2024 年 8 月 26 日,数据管理与数据库领域顶级国际会议 VLDB 2024 在广州举办,蚂蚁集团知识引擎团队的论文《KGFabric: A Scalable Knowledge Graph Warehouse for Enterprise Data Interconnection》被收录为 Industry track 的现场展示论文 (Oral Paper)。
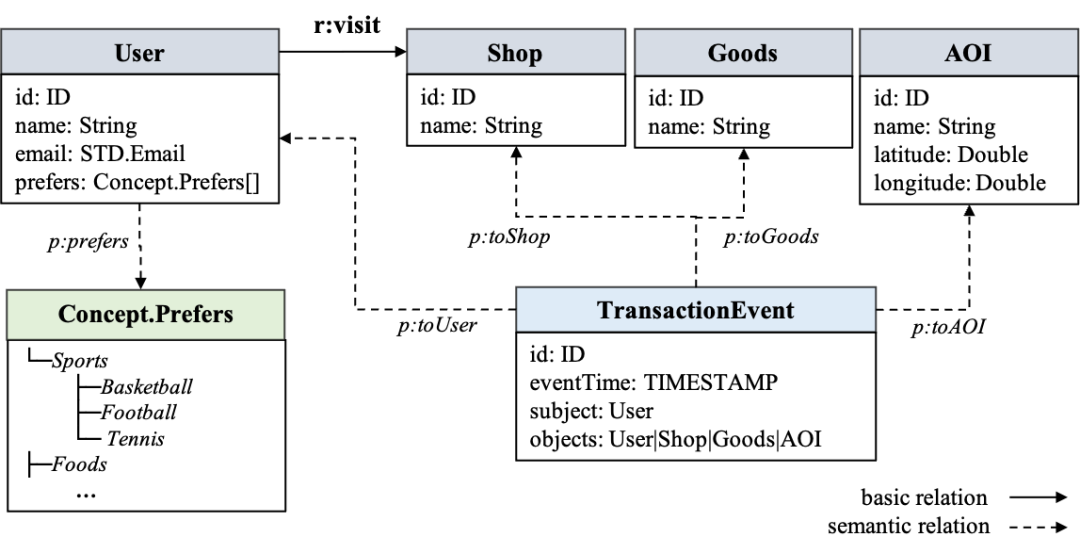
KGFabric 是一种基于分布式文件系统(DFS)的全量知识仓储的解决方案,使用 SPG 作为数据模型,能够更好地表达真实世界,同时优化存储和计算效率。KGFabric 支持 Graph Fabric 能力,在保护用户隐私的同时支持多域图谱的融合,有效解决了知识图谱数据孤岛的问题。与流行的关系 DBMS 和图数据库相比,KGFabric 语义关系的存储空间减少了 90% 以上。在实际工作负载中,图融合的性能提升了 21 倍。在多跳语义图分析中,KGFabric 的性能提高了 100 倍。在蚂蚁集团内部的实践中,我们构建了蚂蚁知识图谱平台。它构建了与商户、公司、账户、产品等相关的众多领域特定知识图谱,管理着数万亿的结构化知识图谱,服务于搜索、推荐、风险控制等业务。提供基于跨领域知识复用的多种企业级知识管理能力,满足多样化图谱业务的自助接入,并支撑了多种下游服务和图推理、图分析应用,线性扩展支撑规模超千亿量级。在平台建设迭代的过程中,随着跨域图谱融合、图匹配和图表示学习等任务对系统能力的要求日渐增高,现存的数据仓库系统(例如ODPS)和图数据库越来越难以满足需求。因此,我们提出了超大规模知识仓储的解决方案KGFabric。KGFabric 采用 SPG(Semantic-enhanced Programmable Graph,语义增强可编程框架)作为数据模型,基于分布式文件系统(DFS)提供了原生知识图谱存储和多域知识图谱融合能力。KGFabric 为底层文件存储设计并实现了一套混合存储格式,在设计之初就考虑到同时兼容多种图模型和超级点(super-vertex)的存储和处理,并且分别为属性图和语义图实现了 CSR 索引和三元组索引。在底层完全使用 POSIX API 来实现文件 I/O 操作,实现了低成本的多云环境部署。KGFabric 使用 SPG 作为数据模型,其语义与属性图兼容。SPG(Semantic-enhanced Programmable Graph,语义增强可编程框架) 是一种基于属性图的语义框架,来自于蚂蚁知识图谱平台支持金融领域业务的多年沉淀。它创造性地融合了属性图结构性与 RDF 语义性,既克服了 RDF/OWL 语义复杂无法工业落地的问题,又充分继承了属性图结构简单与大数据体系兼容的优势。为了更好的增强属性图中对于节点类型的语义表达,SPG 在属性图的节点类型和边类型之上扩展并引入更多主体分类模型对节点类型进行扩充以兼容更加多元的知识表示。实体:业务相关性比较强的客观实例,通过实体 Properties (属性、关系)刻画个体画像,如用户、企业、商户等。例如下图中的 User 包含若干属性且与 Shop 相连
概念:实体从具体到一般的抽象,表述的是一组实体集合、一种分类体系。相对静态、具有较强复用性,如人群标签、领域标准类型等。例如下图中的 Concept.Prefer
事件:加入时间、空间、标的等约束的实体类型,如通过 NLP、CV 等抽取出来的行业事件、企业事件、诊疗事件等。例如下图中的 TransactionEvent 事件类型
KGFabric 的存储架构基于 LSM-Tree,数据层次分为 Base 和 Delta 两层,其中 Delta 层被进一步划分为 Level-0 和 Level-1,其中 Delta Level-0 为流式导入(mini-batch)优化。例如从消息队列导入;Delta Level-1 主要考虑批量导入场景,例如从 Hive 或 ODPS 导入。为了平衡读放大,我们在后台运行 Tiering Compaction,定期将重整并压实(compact)数据。在蚂蚁集团内部,每天有超过 1000 个数据导入任务,在实际生产场景中,该 Compaction 策略将随机读和顺序读的读放大分别控制在 5 倍和 1.6 倍以下。KGFabric 主要分为几个主要的目录层级:
Namespace:业务数据管理的基本单位,用于实现不同领域图谱的数据隔离
RelationGroup:管理图谱数据分组,通常基于实体、关系或事件时间切片来分组
Base:管理周期性快照数据
KGFabric 的版本管理依赖文件系统的 put-if-not-exists 语义,使用 VersionPointer 机制解决读写冲突。当一次导入任务成功后,KGFabric 自动创建新的版本文件,通过时间戳映射相应版本文件,可实现任意快照访问,current 文件总是记录最新数据版本。
实际的图谱数据承载 RelationGroup 目录中,它包含了若干数据文件和对应的元数据。数据文件包括 PGFile 和 SGFile,它们分别存储属性图数据和语义图数据,布局如下图所示:PGFile 和 SGFile 都由 Footer 和文件内的 BlockIndex 组成,不同的是它们内部分别存储 PGBlock 和 SGBlock。PGBlock 和 SGBlock 是基本的写入和压缩单位。我们主要采用 PGBlock 存储属性图。在 PGBlock 内部包括点边(VertexTable)和边表(EdgeTable,包含出边和入边)和属性表(PropertyTable),我们采用了 CSR 索引格式进一步压缩子图数据。属性表支持行或列存储格式,并且使用了位图矩阵来标识 NULL 值属性。PGBlock 内,我们通过点切分的方式将超级点(度数很高的边,通常超过 10 万)的稠密边分配到若干个 PGBlock 中分别存储。如下图所示,vid2 在 block#1 和 block#95 分别触发了两次切分逻辑。基于以上逻辑,我们解决了超级点在加载和计算的内存瓶颈问题,提升了按关系类型加载边时分组 limit 的 I/O 效率。在 KGFabric 中,语义图的存储包含三个存储组件: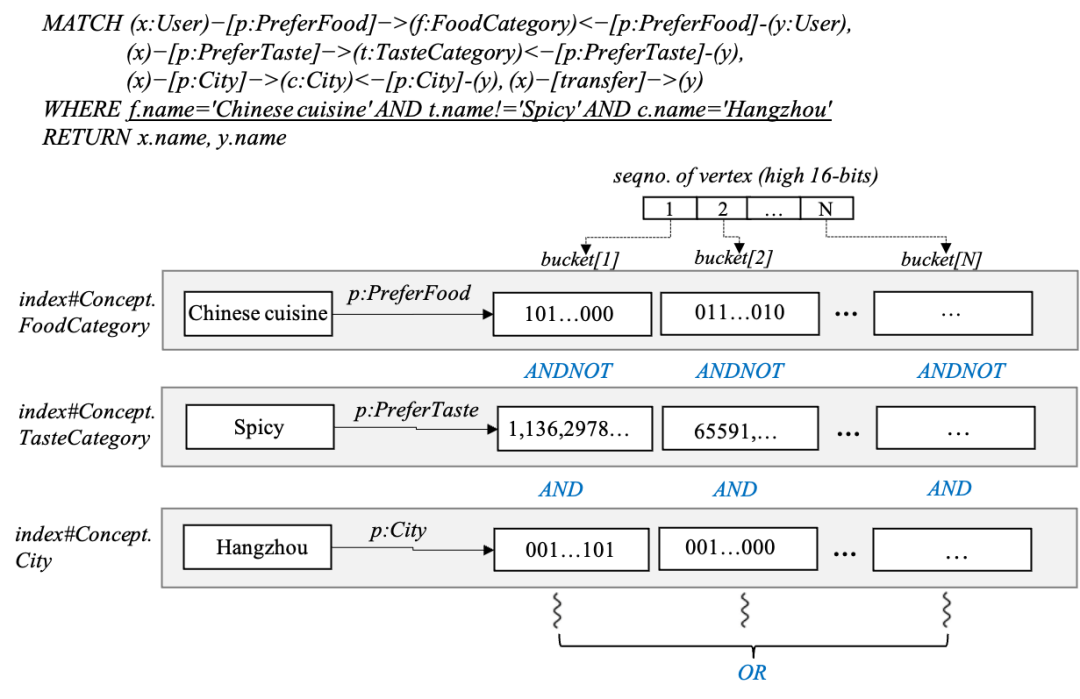
传统的 Data Fabric(数据编织)大多是基于数据冗余实现的,这通常意味着跨集群之间数据拷贝。在 KGFabric 中我们实现了一套 Graph Fabric 框架,在避免冗余拷贝的同时实现了多域图谱融合。只需通过选取待融合的实体类型,再指定链指或融合算子,Graph Merge Tree(GMT)便可自动构造出虚拟类型 FuseType,用户可透明地使用该虚拟类型实现基于 Fuse-On-Write(FOW)或 Fuse-On-Read(FOR)的图谱融合。GMT 是实现 Graph Fabric 的核心数据结构,在逻辑上它是一棵多叉树,FOR 的过程实际上可以抽象为对树的后序遍历。在后序遍历中,我们还集成了 AntPrivacy API,在 Graph Fabric 执行之前,对数据进行属性粒度的加密,能够有效的在图谱融合过程中确保用户数据安全。
为了优化金融场景下的负载性能,KGFabric 可以作为图分析系统的存储后端,提供原生图检索和图加载能力,避免了分布式构图场景下 shuffle 的额外开销。KGFabric 实现了以下优化:为了评估系统性能,我们进行了存储空间,图分析效率和 Graph Fabric 扩展性实验。我们主要选用了 LDBC-Finbench 作为属性图(LPG)数据集,并且通过为 LDBC-Finbench 添加语义关系,扩展了新的数据集 LDBC-Finbench-X 作为语义图(SPG)数据集。另外我们从生产场景选取了用户图谱、商户图谱和资金图谱作为真实数据集。数据集规格如下:对属性图数据集,KGFabric 的存储空间占用仅有 Neo4j 的 43.7%,为 RocksDB 的91.7%。对语义图数据集,KGFabric 得益于对强 schema 建模,大幅优化了语义关系的存储开销,空间占用仅为 RocksDB 的 7%,Neo4j 的 1.9%。我们主要选用了 pairwise path 和 cycle pattern 两种典型的图分析任务,主要对比对象是 ODPS、Neo4j 和 RocksDB。在 pairwise path 实验中,随着分析任务跳数的增多,KGFabric 提供的 backend 可以大幅度提升图计算的扩展性。 在 cycle pattern 实验中,受益于低构图成本,KGFabric 最多可以将 3 跳环路分析的耗时降低 67.8%。对于默认链指策略(IDE),随着数据源的增多,相较于 ODPS,KGFabric 表现出了良好的扩展性。为了优化性能用户自定义链指策略(UDL)的性能,我们实现了 rindex,对数据的预排序,进一步降低了延迟。
在 cycle pattern 实验中,受益于低构图成本,KGFabric 最多可以将 3 跳环路分析的耗时降低 67.8%。对于默认链指策略(IDE),随着数据源的增多,相较于 ODPS,KGFabric 表现出了良好的扩展性。为了优化性能用户自定义链指策略(UDL)的性能,我们实现了 rindex,对数据的预排序,进一步降低了延迟。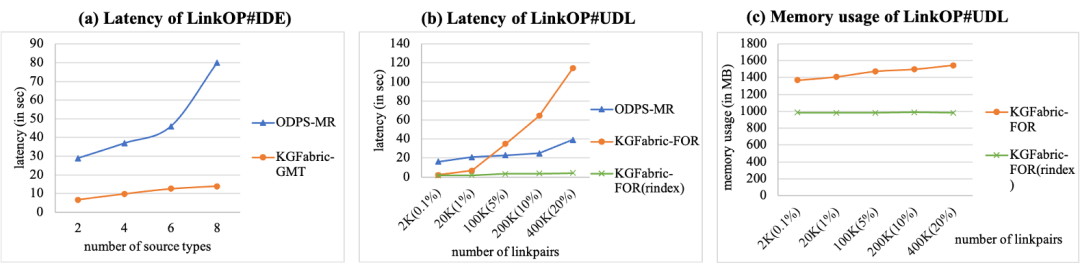

































 粤ICP备17114055号
粤ICP备17114055号