在人工智能的飞速发展中,智能问答系统(QA系统)逐渐成为了企业内部管理、客户服务、搜索引擎等多个领域中的关键技术。今天,我们将深入探讨一个基于大模型、自然语言处理、知识检索的智能问答系统的架构,详细介绍其技术原理、流程以及未来应用前景。一、系统整体概览
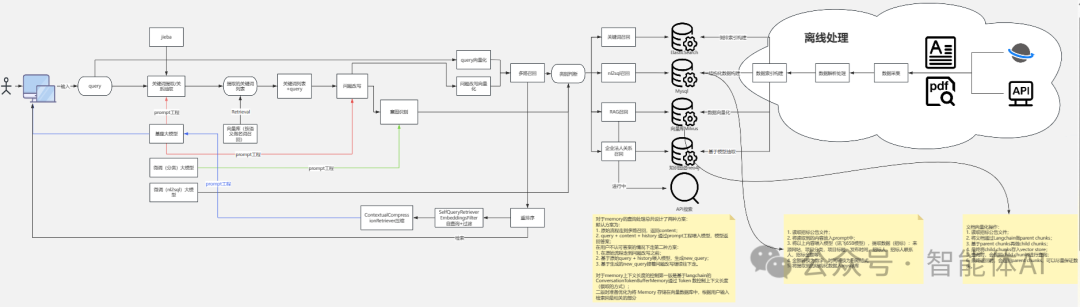
在这个智能问答系统中,整个流程可以大致划分为两大部分:前端问答生成与后端离线数据处理。前端部分是用户交互的核心,通过用户的输入、关键词提取、检索和问答生成等步骤,系统能够迅速生成用户期望的答案。而后端部分则主要负责大量企业文档和数据库的预处理工作,将原始数据进行解析、结构化和索引化,以支持前端的快速响应。这种双模块架构确保了系统能够高效运转,既能动态处理用户的查询,又能充分利用已有知识库进行精准回答。接下来,我们将详细介绍这两大部分的核心组件及其工作原理。
二、前端架构详解:从用户查询到智能回答
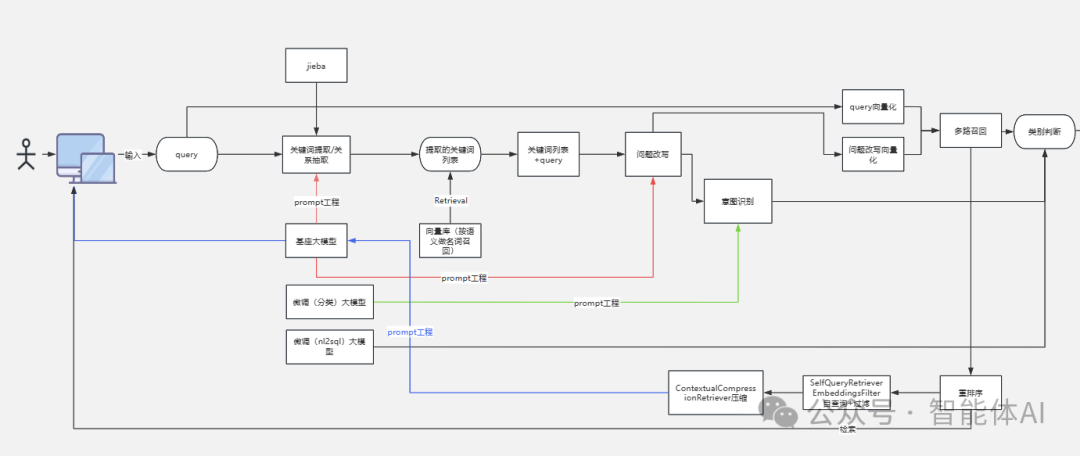
在用户提交查询请求后,系统从用户的输入出发,经过多重处理后生成最终的回答。前端架构包括了多个关键步骤,每一个步骤都对系统的精度和速度至关重要。1、用户查询解析与关键词提取
用户查询解析是整个问答流程的起点。当用户通过界面输入查询内容(query)时,系统首先会利用 jieba 分词工具将用户的自然语言进行切分,提取出有用的关键词。分词后的内容将被送入关键词提取和关系抽取模块,该模块会对句子中的重要关键词和其语义关系进行分析,生成一个关键词列表。这个关键词列表对于接下来的查询和检索过程至关重要。系统将这些提取的关键词与用户的初始查询进行融合,形成一个增强版的查询。这个增强版查询能够提高系统的识别准确度,确保后续的搜索与回答生成更具针对性。2、基于大模型的问答生成
在解析和提取关键词后,系统会进入核心的问答生成环节。在这一阶段,系统借助了多个大模型来生成高质量的答案。具体来说,这些大模型包括:基础大模型:负责处理大部分通用的问答任务,通常可以直接生成合理的答案。
分类模型:该模型用于识别用户查询的类型或分类,并根据查询类别调用不同的下游模块进行回答。例如,如果用户询问的是数据查询类型的问题,系统会调动适合的数据库查询模型。
nl2sql大模型:当用户提出需要从数据库中提取数据的自然语言查询时,nl2sql大模型将这些自然语言转换为相应的SQL语句,从而访问数据库并返回结果。
这些大模型不仅提升了问答的准确性,还让系统能够处理不同种类的复杂查询。无论是简单的对话型问答,还是复杂的数据提取任务,系统都能够流畅应对。
3、多模型召回与问题重写
为了进一步优化生成的答案,系统还引入了多模型召回与问题重写机制。在生成初步答案后,系统会利用向量化技术对用户的查询进行深度分析,并对生成的回答进行问题重写。问题重写可以优化查询表达,使得系统更容易从数据库或知识库中提取出最相关的信息。同时,系统采用了多路召回机制。该机制允许系统从多个不同模型中获取候选答案,并通过比较筛选出最优的回答。这种方法能够提高系统的回答准确性和丰富性,确保用户得到的答案是最符合查询意图的。三、后端架构详解:数据预处理与索引化
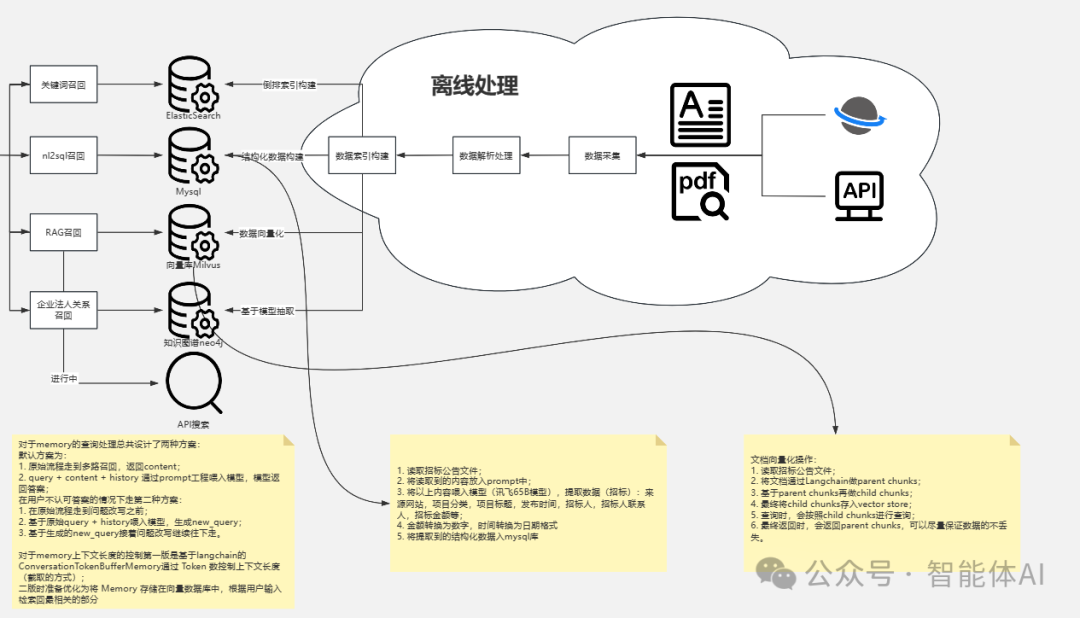
在前端完成问答生成的过程中,后端的离线数据处理部分起到了至关重要的支撑作用。后端通过对大量企业内部数据和外部文档的离线解析与索引构建,为前端提供了强大的数据支撑。具体来说,后端处理流程主要包括以下几个步骤:1、数据解析与结构化
后端的第一步是对海量数据进行解析处理。系统可以从企业内部的文档、PDF、API接口等多种数据源中提取出关键信息。为了确保数据的有效性和可用性,系统会对这些原始数据进行预处理,提取出重要的字段,并通过自然语言处理技术将其转化为结构化数据。例如,对于一份复杂的PDF文件,系统会自动解析其内容,提取出标题、章节、时间、关键词等信息。然后,这些信息会被进一步处理,形成一个可查询的知识库。
2、索引构建与优化检索
在数据解析完成后,系统会通过 ElasticSearch、Mysql、Milvus 等数据库工具对数据进行索引化处理。通过这种方式,系统能够在极短的时间内对用户的查询进行响应,并返回高相关性的结果。此外,系统还结合了向量化技术和知识图谱来优化检索结果。知识图谱能够帮助系统更好地理解不同实体之间的关系,从而提高检索的精准度。基于向量化的检索机制则可以确保即使用户的查询与索引数据并不完全匹配,系统仍然能够找到语义相关的内容。四、记忆机制与上下文处理
为了进一步提升系统的智能化和用户体验,系统设计了记忆机制,用于处理用户的上下文信息和历史查询。在这个机制中,系统会保留用户的查询历史以及上下文信息,从而生成更具连续性和相关性的回答。这个记忆机制通过保存用户的对话历史,允许系统在新问题的基础上参考之前的交互内容,确保回答的连续性。例如,在一个多轮对话中,用户可能会先询问某个项目的总体进展,随后询问具体的细节。系统会基于前一个问题的回答,生成更准确的后续回答。此外,记忆机制还会通过 TokenBufferMemory 进行短期记忆优化,确保在不牺牲性能的情况下能够处理较长的对话上下文。
五、系统优化与未来展望
为了让系统不断适应和优化,设计者还加入了诸如 Langchain 等工具,用于实现复杂的父子节点层次化机制。这种机制能够将数据切分成更小的块(chunks),并通过这些块的组合生成更精确的回答。此过程确保了数据不会因为过度简化而丢失细节,同时能够有效提高查询响应速度。展望未来,智能问答系统将会继续演化,尤其是在数据量、模型规模以及检索精度等方面都将有巨大的提升。这种系统将不仅仅局限于企业内部的知识管理,还将在法律、金融、医疗等多个专业领域得到广泛应用。
六、总结
构建一个高效且智能的问答系统不仅需要前沿的技术支持,还需要完善的架构设计和不断的优化。通过本文的讲解,读者可以对一个完整的智能问答系统有更深入的了解。从前端的问答生成到后端的离线数据处理,系统各个模块紧密协作,确保了整个流程的高效性和准确性。随着技术的不断进步,智能问答系统的应用将更加广泛,并在未来进一步推动人类知识的自动化和智能化管理。读者可以详细了解这个架构的每个组成部分,并理解智能问答系统的技术实现和应用价值。


























 粤ICP备17114055号
粤ICP备17114055号
