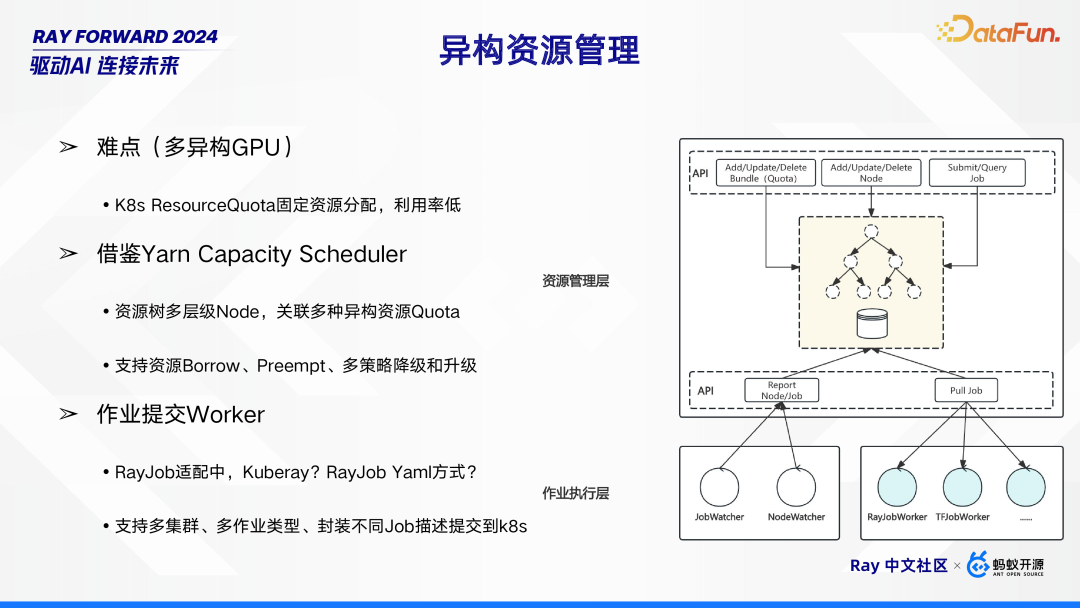
3. Autoscaler 扩展
在 Autoscaler 扩展方面,主要采取了两项关键举措。其一为引入混部资源,这种方式以 Pod 粒度进行资源申请,并通过自定义 Node Provider 来实现对资源的灵活调配。其二是采用 KubeAirNodeProvider,它依据资源状态来动态调整集群规模。当存在 Pending
resource(待处理资源请求)时,触发 Scale up(扩容)操作;而当 Node 处于 Idle(空闲)状态时,则执行 Scale down(缩容)。同时,还可对 Scale
min/max pod(最小 / 最大 Pod 数量)、scale speed(伸缩速度)以及 Idle
timeout(空闲超时时间)等参数进行设置,从而精准地控制集群资源的动态调整,以满足不同业务场景下的资源需求。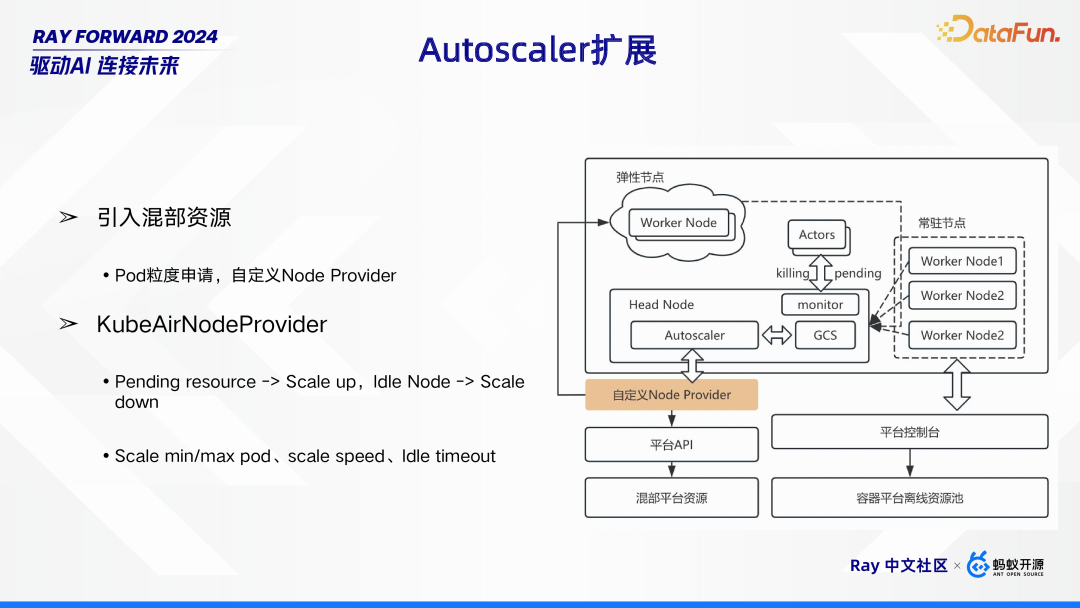
4. GCS 优化
GCS(全局控制服务)优化成为亟待解决的问题,主要源于元信息膨胀现象。当集群运行一段时间后,作业提交速度明显变慢,甚至出现异常情况,同时 Dashboard 下的 list job、actor 等接口也会响应超时。
经过深入的问题剖析,发现 GCS 承受着巨大压力,响应耗时居高不下,问题根源定位在 Redis 查询环节。进一步深入挖掘得知,Redis key 数量增长近 100 万,使得 HScan 操作压力剧增。
为解决这一问题,制定了元信息清理机制。一方面,扩展 Job
Head,在 API 层引入对 JobInfo 的清理功能;另一方面,对 GCS 的 Worker 和 Job Manager 进行扩展,引入 Max 清理机制,以此来缓解 GCS 压力,提升系统整体性能。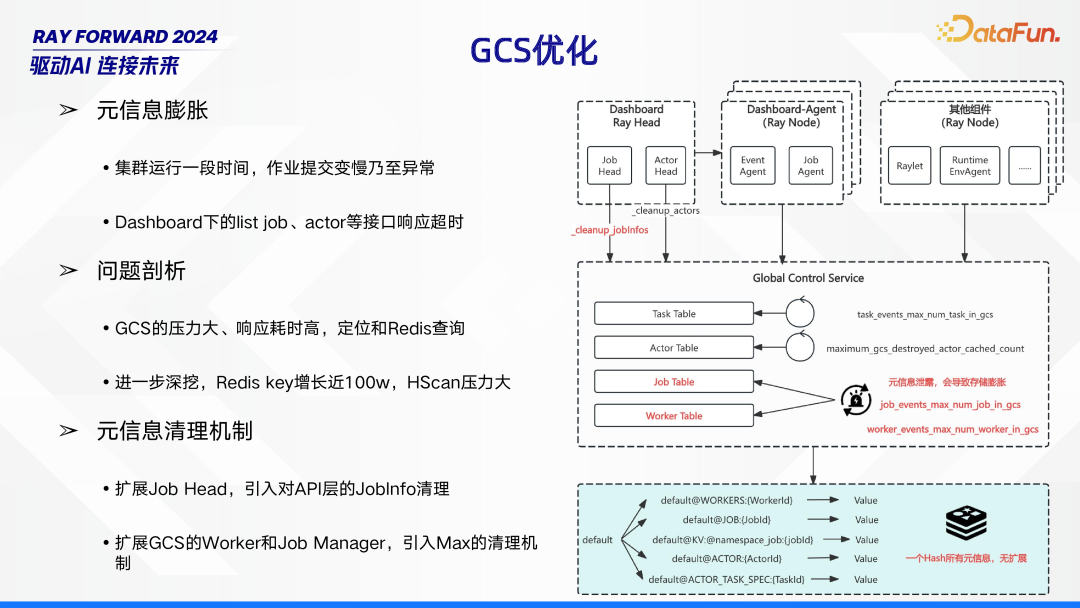
5. Ray Data - SQL 单机
在 Ray Data - SQL 单机场景下,其具备独特的能力与特点。就 SQL 能力而言,主要应用于视频处理,此前该链路采用 Spark SQL。其中,元信息表规模通常不大,而核心处理任务聚焦在视频数据上。为进一步优化,Ray Data 进行了扩展,基于 DataSource 引入了 read_iceberg_sql 功能。不过,该模式也有其适用场景限制,由于底层采用的 DuckDB 为单机计算引擎,并不适合分布式查询。所以,通常会先利用 Filter 对分区进行过滤,之后再借助 SQL 完成针对视频计算的信息检索工作。
6. Ray Data - 分布式写 Iceberg
在 Ray Data - 分布式写 Iceberg 过程中,面临着一些问题。一方面,Ray 本身不支持写 Iceberg;另一方面,PyIceberg 也不支持分布式写操作。为解决这些问题,进行了多方面的扩展。在 Ray
Data 方面,基于 Datasink 接口,创新性地引入了 Iceberg
Data Sink。其采用两阶段操作,首先将数据写入 Parquet 文件,之后再 Commit 元信息,若操作过程中出现异常,则会自动清理文件。同时,对 PyIceberg 也进行了扩展,引入两阶段提交机制,使其支持元信息的 Commit 提交,并生成 Snapshot,以此实现 Ray
Data - 分布式写 Iceberg 的功能。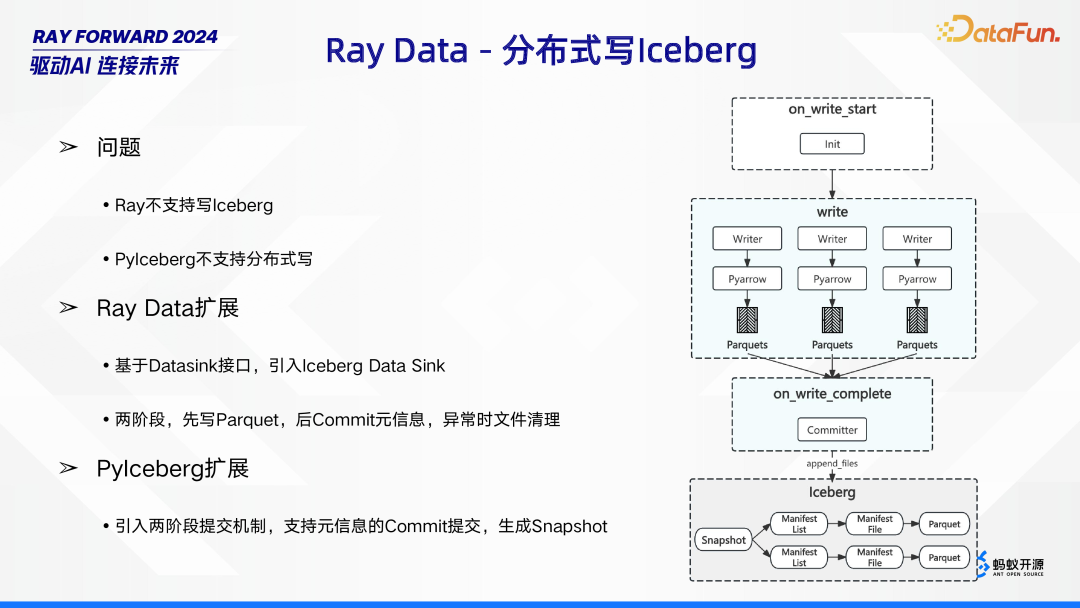
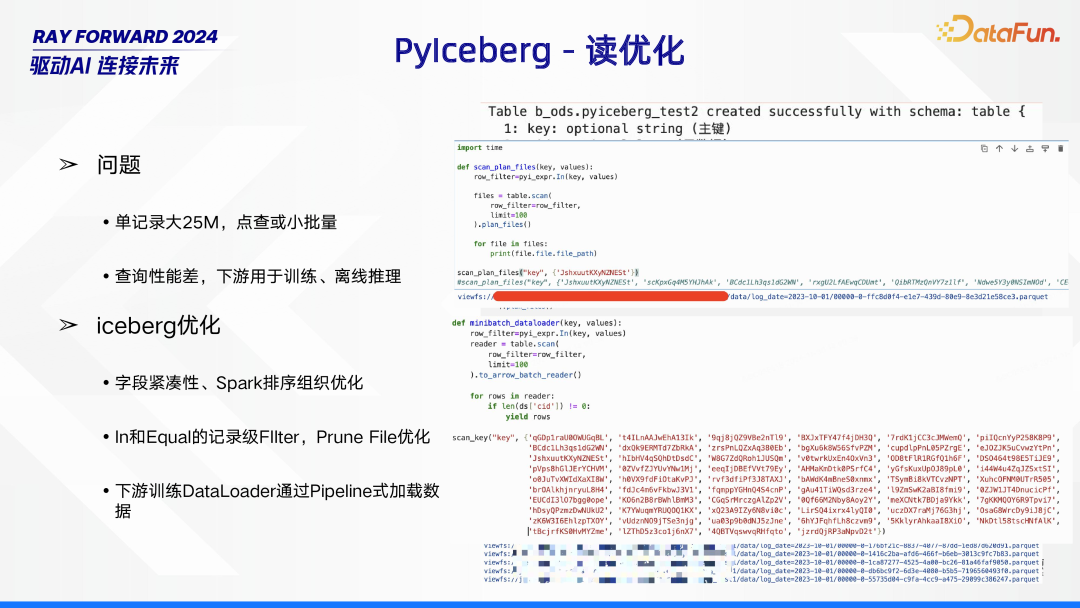
7. PyIceberg - 读优化
在 PyIceberg 的读操作中存在一些问题。当单条记录大小达到 25M,且执行点查或小批量查询时,查询性能较差,而这些数据下游又常用于训练和离线推理,对性能要求较高。针对这些问题,进行了一系列 Iceberg 优化措施。首先,在数据存储结构上,通过字段紧凑性以及 Spark 排序组织优化,提升数据读取的基础效率;其次,在查询过滤方面,采用 In 和 Equal 的记录级 Filter,结合 Prune File 优化,减少不必要的数据读取;此外,针对下游训练,优化 DataLoader,采用 Pipeline 式加载数据,进一步提升数据读取性能,以满足训练和离线推理对数据读取性能的需求。
未来展望
1. 场景扩展及平台化
未来会提升 Ray 的运维管理能力,对内部应用的一些 AIR、Core、可观测三个维度进行增强。基于目前场景进一步扩展,基于 Ray 对 Agent RAG、训练场景等提供支撑。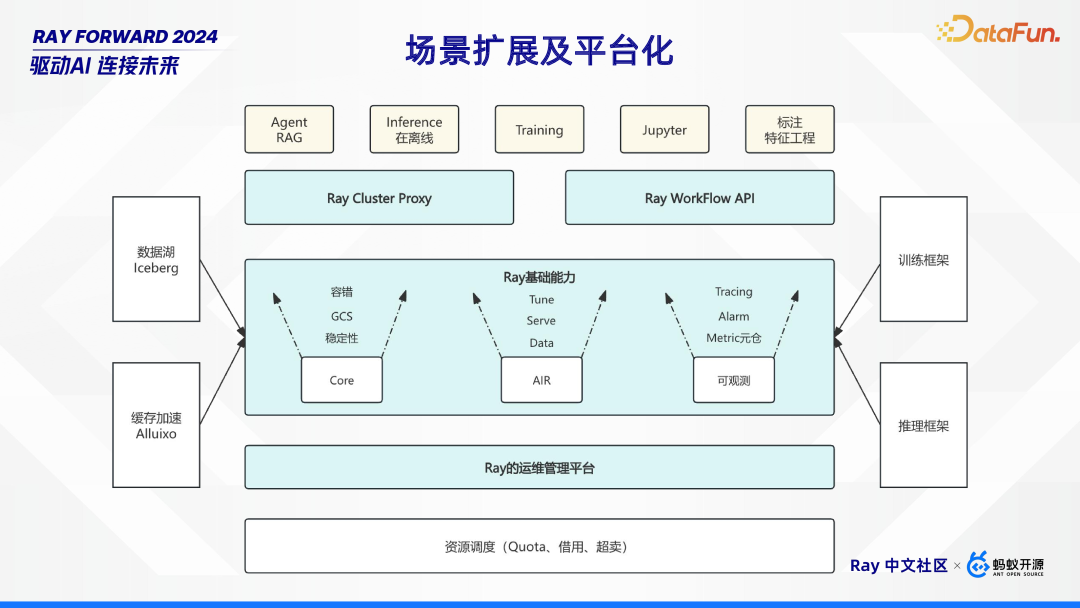
2. 底层能力增强
在底层能力方面,主要对以下几个关键领域进行增强。首先是 WorkFlow,通过提供 DAG 定义,帮助用户屏蔽开发 Job 和 Serve 的复杂细节,降低开发难度,提升工作效率。其次是流式计算,借助 Checkpoint 机制,实现 Exactly Once 语义,确保数据处理的准确性和一致性。同时,Ray 支持 Iceberg 的流读操作,能够依据指定的 Timestamp 或版本号进行快照读,为数据读取提供更多灵活性。此外,稳定性增强也是重点工作,通过采用 History
Server、多 Head HA 机制,以及针对 Actor/Task Failed 的容错处理,保障系统在运行过程中的可靠性,同时实现平滑升级,和多租户能力,进一步提升系统的整体稳定性和适用性,以满足不同场景下的多样化需求。
































 粤ICP备17114055号
粤ICP备17114055号
 支持私有化部署
支持私有化部署