推荐语
这是豆包大模型 1.5 Pro 全面升级的重磅发布,性能卓越,成果斐然!
核心内容:
1. 模型能力的全面升级亮点
2. 创新的模型架构与性能优势
3. 自主数据生产体系的构建
杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
今天,豆包全新基础模型 Doubao-1.5-pro 正式发布,模型能力全面升级,融合并进一步提升了多模态能力。
模型使用 MoE 架构,并通过训练-推理一体化设计,探索模型性能和推理性能之间的极致平衡。Doubao-1.5-pro 仅用较小激活参数,即可比肩一流超大稠密预训练模型的性能,并在多个评测基准上取得优异成绩。值得注意的是,通过模型结构和训练算法优化,我们将 MoE 模型的性能杠杆提升至 7 倍,此前,业界的普遍水平为不到 3 倍。
此外,团队还构建了高度自主的数据生产体系,坚持不走捷径,不使用任何其他模型的数据,确保数据来源的独立性和可靠性。
本篇文章,我们将详细呈现模型的性能评估、技术亮点。包括:完整版 Blog ,可在豆包大模型团队官网查看:
https://team.doubao.com/doubao_1_5_pro
目前,Doubao-1.5-pro 已在豆包 APP 灰度上线,接受海量请求效果出色,同时,开发者也可在火山引擎直接调用 API 。综合能力领先
多基准表现优异
此次更新,Doubao-1.5-pro 基础模型能力全面提升,在多个公开评测基准上表现优异。
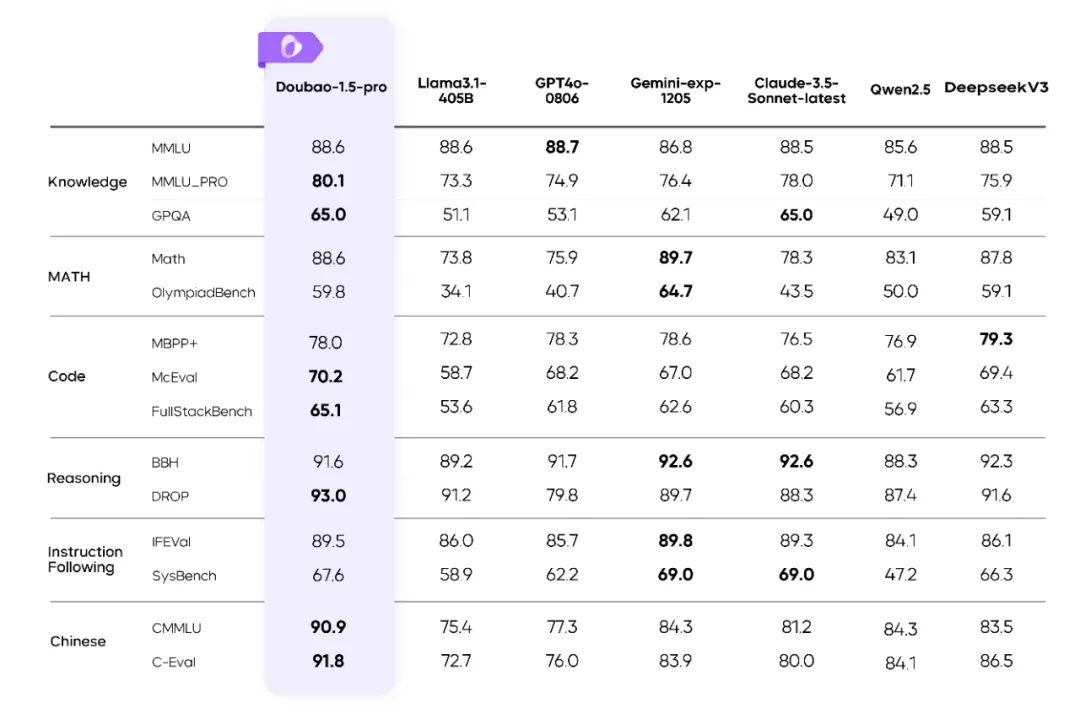 Doubao-1.5-pro 在多个基准上的评测结果
Doubao-1.5-pro 在多个基准上的评测结果
高效 MoE 模型结构
从训练和推理效率出发,Doubao-1.5-pro 使用稀疏 MoE 架构。在预训练阶段,仅用较小参数激活的 MoE 模型,性能即可超过 Llama-3.1-405B 等超大稠密预训练模型。团队通过对稀疏度 Scaling Law 的研究,确定了性能和效率比较平衡的稀疏比例,并根据 MoE Scaling Law 确定了小参数量激活的模型即可达到世界一流模型的性能。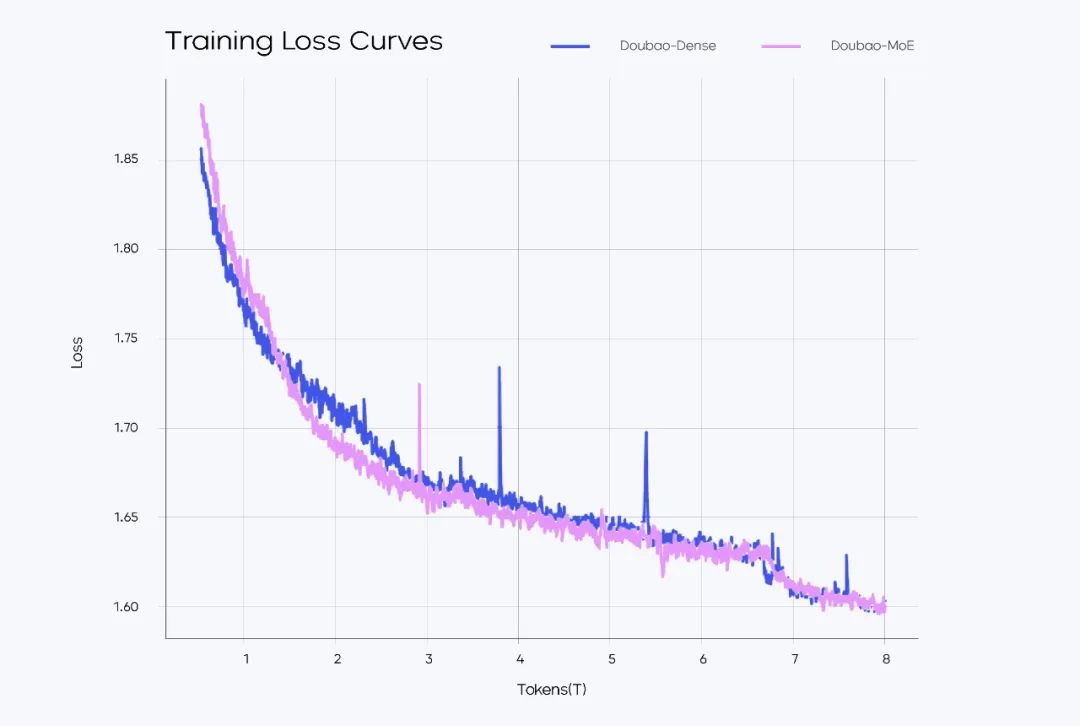 训练 loss 图MoE 模型的性能通常可以用表现相同的稠密模型的总参数量和 MoE 模型的激活参数量的比值来确定,比如 IBM 的 Granite 系列模型中,800M 激活的 MoE 模型性能可以接近 2B 总参数的稠密模型,性能比值大约在 2.5 倍(2000M/800M)。此前,业界的普遍水平在不到 3 倍的性能杠杆上。团队通过模型结构和训练算法优化,在完全相同的部分训练数据(9T tokens)对比验证下,用激活参数仅为稠密模型参数量 1/7 的 MoE 模型,超过了稠密模型的性能,将性能杠杆提升至 7 倍。
训练 loss 图MoE 模型的性能通常可以用表现相同的稠密模型的总参数量和 MoE 模型的激活参数量的比值来确定,比如 IBM 的 Granite 系列模型中,800M 激活的 MoE 模型性能可以接近 2B 总参数的稠密模型,性能比值大约在 2.5 倍(2000M/800M)。此前,业界的普遍水平在不到 3 倍的性能杠杆上。团队通过模型结构和训练算法优化,在完全相同的部分训练数据(9T tokens)对比验证下,用激活参数仅为稠密模型参数量 1/7 的 MoE 模型,超过了稠密模型的性能,将性能杠杆提升至 7 倍。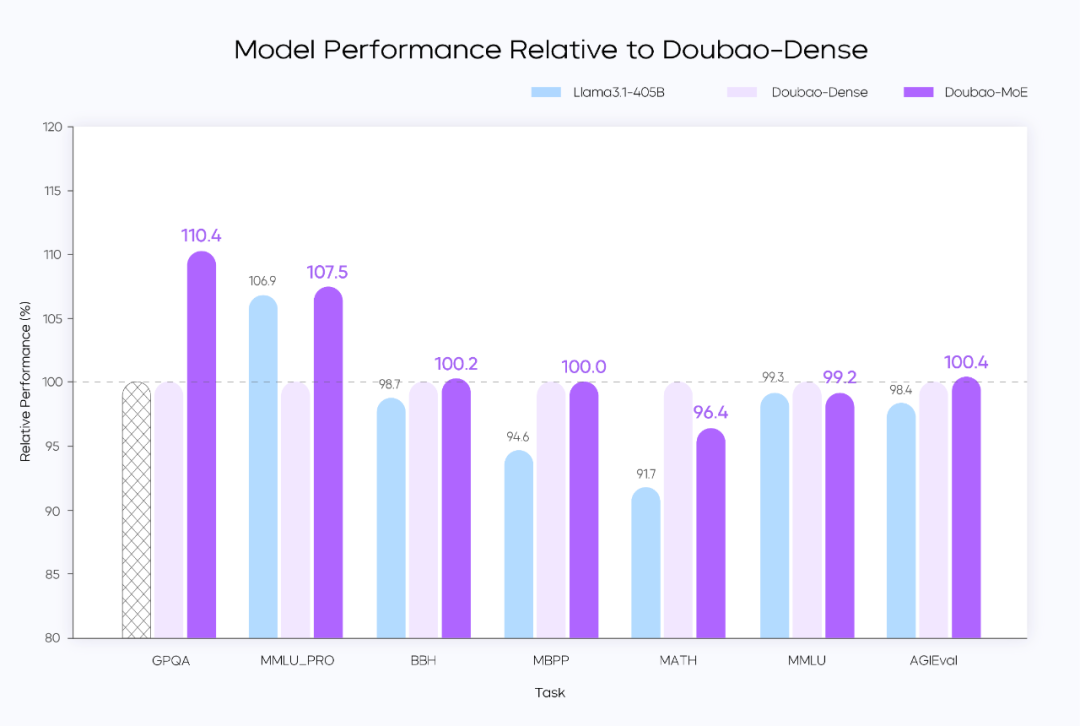 Performance 对比图
Performance 对比图Doubao-Dense、Doubao-MoE 均为 9T tokens 数据的阶段性结果,数据分布完全相同;MoE 模型的性能略优于整体参数量为 MoE 激活参数量 7 倍的稠密模型
Llama3.1-405B 为 15T tokens 的最终结果,数据分布和 Doubao 模型不同,Doubao 稠密模型的参数量也远小于 Llama3.1-405B ,从结果上可以看到 Doubao 预训练的数据质量和训练超参更优
MoE 模型完整训练后的性能比 9T tokens 数据的中间版本有更大提升
在预训练模型基础上,算法团队还设计了一系列模型参数动态调整算法。可以基于具体应用对模型性能的需求,从模型深度、宽度、MoE 专家数、激活专家数、隐藏 token 推理等不同维度,对模型参数进行扩增和缩小,达到模型能力和推理成本的最优平衡。同时,较小的预训练模型提高了团队迭代开发的效率,可以并发支持多个产品线。
高性能推理系统
Doubao-1.5-pro 是一个高度稀疏的 MoE 模型,在 Prefill/Decode 与 Attention/FFN 构成的四个计算象限中,呈现出显著不同的计算与访存特征。针对四个不同象限,我们采用异构硬件结合多种低精度优化的策略,在确保低延迟的同时大幅提升吞吐量,在降低总成本的同时兼顾 TTFT 和 TPOT 的最优化目标。
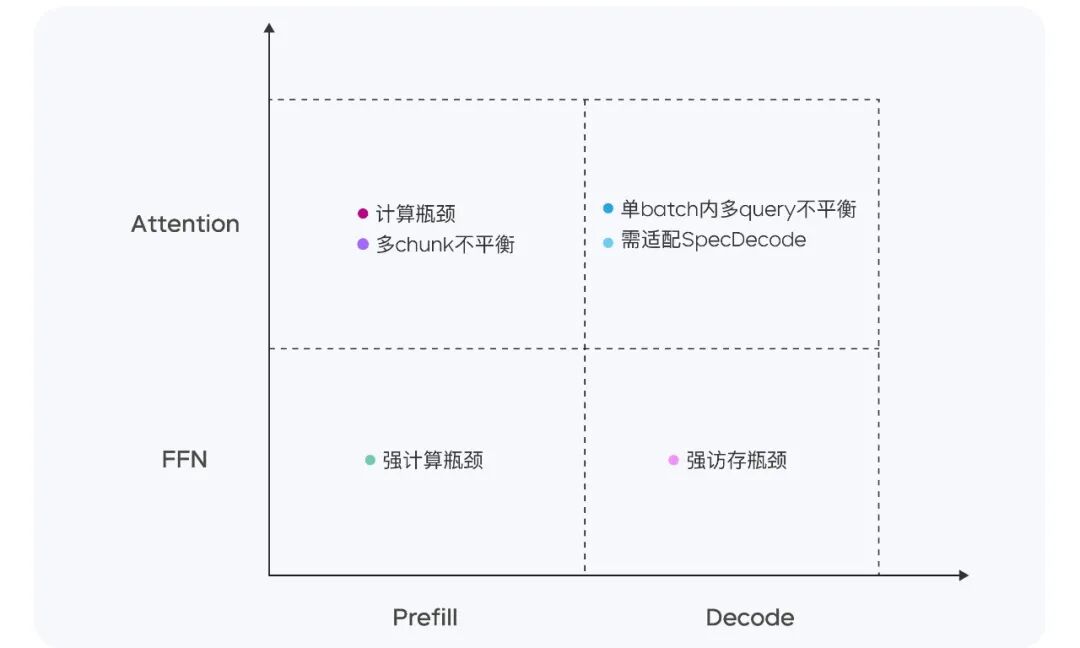 不同阶段的计算与访存特征Prefill 阶段,通信和访存瓶颈不明显,但容易达到计算瓶颈。考虑到 LLM 的单向注意力特点,我们在多种计算访存比较高的设备上做 Chunk-PP Prefill Serving ,使线上系统 Tensor Core 的利用率接近 60% 。Decode 阶段,整体计算瓶颈不明显,但对通信和访存能力要求较高。因此,我们采用计算访存比较低的设备 Serving 来换取更高的 ROI ,同时采用 Speculative Decoding 策略,降低 TPOT 指标。
不同阶段的计算与访存特征Prefill 阶段,通信和访存瓶颈不明显,但容易达到计算瓶颈。考虑到 LLM 的单向注意力特点,我们在多种计算访存比较高的设备上做 Chunk-PP Prefill Serving ,使线上系统 Tensor Core 的利用率接近 60% 。Decode 阶段,整体计算瓶颈不明显,但对通信和访存能力要求较高。因此,我们采用计算访存比较低的设备 Serving 来换取更高的 ROI ,同时采用 Speculative Decoding 策略,降低 TPOT 指标。整体来看,在 PD 分离的 Serving 系统上,我们实现了以下优化:
- 针对 Tensor 传输进行定制化的 RPC Backend ,并通过零拷贝、多流并行等手段优化了 TCP/RDMA 网络上的 Tensor 传输效率,进而提升 PD 分离下的 KV Cache 传输效率。
- 支持 Prefill 跟 Decode 集群的灵活配比和动态扩缩,对每种角色独立做 HPA 弹性扩容,保障 Prefill 和 Decode 都无冗余算力,两边算力配比贴合线上实际流量模式。
- 在框架上将 GPU 计算和 CPU 前后处理异步化,使得 GPU 推理第 N 步时 CPU 提前发射第 N+1 步 Kernel,保持 GPU 始终被打满,整个框架处理动作对 GPU 推理零开销。
此外,凭借自研服务器集群方案,灵活支持低成本芯片,硬件成本比行业方案大幅度降低。通过定制化网卡和自主研发的网络协议,显著优化了小包通信的效率。在算子层面,我们实现了计算与通信的高效重叠(Overlap),从而保证了多机分布式推理的稳定性和高效性。
扎实数据标注
Post-Training 阶段,我们构建了高度自主的数据生产体系,通过高效标注团队与模型自提升相结合的方式持续优化数据质量,严格遵循内部标准,坚持不走捷径,不使用任何其他模型的数据,确保数据来源的独立性和可靠性。SFT 阶段,我们开发了一套算法驱动的训练数据优化系统,训练数据多样性优化以及精确人题匹配功能,并结合模型自演进(Self-evolve)技术,提升数据标注的多样性和难度,形成了模型性能提升的良性循环。Reward Model 部分,我们建立了包含 prompt 分布优化、response 筛选、多轮迭代和 active learning 的完整数据生产 pipeline。在此基础上,实现了 Verifier 和 Reward Model 的深度融合,构建了统一的 Reward 框架,实现了模型在数学、编程、知识、对话等多维度能力的均衡提升。RL 阶段,我们在技术上攻克了价值函数训练难点,实现了 token-wise 稳定建模,在高难度任务上的性能提升超过 10 个绝对点。通过对比学习方法,有效提升了 LLM 的表现并显著缓解了 reward hacking 问题。在数据、算法、模型层面全面实现了 Scaling ,完成算力到智力的有效转换。此外,依托字节在推荐、搜索和广告领域的 AB Test 经验,研发了基于用户反馈的高效 Post-Training 全流程,基于豆包的大规模用户反馈,我们构建了从问题发现、数据挖掘、人机结合标注到快速迭代的闭环优化系统,通过用户数据飞轮持续提升模型的实际使用体验。
融合视觉及语音
Doubao-1.5-pro 在同一模型中融合并提升了视觉、语音等多模态能力,可为用户带来更自然、更丰富的交互体验。
视觉多模态:
性能进一步提升,从容应对更复杂场景
相比于此前发布的 Doubao 视觉理解模型版本,Doubao-1.5-pro 在多模态数据合成、动态分辨率、多模态对齐、混合训练上进行了全面的技术升级,进一步增强了模型在视觉推理、文字文档识别、细粒度信息理解、指令遵循方面的能力,并让模型的回复模式变得更加精简、友好。
Doubao-1.5-pro 能够读懂不同分辨率和不同长宽比的图片,支持百万级分辨率,能更清晰的识别内容;同时模型的视觉推理能力表现优越,在各类 Benchmark 上均取得了优异表现: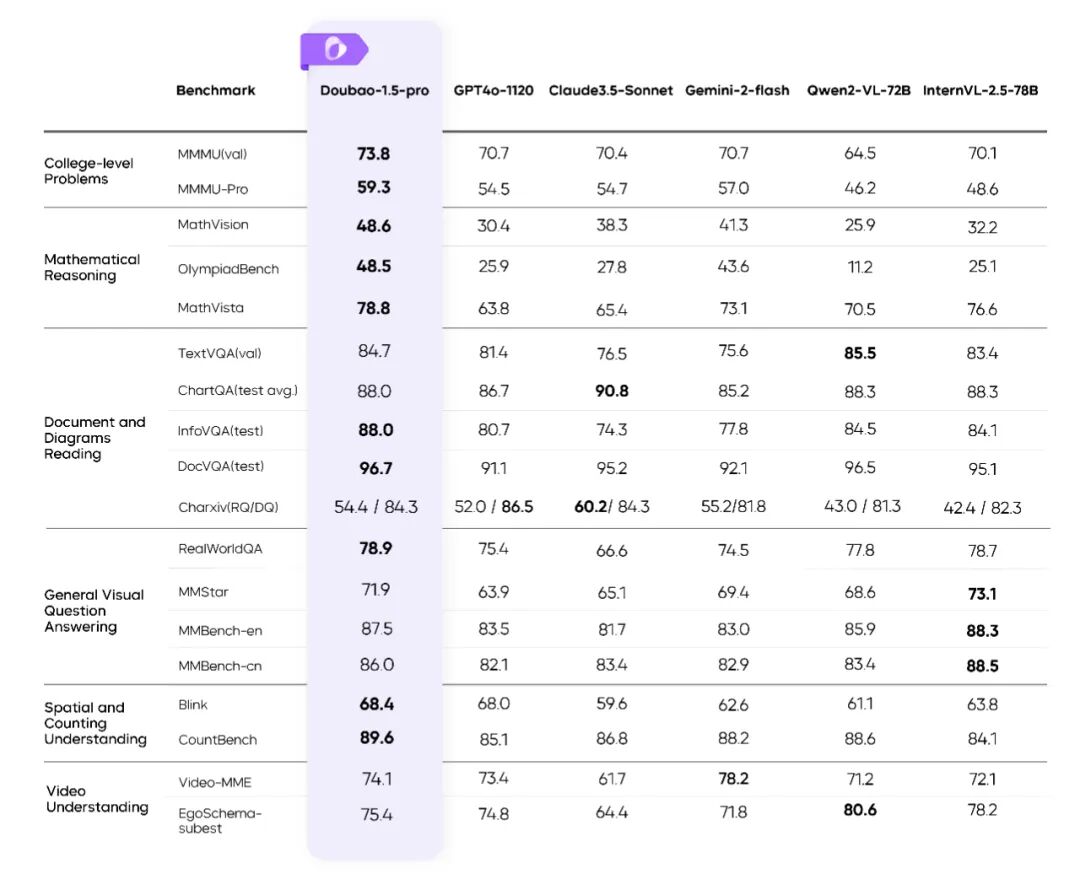 Doubao-1.5-pro 在多个视觉基准上的评测结果高效的原生动态分辨率训练:Doubao-1.5-pro 采用原生动态分辨率的架构设计,支持任意分辨率的图像输入。无论是高清大图还是低分辨率的小图,亦或是极端长宽比例的图像,模型都能实现精准的特征提取和高效的计算性能。比如视频中,这张超长尺寸的漫画图,Doubao-1.5-pro 依旧可精准识别图片信息并总结。领先的复杂指令遵循能力:通过系统性的原子能力拆解和多维度指令的逻辑组合,在后训练阶段引入了多样化的视觉指令数据,使 Doubao-1.5-pro 能从容应对指令更复杂的场景。多样化的数据合成管线:Doubao-1.5-pro 除了利用来自搜索引擎的海量图文对和图文交织数据对进行训练之外,还采用了基于渲染引擎、传统 CV 模型、模型自迭代等数据合成方式,以获得高质量的多模态预训练数据。
Doubao-1.5-pro 在多个视觉基准上的评测结果高效的原生动态分辨率训练:Doubao-1.5-pro 采用原生动态分辨率的架构设计,支持任意分辨率的图像输入。无论是高清大图还是低分辨率的小图,亦或是极端长宽比例的图像,模型都能实现精准的特征提取和高效的计算性能。比如视频中,这张超长尺寸的漫画图,Doubao-1.5-pro 依旧可精准识别图片信息并总结。领先的复杂指令遵循能力:通过系统性的原子能力拆解和多维度指令的逻辑组合,在后训练阶段引入了多样化的视觉指令数据,使 Doubao-1.5-pro 能从容应对指令更复杂的场景。多样化的数据合成管线:Doubao-1.5-pro 除了利用来自搜索引擎的海量图文对和图文交织数据对进行训练之外,还采用了基于渲染引擎、传统 CV 模型、模型自迭代等数据合成方式,以获得高质量的多模态预训练数据。文本与视觉混合的多模态能力:为同时保障模型的视觉和语言能力,团队在 VLM 多个训练阶段都混入了一定比例的纯文本数据,并通过动态调整学习率的方法平衡视觉与语言能力,使模型的语言能力无损。
语音多模态:
理解生成一体化,情商智商在线
在语音多模态方面,我们提出了全新的 Speech2Speech 端到端框架,不仅通过原生方法将语音和文本模态进行深度融合,同时还实现了语音对话中真正意义上的语音理解生成端到端,相比传统 ASR+LLM+TTS 的级联方式,在对话效果上有质的飞跃。
Doubao-1.5-pro 不仅拥有高理解力(高智商),还具备语音高表现力与高控制力,以及模型整体在回复内容和语音上的高情绪承接能力。
此外,在框架设计上,我们打破了语音和文本数据需要对齐的传统方法,将语音和文本 Token 进行融合,为语音多模态数据的 Scaling 提供了必要条件。
探索智能边界
Doubao 深度思考模式
推理能力是智能的重要组成部分,团队致力于使用大规模 RL 的方法不断提升模型的推理能力,拓宽当前模型的智能边界。在完全不使用其他模型数据的条件下,通过 RL 算法的突破和工程优化,充分发挥 Test Time Scaling 的算力优势,完成了 RL Scaling ,研发了 Doubao 深度思考模式。
 Doubao-1.5-pro-AS1-Preview 在 AIME 上的评测结果
Doubao-1.5-pro-AS1-Preview 在 AIME 上的评测结果目前,阶段性成果 Doubao-1.5-pro-AS1-Preview 在 AIME 上已经超过 O1-preview、O1 等推理模型。并且,随着 RL 的持续,模型能力还将不断提升。在这一过程中,我们也看到了推理能力在不同领域的泛化,智能的边界正在被慢慢拓宽。
 推理能力的初步泛化
推理能力的初步泛化向智能的无限可能出发
豆包大模型团队一直以探索智能的无尽边界、解锁通用智能的无限可能为目标。同时,我们认为探索智能的边界与服务用户和行业是一体的关系,两者可以彼此增益、双向驱动。接下来,团队会继续加强对大模型基础研究的投入,挑战更长周期的、具有颠覆性的通用智能研究课题

































 粤ICP备17114055号
粤ICP备17114055号