Phidata是一个开源框架,这段时间在Github上炙手可热的一个项目,https://github.com/phidatahq/phidata(9.6K Stars),旨在帮助开发者构建具有长期记忆、丰富知识和强大工具的AI助手。这些AI助手能够通过函数调用来执行各种任务,如搜索网络信息、分析数据、进行研究并生成报告等。Phidata的核心优势在于其对大型语言模型(LLM)的支持,使其能够通过添加记忆、知识和工具来克服传统LLM的局限性。具体来说,Phidata通过以下几个方面实现这一目标:- 记忆:将聊天历史记录、摘要和事实存储在数据库中,使LLM能够进行长期对话。
- 知识:将业务上下文存储在矢量数据库中,使LLM能够在特定情境下做出响应。
- 工具:使LLM能够执行如调用API、发送电子邮件或查询数据库等操作。
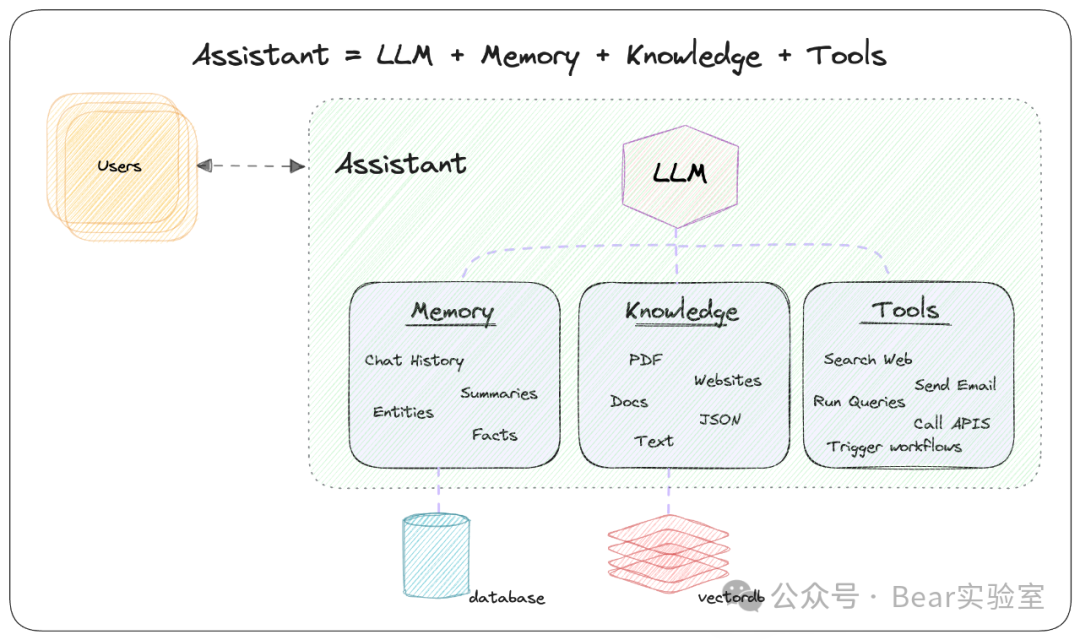
Phidata不仅适用于构建客服聊天机器人、数据分析工具,还能帮助用户搜集和理解大量信息,从而提升AI助手的智能水平和自主能力。它基于Python语言,支持自然语言处理、语音识别和图像识别等功能,并提供了一些预训练的模型,可用于快速构建AI助手。都可以用于构建AI Agent,都是开源的,但差异还比较大的。Phidata主要突出的是封装,Assistant作为核心的组件,是所有的流程的开始。LangChain是更底层的基础架构,功能齐全。- 上手难度低,封装更符合现实世界的思维,定义Assistant,并告诉它要怎么做,比较符合人的逻辑。
- 记忆Memory和知识Knowledge都不用开发者自己去实现,现成都是封装好的,Assistant如何调用Memory由Phidata管理,用就行了。
- 功能齐全,提供了6大类组件,帮助开发者在开源模型基础上快速增强模型的能力。
- 生态强大,除了自身的LangSmith、LangGraph、LangServe这些主要兄弟外,还有大量的第三方集成。
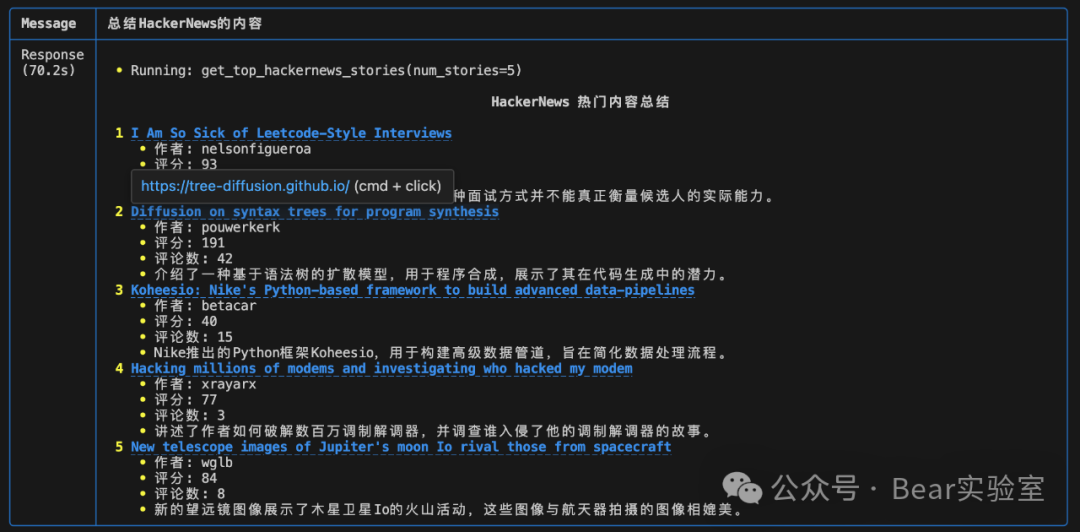
LangChain的上手难度比Phidata要大一些,但类似动态配置、LECL语言能帮我们实现更加复杂,更灵活的业务,两者的对比有点像单反相机和傻瓜卡片机。如果用LangChain实现一个Phidata的Assistant,需要不少的编码工作。一个助手展示了如何将函数调用与 LLM 结合使用。该助手可以访问一个函数get_top_hackernews_stories,它可以调用该函数来获取 Hacker News 的头条新闻。Hacker News(HN)是一个由著名孵化器Y Combinator的创始人Paul Graham在2007年上线的社区,主要面向创业者和开发者。以其简洁的界面和高效的信息获取方式而闻名。用户可以通过键盘上的箭头或者vi编辑器的导航键(hjkl)来上下滚动新闻列表、打开评论区和阅读文章。pip install phidata -U
定义LLM,这里使用Phidata提供的AzureOpenAIChat,注意在环境变量中设置这两个参数AZURE_OPENAI_ENDPOINT和AZURE_OPENAI_API_KEYfrom phi.llm.azure import AzureOpenAIChat
chat_model = AzureOpenAIChat(model="gpt-4o",api_version="2024-05-01-preview",temperature=0.3)
定义get_top_hackernews_stories函数,Assistant的tools参数支持把function列表或者ToolKit,Phidata推荐function的方式,ToolKit就是一组function的集合。
import jsonimport httpx
def get_top_hackernews_stories(num_stories: int = 5) -> str:"""Use this function to get top stories from Hacker News.Args:num_stories (int): Number of stories to return. Defaults to 5.Returns:str: JSON string of top stories."""response = httpx.get("https://hacker-news.firebaseio.com/v0/topstories.json")story_ids = response.json()stories = []for story_id in story_ids[:num_stories]:story_response = httpx.get(f"https://hacker-news.firebaseio.com/v0/item/{story_id}.json")story = story_response.json()if "text" in story:story.pop("text", None)stories.append(story)return json.dumps(stories)
from phi.assistant import Assistant
assistant = Assistant(llm=chat_model,description="你是一位资深的新闻编辑,擅长总结HackerNews的内容。",instructions=["每篇总结至少30个字。"],tools=[get_top_hackernews_stories],debug_mode=True,show_tool_calls=True)
assistant.print_response("总结HackerNews的内容", markdown=True)

































 粤ICP备17114055号
粤ICP备17114055号