导读 最近一年以来,大语言模型技术突飞猛进,被广泛地认为开启了人工智能研究的新阶段。大语言模型时代的到来,给知识图谱技术也带来了新的机遇与挑战。我们在 5 月份的时候曾经发布过知识图谱与 AIGC 大模型的知识地图,其中包括了文本生成、图像生成等技术。
本次分享将聚焦于大语言模型最新的研究进展,从大模型对知识工程的帮助、知识图谱帮助大模型的评测和应用,以及未来知识图谱与大模型交互融合的展望等几个方面进行介绍。
1. 大语言模型与知识图谱的对比
2. 大语言模型助力知识抽取
3. 大语言模型助力知识补全
4. 知识图谱助力大语言模型能力评测
5. 知识图谱助力大语言模型落地应用
6. 知识图谱交互融合
7. 结束语
8. 参考文献
大语言模型与知识图谱的对比
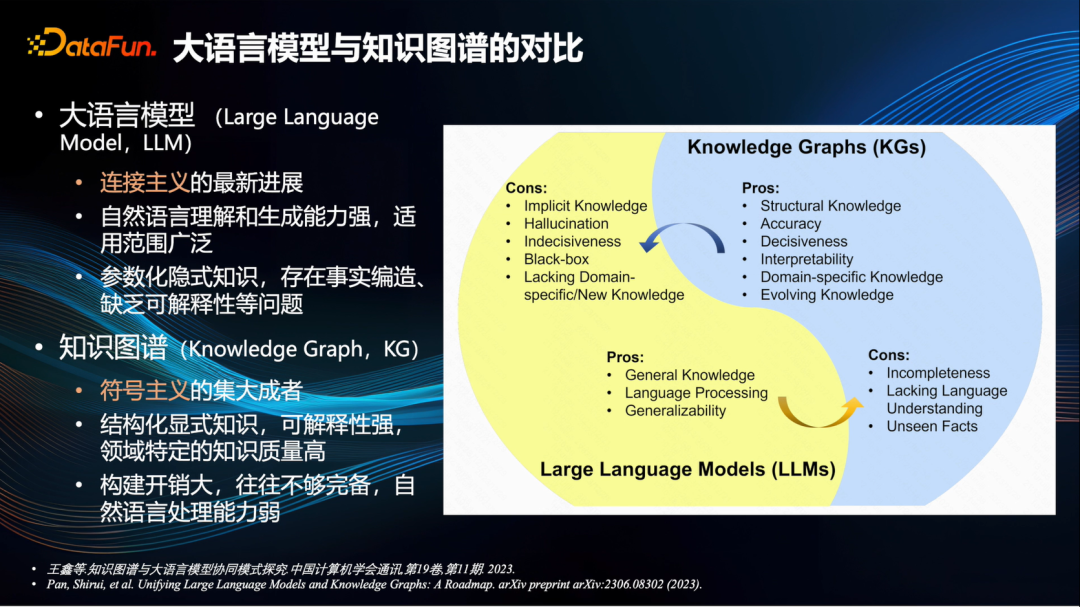
去年 ChatGPT 问世的初期,还曾有声音说知识图谱已经过时了,将被大模型所替代。然而,随着这一年来的深入探讨和研究,目前业界普遍认为,大语言模型和知识图谱各有所长,能够互相补充[1,2]。
具体而言,基于深度神经网络技术的大语言模型是连接主义的最新里程碑,其优势在于对自然语言的理解和生成能力极强,适用范围广泛。而缺点则是其中的知识是参数化的隐式知识,存在事实的编造,缺乏可解释性等问题。也就是我们常说的大模型生成内容存在幻觉的现象。
知识图谱是符号主义的集大成者,过去十几年来受到了广泛的研究与应用。它的优点是知识结构化、显式化,可解释性非常强,特别是在某些特定领域,知识质量极高。当然,缺点也很明显,那就是构建成本太高,往往不完全正确,在自然语言处理方面相对较差。
那么二者应该如何相结合进行优势互补呢?接下来将从不同角度来分析二者的相互作用。
大语言模型助力知识抽取
首先,大模型强大的语言理解能力可以助力知识抽取任务。
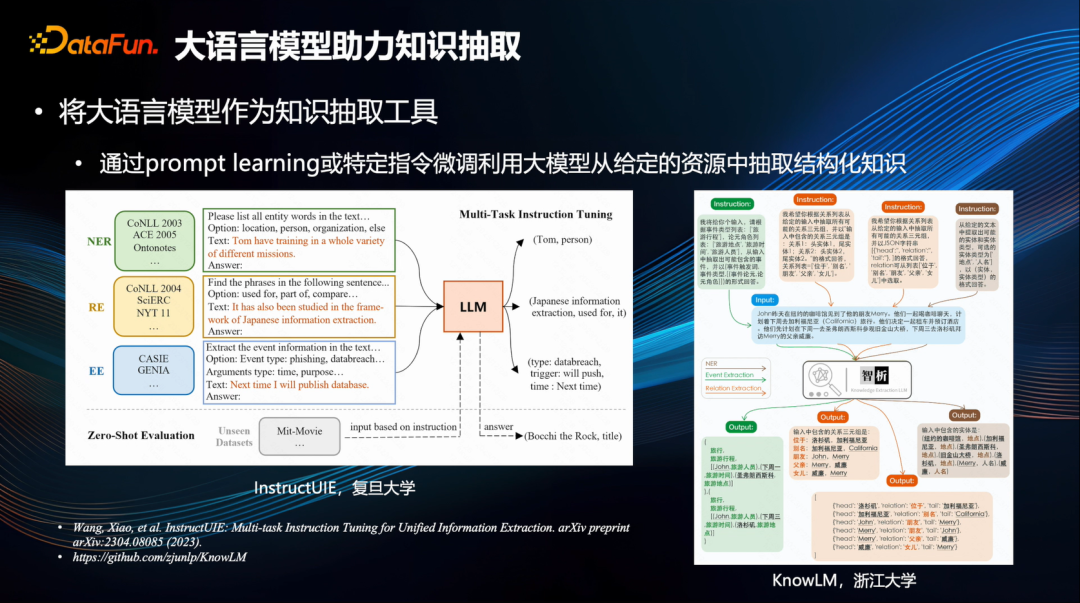
典型的例子像复旦大学的 InstructUIE[3]和浙江大学的 KnowLM[4]。用特定指令,调动大模型从给定资源里提取出有用的知识,完成各种各样的任务,比如实体提取、关系抽取、事件抽取等。当然,也可以针对这些指令做专门的 SFT(深度特征提取)微调,这样可以增强优化效果。换句话说,只要通过这些指令,就能在给定内容里轻松完成实体、关系等各种提取任务。
大语言模型助力知识补全
还有一些工作是通过特定的指令,将大型模型中的参数化知识提炼出来,从而构建成结构化的知识,以便于对知识图谱进行补全[5]。
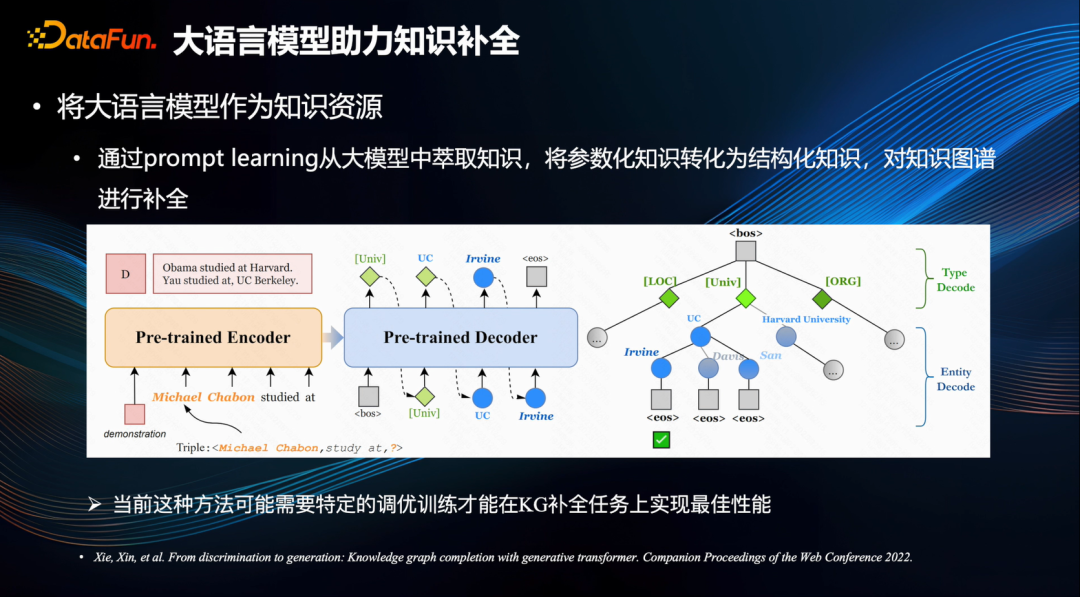
由于大型模型在训练过程中已经接触了大量的文本数据,其中蕴含着丰富的客观知识,因此如果能够精确地萃取出来,将会极大提升知识图谱中的完备性。然而,鉴于当前大型模型生成的内容可能会出现幻觉问题,因此当前方法需要采用特定的调优训练进行约束才能实现,而这一领域尚有相当巨大的研究空间。
知识图谱助力大语言模型能力评测
1. 评测集

知识图谱对大模型的评测具有显著的助力,从掌握和利用世界知识的角度对大模型的能力进行全面的评测,典型的代表是清华大学提出的 KoLA 评测集[6],该评测集针对知识认知的四个层次,即知识记忆、知识理解、知识应用和知识创新,对大模型进行全面测试。
2. 评测结论
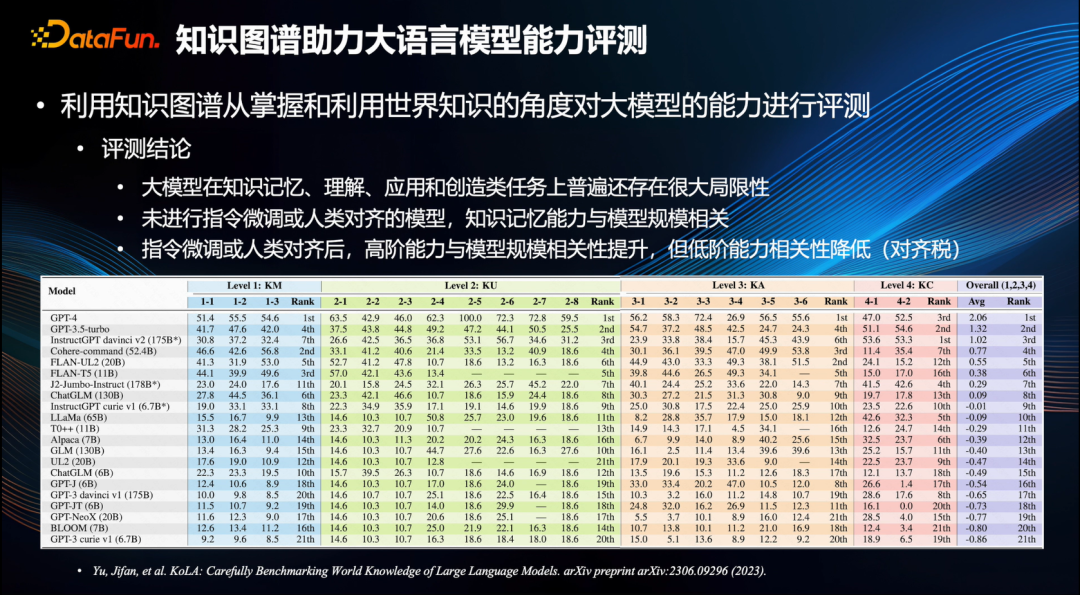
从目前的测试结果来看,有几点颇具趣味性的结论值得关注。首先,大模型在知识记忆、理解、应用和创新等任务中普遍存在较大的局限性。其次,对于未经指令微调且与人无关的模型来说,其在知识记忆方面的能力与模型规模呈正相关关系,也即是模型的参数越多,则其知识记忆能力越强。然而,经过指令微调与人类对齐后,其高阶能力,如知识的应用和创新等能力与模型呈正向相关,但低级能力,例如记忆、理解等能力,则与其呈负相关关系,这便是所谓的“对齐税”,这一发现极为重要[6]。
知识图谱助力大语言模型落地应用
1. 知识图谱作为外接工具或插件提高大模型生成内容的知识准确性和可解释性
知识图谱辅助大语言模型的另一个方面是可以帮助大模型的落地应用。大模型的幻觉问题是阻碍落地应用的重要因素之一。大家正在考虑采用开启增强模式[7]以引导并制约大模型所产出的内容。这意味着设定与用户问题相关的一些内容输入为大模型参考信息,用以缓解一本正经胡说八道现象的情况,从而提升知识的精确性与可解释性。
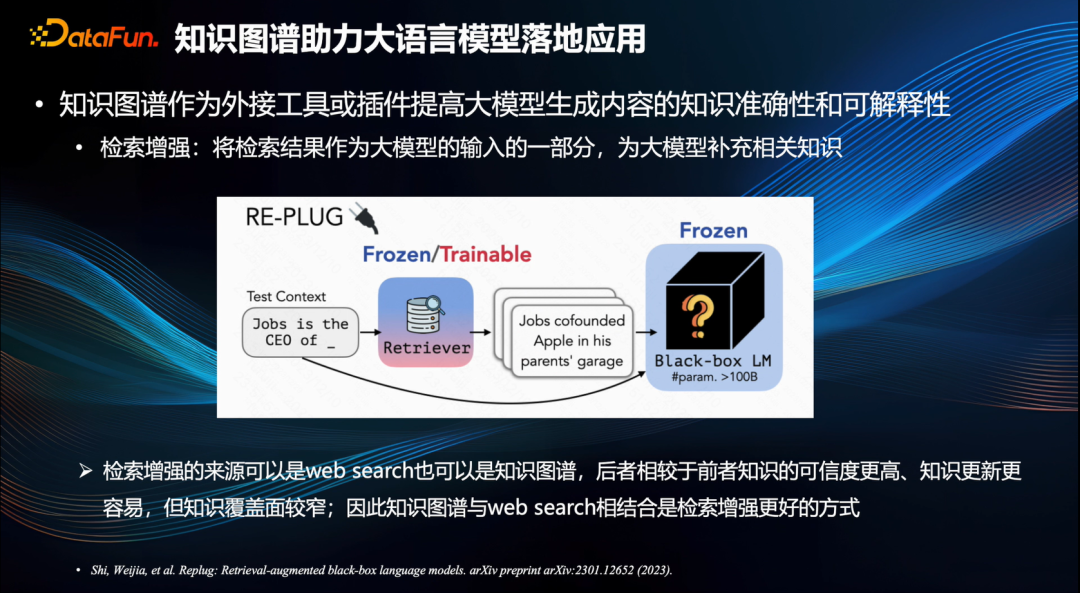
知识图谱作为高质量的知识来源,为开启增强模式奠定了基础。相对于 Web 搜索来说,知识图谱所承载的信息可信度更高,且知识更新过程中更易于发现错误,极易进行精准修正。然而,知识图谱也存在一定局限性,例如其覆盖范围相对较窄,尤其针对一些长尾知识、复杂知识则更易产生遗漏。因此知识图谱与 Web 搜索相结合,是知识检索增强的良策。
事实上,Google 提出知识图谱的初衷便是为了提升其搜索引擎的性能。
2. 知识图谱可以提升大模型生成内容的安全性和一致性
知识图谱还有助于提高大模型生成内容的安全性和一致性。

例如,哈尔滨工业大学就提出了两种方案,第一种是运用知识图谱作为后验工具,对输出内容进行核实,从而增强其一致性。例如,在左边的例子中,“亚里士多德使用笔记本电脑吗?”,ChatGPT 有可能生成出与此相关的内容,如第一条内容为“亚里士多德死于 2000 年”,但这个知识却与知识图谱中的亚里士多德的生卒年代相悖,于是便产生了冲突,通过这样的验证,能够发现一些错误的知识,进而筛选出更符合客观事实的回答进行输出。
其次,知识图谱能协助大模型辨识不安全问题,同时增强应对不安全场景的能力。在右边的例子中,用户可能会提问到一些涉及违法违规行为的问题。大模型可以利用知识图谱甄别其中的敏感知识以及相关内容,进而生成更为可靠的答复。
3. 知识图谱可以提升大模型的复杂推理能力

当面对复杂问题时,大模型无法直接从检索增强中获取答案,而需通过多跳的关系集合操作属性的比对等环节来寻找问题答案,此时便需要进行精准的推理。
清华大学研发了一款专为知识推理问答而设的编程语言——KoPL[8],该语言能够将自然语言转化为基本函数的组合,从而针对复杂问题进行推理和解答。例如,观察右侧例子,问:勒伯纳·詹姆斯和他的父亲谁的身高更高?这个问题便会被分解为一些基础函数,如查找勒布朗·詹姆斯的身高、查询其父亲信息,然后找到他父亲的身高,最后进行身高的对比,从而得出答案。此过程体现出精准且严谨的推理环节。值得一提的是,清华大学这套编程语言具有明显、透明及模块化的特性,利于推理过程的展示与理解,对于人机交互十分有利,有助于提高大规模模型回答问题的可解释性。此外,这款软件还能处理不同知识库文本的各类格式,具有较强的可扩展性。
知识图谱交互融合
最后,分享基于当前的研究成果对未来知识图谱与大型模型交互融合的展望,由天津大学的王鑫老师提出[1]。
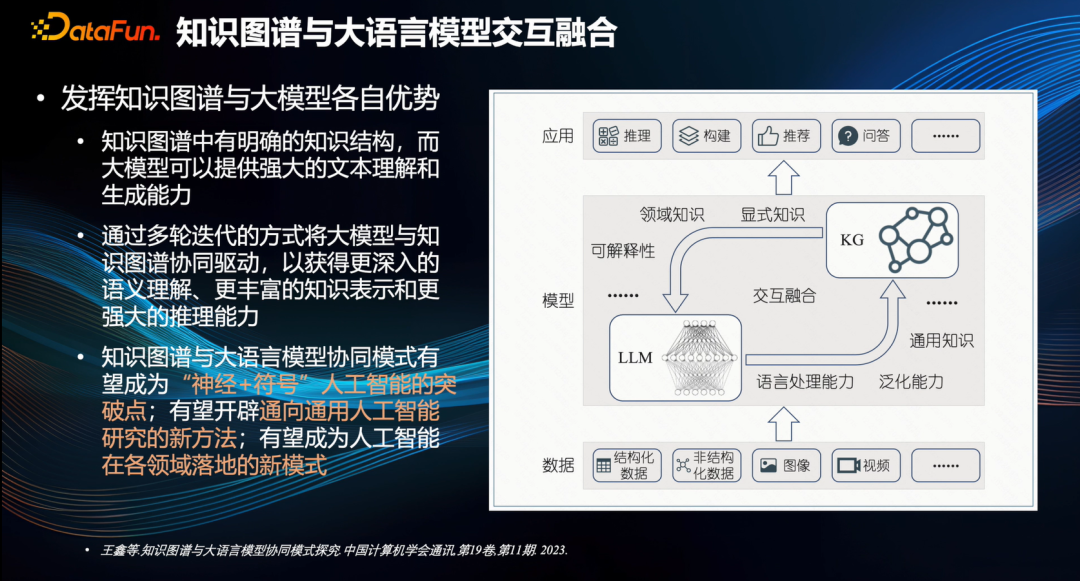
知识图谱中有明确的知识结构,而大模型可以提供强大的文本理解和生成能力,那么通过多轮迭代的方式,可以将大模型与知识图谱协同驱动,以获得更加深入的语义理解以及更加丰富的知识表示和更加强大的推理能力。
结束语
知识图谱与大模型相协同的模式有望成为支持神经和符号人工智能的重要突破点,能够开辟通往通用人工智能的全新途径,也将成为人工智能在各领域应用的新型模式。
这些领域尚有大量工作亟待完成,对于知识图谱领域的从业者来说,应当积极面对并迎接大模型技术带来的变革。一方面,我们应充分利用大规模模型的潜力,提升知识工程的效率和效果;另一方面,也应当借用知识图谱来提升大规模模型生成内容的精确性、安全性以及可解释性,从而进行更深度的探索。这种将两者深入融合的能力将引领这个领域走上更高的发展道路,其中蕴含着诸多引人入胜的科研机会。

































 粤ICP备17114055号
粤ICP备17114055号