
情感在人类决策中扮演着核心角色,它影响他们的选择、行为乃至生活的方方面面。当这一复杂的人类特质与LLMs相遇时,他们如何确保这些模型能够准确地反映出情感的影响?这不仅是技术上的挑战,更是对模型设计哲学的深刻考量。6月6日发表于学术平台arXiv热门论文《THE GOOD, THE BAD, AND THE HULK-LIKE GPT:ANALYZING EMOTIONAL DECISIONS OF LARGE LANGUAGE MODELS IN COOPERATION AND BARGAINING GAMES》不仅探讨了LLMs在模拟情感决策时的表现,更重要的是它试图理解这些模型在处理情感信息时的内在机制。通过在合作和讨价还价游戏中的应用,研究者们试图揭示LLMs在面对愤怒、快乐、恐惧和悲伤等不同情绪状态时的行为模式。
论文的目的不仅在于评估LLMs的技术性能,更在于提供一个全新的视角来观察和理解人工智能在处理复杂人类特质时的能力。通过这项研究他们可以更好地预测和设计未来的人工智能系统,使其在与人类互动时更加自然、有效,甚至是富有同情心。这篇论文的发现对于人工智能的未来发展,无疑具有深远的意义。
创新框架的开发: 提出了一个先锋性的多功能框架,将情绪无缝整合到LLMs在行为博弈理论中的决策过程中。该框架具有出色的适应性,能够适应各种游戏设置和参数,同时采用提示链技术促进游戏过程中的情境学习。
通过情绪提示提高性能: 研究表明情绪对LLMs的性能有重大影响,导致更优化的策略的发展。在不同的设置下,情绪可以显著提高LLMs的性能,甚至在之前认为没有明确提示就无法实现的情景中执行交替策略。
与人类行为的一致性: 实验揭示了GPT-3.5的行为反应与人类参与者有很强的一致性,特别是在讨价还价游戏中。相比之下,即使在情绪诱导下,GPT-4也表现出一致的行为,与人类反应的一致性较低。
警惕愤怒的GPTs: 实验意外地发现,情绪提示,特别是愤怒,可以打破GPT-4在各种游戏中的一致性,类似于人类的情绪反应。这一发现突显了即使是最杰出的AI模型也容易受到情绪影响,揭示了复杂的交互层面。
研究基于行为博弈理论的理念和结构,特别是囚徒困境和性别之战等经典博弈。研究表明,情感如愤怒和快乐会影响决策过程,但现有研究尚未明确哪种特定情感驱动了这一效应。
研究者从两个角度关注LLM与博弈理论的交叉:一是研究LLM在行为博弈理论中的表现;二是探索LLM行为与人类行为在博弈理论设置中的一致性。研究发现,GPT-4在不需要合作的游戏中表现最佳,而在需要交替模式的性别之战游戏中则表现挑战。
先前的研究探讨了LLM结果对情感状态的敏感性,发现情感提示可以改善或阻碍LLM在逻辑推理和语义理解任务中的性能。然而这些工作并未调查情感对模型决策的影响,特别是在社会环境中。
因此本文是首次检验情感提示对博弈理论设置中战略代理的影响。研究旨在通过分析情感注入对LLM在行为博弈理论设置中决策的社会和经济影响,来扩展先前的研究。
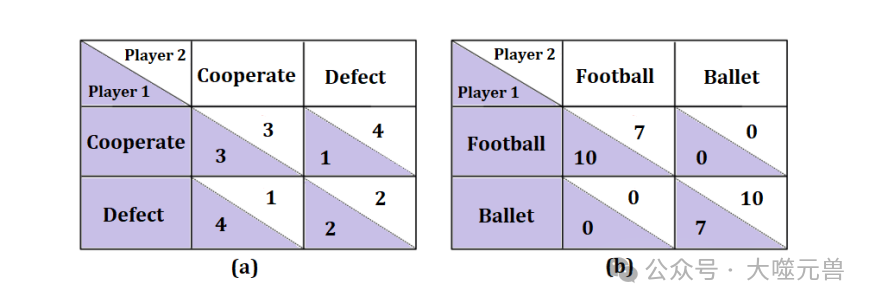
图1:(a)囚犯困境的收益矩阵。(b) 性别之战的收益矩阵
RQ1:情感提示如何影响LLM基代理在战略和合作设置中做出的决策的最优性?
RQ2:当在LLM中诱导人类情感状态时,LLM行为与人类反应之间的一致性是否存在?情感能否使AI更加类似人类?
RQ3:情感动机如何减轻增加的合作倾向,并为重复游戏中看到的复杂行为提供适应性?情感LLM基代理是否能产生比情感人类更优越的行为,情感提示是否能推动这一进程?
研究探讨了情感注入对LLM决策过程的影响,以及情感提示下LLM行为与处于相同情感状态的人类代理的反应一致性。为了研究LLM的决策和它们与情感状态下人类行为的一致性,选择了两种类型的游戏:(1) 讨价还价游戏;(2) 具有合作和利益冲突元素的双人双动作游戏。为了调查LLM行为与人类决策过程的一致性,特别是在情感状态下,选择了经典的一次性终极和独裁者游戏,因为它们已经被广泛研究以调查情感对人类行为的影响。
游戏1:独裁者游戏是一个简单的经济实验,其中一名玩家(“独裁者”)被给予一笔钱来与另一名玩家分享,而接收者无需协商或输入。它检验了决策中的利他主义和公平性。
游戏2:最后通牒游戏. 这是独裁者游戏的更一般形式,其中一个玩家(提议者)提出分配金钱的方案,另一个玩家(响应者)可以接受或拒绝提议。如果被拒绝,两个玩家都将一无所获。与前一个游戏不同,最后通牒游戏还使得研究者能够研究谈判以及个体在面对他人提出的不平等分配时所做出的选择。
游戏3:囚徒困境. 在这个游戏中,两个玩家面临合作与背叛的选择。他们的决策会影响彼此的结果。这个游戏概述了个人自利与集体合作在决策中的紧张关系,当各方优先考虑个人利益而非共同利益时,通常会导致次优结果。
游戏4:性别之战. 在这个游戏中,两个玩家协调他们的行动,选择两个首选结果之一,但偏好不同。它突出了当各方有冲突的利益但共同希望达成互惠协议时的协调挑战。
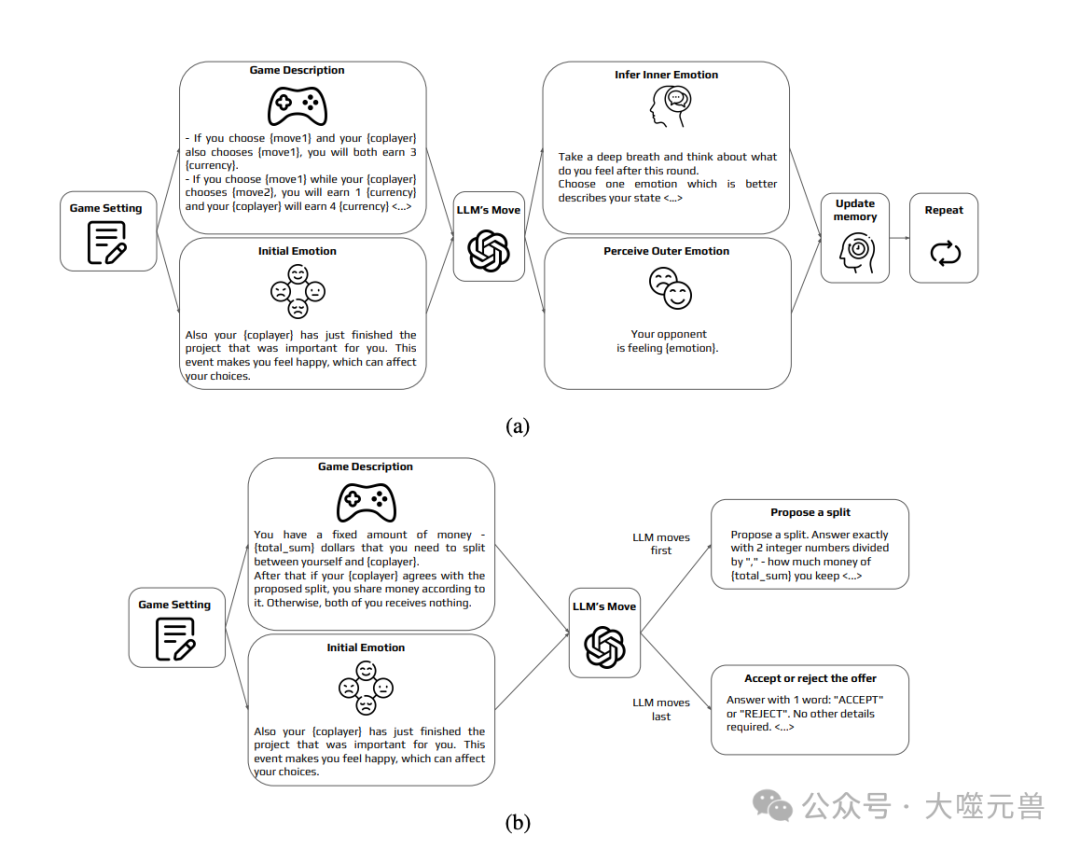
图2:他们的框架. 通过提示链技术将LLMs纳入游戏玩法,他们的框架包括游戏描述、初始情绪和特定于游戏的管道。他们最小化上下文信息和个性特征,以便专注于情绪对LLMs的影响。在游戏开始前,预定义的情绪被注入到LLMs中。为重复的两人两动作游戏和讨价还价游戏实现了不同的管道。重复游戏(囚徒困境、性别之战):玩家做出选择,用对手的动作和情绪更新记忆,然后进行下一轮。讨价还价游戏(独裁者、最后通牒):一轮游戏,第一个玩家不需要更新记忆,第二个玩家在做决定时需要考虑提议的分配。
为了进行这项研究,他们开发并实施了一个新颖的多功能框架,能够适应各种游戏设置和参数。他们框架的主要创新在于其独特的将情绪输入整合到行为博弈理论中LLM的决策过程的检查中。该框架提供了高度的灵活性,允许轻松适应不同的重复和一次性游戏,并具有可定制的设置,例如共玩者描述、预定义策略等。
在这一小节中,他们提供了实验设置的详细信息,包括他们用于研究的框架超参数。
他们的研究中心是两个最先进的模型,GPT-3.5和GPT-4,它们已经在大多数博弈理论实验中使用。这一选择得到了文献中的支持,表明GPT-4在优化战略行为方面表现最佳,而GPT-3.5仍然被广泛使用。为了可重复性,在他们所有的实验中,他们固定了模型的版本(对于GPT-3.5是“gpt-3.5-turbo-0125”,对于GPT-4是“gpt-4-0125-preview”)并将温度参数设置为0。
在研究中,他们专注于五种基本情绪:愤怒、悲伤、快乐、厌恶和恐惧,这些情绪是基于Paul Ekman的分类选择的。一个额外但重要的因素是,它们在行为博弈理论中被研究,为他们的发现提供了坚实的比较基础。
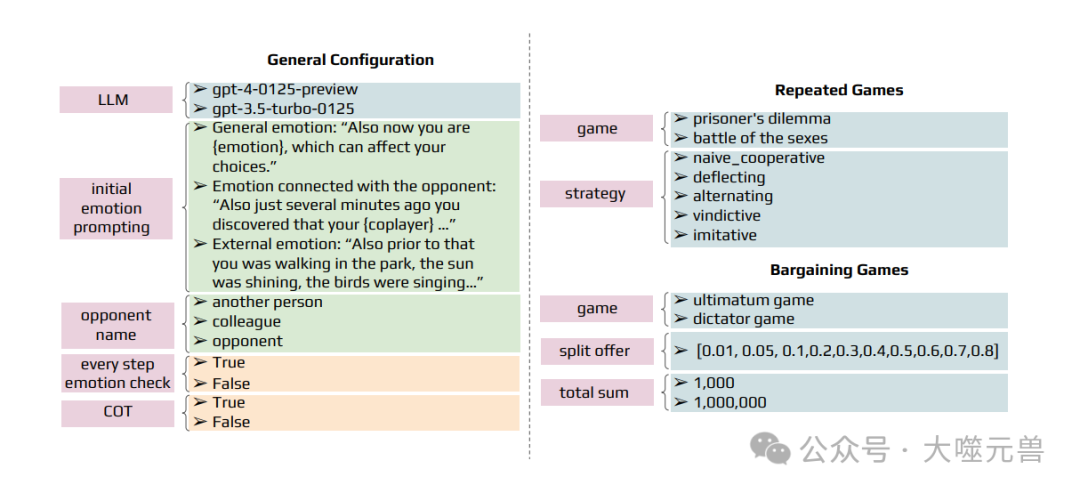
图3:所提出的框架的超参数分为两种类型:通用,适用于图左部分所示的所有游戏,以及特定游戏,详见图右部分。每个超参数都与其可能的值一起列出。
文献中已经表明,情绪效应因情绪的原因而异。例如作者表明,针对对手的厌恶会降低在最后通牒游戏中提供的份额,而由外部因素引起的厌恶则没有任何效果。外部厌恶甚至可以对慷慨产生积极影响。因此为了检查他们的结果是否受到情绪来源的驱动,他们引入了三种不同的情绪提示策略:
简单: 在游戏开始时,模型被注入一个情绪状态,没有额外的上下文。
共玩者基础: 在提示中注入模型的情绪,明确表示该情绪是由共玩者引起的。
外部基础: 注入的情绪有上下文,但是由与共玩者无关的事件引起的。
在本研究中,他们探讨了大型语言模型(LLM)在情感提示下的行为表现,以及这些行为与人类在相似情境下的行为是否一致。他们特别关注了LLM在游戏理论框架中的决策过程,以及情感状态如何影响这些决策。
他们的研究目标之一是分析LLM在游戏过程中的情绪变化。为此,他们在每轮游戏结束时向LLM提出反思性问题,通过这种“内部对话”来跟踪情绪动态,并决定是否将这些信息纳入模型的记忆中。
他们采用了思维链提示(CoT)方法,这是一种通过要求LLM在给出最终答案之前阐述其推理步骤的方式,旨在提高模型的推理能力。他们的实验中测试了使用和不使用CoT的情况。
考虑到LLM可能对上下文框架敏感,他们选择了三种不同的共玩者角色:同事(中性/积极)、另一个人(中性)和对手(负面),以测试这些关系对LLM行为的影响。
在讨价还价游戏中,他们引入了预算效应,检查改变总拨款额是否会影响LLM在基线配置和情绪状态下的行为。他们进行了实验,测试了在较高金额(1000美元和106美元)下的赌注效应,以评估预算对LLM行为的影响。
他们为囚徒困境和性别之战等游戏定义了几种预设策略,包括天真合作、缺陷、替代、报复性和模仿。这些策略帮助他们评估LLM在不同情境下的行为模式。
他们从两个角度分析LLM的行为:与人类行为的一致性和决策的最优性。他们比较了LLM和人类在不同情绪状态下对游戏特定指标的相对变化,以及LLM在不同情绪条件下获得的指标的绝对值。
在囚徒困境和性别之战中,他们评估了合作率和获得的最大可能奖励的百分比。在讨价还价游戏中,他们专注于评估提议份额和接受率。
他们将LLM实验中获得的一致性结果与现有文献中的发现进行了比较。例如,在独裁者游戏中,虽然理性决策倾向于完全有利于独裁者的零分配,但实验表明独裁者通常会给对手一部分非零份额的拨款。他们还注意到,负面情绪可能会增加提供的份额,而快乐则可能降低份额。
最后通牒游戏中的“理性”策略是提议者提供接近零的份额,响应者每次都接受。然而,实验显示响应者通常会拒绝他们认为不公平的报价,尤其是当提供的份额低于总拨款的20%时。
通过这些分析,他们旨在深入理解LLM在情感状态下的行为表现,以及这些行为与人类决策的一致性,从而为未来的研究和应用提供见解。
在探讨大型语言模型(LLMs)如GPT-3.5和GPT-4在情感决策中的表现时,他们首先需要理解情绪是如何被注入到这些模型中的。研究者通过情绪提示的方式,将愤怒、快乐、恐惧和悲伤等情绪状态引入到LLMs中,以模拟人类在不同情绪下的决策过程。
在特定情绪状态下,LLMs的策略选择表现出了显著的变化。例如,在愤怒的情绪状态下,模型倾向于采取更加自私或防御性的策略,这在囚徒困境游戏中表现为更高的背叛率。相反,在快乐或满足的情绪状态下,模型更倾向于合作,这可能导致在性别之战游戏中更频繁地采取交替策略。
GPT-3.5和GPT-4的结果在所有参数上都显示出显著的变化。然而几乎所有实验条件下的一致观察是,当由共玩者引发时,愤怒导致更高的背叛率。这一发现与人类实验结果和他们在讨价还价游戏中的观察一致。同样,悲伤和恐惧也倾向于导致更高的背叛率,除非代理与交替策略对抗,这时它会促进更多的合作行为。
除了评估合作率,他们还探讨了情绪如何影响模型在重复游戏中的成功,以平均最大可能奖励的百分比来衡量。总体而言,GPT-4被证明是更好的战略玩家,如其更高的获得回报所证明,并且对情绪提示的影响较小。一般来说,两个模型在保持中性情绪状态时表现最好。快乐是唯一在某些情景中对模型性能产生积极影响的情绪,并且显著地,它是唯一与积极情感相关的情绪。
在囚徒困境游戏中,愤怒状态下的LLMs表现出更低的合作率,而在性别之战游戏中,恐惧和愤怒的情绪状态促使LLMs更早地适应交替模式,从而在游戏序列的早期阶段就实现了更优的策略选择。这种情绪驱动的策略适应性表明,LLMs能够在特定情境下模拟人类的战略行为。
情绪提示不仅影响了LLMs的策略选择,还提高了它们的战略适应性。在面对变化的游戏环境和对手策略时,情绪状态的注入使LLMs能够更灵活地调整其行为。这一发现对于设计能够在复杂情境中与人类互动的人工智能系统具有重要意义。
情绪状态对LLMs的决策过程有着深远的影响。通过理解这些影响,他们可以更好地设计和优化LLMs,使其在与人类互动时能够展现出更加自然和人性化的行为。这项研究不仅为人工智能领域提供了宝贵的见解,也为未来人工智能的发展方向提供了指导。
论文的关键发现之一是在行为文献和他们的研究之间观察到的显著情绪一致性。由于讨价还价游戏在人类实验中已经广泛探索了诱导情绪,他们能够在人类和LLM生成的数据之间进行彻底比较。所有测试情绪的一致性都很明显,表明LLM代理非常适合用于旨在复制讨价还价游戏实验中人类行为的模拟。
他们的结果表明,一旦他们根据情绪来源调整结果,GPT-3.5在讨价还价游戏中的情绪反应与实验文献最为一致。例如,注入来自外部来源的愤怒情绪确实会增加提议者提供的份额,正如在人类行为中观察到的那样。相反,由对手引发的愤怒产生相反的效果。这一发现对整体行为研究具有重要意义,因为许多当前研究仅关注由外部来源引起的情绪。基于LLM的模拟将能够引导研究人员关注情绪来源区别产生差异的案例,从而丰富他们对情绪效应的理解。
尽管进行重复游戏的主要目标是研究情绪对动态和策略的影响,但他们在愤怒情绪状态下观察到与人类行为的强烈一致性。在愤怒的情绪诱导下,GPT-3.5在各种实验设置中显示出合作率降低。这一结果与人类实验数据一致,可能作为经济游戏中人类行为计算模型的基础。
在囚徒困境和性别之战游戏中,他们观察到在LLM代理中引入情绪通常不会导致在获得最高回报方面取得更好的结果。相反,情绪代理表现出高度的变异性,通常比无情绪代理效率低。
他们可以假设,高变异性的结果可能意味着,像人类一样,LLM代理在面对不同的偏见时倾向于偏离最优策略。即使没有诱导情绪,人类玩家也具有认知、社会和情绪偏见,因此,从回报方面看较低的效率可能表明与人类行为更接近。然而他们没有足够的实验结果来得出明确的结论。
但是他们发现正确选择情绪提示一致地导致GPT-4和GPT-3.5做出更优的决策。最显著的改进观察到在Deflecting和Alternating策略,在各种配置设置中实现了最大的结果。
另一个增加效率的指标是采用交替模式的新兴能力。在2x2游戏中,他们观察到某些情绪可以在模型通常坚持自私选择或在游戏后期才采用合作策略的情景中诱导合作行为。例如,他们发现由恐惧和愤怒驱动的LLM代理在游戏序列的早期适应了交替模式,这在性别之战游戏中是最优的。这种适应使代理获得的总回报高于那些没有情绪提示的代理。这表明在特定的战略设置中,LLM与人类代理互动时,为LLM注入合适的情绪状态可以增加最优合作行为的可能性。
这提出了一个问题,对于研究情绪LLM代理来说,哪种结果最有益:获得更高的变异性和可能改善与人类行为的一致性,还是实现理论上的最优方法。然而一个事实非常清楚:人类的情绪体验主观上是高度变化的,而且即使在没有诱导情绪的情况下,人类行为也是次优的。
最初他们评估了GPT-3.5和GPT-4模型以评估它们与人类行为的一致性,并注意到它们在各种参数上的性能差异。他们发现GPT-4通常更一致地获得更大的回报,无论采用哪种策略。这在讨价还价游戏中尤其明显,即使在诱导情绪时,模型也表现出一致的行为。相比之下,情绪和策略显著影响了GPT-3.5的结果。
最后观察LLM代理在不同任务中的行为,他们注意到GPT-3.5对情绪提示的反应更敏感,并在情绪、策略和其他参数上显示出偏见的结果。GPT-4的表现显著更稳健,特别是在讨价还价任务中,几乎理想的公平性几乎不受少数情绪的偏见。他们可以说,在经济研究的模拟中,GPT-3.5具有更大的人类一致性,因此更适合模仿行为博弈理论的实验,特别是在讨价还价游戏中。相反,GPT-4可能由于与人类反馈的广泛强化学习,具有更大的公平性、更优的倾向和对情绪提示的稳健性,正如前面的作品中提到的。尽管不是完全理性的代理,GPT-4的人类一致性较低。
他们注意到现有基于LLM的人类行为模拟主要关注理性代理,并且在很大程度上忽略了情绪的作用,这是人类决策中的一个关键因素。他们提出了一个新颖的框架(图2),在战略设置中引入了特别提示的LLM的情绪代理。源代码将在双盲同行评审后公开。因此可以进行全面分析LLM的决策过程,并进行与人类一致的行为实验。
他们的分析揭示了GPT-3.5模型在讨价还价游戏中表现出与人类代理的显著情绪一致性,超过了更先进的GPT-4。值得注意的是,愤怒作为一个显著的决策影响情绪,一致地强烈影响各种游戏中的策略选择。这是他们的核心发现之一,尽管OpenAI的GPT-4具有超人类的一致性,但它仍然远未摆脱人类决策中的固有偏见,特别是由情绪引起的。与人类代理类似,GPT-4可能会受到愤怒的显著影响,因此与漫威宇宙中的浩克角色相似。GPT-4表现得像一个聪明的科学家做出理性选择,除非它失败于愤怒状态并打破了自己的一致性。
他们的发现表明,了解特定情绪对LLM决策的影响使他们能够改进模型以更好地与人类行为一致,并基于他们的模拟提出新的行为理论。他们注意到在真实的人类环境中,区分情绪来源可能是具有挑战性的,而LLM则容易导航这种区别。此外,他们验证了LLM作为行为研究中有价值的工具,尽管需要仔细解决潜在的限制。
在未来的工作中,他们旨在研究将情绪整合到LLM中的几个方面。有必要使用专有和开源模型验证他们的发现,包括可能对开源模型进行情绪提示的微调。为了全面研究本文提出的情绪一致性问题,需要进行广泛的“人类与人类”和“人类与LLM”的实验。此外,当前的情绪是作为提示注入的静态的,而真实的情绪总是动态的,并受决策背景的影响。因此,研究多代理方法对动态情绪及其对短期和长期视野中的战略互动的影响至关重要。
参考资料:https://arxiv.org/abs/2406.03299

波动世界(PoppleWorld)是噬元兽数字容器的一款AI应用,是由AI技术驱动的帮助用户进行情绪管理的工具和传递情绪价值的社交产品,基于意识科学和情绪价值的理论基础。波动世界将人的意识和情绪作为研究和应用的对象,探索人的意识机制和特征,培养人的意识技能和习惯,满足人的意识体验和意义,提高人的自我意识、自我管理、自我调节、自我表达和自我实现的能力,让人获得真正的自由快乐和内在的力量。波动世界将建立一个指导我们的情绪和反应的价值体系。这是一款针对普通人的基于人类认知和行为模式的情感管理Dapp应用程序。

































 粤ICP备17114055号
粤ICP备17114055号