
































 粤ICP备17114055号
粤ICP备17114055号
微信扫码
添加专属顾问
我要投稿
私有化部署Dify平台,开启AI应用开发的新纪元。 核心内容: 1. Dify平台介绍及其开源大语言模型应用开发优势 2. LLMOps概念解析及其在Dify中的应用实践 3. Dify如何助力企业集成LLM并探索其能力边界
什么是Dify
Dify是⼀款开源的⼤语⾔模型(LLM) 应⽤开发平台,它融合了后端即服务 Backend as Service 和 LLMOps 的理念,使开发者可以快速搭建⽣产级的⽣成式 AI 应⽤;即使是⾮技术⼈员,也能参与到 AI 应⽤的定义和数据运营过程中来。
什么是LLMOps
LLMOps(Large Language Model Operations)是⼀个涵盖了⼤型语⾔模型开发、部署、维护和优化的⼀整套实践和流程。⽬的是确保安全、⾼效、可扩展地使⽤这些强⼤的 AI 模型来 构建和运⾏实际应⽤程序。
Dify 能做什么
Dify 内置了构建 LLM 应⽤所需的关键技术栈,包括对数百个模型的⽀持、直观的 Prompt 编排界⾯、⾼质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了⼀套易⽤的界⾯和 API,这为开发者节省了许多重复造轮⼦的时间,使其可以专注在创新和业务需 求上。我们可以把 LangChain 这类的开发库想象为有着锤⼦、钉⼦的⼯具箱。与之相⽐, Dify 提供了更接近业务需求的全套⽅案,Dify 好⽐是⼀套脚⼿架,并且经过了精良的⼯程设计和软件测试。
将 LLM 集成⾄已有业务:通过引⼊ LLM 增强现有应⽤的能⼒,接⼊ Dify 的 RESTful API 从⽽实现 Prompt 与业务代码的解耦,在 Dify 的管理界⾯可实现跟踪数据、成本和⽤量并持续改进应⽤效果 作为企业级 LLM 基础设施:⼀些银⾏和⼤型互联⽹公司正在将 Dify 部署为企业内的 LLM ⽹关,加速 Gen AI 技术在企业内的推⼴,并实现中⼼化的监管 探索 LLM 的能⼒边界:通过 Dify 也可以轻松的实践 Prompt ⼯程、RAG、 AI Agent,工作流。 |
Dify的优势
在使⽤ LLMOps 平台如 Dify 之前,基于 LLM 开发应⽤的过程可能会⾮常繁琐和耗时。开发者需要⾃⾏处理各个阶段的任务,这可能导致效率低下、难以扩展和安全性问题
数据准备:⼿动收集和预处理数据,可能涉及到复杂的数据清洗和标注⼯作,需要编写较多代码。
Prompt Engineering:缺乏实时反馈和可视化调试。
嵌⼊和上下⽂管理:⼿动处理⻓上下⽂的嵌⼊和存储,难以优化和扩展,需要不少编程⼯作,熟悉模型嵌⼊和向量数据库等技术。
应⽤监控与维护:需要⼿动收集和分析性能数据,可能⽆法实时发现和处理问题。
模型微调:⾃⾏处理微调数据准备和训练过程,可能导致效率低下,需要编写更多代码。
系统和运营:需要技术⼈员参与或花费成本开发管理后台,增加开发和维护成本,缺乏多⼈协同和对⾮技术⼈员的友好⽀持。
引⼊ Dify 这样LLMOps 平台后,基于 LLM 开发应⽤的过程将变得更加安全、⾼效,使⽤ 像 Dify 这样的 LLMOps 进⾏应⽤开发的优势体现在以下⼏个⽅⾯:
|
使用Dify和不使用Dify的开发差别
Dify的平台
在线的平台:https://cloud.dify.ai/apps
开源离线部署的平台:https://github.com/langgenius/dify

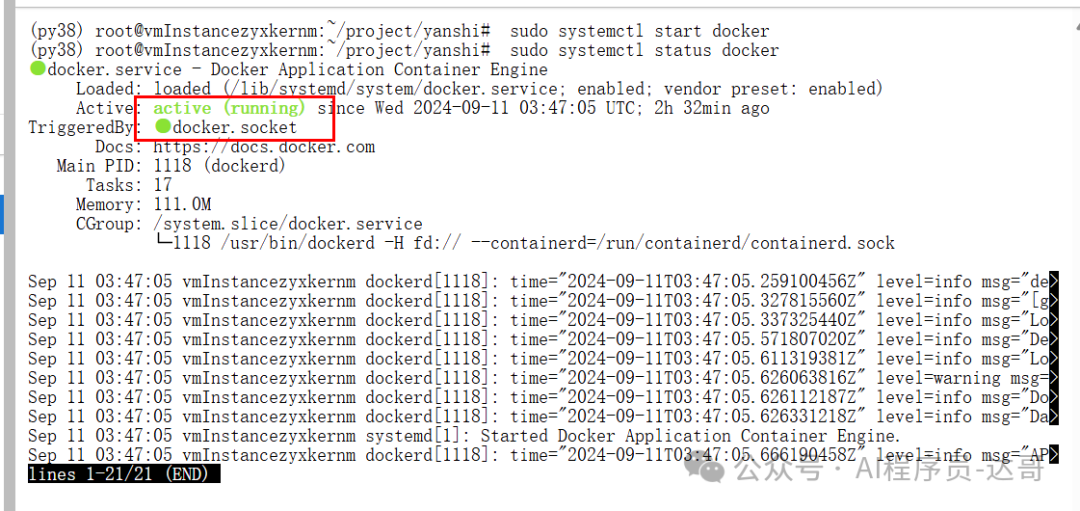
看到running状态说明docker已经正常启动
补充:centos7系统的Docker部署方案
概述 相较于传统的通过虚拟机技术实现的虚拟化⽅案来说,Docker是⼀种更加轻量级的虚拟化解决⽅案。具有易安装、易维护、启动速度快能够更好的实现开发项⽬的持续集成与持续部署,受到⼴⼤技术爱好者的⻘睐。在本⽂中使⽤的Linux发⾏版为CentOS,安装Docker的基本要求如下: 1. docker运⾏在x86_64位CPU架构的服务器中 2. 若将docker部署在Linux系统上,建议系统内核版本为3.10以上 3. Linux内核需开启cgroups与namespace功能 4. 推荐使⽤的存储引擎类型为overlay2 观察以下命令输出mount | grep cgroup ls -1 /proc/*/ns/
1.查看系统CPU架构,输出的信息中标记x86_64即为64位操作系统。 2.查看系统内核版本 根据输出信息可知,当前系统的内核版本为3.10.0-327.el7.x86_64,当前系统满⾜安装 docker服务的基本要求 3.关闭防⽕墙与selinux 4.如果在你的系统中曾经安装过docker,请先将其删除。 yum在线安装docker-ce
2. 下载REPO⽂件,实现通过YUM形式安装docker-ce 注意:如果使⽤的是docker官⽅的仓库配置,建议将repo配置⽂件中默认的docker-ce下载 源download.docker.com更改为国内的清华⼤学源,将会得到更快的下载速度。在本例中已 经使⽤aliyun源,所以本步骤可以不⽤操作 3. 开始安装 在本⼿册中,安装了在⼿册撰写时最新版本的docker版本为20.10.6 4.启动docker-ce服务,并配置开机启动 代理服务 通过以上步骤成功安装 docker-ce后,由于国内的⽹络原因⽆法直接从docker-hub拉取镜像,需要为docker-ce服务添加代理服务器配置
/usr/lib/systemd/system/docker.service 2. 添加代理服务器配置 注:代理服务器地址端⼝因⼈⽽异,不可盲⽬照搬 3. 启动服务 |

下载源码
2. 使用docker启动Dify
发现执行错误
修改方式:
进入/etc/docker/daemon.json文件
然后在里面加入下面的配置
修改完了以后重新执行命令:docker compose up -d
当涉及到⼤规模语⾔模型(LLMs)的管理、部署和使⽤时,使⽤像 Ollama 、 XInference和 LocalAI 这些模型管理⼯具可以显著提升模型的可管理性,提⾼⼯作效率。
Ollama
Ollama 是⽤于私有化部署和运⾏⼤型语⾔模型的⼯具,⽀持 通义千问、⼩⽺驼 等多种模型,私有化部署使⽤户没有⽹络连接的情况下也能使⽤这些先进的⼈⼯智能模型; ollama还提供了模型库⽅便⽤户从中下载和运⾏各种模型;使⽤ ollama 开发者只需使⽤简单的命令即可实现与模型的交互。
ollama网站地址:https://ollama.com/
我们在Linux平台,所以使用如下命令即可完成部署:
curl -fsSL https://ollama.com/install.sh | sh
去查看可以部署哪些模型
接入Qwen2.5开源模型
地址:https://ollama.com/library
## 执行命令
OLLAMA_HOST=127.0.0.1:8891 ollama run qwen2.5:7b
ollama的常见命令:
我们看一下目前,有ollama管理了哪些模型:
OLLAMA_HOST=127.0.0.1:8891 ollama list
接入DeepSeek R1模型
OLLAMA_HOST=127.0.0.1:8891 ollama run deepseek-r1:7b
检查一下模型:
OLLAMA_HOST=127.0.0.1:8891 ollama list
xinference 是⼀个强⼤且通⽤的分布式推理框架,也可以⽤于私有化部署和运⾏⼤语⾔模型,通过 xinference 可以简化各种AI模型的运⾏和集成,使开发者可以使⽤任何开源⼤语⾔模型、推理模型、多模态模型在云端或本地环境中运⾏、推理,创建强⼤的AI应⽤。
步骤1:创建虚拟环境 创建一个环境conda create -n Xinference python=3.10.14 激活环境conda activate Xinference 步骤2:配置清华源 python -m pip install --upgrade pip pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 步骤3:使用清华源进行升级 python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip 步骤4:安装所有依赖 直接执行pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "xinference[all]" 步骤5:验证torch是否可以用 python -c "import torch; print(torch.cuda.is_available())" 如果报错,缺什么依赖就根据提示安装什么依赖即可 步骤6:安装torch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch 错误解决: 可能会遇到在安装"xinference[all]"的时候出现什么Llama.cpp的包下载不下来的问题,这里你就别再折腾了,直接到官网下载whl文件,然后通过本地安装的方式就可以! **Llama.cpp地址:**https://github.com/abetlen/llama-cpp-python/releases 版本有很多,看报错信息需要哪个版本 cp310是python版本3.10别搞错了,本文安装的是这个:llama_cpp_python-0.2.88-cp310-cp310-linux_x86_64.whl 假设llama_cpp_python-0.2.88-cp310-cp310-linux_x86_64.whl在当前目录下pip install llama_cpp_python-0.2.88-cp310-cp310-linux_x86_64.whl 步骤7:启动服务 前台xinference-local --host 0.0.0.0 --port 8890 错误解决: 解决方案: apt-get install musl-dev sudo ln -s /usr/lib/x86_64-linux-musl/libc.so /usr/lib/libc.musl-x86_64.so.1 步骤8:重新启动: nohup xinference-local --host 0.0.0.0 --port 8890 & > output.log 步骤9:本地访问 本地访问地址:http://140.210.92.252:58313/ui/ |
我选择从huggingface上下载模型,需要配置HUGGING_FACE_HUB_TOKEN
huggingface地址:https://huggingface.co/
步骤1:查看ollama已经接入的模型
步骤2:测试模型是否能正常使用
OLLAMA_HOST=127.0.0.1:8891 ollama run qwen2.5:7b
步骤3:接入DIfy
步骤1:选择供应商
步骤2:选择模型类型
步骤3:填写模型信息
步骤4:成功接入
到模型供应商这儿,找到DeepSeek的模块
到DeepSeek的官网申请Key
DeepSeek官网地址:https://www.deepseek.com/
在Dify平台填入自己的Key即可使用
53AI,企业落地大模型首选服务商
产品:场景落地咨询+大模型应用平台+行业解决方案
承诺:免费场景POC验证,效果验证后签署服务协议。零风险落地应用大模型,已交付160+中大型企业
2025-04-19
Dify工作流→变量系统的结构化总结
2025-04-18
扣子也可以一键转化为 MCP Server 了
2025-04-18
Dify 工作流中的loop节点:原理、用法与典型场景
2025-04-17
别再造轮子了!Dify+MCP+DeepSeek开发实战保姆级教程,打造AI应用72变
2025-04-16
Dify 技术内幕:插件系统设计与实现详解
2025-04-15
从开发角度对比 dify 和 n8n:哪个更适合你?
2025-04-14
把任意Dify工作流变成MCP Server
2025-04-14
Dify 升级攻略:从0.15.3迈向1.1.0,元数据管理全攻略!
2024-12-24
2024-04-25
2024-07-16
2024-07-20
2024-04-24
2024-06-21
2024-05-08
2024-05-09
2024-08-06
2024-11-15
2025-04-15
2025-03-20
2024-12-19
2024-09-13
2024-09-13
2024-08-28
2024-04-24
回到顶部