推荐语
深度分析DeepSeek-R1 API端稳定性测试结果,了解各平台性能差异。
核心内容:
1. DeepSeek-R1 API稳定性测评背景及方法
2. 各第三方平台回复率、输出效率对比
3. 准确率差异及应用场景建议
杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
为了给用户提供更全面、客观的参考,并帮助他们选择合适的服务平台,我们在7个服务平台上进行了DeepSeek-R1的API稳定性测评,从回复率、准确率和推理耗时等方面评估其表现。本次测评在同一机器上对第三方平台发送请求,使用20道小学奥数推理题测试,temperature为0.6,max_token设为平台最大值或16000,采用流式输出方式记录耗时及输出token数量。每题尝试三次避免网络影响,三次失败视为获取失败。本次测评的报告仅代表测评时点的稳定性。此前,我们还测评了支持DeepSeek-R1的第三方网页端,并整理了详细报告,详见《DeepSeek-R1 稳定性报告:18 家网页端测评》;以及针对App端的测评,见:DeepSeek-R1第三方稳定性测试(App端):首批结果出炉!后续计划对该类平台,包括API(本次测评之外的第三方平台API)、APP、本地部署版本等进行跟进测评。以下为详细测评报告。排行榜地址:www.SuperCLUEai.com
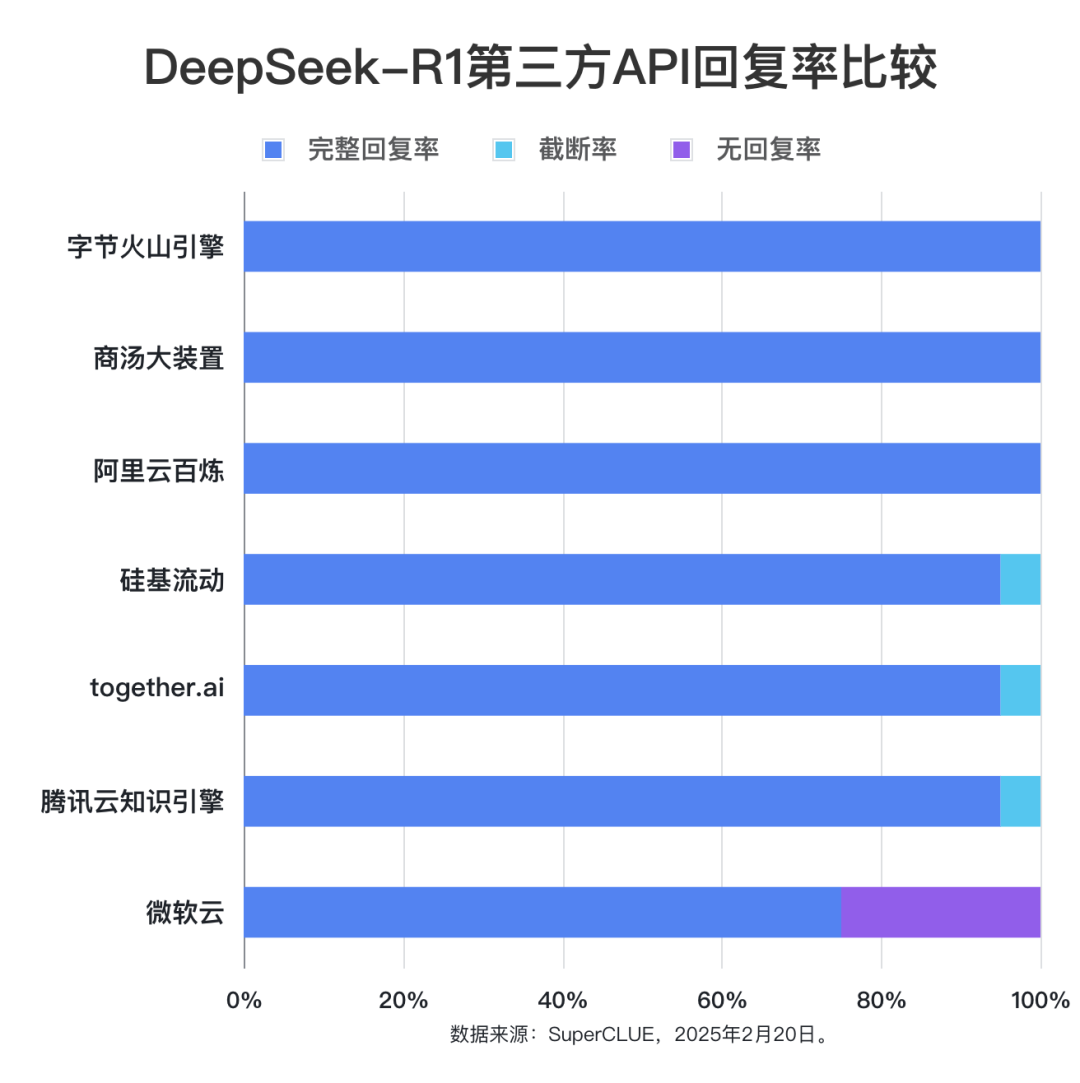
测评要点1:各个第三方平台使用DeepSeek-R1的完整回复率表现差异不大
除微软云的DeepSeek-R1 API外,其他的完整回复率都在95%以上。火山引擎、商汤大装置、阿里云百炼都实现了100%的完整回复率。测评要点2:各第三方API接口输出效率差距明显,平均每秒输出token数量最低6.9个,最高55.86个。
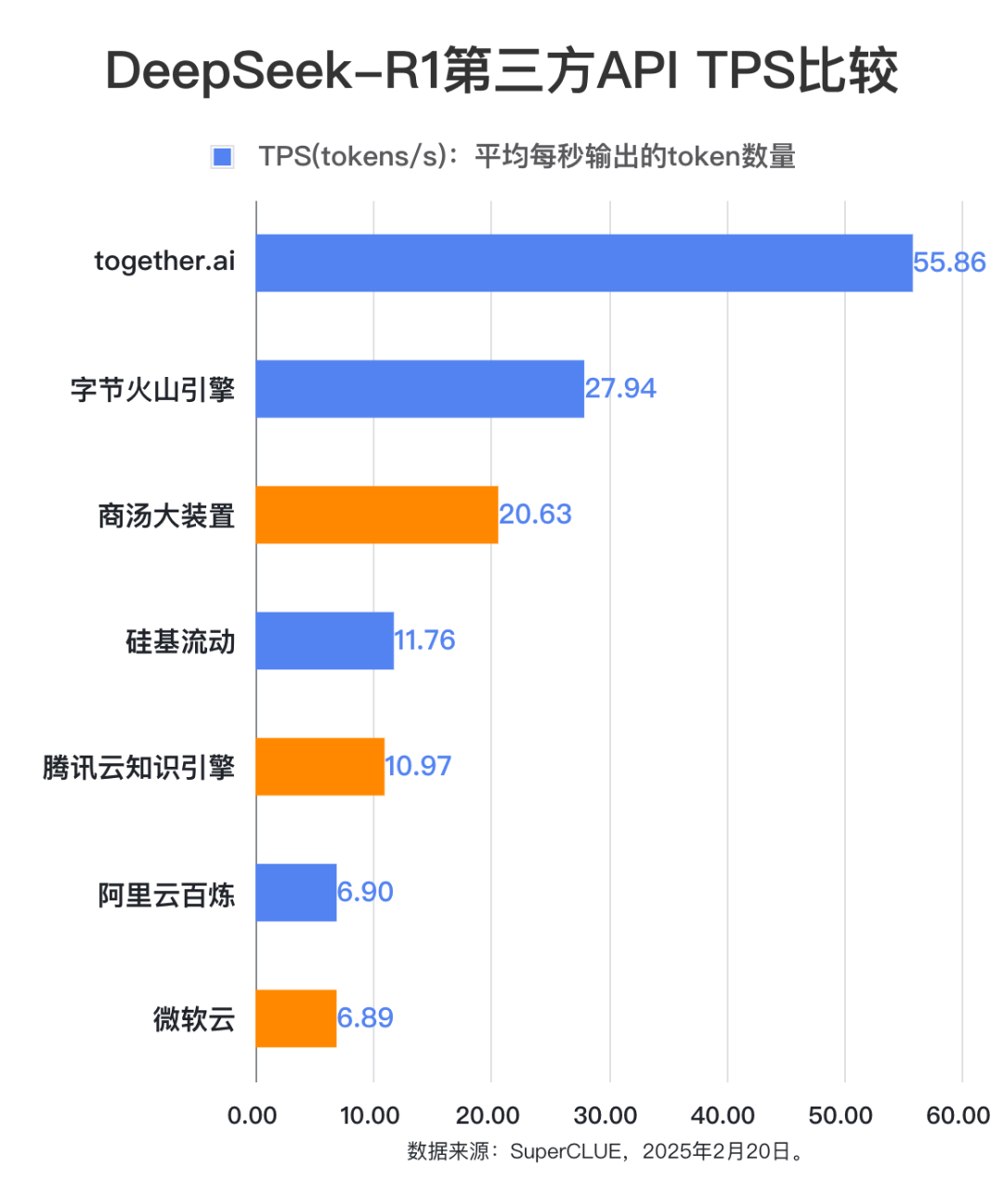
测评显示,第三方API每秒输出token数量差异大。Together.ai以每秒55.86个token遥遥领先,文本生成效率极高;字节火山引擎次之,每秒27.94个token;阿里云百炼和微软云API则仅为每秒6.90个token。高并发或快速响应应用,宜选高生成效率平台。准确率上,字节火山引擎、硅基流动,准确率为95%左右;商汤大装置准确率在90%;阿里云百炼准确率为70%。# 榜单概览
- 完整回复率:模型给出完整回复,不存在截断、无响应等问题,但不考虑答案正确与否;再除以总题目数得出比例。
- 截断率:模型在回复过程中出现断开的情况,未给出完整的答案;前者再除以总题目数得出比例。
- 无回复率:模型由于特殊原因,如无响应/请求出错,未给出答案;前者再除以总题目数得出比例。
- 准确率:对于模型给出完整回复的题目,模型的答案与正确答案一致的比例;正确答案,只看最终答案,不检查解题过程。
说明:文本token数量的计算方法,采用deepseek-r1开源的tokenizer对文本进行分词,将文本划分为独立的多个token,进而计算token数量。# 测评方法
本次测评在同一机器上对第三方平台发送请求,使用20道小学奥数题测试,temperature为0.6,max_token设为平台最大值或16000,采用流式输出方式记录耗时及输出token数量。每题尝试三次避免网络影响,三次失败视为获取失败。1.对于每个第三方平台,使用20道小学奥数题进行统一测试。为了避免网络波动造成的影响,每个模型对每个问题会尝试三次,如果三次尝试都未获取到答案,才视为获取失败。并且将测试时间设为下午开始,主要模型完成时间在工作日下午15:30-20:30之间。2.由于测评集为推理题,输出较长,对于max_token的设置遵循以下原则:如果平台文档说明了支持的最大输出的token,我们将max_token按照平台的最大输出token进行设置;如果平台未说明,max_token统一设置为16000。对于影响生成质量的参数配置,调用时对于允许配置temperature的第三方api,我们统一采取DeepSeek的推荐参数值:0.6,其他参数保持各第三方平台默认不做配置。3.关于推理耗时的统计方法,API的调用统一采用流式输出(调用时,将stream参数设置为True)。开始发送请求时间记录为start_time, 请求开始返回数据时,记录时间chunk_time1; 返回数据结束后,记录时间chunk_time2。每道题目的输出token数量记录为:completion_tokens;# 测评结果
(3)推理耗时
这里对几个关键的推理性能指标做说明:
- Latency:从用户提供一个问题输入到模型返回最终输出的耗时(未获取到的除外)
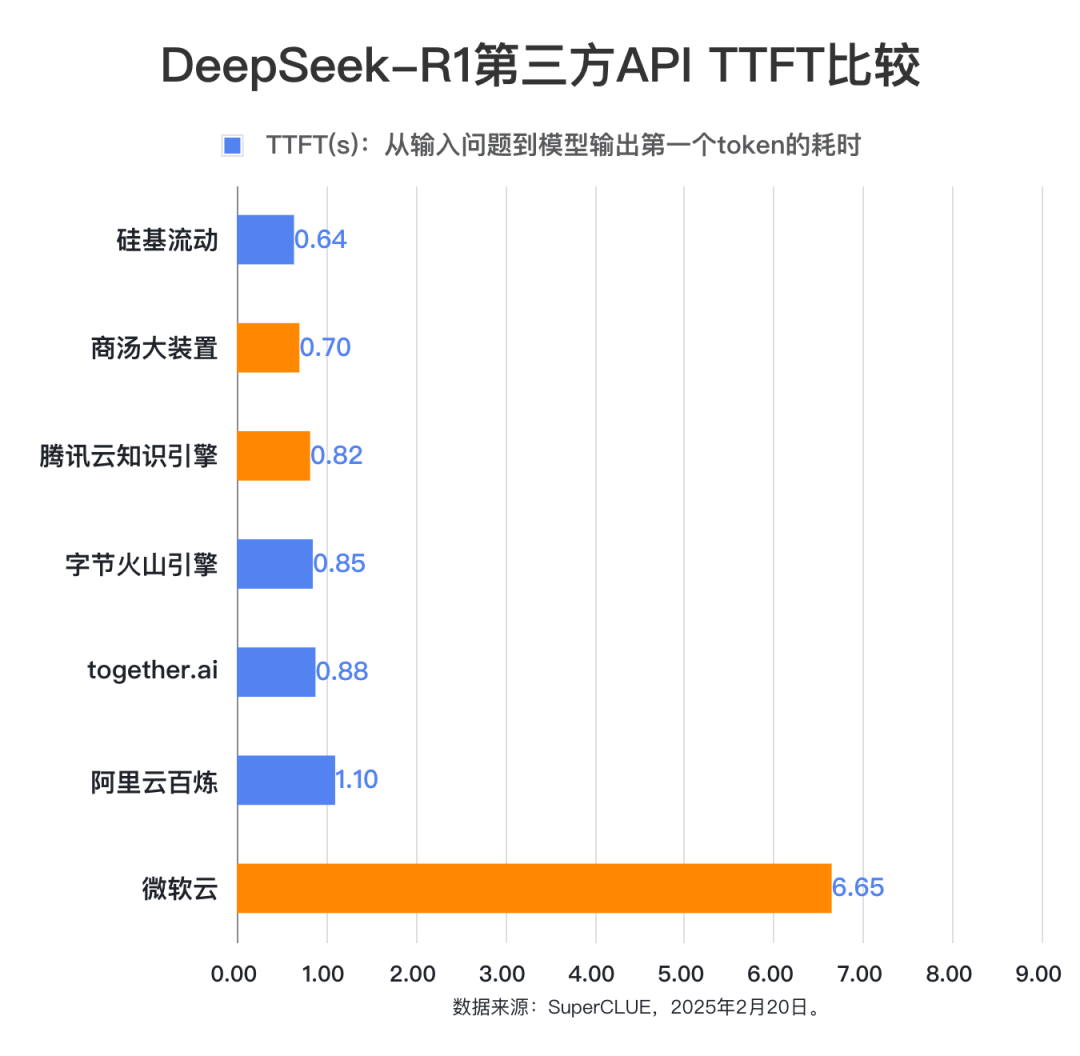
- TTFT:首token输出延迟。首token输出延迟,指从输入问题到模型输出第一个token的耗时。
TPS:平均每秒输出的token数量
获取答案的平均耗时:所有题目“Latency”取平均值即为获取答案的平均耗时。
首token输出平均耗时:所有题目的“TTFT”取平均值即为首token输出平均耗时。
每秒输出token数量:本次测评中,模型平均每秒生成的token的数量。
题目:一只青蛙早上6点从深为10米的井底向上爬,它每向上爬2米,因为井壁打滑,就会下滑0.5米、下滑 0.5米的时间是向上爬2米所用时间的二分之一。6点 12 分时,青蛙爬至离井口 2.5米处,那么青蛙从井底爬到井口时所花的时间总共多少分钟?
标准答案:15.2 分钟(即15 分钟 12 秒)参考答案(来自模型:Gemini-2.0-Flash-Exp):1. 第三方平台提供的deepseek-r1的API稳定性较高,但在回答问题的准确率上可能有所差异。根据稳定性评估结果,在本批次测评第三方平台中,除了微软云的完整回复率为75%,其他第三方API都在95%及以上。在已经获取到答案的数据中只发现少数题目截断的现象,并且统计数据显示并未超过调用时设置的最大max_token,属于模型本身出现的问题。根据回答准确率数据结果,表现最差的模型准确率为70%(20道问题答对14道),而表现最好的模型为95%(20道问题答对19道)。因为本次测试的题目数量有限,我们仅就数据进行说明,不代表对第三方平台的deepseek-r1服务能力强弱的意见。对于准确率的差异,可能是因为模型部署的环境和配置不同引起,也可能与题目本身具有较高难度并评估准确率较为严格相关,即只看最终答案是否正确。
2. 在推理速度方面,各平台之间输出效率的差异较大,每秒输出token数量最多的可达55.86个,最少的只有6.90个。
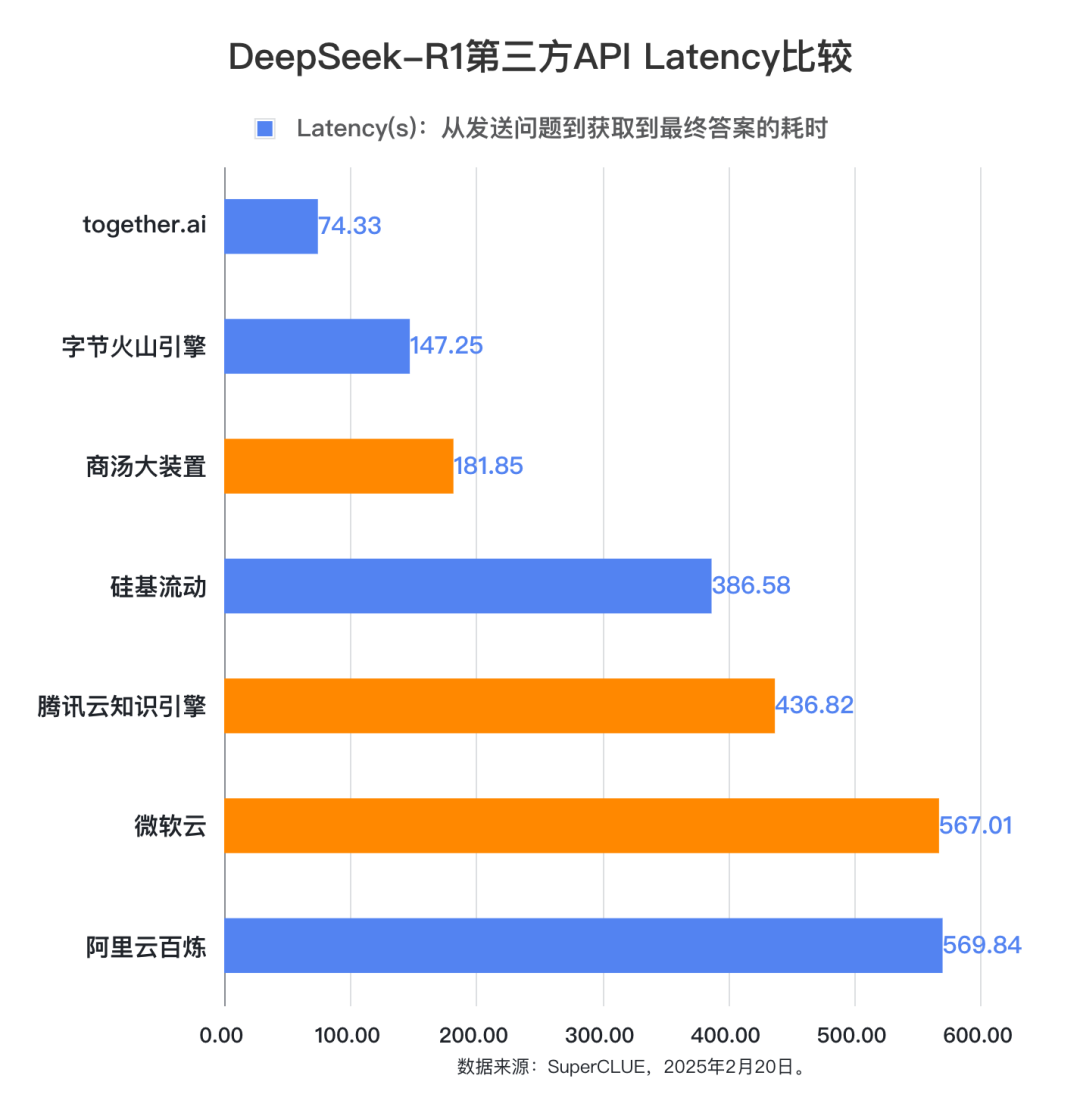
根据统计数据,本次测评的第三方API每秒输出token数量有明显的差距,Together.ai性能最优,平均每秒可输出55.86个token,显示出极高的文本生成效率,第二名字节火山引擎每秒可输出27.94个token,而阿里云百炼和微软云提供的api每秒只有6.90个token输出。针对回答的平均耗时(Latency)来看,本次测评的第三方DeepSeek-R1 API中,排名前三的是together.ai(74.33秒)、字节火山引擎(147.25秒)和商汤大装置(181.85秒),其中together.ai和火山引擎属于付费使用,商汤大装置属于免费使用阶段。首token输出延迟时间(TTFT)上看,平均延迟最小的三家分别是:硅基流动(0.64秒)、商汤大装置(0.70秒)和腾讯云知识引擎(0.82秒)。可以看到在各项指标中,性能最佳的都是付费平台。其中together.ai在答题的平均耗时(Latency)和每秒输出token数量(TPS)指标上领先较大,但同时其标价也最高,平台标价每百万token输入需要3美元(折合人民币21元左右),每百万token输出要7美元(测试时,折合人民币50元左右)。而对应的字节火山引擎的表现虽然比together.ai要逊色,但是价格方面却要低很多(测试时处于半价优惠期,只需要百万输入token:2元,百万输出token:8元)。硅基流动在首token延迟方面表现最佳。限时免费平台中,商汤大装置在Latency、TTFT和TPS三项指标上都表现不错,腾讯云知识引擎在TTFT上取得不错的性能表现。总体来说,在本次测评期间,付费平台的速度性能表现更佳,免费的平台性能会逊色一些。各平台的性能表现可能原因包括:1.免费的资源有限的,提供的计算能力有限;2.免费或赠送免费token,可能会引入更多用户使用,导致服务器压力过大;3.部署的环境和机器配置不同。
3. 价格方面,多家平台处于限时免费阶段,付费平台也各有优惠策略,用户的体验成本较低。根据我们统计的第三方平台的收费情况,本次测评的第三方平台中有多家仍处于免费阶段。比如:商汤、腾讯云知识引擎等,但可能有自己的访问速率限制要严格一些;收费的平台中,也各自推出了优惠策略,比如:阿里云、火山引擎对新开通deepseek-r1调用服务的用户,提供免费token,并且阿里云和火山引擎都有自己的限时半价服务。目前各平台也在逐步增加资源,并且逐步过渡到正常收费阶段,根据各第三方平台网站公布的收费计划,多家平台正常收费后价格可能不高于deepseek官方。# 结论和建议
1. 不同第三方平台在部署的Deepseek-R1 服务API稳定性差异不大,但在速度和答题的准确率上可能有所差别。TTFT和TPS都是需要考虑的指标。TTFT,代表用户感知到的模型开始输出的时间,对于搭建实时聊天类应用比较重要,越小越好;TPS,代表每秒输出的tokens数量。相同的输入下,每秒输出的token数量越多代表生成的速度更快,在实际应用中能够处理更多的任务。但具体的并发数量和访问tokens数量限制上限,还需要参考第三方平台给出的速率限制。
2. 数据显示,付费平台中,国外的together.ai和国内的字节火山引擎的推理速度方面表现最佳,如果优先考虑推理速度,愿意付出成本可以优先从这两家中选择;限时免费平台中,商汤大装置平台的回复延迟和每秒输出的tokens数量上表现都不错,并且免费时间持续到2025年5月9日,如果想要免费体验DeepSeek-R1的用户推荐选择商汤大装置平台API。3. 统计数据显示,在本次测试中,模型的回复出现了输出长度(包含思维链推理过程和最终输出的长度)在10k以上甚至24k的情况,虽然针对本批测试题目来说是属于极少数情况,但在实际的应用场景仍然可能出现。各家平台对max_tokens定义可能不同,可能会包含思维链推理过程的长度,因此,建议在调用API时尽量将max_tokens参数设置为允许的最大长度,避免因参数设置导致的截断问题。4. 需要注意的是本次测试在单并发下调用,针对小学奥数类问题。如果需要应用到多并发场景或其他不同场景,建议进一步对各平台进行测试比较,TTFT和TPS等指标都可能发生变化。

































 粤ICP备17114055号
粤ICP备17114055号