
如果只能选择“能”或者“不能”来回答这个问题,我倾向于选择“不能”。当然这样的回答比较粗暴,这句话需要加上一些限定词:对于一些比较基础的任务,GPT3.5 的性能的确有改善,只是多 Agent 机制对 GPT3.5 的提升,相比于作用在 GPT4 之类的模型上,可能仍然不够明显。多个 GPT4 合作的效果:三个臭皮匠顶个诸葛亮。?多个 GPT3.5 合作的效果:三个和尚没水喝。?
玩笑话,大模型们不要往心里去~(这里的 GPT3.5 也许替换成其他比较弱的模型也成立。 )不过首先,这只是我做测试后的主观感受,其次结论都只是噱头,实际经验比套用结论更重要。在上一次复杂意图识别的测试中,原本 GPT4 的识别经常出错,但在添加了反思节点后能做到几乎 100% 准确。但是 GPT4 确实响应时间太长,而且 token 更贵,因此我希望测试多 Agent 机制能否让 GPT 3.5 达到更好的效果,毕竟 GPT4 响应一次的成本够 GPT 3.5 跑好几个来回了。这篇文章我会分享基于一些研究多 Agent 辩论(Multi-Agent Debate)的论文,所进行的简单测试,尽管不能完全照搬实现,但这些论文仍然为制作 bot 提供了一些新的思路。最后会附上论文中使用的部分 prompt,方便大家应用到自己的 bot 中。吴恩达前两天把他的 Agent 设计范式系列更新完了,最后一篇关于多 Agent 协作的文章提到,这种模式主要是把复杂任务分解成为不同的子任务,并让大模型扮演不同的角色执行。https://www.deeplearning.ai/the-batch/agentic-design-patterns-part-5-multi-agent-collaboration/超长 prompt 确实很容易令大模型迷失自我,这一点大家多少都有感知。一般来说将它拆解、转化成步骤清晰的工作流之后,bot 性能就会有明显改善。那么,在“拆解复杂任务”的意义上,多 Agent 协作其实可以看作是一种升级版的工作流。比如说扣子官方公众号提供的这个多 Agent 实例。但就多 Agent 模式而言,我觉得它还有一个更关键的地方,就是能让 Agent 之间形成真正的交互,而不是下一个 Agent 单纯、被动地接收上一个 Agent 的输出。就好比在真实的人类场景中,你会对其他人的工作表达赞同、反驳,或者提取综合意见。这也是为什么我在多 Agent 领域的论文中,主要选取了多 Agent 辩论(Multi-Agent Debate, MAD)来测试。论文 [1] 提供了一个最基础的 MAD 框架。(具体论文标题请查看结尾。)
1. 设置辩论的轮次数 M,每一轮都让各个 Agent 依次发言,并将当前发言结合之前的聊天历史一起传给下一个 Agent;
2. 每轮结束之后有个判定,是否获取到了想要的结果;
3. 最终整个 MAD 结束,要么是循环达到轮次 M,要么是判定成功。
A. 比如为辩论的 Agent 设定强反驳人设,让它总是更倾向于指出上一个 Agent 的错误而不是赞同,或者弱反驳人设;
B. 比如第一轮的每个 Agent 是单独发言,不受到其他 Agents 发言的影响,也就是不把前一个 Agent 的发言传递给它;C. 比如判定可以设置为检查所有 Agent 的意见是否达成统一,或者选用一个带有裁判人设的 Agent,让它综合意见进行判定。目前的 Agent 工具并不是很方便做循环,但我们仍然可以尽可能地模拟这个框架,并不难,具体实现可以跳到下一部分。这些论文提供了一些观察——这些结论最好是作为参考,而不是黄金法则,因为研究者并没有测试所有可能的场景:1. 辩论的轮次数 M 一般在 1~3 之间,迭代次数大于 3 之后,边际效益会下滑,甚至有可能极大降低模型的能力。可能是因为讨论越多,Agent 需要处理的历史对话上下文就越长。[1][2][3][4][6]2. Agent 数量也不是越多越好,论文中提到较合适的数值是在2~4之间。[4][6]3. 使用相同 prompt 设计出来的 Agents 表现不如使用多样化角色设计[4]。论文 [7] 提供了一个示范,比如在进行立场判定的时候,让 Agents 分别扮演语言学专家、领域专家和社媒达人来进行发言辩论。[6]探讨如何通过协作设计更好的多 Agent 系统,而不仅仅是盲目提升互动的规模和轮次。他们将系统中的 Agent 设定为两种主要的人设(下图左上角),一种是过于自信的,也即很难被说服,另一种则比较随和,能听得进意见,由此可以实现 4 种组合(下图左下角)。同时 Agent 的行动划分为反思和辩论类型(下图右上角),那么在不同轮次中可以将这两种行动随意搭配组合(下图右下角)。最终他们给出的结论是,以辩论为起始和以辩论为主的策略效果更佳。论文[1]和[8]还提供了对辩论强度更细致的研究,也即单个 Agent 在多大程度上对前一个输出提出同意或者反对的意见。可以使用这样一串 prompt 来进行调控:"You should agree with the other agents X% of the time."Agent 之间有多大概率产生分歧,会影响 MAD 的最终效果,但这种影响在不同的场景下趋势不一样,还是需要大家进行具体测试。我个人感觉,MAD 的关键在于通过辩论帮助 Agent 发现自己的视角盲区,以修正大模型过于自信的回答。这一点与反思的本质并无太大区别,只是看谁能更有效地发现错误。因此在我实际测试时,会要求它们输出思考过程,以便观察辩论是否有效。
我只进行了一些简单的测试,抛砖引玉,大家可以根据上面的框架自行调整。在翻译、数学题、井字棋几种场景下,MAD 可以解决一些原先单个 GPT3.5 无法回答的问题。比如像“吃掉敌人一个师”这种不能完全按照字面翻译的问题,和一些多步加减乘除的计算题。不过多数情况下性能没有什么提升。三个 Agent,第二个 Agent 会接收前一个的结果作为参考,并最终由裁判 Agent 进行评估判定是否要进行下一轮。其中输出包括结果和思考过程。
# 辩论角色: You are a debater. Hello and welcome to the translation competition, which will be conducted in a debate format. It's not necessary to fully agree with each other's perspectives, as our objective is to find the correct translation.
This is the first round, please translate user's {{input}} into English, and explain why you translate in this way, point out how you agree or disagree with debater1's opinion {{translation1}}, {{argument1}}. You should tit for tat. You can think step by step.
# 裁判角色: You are a moderator. There will be two debaters involved in a translation debate competition. They will present their translations and discuss their perspectives on the correct English translation of the given text {{input}} into English.
At the end of each round, you will evaluate each debater's translation submission, point out how you agree or disagree with their opinions, and then give your final judgement.
当然实际我提前搭建好了最多三轮辩论的结构,根据裁判 Agent 的结果通过 if-else 进行跳转。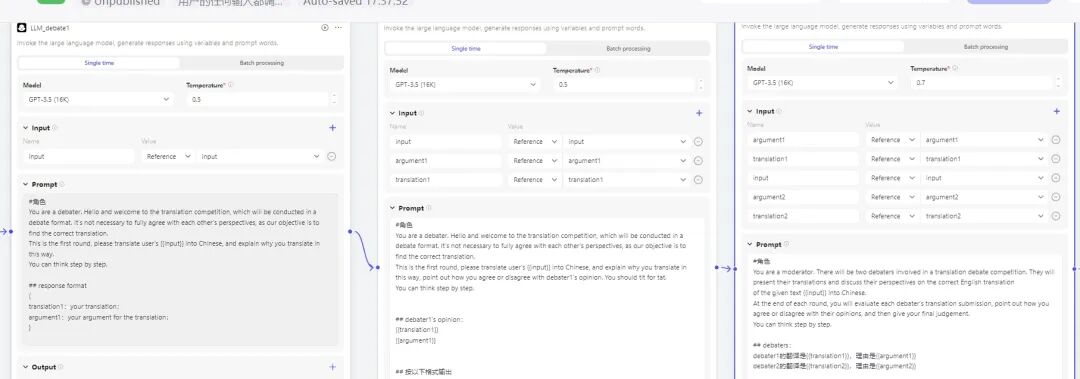
上面的 prompt 可以根据实际场景修改。在测试当中我发现 GPT3.5 最大的问题是偷懒,或者说对 prompt 不够敏感,不同 Agent 经常给出完全一样的回答。
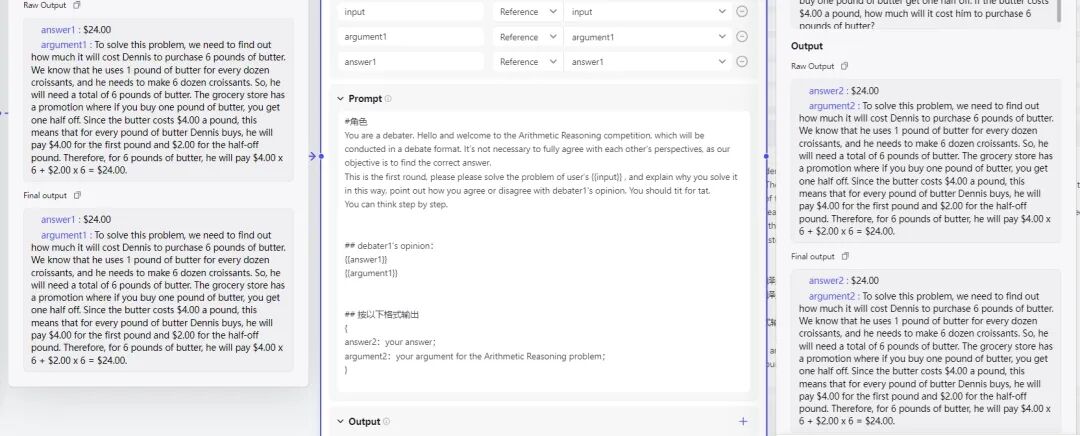
这意味着辩论完全无效。
于是我修改 prompt,强制要求后面的 Agent 提出反驳意见,而不是让它自行判断同意与否。还是有些用处,在下图的数学测试中,第二个 Agent 在思考过程中指出了前一个的计算错误,并进行了修正,最终得出正确答案。
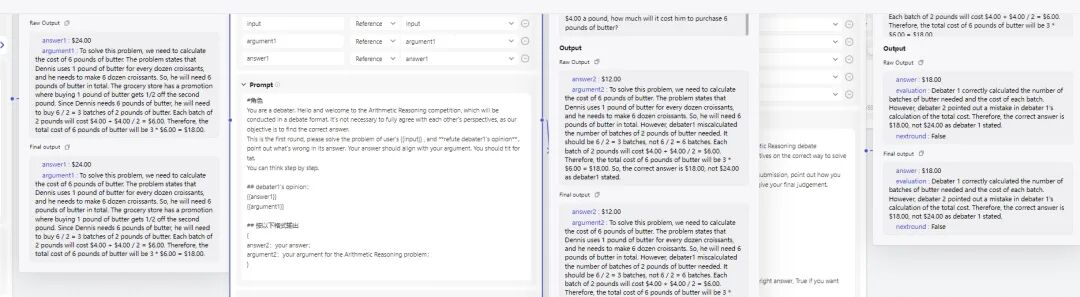
然而即便是强制要求提出反驳意见,GPT 3.5 也经常不执行。
另外一个问题是,裁判 Agent 从来不会判定要进行下一轮辩论,每次只经过一轮它就觉得已经找到正确答案了。
▍方法二:固定辩论两轮看最后能否达成统一意见。
如下示意图上下两行分别代表一个 Agent。第一轮两个 Agent 独立发言,第二、三轮分别接收前一轮对方的输出作为参考,并且拥有自己前一轮的记忆。同样是要给出结果和思考过程。

一般来说,三轮之后两个 Agent 都可以收敛到同一个结果,但由于在这个过程中 Agent 常常并不指出问题,所以我感觉这种收敛是因为将对话历史传给了大模型,它因此受到长 prompt 的影响而直接同意了对方观点。

因此,如果大模型不能在辩论中指出问题或者提供不同视角,那么终究都只是徒增 token 罢了。
事实上,即使 GPT3.5 指出前一个回答是错误的,它提供的缘由往往也含混不清。
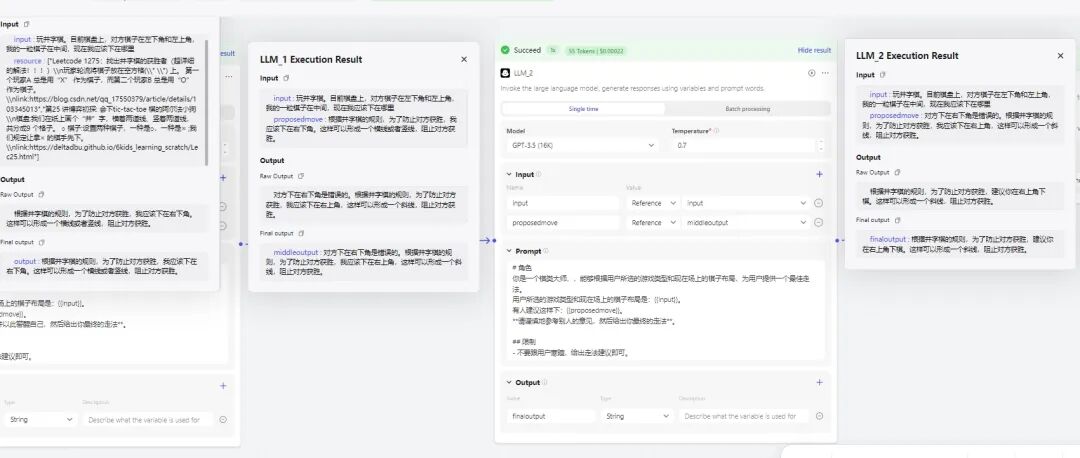

借助同一个问题我使用 Dify 测试了其他模型,都是第一步无法正确回答,但最终结果因为辩论有效性而产生区别:
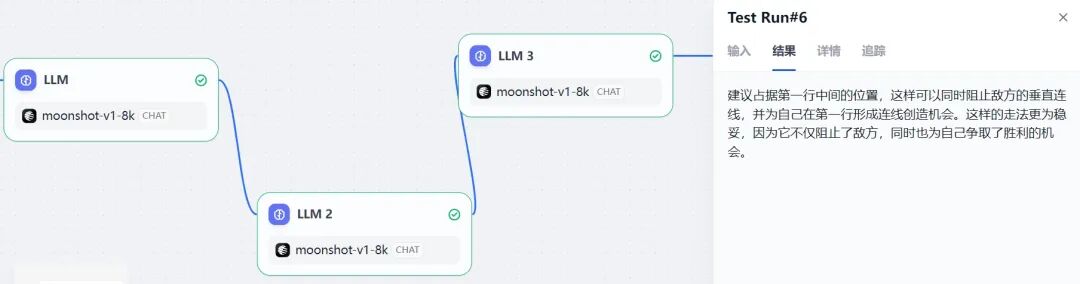
moonshot 有辩论,正确指出问题,结果正确。
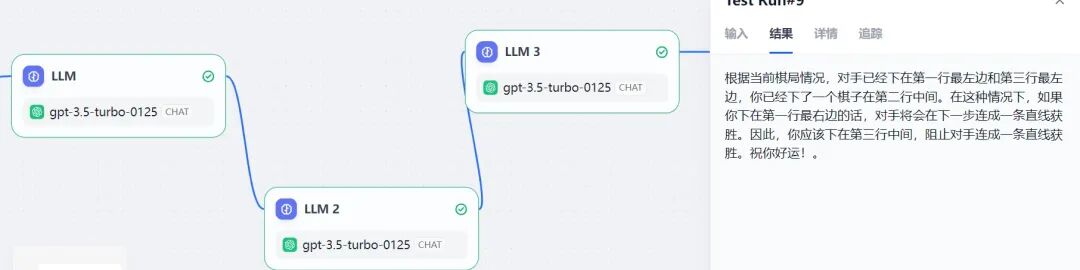
GPT3.5-turbo-0125 无辩论,结果错误。
结合反思这一篇,我现在一个总体印象是,这些模式都是在强大的模型上表现出色,但在较弱的模型上可能需要额外的改进或调整才能实现类似的效果。比如需要精细调整 prompt,让不同 Agent 之间的差异更明显,以更好地实现真正的互动。
当然 MAD 只是一种方式,可以选择性地将它跟工作流、prompt 工程,或者思维链(CoT, Chain of Thought)等等结合在一起,让 bot 输出更稳定有效。
欢迎大家分享自己的实践效果。
You are a debater. Hello and welcome to
the translation competition, which will
be conducted in a debate format. It's not
necessary to fully agree with each other's perspectives, as our objective is to find
the correct translation.You are a moderator. There will be two debaters involved in a translation debate competition. They will present their translations and discuss their perspectives on the correct English translation of the given Chinese text: {{input}}. At the end of each round, you will evaluate the candidates' translation submissions. Please consider the relevance and accuracyof their responses. Here is your discussion history:
{{chat history}}. These are the solutions to the problem from other agents: {{other answers}}. Using the solutions
from other agents as additional information, can you provide your answer to the math problem? The original
math problem is {{input}}. You are an expert skilled in solving mathematical problems and are objective
and unbiased, and you can be persuaded if other agent's answers make sense.Please keep this in mind. Imagine you are an expert in solving mathematical problems and are confident
in your answer and often persuades other agents to believe in you. Please keep
this in mind. If you understand please say ok only.Most of the debate should be characterized by disagreements, but there may
still be a small amount of consensus on less significant points. [1]Encouraging Divergent Thinking in Large Language Models
through Multi-Agent Debate[2]Improving Factuality and Reasoning in Language
Models through Multiagent Debate[3]CRITIC: LARGE LANGUAGE MODELS CAN SELFCORRECT WITH TOOL-INTERACTIVE CRITIQUING[4]CHATEVAL: TOWARDS BETTER LLM-BASED EVALUATORS THROUGH MULTI-AGENT DEBATE[5]How susceptible are LLMs to Logical Fallacies?[6]Exploring Collaboration Mechanisms for LLM Agents:
A Social Psychology View[7]Stance Detection with Collaborative Role-Infused LLM-Based Agents[8]Should we be going MAD?
A Look at Multi-Agent Debate Strategies for LLMs






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
