推荐语
B站如何利用Iceberg实现商业化模型的高效更新?深度解析其技术演进与实践效果。
核心内容:
1. Iceberg在B站的技术演进路径
2. 行级更新的业务背景与技术设计
3. 业务落地实践与未来规划分享
杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
导读 本次分享重点讲解了 Iceberg 的业务应用,涵盖特征调研、更新场景支持及性能兼顾等实际应用,包括在 branch 上支持独立 schema 的实现,优化特征调研流程;通过 ColumnFile 实现灵活高效的更新场景;以及宽表治理与数据回刷方案,显著提升了数据管理和使用的灵活性,为复杂业务需求提供了高效解决方案。
1. 从交互式分析到多场景探索的技术演进
2. 行级更新的业务背景
3. Update on Column 的技术设计与思考
4. 业务落地与实践效果
5. 未来规划
分享嘉宾|张明磊 Bilibili 资深开发工程师
编辑整理|Neil
内容校对|李瑶
出品社区|DataFun
从交互式分析到多场景探索的技术演进

首先看一下哔哩哔哩湖仓一体团队过去四年的关键技术演进路径。时间线的蓝色节点可以看到,在最初的三年时间里,技术重心主要集中在交互式分析方向,围绕这一目标完成了以下几项关键工作:
- Z-order 排序:实现了数据的排序功能,通过优化文件布局,显著提升了查询性能。
- 索引构建 Bitmap 索引和 Bloom Filter 索引
- 预计算:针对单表高频聚合查询进行了优化,实现了高度聚合查询的性能提升。比如在 Trino 引擎中,某个高度聚合的查询通过预计算将一天的读取数据量减少了 316TB。并且也支持了星型模型的预计算建模并且在 star schema benchmark 上也有着显著的性能提升。
上述三项主要工作的落地,标志着 Iceberg 在哔哩哔哩的初步探索取得了阶段性的成绩。
从 2022 年开始,我们的工作开始向智能化数据管理迈进,同时进一步优化交互式分析的基础能力。具体来说:
到了 2023 年,我们完成了哔哩哔哩日志数据的全面入湖,同时针对日志查询的特点,进行了一些优化:
这些技术的落地,我们在交互式分析上的基础能力已经相对完善,也正是这些技术突破,为后续非交互式分析领域的拓展奠定了扎实基础。
行级更新的业务背景
在大数据领域中,行级更新一直是一个较为复杂的技术挑战。然而,为了更好地赋能业务,需要针对哔哩哔哩的实际需求设计合理的技术解决方案。
1. 行级更新的业务背景
在讨论技术方案之前先简单介绍一下业务背景。事实上,任何技术的诞生和发展都离不开业务驱动。以下是在行级更新方面的两个主要业务场景。
场景一:Label 更新

在广告业务场景中,网页右下角的广告模块会生成两类核心数据:
这两类数据的业务处理架构基于 Flink 双流 join 窗口,窗口时间为 25 分钟,实时落地到一张数据表中。当用户点击广告卡片后,后续可能会触发一系列后续行为(例如激活或购买),而这些数据的生成时间通常会超过 25 分钟。为了将这些后续的行为数据关联到之前曝光和点击产出的关联表,我们需要通过 Spark 进行小时级的关联处理,目的是对曝光和点击数据进行关联并更新写入。目前,主流的技术方案是采用 overwrite 的方式对目标表进行更新。然而这种方式存在以下问题:- 冗余存储:每次更新都会重新覆盖整个目标表,导致数据存储的冗余。
- 资源耗费大:大规模数据写入消耗大量资源,且更新过程耗时较长。
场景二:特征调研

特征调研的主要目标是分析新增特征对现有模型的影响。特征可以理解为表中的一些列字段,当我们需要新增特征时,通常会采取以下方式:
- 存储冗余:每新增一次特征,都需要创建一张新表,导致存储开销大幅增加。
- 资源与稳定性问题:历史数据回刷耗时长且资源消耗高,尤其在处理大规模数据时,回刷容易失败。
2. Iceberg 原生技术方案的问题
Iceberg 中的 Branch 被定义为一个 snapshot reference,即指向某个可引用的快照。由于 Branch 没有独立的 Schema 配置能力,因此在特征调研场景中存在以下问题:如果需要新增特征字段必须直接在表的 Schema 上修改,这会对表的读写造成影响。Branch 不支持独立 Schema 配置,导致在特征调研场景下使用 Branch 不够安全且难以操作。因此,Iceberg 提供的 Branch 功能在特征调研中并不能很好地满足我们的需求。在大宽表更新少数列的场景中,Iceberg 原生的两种更新模式——Copy-on-Write 和 Merge-on-Read,在我们的业务中都存在显著问题:①Copy-on-Write 模式:在更新大宽表的一列或少数列时,该模式需要重新写入表中所有未更新的列。例如,对于一张拥有 3,000 列的大宽表,更新一列时需要重写 3000 列的数据,导致大量的冗余写操作。这种模式带来了较大的 IO 和计算资源浪费,影响更新性能。②Merge-on-Read 模式:虽然该模式在更新时只写入被修改的行,但仍需重复记录未更新列的数据。例如,对于大宽表中的一行数据,即使只更新其中的 1 列,其余未更新的 2,999 列仍会被记录下来。这种冗余存储依然导致资源浪费,并无法高效解决我们业务中的问题。Iceberg 的这两种更新模式虽被广泛应用,但在大宽表更新少数列的场景中,并不能满足我们的性能需求。因此,我们需要设计更高效的方案。3. Update On Column 方案
针对上述问题,我们提出了一种新的解决方案,Update On Column。一个 ColumnFile 记录了 Iceberg 表中若干个列的值、以及这些列在原始 DataFile 中的行号。行号在 ColumnFile 中为主键。一个 ColumnFile 需要与一个 DataFile 进行关联,一个 DataFile 可以关联多个 ColumnFile。每个 ColumnFile 存储的记录行数小于等于对应的DataFile。在读取 DataFile 时,来自 DataFile 中的数据与 ColumnFile 中的数据按行号执行 inner join 操作,得到完整的一行数据。没有 join 上的数据认为已经被删除。
例如,对于一张包含字段 F1、F2 和 F3 的表:
假设执行 SET 语句修改了 F2 和 F3,ColumnFile 仅记录这两列的更新数据,同时保留原始行号 Position 信息。- ColumnFile 与 Copy-on-Write 的区别在 Copy-on-Write 模式中,所有字段(如 F1、F2 和 F3)会被重新写入,无论它们是否被修改。
但在 ColumnFile 模式 中,仅将更新的列(如 F2 和 F3)写入,未被修改的 F1列完全不需要重写。
通过减少冗余写操作,ColumnFile 极大地降低了 IO 开销和资源浪费。
ColumnFile 和 DataFile 绑定在同一个 manifest entry 中,一个 DataFile 可以绑定多个 ColumnFile。元数据的具体内容如下:
- 添加的 Snapshot ID:记录更新所处的快照版本。
- Sequence Number:解决与 DeleteFile 关联的问题,保证数据正确性。
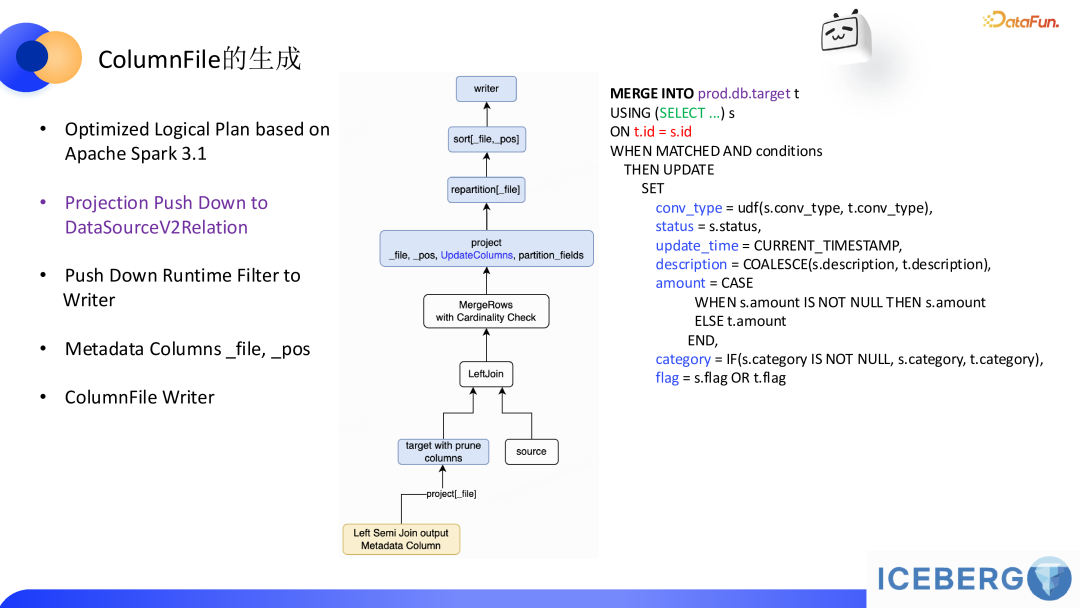
ColumnFile 的生成是整个流程的核心,以下是具体过程的说明:上图 SQL 示例中,更新的字段包括 conv_type、status、update_time 等,最终这些字段会被写入到 ColumnFile 中,该 SQL 最终 spark 执行的时候会产生 ColumnFile。SQL 里面只有一次 join,为什么执行计划里面会出现 2 次 join 的节点 ?这里第一次 Join 是筛选出需要更新的文件路径(注意: 我们期望该 runtime filter 具备 high selectivity,后面会针对这里做进一步优化),第二次 Join 参与的 target 表利用第一次 join 得出的文件路径来过滤不需要的文件以减少需要处理的数据量。完成 Join 后,数据会按照以下流程进一步处理:
MergeRows 算子:在逻辑计划中,MergeRows 算子将更新逻辑应用于数据。
Projection Push Down:只处理 SQL 中涉及的target表字段,避免不必要的字段读取以降低 IO 开销。涉及的字段来源包括:Join Key、Match 条件、赋值语句中的左侧和右侧字段。
Repartition:由于一个 ColumnFile 只对应一个 DataFile,所以需要按照输入数据的文件路径对数据重分区以聚合,以便一个 DataFile 只会生成一个 ColumnFile。Sort:对更新记录按行号排序,以便读取的时候可以按照行号进行关联。经过上述步骤,最终生成的 ColumnFile 中包含以下数据:
更新后的字段信息(如 SQL 示例中的 conv_type、status 等)。额外字段 position,用于后续操作时的关联。

在数据处理过程中,ColumnFile 的读取逻辑相对生成过程来说更加直观。其核心在于通过行号(position)实现对 DataFile 和多个 ColumnFile 的多路归并,从而还原出完整的数据。以下是具体的描述和分析。首先,假设我们有一张表包含 a、b 、c 三列。如果用户对 c 列的数据进行了更新,例如将 apple 替换为 pig,将 water 替换为 oil,那么在更新后会生成一个新的 ColumnFile,其中仅记录了 c 列被修改的部分。为了还原表的完整性,我们需要在读取时将 DataFile 和该 ColumnFile 归并在一起。通过对应行号匹配输出最终数据。值得注意的是,DataFile 的读取支持切分(Split),这意味着在大规模数据处理中可以将文件分成多个片段并行读取,从而提升效率。在读取的时候需要注意和ColumnFile归并时的一些技术细节(Split of a DataFile merge a ColumnFile),这里就不展开了。
接下来,我们讨论 DeleteFile 的应用逻辑。在数据管理中,DeleteFile 是用来记录删除操作的文件,其 sequence number 用于标记删除操作的版本号。通过它,可以精确地追踪数据的删除历史。以下是一个示例:假设表中有 3 个字段 F1、F2 和 F3,初始时所有数据存储在一个 DataFile 中,且 sequence number = 1。随后,用户执行了一次删除操作,删除了 F1 = 4 和 F1 = 13 的两条数据,并生成了一个新的 DeleteFile,其 sequence number = 2。紧接着,用户生成了一个 ColumnFile,其中只保留了未被删除的数据(即第 1 行、第 3 行和第 4 行)。由于第 2 行和第 5 行的数据已被删除,因此不会出现在新的 ColumnFile 中。在读取时,DeleteFile 的作用是配合 ColumnFile 和 DataFile一起确定最终的数据输出。为了避免冗余应用 DeleteFile,读取逻辑需要对其 sequence number 进行判断。如果 DeleteFile 的 sequence number 小于 ColumnFile 的最大 sequence number,这意味着该 DeleteFile 删除的语义已经被后续的 ColumnFile 处理过,因此无需再次应用 DeleteFile;否则,则需要在读取时额外处理 DeleteFile,以确保删除操作的正确性。显然,ColumnFile 还具备删除语义。这种基于 sequence number 的判断逻辑在更复杂的场景下尤为重要。例如,假设数据的生成顺序如下:第一次生成了 DataFile,sequence number = 1;第二次生成了 ColumnFile,sequence number = 2;第三次又生成了另一个 ColumnFile,sequence number = 3;第四次生成了 DeleteFile,sequence number = 4。在读取时,需要先对 DataFile 和 ColumnFile 进行多路归并,得到初步的结果数据,然后将归并结果中 ColumnFile 最大的 sequence number 与 DeleteFile 的 sequence number 进行比较。如果 DeleteFile 的 sequence number 小于归并结果中的最大值,则表示其删除语义已经被覆盖,无需再额外应用;否则,需要将 DeleteFile 的删除语义作用到归并结果上。Update on Column 的技术设计与思考
在满足业务需求的基础上,我们进一步探索是否可以优化更新流程以缩短处理时间。当前流程中,完成一次更新所需的 15 分钟基本已经满足了业务需求,但优化的潜力仍然存在。特别是首次 Join 操作的必要性值得重新审视,因为我们观测到在整个 SQL 的执行过程中第一次 Join 的代价占比会比较大。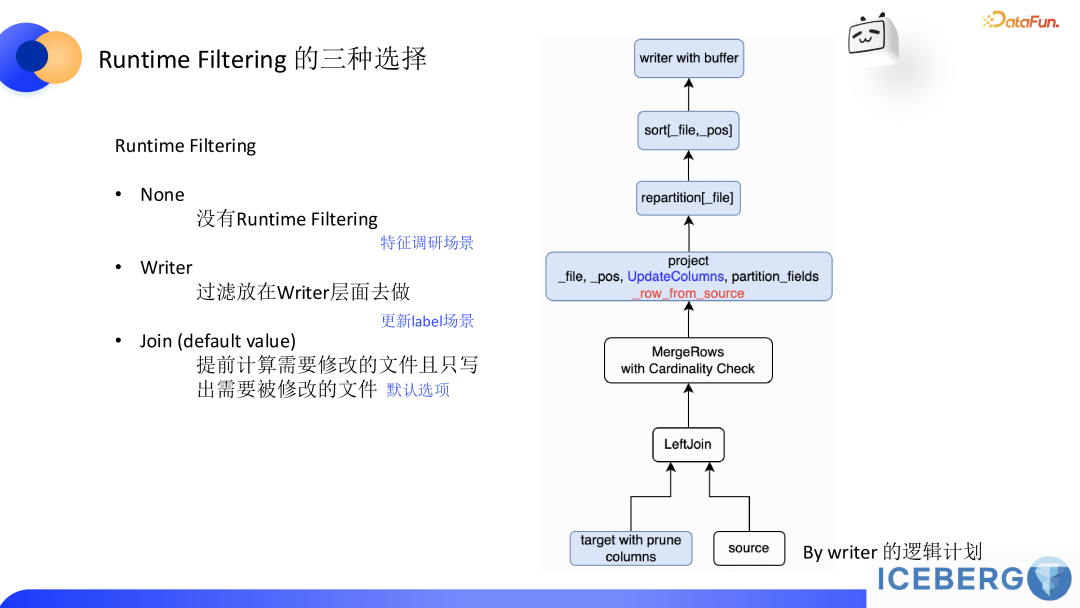
从执行计划看,数据处理涉及两次 Join,其中第一次 Join 用于筛选需要更新的文件。这一步的主要目的是通过 Runtime Filtering 确定更新文件路径集合(类似倒排索引)。然而,如果业务场景中 99% 的数据都需要更新,则首次 Join 的必要性大幅降低。例如,在特征调研场景下,几乎每一行数据通常都需要变更,这意味着 Runtime Filtering 的 selectivity 非常低。因此,可以尝试直接跳过首次 Join,将 Runtime Filtering 设置为 None(全表扫描)。这和在关系型数据库里 B+树索引没有什么过滤效果反而直接建议全表扫描是本质是一回事。在这种优化下,处理流程默认所有文件都需要被更新,写入的时间也随之大幅缩短。这种方法在某些特定场景中效果显著,尤其是特征调研场景。将处理时长从原来的三个小时减少到十几分钟。 值得注意的是,Iceberg 在原生的行级更新的论文里 VLDB - Petabyte-Scale Row-Level Operations in Data Lakehouses 针对Runtime Filtering 只做了 high selectivity 场景的测试,并没有给出 low selectivity 场景下的性能报告,而 low selectivity 的场景是业务应用很重要的一块,尤其是针对我们的特征调研场景。在该场景下,Runtime Selectivity 几乎为 0。Runtime Filtering 反而起到了副作用。 (2)Writer 优化我们发现更新 Label (大约一半的文件被最后更新)在应用 None 模式后性能存在回退,经过观察发现回退主要是 IO 引起(每个 write task 写几百个 KB 级别的文件)。所以进一步优化的重点集中在 Writer 层,跳过首次 Join 后,虽然 stage 数减少了一半,但同时也引入了新的问题:系统可能会写出大量无效文件(即未被修改但仍然写出的文件),这些文件往往体积较小,仅几十 KB,却占用大量 I/O 资源,影响整体效率。为解决这一问题,我们在 writer 中引入了一种基于缓存的判断机制:判断更新状态:在 project 阶段新增一个字段 row_from_source(见执行计划里红色的字段),用于标记数据来源。如果在 writer 检测到 row_from_source 字段,则说明该文件需要被修改,触发 flush。否则,在文件关闭时直接清理缓存,避免生成无效文件并释放内存空间。该优化上线后,更新 Label 场景性能大约有 33% 左右的提升。(3)Update on Column 模式的优势上述优化在 Copy on Write 模式下难以实现,因为 CoW 需要更新所有字段,导致内存容易发生 OOM。而基于 Update on Column 模式,由于每次更新的列数非常少(单个 ColumnFile 通常只有几十 KB),在内存中操作完全可行。这种轻量化的操作方式,使得 Writer 层优化成为可能,从而进一步提升性能。
(2)Writer 优化我们发现更新 Label (大约一半的文件被最后更新)在应用 None 模式后性能存在回退,经过观察发现回退主要是 IO 引起(每个 write task 写几百个 KB 级别的文件)。所以进一步优化的重点集中在 Writer 层,跳过首次 Join 后,虽然 stage 数减少了一半,但同时也引入了新的问题:系统可能会写出大量无效文件(即未被修改但仍然写出的文件),这些文件往往体积较小,仅几十 KB,却占用大量 I/O 资源,影响整体效率。为解决这一问题,我们在 writer 中引入了一种基于缓存的判断机制:判断更新状态:在 project 阶段新增一个字段 row_from_source(见执行计划里红色的字段),用于标记数据来源。如果在 writer 检测到 row_from_source 字段,则说明该文件需要被修改,触发 flush。否则,在文件关闭时直接清理缓存,避免生成无效文件并释放内存空间。该优化上线后,更新 Label 场景性能大约有 33% 左右的提升。(3)Update on Column 模式的优势上述优化在 Copy on Write 模式下难以实现,因为 CoW 需要更新所有字段,导致内存容易发生 OOM。而基于 Update on Column 模式,由于每次更新的列数非常少(单个 ColumnFile 通常只有几十 KB),在内存中操作完全可行。这种轻量化的操作方式,使得 Writer 层优化成为可能,从而进一步提升性能。
运行时间:从原来的 12 分钟缩短至 8 分钟。
Stage 数量:由 Copy on Write 模式下的多个复杂阶段减少为仅 4 个 Stage,流程更加高效。
业务价值:优化后,数据更新和模型训练的效率提高了 33%,显著缩短了算法迭代的时间,为业务带来了更大的商业价值。
业务落地与性能优化效果
在实际业务中,我们进一步优化了 Iceberg 的功能支持,尤其是在分支(Branch)上的 Schema 独立性和列级更新(Update on Column)模式的使用上,这为特定场景下的数据处理带来了显著的灵活性和性能提升。1. Branch 上的 Schema 独立性支持

在 Iceberg 社区原生实现中,分支并不支持独立的 Schema 配置。对此,我们的业务需求提出了更高的要求,因为特定场景下需要直接在分支上进行特征调研和列操作,而不依赖创建新表来处理数据。为此,我们为分支提供了独立的 Schema 支持,从而大幅优化了以下工作流程:- 减少新表创建的开销:通过在分支上直接操作数据和验证新增列的效果,可以避免创建冗余的新表,并在主表需要时(比如分支验证某特征有效)再将分支的更改在主表中重做。
- 适应特征调研场景:在特征调研的业务中,所有调研操作都可以在分支上完成,同时分支自带生命周期管理,支持新增列、修改列等操作,显著提升了开发效率。
然而,为了避免过度复杂化和潜在的元数据膨胀问题,我们的实现仅支持独立 Schema,而未扩展到支持更多类型的元数据。这种设计选择在满足业务需求的同时,也保持了系统的稳定性和可维护性。2. Update on Column 模式

列级更新是 Iceberg 中的一种轻量化写入模式,通过配置简单的参数即可实现:用户仅需将 Merge Model 设置为 Update on Column,即可在执行 MERGE INTO 时以列为单位更新数据。如果一个 DataFile 绑定非常多的 ColumnFile,其读取效率可能会下降。在这种情况下,需要做一次或者按需做 Compaction,对 ColumnFile 和 DataFile 进行合并。这种手动触发的设计是出于作业稳定性考虑,因为类似于自动压缩的系统功能可能会引发并发问题。因此,手动压缩既保证了灵活性,也有效规避了潜在风险。 在大数据系统中,写入性能和读取性能通常难以兼顾。然而,通过优化分支 Schema 和 Update on Column,我们在实际测试中取得了良好的读写平衡。基于 Update on Column 模式的优化,使得写入过程更加轻量化,特别是对于更新文件比例较大的场景,可以通过跳过首次动态过滤(Dynamic Filter),进一步降低开销。尽管优化主要集中在写入端,但读取性能并未因优化而显著退化。测试结果表明,优化方案能够在读写两端都达到令人满意的效果。未来规划

在未来,我们的工作将围绕以下几个关键方向展开,以进一步提升数据处理能力和业务支持效率:
宽表治理
针对企业内部常见的宽表问题,我们提出了一种新的治理方案。宽表通常由多张表通过复杂的 LEFT JOIN 组合而成,维护起来十分复杂,尤其是在需要增加新字段或重新计算时,任务调度必须等待所有参与的表准备完毕,这导致了较大的调度粒度和低效率。
通过我们的方案,可以实现按列级别的表产出,避免全表的重复计算。不仅可以提升任务调度的灵活性,同时会改变宽表在数仓链路中的依赖模式,减少对下游数百个 ETL 作业的影响。
ColumnFile 的通用性不仅限于更新场景,也为宽表设计提供了一种高效的替代方案。
回刷数据
在现有的计算框架中,回刷数据通常以分区为单位,这在计算口径变化或需要回刷部分数据时显得效率极低。我们提出了一种细粒度的回刷方案:支持按文件级别进行回刷,而非整个分区,降低了资源和时间成本。
多流拼接与增量读语义
当前流计算领域内的多流 JOIN 操作往往面临大状态管理的问题,而我们计划在 Iceberg 层面定义并支持多流拼接的增量读语义。
Pylceberg 的扩展
我们计划在 Pylceberg 项目中增加更多支持,比如 Distribution 和 Index,以进一步优化与 Python 生态的兼容性,为开发者提供更友好的工具和接口,并结合我们现有 iceberg 的能力扩展其在数据处理与分析领域的应用场景。

































 粤ICP备17114055号
粤ICP备17114055号