在传统的RAG框架中,基本的检索单元通常是短的。像DPR这样的常见检索器通常使用100个词的维基百科段落。这样的设计迫使检索器在大型语料库中搜索“针”单元。相比之下,阅读器只需要从这些短的检索单元中提取答案。这种不平衡的“重”检索器和“轻”阅读器设计可能导致次优性能。为了缓解这种不平衡,我们提出了一个新的框架LongRAG,由一个“长检索器”和一个“长阅读器”组成。LongRAG将整个维基百科处理成4K个词的单元,比以前长30倍。通过增加单元大小,我们将总单元数从2200万减少到60万。这显著降低了检索器的负担,从而显著提高了检索得分:在NQ上的答案召回率@1达到了71%(之前是52%),在HotpotQA(全维基)上的答案召回率@2达到了72%(之前是47%)。然后我们将前k个检索单元(约30K个词)输入到现有的长上下文LLM中,以零样本方式执行答案提取。无需任何训练,LongRAG在NQ上达到了62.7%的EM,在HotpotQA(全维基)上达到了64.3%的EM,这与(完全训练的)最先进模型相当。我们的研究为将RAG与长上下文LLMs结合的未来路线图提供了见解。
1 引言
检索增强型生成(RAG)方法长期以来一直被用来增强大型语言模型(LLMs)。通过利用来自外部语料库的独立检索组件,可以将知识以自然语言的形式完全从LLMs的参数知识中卸载出来。现有的RAG框架倾向于使用短检索单元,例如在流行的开放域问答任务中的100个词段落。检索器的任务是在具有数千万信息单元的庞大语料库中找到“针”(即精确的检索单元)。然后,检索到的单元被传递给阅读器以生成最终响应。相反,阅读器只需要从这些检索中提取答案,这是一项相当简单的任务。这种不平衡的设计,具有“重”检索器和“轻”阅读器,给检索器带来了太多压力。因此,现有的RAG模型不得不回忆大量的单元,例如前100/200个,结合额外的重新排名器以获得最佳性能。此外,短检索单元可能导致由于文档截断而语义不完整。这可能导致信息丢失,最终损害最终性能。这种设计选择是在NLP模型受到处理长上下文能力严重限制的时代做出的。随着长上下文语言模型的最近进展,检索器和阅读器潜在地可以处理高达128K甚至数百万的词作为输入。在本文中,我们提议重新审视开放域问答的设计选择,并提出LongRAG框架作为平衡检索器和阅读器工作量的解决方案。
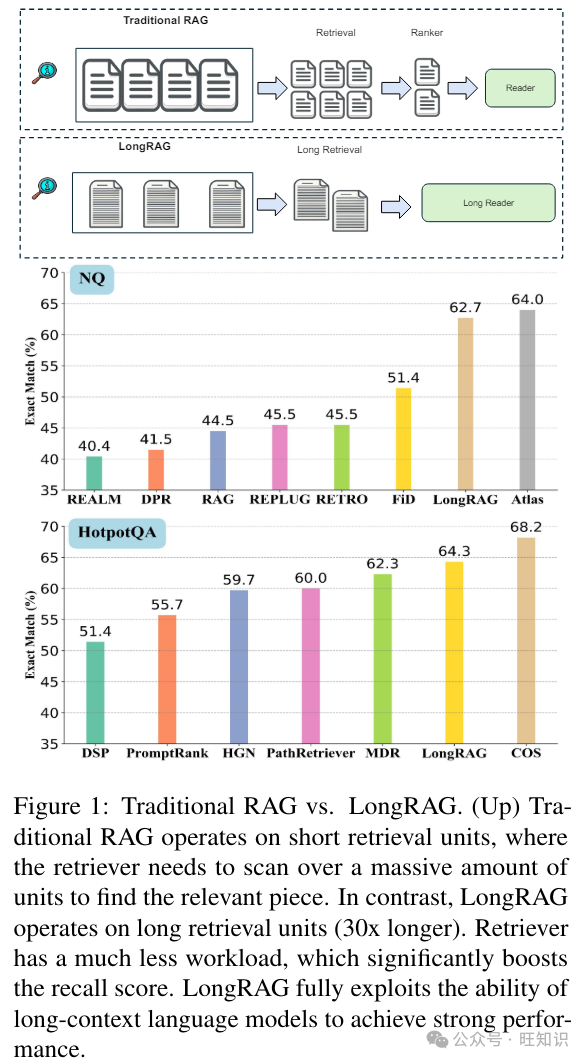
在本文中,我们建议重新审视开放域问题解答的这一设计选择,并提出 LongRAG 框架作为平衡检索器和阅读器之间工作量的解决方案,如图 1 所示。我们的新框架有三个重要设计:
1. 长检索单元:通过使用整个维基百科文档或对多个相关文档进行分组,我们可以构建超过 4K 标记的长检索单元。这种设计还可以大大减少语料库的大小(语料库中检索单元的数量)。这样,检索者的任务就会变得更容易,信息也更完整。
2. 长检索器:长检索器将通过搜索语料库中的所有长检索单元来识别与给定查询相关的粗略信息。只有排名前 4 至 8 位的检索单元(未重新排序)才会被用于下一步。
3. 长阅读器:长文本阅读器将进一步从检索串联中提取答案,检索串联通常约有 30K 标记。我们只需向现有的长语境 LM(如 Gemini 或 GPT4)提示问题,就能以 "0-shot "的方式生成答案。
2 相关工作
2.1 检索增强型生成
通过从大型语料库检索信息来增强语言模型已成为一种流行且有效的方法,特别是对于知识密集型任务,特别是开放域问答。主要架构遵循检索器-阅读器风格,其中输入查询从语料库中检索信息,语言模型使用这些信息作为额外的上下文来进行最终预测。最近的工作集中在改进检索器、增强阅读器、联合微调检索器和阅读器,以及将检索器与黑盒语言模型集成。然而,文档粒度对检索增强型生成流程的有效性和效率的影响仍未被充分探索。
2.2 长上下文大型语言模型
基于Transformer的模型的有效性受到处理长上下文输入时计算成本相对于序列长度的二次增加的限制。为了解决这个问题,已经提出了不同的方法来缓解计算问题,包括滑动记忆窗口和块分割。FlashAttention也是减少内存占用至几乎与序列长度成线性关系的关键策略。为了实现长度外推,RoPE和AliBI位置编码已显示出潜力,使文献中的使用广泛。此外,还探索了处理长输入的替代架构。这些不同的方法声称它们可以提高LLMs处理长上下文输入的能力。
2.3 长上下文嵌入
最近的努力还增加了嵌入模型的上下文长度,将支持的文本片段长度从512个词的限制扩展到32k个词。通常,长上下文嵌入模型的发展涉及首先获得一个长上下文骨干模型。这可以通过从头开始使用长输入进行预训练,或通过使用支持更长上下文的现有大型语言模型来实现。此外,一些工作通过将LLM内容窗口扩展方法应用于嵌入模型,或采用状态空间编码器模型来扩展现有嵌入模型处理长上下文的能力。
3 LongRAG
我们提出的LongRAG框架由两个组件组成:长检索器和长阅读器。这两个组件的示例如图2所示。
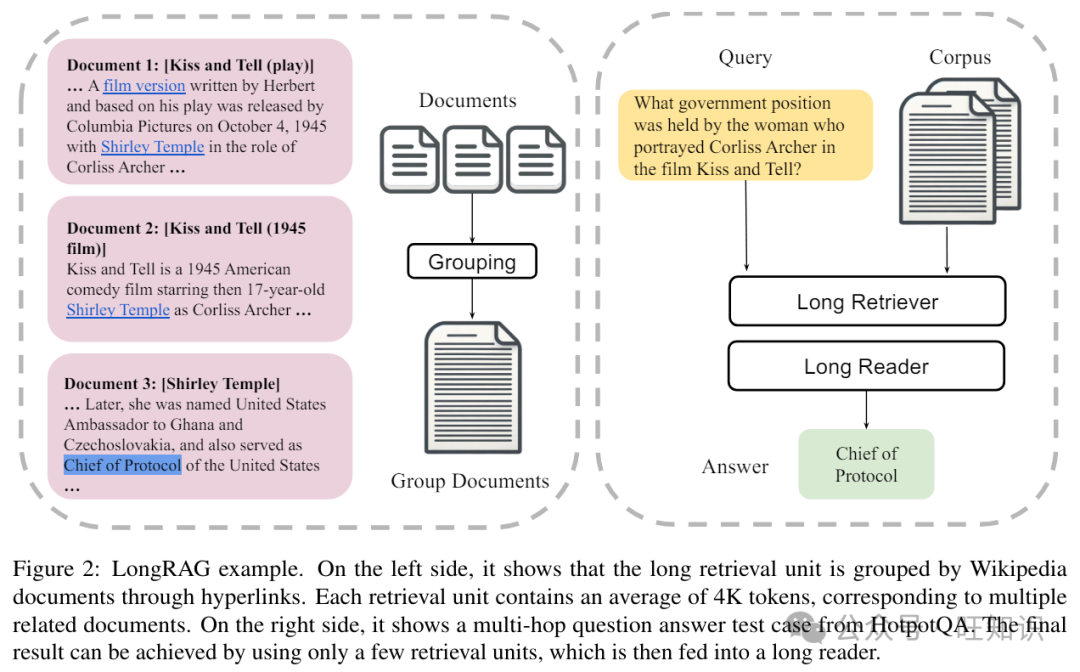
3.1 长检索器
传统的RAG框架采用较小的检索单元,并优先检索包含答案的确切细粒度短上下文。相比之下,我们提出的LongRAG框架更强调召回率,旨在以更粗糙的粒度检索相关上下文。这种设计选择将更多的负担从检索器转移到阅读器,以从相关上下文中提取确切答案。我们将检索语料库表示为C = {d1, d2, ..., dD},这是D个文档的集合。严格来说,长上下文检索器是一个函数:F : (q, C) → CF,它以问题q和语料库C作为输入,并返回C的一个过滤后的文本集CF ⊂ C。在传统的RAG中,CF通常很小,包含大约一百个词,应该包含与问题q相关的确切信息。在我们的框架中,CF通常超过4K个词,包含与问题q相关但不确切的信息。然后,长检索器函数F : (q, C)被分为三个步骤:
a. 形成长检索单元。
一个函数应用于语料库以形成M个检索单元:G(C) = {g1, g2, ..., gM}。在传统的RAG中,检索单元g通常是从文档d中分割出来的短段落,包含数百个词。在我们的框架中,g可以长至整个文档甚至一组文档,从而产生更长的检索单元。我们根据它们之间的关系对文档进行分组,使用每个文档中嵌入的超链接。分组算法显示在算法1中。输出的组是彼此相关的文档列表。通过拥有更长的检索单元,有两个优势:首先,它确保了每个检索单元的语义完整性;其次,它为需要来自多个文档信息的任务提供了更丰富的上下文。
b. 相似性搜索。
我们使用一个编码器,记为EQ(·),将输入问题映射到d维向量。此外,我们使用一个不同的编码器,记为EC(·),将检索单元映射到d维向量。我们使用它们的向量的点积定义问题和检索单元之间的相似性:
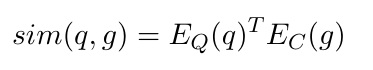
在LongRAG设置中,由于g的长度,EC(g)是具有挑战性的,因此我们采用以下近似。
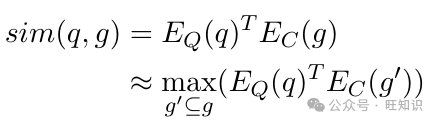
我们通过最大化检索单元g内所有块g′的分数来近似它,类似于Dai和Callan(2019)中的MaxP设计。我们考虑了不同的粒度级别,包括段落级别、文档级别和完整的分组文档。关于这些设置的实证研究在表3中。有了这个相似性分数设置,我们将检索与给定查询最接近的前k个检索单元。为了有效的检索,我们预计算每个检索单元g′的嵌入,并预测FAISS(Johnson等人,2019)中的确切内积搜索索引。
c. 聚合检索结果。
我们将前k个检索单元连接成长上下文作为检索结果,记为CF = Concat(g1, g2, ..., gk)。根据检索单元的选择,较大的检索单元大小将导致使用较小的k值。例如,如果检索单元是段落,k大约是100;如果是文档,k大约是10;对于分组文档作为检索单元,我们通常将k设置为4到8。

3.2 长阅读器
长阅读器的操作很直接。我们将相关指令i、问题q和长检索结果CF输入到LLM中,使其能够在长上下文中进行推理并生成最终输出。重要的是,用于长阅读器的LLM能够处理长上下文,并且不表现出过度的位置偏差。我们选择Gemini1.5-Pro(Reid等人,2024)和GPT-4o(OpenAI,2024)作为我们的长阅读器,因为它们处理长上下文输入的能力强。我们对短上下文和长上下文使用不同的方法。对于短上下文,通常包含少于1K个词,我们指示阅读器直接从检索到的语料库中提供的上下文中提取答案。对于
长上下文,通常长于4K个词,我们的经验发现,使用与短上下文相似的提示,其中模型直接从长上下文中提取最终答案,通常会导致性能下降。相反,最有效的方法是使用LLM作为聊天模型。最初,它输出一个长答案,通常跨越几个词到几句话。随后,我们提示它通过从长答案中进一步提取来生成一个短答案。附录6.1中提供了提示。
4 实验
在这一部分,我们将首先详细介绍我们采用的数据集,然后展示检索器性能。最后,我们将展示最终的问答性能。
4.1 数据
我们提出的方法在两个与Wikipedia相关的问答数据集上进行了测试:Natural Questions和HotpotQA。
Natural Questions(Kwiatkowski等人,2019)旨在进行端到端的问答。这些问题是从真实的Google搜索查询中挖掘出来的,答案是由注释者在Wikipedia文章中确定的跨度。该数据集包含3610个问题。
HotpotQA(Yang等人,2018)包含不同主题的两跳问题。我们专注于全Wikipedia设置,需要两个Wikipedia段落来回答这些问题。由于测试集的金标准段落不可用,我们遵循先前的工作(Xiong等人,2020b)并在开发集上进行评估,该开发集有7405个问题。HotpotQA中有两种主要问题类型:(1)比较问题通常需要对比两个实体;(2)桥接问题可以通过跟随连接一个文档到另一个文档的连接实体来回答。
Wikipedia(知识源)我们按照先前的工作(Lewis等人,2020;Yang等人,2018)为不同的数据集使用不同版本的英文Wikipedia。对于NQ,我们使用2018年12月20日的Wikipedia转储,其中包含大约300万份文档和2200万个段落。对于HotpotQA,我们使用2017年10月1日转储的摘要段落,其中包含约500万份文档。对于每个页面,只提取纯文本,并从文档中剥离所有结构化数据部分,如列表、表格和图表。
4.2 检索性能
指标检索性能使用答案召回(AR)和召回(R)来衡量。对于NQ,我们只使用答案召回,而对于HotpotQA,我们使用两个指标。答案召回是所有检索到的文档中答案字符串的召回,我们计划在阅读器中使用这些文档。例如,如果检索单元在“段落”级别,检索单元的数量是100,答案召回衡量这100个段落中是否存在答案字符串。对于HotpotQA,我们仅针对具有跨度答案的问题计算AR,特别是“桥接”类型的问题,而忽略是/否和比较问题,遵循先前的工作(Khalifa等人,2022)。召回用于衡量两个金标文档是否出现在所有检索结果中。例如,如果检索单元在“文档”级别,检索单元的数量是10,召回衡量这两个金标文档是否出现在检索到的10个文档中。
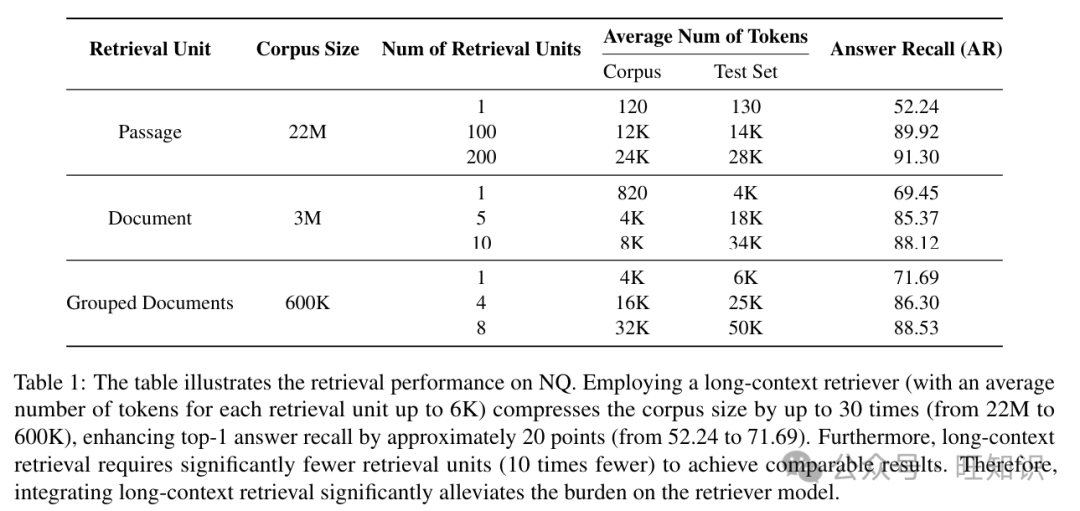
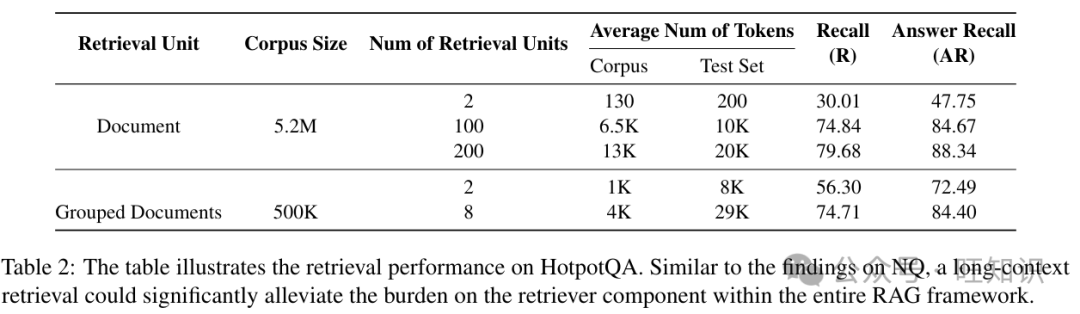
实验设置我们利用开源密集检索工具包Tevatron(Gao等人,2022)进行所有检索实验。我们使用的基嵌入模型是bge-large-en-v1.5,这是一个通用嵌入模型,没有专门针对我们的测试数据进行训练。表1和表2显示了在NQ和HotpotQA上的检索结果。在NQ数据集中,我们使用了三种不同的检索单元,从短到长:段落、文档和分组文档。在表中,我们提到了每种检索单元中每个测试案例的平均词数:一个针对整个语料库,一个针对每个测试集。每个测试案例的检索单元有时可能比整个语料库中的平均大得多,因为语料库可能包括一些字数非常少的Wikipedia页面,而测试案例可能更侧重于更长的文档。通常,我们的长上下文检索器(在文档级别和分组文档级别)使用平均包含6K词的检索单元。通过使用更长的检索单元,有几个优点:1)它将显著减轻检索器的负担,将语料库大小压缩大约30倍,从22M减少到600K。顶级1的答案召回提高了约20个百分点,从52.24提高到71.69。我们可以使用显著较少的检索单元来实现相当的检索性能。例如,在分组文档级别上的8个检索单元可以实现与在段落级别上的100个检索单元相似的召回。2)它可以为阅读器提供更全面的信息。在原始的段落级RAG设置中,由于分块操作,信息可能不完整。在HotpotQA数据集中,我们观察到类似的结果。一个值得注意的区别是,在HotpotQA中,检索单元仅在文档级别和分组文档级别,因为HotpotQA只使用每个Wikipedia页面的摘要段落。

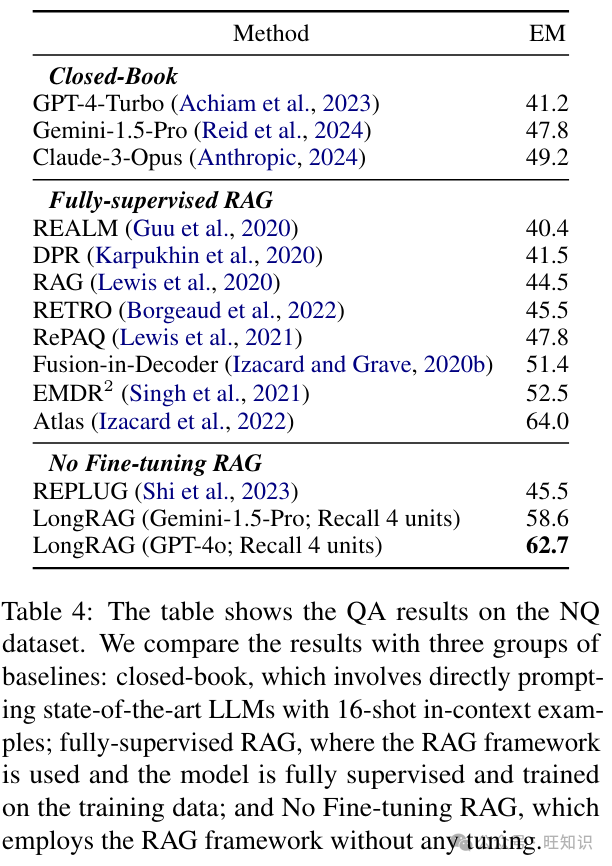
对长检索单元进行编码如第3.2节所讨论的,当g非常长时,使用编码器EC(·)将检索单元g映射到d维向量非常具有挑战性。因此,我们在提出的系统中使用了一个近似。表3演示了我们的近似,sim(q, g) = EQ(q)T EC(g) ≈ maxg′⊆g(EQ(q)T EC(g′)),比直接使用长嵌入模型对整个长上下文进行编码更有效。我们比较了三种方法:1)使用通用嵌入模型“bge-large-en-v1.5”(Xiao等人,2023),将g′选为512个词大小的文本。2)使用长嵌入模型“E5-Mistral-7B”(Zhu等人,2024a),将g′选为整个文档,平均大小为4K个词。3)使用长嵌入模型“E5-Mistral-7B”,不使用近似,直接编码整个g,其中g的平均大小为6K个词。我们可以从表中注意到,通过在查询和长上下文中的每个文本片段之间取最大分数来近似,比直接编码长嵌入模型产生更好的结果。

5 结论
在本文中,我们提出了一个新的框架LongRAG,以缓解检索器的负担不平衡。LongRAG框架由“长检索器”和“长阅读器”组件组成,位于4K个词的检索单元之上。我们提出的框架可以显著减少语料库大小10到30倍,这极大地提高了检索器的召回率。另一方面,长检索单元保留了每个文档的语义完整性。我们在端到端问答任务上测试了我们的框架,并展示了其无需任何训练即可实现的优越性能。我们相信LongRAG可以为现代RAG系统设计铺平道路。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
