某乎上有很多关于long context的回答,多数是kimi的广告软文。没时间写细节,直接给大家分享主要长文本的关键文献吧。不要光看不点赞,点赞才是分享的动力。
这里说的长上下文指的是纯模型输入的情况,基于RAG的方式也能部分解决问题,但是在类似“大海捞针”的实验中一般表现不佳
长文本大模型的关键技术主要是相对位置嵌入、旋转位置嵌入、位置插值、线性偏置等。
1. long context的核心是长文语义和逻辑的一致性,不是KV cache或者Inference速度。就好比博士去写100多页的论文(相对于小学生写几百字的作文)前后是要逻辑自洽的,时间不是最大的影响因素。
2. KV cache优化也好,ring attention也好都是计算效率优化技术,改变不了长文的语义一致性。下面通过几篇文献来了解长文本的关键技术。(附论文地址)
1. 旋转位置嵌入类
1.1 《RoFormer: Enhanced Transformer with Rotary Position Embedding》
旋转位置嵌入(RoPE)使用旋转矩阵对绝对位置进行编码,同时在自注意力公式中结合了明确的相对位置依赖性。旋转位置嵌入保持了序列长度的灵活性、随相对距离的增加而衰减的token间依赖性,以及为线性自注意力配备的相对位置编码的能力。
https://arxiv.org/abs/2104.0986
旋转位置嵌入(RoPE)示意图
1.2 《LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens》LongRoPE通过有效的搜索识别和利用位置插值中的两种形式的非均匀性,为微调提供更好的初始化,并在非微调场景中实现 8 倍扩展。LongRoPE引入了一种渐进扩展策略,首先微调 256k 长度的 LLM,然后对微调的扩展 LLM 进行第二次位置插值,以实现 2048k 上下文窗口。LongRoPE在 8k 长度上重新调整以恢复短上下文窗口性能。https://arxiv.org/abs/2402.1375
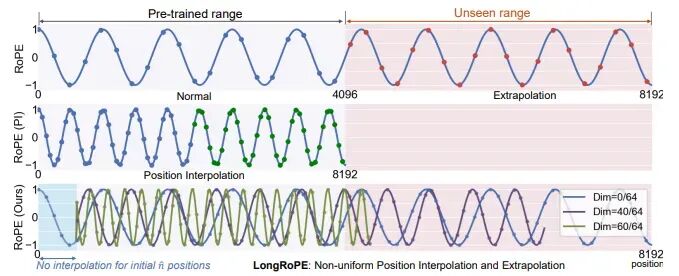 LongRoPE示意图
LongRoPE示意图
2. 相对位置嵌入类
2.1《A Length-Extrapolatable Transformer》
该文献引入相对位置嵌入来最大化注意力分辨率。另外,在推理过程中使用blockwise注意力来提升分辨率。https://arxiv.org/abs/2212.1055
Blockwise注意力示意图
3. 线性偏置方法
3.1《Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation》
基于线性偏置的注意力(ALiBi)不在词嵌入的基础上添加位置嵌入,而是通过与距离成正比的惩罚来偏置查询键值注意力分数。https://arxiv.org/abs/2108.1240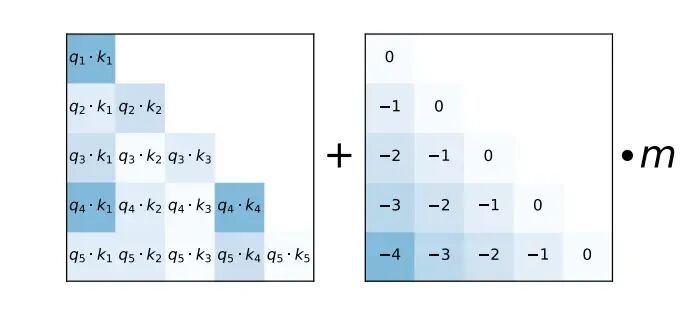
4. 长文本训练方法
4.1 《YaRN: Efficient Context Window Extension of Large Language Models》
旋转位置嵌入 (RoPE) 已被证明可以在基于 Transformer 的语言模型中有效的编码位置信息。然而,这些模型无法泛化超过它们训练的序列的长度。YaRN(另一种 RoPE 扩展方法),用于扩展此类模型的上下文窗口,与以前的方法相比,需要的标记少 10 倍,训练步骤少 2.5 倍。https://arxiv.org/abs/2309.00071
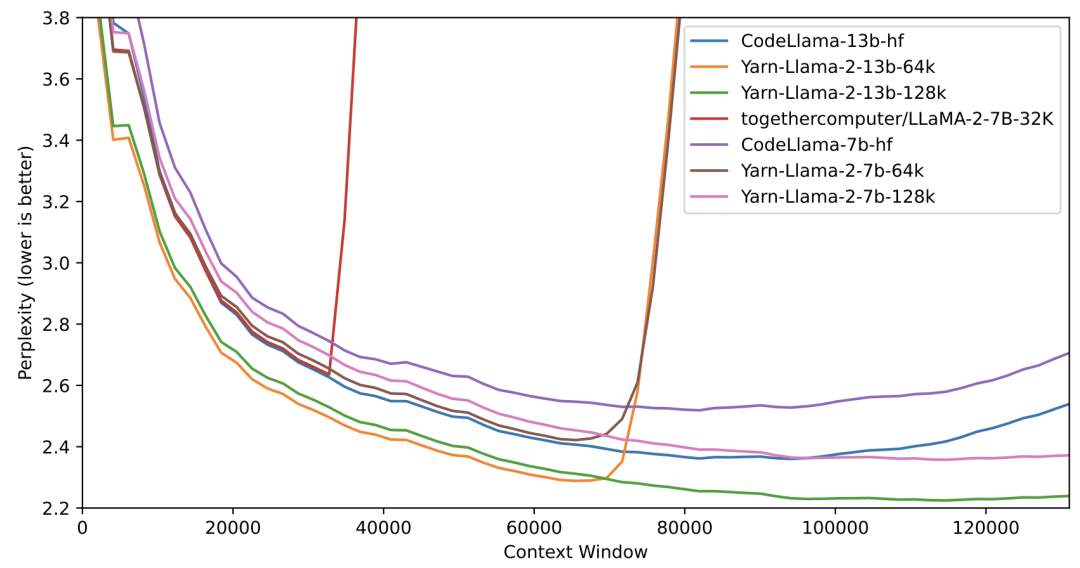
4.2 《Extending Context Window of Large Language Models via Positional Interpolation》
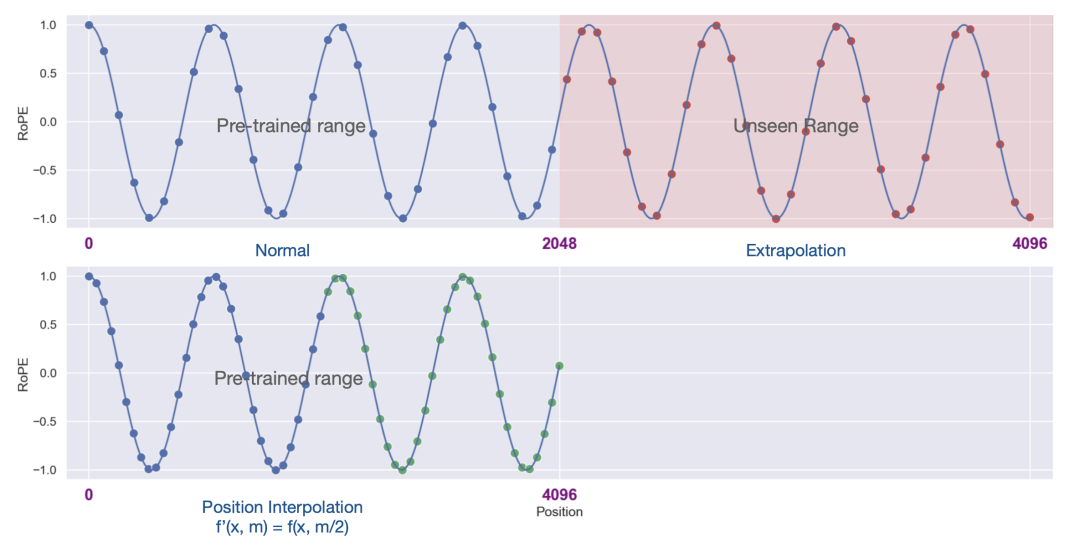
位置插值 (Position Interpolation ,PI),可以将基于 RoPE 的预训练 LLM的上下文窗口大小扩展到 32768,并进行最小的微调(1000 步以内)。位置插值的扩展模型在其原始上下文窗口内的任务上相对较好的保持了质量。通过位置插值扩展的模型可保留其原始架构,并且可以重用大多数已有的优化方法。https://arxiv.org/abs/2306.15595
4.3 《PoSE: Efficient Context Window Extension of LLMs via Positional Skip-wise Training》
Position Skip-wisE (PoSE) 训练使用固定上下文窗口智能模拟长输入。首先将原始上下文窗口划分为几个语块(chunks),然后设计不同的跳过偏置项来操作每个语块的位置索引。这些偏置项和每个语块的长度都会针对每个训练示例调整,从而使模型能够适应目标长度内的所有位置。与全长微调相比,PoSE 大大减少了内存和时间开销,并且对性能的影响最小。https://arxiv.org/abs/2309.1040
Skip-wise方法示意图
以上就是本次分享的全部,长文本的处理是自然语言处理领域的一个重要挑战,主要因为需要处理的信息量大和保持上下文的连贯性。上述提到的关键技术都是在尝试以不同的方式解决长文本处理中遇到的挑战。从旋转位置嵌入的灵活性和序列长度适应能力,到位置插值在上下文窗口扩展中的应用,再到线性偏置方法的创新应用,这些技术的发展都显示了长文本模型在处理大规模数据时的潜力和效率。

































 粤ICP备17114055号
粤ICP备17114055号