现有的信息检索(IR)模型通常假设一个同质化的格式,限制了它们对多样化用户需求的适用性,例如用文本描述搜索图像,用新闻标题图片搜索新闻文章,或用查询图像找到类似的图片。为了满足这些不同的信息检索需求,我们引入了UniIR,这是一个统一的、由指令引导的多模态检索器,能够处理跨模态的八种不同的检索任务。UniIR是一个单一的检索系统,联合训练了十个不同的多模态IR数据集,解释用户指令以执行各种检索任务,在现有数据集上展示了强大的性能,并对新任务进行了零样本泛化。我们的实验强调了多任务训练和指令调整是UniIR泛化能力的关键。此外,我们构建了M-BEIR,一个多模态检索基准,具有全面的结果,以标准化通用多模态信息检索的评估。
我们翻译解读最新论文:UniIR训练和基准测试通用多模态信息检索器,文末有论文链接。
 作者:张长旺,图源:旺知识
作者:张长旺,图源:旺知识
1. 引言
信息检索(IR)是一个关键任务,涉及从庞大的数据集中获取相关信息以满足特定用户需求[50]。随着生成性AI的出现,这一过程变得日益重要[3, 9, 49, 58],因为它不仅能够实现精确的归属,还能够减少生成内容中的不准确和伪造风险[2, 48]。尽管IR在当前技术格局中扮演着重要角色,但现有文献——特别是在多模态IR领域——大多范围狭窄,主要关注预定义格式的同质化检索场景,通常限于单一领域。例如,MSCOCO[35]考虑通过文本说明检索Flickr图像,而EDIS[39]考虑用新闻标题检索新闻头条图片。这种同质化设置不足以满足用户跨越领域和模态的多样化信息检索需求。例如,一些用户可能通过文本查询搜索网络图像,而其他用户可能使用一张裙子的照片以及文本输入“类似款式”或“红色”来寻找特定裙子的类似时尚产品。当前的多模态检索系统在容量上不足以满足这些多样化的用户需求,仅限于对预训练的CLIP[47]模型进行特定任务的微调。认识到这些局限性,迫切需要概念化和发展一个更灵活、通用的神经检索器,它能够连接不同的领域、模态和检索任务,以满足用户的多样化需求。
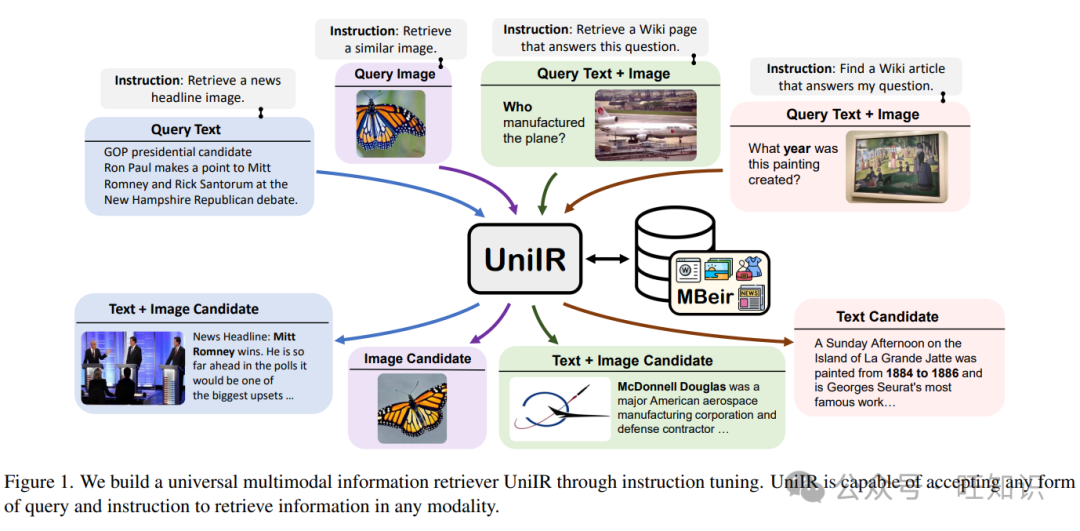 图1。我们通过指令调整构建了一个通用的多模态信息检索器UniIR。UniIR能够接受任何形式的查询和指令来检索任何模态的信息。
图1。我们通过指令调整构建了一个通用的多模态信息检索器UniIR。UniIR能够接受任何形式的查询和指令来检索任何模态的信息。
在这篇论文中,我们提出了UniIR框架,学习一个单一的检索器来完成(可能)任何检索任务。与传统的IR系统不同,UniIR需要遵循指令,以异构查询检索来自异构候选池中的数百万候选项。为了训练UniIR模型,我们构建了M-BEIR,一个基于现有10个不同数据集的指令遵循多模态检索任务的基准,统一了它们的查询和目标在一个统一的任务表述中。查询指令被策划以定义用户的检索意图,从而指导信息检索过程。我们在M-BEIR上的300K训练实例上训练了基于预训练视觉-语言模型如CLIP[47]和BLIP[33]的不同UniIR模型,并采用了不同的多模态融合机制(评分级融合和特征级融合)。我们展示了UniIR模型能够精确地遵循指令,从异构候选池中检索所需的目标。我们最好的UniIR模型是基于评分融合的CLIP,它不仅在微调数据集上取得了非常有竞争力的结果,而且还泛化到了保留的数据集(图6)。我们的消融研究揭示了两个洞见:(1)UniIR(BLIP)中的多任务训练是有益的,这在recall@5方面带来了+9.7的改进(表6);(2)指令调整对于帮助模型泛化到未见过的检索数据集至关重要,并在recall@5方面带来了+10的改进(图5)。
我们的贡献总结如下:
• UniIR框架:一个旨在将各种多模态检索任务整合到一个统一系统中的通用多模态信息检索框架。
• M-BEIR:一个大规模多模态检索基准,汇集了来自多个领域的10个不同数据集,涵盖了8种不同的多模态检索任务。
• 我们引入了在M-BEIR上训练的UniIR模型,为未来的研究设定了一个基础基线。此外,我们评估了SOTA视觉-语言预训练模型在M-BEIR基准上的零样本性能。
2. UniIR框架
2.1. 问题定义
在通用多模态搜索引擎中,用户可以根据特定需求启动各种搜索任务。这些任务涉及不同类型的查询和检索候选项。查询q可以是文本qt、图像qi或甚至是图像-文本对(qi, qt),而检索候选项c也可以是文本ct、图像ci或图像-文本对(ci, ct)。在表1中定义了八种现有的检索任务。请注意,组合查询(qi, qt)通常涉及一个关于图像qi的基于文本的问题qt。另一方面,组合目标(ci, ct)通常包括一个图像ci,伴随着描述性文本ct,提供上下文信息。为了适应不同的检索意图,我们引入了一个语言任务指令qinst来代表检索任务的意图。这个指令清晰地定义了搜索的目标,无论是寻找图像、文本还是两者的混合,并指定了相关领域。更多信息可以在第3节中找到。更正式地说,我们的目标是构建一个统一的检索器模型f,能够接受任何类型的查询来检索由指令qinst指定的任何类型的目標:
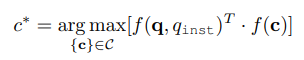
这里,C表示异构候选池,f(·)是我们正在优化的最大点积检索函数,c∗是预测结果。通过包含任务指令,我们将不同的多模态检索任务统一到一个单一框架中,从而使我们能够构建一个通用的多模态检索器。此外,通过指令微调的语言模型已经展示了通过遵循指令执行零样本泛化到未见任务的能力。然而,将这种零样本泛化的概念应用于多模态检索领域面临着挑战,因为缺乏为此目的量身定制的现有数据集。为了解决这一差距,我们创建了一个全面的、统一的数据集,名为MBEIR,详细内容见第3节。M-BEIR将作为探索和推进多模态检索模型能力的基凊资源。
2.2. UniIR模型
在这一节中,我们介绍了UniIR模型,我们的统一多模态信息检索系统。UniIR模型擅长同时处理不同的检索任务。我们为UniIR实验了两种多模态融合机制,即评分级融合和特征级融合。为了探索这些方法的有效性,我们适应了像CLIP[47]和BLIP[33]这样的预训练模型,如下所示。
评分级融合。如图2(a)所示,CLIP和BLIP的评分级融合变体(分别表示为CLIPSF和BLIPSF)使用不同的编码器进行视觉和文本处理。具体来说,视觉编码器被标记为fi,单模态文本编码器为ft。在这些方法中,图像和文本输入(无论是来自查询还是目标)被处理成两个单独的向量。这些向量经过加权和以形成一个统一的表示向量。这个过程在数学上表示为f(qi, qt, qinst) = w1fI(qi) + w2fT (qt, qinst)用于查询,f(ci, ct) = w3fI(ci) + w4fT (c)用于目标。因此,查询q和目标c之间的相似性分数被计算为模态内和跨模态相似性分数的加权和:
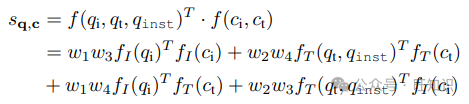
w1, w2, w3, w4是一组可学习的参数,反映了重要性权重。
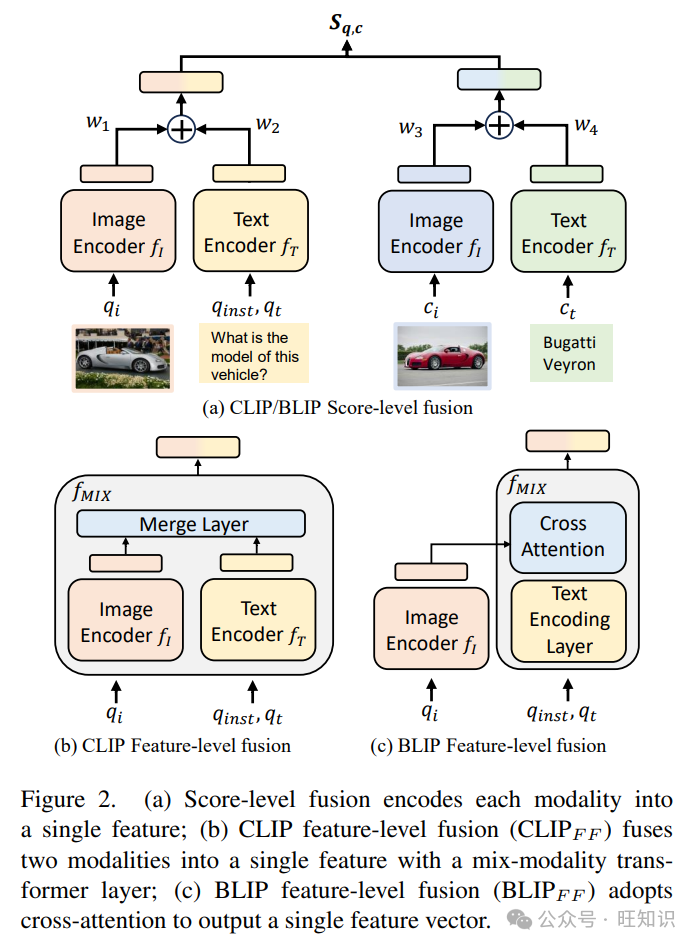
特征级融合。与分别处理单峰数据的方法不同,特征级融合在编码阶段集成特征。这种融合方法使用混合模态注意力层计算多模态查询或候选者的统一特征向量。如图2(b)所示,对于CLIP特征级融合(CLIPFF),我们增强了预训练的视觉编码器fI和文本编码器fT,增加了一个2层多模态变换器,其架构与T5相同,形成了混合模态编码器fMIX。在BLIP特征级融合(BLIPFF)的情况下,过程从通过视觉编码器fI提取图像嵌入开始。这些嵌入然后通过BLIP的图像基础文本编码器的交叉注意力层与文本嵌入集成,也标记为fMIX。在CLIPFF和BLIPFF中,查询和目标的最终表示,分别表示为fMIX(qi, qt, qinst)和fMIX(ci, ct),是分别获得的,但使用相同的fMIX。然后通过以下方式计算查询和目标之间的相似性分数:
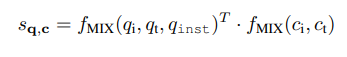
我们在M-BEIR训练数据上微调了上述四种模型变体(详细见第3节),采用查询-目标对比目标。为了遵循统一的指令调整格式,将指令qinst作为前缀集成到文本查询qt中。见图3中的例子。我们为缺少图像或文本模态的查询或候选项输入填充令牌。

3. M-BEIR基准
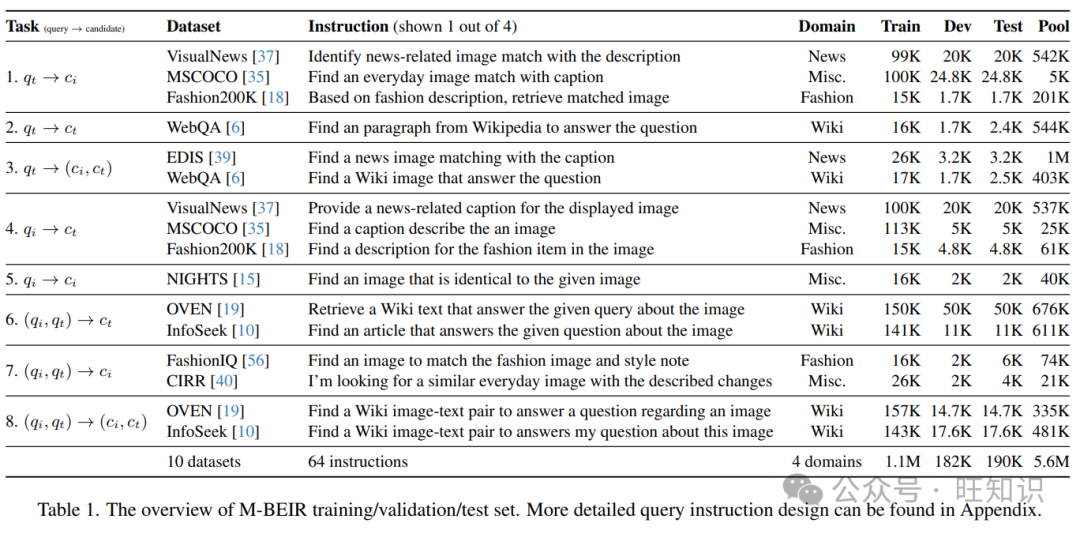
为了训练和评估统一的多模态检索模型,我们构建了一个名为M-BEIR(多模态指令检索基准)的大规模检索基准。M-BEIR基准包括八个多模态检索任务和十个来自不同领域和图像源的数据集。每个任务都伴随着人类编写的指令,总共包含150万个查询和560万个检索候选池(见表1)。
3.1. 数据格式
为了统一多模态检索任务,这些任务由源查询和目标候选者中的不同模态组成,M-BEIR中的每个任务都包括查询Q = {q1, q2, ...},一组候选者C = {c1, c2, ...},其中q和c都支持文本和图像模态,并且提供了人类编写的指令qinst以指定检索任务的意图。M-BEIR数据集中的每个查询实例都包括一个查询q,一个指令qinst,一系列相关(正面)候选数据c+和一系列可能可用的不相关(负面)候选数据c−。见图3中的例子。每个M-BEIR查询实例至少有一个正面候选数据,可能没有负面候选数据。我们的默认检索设置是模型需要从所有不同模态和领域的异构候选池中检索正候选者。
3.2. 数据集收集
M-BEIR基准涵盖了各种领域:日常图像、时尚物品、维基百科条目和新闻文章。它通过利用各种数据集,整合了8个多模态检索任务。数据选择。为了构建一个统一的指令调整多模态检索模型和全面的评估基准,我们旨在涵盖广泛的多模态任务、领域和数据集。这些包括以检索为重点的数据集(OVEN[19], EDIS[39], CIRR[40]和FashionIQ[56]),图像-标题数据集(MS-COCO[35], Fashion200K[18], VisualNews[37]),图像相似性测量数据集(NIGHTS[15]),以及基于检索的VQA数据集(InfoSeek[10], WebQA[6])。这些数据集原本为不同目的设计,但在M-BEIR基准中有效地被重新用作检索任务。对于图像-标题数据集,我们按照MS-COCO的方式重新利用图像-标题对作为检索任务。对于其他数据集,我们采用原始查询,并使用注释的黄金候选者作为正面候选者c+和注释的困难负面作为不相关候选者c−。我们还采用了提供的候选池。总的来说,M-BEIR涵盖了8种不同的多模态检索任务和4个领域,拥有一个全球候选池,共有560万候选者。见表3的完整数据集列表。为确保基准数据的平衡,我们从较大的数据集如VisualNews、OVEN和InfoSeek中修剪了候选池和实例,这些数据集原本包含100万到600万实例,显著大于其他数据集。为了方便训练、验证和测试,我们使用每个数据集的原始数据集拆分。如果数据集只发布验证集,我们将一部分训练数据保留用于验证,并在原始验证集上报告结果。否则,我们使用测试集报告结果。有关数据处理的更多详细信息,请参阅附录。
指令注释指南。指令调整成功的一个关键组成部分是指定任务意图的多样化指令[12, 55]。为了设计多模态检索任务的指令,我们从TART[1]的指令模式中获得灵感。我们的M-BEIR指令通过意图、领域、查询模态和目标候选模态来描述一个多模态检索任务。具体来说,意图描述了检索资源与查询的关系。领域定义了目标候选者的预期资源,例如维基百科或时尚产品。对于像Fashion200K[18]这样的文本到图像检索数据集,我们的指令将是:“基于以下时尚描述,检索最佳匹配的图像。”更多例子见表1和图3。按照指令注释指南,我们为每个检索任务的每个查询编写了4个指令。完整的指令列表在附录表9和表10中。
3.3. 评估指标
我们遵循标准检索评估指标,即在MSCOCO上报告的recall@k,并为所有数据集报告结果。具体来说,我们遵循CLIP[47]/BLIP[33]在MSCOCO上的召回实现,如果检索到的实例与相关实例重叠,则将其计为正确。我们主要报告所有数据集的Recall@5,除了Fashion200K和FashionIQ,按照先前的工作[56]报告Recall@10。完整的Recall@1/5/10结果可以在附录表11中找到。
4. 实验
在我们的实验中,我们评估了各种多模态检索模型在M-BEIR数据集上的性能,利用了预训练的视觉-语言变换器模型。我们使用了公开可用的检查点,如表2所列。我们的评估包括SoTA模型、微调基线和UniIR模型(详细见第2节),在两种检索场景下:(1)从M-BEIR 560万候选池中检索,该候选池由所有任务的检索语料库组成,以及(2)从原始数据集提供的特定任务池(同质候选者)中检索,这使我们能够与现有的SoTA检索器进行公平比较。我们将这个特定任务池称为M-BEIRlocal。检索过程包括两个步骤。首先,我们提取了池中所有查询和候选者的多模态特征向量。然后,我们使用FAISS[26],一个强大的库,用于在密集向量空间中进行高效的相似性搜索,进行索引和检索候选者。
4.1. 基线
零样本SoTA检索器。我们使用像CLIP (L-14)[47]、SigLIP (L)[59]、BLIP (L) [33]和BLIP2 [34]这样的预训练视觉-语言模型作为我们的基线特征提取器。问题是,这些模型无法理解检索任务的意图,因为输入只是查询q,因此,它们在标准设置(1)中从异构候选池中检索查询信息的表现预计会很差。我们不使用q指令,因为我们发现这甚至会降低零样本检索性能。
单/多任务微调基线。我们将CLIP和BLIP作为我们的单任务基线检索器在特定数据集上进行微调。我们还对所有M-BEIR训练数据上的CLIP和BLIP进行了联合微调,没有纳入指令作为我们的多任务基线检索器。模型只接受q和c作为输入,使用查询-目标对比训练目标来最大化正对相似度,同时最小化负对相似度。
实现细节。对于所有CLIP和BLIP变体,我们使用最大的检查点,即ViT-L14 [14]。默认图像分辨率为224×224,除非另有说明。我们使用105的批处理大小用于CLIP变体,115用于BLIP变体。我们采用其他超参数,如原始实现中报告的。对于评分融合方法,我们默认设置w1 = w2 = w3 = w4 = 1。我们所有的实验都在一个节点上进行,有8个H100 GPU。更多细节可以在附录中找到。
4.2. 实验结果
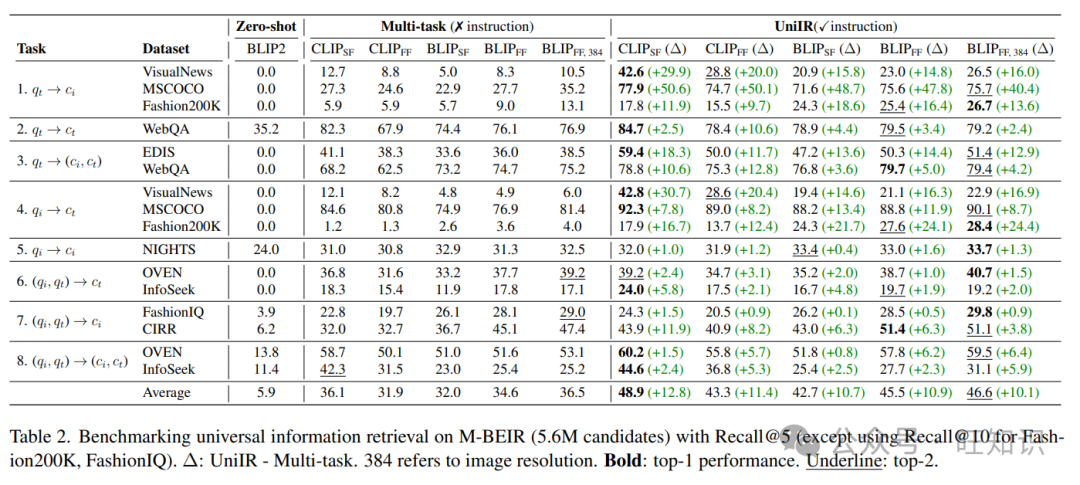
我们在表2中报告了M-BEIR上的主要结果,模型从560万池中检索候选者。我们展示了零样本模型在这样一个异构池中检索查询信息的困难。我们在表3中展示了指令调整作为一个关键组成部分,并在表5中展示了多模态特征融合架构设计洞见。此外,我们还在M-BEIR上进行了实验,以了解UniIR的零样本泛化能力,我们训练了UniIR模型和多任务基线模型在一部分数据集上,并在保留的测试集上对其进行评估,这使得UniIR与其他零样本检索器相当具有可比性。

零样本检索器无法理解检索意图。我们首先对四个开源的跨模态嵌入模型进行了基准测试,发现大多数任务的召回值接近零。为了证明这一点,我们在表2中提供了BLIP2的一个例子。这些预训练模型在没有指令的指导下,很难理解任务意图。例如,在MSCOCO上的文本到图像检索任务中,所有零样本模型都从全局池中检索文本实例,导致召回率为0%。这是预期的结果,因为当查询和候选者来自同一模态时,相似性分数往往更高。此外,我们观察到,例如表2中的BLIP2,零样本模型无法有效地融合模态,当检索候选者是图像-文本对而不是文本片段时,WebQA的召回率从35.2%下降到0%。在图4中,我们展示了BLIP2在EDIS查询中从错误模态检索分心候选者的例子。
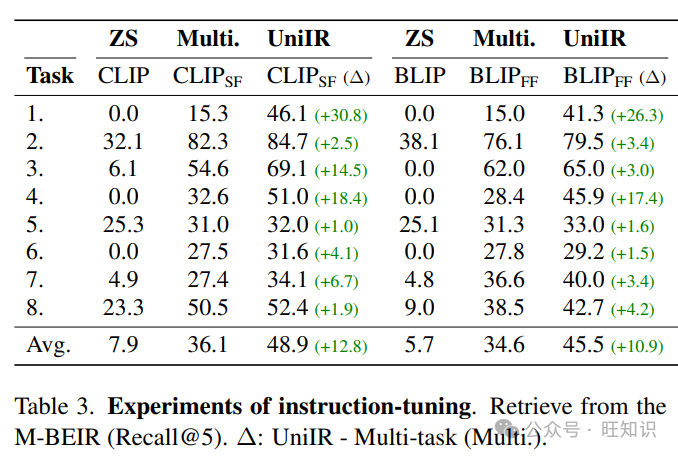
表3. 在M-BEIR上进行指令调整实验(Recall@5)。∆:UniIR - 多任务(Multi.)。
指令调整提高了M-BEIR上的检索。为了理解指令调整在UniIR中的好处,我们在表3中比较了UniIR与多任务微调基线。尽管具有相同的架构,UniIR模型在M-BEIR上的表现显著优于基线,平均Recall@5提高了12.8和10.9。我们还发现最大的改进观察到在跨模态检索任务1和3中。没有指令,多任务基线很难理解任务意图,倾向于从与查询相同模态的候选者中检索。然而,指令调整并没有显著改进模态内检索任务2和5,因为这些任务不需要嵌入模型来理解意图。UniIR能够精确地遵循指令。为了进一步证明UniIR优于多任务微调基线,我们对检索错误进行了分析,错误被分为三类:模态错误、领域错误和其他错误。结果如表4所示。多任务模型在从全局池中检索具有错误模态的实例方面的错误率高达58.8%和50.9%。然而,通过指令微调,UniIR模型成功地学会了检索意图模态,将错误率显著降低到2.7%和15.2%。在图4中,我们展示了零样本、多任务和UniIR模型在EDIS查询上的前5个检索候选者的可视化例子。具体来说,零样本模型(BLIP2)和多任务模型(CLIPSF)大多从错误模态(ct)检索分心候选者,而UniIR(CLIPSF)从正确的模态(ci, ct)检索所有正面候选者。附录中有更多例子。
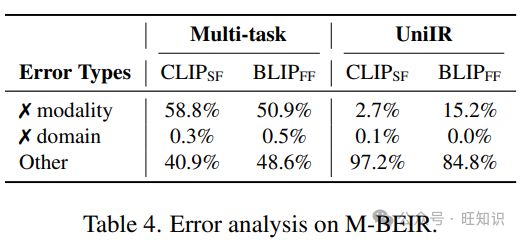
表4. M-BEIR上的错误分析。
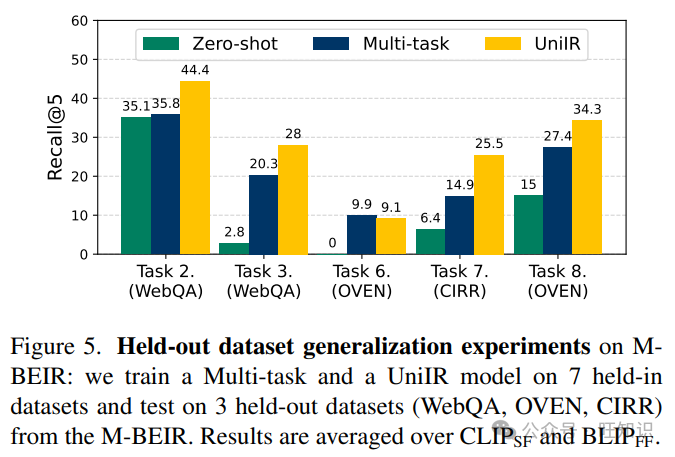
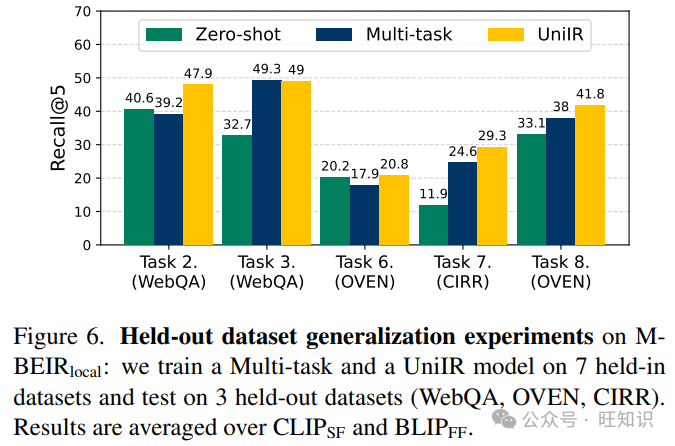
UniIR可以泛化到未见过的检索任务。在UniIR的多任务微调阶段,我们排除了三个数据集(WebQA, OVEN, CIRR),并在其余的M-BEIR数据集上训练了UniIR模型和多任务基线模型。在M-BEIR全局池上的测试时,我们评估了所有微调模型的零样本性能,以及SoTA预训练检索器(CLIP和BLIP)在三个保留的数据集上的性能。在图5中,我们比较了SoTA(CLIP和BLIP)检索器的平均性能,多任务微调基线的平均性能(Multi-task)和UniIR(CLIPSF)和UniIR(BLIPFF)的平均性能。我们的结果表明两个主要发现。首先,UniIR模型在保留数据集上的零样本评估中以显著的优势超过了SoTA检索器基线。其次,我们证明了结合指令调整的UniIR模型在未见任务和数据集上展现出比没有指令的多任务对应物更优越的泛化能力。
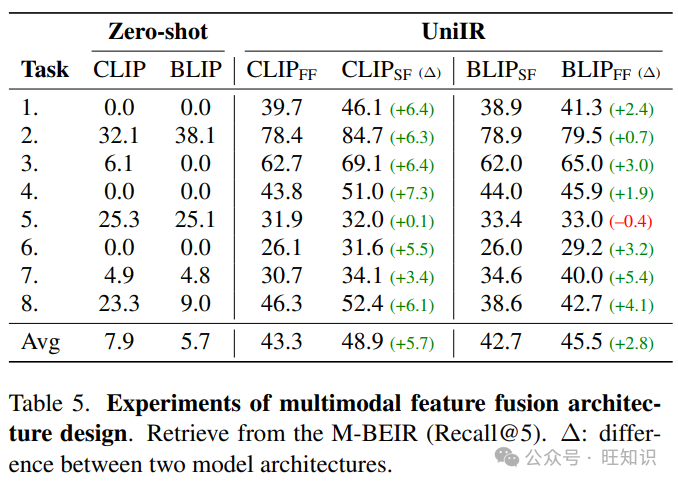
与预训练模型架构保持一致。在表5中,我们比较了评分融合和特征融合之间的融合架构设计,其中评分融合是CLIP模型(即CLIPSF)的原生融合,特征融合是BLIP与其预训练的交叉注意力变换器编码器(即BLIPFF)的原生融合。通过遵循预训练架构设计,我们展示了微调UniIR模型在每个任务上获得了更高的Recall@5分数,平均改进了5.7和2.8。此外,避免在微调期间添加随机初始化的层,例如CLIPFF中使用的T5混合模态层。这些层没有预训练,可能会导致过拟合——特别是对于像OVEN/InfoSeek(任务8)这样的任务。CLIPFF和CLIPSF在任务8中的比较揭示了性能的显著下降,从52.4降低到46.3。
4.3. 与现有方法的比较
为了将UniIR与现有的检索器进行比较,我们还评估了同质设置,其中检索器只需要从特定任务池中检索,这更符合传统的IR设置。此外,我们进行了保留实验,以检查UniIR在与基线模型相比的M-BEIRlocal上的零样本泛化能力。
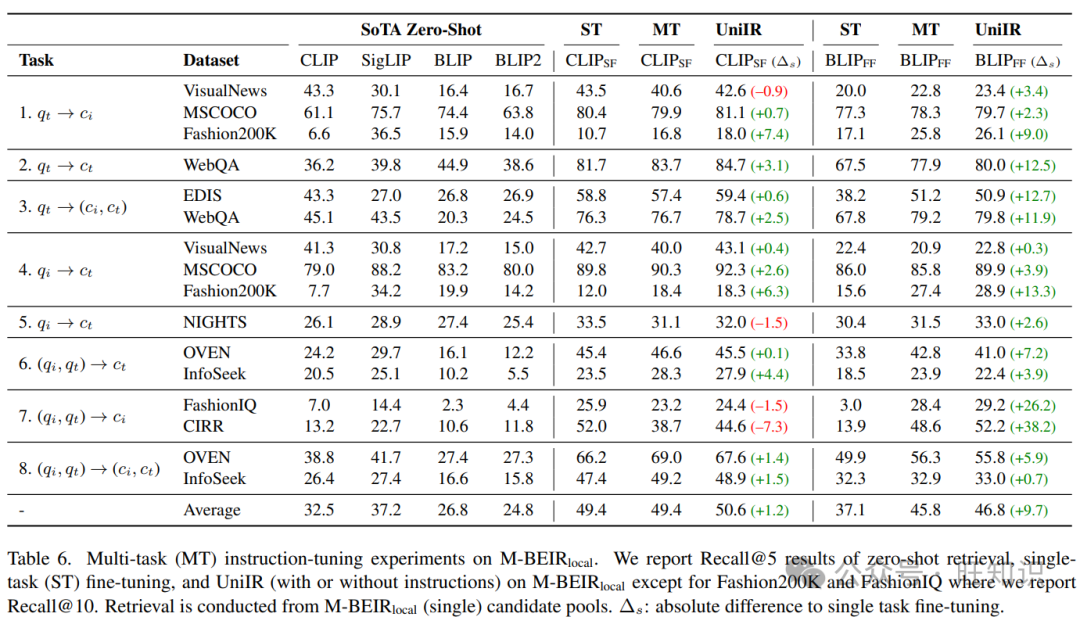
UniIR与零样本检索器。在表6中,我们展示了虽然SigLIP以平均值37.2%在R@5上获得了零样本SoTA检索器中的最高平均值,我们的UniIR模型(CLIPSF)和(BLIPFF)以显著的优势超过了它,平均R@5值分别为50.6%和46.8%。
UniIR与单任务调整。表6表明了多任务指令调整在UniIR框架中优于单任务微调。我们的发现表明,UniIR(BLIPFF)在R@5上大大超过了其单任务对应物,平均提高了9.7%,并且在任务7组合图像检索(如CIRR)上有显著改进,为48.6%,而13.9%。UniIR(CLIPSF)也表现出总体改进了1.2%,特别是在Fashion200K和Infoseek上。相比之下,我们观察到没有使用指令的多任务训练在平均上不会有这样的改进,如CLIPSF保持在49.4%。
在保留数据集和任务上的泛化性能。在图6中,我们展示了SoTA CLIP和BLIP检索器的平均零样本性能,多任务微调基线的平均零样本性能,以及在三个保留的数据集上UniIR(CLIPSF)和UniIR(BLIPFF)的平均零样本性能。UniIR模型在三个保留数据集上的5个任务中持续优于SoTA检索器和多任务训练基线。另一方面,没有使用指令的多任务训练在WebQA(任务2)和OVEN(任务6)等任务上的表现甚至比SoTA检索器基线更差。
5. 相关工作
多模态信息检索。近年来,跨模态信息检索领域得到了显著的探索,特别强调图像到文本的匹配。MSCOCO[27]和Flickr30k[46]等数据集已成为评估预训练视觉-语言模型如ALIGN[25]、VILT[28]、ALBEF[32]、MURAL[24]和ImageBind[16]进展的标准基准。然而,细粒度图像检索往往依赖于通过文本表达意图的能力,这在多模态查询[7]如ReMuQ[42]中提出了挑战。虽然文本到文本检索基准BEIR[52]推进了构建通用零样本文本检索系统的研究,但一个涵盖广泛任务的统一多模态信息检索基准仍然缺失。我们希望M-BEIR的引入将加速向更通用的多模态信息检索模型的进展。
检索增强模型。检索增强在过去几年中得到了广泛的研究。ORQA[29]、RAELM[17]、RAG[30]和FID[22]是最早学习检索器和语言模型联合从弱监督数据集中学习的工作之一。后来,RETRO[4]将检索增强训练扩展到大规模语言模型,以相对较小的语言模型展示了巨大的性能提升。ATLAS[23]进一步将检索增强训练的理念扩展到少样本学习,并在更广泛的知识密集型任务上展示了性能提升。这些工作主要集中在检索文本段落以增强语言模型。后来,RAC3M[58]、REVEAL[20]和MuRAG[8]展示了从Wikipedia检索多模态内容以回答视觉信息寻求问题的优势。多模态增强理念也应用于图像生成,如KNN-diffusion[49]、Re-imagen[9]和RA-diffusion[3]。与我们工作最接近的是TART[1],它也旨在构建一个单一的检索器,根据指令检索不同内容。然而,TART仍然只关注文本到文本模态。
指令调整。指令调整模型,即模型被训练以遵循用户指令,已成为大型语言模型(LLMs)[11, 44, 53]研究的一个重要领域。FLAN和FLAN-T5[12, 55]展示了能够泛化到未见自然语言任务[43]的能力,InstructGPT[45]进一步说明了指令调整如何使语言模型更紧密地与用户的意图对齐。最近,视觉指令调整在视觉-语言任务中得到了探索,如视觉问题回答模型如InstructBLIP[13]和LLaVA[38]或数据集如MultiInstruct[57]。在图像扩散模型中,InstructPix2Pix[5]和MagicBrush[60]数据集展示了扩散模型如何遵循指令编辑图像。然而,与我们工作最相关的检索增强模型,如InstructRETRO[54]、RA-DIT[36]以及嵌入模型如OneEmbedder[51]和TART[1],仍然是纯文本的。相比之下,UniIR展示了在多模态检索中跨数据集泛化的前景,表明了集成到多模态LLMs的潜在进展。
6. 结论
我们介绍了UniIR,一个构建通用多模态信息检索模型的框架。该框架使一个统一的检索器能够遵循自然语言指令,并完成不同模态的各种信息检索任务。我们构建了M-BEIR基准,以支持UniIR模型的训练和评估。我们展示了我们提出的指令调整流程能够在不同的检索任务和领域中很好地泛化。然而,现有模型的性能仍然相对不完美,表明未来有很大的改进空间。我们认为,具有更强视觉-语言骨干模型的大规模预训练算法可以为缩小这一差距奠定基础,我们将这一方向留给未来的探索。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
