标题:
原文标题:
GraphLeak:Patient Record Leakage through Gradients with Knowledge Graph2024
作者:
Xi Sheryl Zhang,Weifan Guan,Jiahao Lu,Zhaopeng Qiu,Jian Cheng,Xian Wu,Yefeng Zheng文献来源:
GraphLeak: Patient Record Leakage through Gradients with Knowledge Graph | Proceedings of the ACM on Web Conference 2024论文导读:
在实际诊所中,医疗数据分散在多家医院。由于安全和隐私问题,几乎不可能将所有数据聚集在一起并训练一个统一的模型。因此,多节点机器学习系统是目前医疗保健系统中模型训练的主流形式。然而,分布式训练依赖于梯度的交换,这在隐私泄露的风险下得到了证明。这意味着恶意攻击者可以利用公开共享的梯度来恢复用户的敏感数据,这是电子医疗记录(EHRs)等极端私有数据的严重问题。当训练数据量增加时,以前的梯度攻击方法的性能会迅速下降,这使得它在实践中的威胁较小。然而,在本文中,通过利用医学知识图谱等先验知识,泄漏风险可以显着放大。特别是,本文提出了 GraphLeak,它在梯度泄漏攻击中加入了医学知识图。GraphLeak 即使在大量数据下也能提高梯度攻击的恢复效果。本文对电子医疗记录数据集进行了实验验证,包括 eICU 和 MIMIC-III。与之前的工作相比,本文的方法实现了最先进的攻击性能。代码可在 https://github.com/anonymous4ai/GraphLeak 获得。论文介绍:
1 引言
随着近二十年信息技术的快速发展,医院积累了大量的临床数据,包括医院信息系统(HIS)的电子健康记录(EHR)、实验室信息系统实验室测试结果(LIS)和图片档案与通信系统(PACS)的医学图像。在这种临床数据上训练的监督模型可以使广泛的临床应用受益,如诊断预测、药物预测[31]和医疗报告生成。在实践中,临床数据分散在多家医院,将所有数据聚集在一起训练一个统一的模型是相当具有挑战性的。为了在分散数据上训练全局模型,分布式训练已成为一种流行的方法。在分布式训练系统中,多个设备和参与者协作通过交换梯度来训练共享模型。例如,不同的医院可以协同工作以提高模型性能,同时保持敏感医疗数据的隐私。通过利用梯度交换,这些医院可以集体训练模型并在不影响患者机密性的情况下提高性能。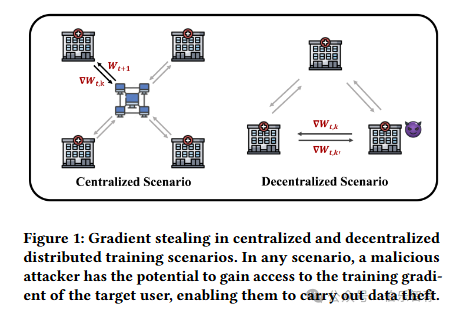
最近的研究引起了人们对与梯度交换相关的隐私风险的担忧。已经表明,诚实但好奇的攻击者可以潜在地利用共享的梯度来损害隐私。如图1所示,攻击者可以在中央服务器或其他参与者中隐藏自己,从目标用户获取梯度。如果成功,这些梯度的盗窃可以使攻击者利用特定的梯度攻击算法并获得对用户私有数据的未经授权的访问。因此,分布式训练的安全性在防止此类攻击方面面临着重大挑战。然而,一个自然的问题是:上述攻击在协作训练期间可以提供多少现实的隐私威胁,从而导致敏感信息从用户数据泄露。例如,分布式机器学习系统中的每个节点可能是一家大型医院,训练批次是由大量患者记录形成的。对于基于优化的梯度攻击或基于递归的梯度攻击来解决这个问题是相当具有挑战性的。换句话说,仅通过梯度泄漏恢复患者的私有数据是困难的。为了应对这一挑战,本文将使用图的先验知识合并到梯度泄漏算法中,以增加恢复数据的机会。特别是,本文中提出了 GraphLeak。这种梯度攻击算法利用医学知识图,旨在提高梯度攻击方法在处理大量训练批次时的性能。关键思想是利用从训练集中构建的共现频率矩阵。该矩阵作为正则化的一个组成部分,以减轻优化难度。通过博弈论观点将患者视为可能的联盟,知识图谱在对训练对进行采样时作为常识性分布做出贡献。特别是,本文使用来自 Banzhaf 交互分数的方差来解释图泄漏损失。GraphLeak 在性能方面取得了显着的增强,并允许在现实场景中更有效地和实际地利用梯度攻击算法,即使在大批量处理训练数据时。本文的贡献总结如下:- 这是一项试点研究,将医学知识纳入梯度攻击算法 GraphLeak,导致数据恢复精度显着提高,尤其是在大批量场景中。
- 本文使用定义明确的 Banzhaf 交互分数对优化目标进行了理论理解。可以证明博弈论分析与损失一致。
- 本文使用各种模型对eICU和MIMIC-III数据集进行了大量实验。这些实验彻底验证了算法在药物推荐和住院死亡率预测任务中的有效性。
2 模型
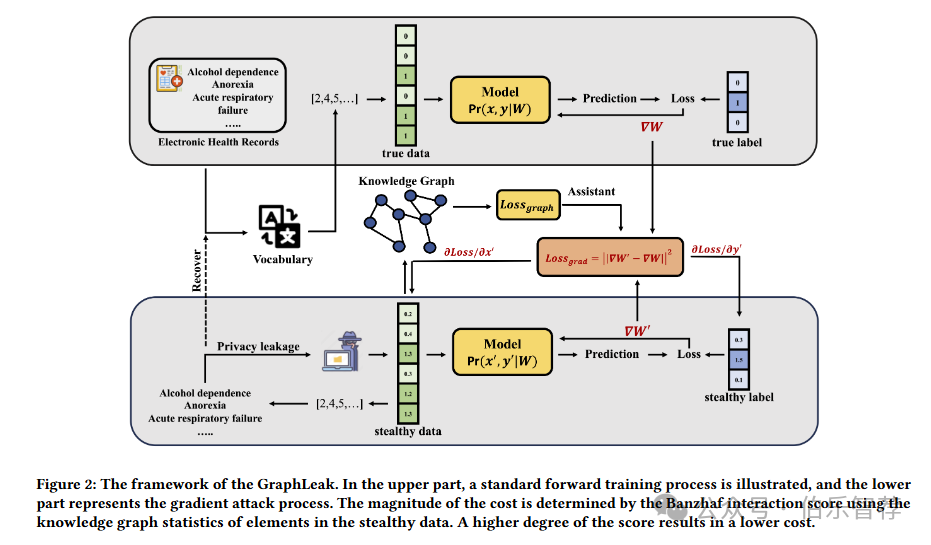
GraphLeak 的框架。在上半部分,说明了标准的前向训练过程,下半部分表示梯度攻击过程。成本的大小由 Banzhaf 交互分数决定,使用隐蔽数据中元素的知识图统计。分数越高,成本越低。3 实验
Baseline:TopK、DLG、TAG、iDLG在 eICU 数据集上,对于不同的梯度攻击算法,AUC 随批量大小的增加而变化如图 3 所示。可以看出,当批次较小时,DLG 和 TAG 都可以获得良好的性能,比 TopK 基线要好得多。然而,随着批量大小的增加(大于 4),AUC 迅速下降,甚至接近随机猜测。相反,在知识图谱的帮助下,GraphLeak 的数据恢复性能保持很高。
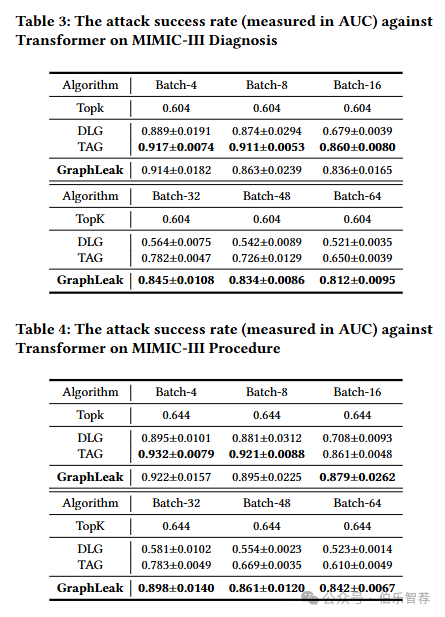
与 eICU 不同,MIMIC-III 的训练数据由两部分组成,诊断和程序。因此,本文分别计算它们的恢复结果,并在表3和表4中显示它们。MIMIC-III上AUC的变化趋势如图4所示。数据生成的图是缓解批大小增加导致的性能下降的有效解决方案。与其他基线方法相比,在处理大量数据时,它表现出显着提高的性能。更多关于 MIMIC-III 的实验结果可以在附录 B 中找到。

在分布式训练的背景下,恶意攻击者无法访问整个数据集,但它们可能会获得具有相同分布的子数据集。如果仅使用一小部分数据构建知识图谱可以显着提高 DLG,则威胁级别将显着增加。因此,比较了使用不同尺度的数据集构建的图的实验结果,结果如图 5 所示。
eICU 和 MIMIC-III 的结果分析揭示了一个有趣的观察结果。它验证了仅使用 5% 数据集的构建图可以产生与使用整个数据集相当的结果。在这里,使用训练数据构建图,这与尝试攻击的数据没有重叠。此外,只需要疾病、程序和药物之间的整体共现静态,不需要关于患者的任何其他信息。这一发现验证了利用从有限数据统计中获得的共现可以帮助优化器在处理大量训练数据时识别正确的优化方向。因此,该方法提高了恢复精度,并在应用于离散数据时极大地放大了 DLG 算法的威胁。
4 结论
在这项工作中,提出了一种新的方法来增强梯度攻击的 EHR 数据恢复效果,利用诚实但好奇的环境中的共现矩阵的先验知识。GraphLeak 使用先前的医学知识图谱和易于实现的协作训练设置取得了显着的效果。本文使用公开可用的 EHR 数据库广泛评估本文的算法并攻击主流架构。实证结果表明,GraphLeak 超越了以前的工作,尤其是涉及大批量。与其他泄漏相比,GraphLeak 可以构建离散数据的关系,因为通过 tallying 它们的特征的共现频率来构建知识图谱。本文将嵌入分组到桶中以获得最终的恢复。

































 粤ICP备17114055号
粤ICP备17114055号