随着LLM技术的蓬勃发展,生成式AI领域具有前所未有的发展机遇,其中以ChatGPT为代表的大语言模型给人们带来了惊喜的同时,也将AI浪潮推向了最高峰。
ChatGTP、LLaMA2等通用大模型具备优秀的推理性能,但在面对复杂多变的业务场景时,往往难以满足多样化的需求。ChatGPT等通用大模型通常需要经过复杂漫长的训练过程,预训练期间需要巨大的算力和存储消耗,大多场景下从0到1训练一个模型不仅成本高昂,而且没有必要,因此基于预训练的模型并对其进行微调成为有价值的研究方向。微调预训练的通用大模型,不仅可以节约成本,也可以使模型更符合特定领域的需求,变得更定制化、专业化。如下图所示,用户基于预训练的基础模型采用合适的微调技术,以定制化的数据集作为输入,经过微调训练最终可输出一个性能更优的微调模型。本文主要调研并梳理了LLM微调常规流程及常用技术,其中介绍了Fine-Tuning(全量参数微调)及Parameter-Efficient Fine-Tuning(高效参数微调),RLHF(基于人类反馈的强化学习),Fine-Tuning全量参数微调成本巨大,应用较少。鉴此本文重点介绍Adapter、Prefix Tuning、LoRA、RLHF 4种常用微调技术的原理,通过归纳整理相关论文及资料,为模型微调工作的技术选型提供参考。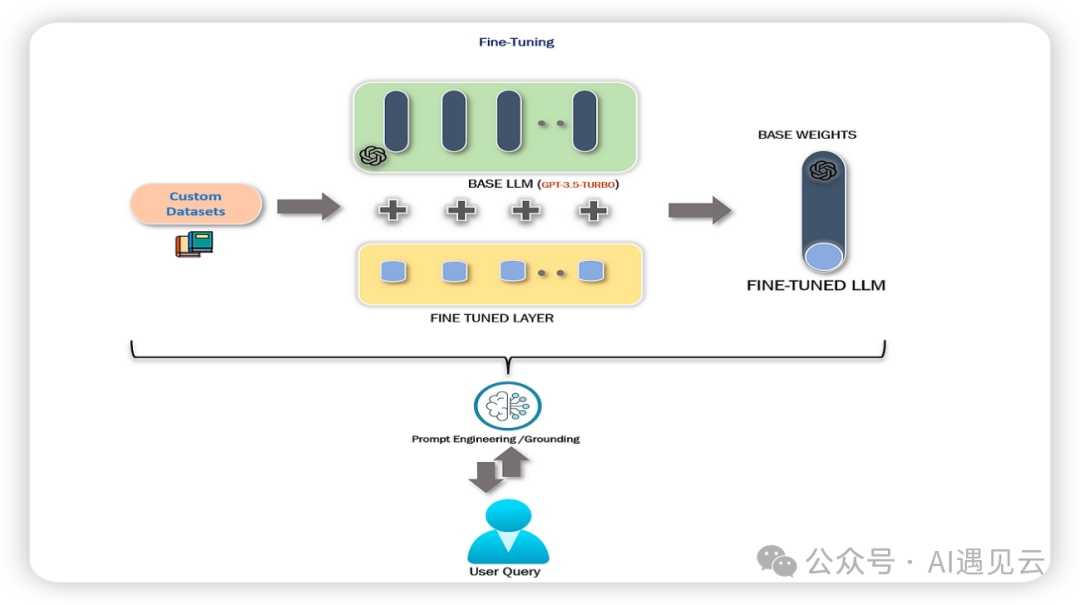
首先对模型微调下个非严谨的定义,大模型微调(Fine-tuning)是指在预训练模型基础之上,采用标注的高质量数据集或基于人类反馈机制对基础模型进行训练,最终输出具备或增强特定领域能力模型的技术。
据国盛证券报告《ChatGPT 需要多少算力》估算,GPT-3 训练一次的成本约为 140 万美元,对于一些更大的 LLM(大型语言模型),训练成本介于 200 万美元至 1200 万美元之间。以 ChatGPT 在 1 月的独立访客平均数 1300 万计算,其对应芯片需求为 3 万多片英伟达 A100 GPU,初始投入成本约为 8 亿美元,每日电费在 5 万美元左右。因此全量训练极其高昂,一般企业难以承受。例如,通用的语言大模型,经过高质量的医疗数据训练,可更加专业的进行医疗对话。在面对“感冒了怎么办?”之类的专业问题,微调前的模型回答可能相对宽泛,比如多喝水,症状严重时注意看医生等,但微调后的模型会基于与用户的多轮对话上下文,给出更精准、更专业的回答,经过医疗数据集微调后的模型,在面对医疗专业知识领域时,将具备更优的性能。经过微调后的模型具备更强的专业能力,诸如在问题回答、语言生成、命名实体识别、情感分析、摘要生成、文本匹配等领域具备更优的性能。例如,基于财经新闻数据的预训练模型经过微调后能够在金融分析、股票预测等领域表现出色;基于医疗数据的预训练模型经过微调后能够提供患者更精准的医疗咨询和用药建议。模型微调后将具备更专业化、特定化的推理能力。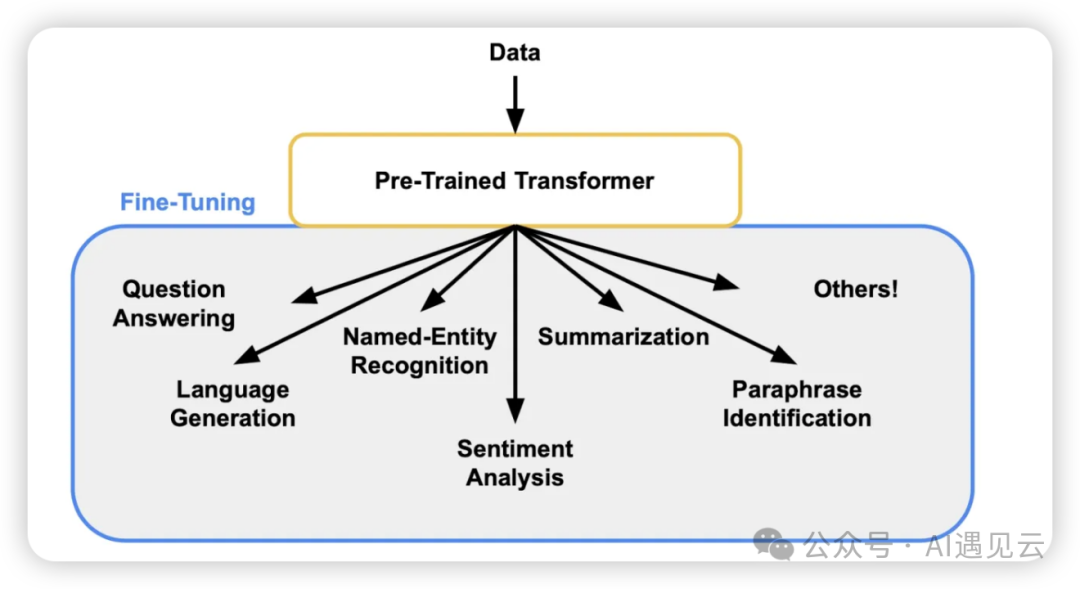
模型微调是一个循序渐进、不断优化迭代的系统工程,一般需要经过模型选取、任务定义、数据准备、策略选择、模型配置、模型微调、结果评估、优化迭代、模型测试、模型部署等流程,通过系统化、流程化的模型微调,将输出令人满意的结果。具体步骤简述如下:
模型选取
选取一个优秀的基础大模型,比如OpenAI的ChatGPT,Meta的LLaMA2等,成熟的大模型有大厂背书及活跃的社区支持,可以具备高质量的模型能力。
任务定义
定义一个特定领域的任务,比如上文所述的医疗问答任务。
数据准备
收集标签化的专业数据,比如上文的医疗问答数据可分为训练集和测试集,一部分用于训练,一部分用于测试。
策略选择
选择合适的模型微调策略,比如下文将详细描述的PERT或RLHF,选择更适合的微调技术。
模型配置
以第一步选取的基础模型作为起点,完成模型微调前的前置配置。
模型微调
基于选择的微调技术,不同不断的迭代训练模型,期间不断调整参数并监控模型的损失函数即精准度。
结果评估
使用测试数据集验证微调后模型的优劣
优化迭代
基于上一步评估的结果,不断迭代微调过程直到达到满意的预期效果。
模型测试
使用验证模型的性能。
模型部署
将微调后满足预期的模型部署后等待投入推理使用
Fine-Tuning指的是全量参数微调,训练时间成本高。一般较少使用,因此本文重点介绍高效参数微调,通过冻结参数,局部微调,显著提供微调效率。
- 在《Parameter-Efficient Transfer Learning for NLP 》论文中提出了Adapter方法,论文指出对预训练模型每层中插入下游任务参数,微调时冻结模型主体参数,仅训练特定任务的参数,最终显著减少训练过程中产生的算力成本。为论证Adapter方法的有效性,论文作者基于BERT Transformer模型,对26种类别的文本任务进行GLUE基准测试,最终Adapter展示了令人满意的效果,在GLUE基准测试中,相比较于100%的全量参数微调,每个任务在仅添加3.6%参数的情况下,仅有0.4% 以内的性能差异。如下图所示,Adapter结构在Transformer Layer中加入Adapter Layer,位置分别位于多头注意力的投影之后及第二个前馈层之后,训练时固定原始预训练模型参数,仅对新增的Adapter及Layer Norm层进行微调。其中每个Adapter 由2个Feedward前馈层组成,首个前馈层接受Transformer输出作为输入,通过将高维特征d投影至低维特征m以控制模型参数量,低维特征m经过中间非线性层输出,第二个前馈层将低维特征m反向还原为高维度特征d,最后作为Adapter的输出。
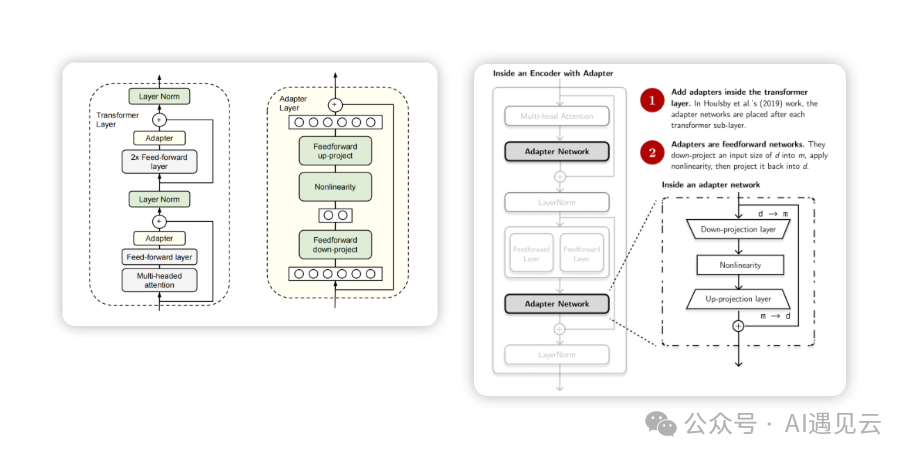
经实验结果表明,通过添加并训练少量参数,Adapter方法的性能可媲美全量微调,论证了Adapter方法可作为一种高效的参数微调方法。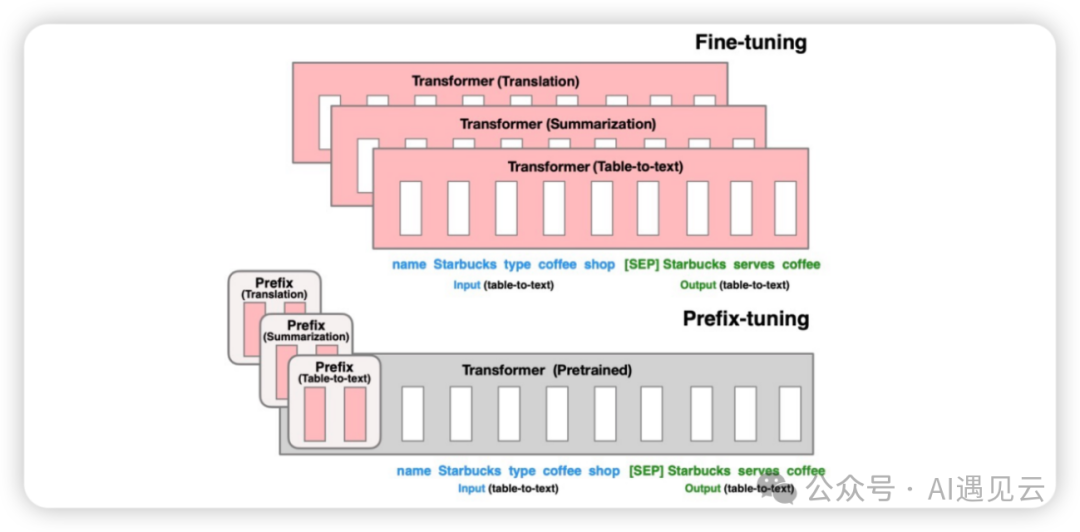
对于Decoder-only的GPT,prefix只加在句首,模型的输入表示为:
对于Encoder-Decoder的BART,prefix同时加在编码器和解码器的开头:

如下图所示,在下游任务微调时,模型参数被冻结,之后Prefix部分参数被更新,显著提高训练效率。
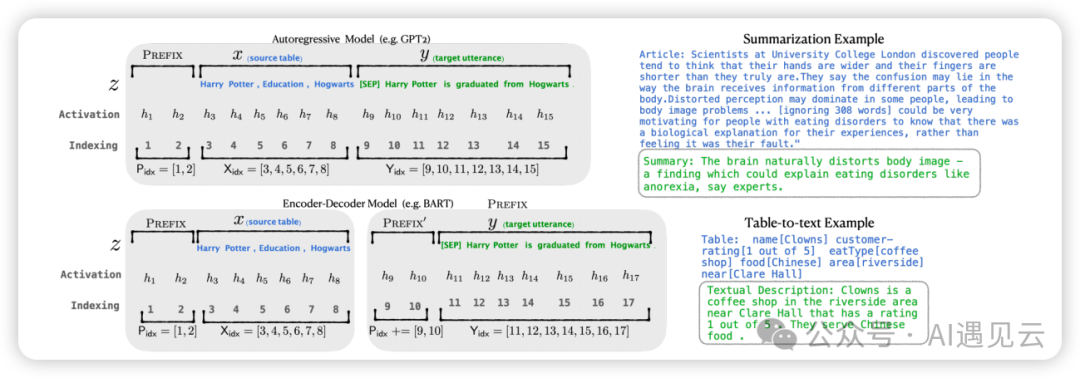
Prefix Tuning通过输入序列的前缀加入prefix token,引导模型模型提取x特征相关的信息,以便更好的生成结果y。训练微调过程中,我们只需要冻结模型其余参数,仅单独训练prefix token相关参数即可,每个下游任务均可单独训练一套prefix token,Prefix-Tuning虽然过程看似方便,但也存在以下弊端:- 原始论文指出,训练模型的效果并非严格随prefix参数量单调递增
- 为节省计算量和显存,我们一般会固定数据的输入长度,增加prefix之后,留给原始文本数据的空间会被挤压,因此可能会降低原始文本prompt的表达能力,使得输入层有效信息减少。
Prefix Tuning训练难度大,那是否有其他的微调方法呢?LoRA(Low-Rank Adaptation)是微软研究团队提出的一种通过冻结预训练模型参数,在Transformer每一层中加入2个可供训练的A、B低秩旁路矩阵(其中一个矩阵负责降维、另一个负责升维),可大幅减少微调参数量的方法。LoRA整体架构如下图:
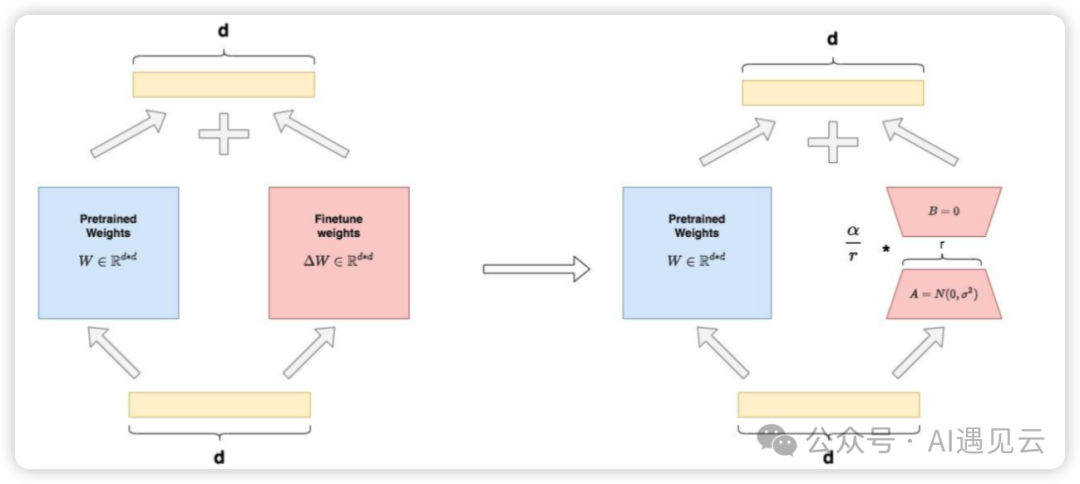
全参微调可视为冻结的预训练权重W+微调过程中产生的增量更新权重 ,假设输入为x,输出为y,则有 。
如图右侧表示LoRA微调场景,我们用矩阵A和矩阵B近似表示 :
- :低秩矩阵A,其中r被称为“秩”,对A进行高斯初始化。
经过拆分,我们将 改写成 的等价形式,微调参数 从降为 ,同时不改变输出数据的维度,即在LoRA下我们可以定义为: 。
其中,论文指出对于AB两个低秩矩阵,会使用超参α(常数)来做调整,以适配更优的微调性能。基于LoRA架构,在原始预训练矩阵的旁路,我们用低秩矩阵A和B来近似代替增量更新权重 ,训练过程中通过固定预训练权重 ,只对低秩矩阵A和B进行微调训练,可大幅提高效率,据论文统计,采用LoRA方法在微调GPT3 175B时,显存消耗从1.2TB降至350GB,极大的降低了训练开销。
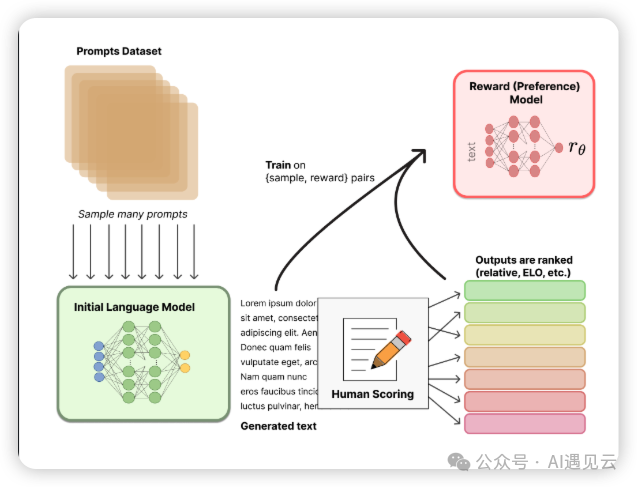
RLHF(Reinforcement Learning from Human Feedback)是基于人类反馈的强化学习。传统基于prompt提示词生成的结果相对主观并依赖上下文,缺少人类的偏好和主观意见。RLHF中使用人类反馈作为性能衡量标准,不断通过反馈结果来优化模型,可使训练后的模型更符合人类预期。RLHF涉及多个模型和多个训练阶段,一般分为以下3大核心步骤:- 使用标注过的数据来调整预训练模型参数,例如OpenAI在其InstructGPT中采用较小版本的GPT-3,Anthropic使用1000万-52B参数的Transformer进行训练使其更好的适应特定任务领域。
- RM奖励模型用于评估文本序列质量,它接收一系列文本并返回数值,数值对应人类的偏好程度。训练数据通常由多个语言模型生成的文本序列组成,这些序列经过人工评估或使用其他模型(比如ChatGPT)进行打分。奖励模型不断指导模型生成更符合人类预期的高质量文本。
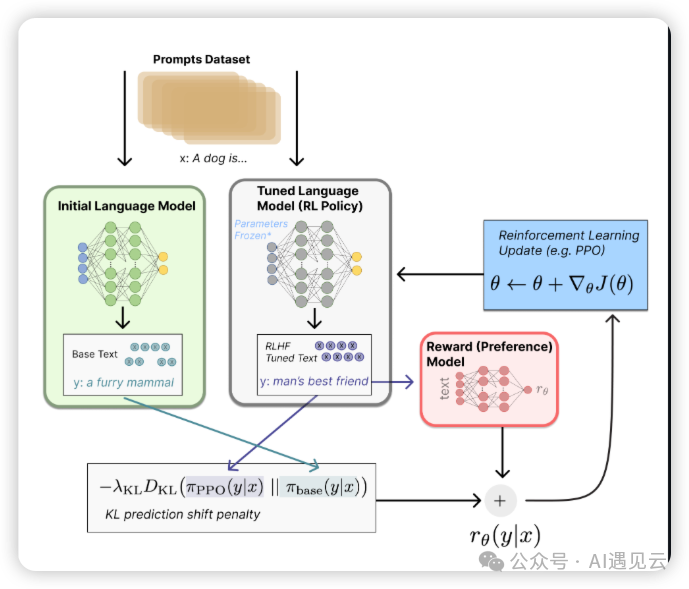
- 利用上一步输出的奖励值,采用强化学习进一步微调,在强化学习中需要定义状态空间、动作空间、策略函数及价值函数。其中,状态空间使输入的序列分布,动作空间是全量的token(词汇表中的词),价值函数基于奖励模型的输出和策略约束,用于评估给定状态下采取特定动作的价值,策略函数根据当前状态选择下一个动作(token),最大化奖励。
本文重点介绍了几种常用微调技术,各种技术的特点描述总结如下表所示:

模型微调过程中可根据实际场景选择合适的微调方案,以获得更优的性能。

































 粤ICP备17114055号
粤ICP备17114055号