LLM主流结构:
LLM主流结构包括三种范式,分别为Causal Decoder、Prefix Decoder、Encoder-Decoder。LLM主流结构主要区别在于Attention Mask不同。LLM训练目标:
1.语言模型:根据已有词预测下一个词,即Next Token Prediction,是目前大模型所采用的最主流训练方式,训练目标为最大似然函数: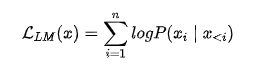
训练效率:Causal Decoder>Prefix Decoder ,Causal Decoder 结构会在所有token上计算损失,而Prefix Decoder只会在输出上计算损失。2.去噪自编码器:随机替换掉一些文本段,训练语言模型去恢复被打乱的文本段,即完形填空,训练目标函数为: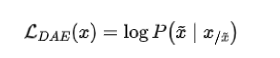
去噪自编码器的实现难度更高,采用去噪自编码器作为训练目标的任务有GLM-130B、T5等。24年大模型面试准备2|LLM构建流程:https://mp.weixin.qq.com/s/21NlHjAYKlklfyisUEhIkwOpenAI-LLM构建流程:
OpenAI 所使用的大规模语言模型构建流程如下图1所示。主要包含四个阶段:预训练、有监督微调、奖励建模、强化学习。这四个阶段都需要不同规模数据集合以及不同类型的算法,会产出不同类型的模型,同时所需要的资源也有非常大的差别。1.预训练(Pretraining):该阶段需要利用海量的训练数据,包括互联网网页、维基百科、书籍、GitHub、 论文、问答网站等,构建包含数千亿甚至数万亿单词的具有多样性的内容。预训练基础大模型构建了长文本的建模能力,使得模型具有语言生成能力,根据输入的提示词(Prompt),模型可以生成文本补全句子。由于训练过程需要消耗大量的计算资源,并很容易受到超参数影响,如何能够提升分布式计算效率并使得模型训练稳定收敛是本阶段的重点研究内容。2.有监督微调(Supervised Finetuning):该阶段也称为指令微调(Instruction Tuning),利用少量高质量数据集合,包含用户输入的提示词(Prompt)和对应的理想输出结果。用户输入包括问题、闲聊对话、任务指令等多种形式和任务。利用这些有监督数据,使用与预训练阶段相同的语言模型训练算法,在基础语言模型基础上再进行训练,从而得到有监督微调模型(SFT 模型)。经过训练的 SFT 模型具备了初步的指令理解能力和上下文理解能力,能够完成开放领域问题、阅读理解、翻译、生成代码等能力,也具备了一定的对未知任务的泛化能力。3.奖励建模(Reward Modeling):该阶段目标是构建一个文本质量对比模型,对于同一个提示词,SFT 模型给出的多个不同输出结果的质量进行排序。奖励模型(RM 模型)可以通过二分类模型,对输入的两个结果之间的优劣进行判断。RM 模型与基础语言模型和 SFT 模型不同,RM 模型本身并不能单独提供给用户使用。 由于 RM 模型的准确率对于强化学习阶段的效果有着至关重要的影响,因此对于该模型的训练通常需要大规模的训练数据。4.强化学习(Reinforcement Learning):该阶段根据数十万用户给出的提示词,利用在前一阶段训练的 RM 模型,给出 SFT 模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好的效果。使用强化学习,在 SFT 模型基础上调整参数,使得最终生成的文本可以获得更高的奖励(Reward)。文献 [7] 给出了强化学习和有监督微调的对比,在模型参数量相同的情况下,强化学习可以得到相较于有监督微调好得多的效果。
24年大模型面试准备3|LLM容易被忽略的Tokenizer与Embedding:https://mp.weixin.qq.com/s/p8NG_0onb4vBNOus6_Hp7QTokenizer作用:
1.分词:tokenizer将字符串分为一些sub-word token string,再将token string映射到id,并保留来回映射的mapping。从string映射到id为tokenizer encode过程,从id映射回token为tokenizer decode过程。映射方法有多种,例如BERT用的是WordPiece,GPT-2和RoBERTa用的是BPE等等。2.扩展词汇表:部分tokenizer会用一种统一的方法将训练语料出现的且词汇表中本来没有的token加入词汇表。对于不支持的tokenizer,用户也可以手动添加。3.识别并处理特殊token:特殊token包括[MASK], <|im_start|>, <sos>, <s>等等。tokenizer会将它们加入词汇表中,并且保证它们在模型中不被切成sub-word,而是完整保留。分词粒度-子词分词法:
分词粒度:最常用的是子词分词法,会把上面的句子Today is Sunday分成最小可分的子词['To', 'day', 'is', 'S', 'un', 'day']。子词分词法有很多不同取得最小可分子词的方法,例如BPE,WordPiece,SentencePiece,Unigram等等。Word-Piece和BPE非常相似,BPE使用出现最频繁的组合构造子词词表,而WordPiece使用出现概率最大的组合构造子词词表。Embedding编码:
Embedding:tokenize完的下一步就是将token的one-hot编码转换成更dense的embedding编码。tokenizer将输入encode成数字输入给模型,模型generate出输出数字输入给tokenizer,tokenizer将输出数字decode成token并返回。 input_ids = tokenizer.encode('Hello World!', return_tensors='pt') output = model.generate(input_ids, max_length=50) tokenizer.decode(output[0]
理解Embedding矩阵:Embedding矩阵的本质就是一个查找表。由于输入向量是one-hot的,embedding矩阵中有且仅有一行被激活。每个单词会定位这个表中的某一行,而这一行就是这个单词学习到的在嵌入空间的语义。
24年大模型面试准备4|在龙年的祝福中聊一聊LLM的幻觉问题:https://mp.weixin.qq.com/s/qAMcc6uponv3cILlEm4PRw幻觉(Hallucination)的定义:
幻觉(Hallucination)的定义:LLM的输出不遵循原文(Faithfulness)或者不符合事实(Factualness),经常表现为一本正经地胡说八道。为什么LLM会产生幻觉?:
数据层面[数据质量直接关系到模型的可靠性和输出真实性]1.训练数据收集过程中,众包/爬虫检索的数据可能包含虚假信息,从而让模型记忆了错误的知识;2.过多的重复信息也可能导致模型的知识记忆出现bias,从而导致幻觉:
模型层面[模型设计和训练策略对减少幻觉同样至关重要]即使有了高质量训练数据,LLMs仍然可能表现出幻觉现象。1.模型结构:如果是较弱的backbone(比如RNN)可能导致比较严重的幻觉问题,但在LLMs时代应该不太可能存在这一问题;2.解码算法:研究表明,如果使用高不确定性的采样算法(如top-p采样)会诱导LMs出现更严重的幻觉问题。3.暴露偏差:训练和测试阶段不匹配的exposure bias问题可能导致LLMs出现幻觉,特别是生成长篇回应的时候。4.参数知识:LLMs在预训练阶段记忆的错误的知识,将会严重导致幻觉问题。5.基于LLM使用概率来推断输出的原理,幻觉这个问题很难彻底解决,xxxx推理流程中,模型固有的抽样随机性也可能导致模型产生幻觉。如何度量幻觉?:
如何度量幻觉?最有效可靠的方式当然是靠人来评估,其他自动化评估的指标:基于信息抽取IE,基于问答系统QA,基于蕴含率NLI,基于Factualness Classification Metric,还可以依靠LLM-GPT4打分评估。更具体的:
1.基于数据的工作:构建高质量数据集
人工标注
GO FIGURE: A meta evaluation of factuality in summarization
Evaluating factual consistency in knowledge-grounded dialogues via question generation and question answering
训练数据:LLM上不可行,只适用于task-specific的幻觉问题
评测数据:构建细粒度的幻觉评估benchmark用于分析幻觉问题
自动筛选:
利用模型打分,筛选出可能导致幻觉的数据并剔除;
预训练时给更faithful的数据加权(wiki vs. fake news),或者不使用可靠来源的数据(比如只选用经过人工审查的数据源,如wiki或者教科书,预训练)
2.模型层面的工作:优化模型结构
模型结构层面的工作往往focus在设计更能充分编码利用source information的方法,比如融入一些人类偏置,如GNN网络。
或者在解码时减少模型的生成随机性,因为diversity和Faithfulness往往是一个trade-off的关系,减少diversity/randomness可以变相提升Faithfulness/Factuality。
「检索增强」被证明可以显著减少幻觉问题,e.g., LLaMA-index。
3.模型层面的工作:优化训练方式
- 可控文本生成:将幻觉的程度作为一个可控的属性,利用可控文本生成技术进行控制。
- Increasing faithfulness in knowledgegrounded dialogue with controllable features
- A controllable model of grounded response generation
- 提前规划骨架,再生成:sketch to content
- Data-to-text generation with content selection and planning
- 强化学习:假设是基于word的MLE训练目标,只优化唯一的reference,可能导致暴露偏差问题。现有工作将减轻幻觉的指标作为强化学习的reward函数,从而减轻幻觉现象。
- Slot-consistent NLG for task-oriented dialogue systems with iterative rectification network
- Improving factual consistency between a response and persona facts
- 多任务学习: 通过设计合适的额外任务,可以达到减轻幻觉的效果。
- Improving faithfulness in abstractive summarization with contrast candidate generation and selection
如何缓解LLM幻觉:
如何缓解LLM幻觉?与幻觉有关的数据问题可以(至少理论上)通过创建高质量无噪声的数据集来解决。其他的方法:事实核心采样。通过使用外部知识验证主动检测和减轻幻觉。SelfCheckGPT采样多个输出并检查其一致性。
24年大模型面试准备5|LLM面试必会的位置编码之绝对位置编码sinusoidal:https://mp.weixin.qq.com/s/zVZb3wbYX-vEQlZgrgY4yA绝对位置编码sinusoidal:
绝对位置编码sinusoidal:绝对位置编码是直接将序列中每个位置的信息编码进模型的,从而使模型能够了解每个元素在序列中的具体位置。原始Transformer提出时采用了sinusoidal位置编码,通过使用不同频率的正弦和余弦的函数,使得模型捕获位置之间的复杂关系,且这些编码与序列中每个位置的绝对值有关。sinusoidal位置编码公式。1.首先,正余弦函数的范围是在 [-1,+1],导出的位置编码与原词嵌入相加,不会使得结果偏离过远而破坏原有单词的语义信息。2.其次,依据三角函数的基本性质,可以得知第 pos + k 个位置的编码是第 pos 个位置的编码的线性组合,这就意味着位置编码中蕴含着单词之间的距离信息。24年大模型面试准备6|LLM面试必会的位置编码之旋转位置编码RoPE:https://mp.weixin.qq.com/s/KUQtGb6r9KmSKLbnAo0HtA旋转位置编码RoPE:
旋转位置编码RoPE:RoPE 借助了复数的思想,出发点是通过绝对位置编码的方式实现相对位置编码。并被用于LLM的设计中,例如LLAMA系列、GLM、Baichuan、Qwen等。RoPE的设计思路可以这么来理解:我们通常会通过向量 q 和 k 的内积来计算注意力系数,如果能够对 q、k 向量注入了位置信息,然后用更新的q、k向量做内积就会引入位置信息。RoPE的表达式的推导【重点】:
假设 表示给在位置 的向量 添加位置信息的操作,如果叠加了位置信息后的 ( 位置 )和 ( 位置 )向量的内积可以表示为它们之间距离的差m-n的一个函数,那不就能够表示它们的相对位置关系了。也就是我们希望找到下面这个等式的一组解:RoPE研究就是为上面这个等式找到了一组解答,也就是
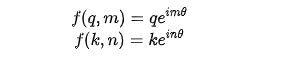
函数就是RoPE的表达式,此时就能够使得两个向量的内积包含它们的相对位置关系 了(在复数域,转为共轭内积后取实部)根据复数乘法的几何意义,这里函数 实际上是对应向量旋转,所以位置向量称为“旋转式位置编码”。还可以使用矩阵形式表示: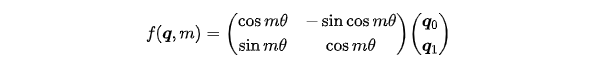 基于函数 的矩阵形式以及根据内积满足线性叠加的性质,任意偶数维的 RoPE,都可以表示为二维情形的拼接,即:
基于函数 的矩阵形式以及根据内积满足线性叠加的性质,任意偶数维的 RoPE,都可以表示为二维情形的拼接,即: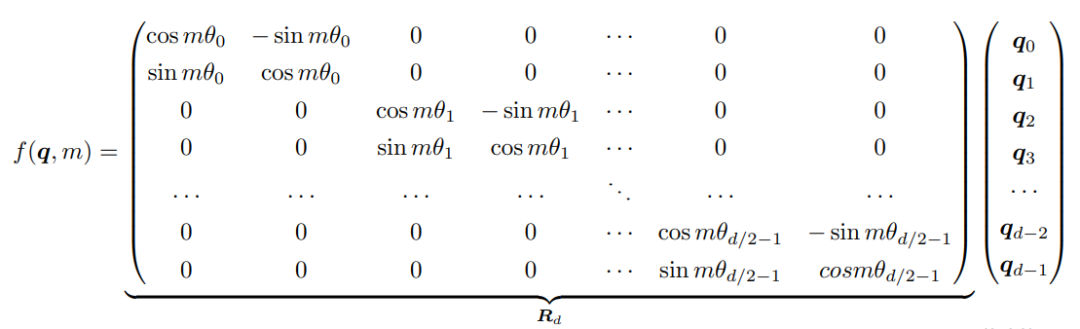
本文主要介绍思想,具体推导感兴趣的可以看苏剑林老师的博客或者论文:RoFormer: Enhanced Transformer with Rotary Position Embedding
LLaMA的RoPE代码实现:
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device) # type: ignore
freqs = torch.outer(t, freqs).float() # type: ignore
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return freqs_cis
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
【重点】RoPE的表达式的推导。LLaMA的RoPE代码实现。
24年大模型面试准备7|LLM面试必会的位置编码之相对位置编码ALiBi:https://mp.weixin.qq.com/s/JT5NizGtU2Hn2STcg3wKpg相对位置编码AliBi:
相对位置编码AliBi:与传统方法不同,ALiBi 不向单词embedding中添加位置embedding,而是根据token之间的距离给 attention score 加上一个预设好的偏置矩阵,比如 q 和 k 相对位置差 1 就加上一个 -1 的偏置,两个 token 距离越远这个负数就越大,代表他们的相互贡献越低。由于注意力机制一般会有多个head,这里针对每一个head会乘上一个预设好的斜率项(Slope)。也就是说,ALiBi 并不在 Embedding 层添加位置编码,而在 Softmax 的结果后添加一个静态的不可学习的偏置项。AliBi优点:ALiBi方法不需要对原始网络进行改动,允许在较短的输入序列上训练模型,同时在推理时能够有效地外推到较长的序列,从而实现了更高的效率和性能。位置编码的长度外推能力:
位置编码的长度外推能力来源于位置编码中表征相对位置信息的部分,相对位置信息不同于绝对位置信息,对于训练时的依赖较少。位置编码的研究一直是基于 Transformer 结构的模型重点。总结来说,为了有效地实现外推,当前主要有以下方法来扩展语言模型的长文本建模能力:1.增加上下文窗口的微调:采用直接的方式,即通过使用一个更长的上下文窗口来微调现有的预训练 Transformer,以适应长文本建模需求。2.位置编码:改进的位置编码,如 ALiBi[3]、LeX[4] 等能够实现一定程度上的长度外推。这意味着它们可以在短的上下文窗口上进行训练,在长的上下文窗口上进行推理。3.插值法:将超出上下文窗口的位置编码通过插值法压缩到预训练的上下文窗口中。
24年大模型面试准备8|图解Transformer最关键模块MHA:https://mp.weixin.qq.com/s/-jeuRsrOehG5ydba0txLugTransformer 原始论文中的模型结构。通过图解的方式对 Multi-Head Attention 的核心思想和计算过程做讲解。1.MHA核心思想:Google 的 Transformer 提出纯 Attention 就可以,单靠注意力一步到位获取了全局信息!Transformer的解决方案是:yt = f(xt , A ,B)。其中 A, B 是另外一个序列(矩阵)。如果都取 A = B = X ,那么就称为 Self Attention,它的意思是直接将 xt 与原来的每个词进行比较,最后算出 yt。
2.Transformer 中的 Multi-Head Attention 可以细分为3种,Multi-Head Self-Attention(对应上图左侧Multi-Head Attention模块),Multi-Head Cross-Attention(对应上图右上Multi-Head Attention模块),Masked Multi-Head Self-Attention(对应上图右下Masked Multi-Head Attention模块)。其中 Self 和 Cross 的区分是对应的 和 是否来自相同的输入。是否Mask的区分是是否需要看见全部输入和预测的输出,Encoder需要看见全部的输入问题,所以不能Mask;而Decoder是预测输出,当前预测只能看见之前的全部预测,不能看见之后的预测,所以需要Mask。
3.注意力计算公式如下: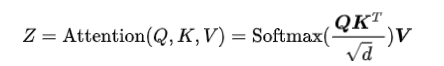 4.多头注意力:MHA通过多个头的方式,可以增强自注意力机制聚合上下文信息的能力,以关注上下文的不同侧面,作用类似于CNN的多个卷积核。24年大模型面试准备9|黎明前夜:初代GPT之奠基:https://mp.weixin.qq.com/s/FD7_pOGgk-w9Zfjdv1zX3w
4.多头注意力:MHA通过多个头的方式,可以增强自注意力机制聚合上下文信息的能力,以关注上下文的不同侧面,作用类似于CNN的多个卷积核。24年大模型面试准备9|黎明前夜:初代GPT之奠基:https://mp.weixin.qq.com/s/FD7_pOGgk-w9Zfjdv1zX3wGPT方法动机:
GPT 是 Generative Pre-Training 的缩写,即生成式预训练,来自 OpenAI 的论文 Improving Language Understanding by Generative Pre-Training。Generative Pre-Training 包含两大方面的含义:
1.Pre-Training:指的是大规模自监督预训练,即在大规模没有标签的文本数据上,自监督地完成模型训练,这样就可以利用并发挥出海量无标签文本数据的价值;2.Generative:自监督预训练是通过Next Token Prediction的方式实现的,即是一种生成式的训练方式。因此GPT的基本思想是:先在大规模没有标签的数据集上训练一个预训练模型,即generative pre-training的过程;再在子任务小规模有标签的数据集上训练一个微调模型,即discriminative fine-tuning的过程。GPT模型结构:
自监督预训练和有监督微调
x
GPT的更多细节:数据集+网络结构+预训练参数+有监督微调
1.数据集-GPT使用了BooksCorpus数据集,这个数据集包含 7000 本没有发布的书籍。
2.网络结构-GPT是Decoder-Only结构,使用了12层的 transformer,使用了掩码自注意力头,掩码的使用使模型看不见未来的信息,得到的模型泛化能力更强。3.预训练参数-使用字节对编码(BPE),共有 40,000 个字节对;词编码的长度为 768;位置编码也需要学习;12层的 transformer,每个 transformer 块有 12 个头;位置编码的长度是 3,072;Attention,残差,Dropout 等机制用来进行正则化,drop比例为 0.1;激活函数为 GLEU;训练的 batchsize 为 64,学习率为 2.5e-4,序列长度为 512,序列 epoch 为 100;模型参数数量为 1.17 亿。4.有监督微调-无监督部分的模型也会用来微调;训练的epoch为 3,学习率为 6.25e-5,这表明模型在自监督阶段学到了大量有用的特征。GPT 模型与BERT最大的区别在于GPT采用了传统的语言模型方法进行预训练, 即使用单词的上文来预测单词, 而BERT是采用了双向上下文的信息共同来预测单词。正是因为训练方法上的区别, 使得GPT更擅长处理自然语言生成任务(NLG), 而BERT更擅长处理自然语言理解任务(NLU)。
24年大模型面试准备10|破晓晨光:二代GPT之进化:https://mp.weixin.qq.com/s/Xt377KIULJ3kMpFgOIOk2wGPT-2核心思想:
GPT-2的学习目标是使用无监督的预训练模型做有监督的任务。GPT-2的核心思想概括为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。在大数据和大模型的加持下,由GPT-1的Pre-Training + Fine-Tuning,改成了GPT-2的Pre-Training + Prompt Predict (Zero-Shot Learning)。
GPT-2训练方式同GPT-1一样,只是数据量变大,模型参数变大,模型结构只是做了几个地方的调整,这些调整更多的是被当作训练时的 trick,而不作为 GPT-2 的创新。GPT-2的Zero-Shot Predict:
1.GPT-2下游任务转向做zero-shot而放弃微调(fine-tuning)。因此,GPT-2使用新的输入形态:增加文本提示,后来被称为prompt。
2.多任务学习Multitask Learning是什么?可以通过同时学习多个相关的任务来提高模型的性能和泛化能力。与单任务学习只针对单个任务进行模型训练不同,多任务学习通过共享模型的部分参数来同时学习多个任务,从而可以更有效地利用数据,提高模型的预测能力和效率。如何做到多任务学习Multitask Learning呢?把所有的任务都归结为上下文的问题回答。具体的,应该满足如下的条件:1.必须对所有任务一视同仁,也就是喂给模型的数据不能包含这条数据具体是哪个任务,不能告诉模型这条数据是要做NMT,另一条数据要做情感分类。2.模型也不能包含针对不同任务的特殊模块。给模型输入一段词序列,模型必须学会自己辨别这段词序列要求的不同的任务类型,并且进行内部切换,执行不同的操作。3.模型还应具备执行训练任务之外的任务的能力,即 zero shot learning。3.Zero-Shot Learning:GPT-2 最大的改变是抛弃了前面“无监督预训练+有监督微调”的模式,而是开创性地引入了 Zero-shot 的技术,即预训练结束后,不需要改变大模型参数即可让它完成各种各样的任务。Zero-shot的含义:用预训练模型做下游任务时,不需要任何额外的标注信息,也不去改模型参数。GPT-2模型结构:
在模型结构方面,整个 GPT-2 的模型框架与 GPT-1 相同,只是做了几个地方的调整,这些调整更多的是被当作训练时的 trick,而不作为 GPT-2 的创新,具体为以下几点:1.后置层归一化( post-norm )改为前置层归一化( pre-norm ); 2.在模型最后一个自注意力层之后,额外增加一个层归一化; 3.调整参数的初始化方式,按残差层个数进行缩放,缩放比例为 1 : sqrt(n);4.输入序列的最大长度从 512 扩充到 1024; 5.模型层数扩大,从 GPT-1 的 12 层最大扩大到 48 层,参数量也从 1 亿扩大到 15 亿。关于 post-norm 和 pre-norm:两者的主要区别在于,post-norm 将 transformer 中每一个 block 的层归一化放在了残差层之后,而 pre-norm 将层归一化放在了每个 block 的输入位置。GPT-2 进行上述模型调整的主要原因在于,随着模型层数不断增加,梯度消失和梯度爆炸的风险越来越大,这些调整能够减少预训练过程中各层之间的方差变化,使梯度更加稳定。GPT-2训练数据:
在训练数据方面,为了保证 zero-shot 的效果,必须要足够大且覆盖面广。所以 GPT-2 专门爬取了大量的网络文本数据,最后得到的数据集叫 WebText。GPT-2 选取了 Reddit 上的高质量帖子,最终得到 4500w 网页链接,800w 有效的文本文档,语料大小为 40G。
24年大模型面试准备11|势不可挡:三代GPT之涌现:https://mp.weixin.qq.com/s/cMKos6OXbzos8Ke1Q_JyJQGPT-3 中的 few-shot learning,只是在预测的时候给几个例子,并不微调网络。GPT-2用 zero-shot 去讲了 multitask Learning 的故事,GPT-3 使用 meta-learning 和 in-context learning 去讲故事。GPT-3自监督预训练:
GPT-3训练方式同 GPT-1 和 GPT-2 一样,只是数据量和模型参数都得到了巨幅提升,网络结构也做了一些优化。
GPT-3的In-context learning:
In-context learning 是 GPT-3 运用的一个重要概念,本质上是属于 few-shot learning,只不过这里的 few-shot 只是在预测的时候给几个例子,并不微调网络,即不会再更新模型权重。
GPT-3的上下文学习能力究竟从何而来:
Few-shot (in-context learning,)虽然与 fine-tuning 一样都需要一些有监督标注数据,但是两者的区别是:1.fine-tuning 基于标注数据对模型参数进行更新,而 in-context learning 使用标注数据时不做任何的梯度回传,模型参数不更新【本质区别】;2.in-context learning 依赖的数据量(10~100)远远小于 fine-tuning 一般的数据量。
Few-shot 模式也有缺陷:1.GPT-3 的输入窗口长度是有限的,不可能无限的堆叠example的数量,即有限的输入窗口限制了我们利用海量数据的能力;2.每次做一次新的预测,模型都要从输入的中间抓取有用的信息。可是我们做不到把从上一个输入中抓取到的信息存起来,存在模型中,用到下一次输入里。GPT-3模型结构:
GPT-3 沿用了GPT-2 的结构,但是在网络容量上做了很大的提升,并且使用了一个 Sparse Transformer 的架构,具体如下:1.GPT-3采用了96层的多头transformer,头的个数为 96; 2.词向量的长度是12,888; 3.上下文划窗的窗口大小提升至2,048个token; 4.使用了alternating dense和locally banded sparse attention。
GPT-3训练数据:
由于 GPT-3 在模型规模上的扩大,在训练数据方面也必须进行扩充来适配更大的模型使其发挥出相应的能力。GPT-3 使用了多个数据集,其中最大的是 CommonCrawl,做一些额外的数据清洗工作来尽量保证数据的质量。
CommonCrawl数据处理主要包括以下几个部分:1.使用高质量数据作为正例,训练 LR 分类算法,对 CommonCrawl 的所有文档做初步过滤;2.利用公开的算法做文档去重,减少冗余数据;3.加入已知 BERT.GPT-2 的高质量数据集。sparse attention:
sparse attention 与传统 self-attention(称为 dense attention) 的区别在于:dense attention:每个 token 之间两两计算 attention,复杂度 O(n²)sparse attention:每个 token 只与其他 token 的一个子集计算 attention,复杂度 O(n*logn)具体来说,sparse attention 除了相对距离不超过 k 以及相对距离为 k,2k,3k,... 的 token,其他所有 token 的注意力都设为 0,使用 sparse attention 的好处主要有以下两点:减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;具有“局部紧密相关和远程稀疏相关”的特性,对于距离较近的上下文关注更多,对于距离较远的上下文关注较少。
24年大模型面试准备12|ChatGPT 的内核——InstructGPT:https://mp.weixin.qq.com/s/Z0u6mHSywWyiJo9iGMKMgQInstructGPT 技术方案:
关于 InstructGPT 的技术方案,原文分为了三个步骤:有监督微调,奖励模型训练,强化学习训练;实际上可以把它拆分成两种技术方案,一个是有监督微调(SFT),一个是基于人类反馈的强化学习(RLHF)。1.有监督微调(SFT)过程:a.采样一个 GPT-3 的下游任务样本;b.标注者根据这个样本的开头续写出完整内容;c.基于标注者续写完成的样本微调 GPT-3;InstructGPT 在 SFT 中标注的数据,正是为了消除这种模型预测与用户表达习惯之间的 gap。在标注过程中,他们从 GPT-3 的用户真实请求中采样大量下游任务的描述,然后让标注人员对任务描述进行续写,从而得到该问题的高质量回答。这里用户真实请求又被称为某个任务的指令(Instruct),即 InstructGPT 的核心思想“基于人类反馈的指令微调”。2.基于人类反馈的强化学习(RLHF)过程:a.收集人类反馈;b.训练奖励模型;c.训练策略模型PPO;InstructGPT 总结:
InstructGPT 总结:InstructGPT 的核心思想“基于人类反馈的指令微调”。解决 GPT-3 的输出与人类意图之间的 Align 问题;让具备丰富世界知识的大模型,学习“人类偏好”;标注人员明显感觉 InstructGPT 的输出比 GPT-3 的输出更好,更可靠;InstructGPT 在真实性,丰富度上表现更好;InstructGPT 对有害结果的生成控制得更好,但是对于“偏见”没有明显改善;基于指令微调后,在公开任务测试集上的表现仍然良好;InstructGPT 有令人意外的泛化性,在缺乏人类指令数据的任务上也表现很好。
24年大模型面试准备13 | 国产大模型的导师或内核——LLaMA v1和v2:https://mp.weixin.qq.com/s/0-q1EE8aYd8EagBrFPHb0wLLaMA模型结构:
LLaMA V1 和 V2 模型结构基本相同,主要由 Attention 和 MLP 堆叠而成,如下图所示。LLaMAV1主要特点:
1.前置的 RMSNorm;2.在Q、K上使用旋转式位置编码 RoPE;3.使用 Causal Mask 保证每个位置只能看到前面的 Tokens;
4.可以将更早的 K、V 拼接到当前 K、V 前面,可以用 Q 查找更早的信息;5.MLP表达式:down(up(x) * SILU(gate(x))),其中 down、up、gate 都是线性层 Linear。LLaMA V2 相对 V1 的更新:
1.预训练语料从 1 Trillion tokens -> 2 Trillion tokens;2.context window 长度从 2048 -> 4096;3.收集了 100k 人类标注数据进行 SFT;
4.收集了 1M 人类偏好数据进行RLHF;5.在 reasoning, coding, proficiency, and knowledge tests 上表现超越 MPT 和 Falcon;6.和 Falcon 模型一样,使用了 Group Query Attention,节省 cache。LLaMA的RMSNorm+SwiGLU+Rope:
RMSNorm:BERT、GPT 等模型中广泛使用的是 LayerNorm。RMSNorm发现 LayerNorm 的中心偏移没什么用(减去均值等操作)。将其去掉之后,效果几乎不变,但是速度提升了40%。注意除了没有减均值、加偏置以外,分母上求的 RMS 而不是方差。LLaMA 在 Attention Layer 和 MLP 的输入上使用了 RMSNorm,相比在输出上的使用,训练会更加稳定。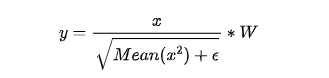
SwiGLU:LLaMA 没有使用 ReLU,而是使用了 SwiGLU,有时也被称为 SiLU。SwiGLU 的效果类似平滑版的 ReLU。RoPE:LLaMA 使用的位置编码是 RoPE。对于 Q 的第 m 个位置向量 q,通过以下方法注入位置编码。其中 θ是值介于 [1,0) 之间的固定向量。RoPE 形式上是绝对位置编码,即依赖其绝对位置m;但当我们计算 Attention 时,RoPE 却可以变成相对位置编码。那绝对位置编码的 RoPR 在计算 Attention 时是怎么变成相对位置编码的呢?从上面这个公式可以看出,q 和 k 的 attention 依赖相对距离 m-n。因此 RoPE 为 q、k 注入的绝对位置编码,计算得到的 attention,却变成了相对位置编码。LLaMA的Rope代码实现:
#1.得到f(q,m)上式中的第二项cos(mθi) 和第四项 sin(mθi):class LlamaRotaryEmbedding(torch.nn.Module): def __init__(self, dim, max_position_embeddings=2048, base=10000): theta = 1.0 / (base ** (torch.arange(0, dim, 2) / dim)) t = torch.arange(max_position_mbeddings) freqs = torch.einsum("i,j->ij", t, theta) emb = torch.cat((freqs, freqs), dim=-1) self.register_buffer("cos_cached", emb.cos()) self.register_buffer("sin_cached", emb.sin()) def forward(self, seq_len=None): return self.cos_cached[:, :, :seq_len, ...], self.sin_cached[:, :, :seq_len, ...]# 在LlamaAttention通过以下命令调用:cos, sin = self.rotary_emb(seq_len=kv_seq_len)#2.再通过以下代码将 q 沿着最后一个维度劈成两半,将后一半乘 -1,然后连接在第一半之前,就得到了上式第三项:# 在接下来的apply_rotary_pos_emb函数里调用 x1 = x[..., : x.shape[-1] // 2] x2 = x[..., x.shape[-1] // 2 :] return torch.cat((-x2, x1), dim=-1)#3.最后通过以下代码得到结合了位置编码的 Q,K (K和Q使用同样的方式进行位置编码):def apply_rotary_pos_emb(q, k, cos, sin, position_ids): q_embed = (q * cos[position_ids]) + (rotate_half(q) * sin[position_ids]) k_embed = (k * cos[position_ids]) + (rotate_half(k) * sin[position_ids])# 在LlamaAttention中通过以下命令调用:query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
24年大模型面试准备14 | 简单透彻理解MoE:https://mp.weixin.qq.com/s/AW7hYFj0K4bxQ2FQqJVQYwMoE介绍【Mixture of Experts】:
MoE(混合专家模型)从本质上来说就是一种高效的 scaling 技术,用较少的 compute 实现更大的模型规模,从而获得更好的性能。
模型规模是提升模型性能的关键因素之一。在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。MoE 的显著优势是它们能够在远少于稠密模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。MoE结构和原理:
作为一种基于 Transformer 架构的模型,MoE 主要由两个关键部分组成:
1.稀疏 MoE 层: 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”(例如 8 个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。2.门控网络或路由: 这个部分用于决定哪些 token 被发送到哪个专家。一般 input Token 会被 router 分配到一个或多个 expert 上做处理。如果是多个 expert 处理同一个 input token,那么不同 expert 的输出会再做一次 aggregate,作为 input token 的最终 output。例如,在下图中,“More”这个 token 被发送到第二个专家,而“Parameters”这个 token 被发送到第一个专家。Token 的 router 方式是 MoE 使用中的一个关键点,因为 router 由可学习的参数组成(一般是由一个 Linear 层和一个 Softmax 层组成),并且与网络的其他部分一同进行预训练。
24年大模型面试准备15 | 数据篇一:LLM数据都是从哪来的?:https://mp.weixin.qq.com/s/tfkmxxpMcnznNnGBJFlW0gGPT-3训练数据来源:
OpenAI GPT-3 的论文[1]介绍了其训练数据的来源,包含经过过滤的 CommonCrawl 数据集[2]、WebText2、Books1、Books2 以及英文 Wikipedia 等数据集合。其中 CommonCrawl 的原始数据有 45TB,进行过滤后仅保留了 570GB 的数据。通过词元方式对上述语料进行切分,大约一共包含 5000 亿词元。为了保证模型使用更多高质量数据进行训练,在 GPT-3 训练时,根据语料来源的不同,设置不同的采样权重。在完成 3000 亿词元训练时,英文 Wikipedia 的语料平均训练轮数为 3.4 次,而 CommonCrawl 和 Books 2 仅有 0.44 次和 0.43 次。由于 CommonCrawl 数据集合的过滤过程繁琐复杂,Meta 公司的研究人员在训练 OPT[3] 模型时则采用了混合 RoBERTa[4]、Pile[5] 和 PushShift.io Reddit[6] 数据的方法。由于这些数据集合中包含的绝大部分都是英文数据,因此 OPT 也从 CommonCrawl 数据集中抽取了部分非英文数据加入训练语料。LLM训练数据来源和分布:
1.通用数据(General Data)包括网页Webpage、图书Book、新闻、对话文本 Conversation Text等内容[7, 8, 9]。通用数据具有规模大、多样性和易获取等特点,因此可以支持 LLM 的构建语言建模和泛化能力。
2.专业数据(Specialized Data)包括多语言数据Multilingual Text、科学数据Scientific Text、代码Code以及领域特有资料等数据。通过在预训练阶段引入专业数据可以有效提供 LLM 的任务解决能力。下图给出了一些典型 LLM 所使用数量类型的分布情况。可以看到不同的 LLM 在训练类型分布上的差距很大,截止目前,还没有得到广泛认可的数据类型分布比例。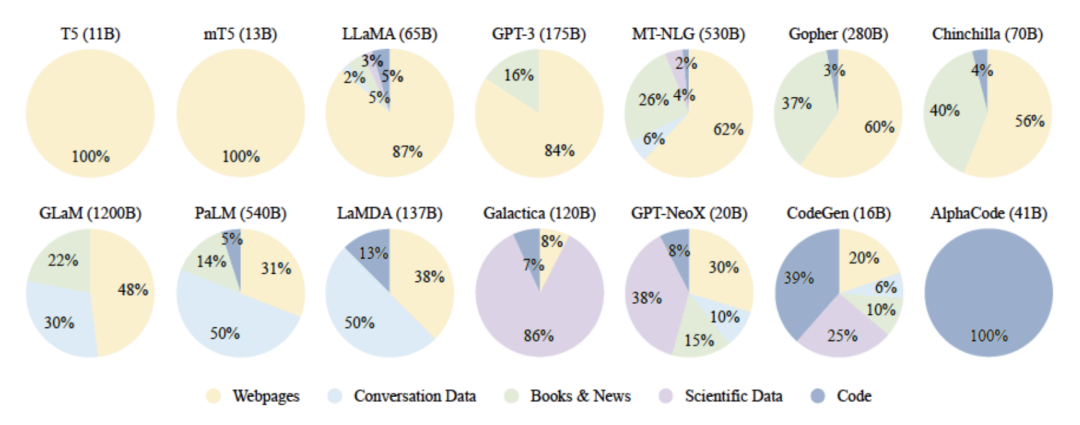
24年大模型面试准备16 | 数据篇二:LLM数据怎么处理?:https://mp.weixin.qq.com/s/CBiYWdf38ybAzhhLgIhTmgLLM训练数据都是怎么处理的:
典型的数据处理过程如下图所示,主要包含质量过滤、冗余去除、隐私消除、词元切分这四个步骤。
24年大模型面试准备17 | 数据篇三:LLM数据有哪些影响?:https://mp.weixin.qq.com/s/manP-GQ_eeOgksSzbv0e1A本篇将从数据规模、数量质量以及数据多样性三个方面分析数据对大语言模型的性能的影响。数据规模影响:
DeepMind 的研究发现,如果模型训练要达到计算最优(Compute-optimal),模型大小和训练词元Tokens数量应该等比例缩放,即模型大小加倍则训练词元Tokens数量也应该加倍。
LLaMA 模型在训练时采用了与文献 [1] 相符的训练策略。研究发现,70 亿参数的语言模型在训练超过1T Tokens后,性能仍在持续增长。在 LLaMA 2 模型训练中增大训练数据量达到2T Tokens。数据质量影响:
结论:语言模型在经过清洗的高质量数据上训练数据可以得到更高的性能。Google Research 的研究结果表明[5],语言模型训练数据的时间、内容过滤方法以及数据源对下游模型行为具有显著影响。Anthropic 的研究[6]发现了强烈的双峰下降现象,即重复数据可能会导致训练损失在中间阶段增加。数据多样性影响:
LLaMA 模型训练混合了大量不同来源数据,包括网页、代码、论文、图书、百科等。针对不同的文本质量,LLaMA 模型训练针对不同质量和重要性的数据集设定了不同的采样概率。
Gopher 模型训练过程对数据分布进行了消融实验,验证混合来源对下游任务的影响情况。7 种不同子集采样权重训练得到 Gopher 模型在下游任务上的性能。可以看到,使用不同数量子集采样权重训练,所获得模型效果差别很大。
24年大模型面试准备18 | 数据篇四:LLM经典开源数据介绍:https://mp.weixin.qq.com/s/dvles60DPU6jdGy9pEm0XQPile数据集:
Pile 数据集[1] 是用于大语言模型训练的多样性大规模文本语料库,由 22 个不同的高质 量子集构成,包括现有的和新构建的,许多来自学术或专业来源。这些子集包括 Common Crawl、 Wikipedia、OpenWebText、ArXiv、PubMed 等。Pile 的特点是包含了大量多样化的文本,涵盖了不同领域和主题,从而提高了训练数据集的多样性和丰富性。Pile 数据集总计规模大小有 825GB 英文文本,其数据类型组成如下图所示,所占面积大小表示数据在整个数据集中所占的规模。
RefinedWeb数据集:
RefinedWeb[6] 是TII 在开发 Falcon 大语言模型时同步开源的大语言模型预训练集合。其主要由从 CommonCrawl 数据集过滤的高质量数据组成。CommonCrawl 数据集包含自 2008 年以来爬取的数万亿个网页,由原始网页数据、提取的元数据和文本提取结果组成,总数据量超过 1PB。CommonCrawl 数据集以 WARC(Web ARChive)格式或者 WET 格式进行存储。WARC 是一种用于存档 Web 内容的国际标准格式,它包含了原始网页内容、HTTP 响应头、URL 信息和其他元数据。WET 文件只包含抽取出的纯文本内容。
SlimPajama数据集:
SlimPajama[11] 是由 CerebrasAI 公司针对 RedPajama 进行清洗和去重后得到的开源数据集合。原始 RedPajama 包含 1.21 万亿词元(1.21T Token),经过处理后的 SlimPajama 数据集包含 6270 亿词元(627B Token)。SlimPajama 还开源了用于对数据集进行端到端预处理的脚本。
RedPajama 是由 TOGETHER 联合多家公司发起的开源大语言模型项目,试图严格按照 LLaMA 模型论文中的方法构造大语言模型训练所需数据。虽然 RedPajama 数据质量较好,但是 CerebrasAI 的研究人员发现 RedPajama 数据集还是存在两个问题:1)一些语料中缺少数据文件;2)数据集中包含大量重复数据。为此,CerebrasAI 的研究人员开始针对 RedPajama 数据集开展进一步的处理。SlimPajama 的整体处理过程如下图所示。整体处理包括多个阶段:NFC 正规化、清理、去重、文档交错、文档重排、训练集和保留集拆分,以及训练集与保留集中相似数据去重等步骤。所有步骤都假定整个数据集无法全部装载到内存中,并分布在多个进程中进行处理。使用 64 个 CPU,大约花费 60 多个小时就是完成 1.21 万亿词元处理。在整个处理过程中所需要内存峰值为 1.4TB。
24年大模型面试准备19 | 怎样训练一个自己的大语言模型?这可能是全网最简单易懂的教程!:https://mp.weixin.qq.com/s/F60XYsT1dwUBmXN6r2G0eA基于Llama-2-7B-Chat 微调LLM:
Github代码:https://github.com/zzzichen277/LLM_SFT
24年大模型面试准备20 | 怎样让英文大语言模型支持中文?——构建中文tokenization:https://mp.weixin.qq.com/s/_WCpSC7i1vlj_RBu4fVOLg基于 llama 家族的模型主要训练语料为英文语料,中文语料占比较少,直接导致基于 llama 家族的模型对于中文的支持不太友好。需要去扩充 vocab 里面的词以对中文进行 token 化。对数据进行预处理,将每一行转化为一句或多句话,过滤掉换行和无效内容。采用 sentencepiece 训练中文词库。spm.SentencePieceTrainer.train()。运行后会得到 tokenizer.model 和 tokenizer.vocab 两个文件。参考使用 sentencepiece_chinese_bpe/chinese_bpe.py参考使用sentencepiece_chinese_bpe/chinese_llama_bpe.py将原始词表中没有的新词加入词表中。参考使用https://github.com/yangjianxin1/LLMPruner如何构建中文tokenization?1.使用 sentencepiece 训练一个中文的词表。2.使用 transformers 加载 sentencepiece 模型。3.合并中英文的词表,并使用 transformers 使用合并后的词表。4.在模型中使用新词表。24年大模型面试准备21 | 怎样让英文大语言模型支持中文?——继续预训练:https://mp.weixin.qq.com/s/6p8MQm84L9SG5eMLFoCv-w新增加了一些中文词汇到词表中,这些词汇是没有得到训练的,因此在进行指令微调之前要进行预训练。参考使用chinese_llm_pretrained/test_dataset.py先使用tokenizer()得到相关的输入,需要注意的是可能会在文本前后添加特殊的标记,比如bos_token_id和eos_token_id,针对于不同模型的tokneizer可能会不太一样。这里在unput_ids前后添加了21134和21133两个标记。然后将所有文本的input_ids、attention_mask, token_type_ids各自拼接起来(展开后拼接,不是二维数组之间的拼接),再设定一个最大长度block_size,这样得到最终的输入。参考使用chinese_llm_pretrained/test_model.py参考使用https://github.com/taishan1994/chinese_llm_pretrained#%E8%AE%AD%E7%BB%83训练脚本如下:torchrun --nnodes 1 --nproc_per_node 1 run_clm_pt_with_peft.py \xxx参考使用https://github.com/taishan1994/chinese_llm_pretrained?tab=readme-ov-file#%E4%BD%BF%E7%94%A8%E6%A8%A1%E5%9E%8B
24年大模型面试准备22 | 怎样让英文大语言模型支持中文?——对预训练模型进行指令微调:https://mp.weixin.qq.com/s/BtFowCkYi3QpBSk59XHDzA指令微调是使用高质量的任务相关的数据来训练模型,使得模型具备指令理解能力和上下文理解能力,进而使得模型的输出更符合任务需求或者人类偏好,比如使得模型能够更好的完成开放领域问题、阅读理解、翻译、生成代码等。在模型的官方代码上找到模型的数据格式buid_instruction_dataset()参考使用chinese_llm_sft/test_tokenizer.py模型构建方式一般使用的是AutoTokenizer和AutoModelForCausalLM参考chinese_llm_sft/test_model.py参考使用https://github.com/taishan1994/chinese_llm_sft#%E6%B5%81%E7%A8%8B训练脚本如下:torchrun --nnodes 1 --nproc_per_node 1 run_clm_sft_with_peft.py \xxx参考使用chinese_llm_sft/test_sft_model.py
24年大模型面试准备23 | 再谈大火的MoE:https://mp.weixin.qq.com/s/aVhVcNsfYPgAdWhoy_epKQMoE原理回顾:
1.MoE 是用稀疏 MoE 层替换前馈层。这些层包含一定数量的专家(例如 8 个),每个专家都是一个神经网络(通常是 FFN)。然后,路由器/门网络负责选择要使用的专家。
2.MoE 具有预训练速度快的特点,通过只激活所需的参数数量,从而获得更快的训练和推理速度。典型的 MoE 架构的大语言模型:Switch Transformers、Mixtral、DBRX、Jamba DeepSeekMoE 等等。MoE分类与对比:
1.Pretrain MoE:Pretrain MoE (预训练 MoE)旨在利用 MoE 架构从头开始预训练语言模型,以期获得比传统密集模型更高效的训练效果。代表性的预训练 MoE 模型有 Switch Transformer、Mixtral 等。
2.Upcycled MoE:Upcycled MoE(再利用 MoE)的思路是在一个已经训练好的基础模型上,通过复制其前馈网络来创建多个专家,形成一个 MoE 模型。Upcycled MoE 的代表性工作包括 DeepSeek-MoE、Upstage SOLAR 等。3.Franken MoE:Franken MoE(转基因 MoE)的思路与模型合并类似,即选择几个在特定任务上表现优异的微调模型,将它们组合成一个 MoE 模型。通过一定的训练,可以让路由器学会将不同类型的 token 发送给对应的专家。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
