
神经机器翻译是最近提出的一种机器翻译方法。与传统的统计机器翻译不同,神经机器翻译旨在构建一个可以联合调整以最大化翻译性能的单一神经网络。最近提出的神经机器翻译模型通常属于编码器-解码器家族,将源句子编码为一个固定长度的向量,解码器从这个向量生成翻译。在本文中,我们推测使用固定长度的向量是提高这种基本编码器-解码器架构性能的瓶颈,并提出通过允许模型自动(软)搜索与预测目标词相关的源句子的部分来扩展它,而无需将这些部分明确地作为硬分段来形成。通过这种新方法,我们在英语到法语的翻译任务上实现了与现有最先进的基于短语的系统相当的翻译性能。此外,定性分析表明,模型发现的(软)对齐与我们的直觉相符。
敲黑板,划重点
注意力机制:联合对齐和翻译(Align And Translate)
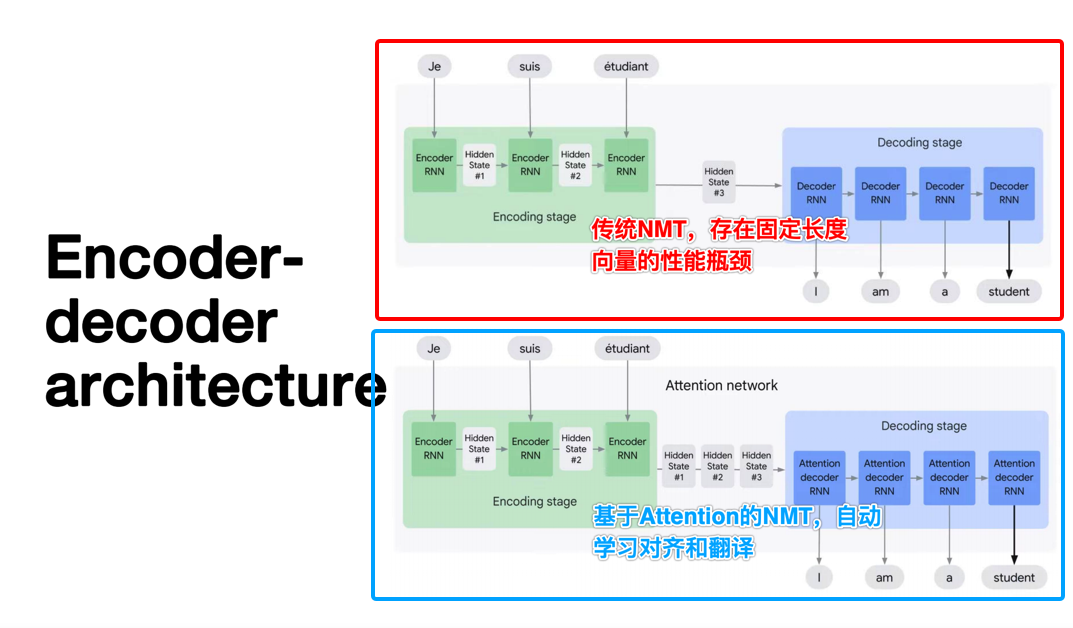
神经机器翻译通过引入注意力机制,克服了传统编码器-解码器架构中固定长度向量的性能瓶颈,在英语到法语的翻译任务上实现了与最先进系统相当的翻译性能,并通过定性分析验证了其合理性和实用性。
关键创新:引入注意力机制,突破固定长度编码向量的限制,提升翻译性能。
实验成果:在英-法翻译任务上达到或接近最先进水平。
方法验证:定性分析显示模型的对齐方式与人类直觉一致,增强了方法的可信度。
基于Attention的NMT
Introduction
1 引言
神经机器翻译是机器翻译领域的一种新兴方法,最近由Kalchbrenner和Blunsom(2013)、Sutskever等人(2014)以及Cho等人(2014b)提出。与传统的基于短语的翻译系统(例如,参见Koehn等人,2003)不同,后者由多个小型子组件组成且分别调优,神经机器翻译则尝试构建和训练一个单独的、大型的神经网络,该网络能够读取句子并输出正确的翻译。大多数提出的神经机器翻译模型属于编码器-解码器(Encoder-Decoder)家族(Sutskever等人,2014;Cho等人,2014a),每种语言对应一个编码器和一个解码器,或者涉及对每个句子应用特定语言的编码器,然后将输出进行比较(Hermann和Blunsom,2014)。编码器神经网络读取并编码源句子为一个固定长度的向量。解码器则从这个编码向量中输出翻译。整个编码器-解码器系统,包括一对语言的编码器和解码器,被联合训练以在给定源句子的情况下最大化正确翻译的概率。编码器-解码器方法的一个潜在问题是,神经网络需要将源句子的所有必要信息压缩到一个固定长度的向量中。这可能会使神经网络难以处理长句子,尤其是那些比训练语料库中的句子更长的句子。Cho等人(2014b)表明,随着输入句子长度的增加,基本编码器-解码器的性能会迅速下降。为了解决这个问题,我们引入了编码器-解码器模型的扩展,该模型学习联合对齐和翻译。每次模型在翻译中生成一个单词时,它都会(软)搜索源句子中信息最集中的一组位置。然后,模型基于与这些源位置相关联的上下文向量以及之前生成的所有目标单词来预测目标单词。与基本编码器-解码器方法最重要的区别在于,该方法不尝试将整个输入句子编码为一个单一的固定长度向量。相反,它将输入句子编码为一个向量序列,并在解码翻译时自适应地选择这些向量的一个子集。这使得神经翻译模型不必将源句子的所有信息(无论其长度如何)都压缩到一个固定长度的向量中。我们表明,这允许模型更好地处理长句子。在本文中,我们展示了所提出的联合学习对齐和翻译的方法在翻译性能上显著优于基本的编码器-解码器方法。这种改进在长句子中更为明显,但可以在任何长度的句子中观察到。在英语到法语的翻译任务中,该方法使用单个模型即可实现与传统基于短语的系统相当的翻译性能。此外,定性分析表明,该模型能够在源句子和对应的目标句子之间找到语言上合理的(软)对齐。敲黑板,划重点
神经机器翻译采用编码器-解码器模型,通过联合学习对齐与翻译,解决了传统模型处理长句限制,实现更高效、准确的翻译。
- 神经机器翻译简介:神经机器翻译是一种新兴的机器翻译方法,通过构建和训练大型神经网络来读取句子并输出翻译,与传统基于短语的翻译系统不同。
SMT vs NMT
- 编码器-解码器模型:大多数神经机器翻译模型属于编码器-解码器家族,其中编码器将源句子编码为固定长度的向量,解码器则从这个向量中输出翻译。整个系统联合训练以最大化正确翻译的概率。
- 潜在问题:基本编码器-解码器模型需要将源句子的所有信息压缩到一个固定长度的向量中,这限制了其处理长句子的能力。
- 联合对齐和翻译:为了解决这个问题,引入了扩展模型,该模型在翻译时学习联合对齐和翻译。模型在生成每个目标单词时,会搜索源句子中最相关的信息位置,并基于这些位置的上下文向量及之前生成的目标单词来预测目标单词。

2 背景:神经机器翻译
从概率论的角度来看,翻译等价于找到一个目标句子y,使得在给定源句子x的条件下,y的条件概率最大化,即arg max_y p(y | x)。在神经机器翻译中,我们拟合一个参数化模型,以使用并行训练语料库最大化句子对的条件概率。一旦翻译模型学习了条件分布,给定一个源句子,就可以通过搜索最大化条件概率的句子来生成相应的翻译。最近,多篇论文提出了使用神经网络直接学习这种条件分布的方法(例如,参见Kalchbrenner和Blunsom,2013;Cho等人,2014a;Sutskever等人,2014;Cho等人,2014b;Forcada和Neco,1997)。这种神经机器翻译方法通常包含两个组件:第一个组件对源句子x进行编码,第二个组件将编码解码为目标句子y。例如,Cho等人(2014a)和Sutskever等人(2014)使用两个递归神经网络(RNN)将可变长度的源句子编码为一个固定长度的向量,并将该向量解码为可变长度的目标句子。尽管神经机器翻译是一种相对较新的方法,但它已经展示了令人鼓舞的结果。Sutskever等人(2014)报告说,基于带有长短期记忆(LSTM)单元的RNN的神经机器翻译在英法翻译任务上接近传统基于短语的机器翻译系统的最先进水平。此外,向现有的翻译系统添加神经组件,例如为短语表中的短语对打分(Cho等人,2014a)或重新排序候选翻译(Sutskever等人,2014),已经允许超过以前的最先进水平。敲黑板,划重点
的技术,它直接从源语言文本生成目标语言文本,无需依赖传统机器翻译中的多个独立处理模块。NMT模型通过大规模语料库的学习,能够捕捉源语言和目标语言之间的复杂映射关系,并生成自然流畅的目标语言译文。
3 Learning To Align And Translate
Learning To Align And Translate3 学习对齐与翻译
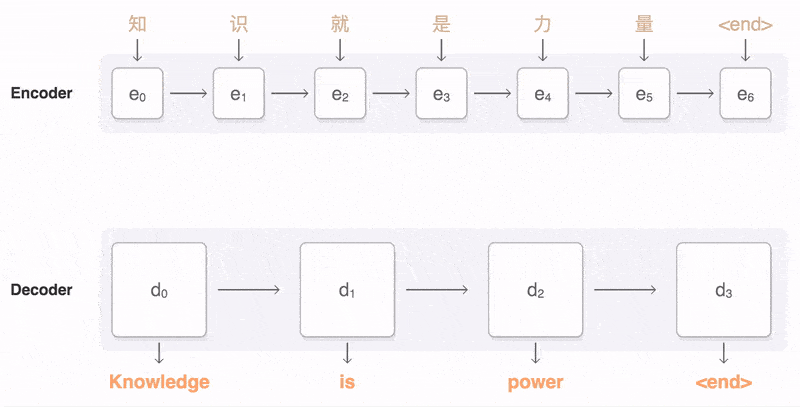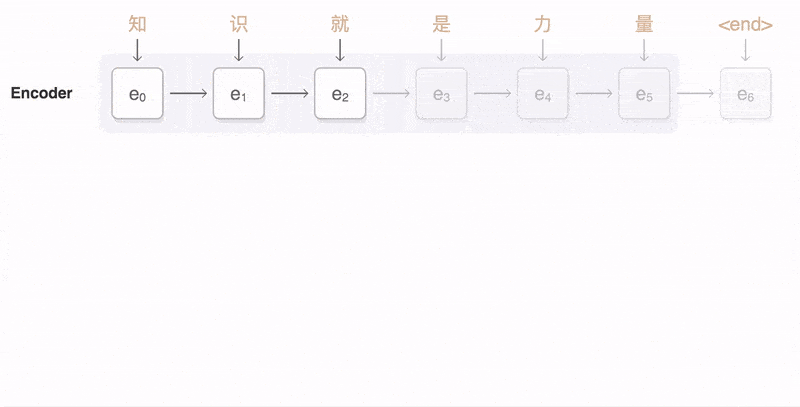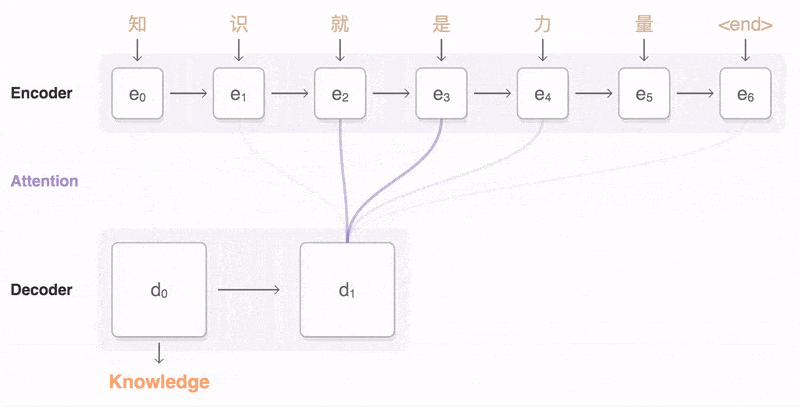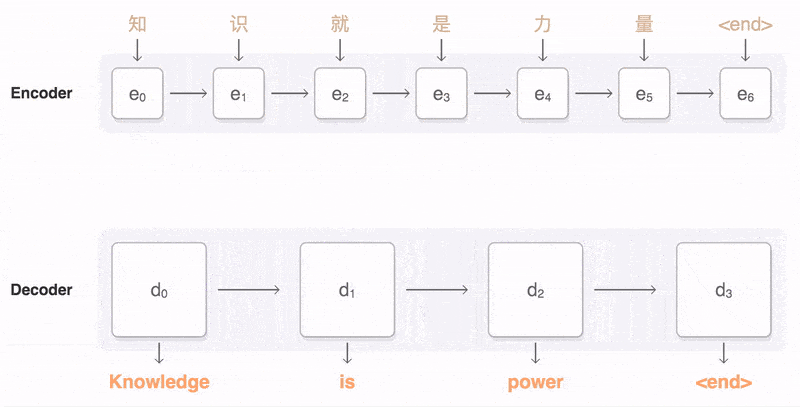
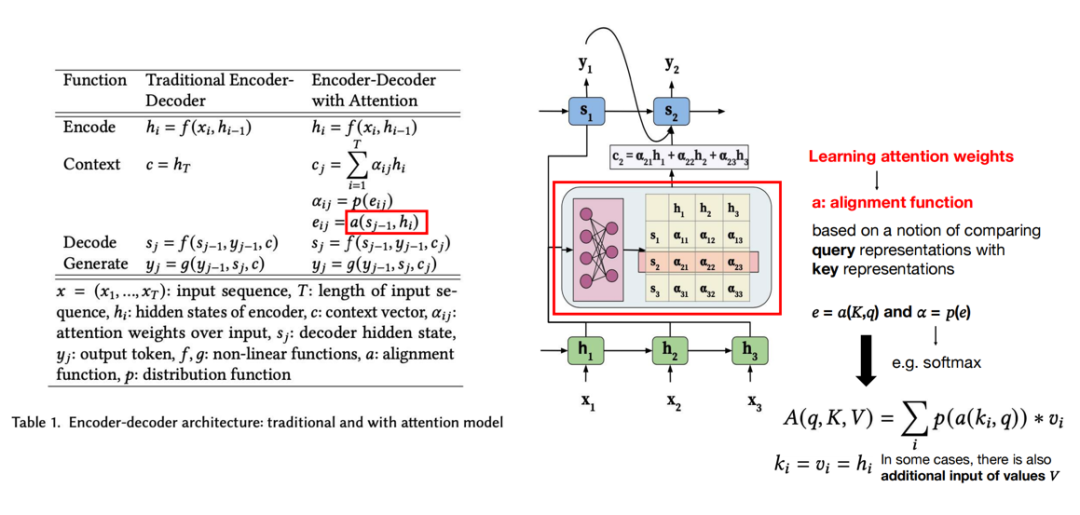
在本节中,我们提出了一种用于神经机器翻译的新型架构。新架构由一个双向RNN作为编码器(第3.2节)和一个在解码翻译时模拟遍历源句的解码器(第3.1节)组成。在新的模型架构中,我们将方程(2)中的每个条件概率定义为:p(yi |y1, ..., yi−1, x) = g(yi−1, si, ci),(4)其中si是时间i的RNN隐藏状态,由si = f(si−1, yi−1, ci)计算得出。值得注意的是,与现有的编码器-解码器方法(见方程(2))不同,这里的概率是针对每个目标词yi的特定上下文向量ci进行条件化的。上下文向量ci依赖于编码器将输入句子映射到的一系列注释(h1, ..., hTx)上。每个注释hi包含关于整个输入序列的信息,并强烈关注输入序列中第i个词周围的部分。我们将在下一节中详细解释如何计算这些注释。然后,上下文向量ci计算为这些注释hi的加权和:ci = ΣTx j=1 αijhj。(5)每个注释hj的权重αij通过αij = exp(eij) / ΣTx k=1 exp(eik)计算得出,(6)其中eij = a(si−1, hj)是一个对齐模型,用于评分输入中位置j附近的词与输出中位置i的词之间的匹配程度。该评分基于RNN隐藏状态si−1(即在发出yi之前,方程(4))和输入句子的第j个注释hj。我们将对齐模型a参数化为一个前馈神经网络,该网络与其他所有组件一起联合训练。请注意,与传统的机器翻译不同,这里对齐不被视为潜在变量。相反,对齐模型直接计算软对齐,这使得成本函数的梯度可以反向传播。该梯度可用于训练对齐模型以及整个翻译模型。我们可以将计算所有注释的加权和的方法理解为计算一个期望注释,其中期望是基于可能的对齐。设αij为目标词yi与源词xj对齐或翻译自源词xj的概率。那么,第i个上下文向量ci是所有注释的期望注释,其概率为αij。概率αij或其相关能量eij反映了在决定下一个状态si和生成yi时,注释hj相对于前一个隐藏状态si−1的重要性。直观地看,这在解码器中实现了一种注意力机制。解码器决定了源句中要关注的部分。通过让解码器具有注意力机制,我们减轻了编码器将源句中的所有信息编码到固定长度向量的负担。通过这种新方法,信息可以分布在注释序列中,解码器可以相应地选择性地检索这些信息。通常的RNN(如方程(1)所述)按顺序从第一个符号x1读取到最后一个符号xTx。然而,在提出的方案中,我们希望每个词的注释不仅能总结前面的词,还能总结后面的词。因此,我们建议使用双向RNN(BiRNN,Schuster和Paliwal,1997),该RNN最近在语音识别中得到了成功应用(例如,参见Graves等人,2013)。BiRNN由前向RNN和后向RNN组成。前向RNN →f 按顺序读取输入序列(从x1到xTx),并计算一系列前向隐藏状态(→h1, ..., →hTx)。后向RNN ←−f 按相反顺序读取序列(从xTx到x1),得到一系列后向隐藏状态(←−h1, ..., ←−hTx)。我们通过连接前向隐藏状态→hj和后向隐藏状态←−hj来获得每个词xj的注释,即hj = [→hj; ←−hj]。这样,注释hj就包含了前面词和后面词的总结。由于RNN倾向于更好地表示最近的输入,因此注释hj将集中在xj周围的词上。这一系列注释稍后将由解码器和对齐模型用于计算上下文向量(方程(5)和(6))。敲黑板,划重点
神经机器翻译新架构通过学习对齐模型,结合双向RNN编码器和带注意力机制的解码器,实现更精准的学习对齐与翻译过程。
解码器与注意力机制:Transformer的前身
解码器在生成每个目标词时,不仅依赖于之前的生成词和当前隐藏状态,还依赖于一个特定的上下文向量ci,该向量是源句注释的加权和。
上下文向量ci通过加权和计算得出,权重αij由对齐模型a决定,该模型评估了源句中每个词与目标词之间的匹配程度。
对齐模型a是一个前馈神经网络,与整个翻译模型联合训练,实现了软对齐,允许梯度反向传播以优化对齐和翻译。
这种机制在解码器中引入了注意力,允许解码器在生成每个目标词时动态地关注源句的不同部分。
编码器与双向RNN:BERT的前身
编码器使用双向RNN(BiRNN)来生成源句的注释序列。
BiRNN由前向RNN和后向RNN组成,分别从前到后和从后到前读取输入序列,生成前向和后向隐藏状态。
每个词的注释由对应位置的前向和后向隐藏状态连接而成,包含了该词前后文的信息。
这种注释方式使得每个注释都能更好地表示其周围词的信息,为解码器提供了更丰富的源句表示。
整体架构与优势:
该新架构通过结合双向RNN编码器和带有注意力机制的解码器,实现了更高效的神经机器翻译。
注意力机制减轻了编码器将源句信息压缩到固定长度向量的负担,允许信息分布在注释序列中,并由解码器根据需要选择性地检索。
这种方法提高了翻译的准确性和流畅性,特别是在处理长句和复杂结构时表现出色。

































 粤ICP备17114055号
粤ICP备17114055号