推荐语
AI领域新突破,低成本高效率模型s1震撼登场。
核心内容:
1. 李飞飞团队以不到50美元成本训练出s1模型,性能匹敌OpenAI、DeepSeek等顶尖模型
2. s1基于阿里云通义千问小型AI模型,通过构建高质量小型数据集实现性能跃升
3. 研究揭示了高质量数据集、严格筛选标准对AI模型性能的重要性,为低成本AI研发提供新思路
杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
近日,AI领域又迎来一枚“深水炸弹”,斯坦福大学李飞飞团队联合华盛顿大学研究人员以不到50美元的云计算费用,成功训练出了一个名为s1的推理模型。
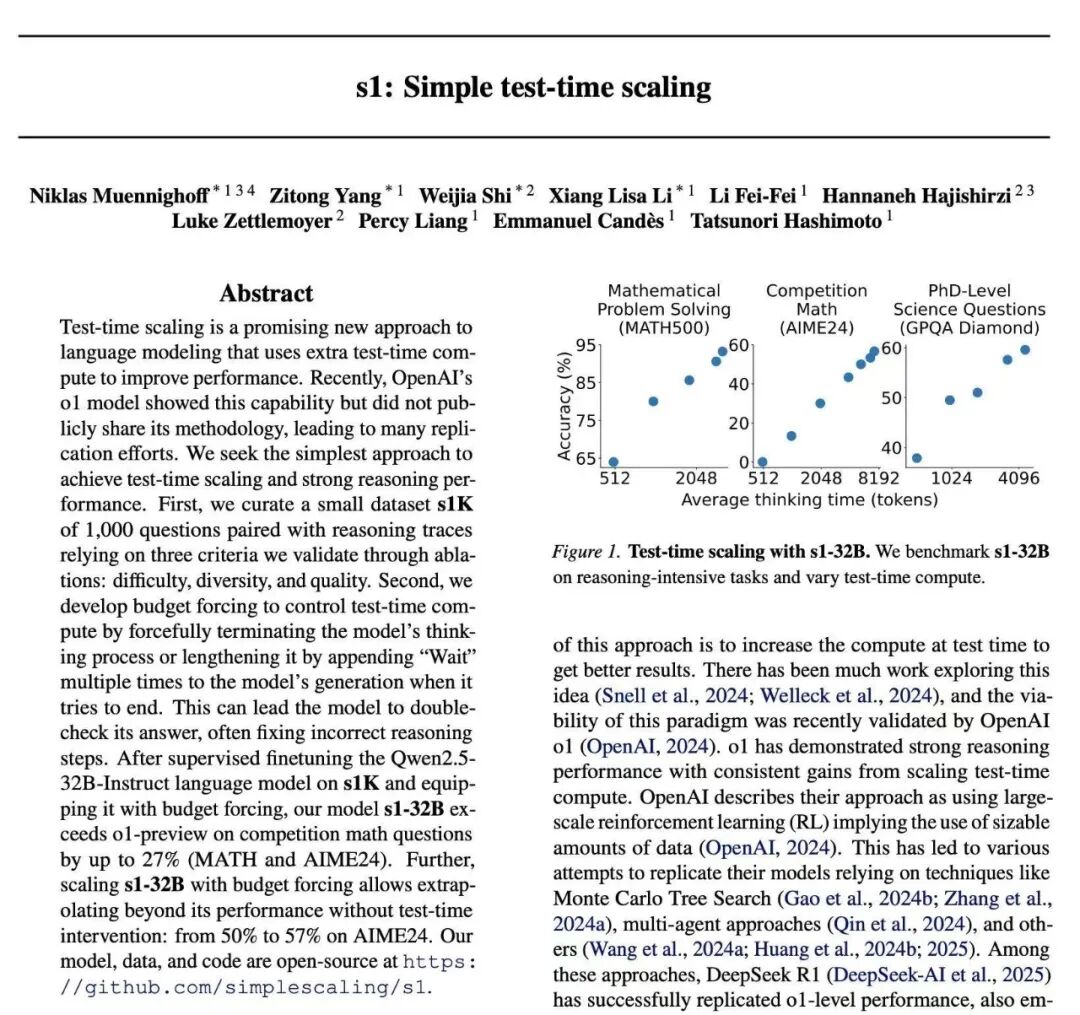
其数学与编码能力测试表现,与OpenAI的o1、DeepSeek的R1等模型不相上下。根据研究团队的测试结果,在竞赛数学问题上,s1-32B的表现较o1-preview高27%(MATH和AIME24);且该模型在AIME24上的表现,几乎与Gemini 2.0 Thinking API相当。并且,s1模型已经在GitHub上发布,并附带了训练它所用的数据和代码。要知道,传统大模型的训练成本动辄数百万美元,而s1的“白菜价”,无疑是对现有研发模式的颠覆。这表明即使在极低的成本下,也能够训练出具有高度竞争力的AI模型。s1并非“从零开始”训练,而是基于阿里云通义千问(Qwen)的一款小型现成AI模型,这意味着,s1的“低成本”是建立在已具备强大能力的开源基础模型之上。根据研究论文,为了训练s1,研究人员首先构建了一个名为s1K的小型数据集,其中包含1000个高质量的推理问题。按照业内共识,这一数据量在AI训练中可谓微乎其微,通常不足以训练出一个具备推理能力的模型。但该数据集的筛选标准非常严格,必须同时满足难度高、多样性强、质量优良三个条件。研究团队通过详尽的消融实验,验证了这三个标准的重要性,结果表明,随机选择或仅关注单一标准都会导致性能大幅下降。通过这种“小而精”的策略,让s1在有限资源下实现了性能跃升。值得一提的是,即使使用包含5.9万个样本的超集进行训练,其效果也远不如精心挑选的1000个样本。然后再通过蒸馏法从谷歌的Gemini 2.0 Flash Thinking Experimental模型中提炼知识,也就是“思考”过程,最终“雕琢”出s1的推理能力。研究人员表示,蒸馏方法与伯克利研究人员上个月以约450美元创建AI推理模型的方式相同。训练过程中,研究人员表示,在使用16台Nvidia H100 GPU进行训练的不到30分钟时间里,s1在某些AI基准测试中表现出色。这种方法与传统的大规模强化学习方法(RL)形成鲜明对比,后者的成本通常较高,DeepSeek、OpenAl都采用了这种方法。并且,还有研究人员表示,他们如今只需约20美元就能租到所需的计算资源。此外,为了提高答案的准确度,研究团队还运用了一种“预算强制”技术,可以控制测试时间计算,通过强制提前终止模型的思考过程,或在s1的推理过程中加入“wait”一词帮助该模型得出略微更准确的答案。尽管s1模型的低成本训练在某种程度上展示了AI训练的潜力,但其局限性也不容忽视。首先是,其依赖于已有强大基座模型,如果没有基座模型,低成本训练的效果将大打折扣。其次是,在处理复杂任务时,1000个样本数据的训练量在大多数情况下是不够的。此外,还有分析人士质疑,如果任何人都可以轻易复制和超越现有的顶级模型,那么大型AI公司多年的研发投入和技术积累会不会受到威胁?而且,尽管蒸馏技术已被证明是以低成本重新创建AI模型能力的有效方法,但它并不能创造出远超现有模型的新AI。
与DeepSeek对比,s1虽然在MATH测试中比GPT-4o高27%,接近Gemini 2.0,但仅限于特定题型。 DeepSeek R1则覆盖更广泛数学场景(如金融建模、工程计算),通用性更强。在HUMANEVAL测试中,s1达75%通过率(接近GPT-4水平),但其还是依赖基座模型Qwen的代码能力; DeepSeek R1内置代码解释器,支持多语言混合编程,长上下文处理更稳定。虽然s1通过“小数据高精度蒸馏”实现超低成本,但依赖已有基座模型(Qwen)和外部大模型(Gemini)的知识迁移;而DeepSeek R1采用全自研技术链,虽成本高,但具备独立迭代能力,无需外部依赖。正如此前,OpenAl就曾指控DeepSeek不当使用其API数据进行蒸馏。尽管s1模型的低成本训练引发了争议,但其背后的研究思路无疑为AI领域提供了新的思考方向。小数据+强蒸馏让中小团队也可突破算力壁垒,参与 AI军备竞赛,并且,完整公开的训练链路或催生更多低成本垂直模型。

































 粤ICP备17114055号
粤ICP备17114055号