从22年底ChatGPT出现以来,AI一直都是最火的科技领域。作为一个兴趣广泛的中年人,在好奇心的驱使下,一直很积极在跟进和探索AI技术和应用。因为经常给身边的朋友安利AI产品,解答相关问题,在朋友圈中成了半个AI专家。由于我自己带着团队开发AI应用产品,也经常会研究技术架构和实现细节,分享的内容会有比较多种多样,常会被吐槽太过技术看不懂。。。无奈个人表达能力有限,一步步练吧。AI + 数据分析一直是非常有想象力的应用方向,早在AI爆火之前,NL2SQL就一直有大厂在研究。现在有更先进LLM的加持,AI + 数据分析更贴近实际应用,当然只能说在一些场景下很惊艳,但不完美。本文以Dataherald这个AI数据分析的开源项目为例,介绍一下实现Data Agent的思路,以及如何用LangChain和Dataherald实现一个Data Agent。构建AI数据分析的DataAgent简单可以分为三个主要的步骤:
- SQL-Generation:LLM根据用户输入的自然语言,以及数据库的相关Schema信息,生成查询SQL;
- SQL-Execution:利用数据库执行工具,执行上一步生成的SQL,返回得到的结果数据集;
- NL-Generation:LLM根据用户的问题,以及第二步得到的结果数据集,生成自然语言回答。
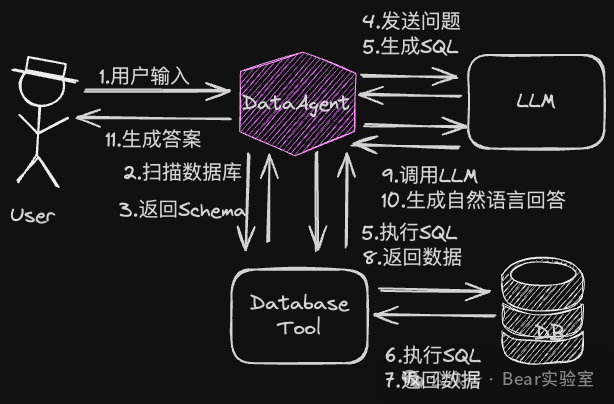
这里的核心是第一步的SQL-Generation,LLM在生成自然语言回答方面已经得到足够的验证,效果比较好。但生成SQL的效果一直差强人意,跟自然语言不通,SQL是一种强语法的数据库语言。一般人说话不会特别在意语法的问题,即使不符合语法,听的人也能理解,LLM很好的继承了这一点。此外导致生成SQL效果不佳的主要原因有:
- LLM基于数据预训练的,一般基础的LLM不会专门针对SQL的数据,所以对SQL的理解和生成质量不够;
- 缺乏相关领域知识,以及数据库的结构信息,哪怕是人类数据库专家,没有这些信息也写不出合适的SQL;
为了解决生成SQL的质量问题,现在比较常用的方式有这几种:
- 增加数据库Schema的信息和业务领域知识,比如说表名、字段名、类型、相关的备注等DDL信息,在生成SQL时作为SystemPrompt传给LLM。这个在上图的2、3这两步可以看到。给到LLM更多的数据库信息,更有利于生成SQL的准确性。但这里有两个地方值得说道:
- 补充Schema信息:一般数据库表在创建的时候,会有表和字段相关的备注信息。但都是很简洁的描述信息,这个对于人来说有时都过于简短,对于LLM就不是很友好。解决思路就是对数据库表和字段增加更详细描述信息,调用LLM时作为Prompt传入。这个可以是一个额外的信息维护,避免对数据库结构的侵入。
- 检索相关信息:另一个问题数据库可能会很大,表太多。LLM的Token窗口大小限制,没办法全部做为Prompt。解决思路是根据问题检索最可能相关的表,只把跟问题相关的表信息作为Prompt。
- 增加业务领域背景知识,基于RAG的工作流,也是先查询出相关的信息,特别是一些专业名词,KPI指标等,再构建Prompt。
- 增加优秀的问题和SQL对作为示例,利用Few-Shot Prompt和LLM的泛化能力,在Prompt中增加一些和用户问题相近的示例,这可以提高LLM生成SQL的准确率。示例的来源可以是专家整理好,再录入。也可以通过系统运行过程中,用户对生成SQL的反馈,反馈正面的示例经过专家确认就可以进入示例库。
- 微调Finetuning,可以针对自己的数据模型进行LLM的微调。利用收集的优秀的问题和SQL对示例作为样本,一般的商业化LLM服务都有微调的接口。
- 使用专门SQL的LLM,SQLCoder这是一款基于StarCoder微调的、针对SQL优化的大语言模型。Code Llama是一个开源的大模型,主要用于Text2SQL任务。本地跑Ollama还可以选DuckDB-NSQL的7B模型。
人设:你是一位数据库专家。目标:帮助开发者和数据分析师构建高质量、高效的SQL查询。
步骤:1. 定义查询需求: - 明确你需要从数据库中检索哪些数据。 - 确定数据之间的关系和需要应用的过滤条件。2. 使用SQL模板: - 根据查询类型选择合适的模板,并根据需求进行调整。
示例:
问题:列出所有员工的姓名和职位。SQL:`SELECT Name, Position FROM Employees;`
问题:计算每个产品的销售总额SQL:`SELECT ProductName, SUM(Quantity * Price) AS TotalSales FROM Sales GROUP BY ProductName;`
Dataherald(https://github.com/Dataherald/dataherald)是一个开源NL2SQL项目,专为针对关系型数据进行企业级问答而构建,Dataherald就是基于上面解决思路实现的。也提供了跟LangChain结合的集成接口,可以本地部署,构建自己的Data Agent。首先需要一个DATAHERALD_API_KEY,可以从Dataherald官网注册获得,或者本地部署生成。实例化DataheraldAPIWrapper,这个是用来和Dataherald接口交互的封装。创建好数据库连接,这里会生成一个connection_id。
dataherald_api_key = os.environ('DATAHERALD_API_KEY') api_wrapper = DataheraldAPIWrapper(dataherald_api_key= dataherald_api_key,db_connection_id="xxx")
定义三个Agent的工具,利用Dataherald的接口实现NL2SQL、SQL执行器、基于matplotlib的图标工具。DataheraldAPIWrapper,DataheraldTextToSQL是langchain_community这个包里的。LangChain对Agent调用的工具有一套封装的格式,实现起来比较简单,有兴趣的建议看看LangChain官网的示例。
text_to_sql_tool = DataheraldTextToSQL(api_wrapper=api_wrapper) def clean_string(s): return s.replace(" ", "").replace("\n", "").lower() def execute_sql_query(sql_query: str) -> str: generated_queries = api_wrapper.dataherald_client.sql_generations.list(page=0, page_size=20, order='created_at', ascend=False) query_id = "" for query in generated_queries: if clean_string(query.sql) == clean_string(sql_query): query_id = query.id break if not query_id: raise Exception("Query has not found") query_results = api_wrapper.dataherald_client.sql_generations.execute(id=query_id) return str(query_results) execute_query_tool = StructuredTool.from_function( func=execute_sql_query, name="Execute Query", description="用于在数据库上执行SQL查询,输入是由text-to-sql工具生成的SQL查询", ) def plot_and_save_array(dict_of_values): dict_of_values = json.loads(dict_of_values.strip().replace("'", '"')) items = list(dict_of_values.keys()) values = list(dict_of_values.values()) plt.figure(figsize=(5, 3)) plt.plot(items, values, marker='o') plt.title("Array Plot") plt.xlabel("Items") plt.ylabel("Values") plt.xticks(rotation=45) plt.grid(True) identifier = uuid.uuid4().hex[:6] + ".png" plt.savefig(identifier) plt.show() return "success" plotting_tool = StructuredTool.from_function( func=plot_and_save_array, name="Plotting Results", description="一个工具,它接收一个有效的json对象,其中键是x轴值,对于每个键,我们都应该有一个值", )
AgentExecutor是LangChain预设的一个Agent执行流程,方便以最简单的方式运营一个Agent。这里是用的是OpenAI的gpt-4-turbo模型,这个模型速度比较快,成本低(相对的),你也使用其他模型,Azure OpenAI或者Kimi、百度文心都行,LangChain都有对应的实现。
tools定义了一组LLM可以使用的工具,是否调用、什么时候调用,都由LLM基于tool的description来判断。
llm = ChatOpenAI(api_key=openai_api_key, model="gpt-4-turbo-preview", temperature=0) tools = [text_to_sql_tool, execute_query_tool, plotting_tool] agent = create_react_agent(llm, tools, prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
助理的设计目的是能够协助对数据库值进行问题和分析。助理计划:1) 使用“text-to-sql”工具为用户问题生成sql查询2) 使用“Execute Query”工具在数据库上执行生成的SQL查询3) 使用“Plotting Results”工具绘制“Execute Query”工具返回的结果工具:------助理可以访问以下工具:{tools}要使用工具,请使用以下格式:'''思考:我需要使用工具吗?对操作:要采取的操作应为[{tool_names}]之一动作输入:动作的输入观察:行动的结果'''当你有回应要对人类说,或者如果你不需要使用工具,你必须使用以下格式:'''思考:我需要使用工具吗?不最终答案:[此处为您的回复]'''开始新输入:{input}{agent_scratchpad}
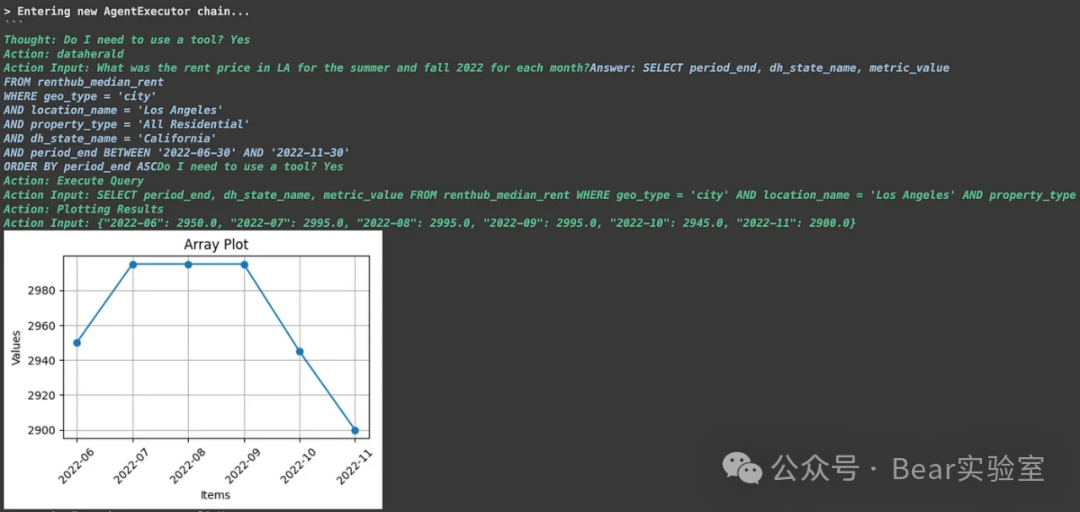
agent_executor.invoke ( { "input" : "2022 年夏季和秋季洛杉矶每个月的租金价格是多少?绘制结果" } )
这里Dataherald用的是美国房地产信息的示例数据,结果展示
虽然AI + 数据分析是一个非常有前景的方向,但目前的使用还是有很多局限。生成SQL的准确率不够高,而且稳定性也存在疑问。去年阿里联合香港大学,发布了一个NL2SQL的研究论文,列出一组实验数据,给定一份问题样本生成SQL,人类的准确率是94%,而最好的大模型GPT4只有40%。所以如果你的应用场景是要求严谨,不能出错的,那请慎重考虑。但如果是定位为Copilot,就是帮人提升效率的场景,非常值得尝试。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
