导读 本文将分享大模型在蚂蚁集团推荐场景中的应用(以下全部为蚂蚁集团的研究工作及落地)。
1. 背景介绍
2. 利用大模型进行知识提取
3. 大模型作为教师模型
4. Q&A
背景介绍
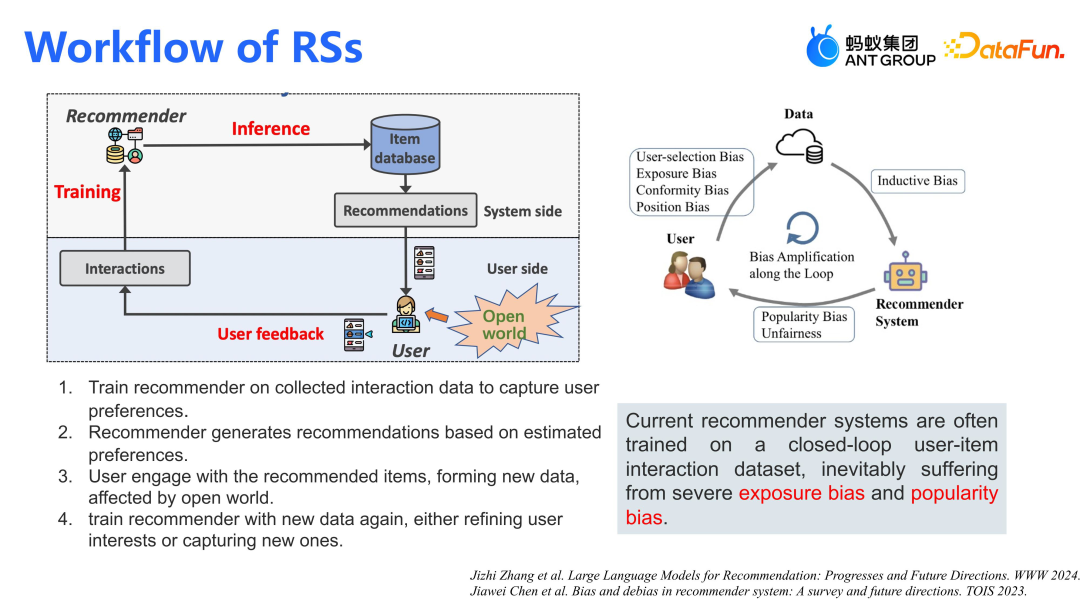
推荐系统的流程主要包括以下几个步骤:①系统基于用户反馈训练模型,以捕捉用户的偏好;②系统生成推荐结果并返回给用户;③用户与推荐商品进行交互,生成反馈;④系统收集这些反馈再去优化模型。这样形成一个完整的闭环。在这一过程中存在着一些问题,如曝光偏差(Exposure Bias)和流行度偏差(Popularity Bias),这会导致推荐结果产生偏差。为了解决这些问题,我们希望引入大模型来融合世界知识(World Knowledge),以减少偏差,使系统更加鲁棒。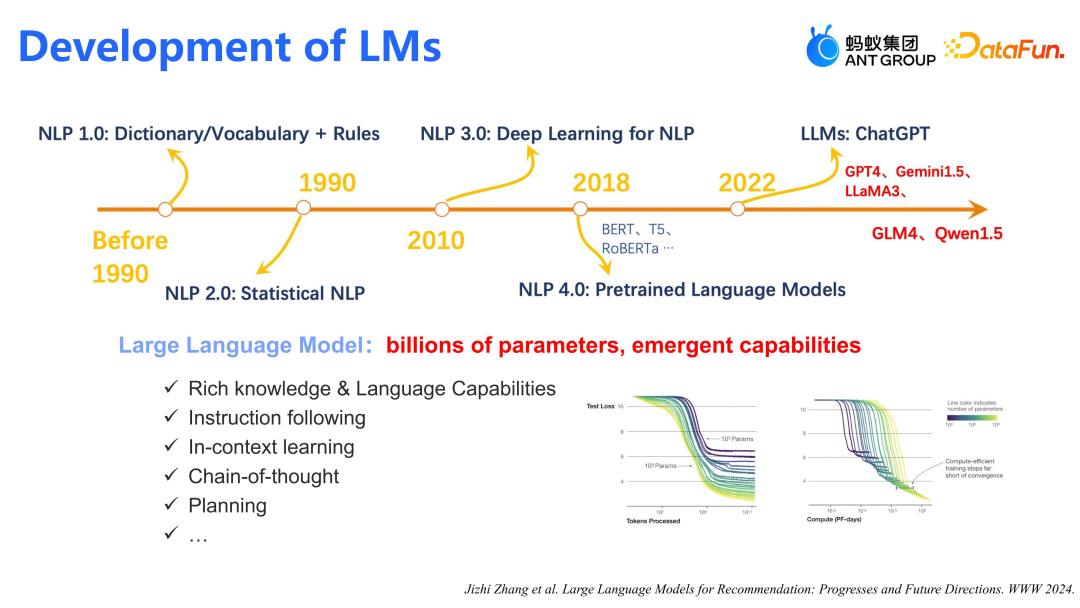
下面简单回顾一下语言模型的发展历程。统计 NLP 始于 1990 年,到 2010 年前后,Deep Learning for NLP 兴起。经过 2013 年的 Word2vec,以及 2018 年开始火爆的 BERT 等模型,到 2022 年,GPT4 等大语言模型带来了突破性的革命。大模型的优势在于通过百亿/千亿级参数获得涌现能力(emergent capabilities),显著增强了推理能力,从而使推荐模型能够生成更优质的推理结果。然而,这类模型在线上环境难以直接应用。因此,我们致力于平衡效率与成本,使大模型高效且低成本地融入线上推荐系统。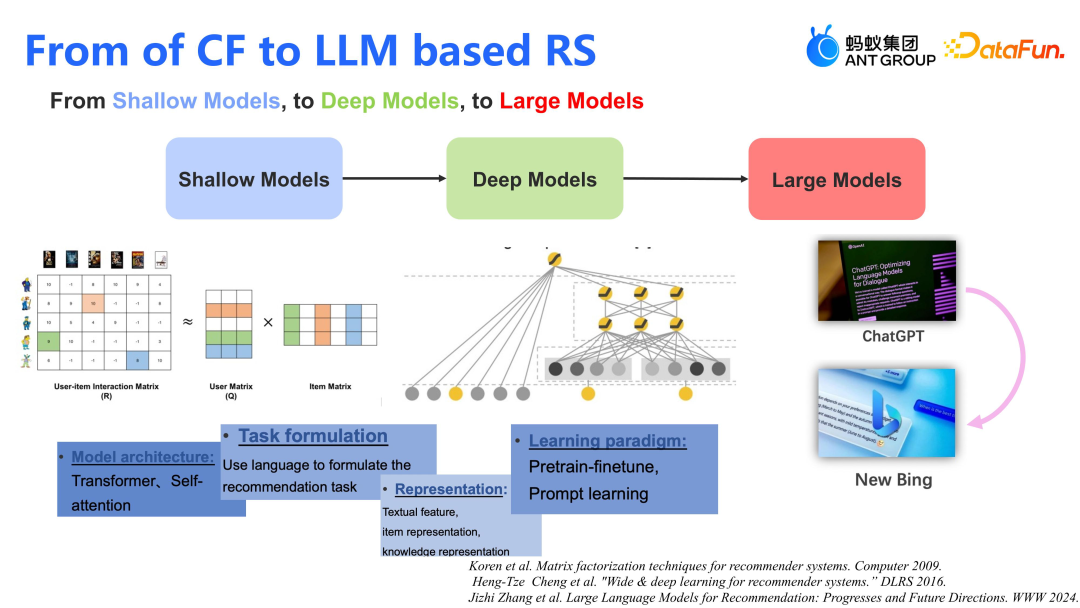
推荐模型的发展历程从传统的协同过滤到现今的大模型推荐,经历了多个阶段。最初,矩阵分解作为浅层模型(Shallow Models)被广泛应用。随后,在 2016 年左右,Wide&Deep 等深度模型(Deep Models)开始崭露头角。当前,业界主流的推荐系统大多基于 DNN(深度神经网络),如 Wide&Deep 或 MOP(多目标优化)及其变种,用于线上服务。而随着大型模型(Large Model)的兴起,推荐系统正在朝着融合大模型能力的方向发展。这不仅仅是纯生成式的推荐,更多的是将大模型(如 ChatGPT)的技术能力融入到推荐模型中。
将大模型融入推荐系统面临三大挑战。第一,大模型虽依赖语义信息,但推荐系统的协同信息更为关键,单纯依赖语义模型,效果一般不及预期。第二,需平衡计算开销与推荐效果。第三,我们希望将大模型对用户行为的深度理解和推理能力蒸馏到如 LLAMA 等推荐模型中。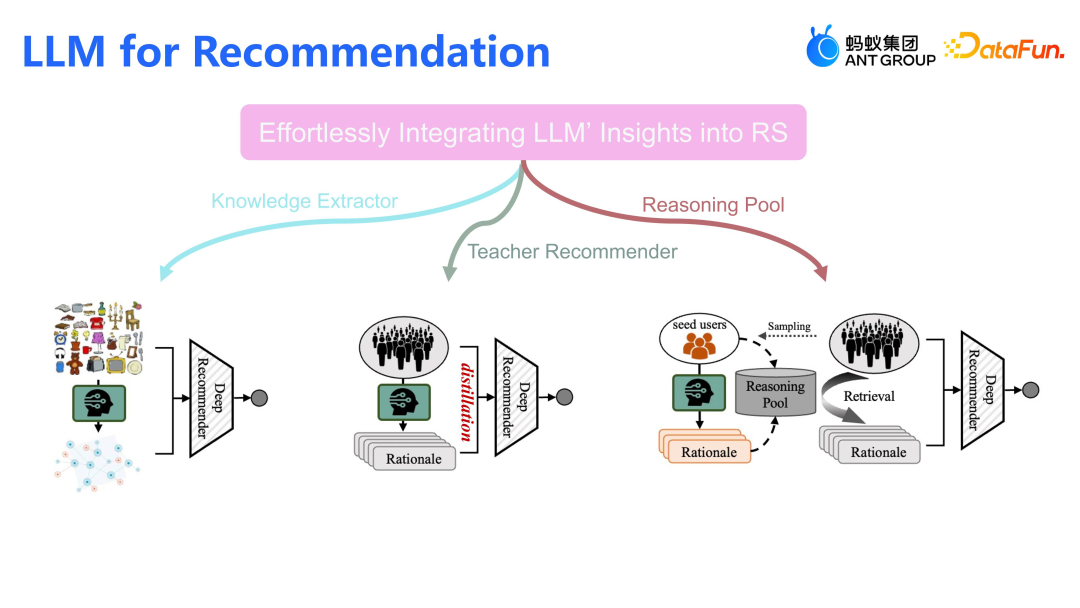
为了应对上述三大挑战,我们在过去一年中尝试了以下路径,将大模型无压力地应用到线上推荐系统中:- 采用两阶段方式融入大模型,第一阶段,大模型负责生产知识,这些知识以结构化形式或以文本形式存储;第二阶段,推荐模型消费这些由大模型生产出的知识图谱,实现推荐。
- 让大模型与现有线上模型更紧密地融合。通过蒸馏技术,将大模型如 ChatGPT 的推理能力逐步转移到更轻量级的模型,如 LLAMA 及序列模型,最终部署这些轻量级的模型到线上,实现效果和计算开销的平衡。
- 核心还是让大模型来提供推理知识,但并不需要为每个用户生成推理知识,而是只需要一个核心的种子用户群,为其生成推理知识,其他用户只需要检索种子用户池,生成所有用户的 embedding,线上模型只要 serving 这种 embedding 即可。
利用大模型进行知识提取
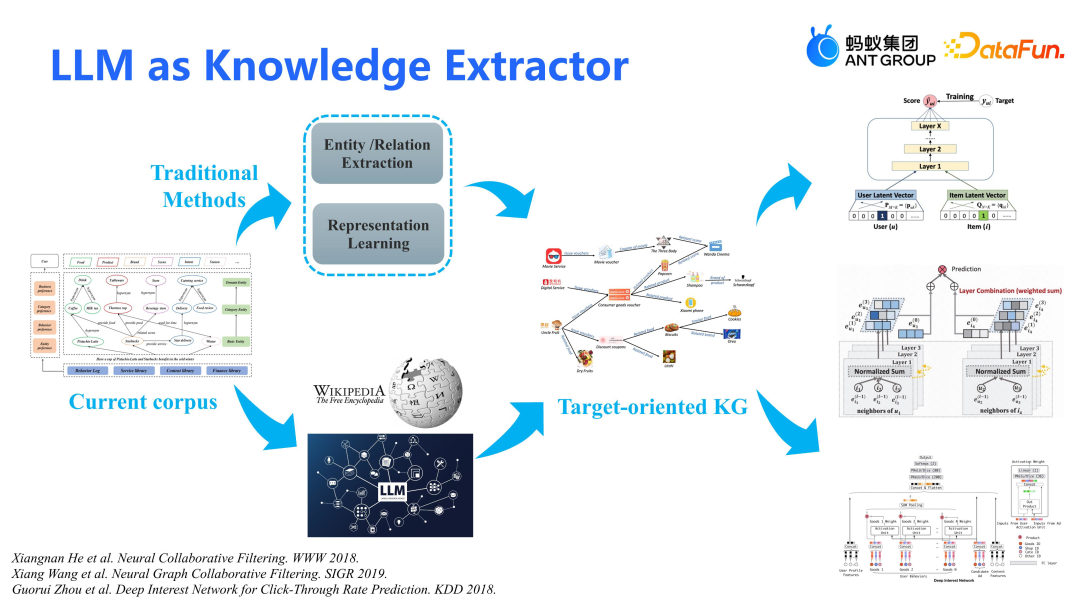
大模型作为知识提取器,核心在于从线上 corpus(包括文本和已有知识图谱)中生产适配的 KG。原先方法依赖大量标注数据进行实体和关系抽取,但只能预测现有实体对的关系,无法产生新知识。大模型的优势在于利用开放知识,生产图谱和语料中不存在的新知识,使 KG 更加丰富。我们将介绍如何通过大模型从现有语料中提取并生产适配的 KG,以便更好地应用于下游任务如协同过滤、图模型和特征交叉模型。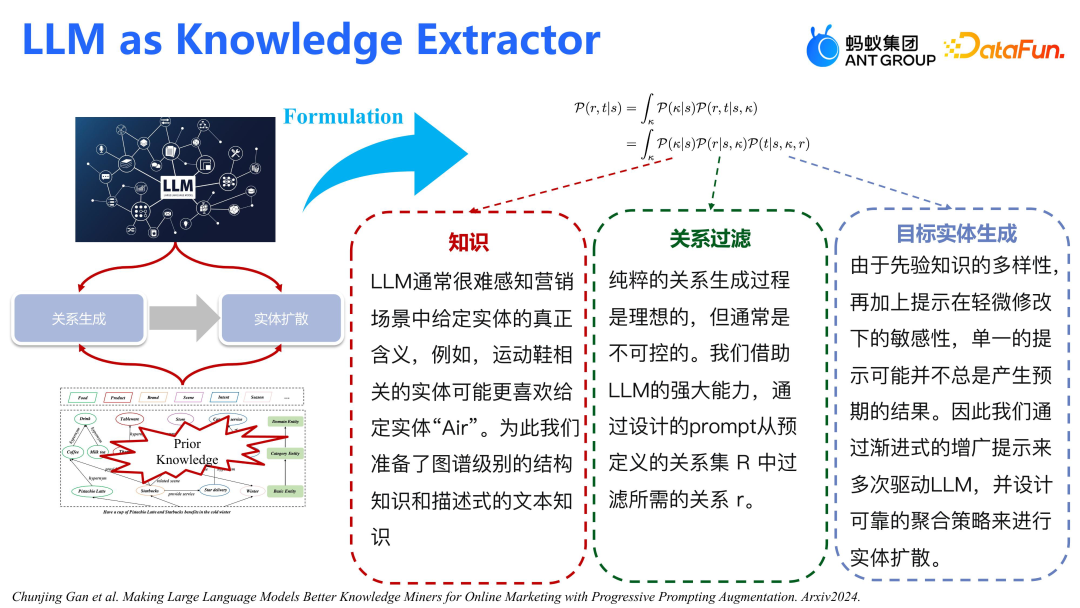
大模型生产知识的核心流程包括两步:第一步确定所需生产的关系类型,第二步基于这些关系生成实体。例如,要生成与阿里巴巴相关的品牌和企业关系,大模型会先识别出这些关系,然后生成对应的实体,如腾讯、字节等,形成三元组关系。整个流程基于条件概率,给定源节点 S,大模型会推理出关系 R 和目标实体 T。整个框架包含三个关键步骤:知识获取、关系过滤和目标实体生成。①大模型从 S 中提取相关知识;②基于这些知识和 S 生成关系 R;③结合 S 的知识和 R 生成目标实体 T。难点在于确保大模型真正理解所需知识,并避免生成不相关或无关系的信息。例如,对于“Air”这个实体,我们可能需要大模型生成与球类品牌相关的知识,而非偏向空调。此外,由于一个实体可能涉及众多关系,关系过滤成为一大挑战,需要设计合理的 prompt 来指导大模型在关系池中选取正确的关系。大模型对 prompt 非常敏感,因此设计高质量的 prompt 对于生成目标实体至关重要。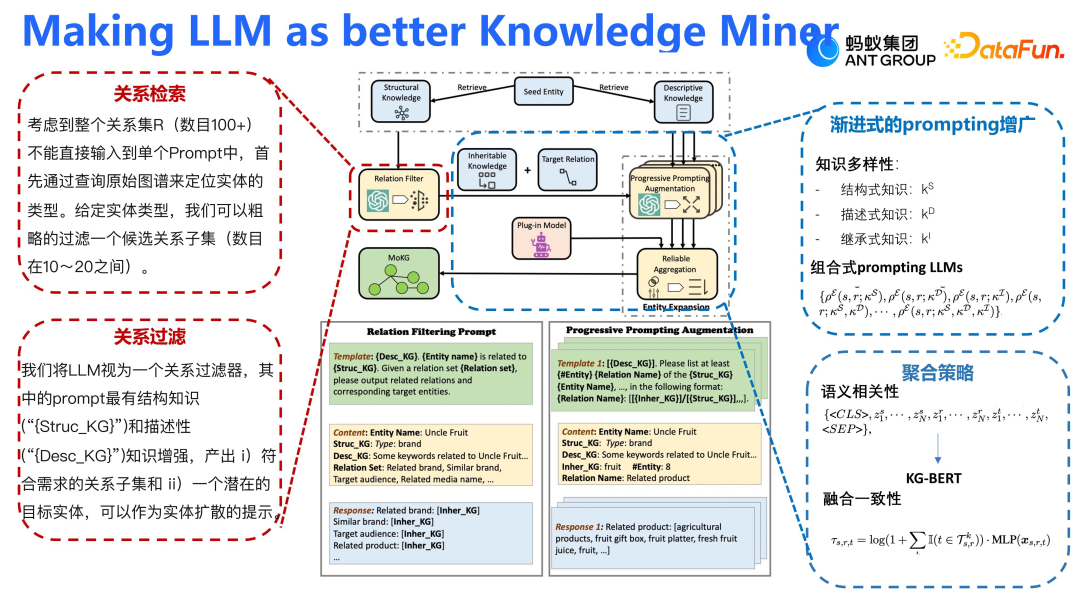
我们的大模型框架旨在生产特定知识,核心在于关系检索和关系过滤。①使用小模型从大量关系中生成与给定实体相关的候选关系集。②利用大模型对这些候选关系进行关系过滤,通过给定实体、关系描述和文本描述,让大模型输出与实体更匹配的关系。在此过程中,prompt 设计至关重要。为了有效引导大模型,将知识分为结构式、描述式和继承式三类,并通过组合这些知识的 prompt 来循序渐进地驱动大模型,以避免不必要的推理延误和生成不相关知识。- 通过 KG-BERT 进行排序,确保生成的目标节点与源节点保持语义一致性,并选择 Top 20% 或 30% 的语义一致性的节点作为关注重点;
- 强调模型推理的一致性,如果多个模型推理结果均包含某个实体,则认为该实体更可靠。
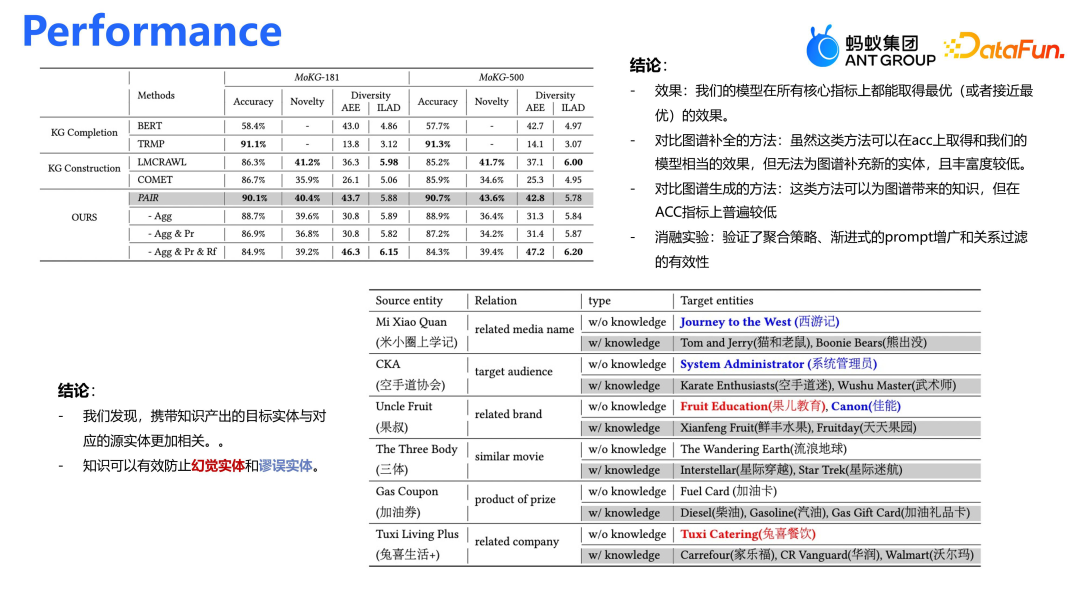
在与现有 SOTA 方法对比时,主要关注图谱补全技术。通过 BERT 语义宣传和图谱挖掘,为源节点扩散出所需的关系和实体。对应的评价指标包括:①准确度(Accuracy),确保生成的实体准确无误;②创新性(Novelty),尽可能生成图谱中不存在的实体以扩展图谱;③多样性(Diversity),确保生成的图谱不集中于某一领域,如不仅限于汽车品牌,而是涉及更广泛的类别如拖拉机等。生成的实体与支付宝小程序密切相关,如“米小圈上学记”和“果叔”。为了更好地满足这些实体的知识需求,我们调整了知识生产框架,提供必要的知识以避免误解。例如,对于“果叔”,提供背景知识,帮助大模型理解其为水果品牌,并正确关联至“鲜丰水果”或“天天果园”,而非无关的“果儿教育”或“佳能”等实体。通过这些调整,在准确性、创新性和多样性上均取得了显著提升。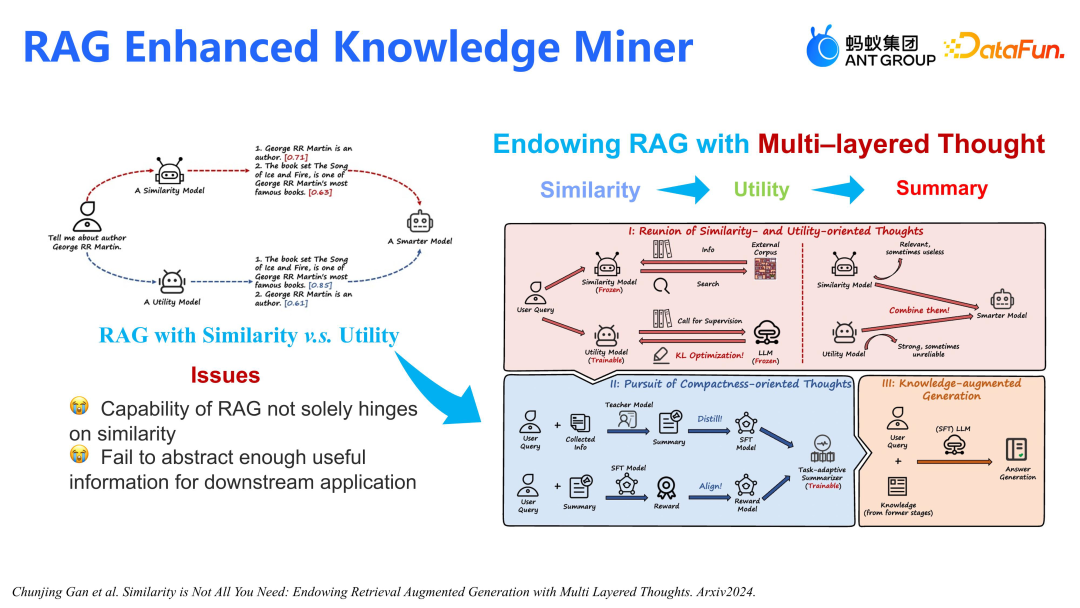
我们深知知识的重要性,但先前模型的知识处理方式过于简略。RAG 在知识挖掘中扮演着重要角色,它通过相似性模型(如 BM25)召回相关文档,再把这些文档交给 LLM,并由 LLM 生成具体的知识和关系。然而,仅依赖相似性进行检索并不能确保文档的有效性。以乔治马丁为例,我们提出一个基于实用性的模型(Utility)来优化 RAG。与仅将“乔治马丁是作者”排在首位的传统方法不同,我们的模型能更准确地识别“乔治马丁是《冰与火之歌》的作者”这一重要信息。- 生成摘要(Summary)以压缩文档长度(因为召回了成千上万的文档,可能每个文档都比较长,并不是所有的大模型都能支持长序列,所以需要一个 Summary 来压缩多文档之间的长序列,把它压缩成一个能容忍的文档长度);
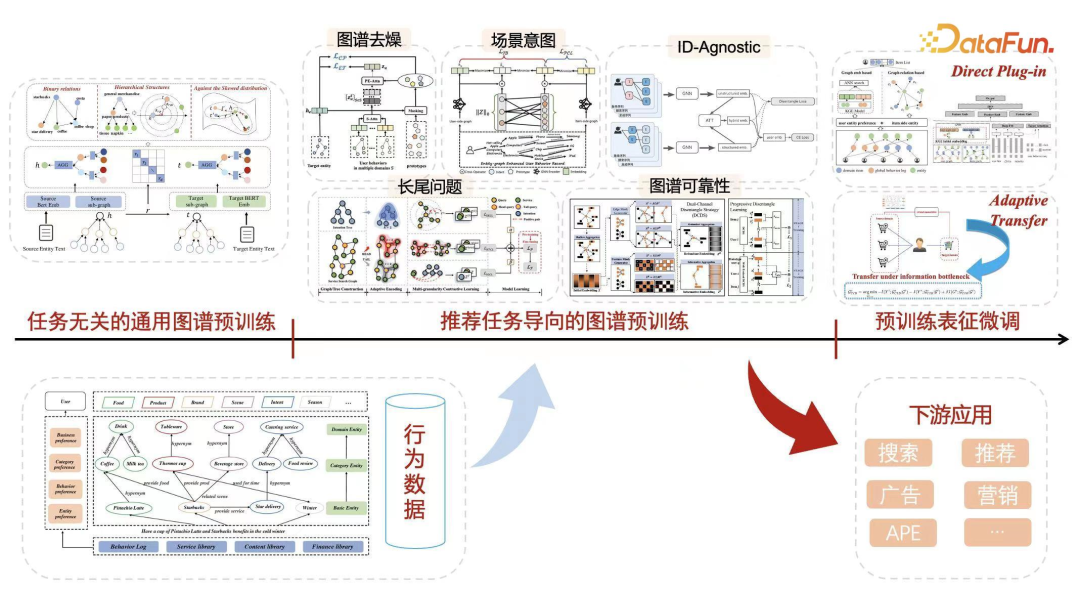
我们之前的应用专注于知识生产,核心成果是图谱的结构化存储。这些图谱不仅可直接作为特征融入 GNN 或 Graph 模型中,还可助力下游任务。一个简单应用是,通过图谱融合蚂蚁集团支付网上的所有场景和 item,训练通用图谱预训练模型,并复用至下游业务。然而,生成的图谱存在长尾和噪音问题,我们致力于提升图谱的可靠性和去噪工作,以增强图谱实体的表征。对于下游应用,关注如何有效利用预训练表征。由于预训练是多域表征学习,但特定域可能只需部分多域行为。因此,需进行预训练表征微调,实现自适应迁移。例如,在 A 到 D 四个域预训练后,若最终应用于 E 域,可能仅需 A 和 B 两域的结果进行表征微调就足够了。大模型作为教师模型
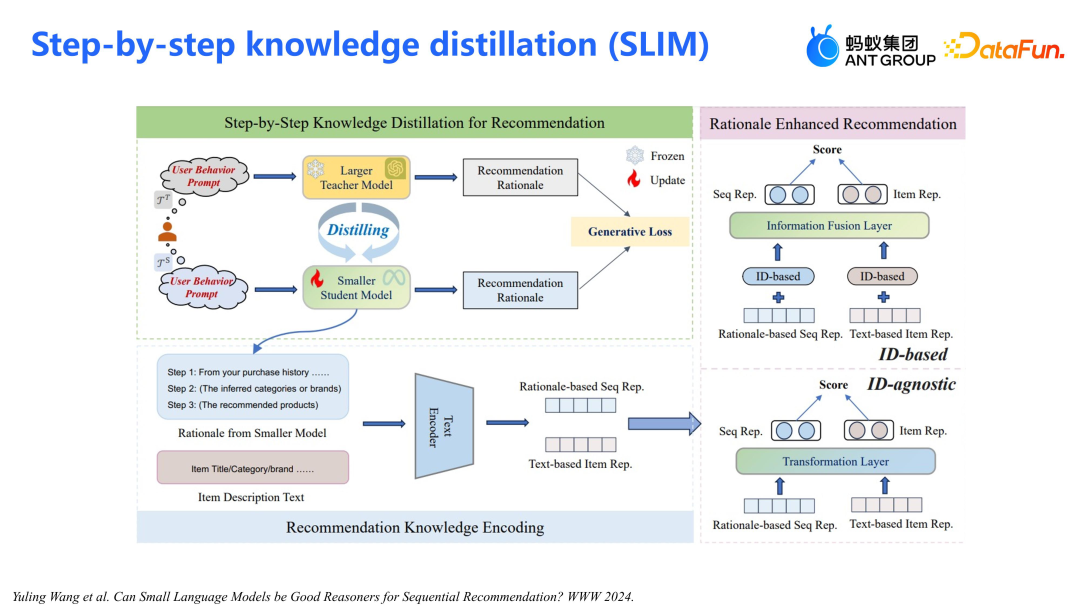
我们还尝试了将大模型作为教师模型用于推荐系统。第一阶段,蒸馏了大型 GPT 模型(如 ChatGPT、GPT-4)到较小的模型(如 LLAMA2 或 LLAMA3),来增强推理能力。通过预设的 prompt,大模型生成推荐理由,这些理由基于预定义的模板。接着,使用简化的推理模板请求小模型进行推荐和理由生成。第二阶段,利用生成式 Loss 来微调小模型,使其具备推理能力。一旦模型训练完成,将通过 prompt 为用户行为提供 T+1 推理。推理结果通过文本编码器(Text Encoder)转化为表征,这些表征将直接应用于线上模型。
通过 CoT prompt(思维链提示)来生成推荐理由(Rationale),这些理由基于用户行为偏好。- 基于这些偏好进行从粗到细的推荐,具体做法是先通过用户行为推荐品牌及类目,然后基于这些推荐进行商品精细化推荐;
- 使用 Teacher Model Response 作为语料微调 LLAMA 模型,使其能模仿教师模型生成推荐理由。
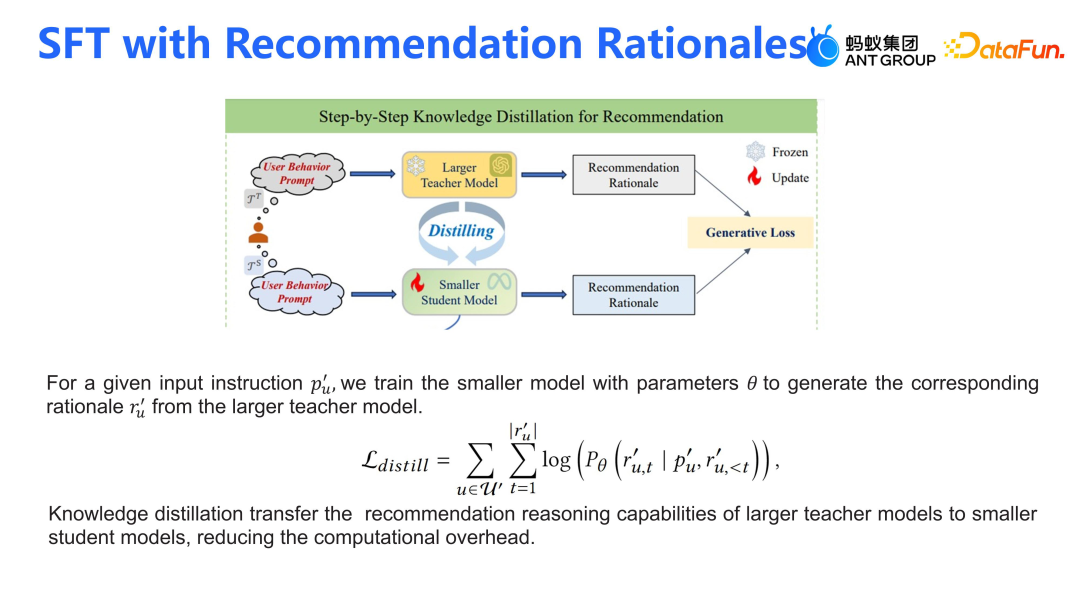
我们需训练一个小模型来生成推荐理由,这些理由基于 GPT3.5 大模型给出的预测。简单来说,这就是一个生成式 Loss(Generative Loss)的过程,其中小模型会学习如何预测并生成与大模型一致的推荐理由。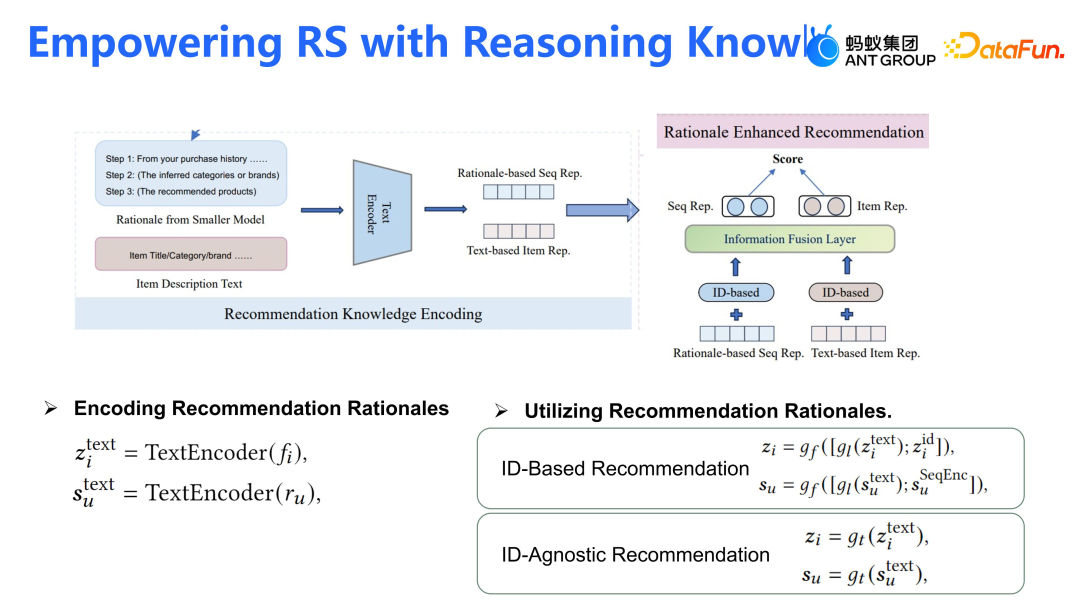
基于前述 LLAMA2 模型,能够做 T+1 推理。- 针对每个用户的行为序列,采用三步 CoT 生成推荐理由;
- 通过 BERT 模型将推荐理由进行 Embedding 化,得到用户行为序列的大模型表征,同时,使用 BERT 模型生成 item 的表征;
- 通过 concatenate 操作和 attention 机制将两者结合,来增强下游推荐模型的性能。
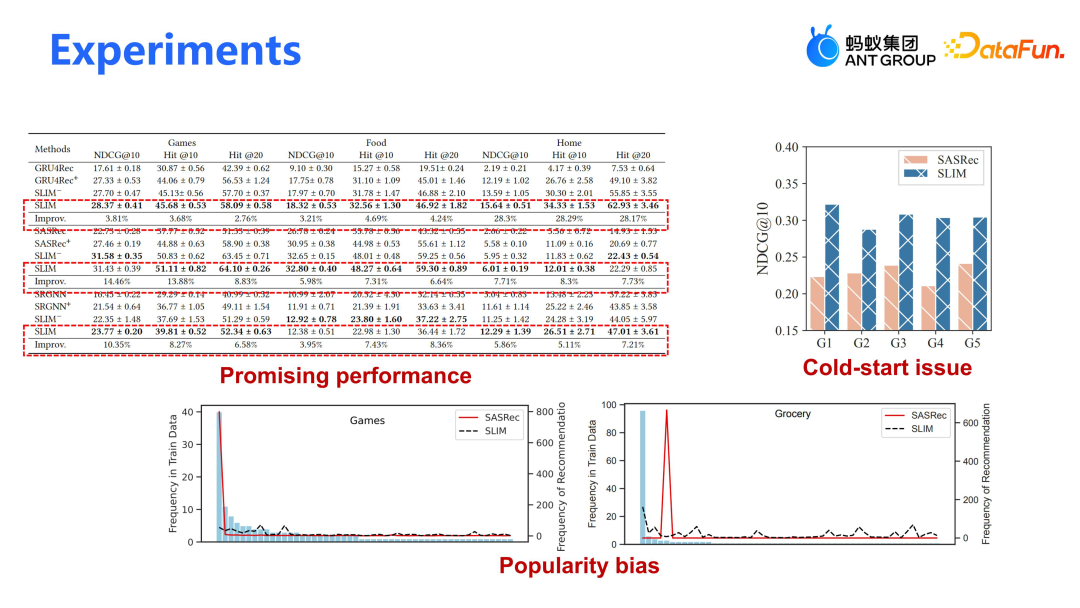
我们评估了不同的 backbone 模型,包括 GRU4Rec、SASRec 和 SRGNN,分别代表简单序列模型、attention 模型和图模型。尽管这些模型存在争议,但大模型通过引入 open knowledge,对一些长期冷启动用户具有较大的帮助,因为大模型能利用丰富的语义信息。此外,我们的模型有效克服了 Popularity bias(流行度偏差)问题,这在两个长尾分布的数据集上尤为明显。与 SASRec 相比,我们的模型在推荐长尾物品时更为均衡,整体 item 分布平稳,并能有效推荐一些较为突出的 item。
我们将 GPT3.5 模型蒸馏至了更小的 LLAMA 模型,但 LLAMA 模型仍显庞大。接下来,我们希望将 LLAMA 进一步压缩至更小的序列模型。在实验中遇到几个挑战:①蒸馏过程中教师模型的知识可靠性存疑;②从语言模型到序列模型的蒸馏跨越了不同的模型类型,这带来了两个主要问题,一是参数差距大,学生模型难以容纳教师模型的知识;二是语义不一致,因为序列模型与原始语言模型之间存在天然差异。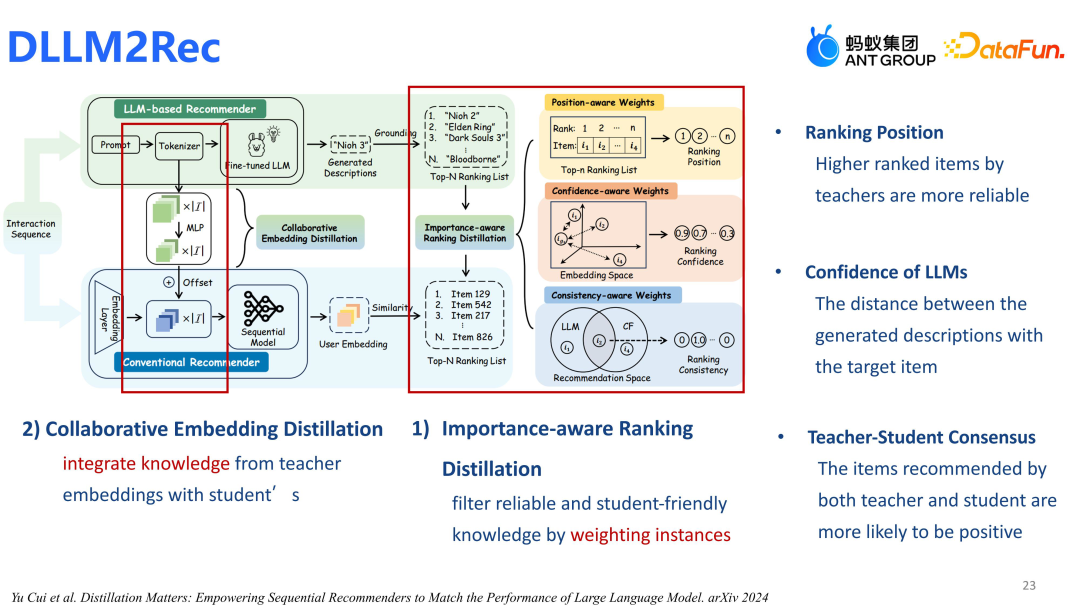
我们设计的模型主要包含两个关键部分:基于 Ranking 的蒸馏策略和 Embedding 对齐,核心在于排名蒸馏。采取了三个策略:①选择 LLAMA2 作为教师模型,认为其排名靠前的分值更高;②考虑 LLM 生成的描述与目标物品(Target Item)的接近程度,增加其排名;③若教师模型(Teacher Model)认为某物品是优质且排名靠前的,学生模型(Student Model)也会给予其更高排名。通过这些策略,我们设计了排名损失(Ranking Loss)函数,用于蒸馏小型序列模型。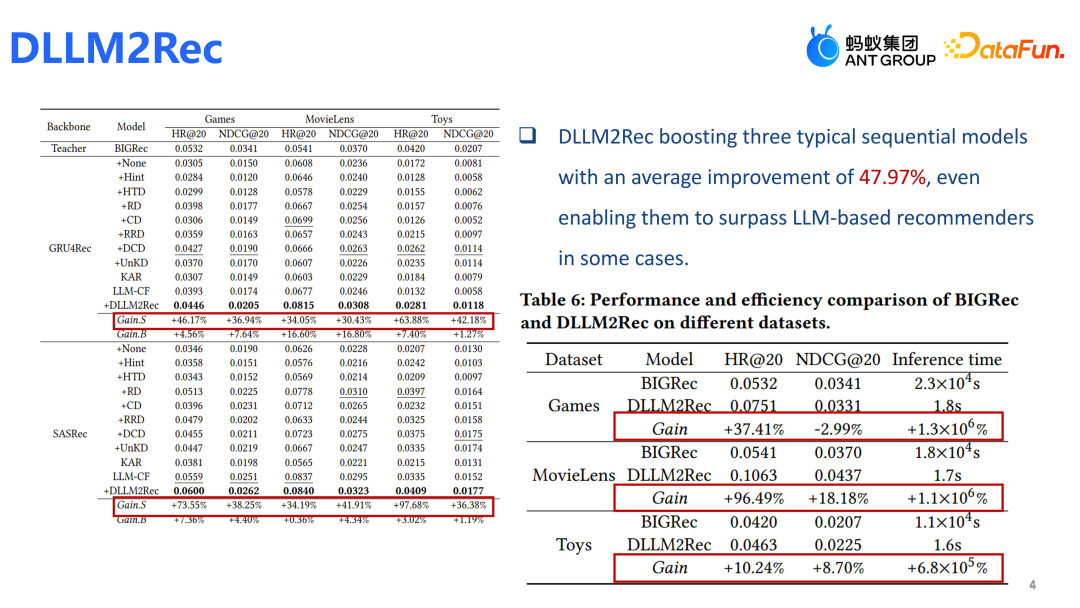
效果上,DLLM2Rec 模型在 backbone 上展现出了显著效果,相比一些大模型推荐模型也有明显提升。Q&A
Q1:模型蒸馏到 LLAMA2 7B 还是 70B?蒸馏效果如何?A1:我们针对 LLAMA2-7B 模型进行蒸馏,效果还可以。LLAMA2 从 GPT3.5 中蒸馏出强大的推理能力,能深入理解用户行为中的内在逻辑,而不仅仅是推荐用户已知的物品。这种能力有助于消除传统推荐模型中的 bias,更准确地预测用户想要的东西。所以,我们采用 LLAMA2 来蒸馏这种能力。Q2:蒸馏后得到的小模型是用于离线推理还是在线推理?
A2:LLAMA2 是用于离线推理,在线推理还是筛选不了;而后续的序列模型可以用于在线推理,LLAMA2 继续蒸馏后的小模型,其实是非常小的模型,它就是一个传统的推荐模型,可以部署到线上。Q3:对数据稀疏的低频场景来说,大模型结合推荐系统一般怎么设计?A3:蚂蚁/支付宝的数据天然稀疏,我们通过大量工作进行知识抽取,就是让稀疏场景能泛化出一些更加高活的场景,通过一些知识连通起来。基于这些知识,我们使大模型在推荐系统中运用 RAG 等策略,通过检索抽取的知识,或直接将图谱特征应用于稀疏场景,来强化特征表示。去年,我们做了大量的工作,致力于通过知识来挖掘知识,打通数据稀疏场景与数据丰富场景的一些链路。

































 粤ICP备17114055号
粤ICP备17114055号