删除权重矩阵的一些行和列,让 LLAMA-2 70B 的参数量减少 25%,模型还能保持 99% 的零样本任务性能,同时计算效率大大提升。这就是微软 SliceGPT 的威力。
大型语言模型(LLM)通常拥有数十亿的参数,用了数万亿 token 的数据进行训练,这样的模型训练、部署成本都非常高。因此,人们经常用各种模型压缩技术来减少它们的计算需求。一般来讲,这些模型压缩技术可以分为四类:蒸馏、张量分解(包括低秩因式分解)、剪枝和量化。其中,剪枝方法已经存在了一段时间,但许多方法需要在剪枝后进行恢复微调(RFT)以保持性能,这使得整个过程成本高昂且难以扩展。为了解决这一问题,来自苏黎世联邦理工学院、微软的研究者提出了一个名为 SliceGPT 的方法。SliceGPT 的核心思想是删除权重矩阵中的行和列来降低网络的嵌入维数,同时保持模型性能。研究人员表示,有了 SliceGPT,他们只需几个小时就能使用单个 GPU 压缩大型模型,即使没有 RFT,也能在生成和下游任务中保持有竞争力的性能。目前,该论文已经被 ICLR 2024 接收。
- 论文标题:SLICEGPT: COMPRESS LARGE LANGUAGE MODELS BY DELETING ROWS AND COLUMNS
- 论文链接:https://arxiv.org/pdf/2401.15024.pdf
剪枝方法的工作原理是将 LLM 中权重矩阵的某些元素设置为零,并(选择性地)更新矩阵的周围元素以进行补偿。其结果是形成了一种稀疏模式,这意味着在神经网络前向传递所需的矩阵乘法中,可以跳过一些浮点运算。运算速度的相对提升取决于稀疏程度和稀疏模式:结构更合理的稀疏模式会带来更多的计算增益。与其他剪枝方法不同,SliceGPT 会剪掉(切掉!)权重矩阵的整行或整列。在切之前,他们会对网络进行一次转换,使预测结果保持不变,但允许剪切过程带来轻微的影响。结果是权重矩阵变小了,神经网络块之间传递的信号也变小了:他们降低了神经网络的嵌入维度。下图 1 将 SliceGPT 方法与现有的稀疏性方法进行了比较。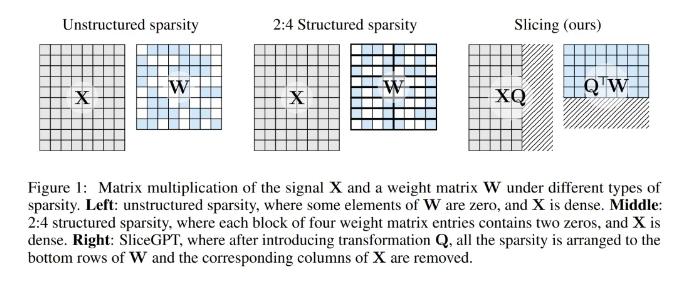
通过大量实验,作者发现 SliceGPT 可以为 LLAMA-2 70B、OPT 66B 和 Phi-2 模型去除多达 25% 的模型参数(包括嵌入),同时分别保持密集模型 99%、99% 和 90% 的零样本任务性能。经过 SliceGPT 处理的模型可以在更少的 GPU 上运行,而且无需任何额外的代码优化即可更快地运行:在 24GB 的消费级 GPU 上,作者将 LLAMA-2 70B 的推理总计算量减少到了密集模型的 64%;在 40GB 的 A100 GPU 上,他们将其减少到了 66%。此外,他们还提出了一种新的概念,即 Transformer 网络中的计算不变性(computational invariance),它使 SliceGPT 成为可能。
SliceGPT 详解
SliceGPT 方法依赖于 Transformer 架构中固有的计算不变性。这意味着,你可以对一个组件的输出应用一个正交变换,只要在下一个组件中撤销即可。作者观察到,在网络区块之间执行的 RMSNorm 运算不会影响变换:这些运算是可交换的。在论文中,作者首先介绍了在 RMSNorm 连接的 Transformer 网络中如何实现不变性,然后说明如何将使用 LayerNorm 连接训练的网络转换为 RMSNorm。接下来,他们介绍了使用主成分分析法(PCA)计算各层变换的方法,从而将区块间的信号投射到其主成分上。最后,他们介绍了删除次要主成分如何对应于切掉网络的行或列。假设 X_ℓ 是 transformer 一个区块的输出,经过 RMSNorm 处理后,以 RMSNorm (X_ℓ) 的形式输入到下一个区块。如果在 RMSNorm 之前插入具有正交矩阵 Q 的线性层,并在 RMSNorm 之后插入 Q^⊤,那么网络将保持不变,因为信号矩阵的每一行都要乘以 Q、归一化并乘以 Q^⊤。此处有: 
现在,由于网络中的每个注意力或 FFN 块都对输入和输出进行了线性运算,可以将额外的运算 Q 吸收到模块的线性层中。由于网络包含残差连接,还必须将 Q 应用于所有之前的层(一直到嵌入)和所有后续层(一直到 LM Head)的输出。不变函数是指输入变换不会导致输出改变的函数。在本文的例子中,可以对 transformer 的权重应用任何正交变换 Q 而不改变结果,因此计算可以在任何变换状态下进行。作者将此称为计算不变性,并在下面的定理中加以定义。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
