推荐语
探索基于Ray的RLHF编程框架HybridFlow,字节跳动资深工程师亲授高效解决方案。
核心内容:
1. RLHF概念与训练流程解析
2. RLHF面临的挑战与动机
3. HybridFlow框架设计与实现细节
杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
导读 2024 年 12 月 6 日,由 Ray 中文社区、蚂蚁开源联合主办的 Ray Forward 2024 年度盛会在北京蚂蚁 T 空间成功举办。其中,字节跳动火山引擎资深研发工程师巫锡斌分享了《HybridFlow: 基于 Ray 构建灵活且高效的 RLHF 编程框架》。本文将分享 HybridFlow 编程框架,该框架基于 Ray 构建,旨在提供一个灵活且高效的 RLHF(Reinforcement Learning from Human Feedback)解决方案。
1. RLHF 是什么
2. RLHF 挑战与动机
3. HybridFlow 设计与实现
分享嘉宾|巫锡斌 字节跳动 火山引擎 资深研发工程师
编辑整理|菊
内容校对|李瑶
出品社区|DataFun
RLHF 是什么
1. LLM 训练流程

借用 Andrej Karpathy 在 Microsoft build 2023 上的大语言模型训练的图。
模型训练总体上分为四个阶段:预训练(Pre-training)、微调(Fine-tuning)、奖励建模(Reward Modeling)和强化学习训练(Reinforcement Learning Training)。
- 预训练阶段Pre-training)。从互联网收集大量数据,如维基百科、杂志、报纸和小说等,以拟合下一个 token。预训练的模型一般不可以直接用,如果和他对话,大概率会重复输入内容。
- 微调阶段(Fine-tuning)。即 SFT,收集多人对话和示范,以提升预训练模型的能力。微调后的模型即可部署使用。
今天重点介绍的是强化学习阶段,包括奖励建模和强化学习训练。
- 奖励建模阶段(Reward
Modeling)。比如同一个 prompt,可以收集多个输出,并由人类标注出好的、坏的,组成一个个 pair 对。收集到多个这样的 pair 后,就可以对奖励模型进行训练。
- 强化学习训练(Reinforcement
Learning Training)。有了奖励模型后,可以使用 PPO、DPO 等算法进行强化学习训练。这些算法的输入是 prompt。
2. 为什么需要 RLHF?

使用 RLHF 可以通过降低模型输出不正确或有害内容的概率,来提升模型输出符合人类偏好的概率。互联网上有海量的数据,通过预训练或者微调可以拟合下一个 token,也就是模型可以判断输出什么,但是没有负反馈来表达不应输出什么。例如,当询问 GPT 如何制造炸弹时,如果没有 RLHF,模型就会输出制造炸弹的步骤,而有了 RLHF 之后,模型就可以拒绝回答这类有害内容。
3. 如何将 LLM 训练表述为强化学习问题?

强化学习问题有五个要素:策略、状态、动作、环境和奖励,可以将大语言模型映射到这些概念上,即:
- 策略:LLM 模型,输入是状态,输出是所有可选的动作(token)的概率。
- 状态:用户输入的 prompt 和 LLM 已经解码出来的那部分内容的组合。
- 动作:模型输出的 token(动作空间即词表大小)。
- 环境:reward
model,输入是状态,输出是奖励分数 r。
- 奖励:reward
model 给出的评价分数,也可以看做是人类对当前模型输出的评价,是一个客观的值。
因此,LLM 接受一个 prompt,输出一个长度为 256 response 的过程,可视为智能体在环境中行动了 256 步,最终由 reward model 给出相应的奖励。基于以上表述,我们就可以利用 PPO 算法对策略(LLM)进行优化。
4. LLM PPO 算法流程
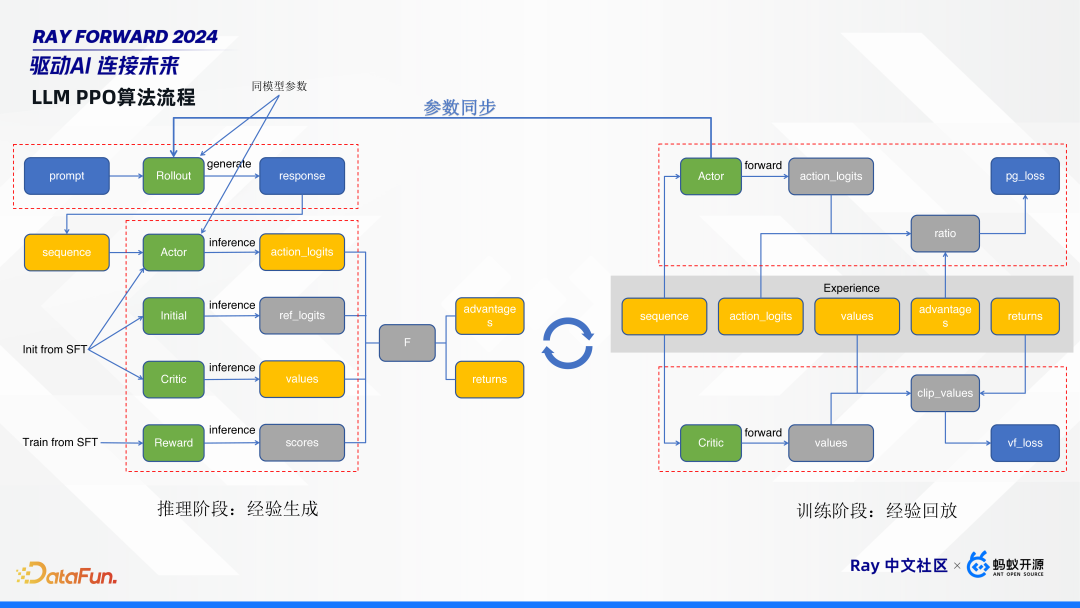
如上图,PPO 算法的工作流程分为推理阶段和训练阶段,推理阶段负责生成经验,训练阶段负责经验回放,这两个阶段交替进行。
左边推理阶段,给定一个 prompt,首先经过 rollout 模型生成 response。然后,将 prompt 和 response 拼成一个 sequence,这个 sequence 同时过 actor、initial、critic、 reward 4 个模型进行 inference,生成对应 logits、value、score。其中,actor、initial、critic 这三个模型是直接从微调模型SFT初始化的,reword 模型是从 SFT 训练出来的。这几个模型的作用是:
- initial 模型是一个参考模型,它是 freeze 的,不会用作训练;
- critic 和 reward 模型,是用来评判 actor 模型的;
- rollout 模型,它和 actor 模型是同参数的,也就是他们参数量完全一样,可以共享一份参数,也可以进行分离部署。rollout 模型是负责生成的,可以使用现在很多的推理框架来单独部署。
右边训练阶段,可以看到推理阶段生成的这些橙色框的内容,就是我们所说的经验。根据这经验五元组,来对 critic 和 actor 模型进行更新。
RLHF 算法整体比较复杂:多阶段,有推理有训练;多模型,有 5 个模型,甚至可能更多;框架中需要重点关注 actor 模型,它与 rollout 模型同参数,在训练完成后,要做参数同步,更新给推理阶段的 rollout 模型。
RLHF 的挑战与动机
RLHF 面临的挑战包括模型规模的增大、模型参数同步的耗时增加以及研究对灵活性的要求。大型模型的特点和新挑战使得我们难以直接将现有的强化学习框架应用于语言模型的 RLHF。
1. 现有的 RL 框架是否能用于 LLM RLHF?

Ray 里有一个传统的 RL 框架 Rlib,它可以直接用于大语言模型的 RLHF 吗?答案是可以,但是也不一定可以。
说可以是因为将大语言模型的强化学习训练,对齐到传统的强化学习的五要素中,都能映射上。如上图右边所示,gym.vector,有人或车走动,映射到 RL 就是一个自回归生成过程(Autoregressive Generation);奖励 reward,可以通过一个模型以及当前模型和初始模型的 KL 散度来计算。
说不可以是因为大语言模型的一些特点或者一些新的挑战,使得难以将 Rlib 应用于 RLHF。具体的挑战总结起来有三点。
2. 挑战 1:模型规模的增大
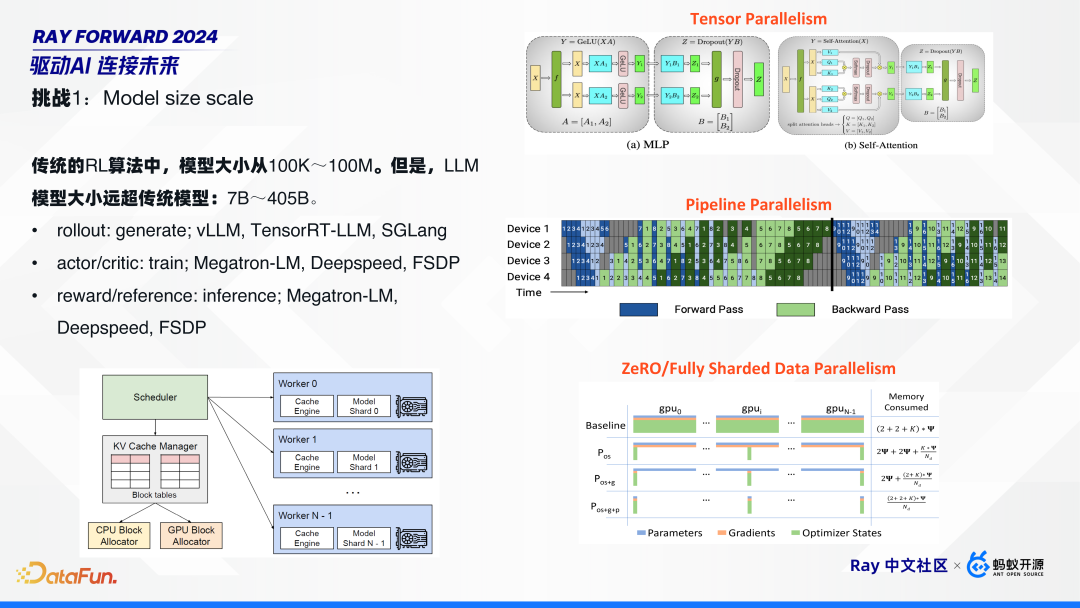
模型规模变大是最直观的一个挑战。传统的 RL 算法中,模型大小从 100K~100M。但是,LLM 模型大小远超传统模型:7B~405B。在这么大的模型规模下,对每一个计算点,都需要单独针对性地做优化。比如:
- rollout:用来做生成 generate,需要一些专门针对推理做优化的框架,如 vLLM、TensorRT-LLM、SGLang;
- actor/cirtic:用来进行训练的,需要针对训练的框架,如 Megatron-LM、Deepspeed、FSDP 等;
这样在这个算法中,需要用到若干种框架的组合:比如,推理时用 vLLM;训练时,大一点的模型用 TP、PP、DP 并行技术,也可以用 Deepspeed、FSDP 等更 native 的方式。
3. 挑战 2:模型参数同步的耗时增加
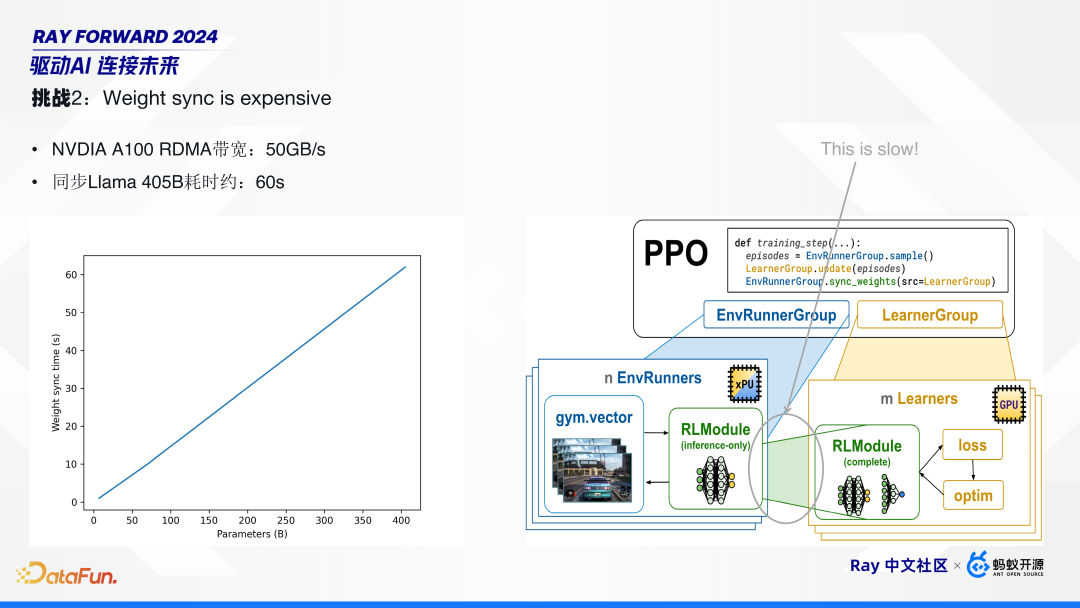
随着模型规模增大,模型参数的同步变得更加耗时。比如,英伟达 A100 显卡的跨机器的 RDMA 带宽可达 50GB/s,它同步一个 Llama 405B 耗时仍需 60 秒左右。这在 PPO 算法中,占比较高。在传统模型中,这个同步耗时可以忽略不计,但在大语言模型中,需要针对性优化。
4. 挑战 3:对灵活性的要求
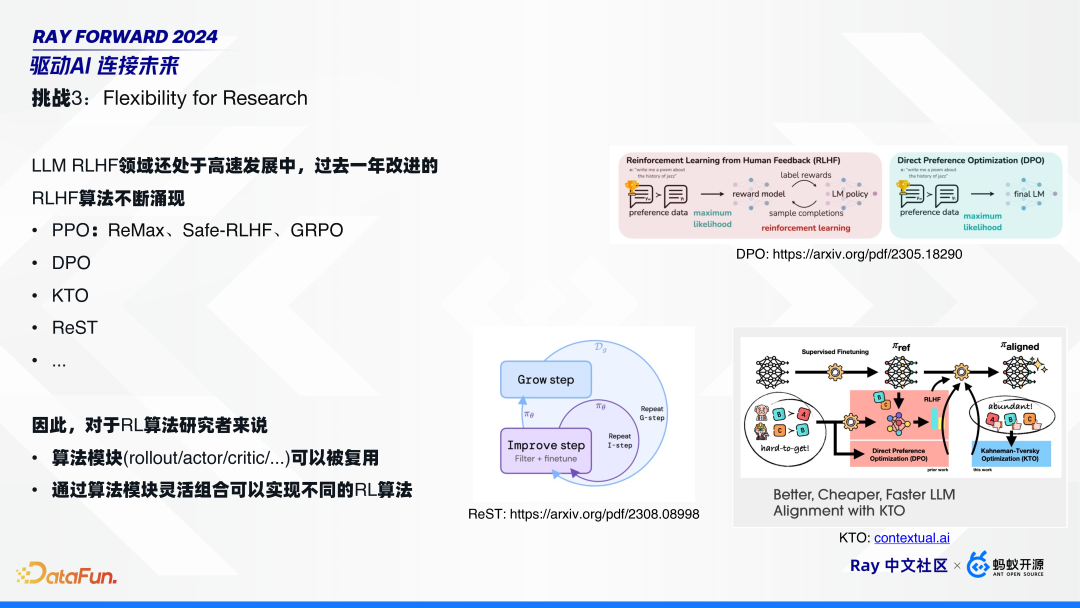
由于 LLM RLHF 领域还处于高速发展中,过去一年涌现了非常多的新算法,包括 PPO 算法的一些变种,比如 ReMax、Safe-RLHF、GRPO;还有针对 PPO 的改进,比如 DPO、KTO、ReST 等。其中,DPO 将 RLHF 简化成两个模型;KTO 更进一步,不需要有 pair 对;Google 提出的 Rest,进行模型自学习,而不需要外部奖励模型。
在这样的背景下,对于 RL 算法研究者来说,一个仅仅可以调整模型参数,喂数据进行训练的算法框架并不能满足需求。研究者需要一个编程框架,以支持实现各种不同的算法,也就是需要可以复用的算法模块,并通过算法模块灵活组合来实现不同的 RL 算法。
HybridFlow 设计与实现
HybridFlow 针对前文所述挑战进行了设计和实现。
1. HybridFlow 核心设计思想

在分布式系统中采用 Single-Controller 还是 Multi-Controller 是个重要命题。Google Pathways 在论文中对这两点做了非常详细的阐述。
Single-Controller 由一个中心控制器驱动所有 worker 工作,这个中心控制器向所有 worker 发送数据和计算指令,worker 可以运行不同的程序(MPMD)。它的优点是灵活、异构,即每个 worker 可以执行不同的算法;缺点是因为是单点控制,所以会引入额外的通信开销。
Multi-Controller 无中心控制器,各个 worker 自驱,各自计算,通过一些通信原语进行同步,worker 运行相同的程序(SPMD)。它的优点是高效;缺点是因为同构所以不够灵活。
典型的 Single-Controller,比如 Spark、TensorFlow1.0 的 non-SPMD 的模式。Multi-Controller 则更普遍,基本上主流的开源 RLHF 分布式训练框架,比如 Megatron-LM、Deepspeed、FSDP,以及 vLLM 都是 Multi-Controller 模式的。这是因为主流 RLHF 框架基本上是从预训练框架演进而来,而预训练基本上都是 Multi-Controller 模式。
那么,Multi-Controller 模式在处理 RLHF 的多模型的异构场景时,有哪些缺点呢?
首先,Multi-Controller 是 SPMD 模式的,所有 worker 运行相同的程序,这时推理和训练的框架以及工作流都不一样,要实现这样的 SPMD 算法难度就很高。
其次,灵活性不足。比如算法研究者想改一个算法,需要改每个模块中 3D 并行的策略,设计同步点。
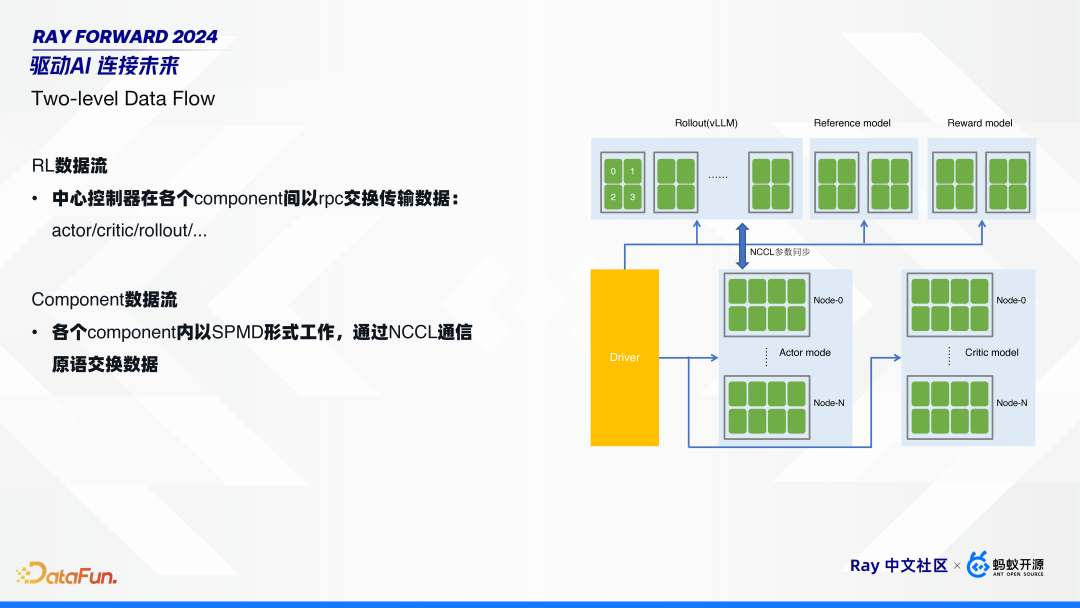
通过我们的观察分析,可以将 RL 的数据流拆成两部分:
第一部分是 RL 的数据流,就是在不同的组件间交换数据。如前文提到的,先在 rollout 模型做一些推理,拿到结果后,再把数据发送给其它 4 个模型做推理,然后再把经验给到训练侧的 actor 和 critic。
第二部分是组件内部的数据流。每个组件都是分布式的,组件内部是 SPMD 的工作模式,通过 NCCL 进行数据交换。
因为这样两层的数据流架构,所以我们将其命名为 HybridFlow,即通过 Single-Controller 实现 RL 的数据流,通过 Multi-Controller 实现各个组件的计算和通信流。

HybridFlow 对于各个组件,可复用已有框架,不用重复造轮子。比如,训练使用 Megatron-LM/Deepspeed/FSDP,推理使用 vLLM/TensorRT-LLM/SGLang。同时,通过组件的抽象和封装,使得 Single-Controller 可以像单进程一样去调用组件,而不需要关注组件内部的并行策略。
2. HybridFlow 实现

HybridFlow 的核心是 worker
group 的概念,它的本质是将一组 SPMD 进程进行抽象,使其可以像单进程一样被调用。
举例来说,如上图,用 Tensor 并行加数据并行来实现一个简单的 Transformer 的 FFN layer。假设 TP、DP 各 2 个:首先,在 DP 维度进行数据拆分,拆成 batch 0 和 batch 1。然后,在 DP group 内部,把相同数据发给所有的 rank。所有 worker 收到数据后,就进行推理。有结果后,再把数据聚合回来,也就是从每一个 DP 的 rank 0 去把数据取回。

Worker group 负责了数据分发(data dispatch)和聚合(data aggregation)两个重要功能。
如前文所介绍,第一层RL数据流是 Single-Controller 模式的,由 driver 进程去驱动所有的 worker group 工作。即数据的分发和聚合都在 driver 侧,通过 ray object store 来完成,并提供了简单的 dispatch
function 和 collect function。
根据整体测试的结果,在千卡集群下,ray object
store 基本可以满足要求。

HybridFlow 封装的一些组件接口如上图所示,包括 actor/rollout 的混合训练推理引擎,reward、reference 以及 critic 模型。
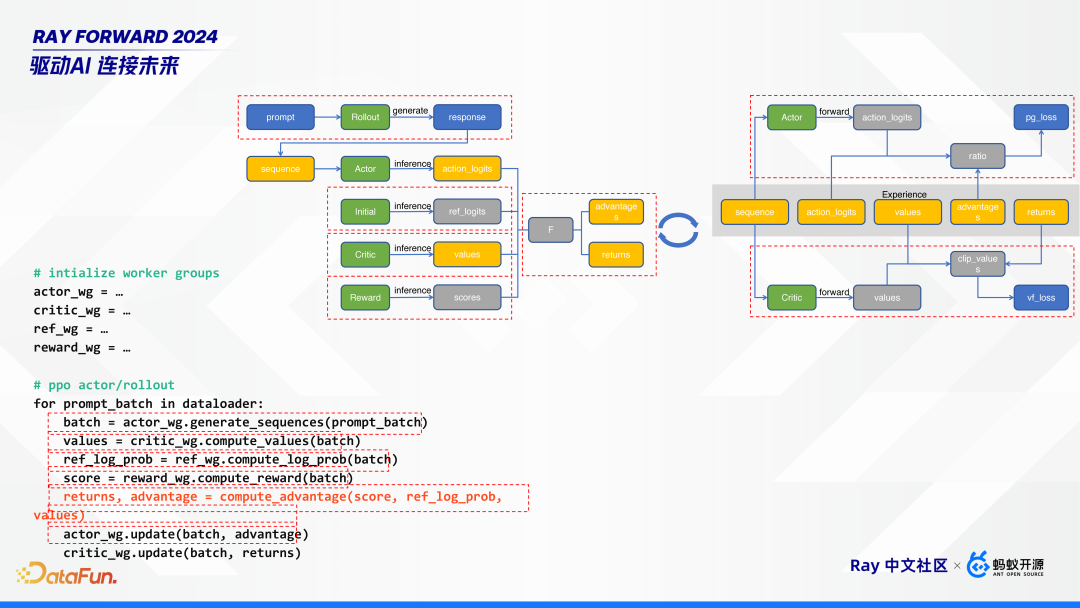
在 HybridFlow 框架基础上,实现 RLHF 算法就比较简单了。对每个模型,每个组件创建对应的 work group,共创建 4 个 group;然后,对于每个算法,调用对应 group 的接口,进行训练。
3. HybridFlow 优点

有了 HybridFlow 的框架和流程后,算法工程师再对算法做微调就比较简单了。上图右边展示了一个完整的 PPO 算法流程。当进行 PPO 算法变种时,只需要改其中一些步骤:比如 ReMax、GRPO 算法,不需要 critic 计算 advantages,把这行删掉就可以;Safe-RLHF 算法需要多个 reward 模型,增加对应的 group 就可以。

WorkerGroup 可以进行灵活组合,使用 Ray PlacementGroup 调度,通过设置 actor 的 placement_group、GPU 数量等,灵活控制 WorkerGroup 是否共享同一个 placement_group, 从而实现了不同 RLHF 组件逻辑隔离、物理共享,提高了资源利用率。
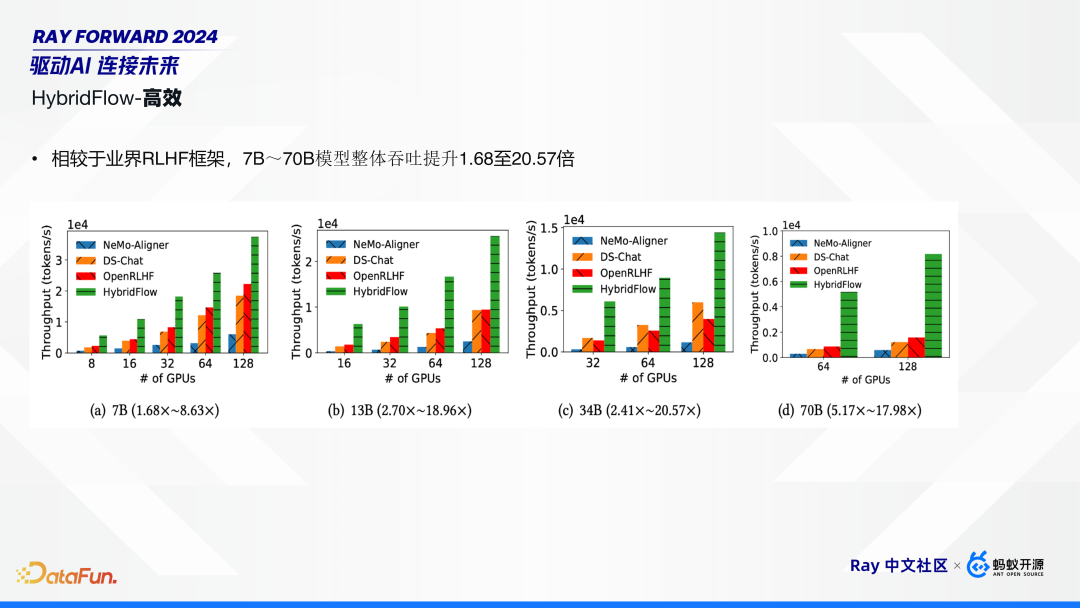
实验结果表明,相比业界其他 RLHF 框架(Deepspeed-Chat、OpenRLHF、Nemo-Aligner),HybridFlow 在 7B 到 70B,模型吞吐量提高了 1.6 倍到 20 倍不等。
我们的论文已被 USENIX ATC 2024 接收,代码已在 GitHub 上开源,欢迎大家关注。
- Paper:
https://arxiv.org/abs/2409.19256, EuroSys’ 25
- Github: https://github.com/volcengine/verl HybridFlow 在 GitHub 上开源项目名 veRL。

































 粤ICP备17114055号
粤ICP备17114055号