摘要
知识图谱对齐(Knowledge Graph Alignment, KGA)旨在整合来自多个来源的知识,以解决单个知识图谱在覆盖范围和深度方面的局限性。然而,当前的KGA模型在实现“完整”的知识图对齐方面存在不足。现有的模型主要强调交叉图实体之间的联系,而忽略了跨KGs的对齐关系,因此只能提供部分的KGA解决方案。嵌入在关系中的语义相关性在很大程度上被忽视了,这可能会限制对跨kg信号的全面理解。在本文中,我们建议将关系对齐概念化为一个独立的任务,并通过将其分解为两个不同但高度相关的子任务:实体对齐和关系对齐来进行KGA。为了捕捉这些目标之间相互加强的相关性,我们提出了一个新的基于期望最大化的模型,EREM,它迭代地优化这两个子任务。在真实世界数据集上的实验结果表明,EREM在实体对齐和关系对齐任务中始终优于最先进的模型。1. 引言
(知识图(Knowledge Graphs, KGs)结构为三元组(头部实体、关系实体和尾部实体)的集合,作为从现实世界数据中提取的事实知识的概念表示。KGs通常作为跨不同领域的重要参考和补充知识库。单独的KG通常缺乏充分支持各种需求所需的信息的广度和深度应用程序,在单一图结构中全面捕获和表示不同的知识领域面临固有的挑战。因此,迫切需要制定策略来解决这一不足,并实现来自多个来源的知识的有效集成,称为知识图对齐(KGA)。现有的KGA模型主要集中于连接不同KGs之间的实体。最初,文本描述和关系被编码成低维嵌入来表示实体。随后,使用少量或不使用对齐种子来训练匹配函数,以最小化成对实体之间的距离。匹配函数根据实体嵌入推断出等效实体,通常形式化为全局分配问题或最优运输问题。尽管现有的方法具有先进的性能,但它们本质上关注实体对齐而不是知识图对齐。kg由两个基本组成部分组成:实体和关系。实体表示对应对象的内在属性,而关系表示实体之间的语义关联。直观地说,一个最佳的KGA模型应该能够在一个统一的框架内对齐实体和关系。然而,现有的研究主要集中在实体对齐上,往往忽略了关系对齐。这一缺陷导致只解决了所研究问题的部分方面,从而导致来自不同知识图的知识的不充分或错误集成。此外,关系仅用于提高实体嵌入的质量,而忽略了关系中固有的重要跨kg语义。在下图中,关系“父亲”在KG-ZH中的语义与KG-EN中的“父亲”关系具有相同的语义。这种嵌入在关系中的语义相关性在很大程度上被忽视了,这可能限制了对跨kg信号的全面理解。与现有的实体对齐模型不同,本文旨在解决KGA的“完整”任务。我们的动机在于将KGA形式化为两个相互关联的子任务:实体对齐(EA)和关系对齐(RA)。与实体对齐类似,关系对齐旨在匹配不同kg之间的相同关系。这两个子任务相互依存,相互加强,产生协同效应,从而增强整体对齐过程。一方面,准确的实体对齐提供了有价值的上下文,极大地帮助了关系的对齐。例如,给定对齐的实体对<“拿破仑一世”,“Napoleon”>和<“拿破仑二世”,“Napoleon_II”>,可以直观地推断出连接这些实体的关系(即KG-ZH关系“父亲”和KG-EN关系“父亲”)倾向于共享相同的含义。另一方面,关系的精确对齐可以帮助加强实体对齐的一致性约束。例如,如果我们确定头部实体对<“拿破仑一世”,“拿破仑”>和关系对<“父亲”,“父亲”>是对齐的,则可以直接推断出尾部头部实体对<“卡洛·波拿巴”,“路易_波拿巴”>指的是同一个人。虽然EA-RA对齐任务代表了具有共同进化潜力的全面努力,但它面临着几个挑战。首先,设计一个关系匹配模块来有效地对齐跨kg关系仍然很重要,特别是考虑到现有工作有限。一种直接的方法是基于文本相似度对关系进行对齐,这种方法忽略了关系的结构特征和相互关系实体在关系匹配中的文本重要性。其次,为EA和RA之间的相互迭代增强设计一个集成的框架提出了重大的挑战。实体对齐需要利用多个关系来实现更健壮的实体表示。相反,关系对齐需要考虑相互连接的实体,以有效地捕获与关系相关的上下文细微差别。在统一框架内平衡这些需求是一项复杂的任务,需要考虑实体和关系对齐的不同特征和目标。为了应对上述挑战,我们提出了一个新的集成框架,用于EA和RA之间的相互增强,称为EREM。EREM由两个模块组成:实体匹配(E-step)模块和关系匹配(Mstep)模块,定义为变分期望最大化框架。在e步骤中,使用RA学习到的关系锚点对EA进行优化,目标是最大化实体锚点对应。在m步中,通过利用EA预测的实体锚点来优化RA,目的是最大化关系锚点之间的对应关系。EA和RA的匹配过程被表述为最优运输(OT)对齐任务,该任务通过Sinkhorn算法有效解决。在几个广泛使用的数据集上的实验结果证明了我们提出的框架的优越性能。值得注意的是,七种SOTA EA方法可以无缝地集成到EREM中,一致地显示性能改进。本文的贡献有三个方面:•据我们所知,我们是第一个将关系对齐概念化为一项独立任务的人。“完整的”知识图谱对齐任务被分解为两个不同但高度相关的子任务。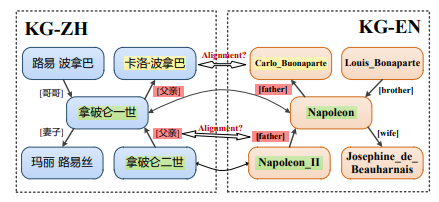
2. 方法
本节提供了拟议的EREM框架的详细说明。EREM包括三个基本组件:混合嵌入模块、实体匹配模块和关系匹配模块。混合嵌入模块负责将实体和关系编码到低维表示空间中,并生成实体锚点和关系锚点的初始集合。实体匹配模块和关系匹配模块旨在对齐跨kg的实体和关系,这两个匹配模块通过在e步(EA)和m步(RA)之间交替的迭代过程进行联合训练。
现有的EA模型采用了各种类型的实体编码器,包括纯基于文本的模型(例如BERT、RoBERTa和DeBERTa)以及关系感知模型(例如TransD、TransH、TransR、PTransE)。为了适应这种多样性并增强通用性,构建了混合嵌入模块以支持多种类型的实体和关系编码器。对于实体,该模块集成了基于文本和关系感知的编码器。关系的嵌入是通过使用多语言语言模型对其标题进行编码来学习的。形式上,所选择的嵌入模块g旨在将实体e和关系r嵌入到嵌入 和 中,具体如下: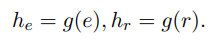
混合嵌入模块能够利用不同的编码器类型,从而促进所提出的训练框架的泛化。
这项工作将EA任务定义为最优运输(OT)问题,其目标是最小化全球运输距离。给定G中有m个实体,G '中有n个实体,实体成本矩阵 ∈R m×n由实体嵌入矩阵 、关系感知矩阵 和实体结构感知矩阵 之和计算,OT对齐过程形式为: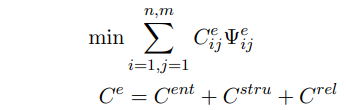
给定实体和关系锚点的输入,通过关系对齐来增强实体对齐的一种直接方法是根据对齐关系的条件获得高质量的实体锚点。这种方法的灵感来自于一个概率场景:“如果来自不同知识图的两个实体,共享相同的关系,连接到相同的实体,那么这两个实体很有可能是相同的”。这种概率场景强调了对齐关系在准确识别不同知识图中对应实体方面的重要性。鉴于我们的对齐目标是最大化基础真值对应,我们的工作将我们的实体对齐目标制定为最小化实体锚点和关系感知硬实体锚点的负对数似然。因此,EA的优化函数为: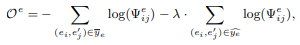
3. 实验
DBP15K_ZH-EN数据集包含997对对齐关系对,而DBP15K_JAEN和DBP15K_FR-EN数据集分别包含684对和274对对齐关系对。表1提供了这些数据集的详细信息。为了验证EA和RA任务,我们的工作手动标记了DBP15K数据集中的数据以进行关系对齐。
根据之前的研究(Yang et al., 2021), EA和RA的评价指标包括Hits@k (k = 1,10)和Mean Reciprocal Rank (MRR)。
我们的工作采用七种竞争性的KG对齐方法作为基线,包括基础的基于KG的技术和最新的先进方法。keg、GCNAlign、RotatE 和BootEA 是基于keg的方法。BERT-INT是基于SOTA bert的方法。FGWEA采用“嵌入模块和实体匹配模块”策略,即SOTA无监督方法。将法学硕士纳入我们的工作中,我们的工作利用ChatGLM-6b构建了一个基础模型。
我们的工作使用Pytorch实现了我们的框架。对于我们的方法,常见的超参数如下:嵌入模块可以是LaBSE、keecg、BootEA、RotatE和GCN-Align,其嵌入维数为768、128、75、200和100。我们的工作更新了EA OT对齐的8次迭代(T = 8), RA OT对齐采用Sinkhorn算法求解(熵正则化权值设为0.1)。λ设为1e-5。λ设为1。奖励α设置为2。使用LaBSE作为嵌入模块,将实体和关系的名称和属性信息编码为文本语义向量。对于keecg, BootEA, RotatE和GCN-Align, 30%的监督标记实体信息被删除以构建测试集,以防止在验证阶段数据泄漏。在我们的实验中,我们的工作没有使用DBP15K的翻译版本。我们的实验是在使用GeForce GTX 3090 GPU的工作站上进行的。
实体对齐的性能分析。所有模型在实体对齐任务上的结果如表2所示。从结果来看,我们的工作有以下发现。与所有三个数据集上最强基线FGWEA相比,我们的EREM在Hits@1上实现了0.1%至0.4%的相对改进,在Hits@10上实现了0.1%的相对改进。对于BERT-INT, EREM在Hits@1上实现了0.4%到2.9%的相对改进,在Hits@10上实现了0.2%到1.0%的相对改进。基于kge的模型可视为嵌入模型,并使用EREM对其进行优化。通过EREM, keecg可以提高平均Hits@1分数34.2%,GCNAlign可以提高平均Hits@1分数33.6%,RotatE可以提高平均Hits@1分数25.4%,BootEA可以提高平均Hits@1分数27.9%。ChatGLM6b可以将平均Hits@1分数提高5.6%。这些改进证明了我们的建议的优越性,以及利用EM优化联合训练EA和RA的有效性。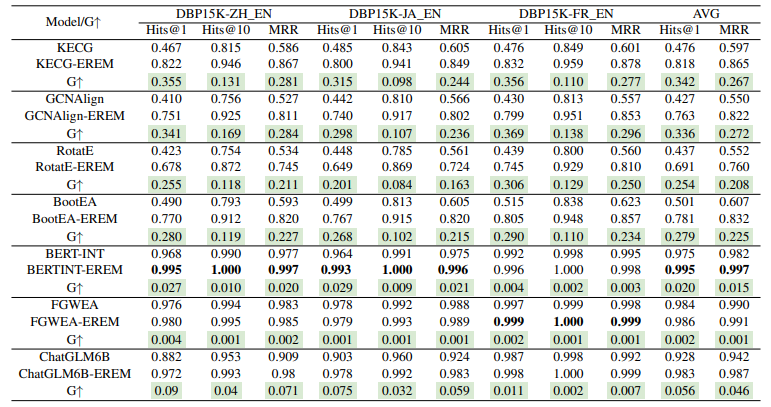
4. 总结
EREM主要由实体匹配模块和关系匹配模块组成,使用EM优化框架对EA和RA进行多重增强。EREM通过e -步骤和m -步骤交替更新EA和RA。在每个步骤中,EA和RA都通过学习其他模块预测的锚点来相互增强。此外,我们的工作将llm应用于eem并设计CoT策略。在EA和RA验证数据集上进行的大量实验证明了EREM的有效性和效率。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
