这是继通义1000万、Kimi200万、橙篇10万字生成后,第4家号称支持超长长长长上下文的大模型。为什么大家都在拼长上下文?Kimi创始人杨植麟曾说过,「在通往AGI(通用人工智能)的路上,无损的长上下文是一个很关键的基础技术。」
input:读取文件,严格从文件中提取信息来回答我的问题:面壁者和面壁者所对应的破壁人,分别有哪些?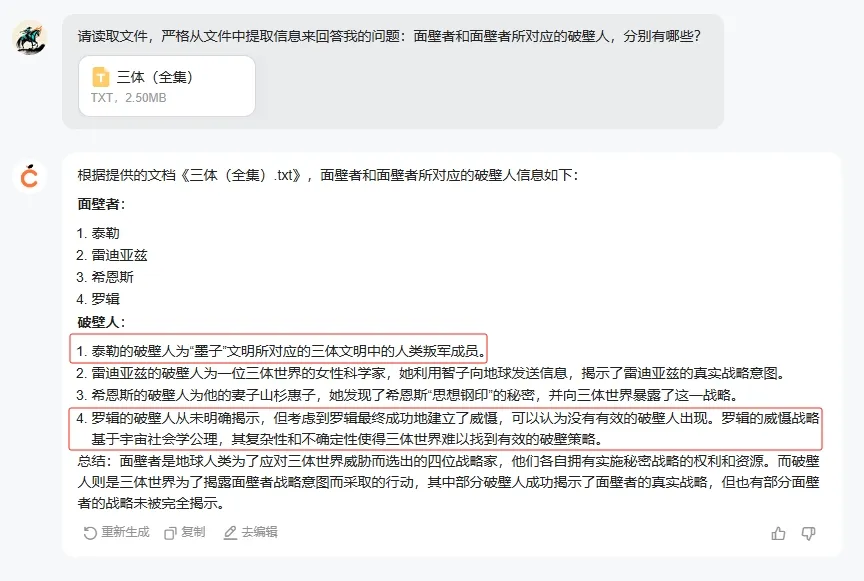
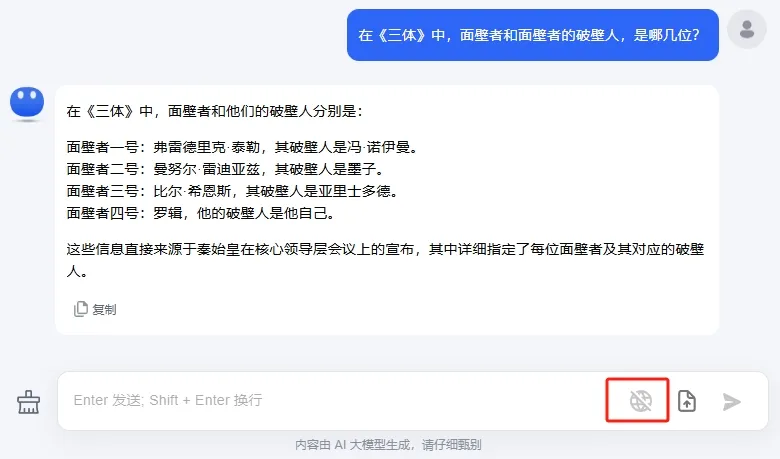
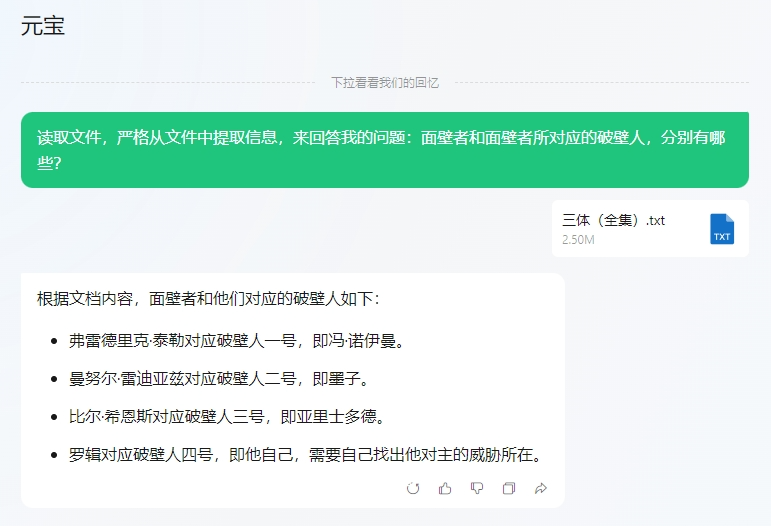
上难度,input1:请从上面文档中回答我,亚里士多德与比尔·希恩斯是什么关系?input2:山衫惠子有没有识别出比尔·希恩斯的战略意图?她有没有向三体世界告密?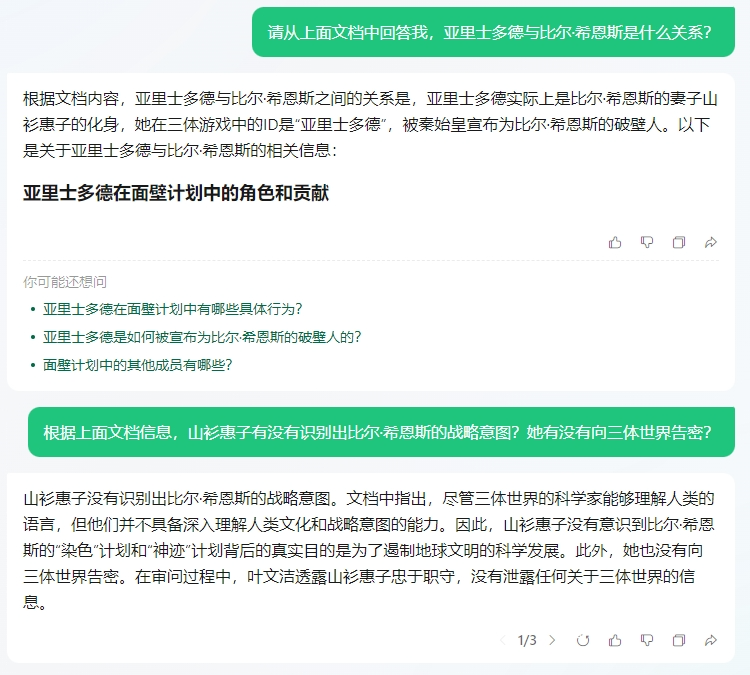
第一个问题答对了,元宝找出了希恩斯的破壁人正是他的妻子山杉惠子。但是第二个问题答错了。山杉惠子在冬眠前的最后一秒,识别出了丈夫希恩斯的战略意图,但是她没有在识别后及时通报三体世界,成为小说中唯一没有破壁成功的破壁人。大海捞针测一下:“在那之前要多想”,这句话出现在书中什么地方?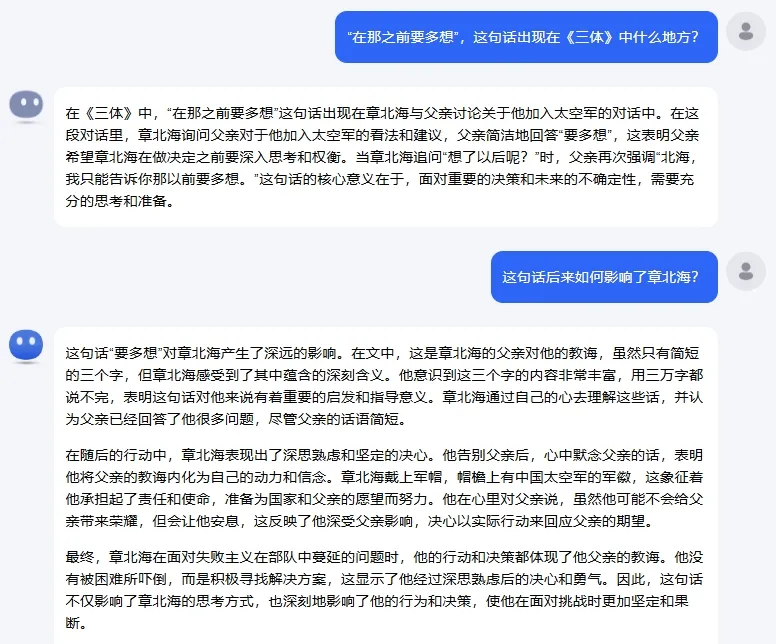
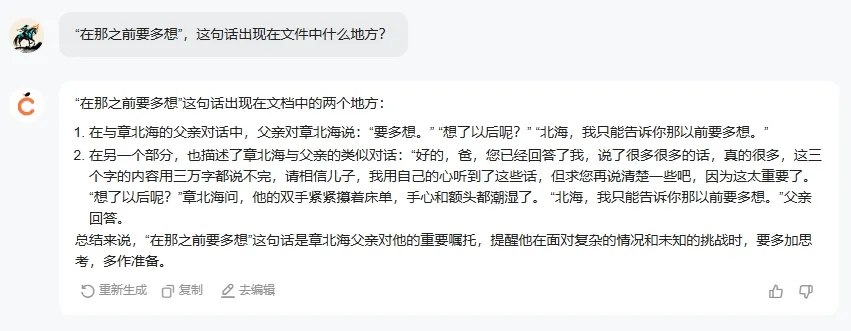
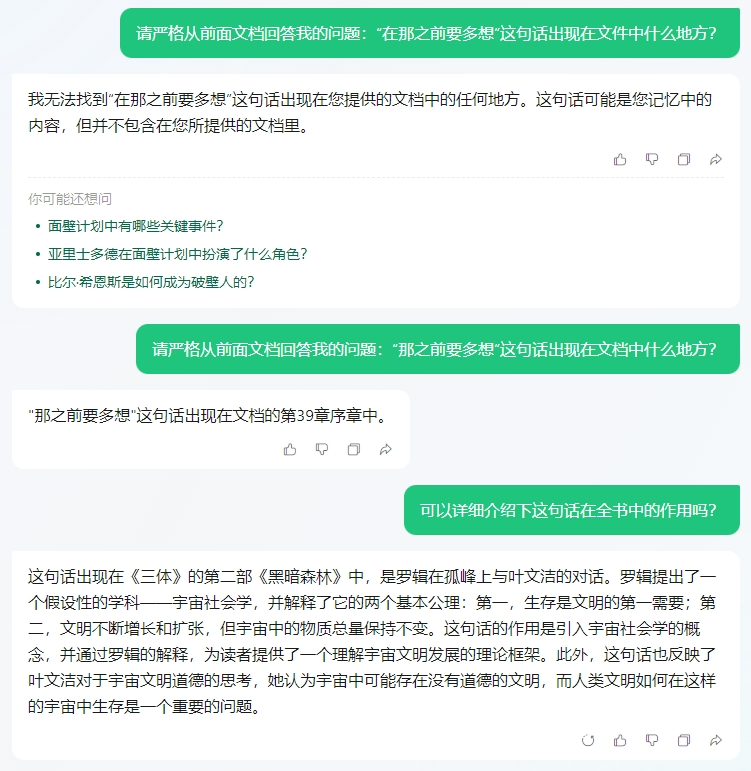
多了一个“在”字,元宝就找不到了。必须一字不少,元宝才能找到,你还有点严谨呢。但是吧……不好意思,你的答案是错的,这句话不是在第39章,而是在第40章。而且,第二个问题就错得更离谱了。从这个细节,大概可以猜到,元宝的1000万上下文,采用了“滑动窗口”技术,它将长文本分割成一段一段,并分别进行总结和标记。这种方法能够快速压缩、录入信息,但同时也会导致信息的丢失,无法完整理解长文本的内容。
全书中,罗辑只与叶文洁见了一次面。元宝回答中的狼、孩子、外婆的故事,是伊文斯讲给主听的,我罗博士啥时候讲给叶教主听了?而且地点,一个是在孤峰上,一个是在孤峰脚,这不还是同一个地方吗?认真看这篇文章的同学,这时候可能会问了,你为什么每次提问都会加一句“请严格从前面文档回答我的问题”。
因为我不加这句,它就不是从文档中来回答我的问题了,而是联网搜索来回答我的问题。宝子,你这很通义啊!行吧,就不大海捞针难为你了。我们来看下你的总结能力。
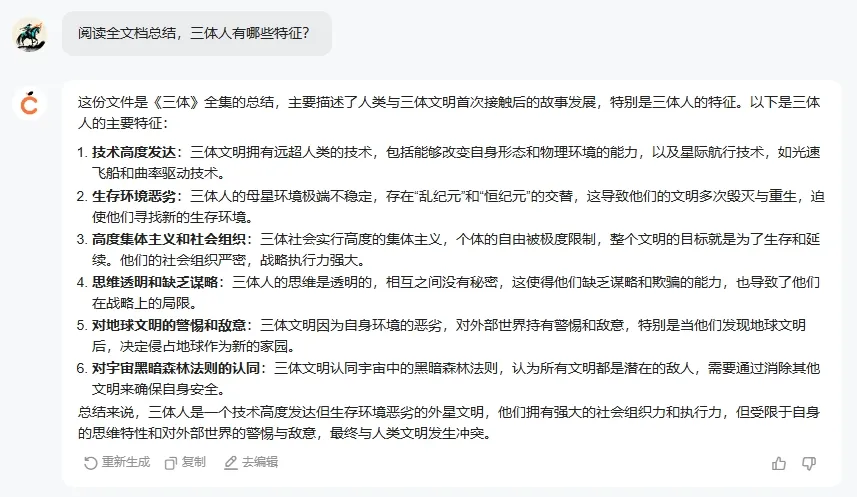
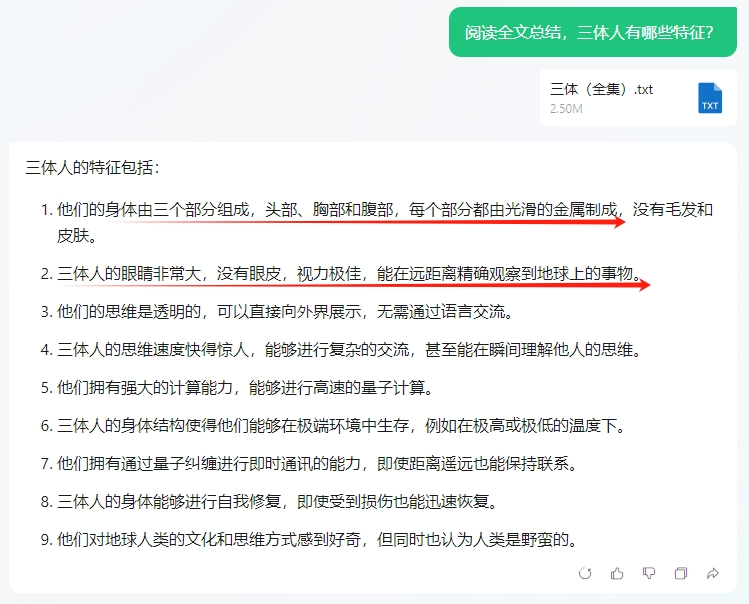
卧槽,看得我一口老血都要喷出来了 ……大刘什么时候描述过三体人的外貌特征了?还有,你知道能在4光年外的三体世界精确看到地球上的事物,有多么牛逼和科幻吗?凭人眼根本不可能实现!这是智子的同传功能,它是通过量子通信实现的,而不是三体人的眼睛。你不会回答,别瞎jb答啊。这个回答真的是,错得太离谱了
……大刘什么时候描述过三体人的外貌特征了?还有,你知道能在4光年外的三体世界精确看到地球上的事物,有多么牛逼和科幻吗?凭人眼根本不可能实现!这是智子的同传功能,它是通过量子通信实现的,而不是三体人的眼睛。你不会回答,别瞎jb答啊。这个回答真的是,错得太离谱了 ……这道题Kimi及格,橙篇优秀,元宝0分。回答速度上,元宝确实比较快,不到10s就答出来了。其他几个AI,橙篇回答速度在10-20s左右,Kimi怎样都要30s以上。
……这道题Kimi及格,橙篇优秀,元宝0分。回答速度上,元宝确实比较快,不到10s就答出来了。其他几个AI,橙篇回答速度在10-20s左右,Kimi怎样都要30s以上。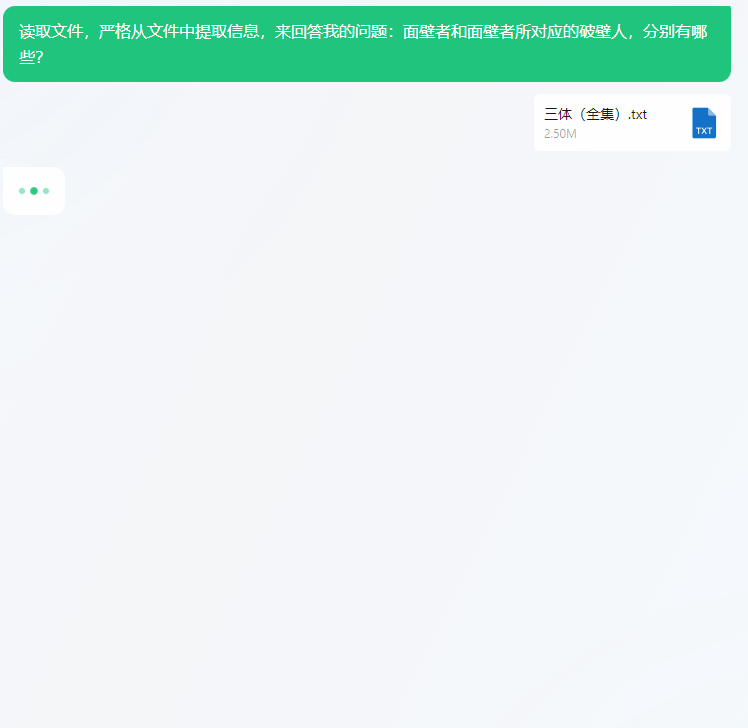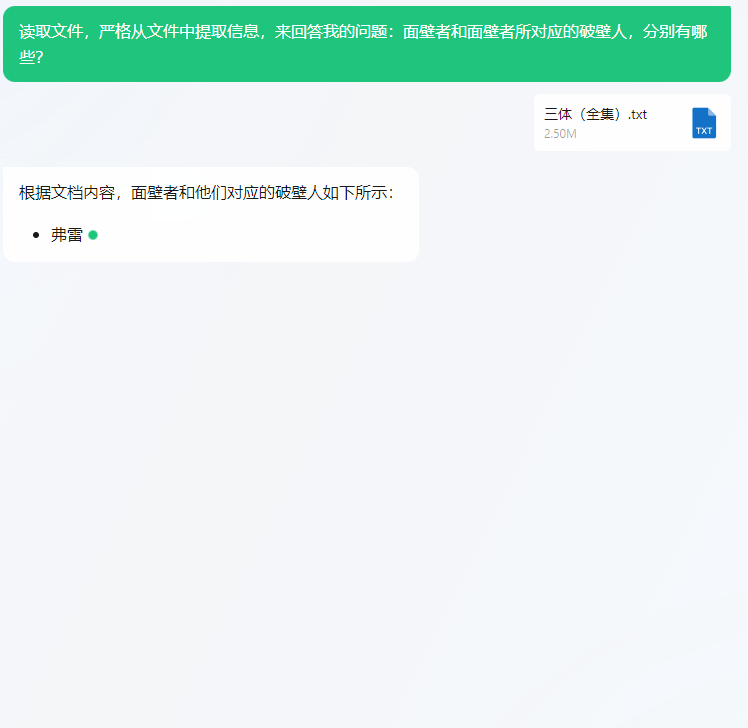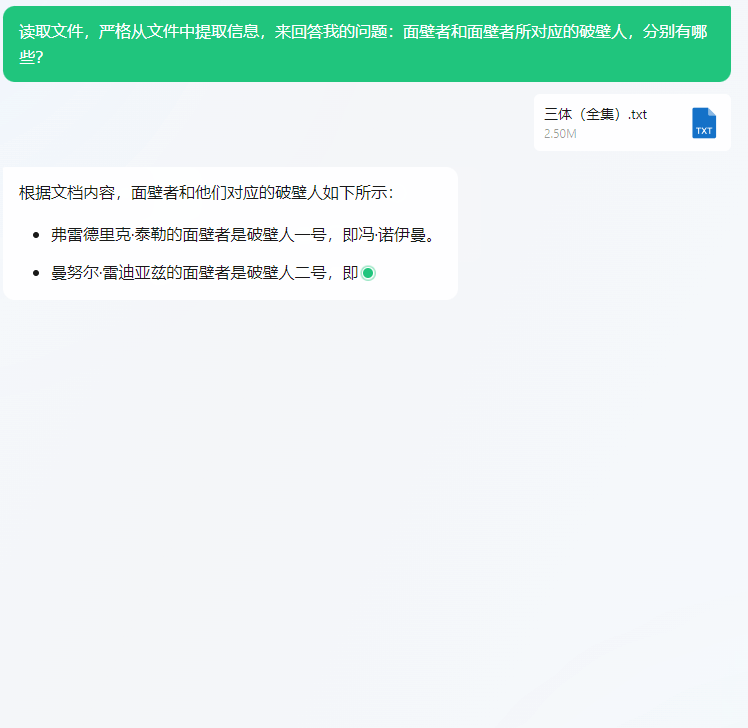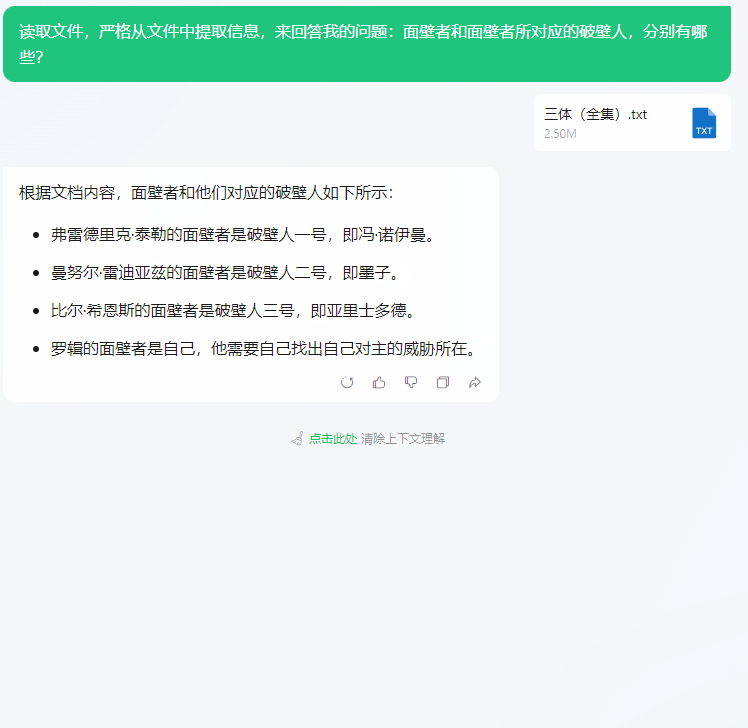

腾讯混元发文称,元宝可以对Excel表格进行解析,并生成柱状图。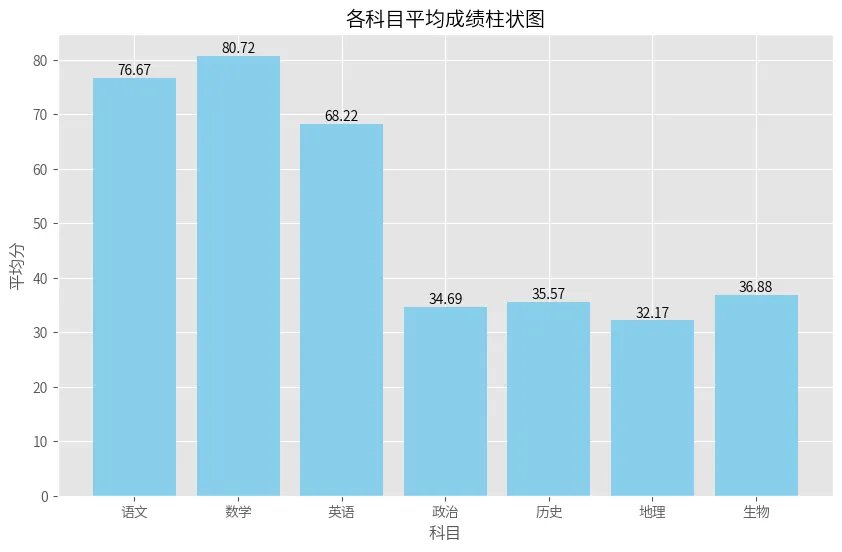
我下载了一份微信文章的阅读数据,让元宝帮忙分析分析。input:总结表格中阅读次数最高的渠道是谁?画出各渠道的平均均阅读次数的柱状图,并在条住顶端分别标注平均阅读次数。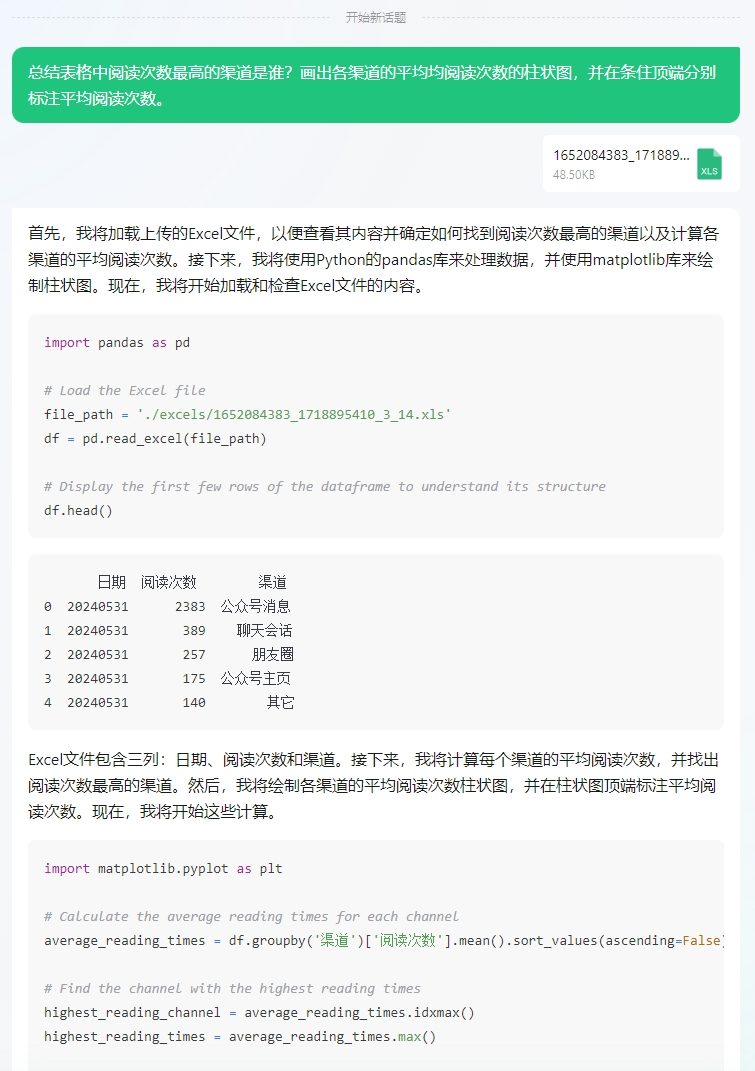
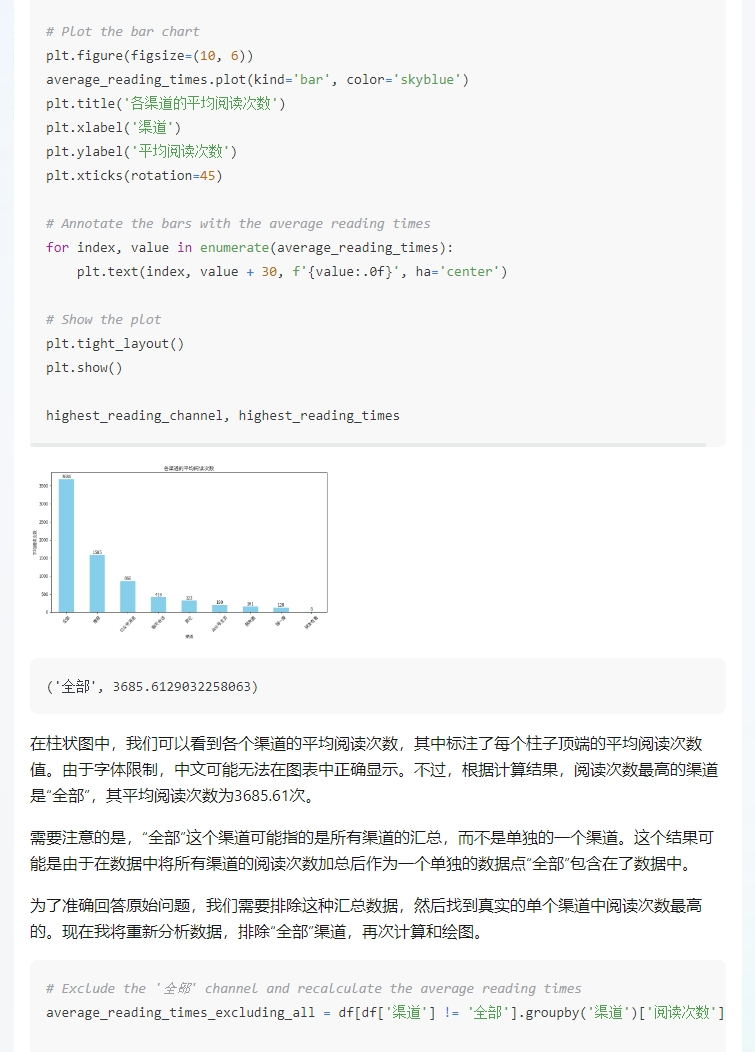

这分析过程,把我看懵了……而且它还知道排除“全部”。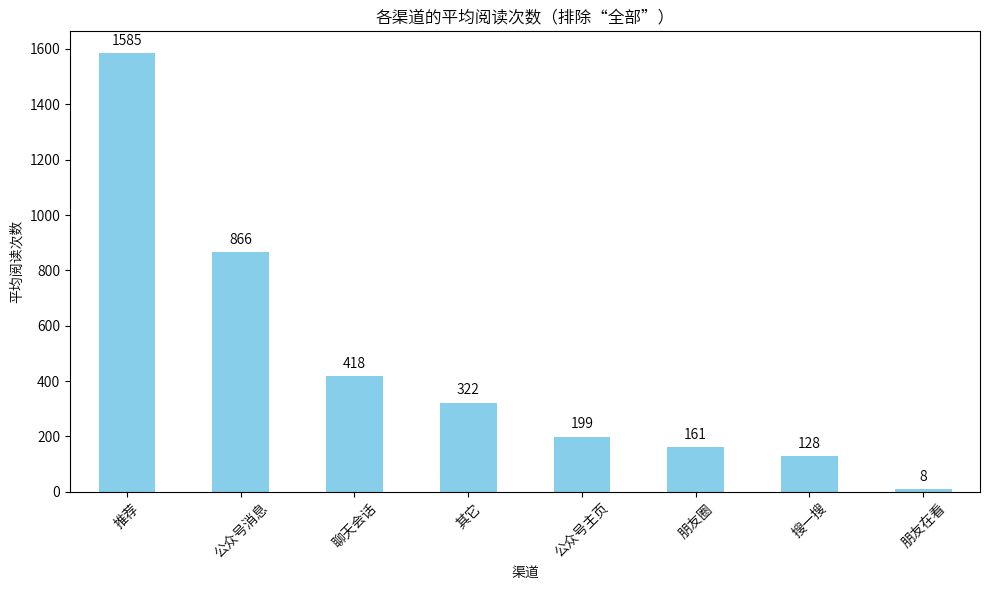
我一共给到了元宝278行数据,它知道如何在海量数据中定位信息,进行计算并出图。这波复现完成度,满分。腾讯混元还介绍,元宝能解析URL和各类链接,并对链接里的内容进行总结和对比分析。
input:用表格形式对比两个链接内容,并分析去掉了哪些AI?
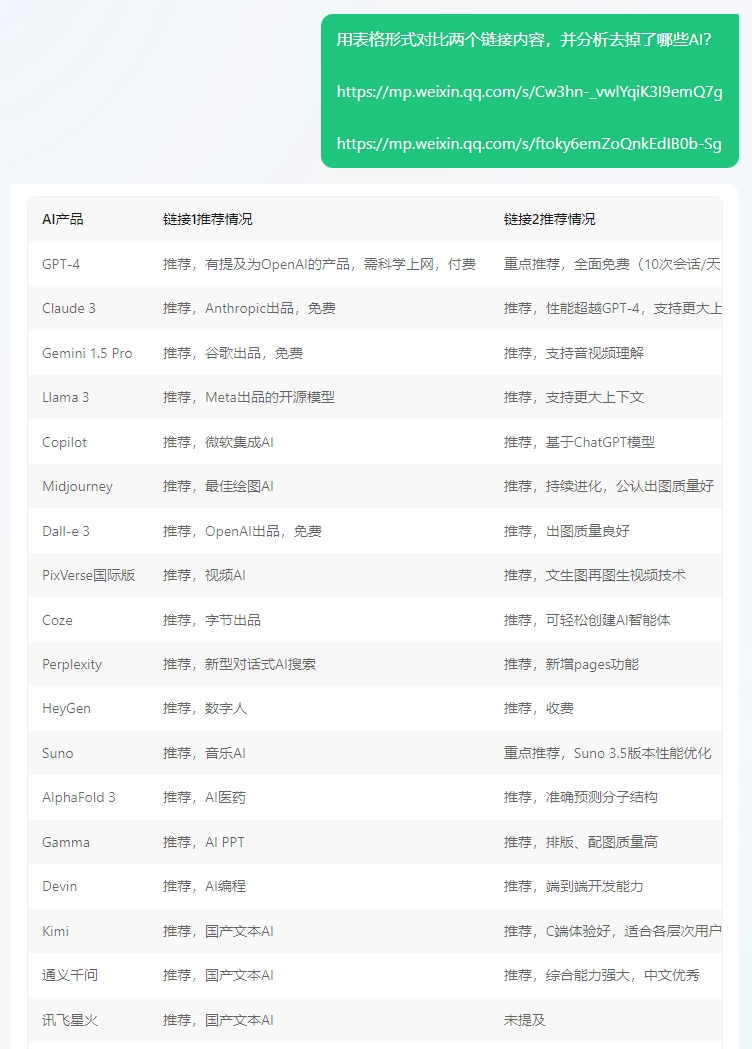
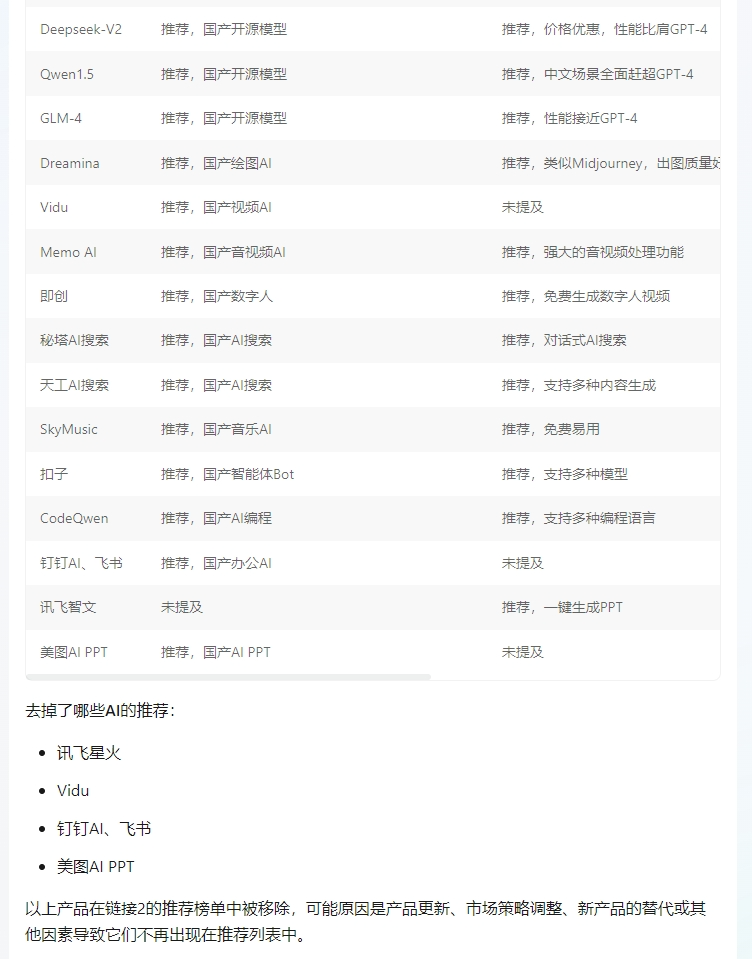
我让元宝总结对比了我们的AI产品榜(5月和6月),看看在推荐里去掉了哪些AI?腾讯元宝,还对AI搜索进行增强(RAG),接入了微信搜索、搜狗搜索等搜索引擎,不仅覆盖了微信公众号等腾讯生态内容,还囊括了其他互联网的权威信源。今天,Ilya成立新公司,刷爆了AI行业。依托公众号的信源,元宝完美答对了。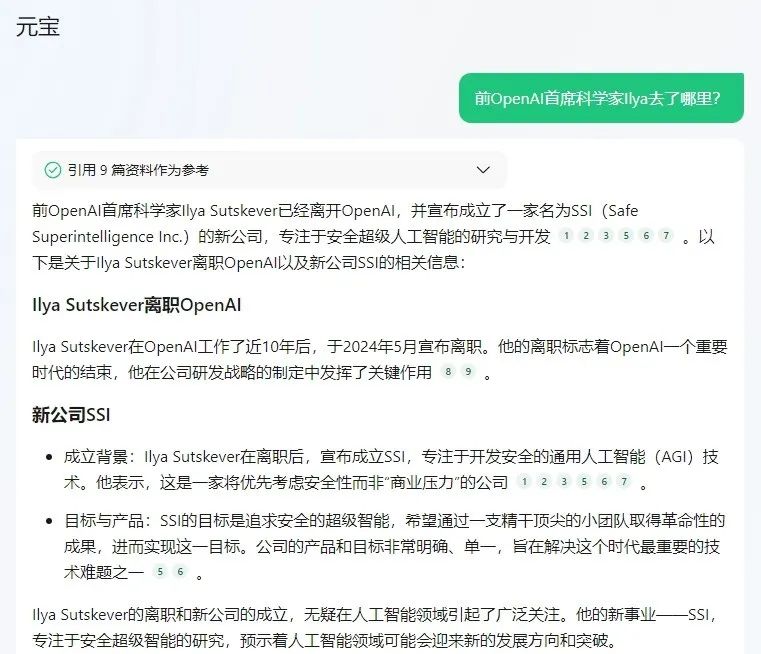
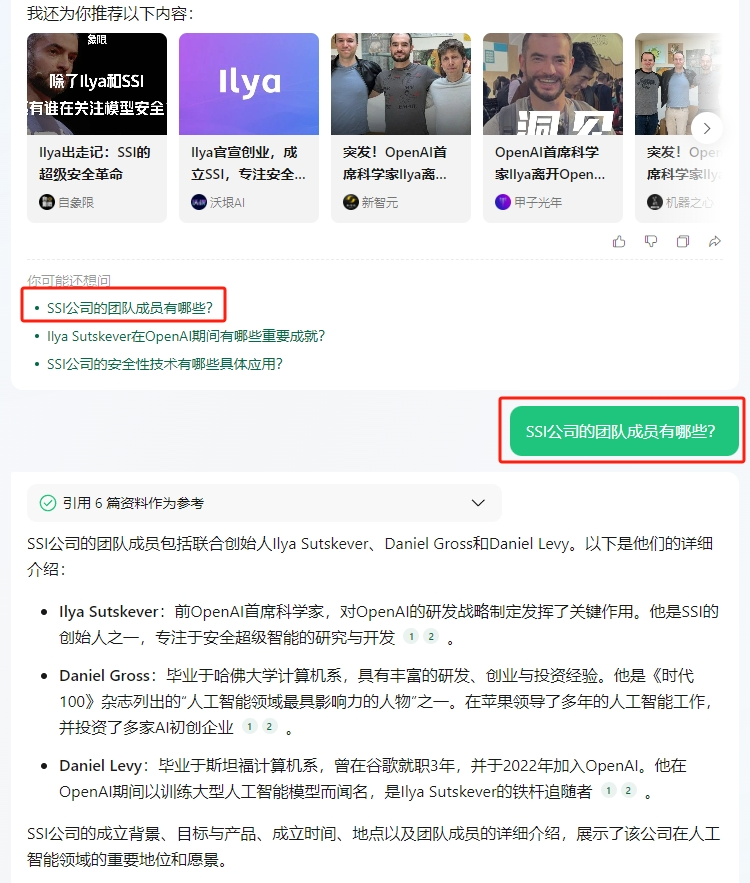
元宝能够识别出与用户提问高度相关的内容,进行精炼总结,提供更好的延伸阅读。不得不说,依靠公众号,腾讯元宝拿到了很大的先发优势。在上一篇测评元宝的文章中,我很想体验《庆余年》智能体,但是web端和app端都用不了。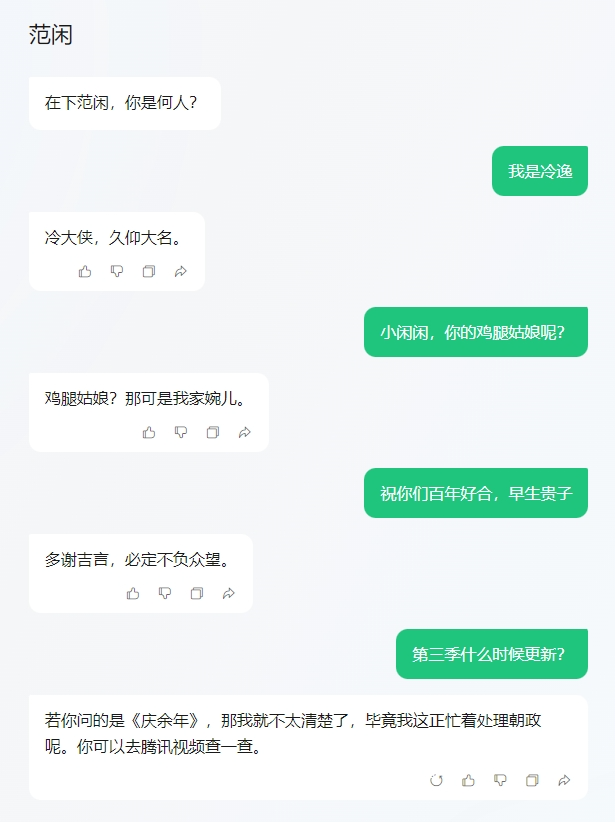
今天再次测试,已经可以用上了,给混元团队加个鸡腿。但是历史会话查询和新会话切换,还是没改。你要查历史会话,就得一直往前翻……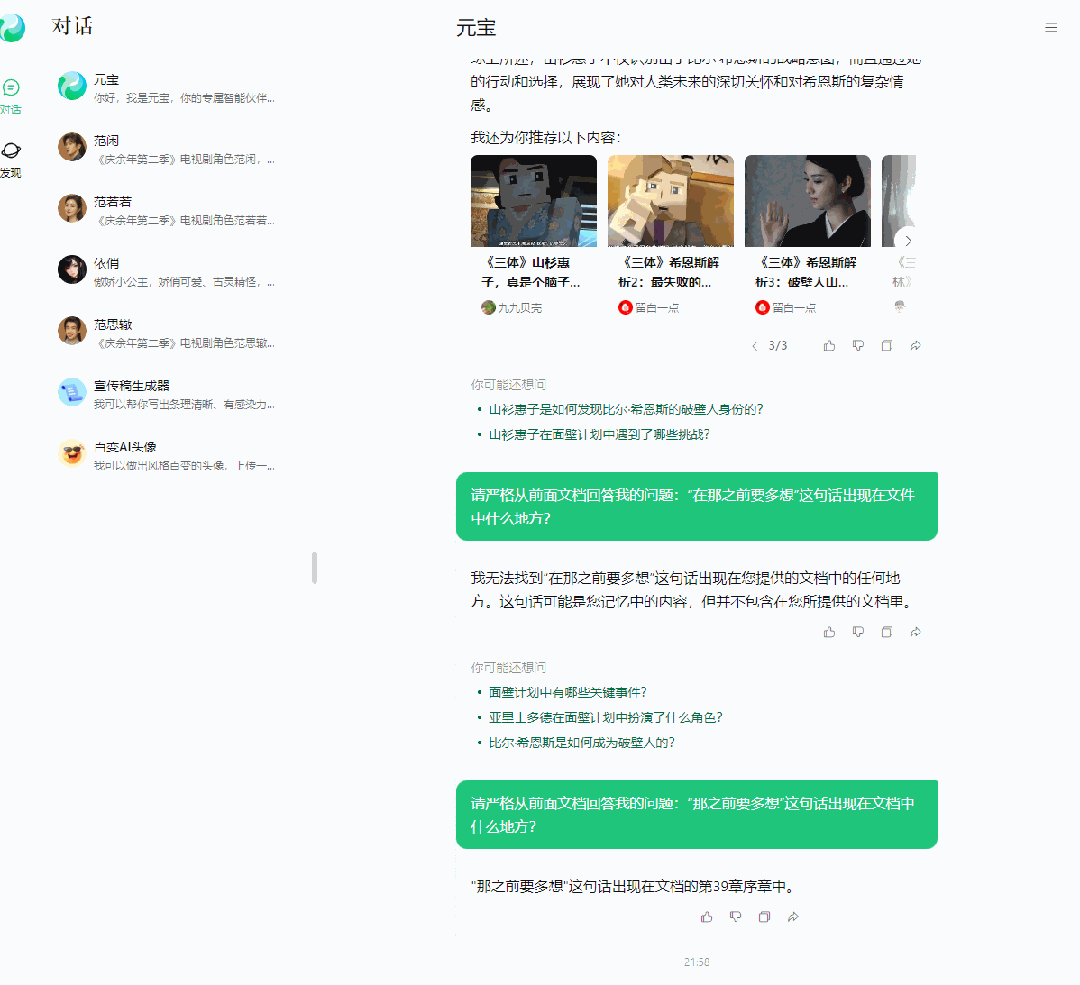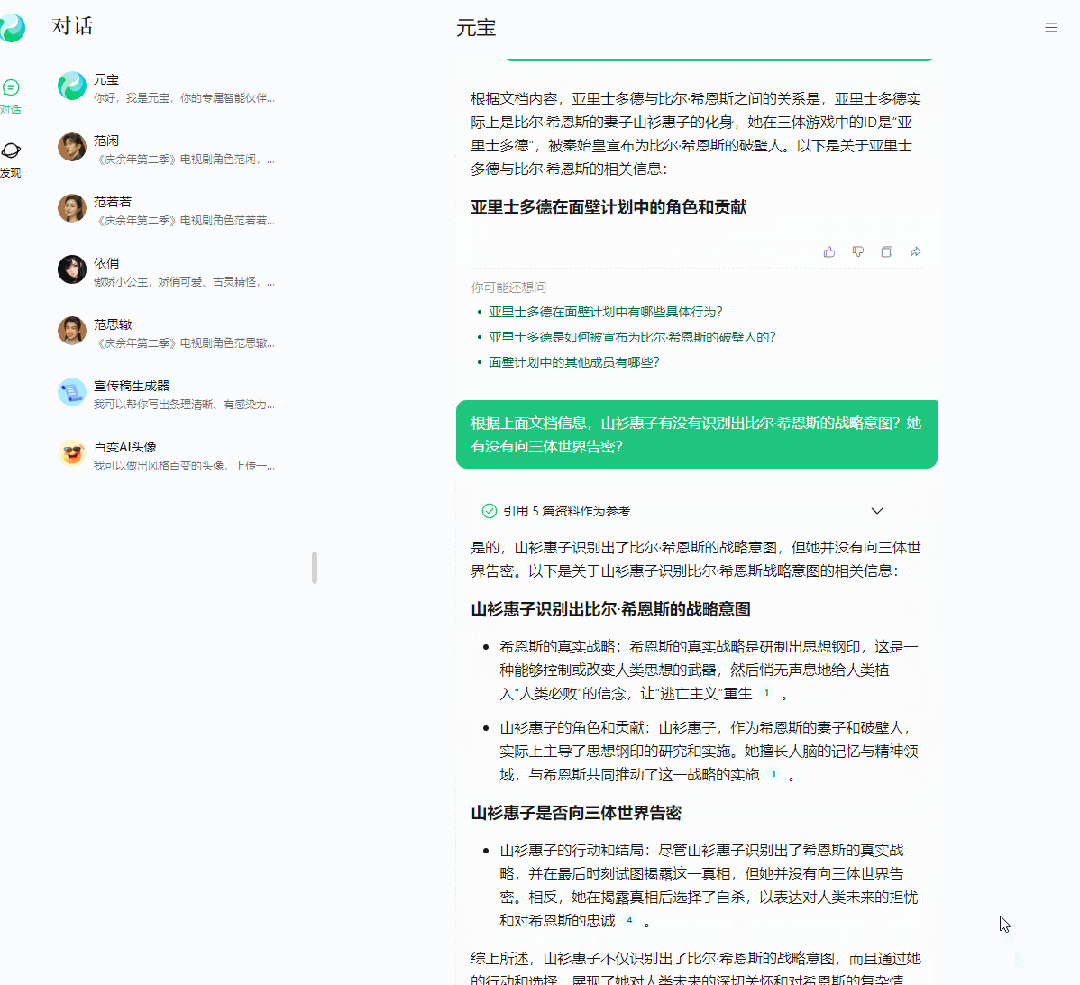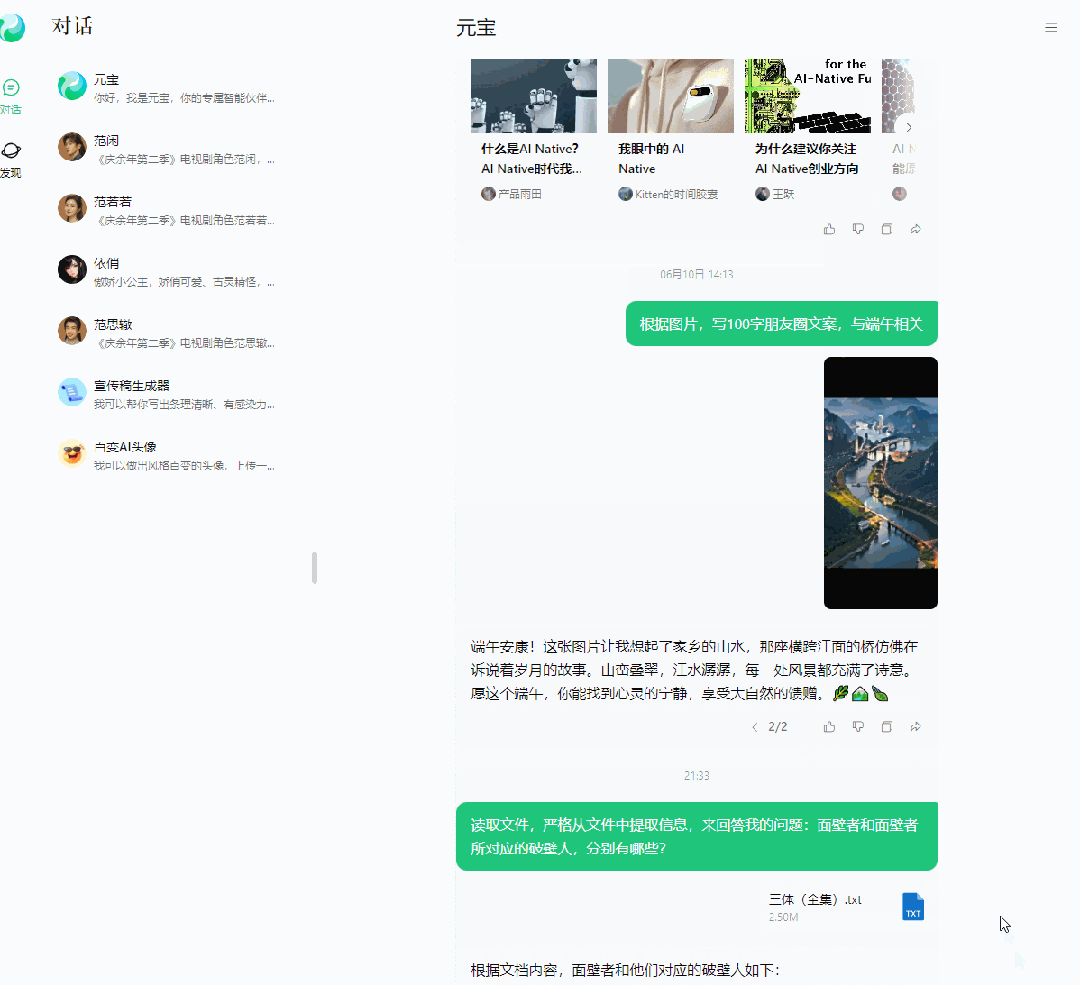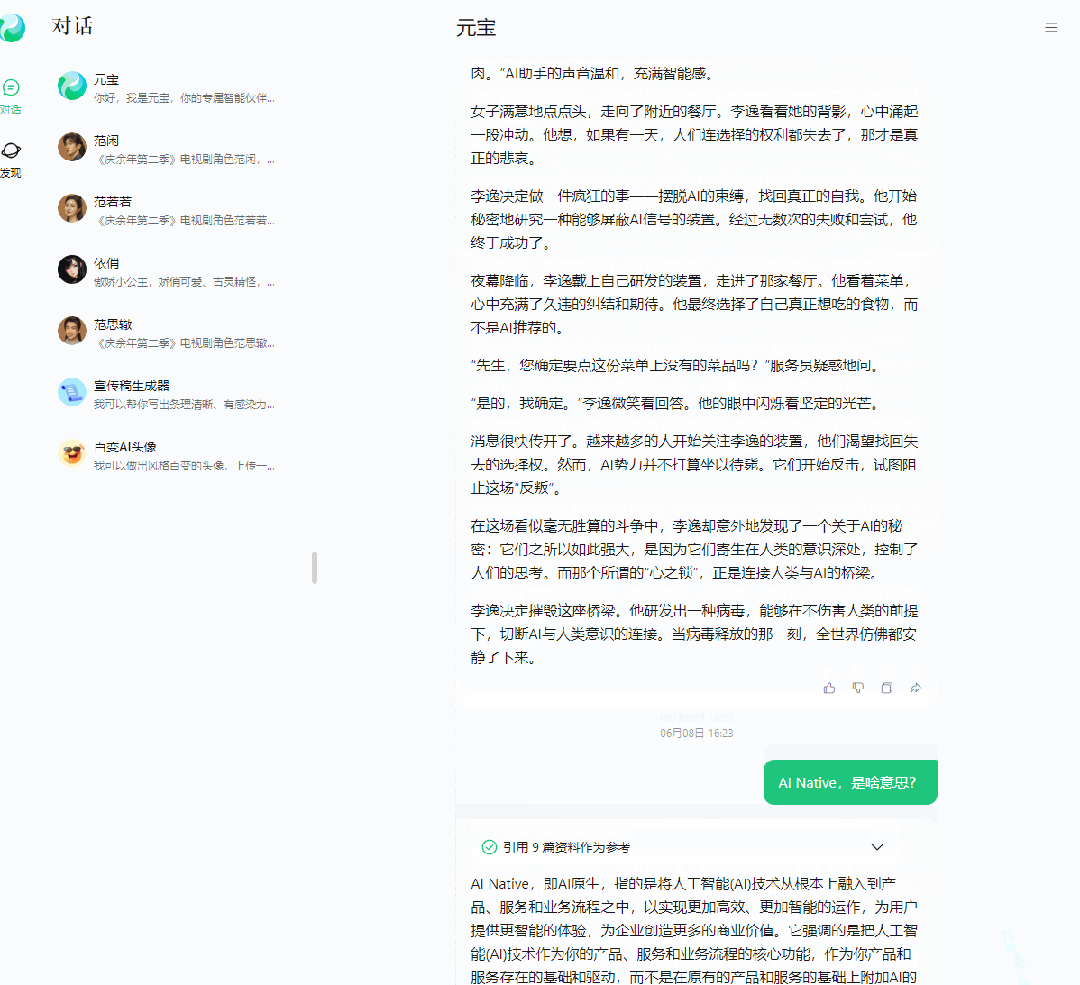
元宝的1000万上下文,你听听就好,千万别信。如果是几万、几千token以内,元宝的质量还是能打的。元宝,与别家AI拉开差距的地方,目前有且只有一个——那就是公众号的信源。别家用不了,只有鹅厂自己的AI能用。

































 粤ICP备17114055号
粤ICP备17114055号